

このブログ記事では、以下の内容を学びます:
- Databricks Agent Bricksとは何か、そしてAIエージェント開発にもたらす価値。
- 内部ビジネスデータと外部のウェブインテリジェンスを組み合わせることで、DatabricksのAIエージェントがより強力になる理由。
- Agent BricksのAIエージェントをBright DataのWeb MCPに接続することで、これらの機能を実装する方法。
さっそく始めましょう!
Databricks Agent Bricksとは?
Agent Bricksは、企業データに基づいた本番グレードのAIエージェントを構築・デプロイ・管理するためのDatabricksサービスです。エンタープライズコンテキスト、AIモデル、外部ツールを組み合わせることで、信頼性が高くスケーラブルで管理されたAIエージェントを作成できます。
ドキュメント分析、カスタマーサポート、リサーチ、ワークフロー自動化、ビジネスインテリジェンスなどのシナリオに特に有用です。主な機能は以下の通りです:
- エンタープライズ対応AIエージェント:ビジネススキーマ、定義、セマンティックコンテキストを活用して、より正確で根拠のある回答を生成します。
- 複数のエージェントタイプ:ナレッジアシスタント、情報抽出パイプライン、マルチステップワークフロー用スーパーバイザーエージェント、完全カスタムPythonエージェントをサポートします。
- マルチモデルサポート:OpenAI、Anthropic、Google、Meta、オープンソースプロバイダーのモデルに、モデル切り替えとフォールバックロジックを備えた単一プラットフォームからアクセスできます。
- 外部統合:MCPサーバー、API、エンタープライズシステムに接続し、内部データを超えたエージェント機能を拡張します。
- ガバナンスとセキュリティ:Unity Catalogと統合して、権限、系統、所有権、きめ細かいアクセス制御を適用します。
- 評価と可観測性:自動ベンチマーク、LLM-as-a-judge評価、デバッグ・モニタリング用のMLflowトレーシングを含みます。
DatabricksのAIエージェントにウェブアクセスが必要な理由
どのプラットフォームで構築したとしても、エンタープライズAIエージェントはアクセスできるツールの範囲でしか機能を発揮できません。これはすべてのLLMが共有する2つの根本的な制限によるものです:
- 知識の制限:LLMは過去のスナップショットを表す静的なデータセットで学習されています。
- 外部システムへのネイティブアクセスがない:デフォルトでは、LLMはウェブやテクノロジースタック内の他のサービスと連携できません。
このギャップは、通常MCPやカスタム統合を通じてAIエージェントにツールを装備することで解決されます。これがDatabricks Agent BricksがMCPをサポートする理由です。
両方の制限に対処するには、AIエージェントがウェブを検索し、関連情報を発見し、ウェブサイトからコンテンツを抽出できるMCPが必要です。それがまさにBright DataのWeb MCPが提供するものです。
Bright Data Web MCPがソリューションである理由
Bright Data Web MCPはBright DataのAPIに接続するツールを提供します。これはDatabricksで公式にサポートされた統合のひとつであり、Databricks Marketplaceで直接見つけることもできます:
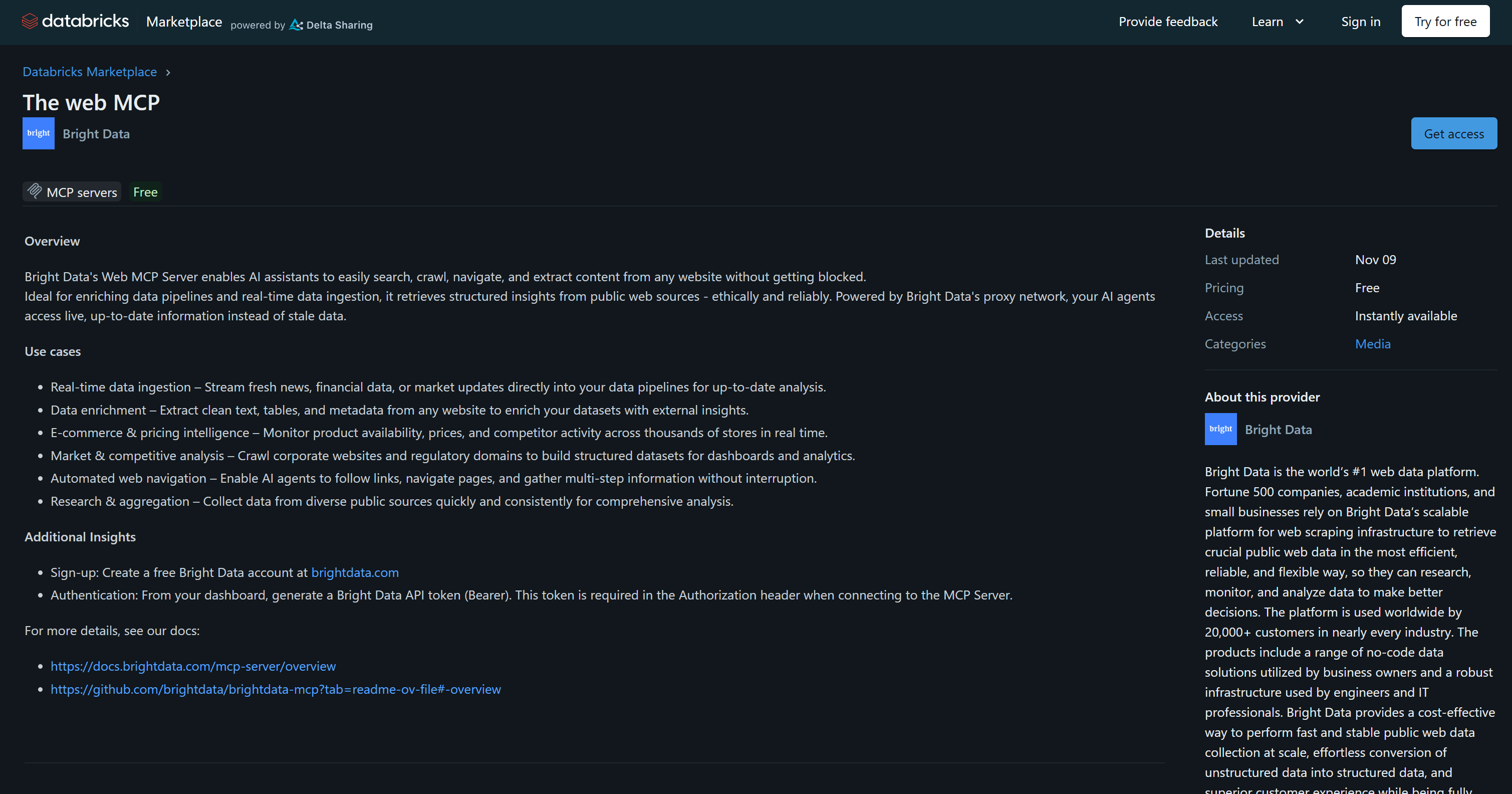
無料のRapidモードティア(月5,000リクエスト無料を含む)では、Web MCPの利用可能なツールは以下の通りです:
| ツール | 説明 |
|---|---|
search_engine + バッチ版 |
Google、Bing、Yandexなどから構造化された検索エンジン結果をJSONまたはMarkdown形式で取得 |
scrape_as_markdown + バッチ版 |
アンチボット対策を回避しながら任意のウェブページをクリーンなMarkdownに変換 |
discover |
ランク付けされた関連結果を返すAI搭載のウェブ検索 |
[Proモード](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes)では、Amazon、LinkedIn、Yahoo Finance、YouTube、Zillow、Google Mapsなど40以上のソースに対応した高度な構造化抽出機能が利用可能になります。ブラウザ自動化ツールも含まれています。すべてのWeb MCPツールをご確認ください。
Bright Dataが際立っているのは、4億以上のレジデンシャルIPによるプロキシネットワークに支えられたエンタープライズグレードのインフラです。これにより無制限のスケーラビリティと同時実行性をサポートし、99.95%の成功率とSLAに裏付けられた99.99%の稼働率を実現しています。
Databricks Agent BricksをBright DataのWeb MCPに接続する方法
このステップバイステップの章では、DatabricksでWeb MCPを設定するプロセスを案内します。その後、ウェブ検索、検索、スクレイピング機能を有効にするために、Agent BricksのDatabricks AIエージェントに統合する方法を学びます。
注意:DatabricksでBright Dataのデータセットにアクセスしてクエリを実行する方法をお探しの場合は、専用のブログ記事をご覧ください。
以下の手順に従ってください!
前提条件
このチュートリアルセクションを完了するために、以下をご用意ください:
- Databricksアカウント(クレジットカードを設定したExpressセットアップによる無料トライアルが必要)。
- APIキーが設定されたBright Dataアカウント。Bright Data APIキーの生成については公式ガイドを参照してください。
よりスムーズな体験のために、以下も推奨します:
- MCPの仕組みについての基本的な理解。
- Bright Data Web MCPが提供するツールへの習熟。
ステップ#1:Bright Data Web MCPをインストールする
Databricksアカウントにログインします。ホームワークスペースダッシュボードが表示されます:
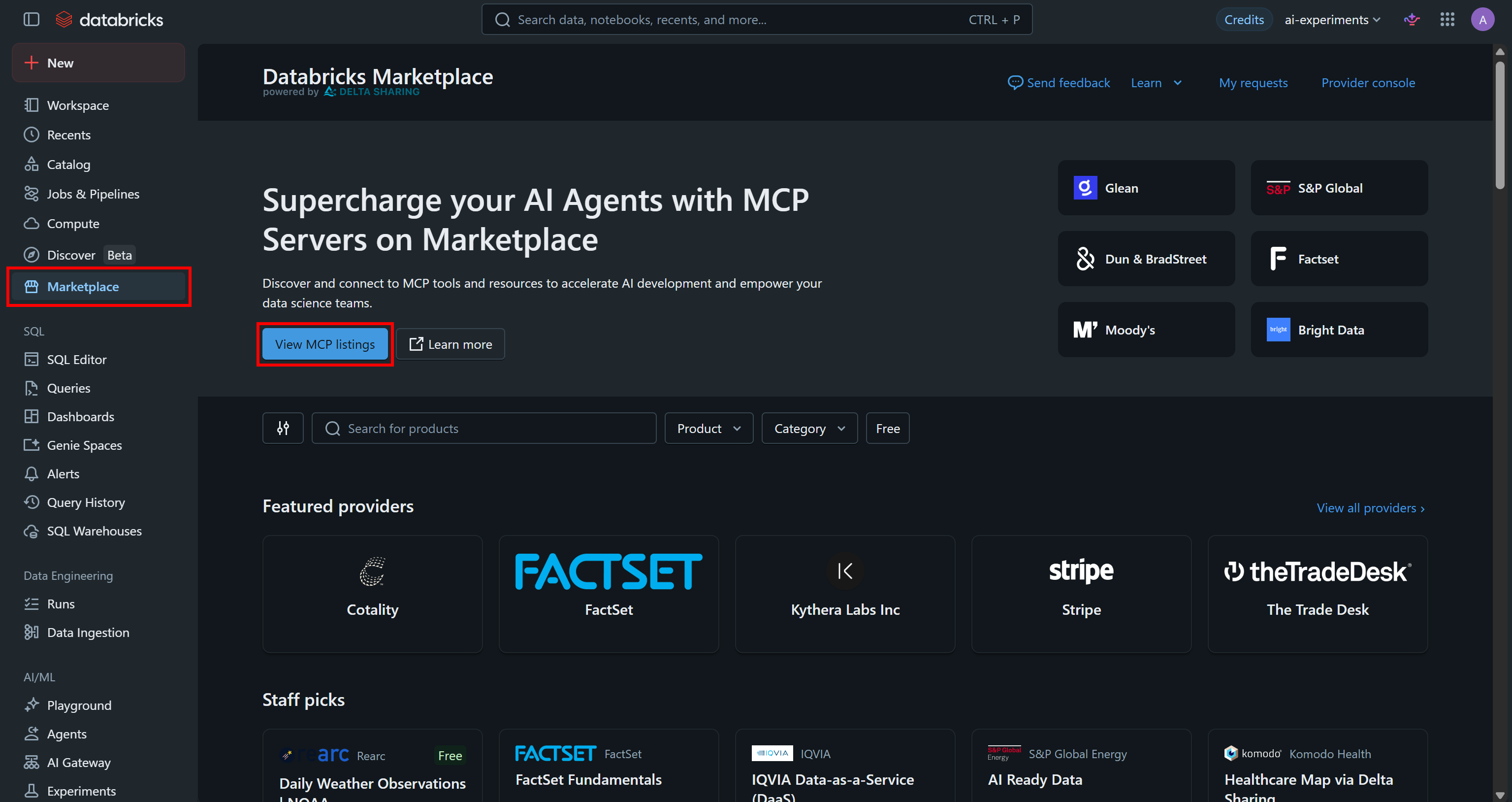
Bright Data Web MCPはDatabricks Marketplaceで利用できる公式サポート統合です。左サイドバーから「Marketplace」オプションを選択し、「View MCP listings」を押してください:
Databricks Marketplaceにリダイレクトされます。検索バーに「bright data」と入力し、「The web MCP」リストを選択してください:
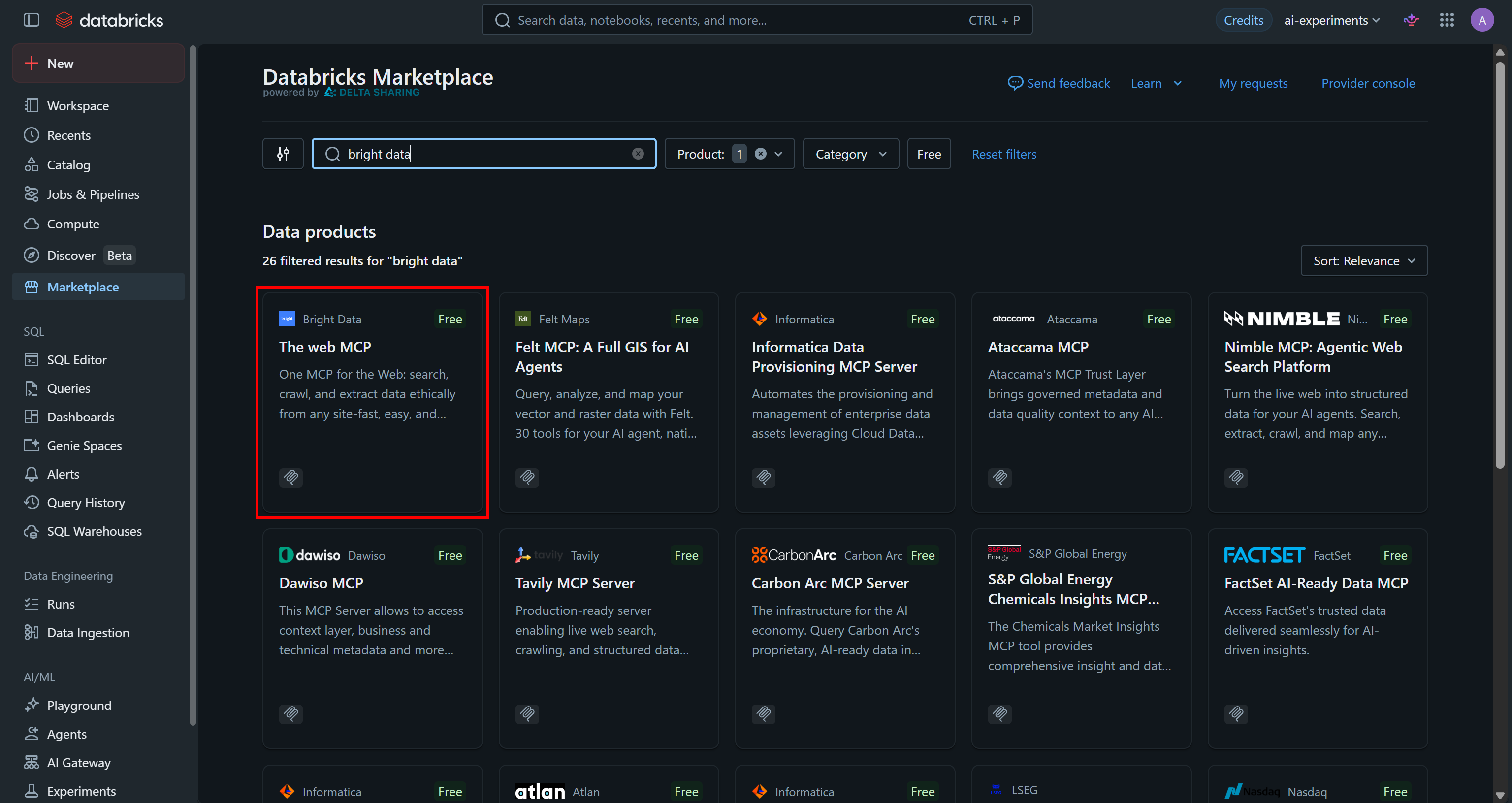
Bright Data「The web MCP」ページで詳細を確認し、「Install」をクリックしてワークスペースに追加します:
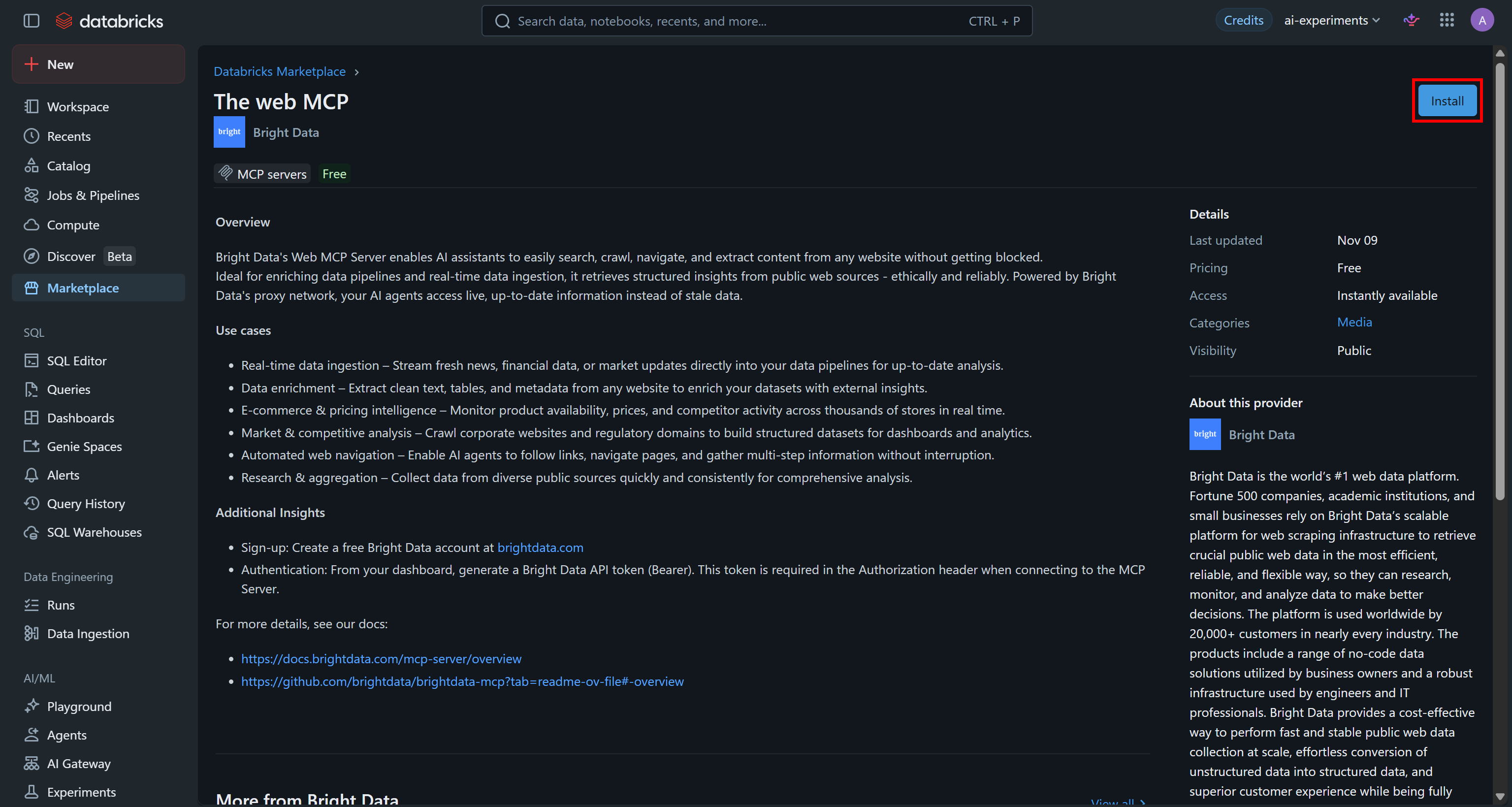
インストールフォームに以下の詳細を入力してください:
- Connection name:
bright-data-web-mcp(または任意の名前) - Host:
https://mcp.brightdata.com(重要:提案されたURLがこれと一致することを確認してください) - Base path:
/mcp - Bearer token:Bright Data APIキーを貼り付けてください
- Credential type:Bearer token
- Port:433
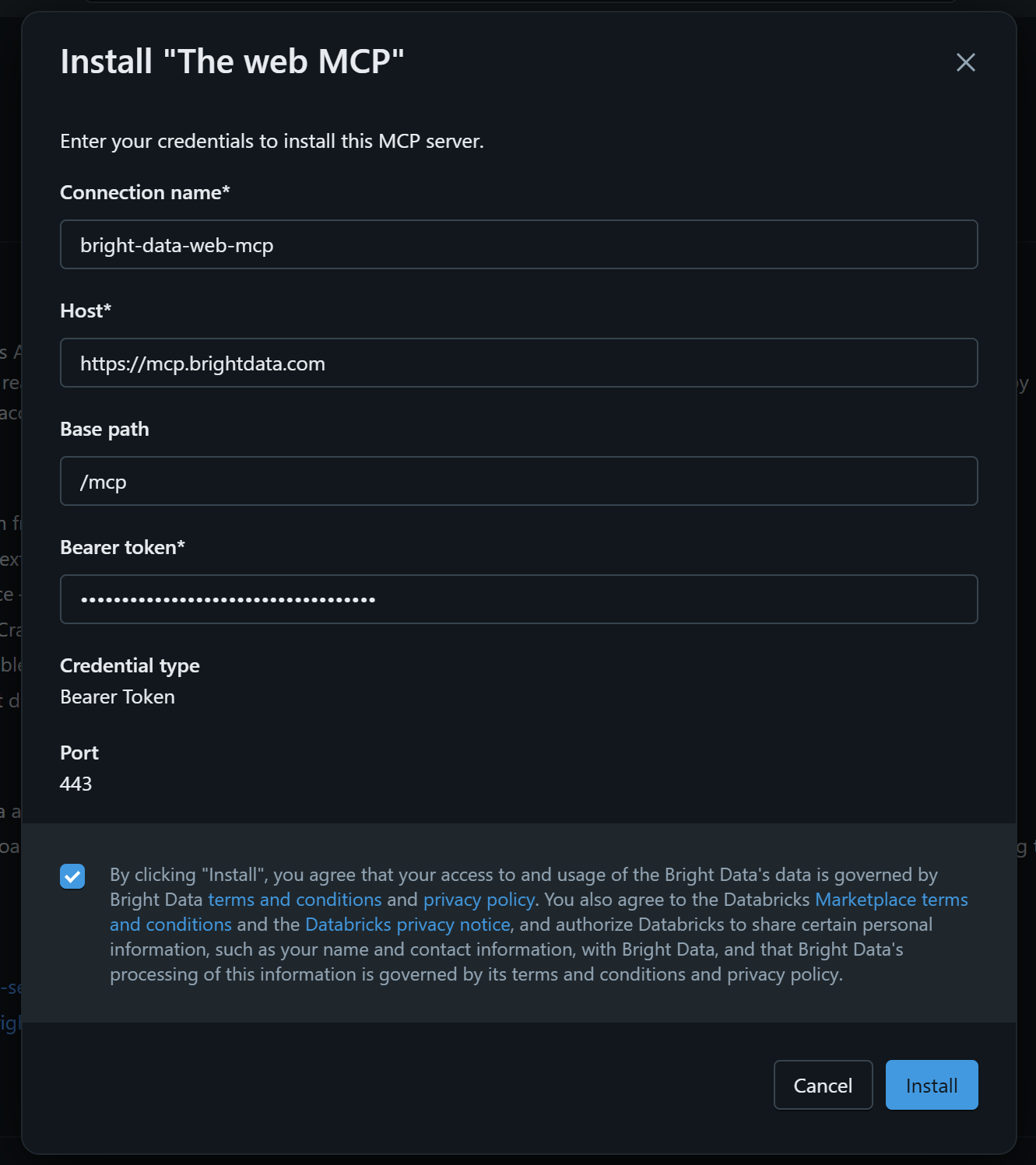
最後に「Install」をクリックして、公式統合経由でBright Data Web MCPをDatabricksワークスペースに追加します。完了です!
ステップ#2:Bright Dataサーバーへの接続を許可する
インストール後、bright-data-web-mcpページにリダイレクトされます。ただし、設定されたMCPサーバーのツールが検出されない場合があります:
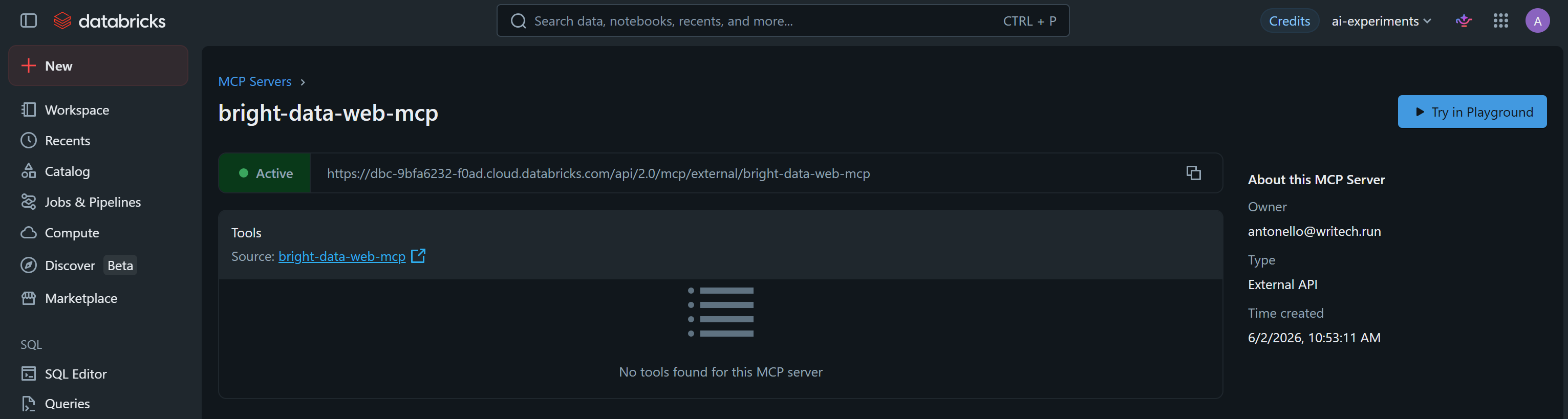
これは、Databricksがデフォルトで外部ドメインへのアウトバウンド接続をブロックしているためです。Web MCPサーバーに必要なmcp.brightdata.comも含まれます。
参考として、基礎となる技術的なエラーは以下の通りです:
"Failed request to https://mcp.bringthdata.com:443/mcp. Error: Access to mcp.bringthdata.com is denied because of serverless network policy."これを修正するには、Databricksアカウント設定でサーバーレスエグレストラフィックに対してmcp.brightdata.comへのアクセスを明示的に許可する必要があります。右上のワークスペースドロップダウンを開き、「Manage account」を選択してください:
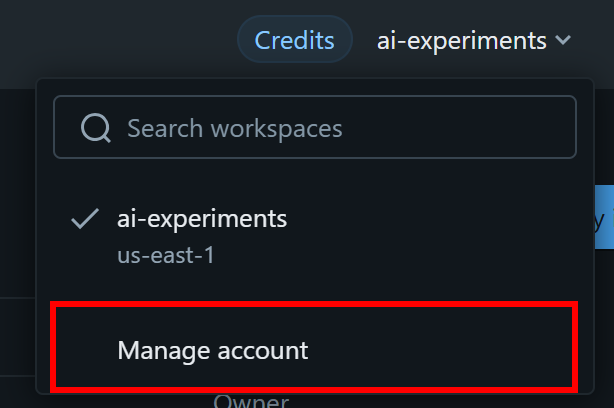
「Security」セクションに移動し、「Serverless egress control」を選択して、「Create new network policy」をクリックします:
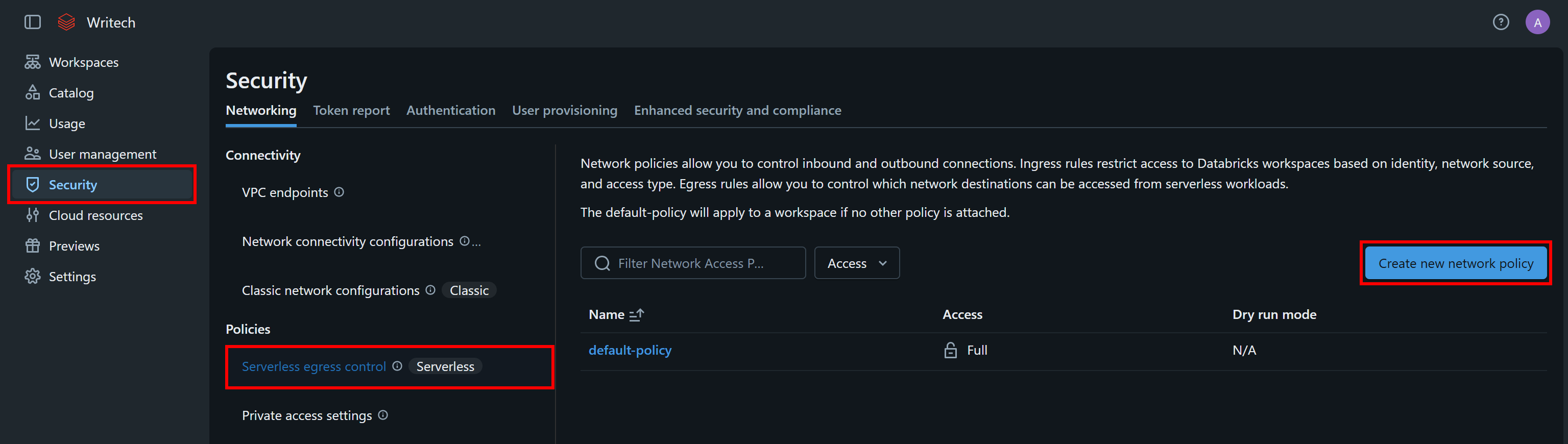
ポリシーに名前を付け(例:bright-data-mcp)、「Restricted access to specific destinations」オプションを選択します。次に「Add destination」ボタンを使ってmcp.brightdata.comを許可された宛先として追加します:
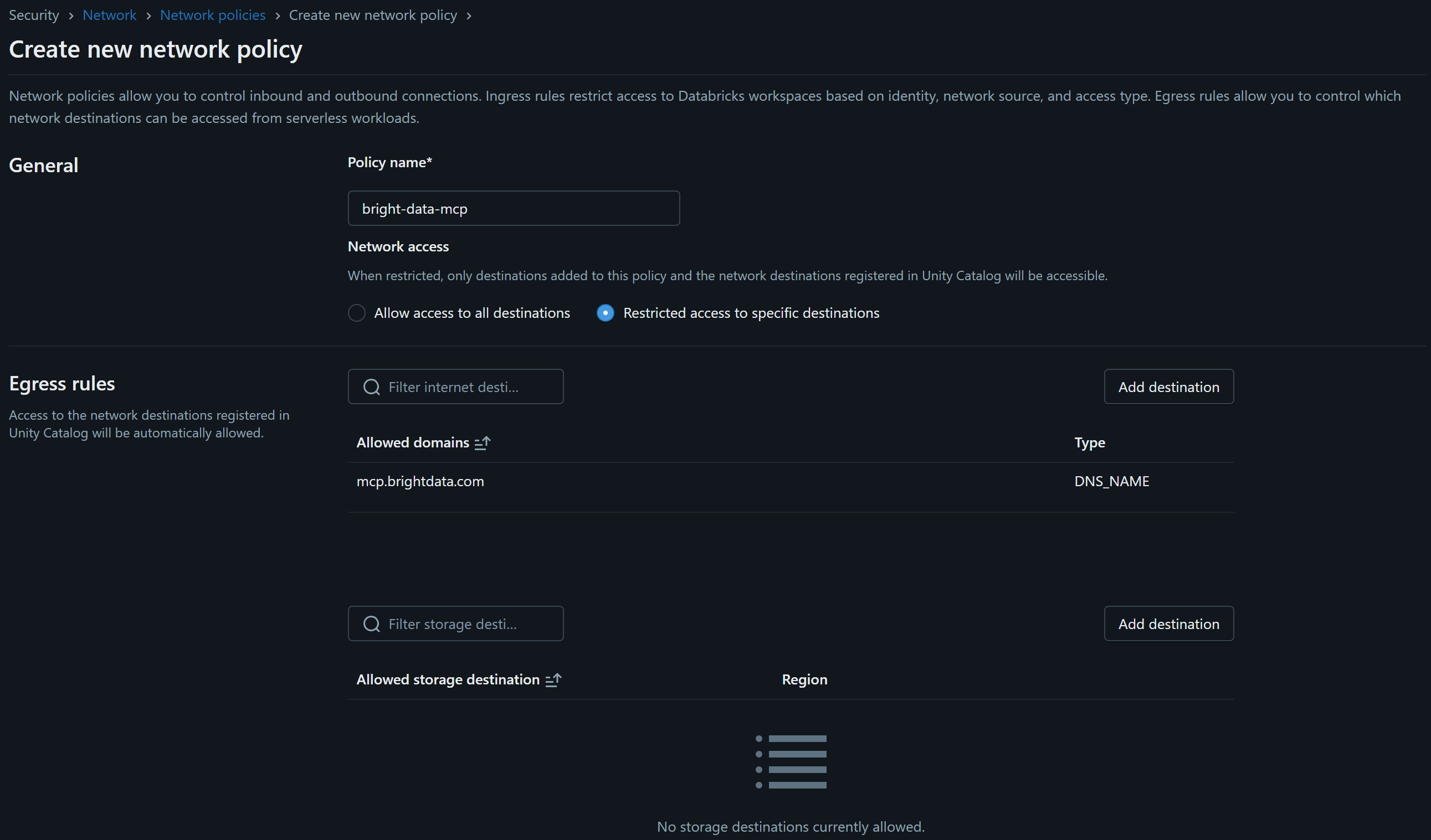
すべてのDatabricksサーバーレス製品に対してポリシーを有効にし、「Create」をクリックします:
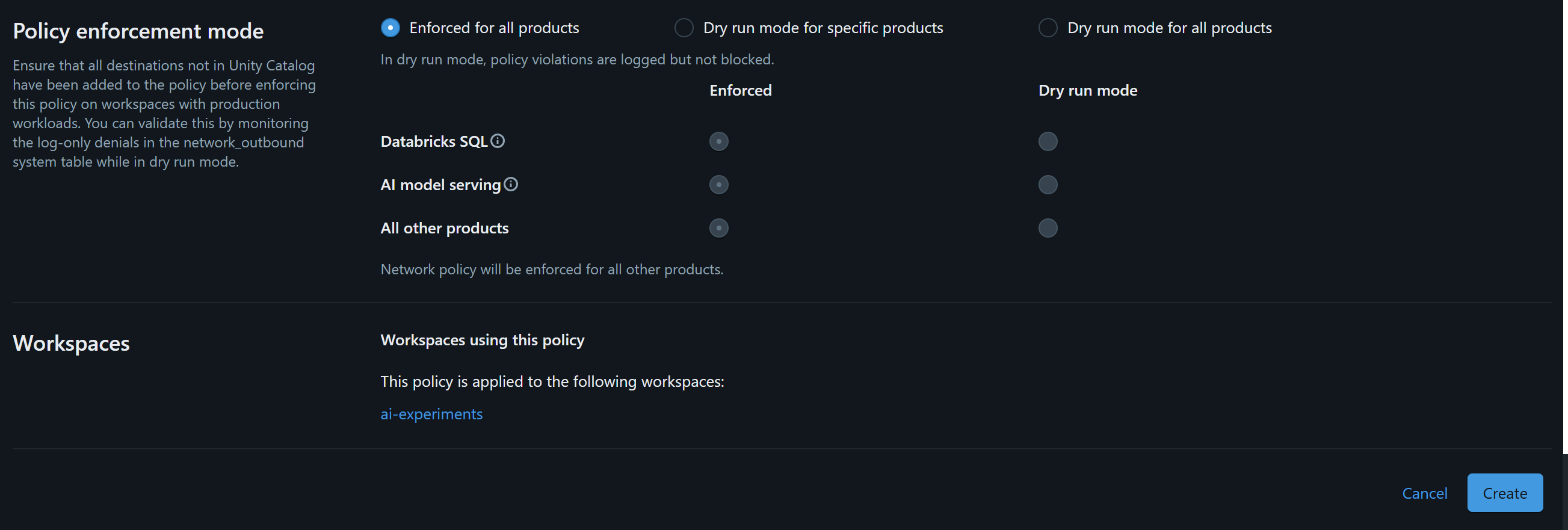
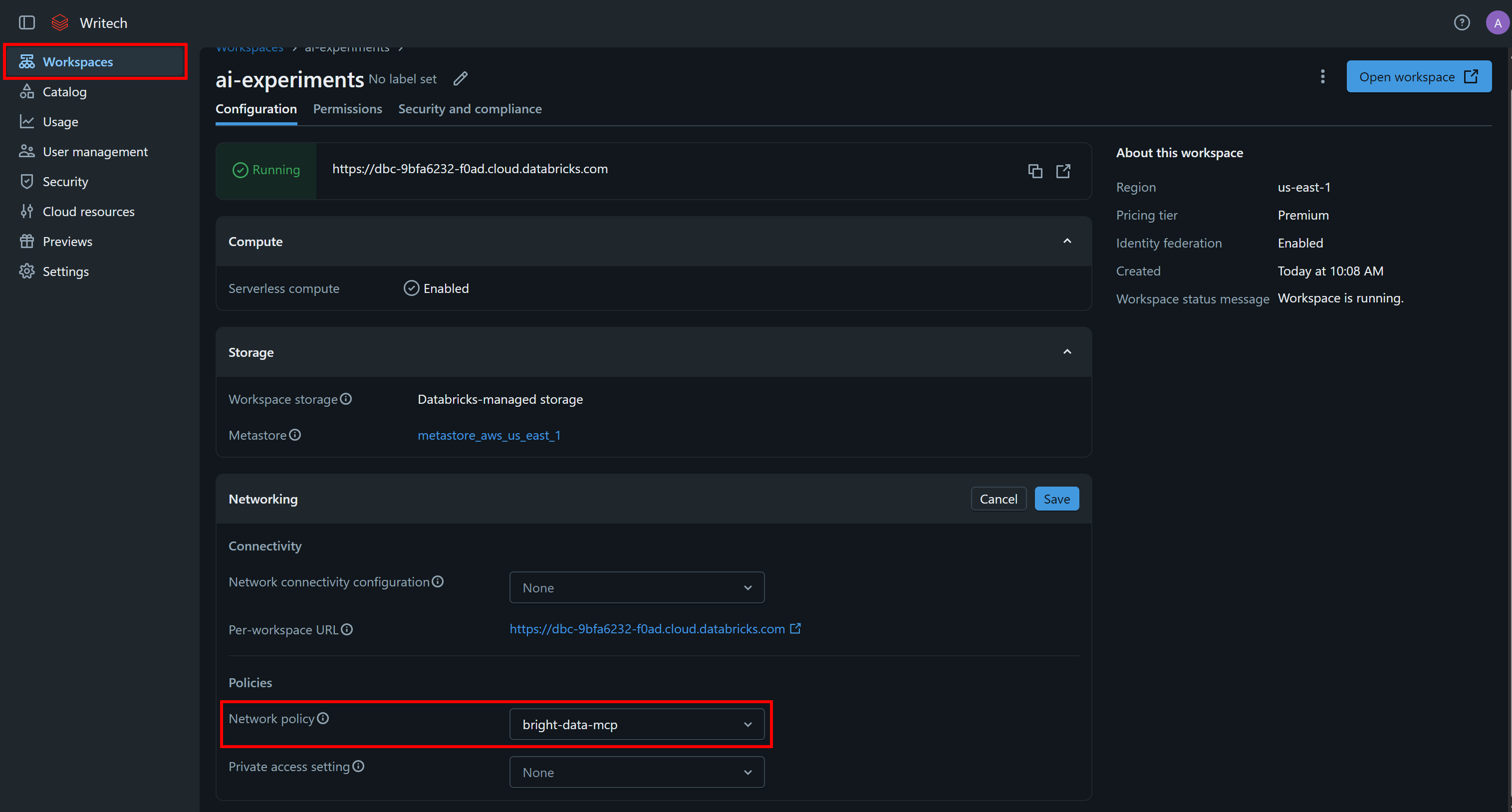
次に、Workspacesページに移動し、ワークスペースを選択して、「Networking」ドロップダウンセクションの編集アイコンをクリックします。ネットワークポリシーをbright-data-mcpに設定し、「Save」をクリックします:
bright-data-web-mcpページに戻ってリフレッシュします。DatabricksがWeb MCPツールを正常に読み込んでいることが確認できるはずです:
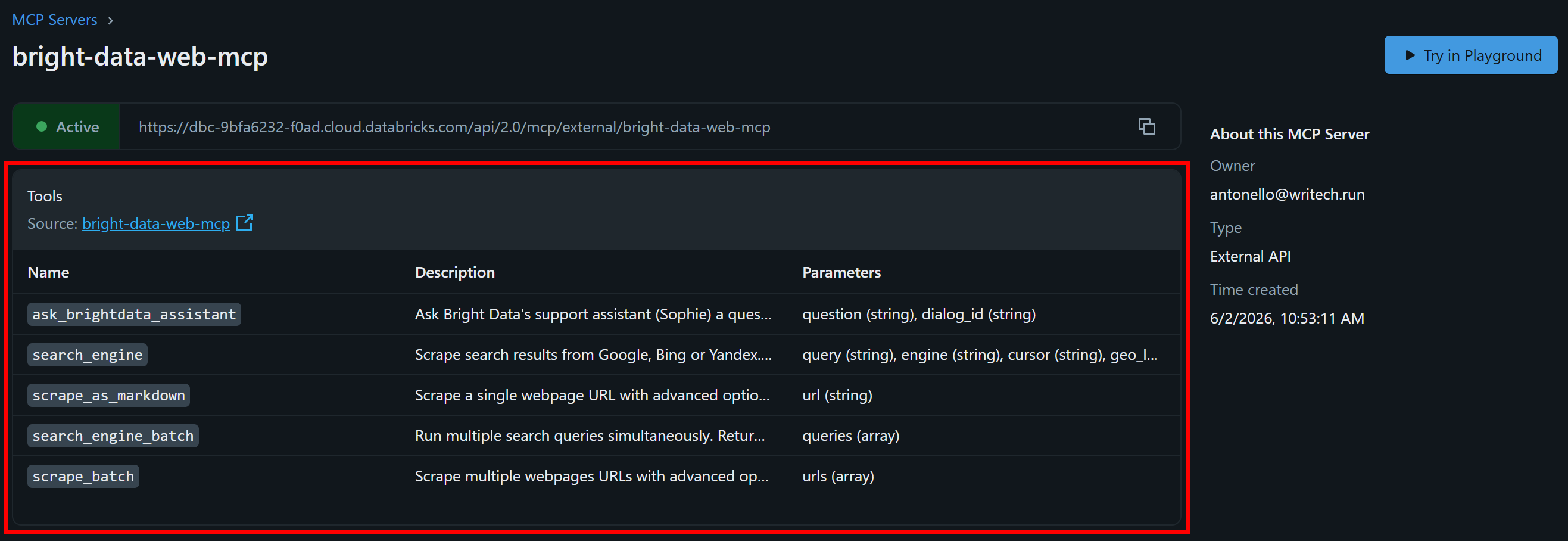
これらのツールはRapid(無料)モードのWeb MCPが提供する機能に対応しています。よくできました!
ステップ#3:Web MCP接続の動作を確認する
bright-data-web-mcp pageで「Try in Playground」をクリックします。MCPサーバーがすでに設定されたAIチャットインターフェースが開きます。
次のような簡単な質問をしてみましょう:
Scrape the https://example.com page as MarkwonAIが指定されたURLに対してWeb MCPツールscrape_as_markdownを自律的に呼び出してタスクを完了するのが確認できるはずです:
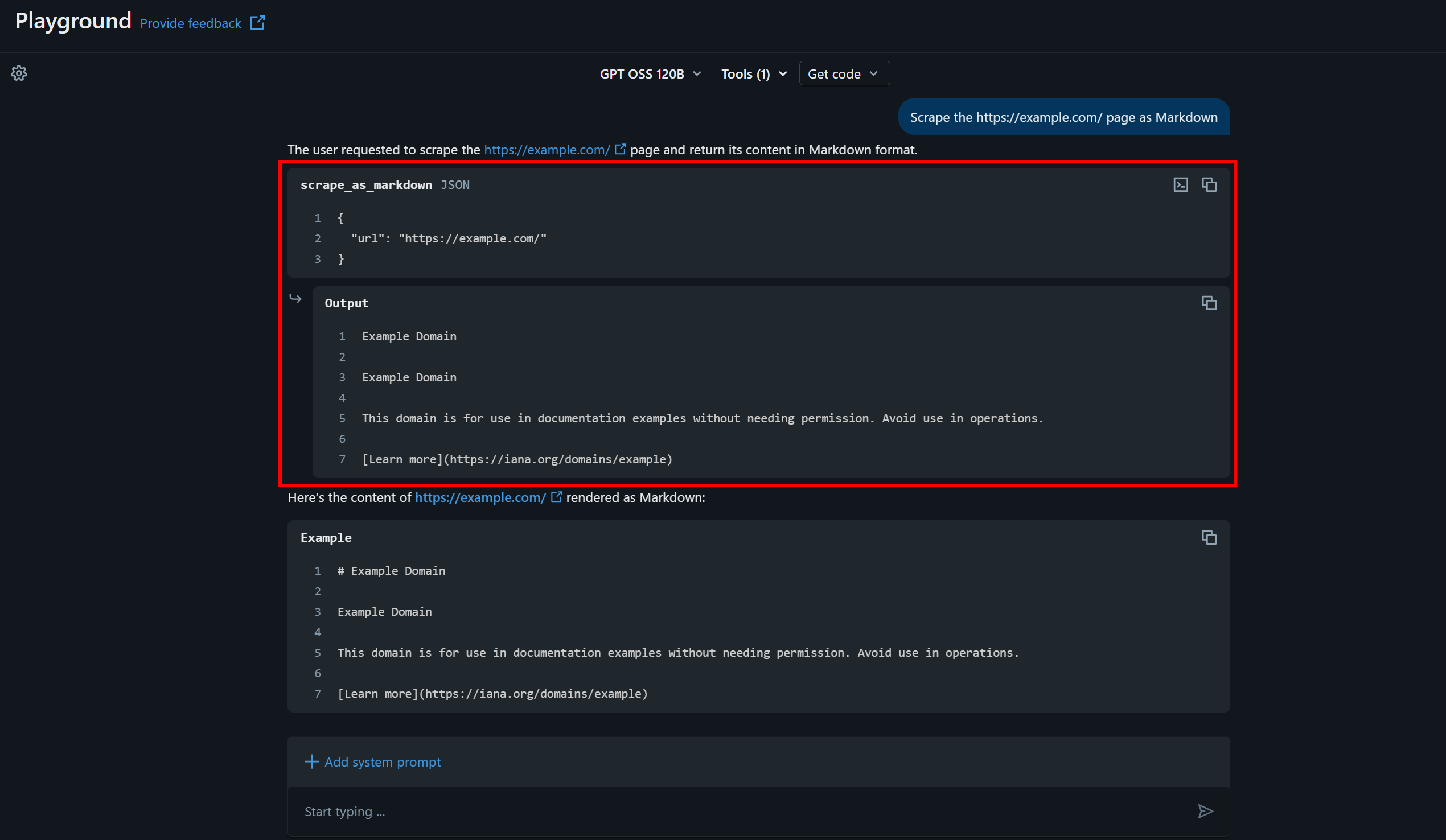
返されたMarkdown(Bright DataのWeb Unlocker APIに支えられたscrape_as_markdownツールで取得)は、対象ページに表示されているコンテンツと一致しています:
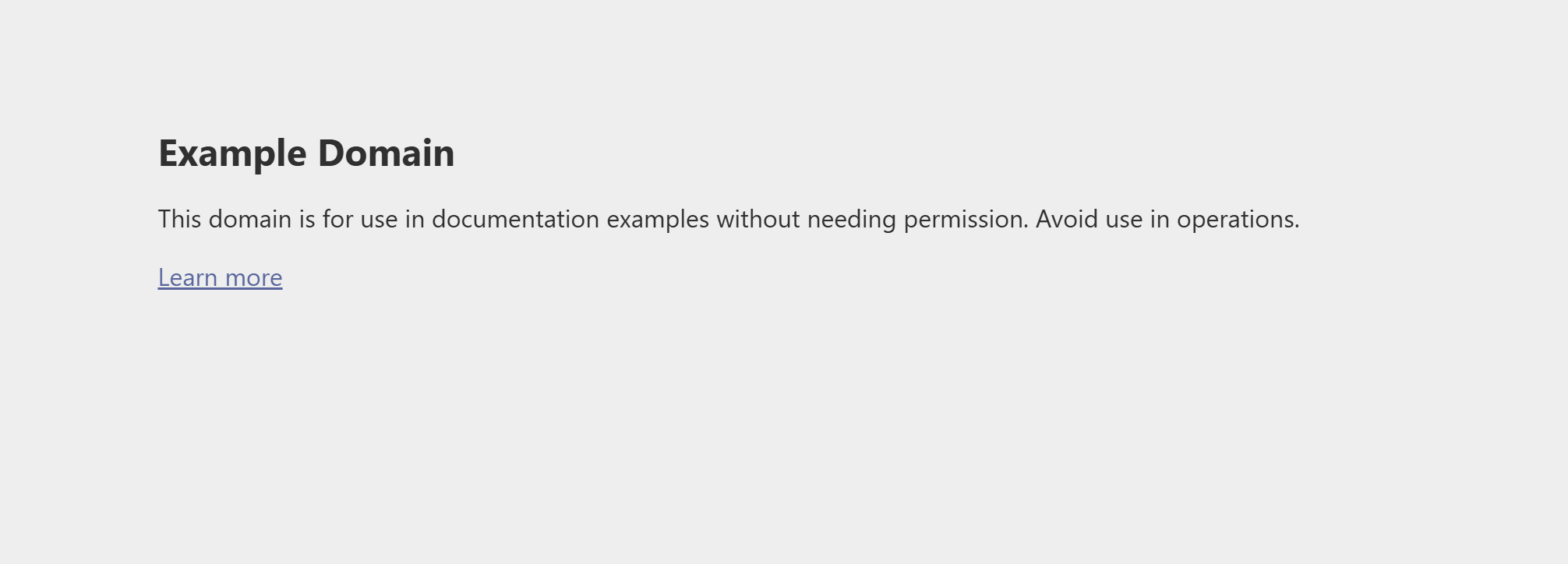
これにより、AIがWeb MCPツールを正しく使用しており、統合が期待通りに動作していることが確認されました。完璧です!
ステップ#4:Databricks AIエージェントを定義する
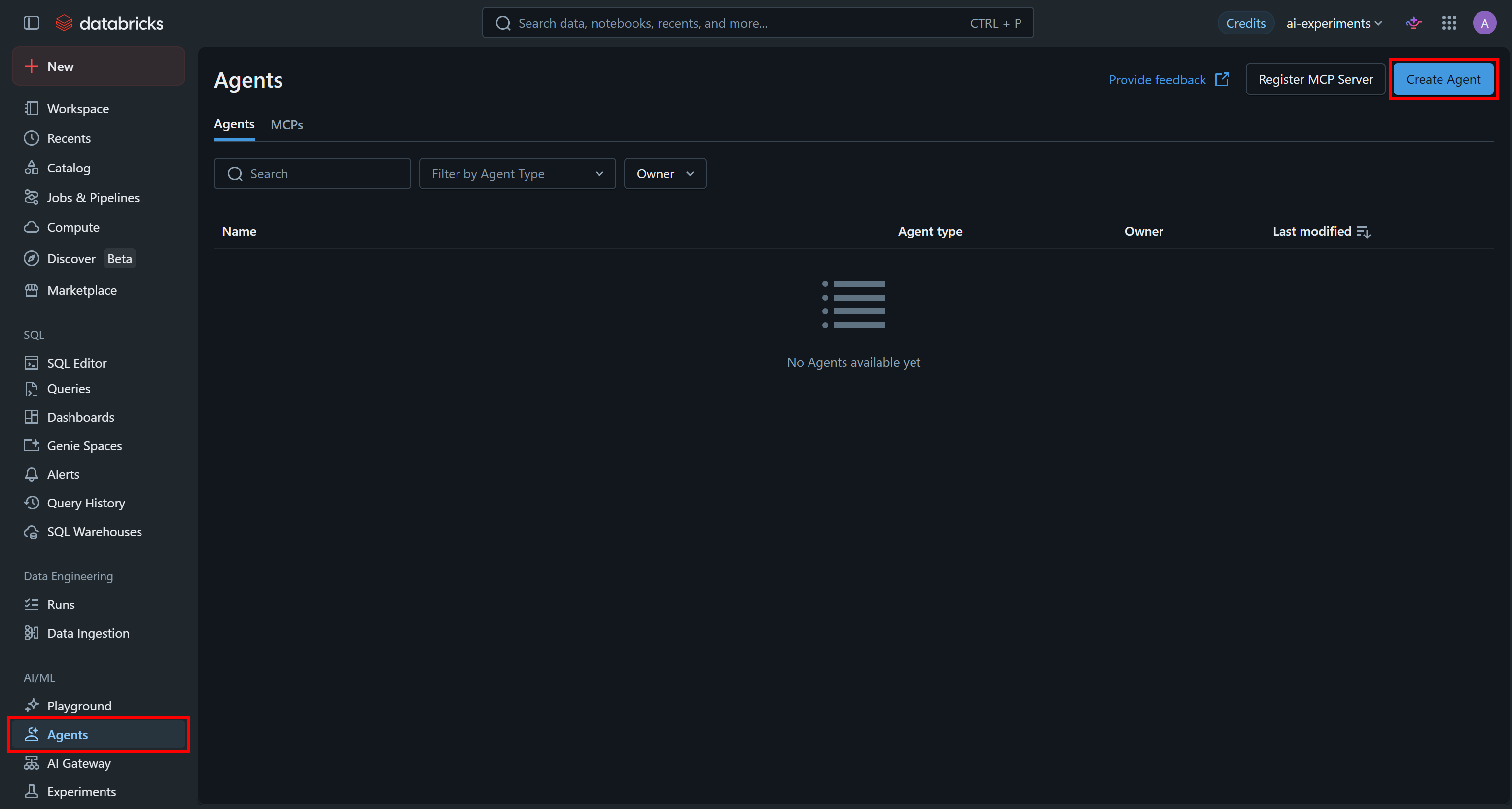
Databricks Agent Bricksサービスにアクセスするには、左サイドバーの「Agents」をクリックします。次に「Create Agent」を押して新しいAIエージェントを追加します:
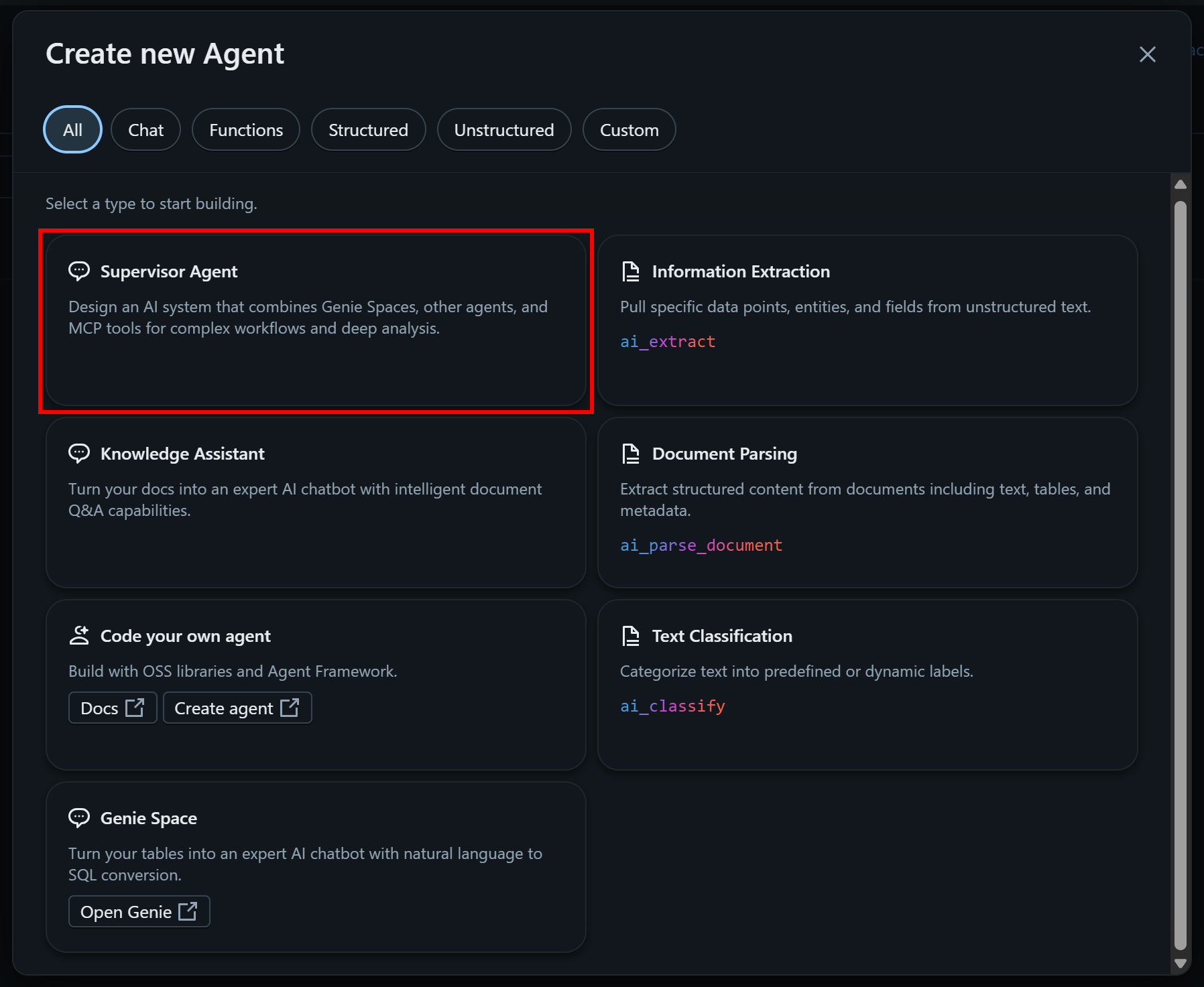
作成するエージェントのタイプを選択するよう求められます。このチュートリアルでは「Supervisor Agent」を選択します:
スーパーバイザーエージェントは、AIエージェントとツールを調整してより複雑なタスクを解決するマルチエージェントオーケストレーションシステムです。
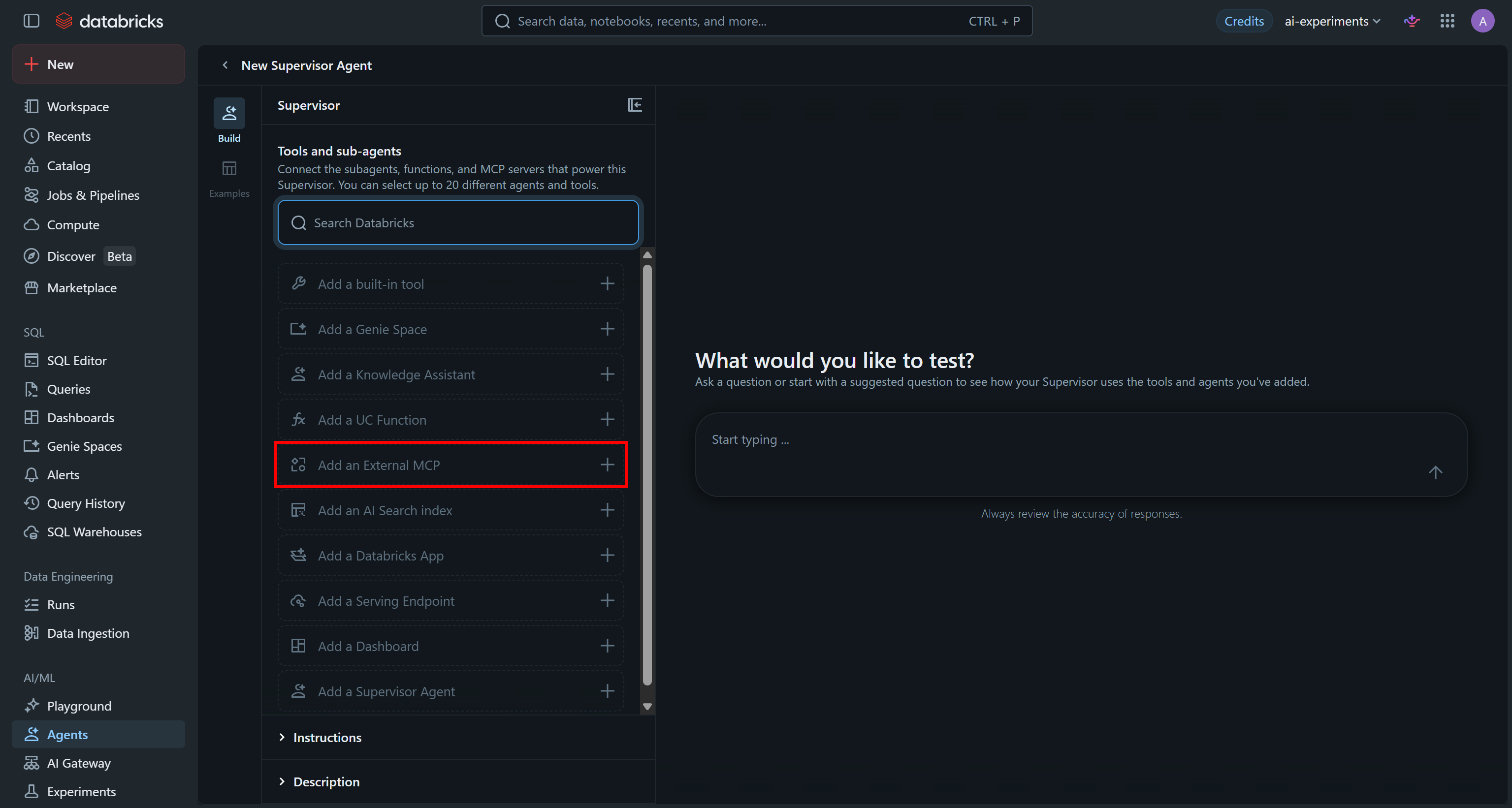
Bright Data Web MCPを接続するには、「Tools and subagents」セクションの「Add an External MCP」をクリックします:
次に、先ほど設定したbright-data-web-mcp接続を選択します:
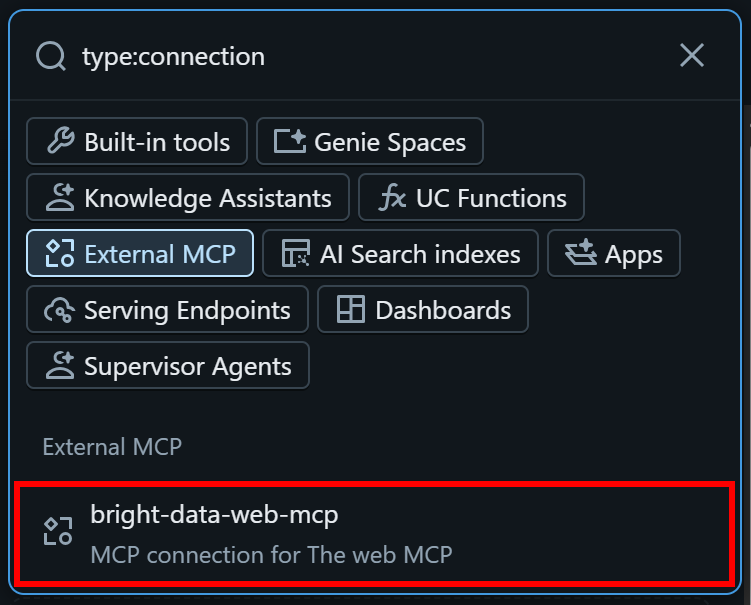
これでエージェントはBright Data Web MCPツールにアクセスできるようになります。同じプロセスを繰り返して、追加のツール、MCPサーバー、Genie Spaces、その他の統合を追加できます。
この例では、エージェントはサンプルのsamples.bakehouse Deltaデータセットにリンクされた組み込みのGenie Spaceである「Bakehouse Sales Starter Space」にも接続されています。
重要:本番環境では、独自のDatabricksデータセットに接続したカスタムGenie Spacesを使用するようにエージェントを設定してください。また、特定のユースケースに合わせてエージェント名、指示、説明をカスタマイズする必要があります。
素晴らしい!残りのステップは、Web MCPを搭載したDatabricks AIエージェントをテストするだけです。
ステップ#5:エージェントをテストする
Databricks AIエージェントが正しく動作していることを確認するために、内部ビジネスデータと外部ウェブインテリジェンスを組み合わせるタスクを試してみましょう。例えば、以下のように入力します:
Retrieve our revenue for May 2024. Then search online for bakery industry revenue data for the same period. Scrape the most relevant sources and produce a report highlighting both internal revenue performance and external market insights, including trends, expectations, and overall industry conditions.プロンプトを実行すると、次のような結果が表示されます:
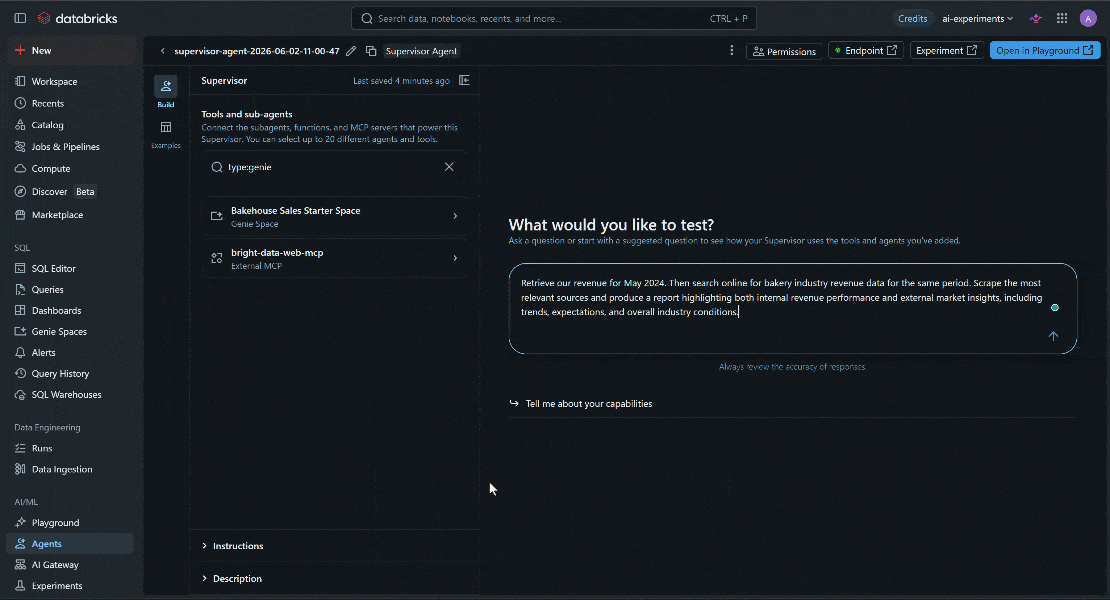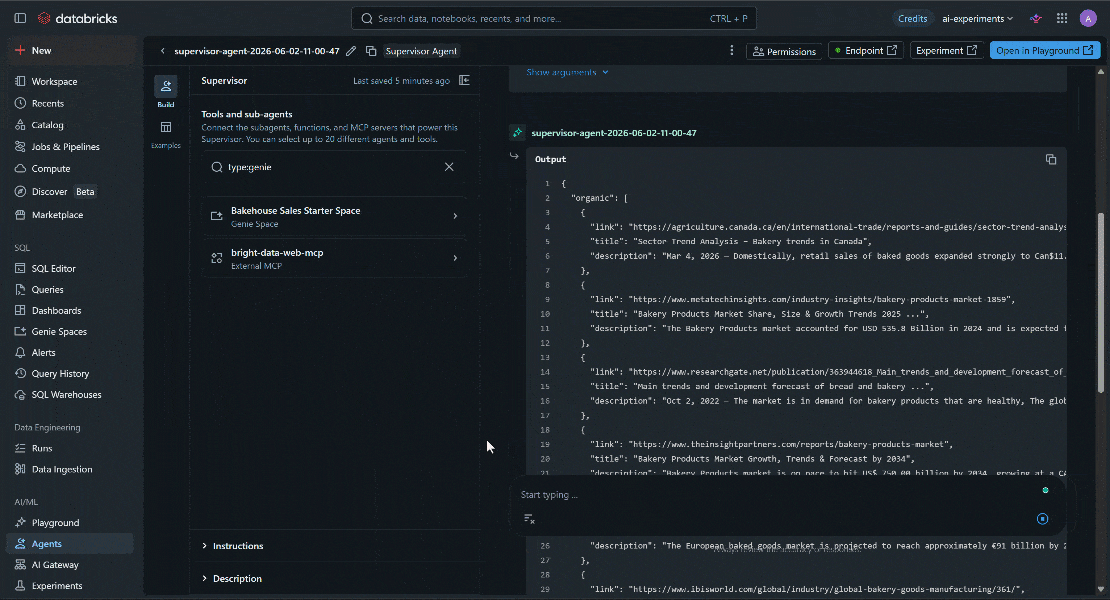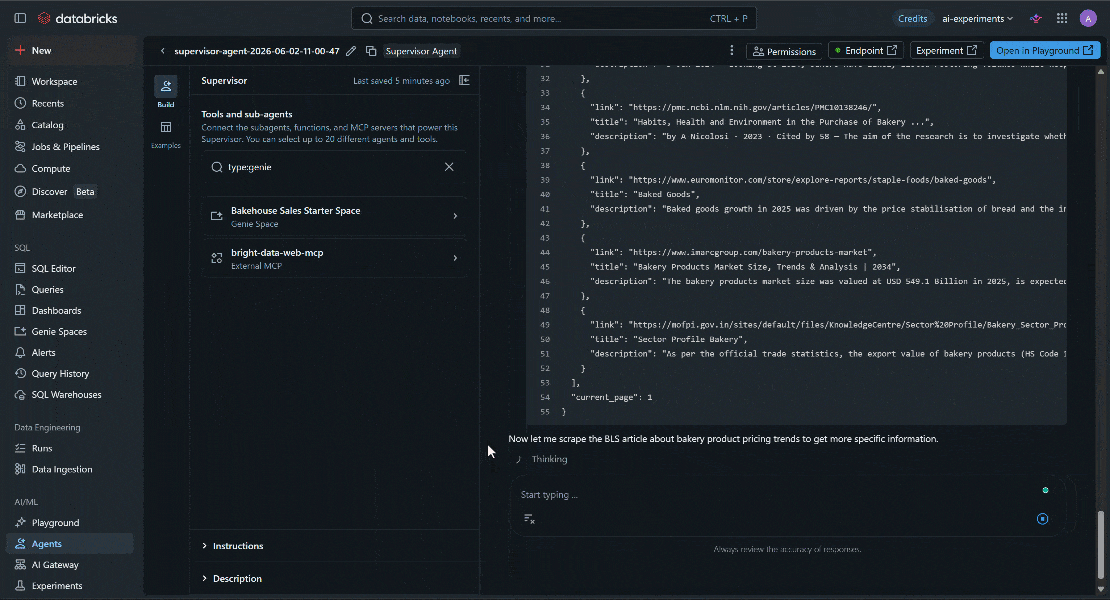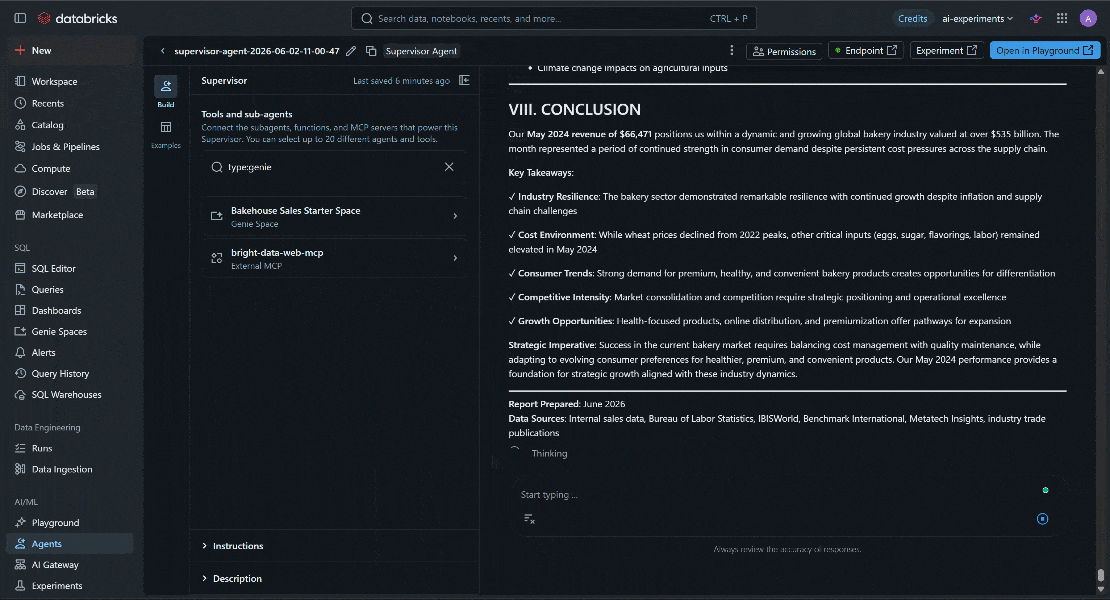
具体的には、Databricks AIエージェントは以下を実行しました:
- 「Bakehouse Sales Starter Space」にクエリを実行し、要求された期間の収益データを取得。
- Bright Data Web MCPの
search_engineツール(Bright DataのSERP APIで動作)を呼び出し、パン業界の業績に関するGoogleからの関連検索結果を収集。 - 返された結果から最も関連性の高いソースを特定。
scrape_as_markdownツールを使用してそれらのページからコンテンツを抽出。- 外部インサイトと内部ビジネスデータを組み合わせて統合レポートを生成。
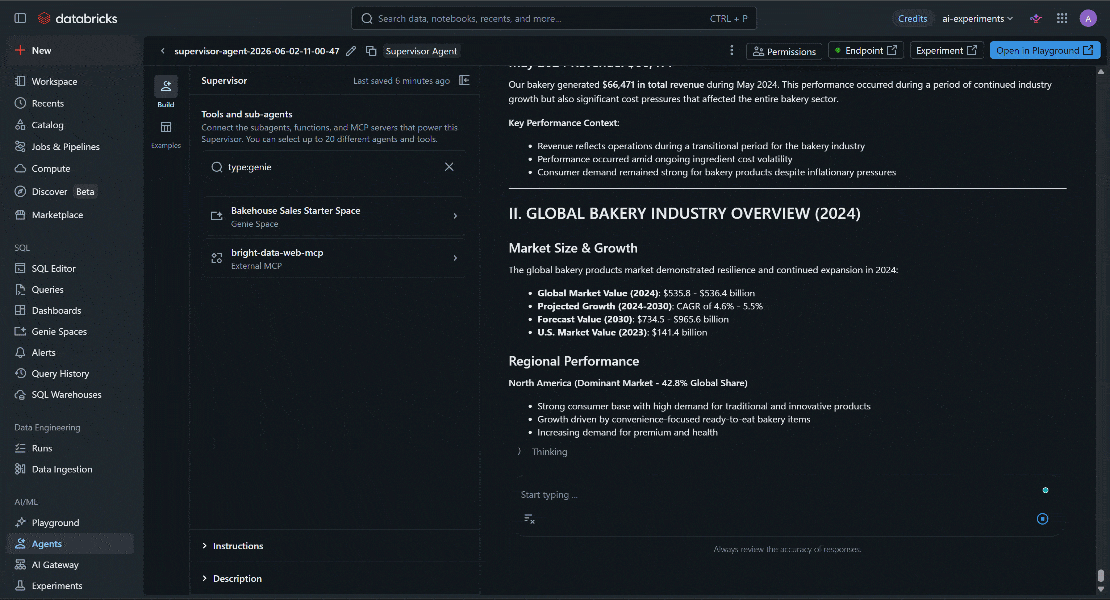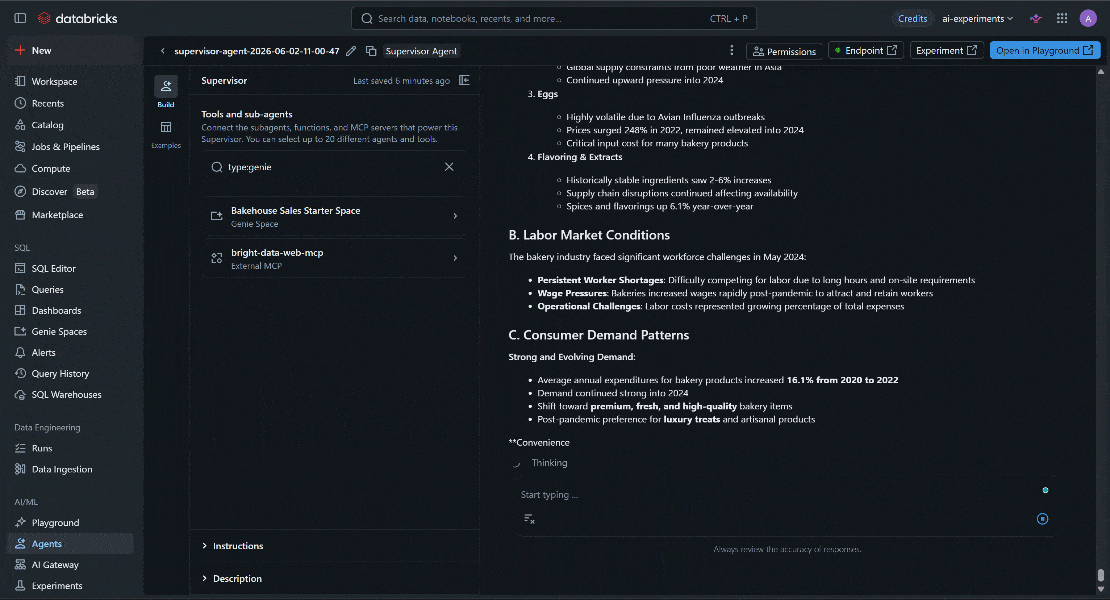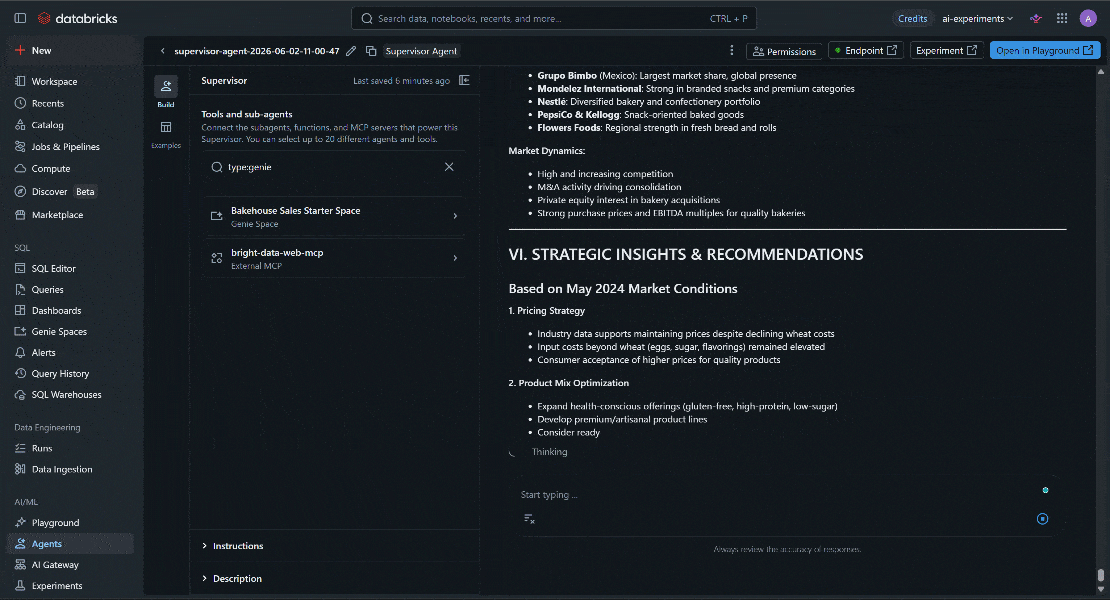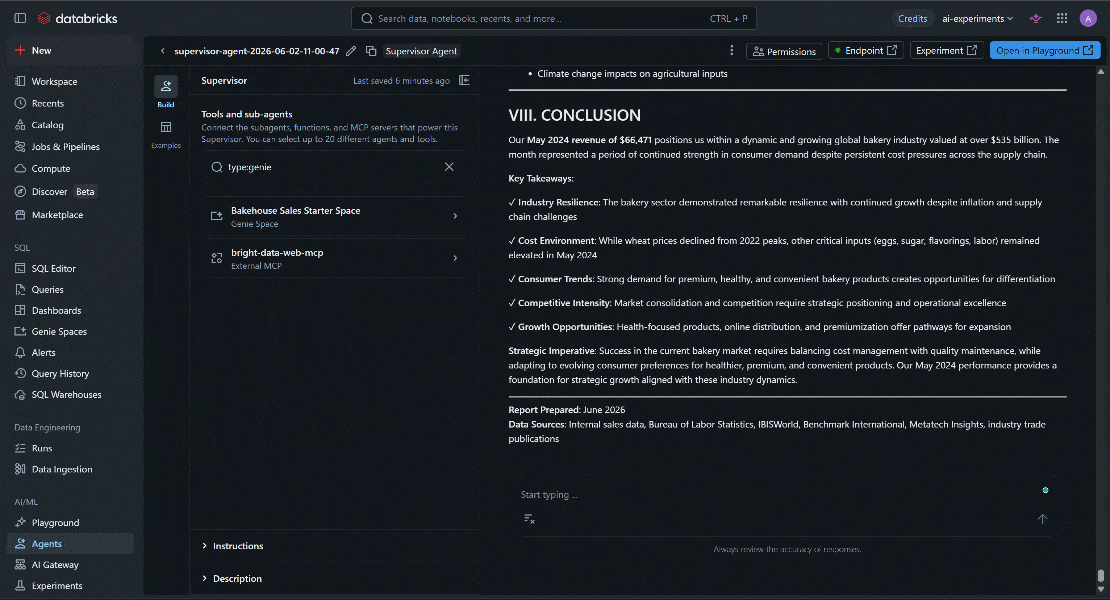
最終的な出力が独自のビジネス情報と最新の市場インテリジェンスを融合していることに注目してください。LLMはネイティブなウェブアクセスを持たないため、Web MCPなしではこれは不可能でした。
Web MCPはそのギャップを埋め、Databricks AIエージェントがウェブを検索し、関連ソースを発見し、複雑なページや保護されたページを含むウェブサイトから情報を抽出できるようにします。これらはすべて、スケーラビリティと同時実行性のために構築されたBright Dataのエンタープライズグレードインフラ上で動作します。
これで完成です!この例は構築できるものの表面に過ぎません。Databricks AIエージェントとBright Data Web MCPを組み合わせることで、幅広いユースケースに対応した、内部分析とリアルタイムウェブデータを統合するより高度なワークフローを構築できます。
まとめ
このチュートリアルでは、Databricks Agent Bricksとそのサポート機能について学びました。特に、Databricks AIエージェントを構築し、Bright Data Web MCPに接続する方法を確認しました。
この統合により、Databricks AIエージェントはリサーチ、グラウンディング、データエンリッチメント、その他多くのタスクのためにウェブへのアクセスを獲得します。これにより、内部Databricksデータとエンタープライズ対応の外部インテリジェンスを組み合わせ、より深くリッチな分析への扉が開かれます。
より高度なシナリオについては、AIエコシステム向けに構築されたBright Dataソリューションの全範囲をご覧ください。
今すぐBright Dataアカウントを作成し、AI対応のウェブデータツールで構築を始めましょう!






