
このチュートリアルでは、次のことを学びます:
- Cursorとは何か、なぜこれほど人気があるのか。
- Bright DataのようなMCPサーバーをCursorに追加する主な理由。
- CursorをBright Data Web MCPに接続する方法。
- Visual Studio Codeで同じ結果を得る方法。
さっそく見ていきましょう!
Cursorとは?
Cursorは、Visual Studio Codeのフォークとして構築されたAIを搭載したコードエディタです。核となる機能は、他のテキストエディタと同様、コードを書くためのインターフェースを提供することだ。しかし、Cursorを特別なものにしているのは、組み込みのディープAI統合だ。
基本的なオートコンプリートの代わりに、CursorはLLmsを使ってコードベース全体とコンテキストを理解する。これにより、以下のようなスマートな機能を提供できる:
- 会話型プロンプト:必要な内容をわかりやすく説明すると、Cursorがあなたに代わってコードを記述または編集します。
- 複数行オートコンプリート:1行だけでなく、コードのブロック全体を提案して完成させます。
- AIによるリファクタリング:プロジェクト全体のコンテキストに基づいて、コードをインテリジェントに最適化、クリーンアップ、修正します。
- デバッグ支援:AIにコードのバグを見つけて説明するよう依頼します。
Cursorは、標準的なコードエディタをプロアクティブで高度にインテリジェントなペアプログラマに変えます。様々なプロバイダーの複数のLLMをサポートし、MCPによるツールのビルトインサポートも含まれています。
CursorにBright DataのWeb MCPを追加する理由
舞台裏では、Cursorは既知のLLMモデルに依存しています。その統合は、ほとんどのツールよりも深く洗練されているが、それでも他のLLMと同じ核となる限界に直面している:AIの知識は静的である!
結局のところ、AIのトレーニングデータは時間のスナップショットを反映している。特にソフトウェア開発のような日進月歩の分野では、それはすぐに古くなってしまう。では、CursorのAIエージェントに次のような機能を持たせることを想像してみてほしい:
- RAGワークフローの最新のチュートリアルとドキュメントを取り込む、
- コードを書きながらライブガイドを参照する。
- ローカルファイルをナビゲートするのと同じくらい簡単にリアルタイムのウェブサイトを閲覧する。
CursorをBright DataのWeb MCPに接続することで、このようなことが可能になります!
Web MCPは、リアルタイムのWebインタラクションとデータ収集のために構築された60以上のAI対応ツールへのアクセスを提供します。これらはすべて、Bright Dataの豊富なAIインフラストラクチャによって提供されています。
無料版でも、Cursorエージェントはすでに2つの強力なツールにアクセスできます:
| ツール | ツール |
|---|---|
検索エンジン |
Google、Bing、Yandexの検索結果をJSONまたはMarkdownで取得します。 |
scrape_as_markdown |
ボット検知やCAPTCHAをバイパスして、あらゆるウェブページをクリーンなMarkdownフォーマットにスクレイピングする。 |
これら以外にも、Web MCPにはクラウドブラウザの自動化や、Amazon、YouTube、LinkedIn、TikTok、Google Mapsなどのプラットフォームからの構造化データ取得のためのツールが含まれています。
以下は、Bright DataのWeb MCPでCursorを拡張した場合に可能になることのほんの一例です:
- 最新のAPIリファレンスやフレームワークのチュートリアルを取得し、作業コードやプロジェクトの足場を自動生成します。
- 最新の検索エンジン結果を即座に取得し、ドキュメントやコードコメントに埋め込む。
- ライブのウェブデータを収集し、リアルなテストモック、分析ダッシュボード、自動コンテンツパイプラインを作成できます。
全機能については、Bright Data MCPのドキュメントをご覧ください。
WebMCPをCursorに統合してAIコーディング体験を強化する方法
このステップバイステップでは、Bright Data Web MCPのローカルサーバーインスタンスをCursorに接続する方法を説明します。このセットアップにより、IDEで60以上のツールを直接利用できるようになり、AIエクスペリエンスが強化されます。
詳細には、Web MCPツールを使用して、Amazonから実世界のデータを返すモックAPIを持つExpressバックエンドを作成します。これは、この統合によってサポートされる多くの使用例のほんの一例です。
以下の手順に従ってください!
前提条件
このチュートリアルについて行くには、以下のものが必要です:
- Cursorアカウント(Freeプランで十分です)。
- 有効なAPIキーを持つBright Dataアカウント。
今すぐBright Dataを設定する必要はありません。このチュートリアルを読みながら、そのプロセスを説明していきます!
MCPの機能、Cursorの仕組み、Web MCPが提供するツールの基本的な理解も役に立ちます。
ステップ#1: Cursorを使い始める
お使いのオペレーティング・システムに対応したバージョンのCursorをインストールして開き、アカウントでログインします。
アプリケーションを初めて起動する場合は、セットアップウィザードを完了します。
するとこのような画面が表示されます:
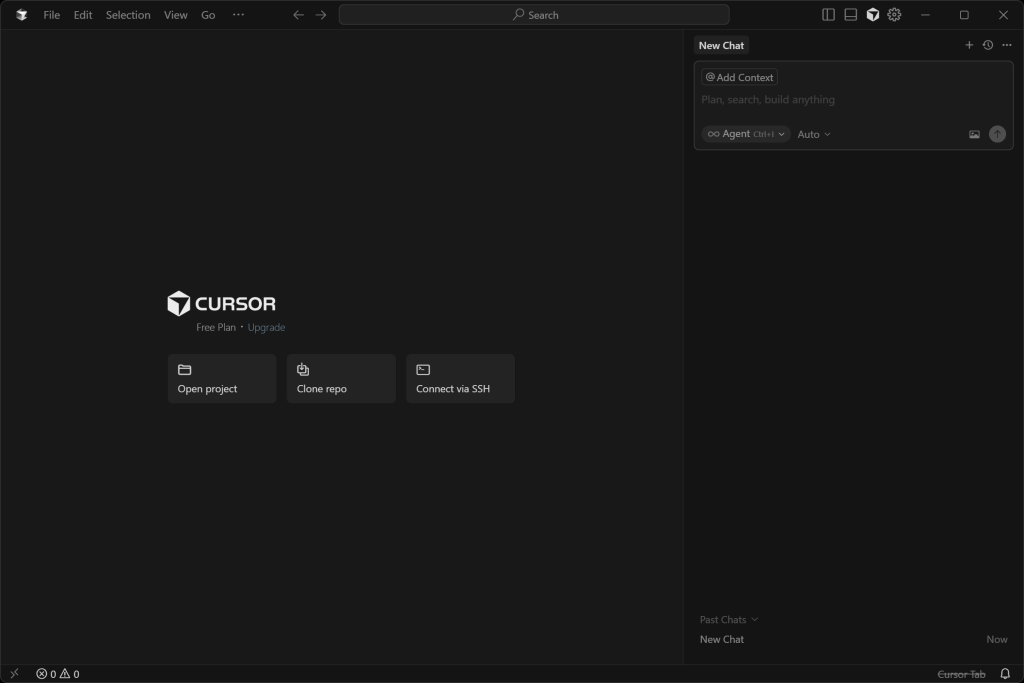
素晴らしい!プロジェクトフォルダを開き、Web MCPで拡張された組み込みAIコーディングエージェントを使用する準備をします。
ステップ2:LLMの設定
この記事を書いている時点では、Cursorはデフォルトでクロード4.5モデルを使用しています(“Auto “モードを通して)。それでよければ、次のセクションに進んでください。ClaudeはWeb MCPとも統合できることを覚えておいてください。
デフォルトモデルを変更したい場合は、”cursor settings “を検索し、同等のオプションを選択してください:
開いたタブで、”Models “タブに進んでください:

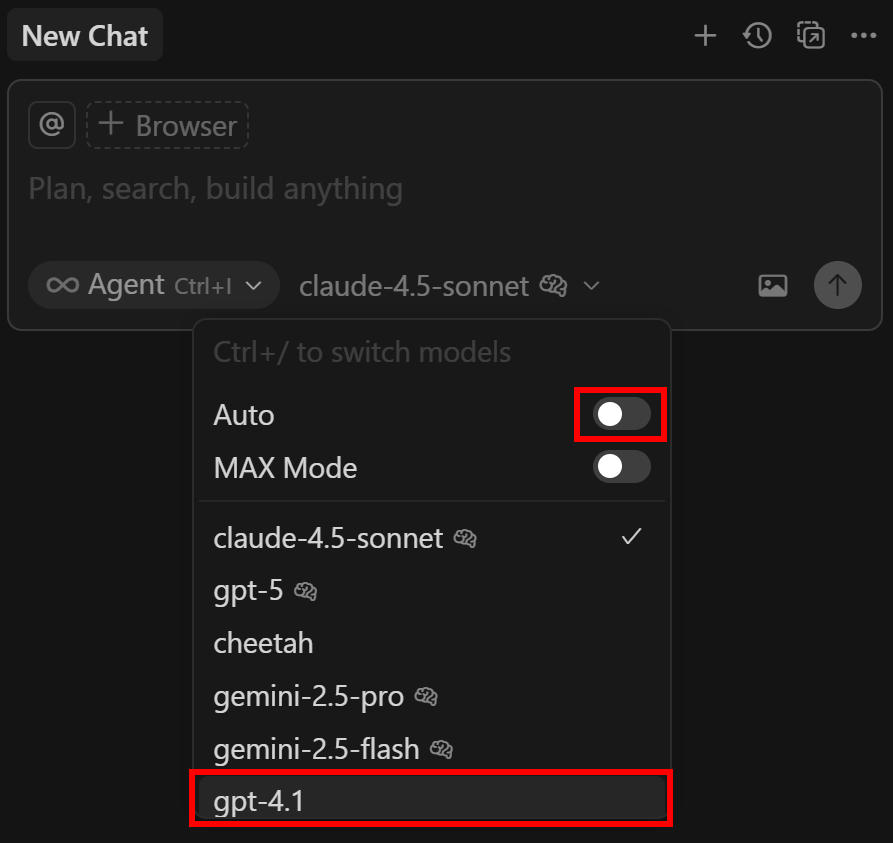
ここで、どのLLM CursorのAIエージェントを利用するかを設定できます。無料ユーザーは、プレミアムモデルとしてGPT-4.1と “Auto “しか選択できないことに留意してください。
GTP 4.1に変更するには、”gpt “を検索し、”gpt-4.1 “モデルを見つけ、有効にします:

ProまたはBusinessのサブスクリプションをお持ちの場合、サポートされているその他のLLMを有効にすることができます。さらに、選択したプロバイダーのAPIキーを提供することもできます。
次に、右側の “新規チャット “パネルを開きます。自動” ドロップダウンをクリックし、無効にし、”gpt-4.1″ オプションを選択します:
これで完了です!これで Cursor は設定した LLM を通して動作します。
ステップ #3: Bright Data の Web MCP をマシンでテストする
Cursor を Bright Data Web MCP に接続する前に、実際にローカルでサーバーを実行できるかどうかを確認してください。これは MCP サーバーがSTDIO 経由で設定されるために必要です。
まずBright Data にサインアップしてください。アカウントをお持ちの場合は、ログインしてください。簡単なセットアップには、ダッシュボードの “MCP“セクションの指示に従ってください:
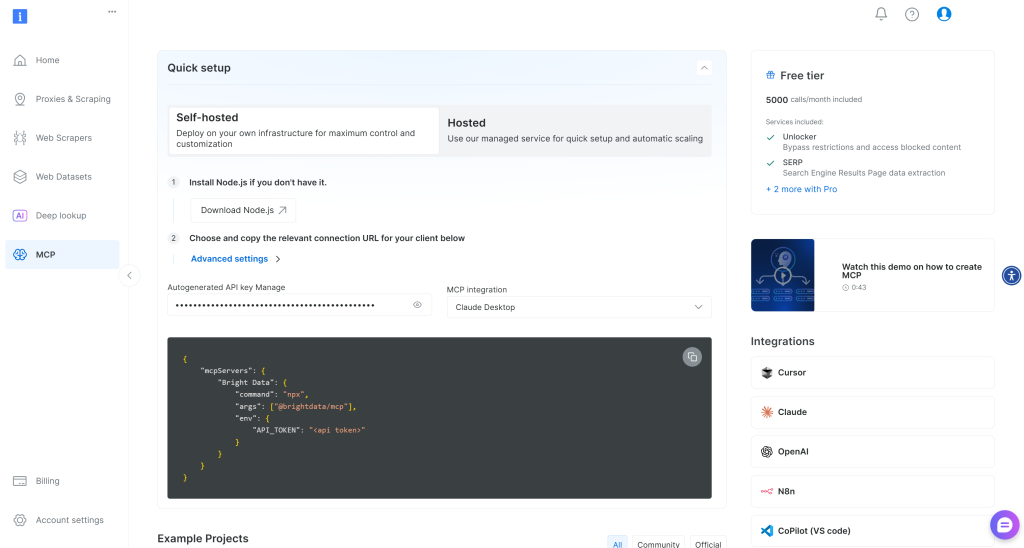
詳細については、以下の説明を参照してください。
まず、Bright Data APIキーを生成し、安全な場所に保管してください。次のステップで必要になります。ここでは、API キーが管理者権限を持っていると仮定します。
次に、以下のnpmコマンドでWeb MCPをあなたのマシンにグローバルにインストールします:
npm install -g @brightdata/mcpMCPサーバーを起動して動作することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpまたは、PowerShellでも同様です:
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API> のプレースホルダを Bright Data API トークンに置き換えてください。これらのコマンドは、必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを通してWeb MCPをローカルに起動します。
成功すると、このような出力が表示されます:

最初の起動で、Web MCPはBright Dataアカウントに2つのデフォルトゾーンを作成します:
mcp_unlocker:mcp_unlocker:Web Unlocker用のゾーンです。mcp_browser:mcp_unlocker:Browser API用のゾーン。
Web MCPはこれら2つのBright Dataサービスに依存して60以上のツールを動かします。
ゾーンが設定されていることを確認したい場合は、Bright Dataアカウントの “プロキシ&スクレイピングインフラ“ページにアクセスしてください。表の中に2つのゾーンがあるはずです:
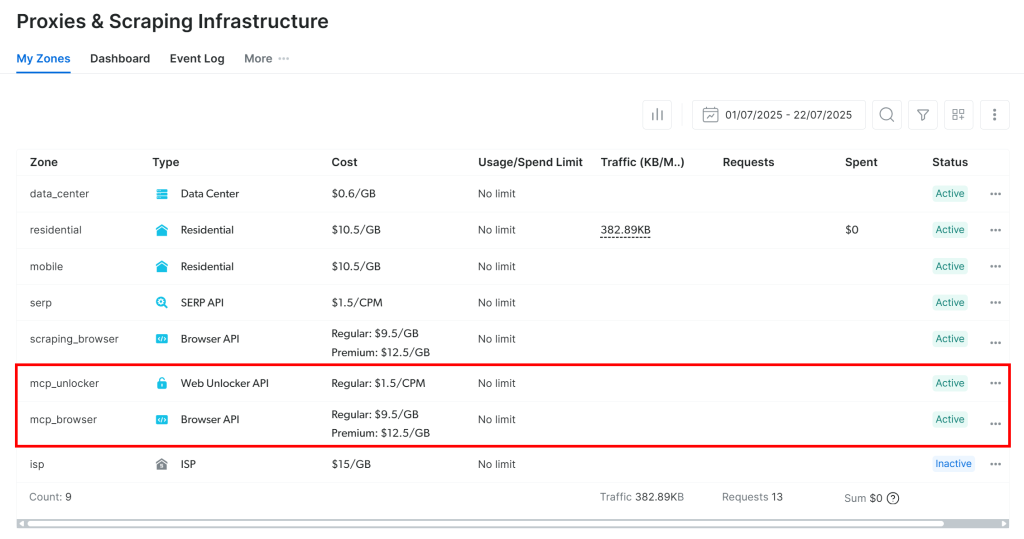
注意: API トークンにAdmin権限がない場合、2つのゾーンは自動的に作成されません。その場合は手動で定義し、GitHub の説明に従って環境変数で設定してください。
無料版では、Web MCPはsearch_engineと scrape_as_markdownツール(とそのバッチ版)のみを公開することを覚えておいてください。他のすべてのツールのロックを解除するには、環境変数PRO_MODE="true "を設定することで、**Proモードを有効にしてください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpプロ・モードは60以上のツールをアンロックしますが、フリー・ティアには含まれていませんので、追加料金が発生します。
素晴らしい!これでWeb MCPサーバーがローカルで動作することが確認できました。これからCursorがMCPを起動し、MCPに接続するように設定するので、MCPプロセスを終了してください。
ステップ#4: CursorでWeb MCPを設定する
mcp “を検索し、”View:MCP設定を開く “オプションを選択します:
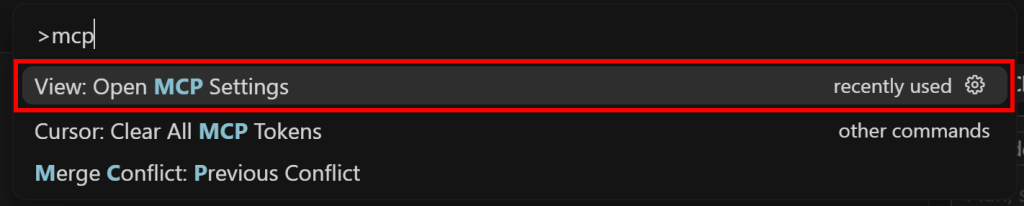
Tools & MCP “セクションで、”Add Custom MCP “ボタンをクリックします:

これで、以下のmcp.json設定ファイルが開きます:

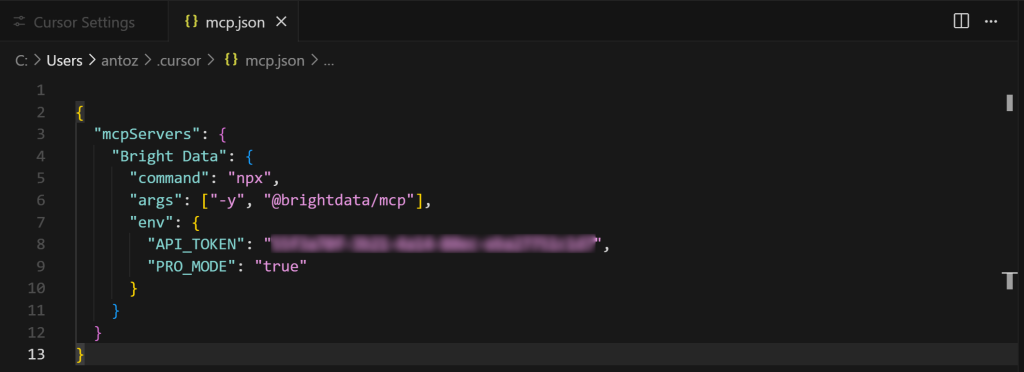
ご覧の通り、デフォルトでは空です。Bright DataのWeb MCPインテグレーションでは、以下のように入力してください:
{
"mcpServers":{
"Bright Data":{
"command":"npx"、
"args": ["-y", "@brightdata/mcp"]、
"env":{
"API_TOKEN":"<your_bright_data_api_key>"、
"PRO_MODE":"true"
}
}
}
}次に、Ctrl + S(macOSではCmd + S)を使ってファイルを保存する:
上記の設定は、以前にテストしたnpxコマンドを複製したもので、環境変数を使って認証情報と設定を渡している:
API_TOKENが必要です。API_TOKENは必須です。先ほど生成したBright Data APIキーを設定してください。PRO_MODEはオプションです。Proモードを有効にしない場合は削除してください。
つまり、Cursor はmcp.jsonの設定を使用して、先ほど見たnpxコマンドを実行します。ローカルでWeb MCPプロセスを実行し、それに接続して、公開されているツールにアクセスします。
Cursor + Bright Data Web MCP の統合が完了したら、mcp.jsonタブを閉じます!
注意: STDIO を使用せず、SSE またはストリーマブル HTTP を使用したい場合は、Bright Data の Web MCP はリモートサーバーオプションも提供しています。
ステップ#5: MCPインテグレーションからツールの可用性を確認する
Cursor が Web MCP サーバーに正常に接続され、すべてのツールにアクセスできるかどうかを確認します。
これを行うには、”Cursor Settings “タブの “Tools & MCP “セクションに戻ります。設定された “Bright Data “オプションが表示され、利用可能なすべてのツールがリストアップされているはずです:
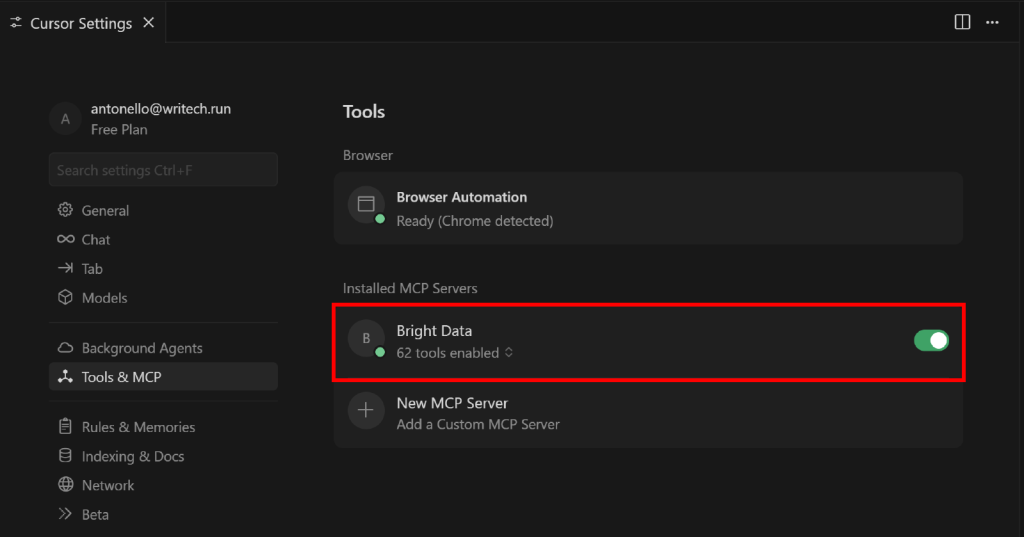
N tools enabled” ドロップダウン(N は有効なツールの数)を展開し、利用可能なすべてのツールを確認します:
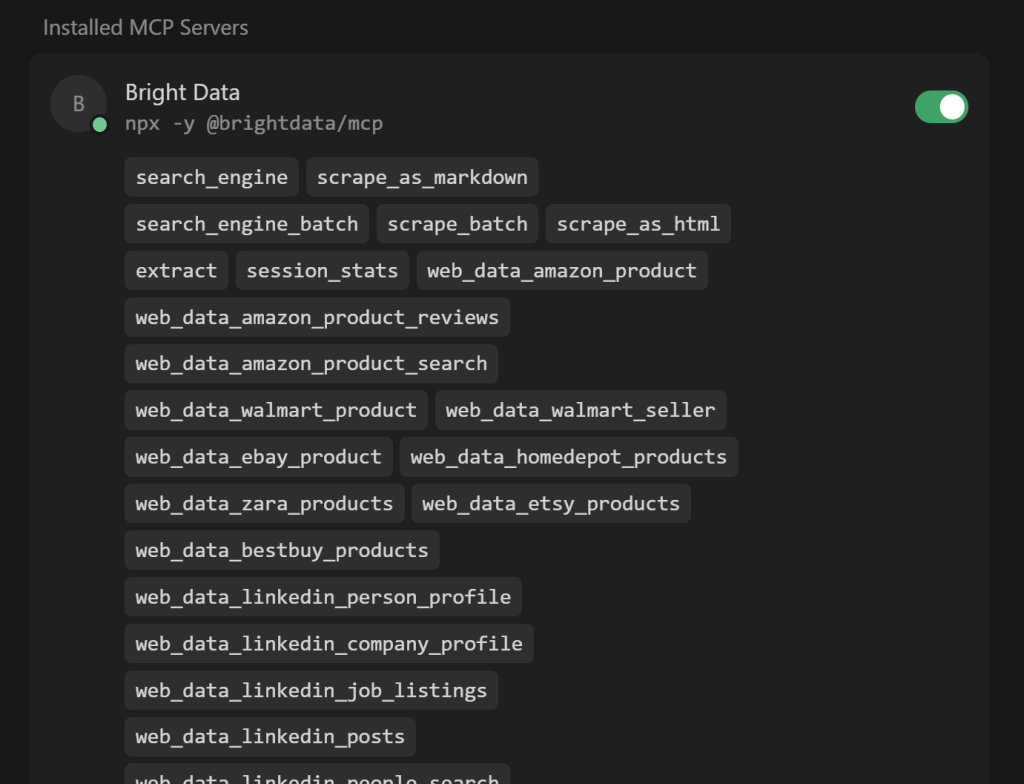
Cursor は自動的にサーバーに接続し、60 以上のツールを取得します。
プロモードが無効の場合、利用可能な4/5の無料ツールしか表示されません。ここで、お好みに応じてツールをアクティブにしたり、非アクティブにしたりすることもできます。デフォルトでは、すべて有効になっています。
確認したら、「カーソル設定」タブを閉じます。AIを活用したコーディング体験のために、これらのツールを活用する準備をしよう!
ステップ #6: 強化されたAIコーディングエージェントでタスクを実行する
Cursor コーディングエージェントの機能をテストするには、新しく設定したウェブデータ検索機能を実行するプロンプトが必要です。
例えば、電子商取引アプリケーションのバックエンドをExpress.jsで構築しているとします。実際のAmazonの商品データを返すAPIをモックしたいとします。
次のようなプロンプトでそれを実現する:
以下のAmazon商品からデータをスクレイピングしてください:
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
次に、スクレイピングしたデータをローカルのJSONファイルに保存する。次に、ASIN(Amazonの商品を表す)を受け取り、JSONファイルから読み取った対応するデータを返すエンドポイントを持つシンプルなExpress.jsプロジェクトを作成します。Proモードで操作しているとします。上記のプロンプトをCursorで実行します。
これが次に起こるステップです:
- Cursorで設定されたLLMは、Amazon商品データを取得するためのツールとして
web_data_amazon_productを特定します。 - プロンプトの3つのAmazon商品それぞれについて、データを取得するために
web_data_amazon_productを実行する許可を求められます。 - 各ツールに許可を与え、非同期データ収集タスク(Bright Data Amazonスクレイパーを呼び出します)をトリガーします。
- 各商品の取得されたデータはJSON形式で表示されます。
- GPT-4.1は取得したデータを処理し、
products.jsonファイルに入力します。 - Cursorはnpmプロジェクト構造を作成し、
package.jsonを定義し、Expressサーバーロジックを含むindex.jsファイルを作成します。 npm installを介してプロジェクトの依存関係をインストールする許可を求められます。これにより、package.jsonファイルがnode_modules/フォルダに作成されます。npm startでサーバーを実行する許可を求められます。
注意: プロンプトで明示的に指定されていなくても、GPT-4.1ではプロジェクトの依存関係のインストールとサーバーのセットアップを求めることにしました。これはいい追加機能だ!
この例では、最終的に以下のようなプロジェクト構造が出力されます:
your-project/
├── node_modules/
├── index.js
├── package.json
├── package-lock.json
└── products.json完璧だ!意図したゴールに到達したかどうか、結果を検証してみよう。
ステップ #7: 出力されたプロジェクトを調べる
AIコーディングエージェントがファイルを生成すると、Cursorの左カラムに表示されます。
免責事項:AIの実行によって結果が異なることがあるため、あなたのファイルは以下に示すものと異なる可能性があります。
まず、products.jsonファイルを確認してください:
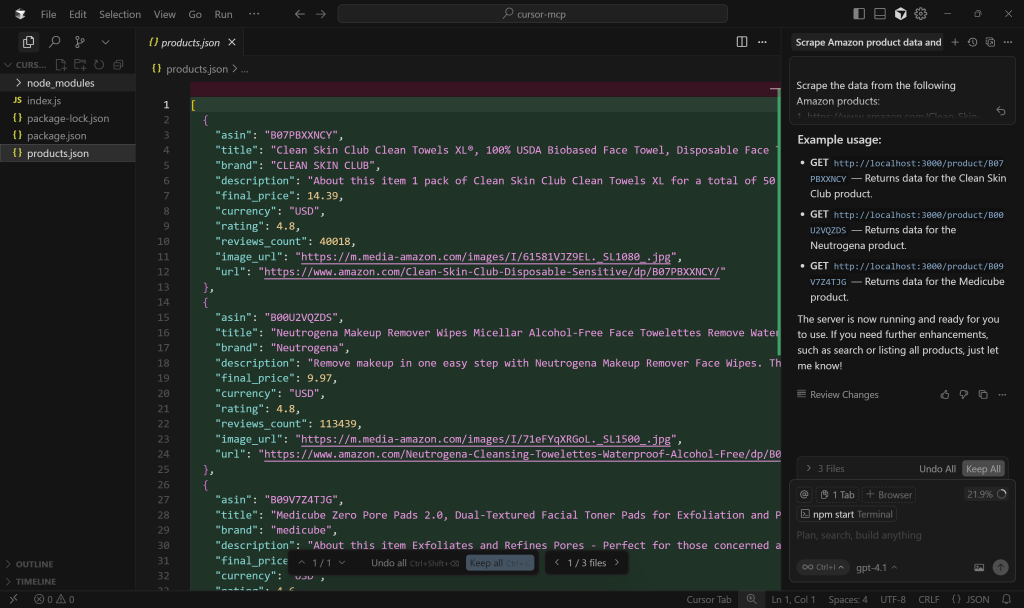
ご覧の通り、このファイルには、web_data_amazon_productツールによって返されたスクレイピングデータの簡易版が含まれています:
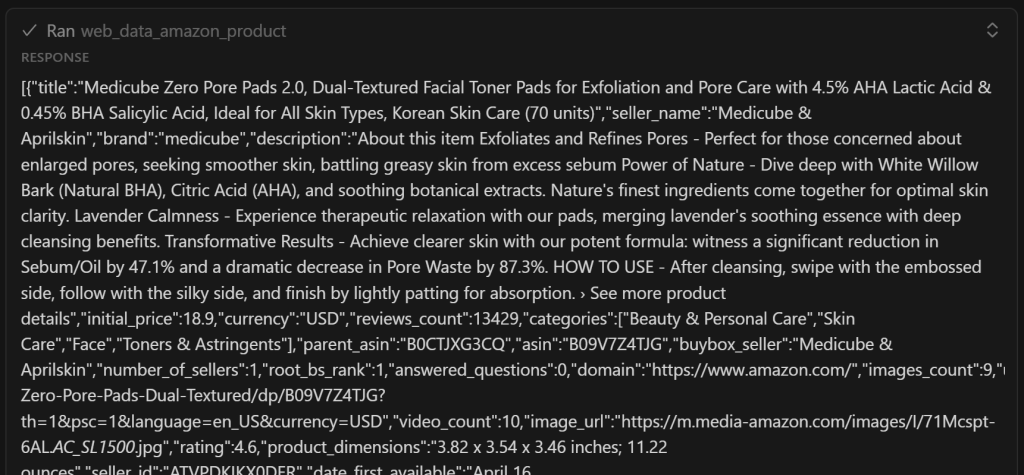
重要:web_data_amazon_productは、実際にはいくつかのフィールドだけでなく、アマゾンのページからすべての商品データを返します。それでも、AIは最も関連性の高いフィールドだけを含めることにしました。最適化を促せば、AIにすべてのフィールドを含めるように指示することができます。
次に、index.jsを開いてExpress.jsのサーバー・ロジックを確認する:
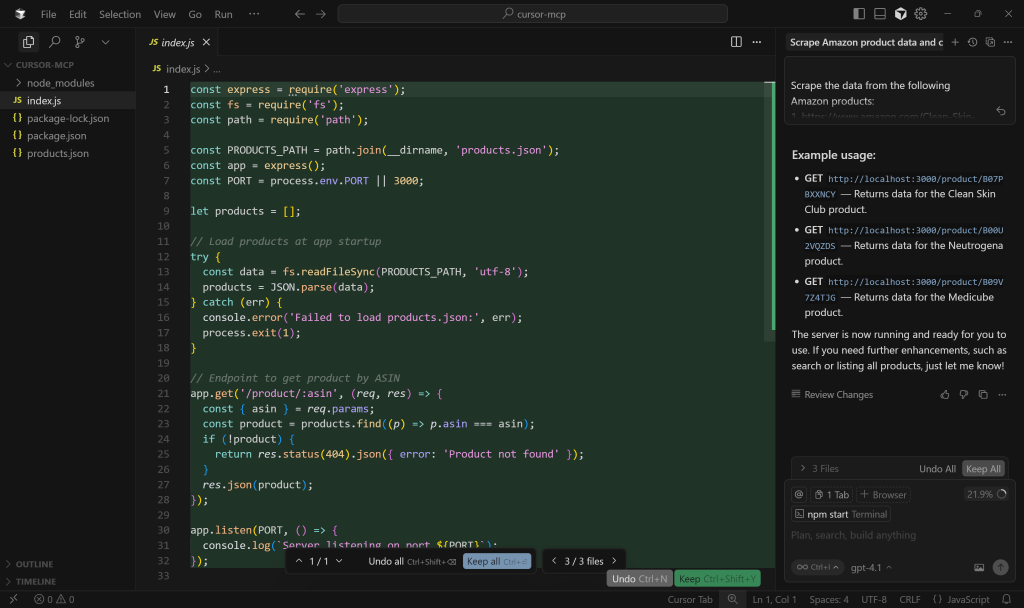
具体的には、商品データ検索用のモックエンドポイントは、/product/:asinというパスを使用しています。
続けて他のファイルも調べますが、どれも問題ないはずです。それでは、”Keep All “ボタンを押してAIが生成した出力を確認し、プロジェクトをテストする準備をしてください!
ステップ#8: プロジェクトをテストする
GPT-4.1がnpm startの実行許可を求めたので、Express.jsアプリケーションはすでに実行されているはずです。実行されていない場合は、手動で起動することができます:
npm startこれでExpress.jsバックエンドがhttp://localhost。
次に、以下のcURLコマンドを実行して、GET/product/:asinエンドポイントをテストします:
curl "http://localhost/ product/B07PBXXNCYここで、B07PBXXNCYはプロンプトに記載されているアマゾン製品のASINです。
このようなものが表示されるはずです:

素晴らしい!このデータは、生成されたproducts.jsonファイルに正しくフェッチされました。この結果は、オリジナルのAmazonページのデータ(の簡略版)に対応しています。
Amazonから商品データをスクレイピングしようとしたことがある人なら、悪名高いAmazon CAPTCHAやその他のボット対策のために、それがどれほど難しいか知っているでしょう。確かに、バニラGPT-4.1だけでは、Amazonからその場でデータを取得することはできません。
これはWeb MCPとCursorの組み合わせの威力を示している。さて、これは非常に単純な例に過ぎない。しかし、利用可能な60以上のツールと適切なプロンプトがあれば、IDE内でより高度なシナリオを直接扱うことができます!
出来上がり!Cursor + Bright Data Web MCPの統合により、モックされたAPIエンドポイントを持つExpressバックエンドの作成に成功しました。
[おまけ] Visual Studio Codeでの代替アプローチ
Visual Studio Code で Cursor のようなエクスペリエンスを実現するには、ClineやRoo Code などの拡張機能を使用します。
特に、Web MCPをVS Codeに統合するには、以下のガイドを参照してください:
まとめ
このブログポストでは、CursorのMCP統合を最大限に活用する方法を学びました。IDEに組み込まれたAIコーディングエージェントはすでに便利ですが、Bright DataのWeb MCPに接続すると、はるかに有能でリソースが豊富になります。
この統合により、Cursorはライブウェブ検索の実行、構造化データの抽出、ダイナミックデータフィードの利用、さらにはブラウザとのインタラクションの自動化が可能になります。これらはすべて、コーディング環境から直接実行できます。
さらに高度なAIを活用したワークフローを構築するには、Bright DataのAIエコシステムで利用可能なサービスとデータソリューションの完全なスイートをご覧ください。
今すぐ無料のBright Dataアカウントを作成し、AI対応のウェブデータツールの実験を開始してください!





