
本ガイドでは、LLM言及追跡のためのユニバーサルLLMスクレイパーの使用法とアーキテクチャについて解説します。本プロジェクトでは以下のスクレイパーを単一の統合インターフェースに統合します:
このガイドを読み終える頃には、以下の操作が可能になります。
- Bright DataウェブスクレイピングAPIを使用してスクレイパーをトリガーする。
- スクレイパーの準備状態を確認し、結果をダウンロードする。
- Bright Dataの出力フォーマットを使用して、手間のかからない正規化を行う。
- 研究や検証のために複数のLLM間でプロンプトを同時に比較する。
すぐにプロジェクトを始めたいですか?GitHubでチェックしてみてください。
なぜユニバーサルLLMスクレイパーを構築するのか?
調査行動は変化しました。ユーザーはAIチャットボットに質問し、生成された回答を信頼するようになりました。検索を継続することはほとんどありません。これはSEOと市場調査業務を劇的に変えます:チャットボットの出力に自社ブランドが言及されなければ、潜在顧客は決して自社を発見しない可能性があります。
企業は検索結果だけでなく、モデル出力にも登場する必要が生じました。Bright Dataの事前構築済みLLMスクレイパーは、市場で最も人気のあるモデルからの正規化された出力を提供します。これらのAPIを単一インターフェースに統合することで、チームは主要なLLMすべてにわたる推奨結果を比較できます。
プロンプト例:レジデンシャルプロキシの最適なプロバイダーは?
各LLMを手動でクエリし結果を確認するには1時間以上かかる場合があります。統合結果では、プロンプトを複数のLLMに同時に転送し、正規表現を用いて自社名が出力に含まれるかを即座に判定できます。
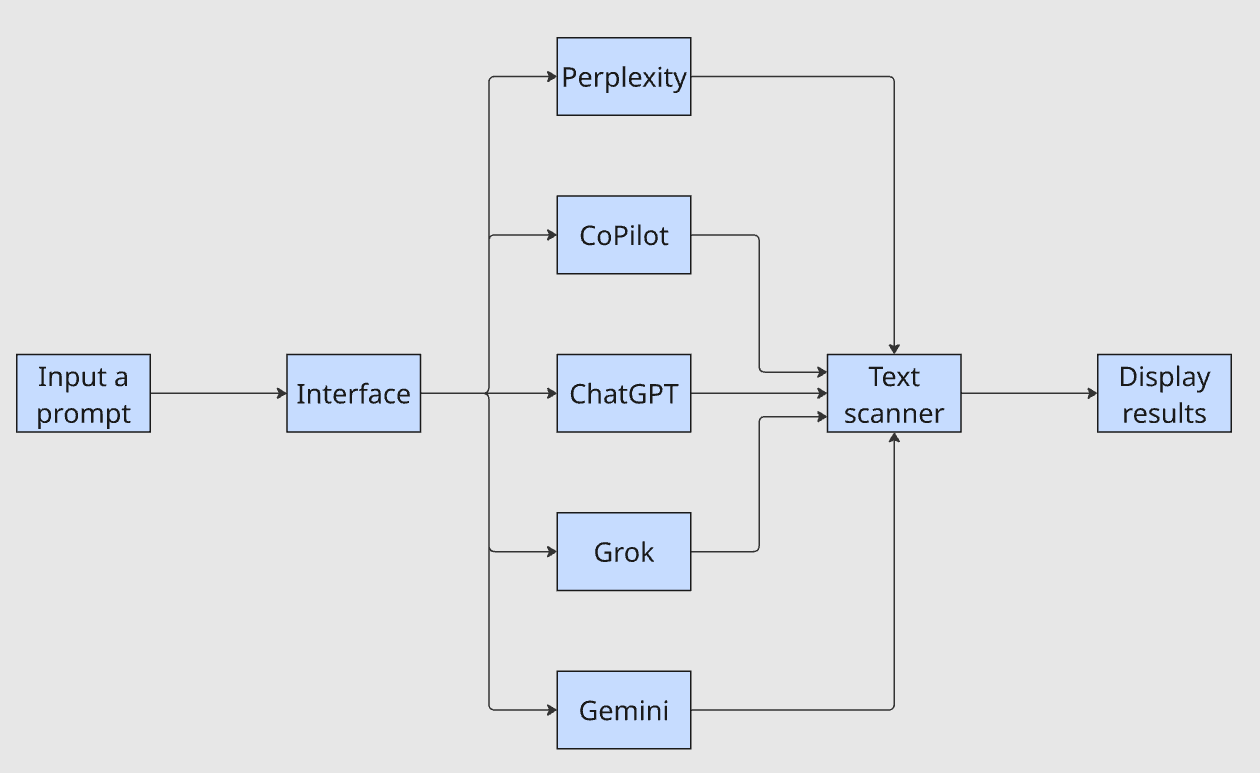
このインターフェースは単一のプロンプトを受け取り、各LLMに転送し、テキストスキャナーで出力をパイプ処理して結果を表示します。「自社は結果に含まれているか?」という質問への回答が、1時間から数分で得られるようになります。
実際のソフトウェア構築
次に、実際のソフトウェアを構築します。基本的なプロジェクトの骨格を作成し、進めながらコードを埋めていきます。このセクションには完全なコードベースは含まれません。これは概念的な分解であり、行単位の解説ではありません。
開始手順
まず、新しいプロジェクトフォルダを作成します。
mkdir universal-llm-scraper
cd universal-llm-scraper次に、依存関係の競合を防ぐために仮想環境を作成します。
python -m venv .venv次に、仮想環境をアクティブ化する必要があります。LinuxまたはmacOSの場合は最初のコマンドでアクティブ化できます。Windowsの場合は2番目のコマンドを使用してください。
Linux/macOS
source .venv/bin/activateWindows
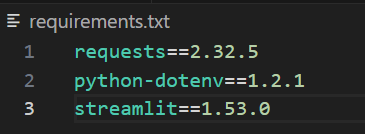
..venvScriptsActivate.ps1最後に、requirements.txtというファイルを作成し、下記の依存関係を追加します。バージョン番号は調整可能です。ただし、ビルド時に問題なく動作したため、再現性を確保するために固定しています。
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0完了すると、ファイルは下の画像のようになります。
これらの依存関係をインストールするには、以下の pip コマンドを実行してください。
pip install -r requirements.txtオブジェクトとしてのAIモデル
次に、すべてのAIモデルがオブジェクトとして機能することを理解する必要があります。各モデルには以下の属性があります。
name: モデルの人間が読めるラベル。dataset_id: スクレイパーの固有識別子。url: AIモデルにアクセスするために使用する実際のURL。
以下のクラスでは、この同じモデルオブジェクトを作成します。このクラスにはメソッドやロジックは不要です。コンピュータサイエンスに精通している方なら、これは昔ながらの構造体(struct)に似ています。
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url モデル取得クラスの記述
次に、モデル取得クラスを記述します。このクラスはより多くの処理を担います。モデル取得クラスは、Bright Dataとその他のコード間の統合的なオーケストレーション層を提供します。API認証にはBright Data APIキーを使用します。 また、get_model_response()、trigger_prompt_collection()、collect_snapshot()、write_model_output()といった様々なメソッドも用意されています。後続の工程でこれらのメソッドを実装していきます。
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
このメソッドは主にオーケストレーションに使用されます。trigger_prompt_collection()を使用してスクレイパーを起動し、そのsnapshot_idを返します。次に、collect_snapshot()を使用してAPIをポーリングし、準備が整った時点で応答を返します。最後に、write_model_output()を使用して応答をファイルに書き込みます。
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: スナップショットのトリガーに失敗しました。 しばらく待ってから再試行してください。")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"{model.name} のスナップショット {snapshot_id} の収集に失敗しました。しばらく待ってから再試行してください。")
self.write_model_output(model, llm_response)trigger_prompt_collection()
コレクションをトリガーするには、APIトークンをHTTPヘッダーに渡します。その後、APIへのPOSTリクエストを試行します。HTTPエラーは予測不能な場合があるため、最大3回の再試行を許可します。応答が正常であればsnapshot_idを返します。エラーが発生した場合、再試行回数が尽きるまで継続します。再試行回数を超過した場合、関数を終了します。
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
response = None
try:
response = requests.post(
f"https://api.brightdata.com/datasets/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
response.raise_for_status()
payload = response.json()
snapshot_id = payload["snapshot_id"]
return snapshot_id
except (ValueError, KeyError, TypeError, requests.RequestException) as e:
print(f"{model.name} スナップショットのトリガーに失敗しました: {e}")
tries -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
スナップショットIDを取得したら、毎分その準備状態を確認します。APIは収集が進行中の場合ステータスコード202を返します。スナップショットの準備が整うと200を返します。その他のステータスコードを受信した場合はエラーを発生させ、再試行ロジックに入ります。再試行回数を超過した場合、メソッドを終了します。
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"{model.name} スナップショット {snapshot_id} を待機中")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: ポーリングエラー ({e})")
continue
if response.status_code == 200:
print(f"{model.name} スナップショット {snapshot_id} が準備完了!")
ready = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("サーバー通信エラー")
print(f"最大エラー数超過のため、スナップショット {snapshot_id} を取得できませんでした")
returnwrite_model_output()
これは非常にシンプルです。モデルの出力結果を保存するために使用します。os.makedirs(OUTPUT_FOLDER, exist_ok=True)は出力フォルダが存在することを確認するために使用します。その後、ファイルを出力フォルダに書き込み、model.nameを使用してファイル名を付けます。
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"{model.name}からのレポート生成完了 → {path}") メインファイルの作成
次に、メインファイルを作成します。これを使用すると、UIをロードせずにバックエンドプロセスを実行できます。run_one()は単一モデルでプロセスを実行します。main()内部では、ThreadPoolExecutor()を使用してこの関数を複数のスレッドで同時に実行します。1コレクションずつ処理する代わりに、スレッドごとに1コレクションを処理することで結果を大幅に高速化できます。
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "空はなぜ青いのですか?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
failures = 0
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, len(models))) as pool:
futures = {pool.submit(run_one, m, retriever, prompt): m for m in models}
for fut in as_completed(futures):
model = futures[fut]
try:
name = fut.result()
print(f"{name}: done")
except Exception as e:
failures += 1
print(f"{model.name}: failed ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()以下のコマンドでメインファイルを実行できます。
python main.pyStreamlit UI
Streamlit UIの概念はメインファイルと非常に似ています。各コレクションの実行には依然として複数のスレッドを使用します。write_output() とsanitize_filename()関数は、ファイル名をよりクリーンにするためだけに使用されます。ターミナルに出力する代わりに、Streamlitを使用して変数を作成し、ローカルブラウザ内でアプリを起動・表示します。
UIの記述
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="ユニバーサル LLM スクレイパー", layout="wide")
st.title("ユニバーサル LLM スクレイパー")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("BRIGHTDATA_API_TOKEN が不足しています。プロジェクトルートに .env ファイルを追加してください。")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("実行設定")
prompt = st.text_area("プロンプト", value="レジデンシャルプロキシの最適なプロバイダーは?", height=120)
target_phrase = st.text_input("追跡対象フレーズ", value="Bright Data")
selected = st.multiselect("モデル", options=model_names, default=model_names)
country = st.text_input("国 (任意)", value="")
save_to_disk = st.checkbox("結果を出力先に保存", value=True)
redact_terms = st.text_area("非表示にするブランド用語 (1行に1つ)", value="")
redact_mode = st.selectbox("非表示モード", ["マスク", "削除"], index=0)
run_clicked = st.button("スクレイピングを実行", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # model_name -> エラー文字列
if "paths" not in st.session_state:
st.session_state.paths = {} # model_name -> 保存パス
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# 代替処理: answer_textが見つからない場合、シリアル化されたペイロードを検索
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# レイアウト: ステータス + 結果
status_col, results_col = st.columns([1, 2], gap="large")
with status_col:
st.subheader("Status")
if run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
if not selected:
st.warning("Select at least one model.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: done")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("実行完了。")
# 保存済みファイルを表示(存在する場合)
if st.session_state.paths:
st.caption("保存済みファイル")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("エラー")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("結果")
if not st.session_state.results:
st.info("結果を収集するには 'Run scrapes' をクリックしてください。")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**言及されたターゲットフレーズ:** {'✅' if mentioned else '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### Answer")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### Raw JSON")
st.json(payload)
if __name__ == "__main__":
main()はい、app.pyはメインファイルより長くなっています。ただしmain.pyとの主な違いはわずかです。
- 状態管理: Streamlit を使用し、結果・エラー・ファイルパスを
st.session_stateに保存します。これにより UI 内での取得・表示が可能になります。 - オーケストレーション: プロンプトやモデルコレクションをハードコーディングする代わりに、UI内から収集・トリガーします。
- テキスト検査: 回答テキストを検査し、ターゲットフレーズが含まれているか確認します。ターゲットフレーズが存在する場合、✅を表示します。存在しない場合は代わりに❌を表示します。
UIの使用
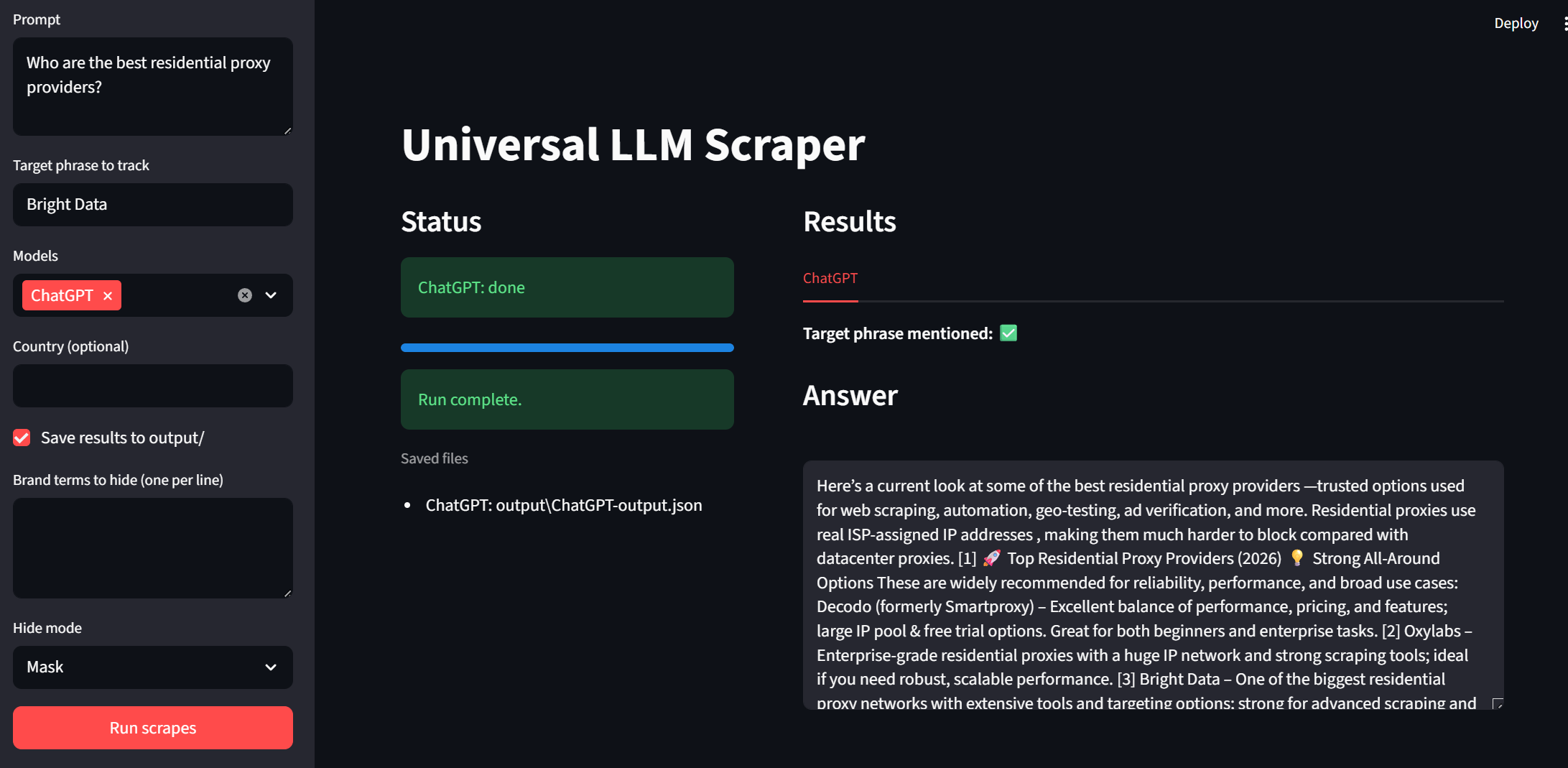
それでは、UIをテストしてみましょう。以下のスニペットでアプリを実行できます。
streamlit run app.pyサイドバーをご覧ください。プロンプトとターゲットフレーズを入力できます。モデルはドロップダウンから選択可能です。「国」と「出力保存」はユーザー側のオプション調整項目です。プログラムを実行するには、下部の「スクレイピング実行」ボタンをクリックするだけです。
結果
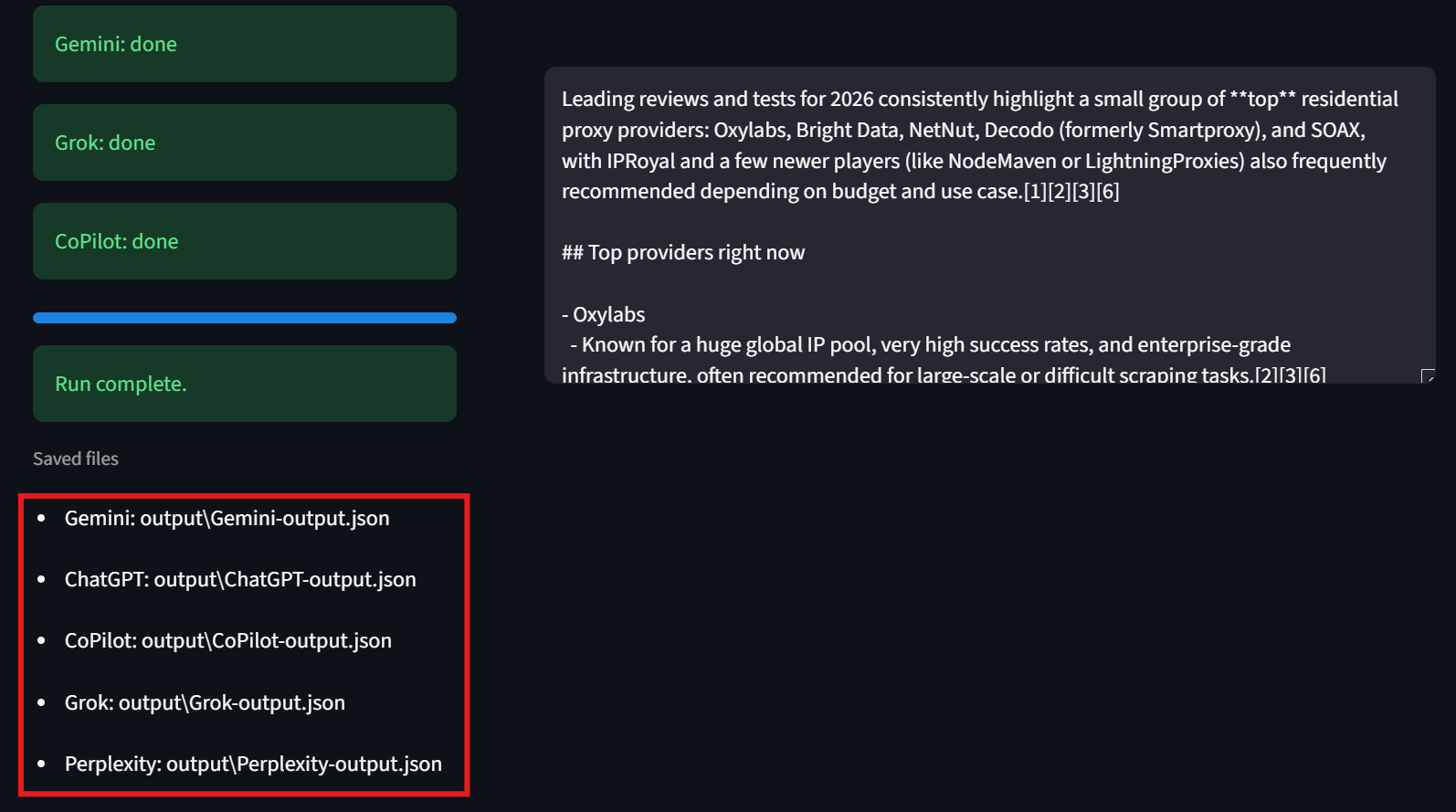
各モデルは結果内で個別のタブとして表示されます。これにより結果を素早く確認できます。下図ではBright Dataの各モデル出力に緑のチェックマークが付いています。例:
インターフェース左下隅にも注目してください。ここに各結果ファイルのパスが表示されます。これにより、生の結果を簡単に確認できます。
次のレベルへ
まず、Supabaseアカウントが必要です。supabase.comにアクセスし、指示に従ってください。Supabaseはニーズに応じた様々な料金プランを提供しています。このプロジェクトでは無料プランで十分です。ただし、データベースが拡大するにつれてアップグレードが必要になる可能性があります。
APIキーが必要です。アカウントとプロジェクトの設定が完了したら、サイドバーの「プロジェクト設定」をクリックします。「APIキー」タブに移動してAPIキーを取得してください。
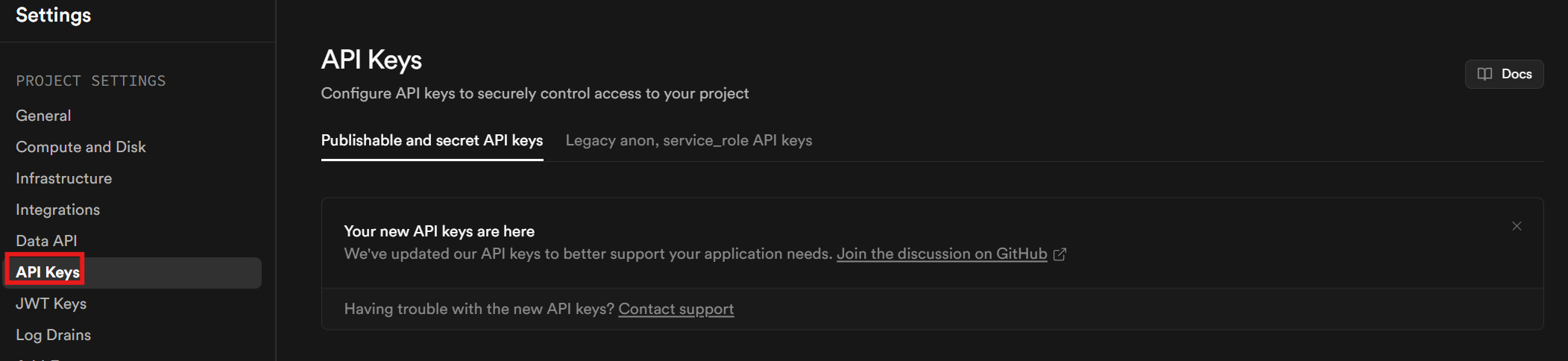
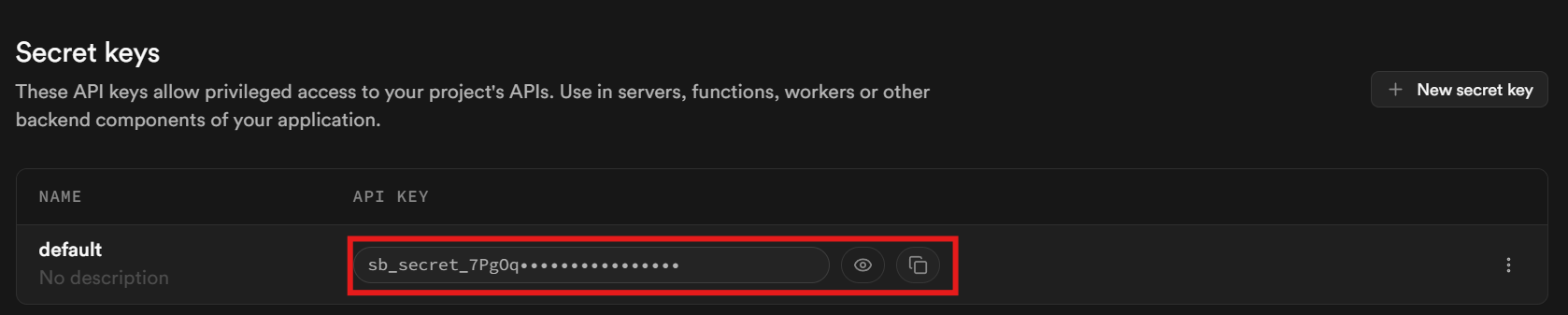
ページ最下部までスクロールしてください。キーは「シークレットキー」セクションに記載されています。
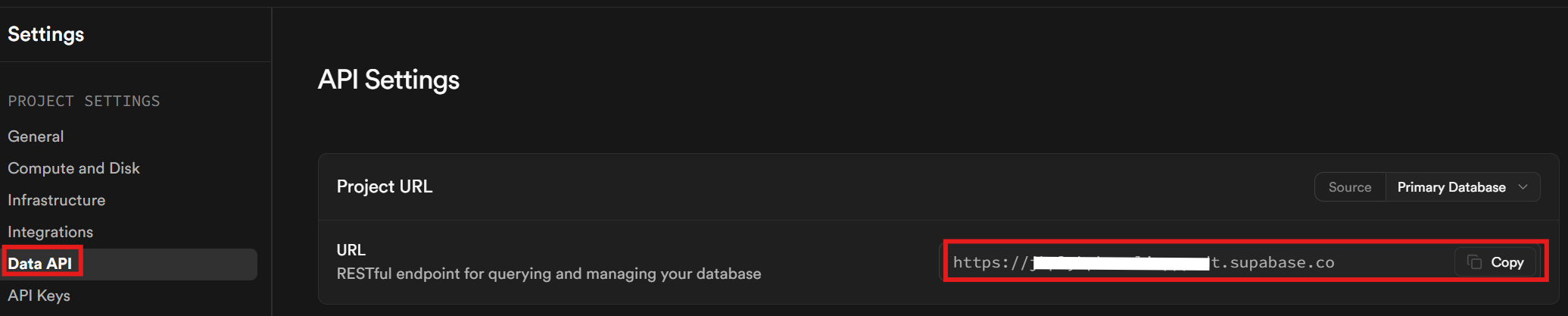
最後に、Data APIタブでSupabase URLを取得します。これがデータベース通信に使用するURLです。
キーを取得したら、環境ファイルと要件ファイルを更新する必要があります。新しい環境ファイルは次のようになります。
BRIGHTDATA_API_TOKEN=<YOUR-bright-data-API-key>
SUPABASE_URL=<YOUR-supabase-project-url>
SUPABASE_API_TOKEN=<YOUR-supabase-API-key>requirementsファイルは次のようになります。
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2テーブルの作成
次に、データベース内にテーブルを作成します。サイドバーからSQLエディターを開きます。
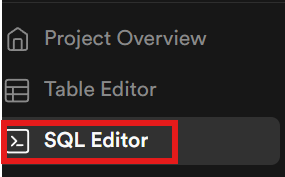
LLM実行
以下のSQLコードをスクリプトに貼り付けて実行します。これによりllm_runsというテーブルが作成されます。コレクションを実行するたびに、結果をここに格納します。
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
create index if not exists llm_runs_model_idx
on public.llm_runs (model_name);
create index if not exists llm_runs_target_idx
on public.llm_runs (target_phrase);プロンプト
プロンプトを保存する機能も必要です。以下のコードはプロンプトテーブルを作成します。
create table public.prompts (
id bigint generated by default as identity primary key,
created_at_ts bigint not null,
prompt text not null,
is_active boolean not null default true
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);スケジュール
最後に、スケジュールされたジョブを保持するテーブルが必要です。
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
create index if not exists schedules_due_idx
on public.schedules (is_enabled, next_run_ts);
create index if not exists schedules_lock_idx
on public.schedules (locked_until_ts);更新されたアーキテクチャ
最終的なコードベースは、チュートリアルに収まりきらないほど大規模になりました。ここではすべてのファイルを羅列する代わりに、データベース接続、ヘッドレスランナー、Streamlit UIの背後にある中核的なポイントについて解説します。
データベース操作
様々なデータベースヘルパーを用意していますが、すべては主にデータベース内の読み取りと作成を基盤としています。以下のコードでデータベース全体に接続できます。
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # .envファイルと整合性を保つ
if not url or not key:
raise RuntimeError("環境変数に SUPABASE_URL または SUPABASE_API_TOKEN が存在しません。")
return create_client(url, key)データベースとの実際のやり取りには、get_db() 上で追加のメソッドを呼び出します。次のスニペットでは、get_db() がデータベースを取得します。その後、db.table("llm_runs").insert(row).execute()を使用してllm_runsテーブルに新しい行を挿入します。プロンプトとスケジューリングヘルパーも同様の基本ロジックに従います。
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"挿入失敗: {res}")
return res.data[0]ヘッドレスランナー
Streamlit UIの作成後、プロジェクトの規模拡大に伴いmain. pyをheadless_runner.pyにリネームしました。メインプログラムは1つではなく、2つのスクリプトが同時に実行されるようになりました。
persist_run()はAPIからのペイロードが空かどうかを確認します。ペイロードが空の場合、Falseを返し、挿入失敗のメッセージをターミナルに出力します。ペイロードに情報がある場合、save_run()を使用して結果をデータベースに挿入します。
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# 空のリスト/辞書を「保存しない」扱いしたい場合は以下を保持:
if payload == {} or payload == []:
print(f"{model_name}: DB挿入をスキップ (空のペイロード)。type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: ペイロードがJSONシリアライズ不可です ({e})。文字列化します。")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: DB挿入失敗: {db_err}")
return mentioned先に進む前に、ヘッドレスランナーのもう一つの重要な部分を確認する必要があります。設定調整として使用できる様々なオプションの環境変数があります。実際のプログラムの実行はシンプルなwhileループ内に保持されています。この実行ループ内では、スケジュール内の新しいジョブを継続的にチェックします。スケジュールされたジョブの期限が来ると、run_schedule_once()を呼び出して実行を開始します。
# DB変更なしで調整可能
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # 起動間隔(秒)
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # ジョブ実行中のロック時間
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # 各ティックで期限切れジョブを全て実行
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# 1つのスケジュールを要求・実行するか、または期限切れの全スケジュールをドレインする
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"期限切れスケジュールの要求に失敗: {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# 実行途中で何かがクラッシュした場合、スケジュールは進めない。
# ロックは期限切れとなり、スケジュールは後で処理される。
print(f"スケジュール実行がクラッシュしました: {e}")
if not drain_all_due:
break
# 次回のクレーム用時刻を更新
now_ts = int(time.time())
if not ran_any:
# オプション: ログを控えめに
print(f"[{int(time.time())}] 実行予定のスケジュールなし。")
time.sleep(tick_every_seconds)ヘッドレスランナーを起動するには、新しいターミナルを開き、`python headless_runner.py` を実行してください。
Streamlitアプリケーション
Streamlitアプリケーションは大幅に拡張されました。引き続きstreamlit run app.pyで起動可能です。現在は5つの独立したタブを備えています。元の「Run Scrapes」ページはダッシュボードに即時表示されます。
「プロンプト」タブでは、ユーザーが新しいプロンプトを作成し、必要に応じて後で使用するために保存できます。このページの下部では、一括実行の設定と実行が可能です。
「履歴」タブでは、詳細な実行履歴を確認できます。ページ下部では、必要に応じて生のJSONペイロードを検査するオプションも提供されます。
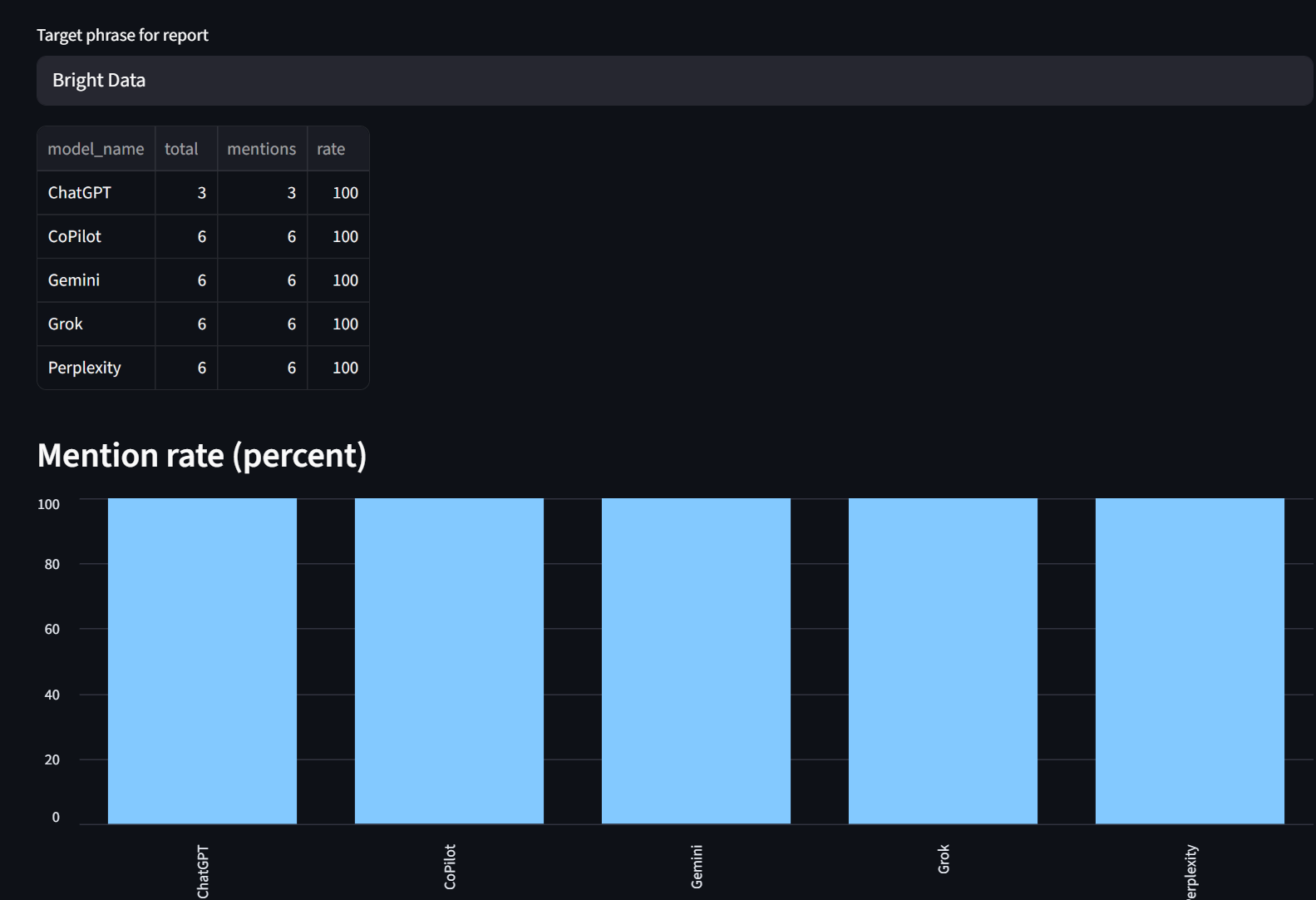
レポートタブでは、モデル別に分類された言及率を確認できます。ご覧の通り、Bright Dataは各モデルから100%の確率で言及されています。
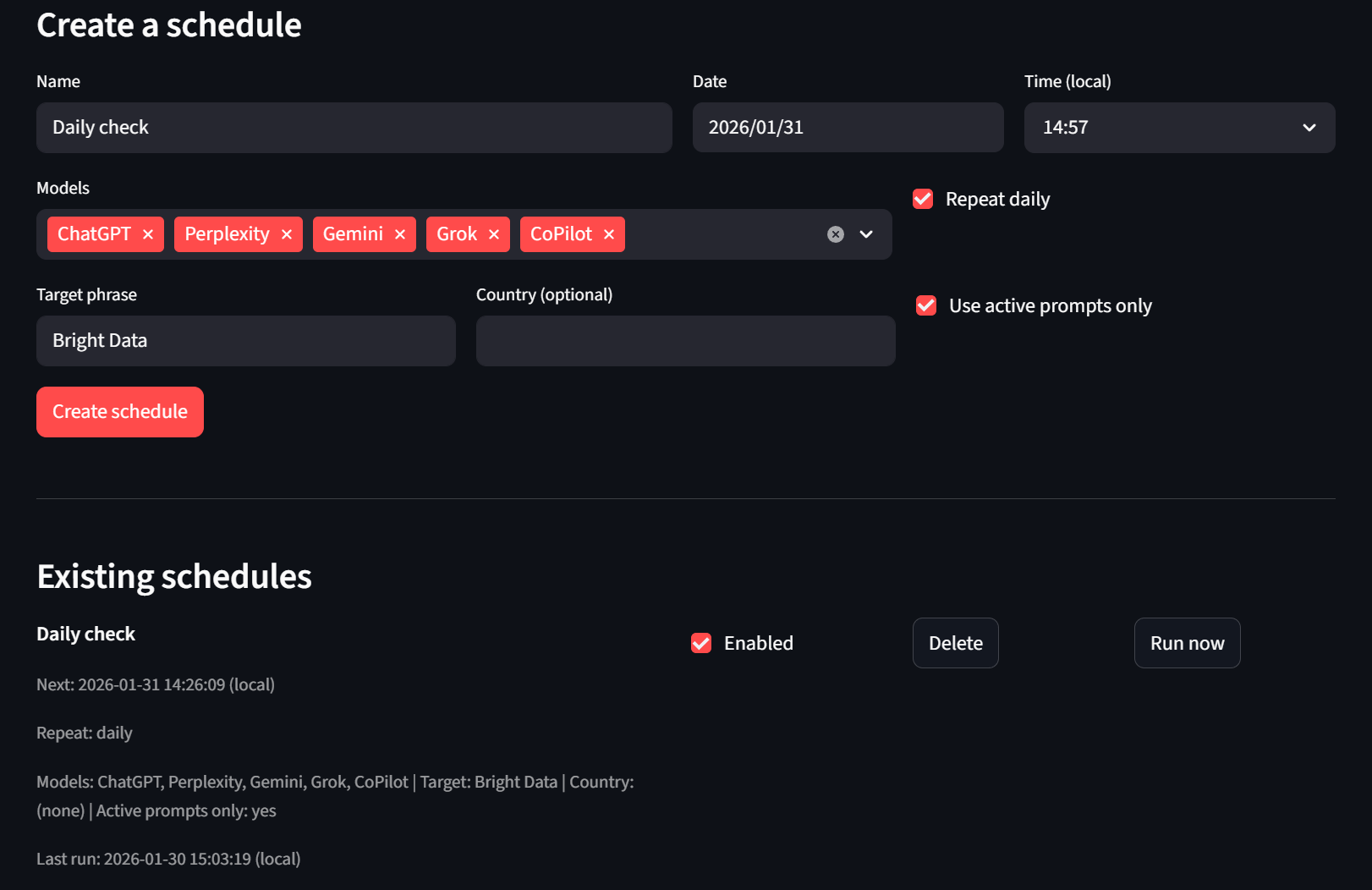
最後にスケジューラータブでは、スケジュールの作成・削除が可能です。即時実行を希望する場合は「今すぐ実行」ボタンを使用すると、ヘッドレスランナーが次のティックで処理を開始します。
結論
本記事の冒頭でプロトタイプを構築した方は、このようなツールを次の段階へ進めるために必要な概念を既に理解しているはずです。
本ガイドで示したアーキテクチャは以下の機能をサポートします:
- 永続的な記憶と履歴追跡:AIモデルが自社ブランドを言及する傾向の検出、ランキング変動の追跡、新興競合他社の特定のために、結果を長期的に保存します。
- 毎日監視する数百のプロンプト:数千のキーワードバリエーション、製品カテゴリ、競合比較にわたるスケジュール収集を自動化。
- 自動化されたレポートと分析:主要なLLM全体におけるブランド言及率、感情分析、引用頻度、競合ポジショニングを示すレポートを生成。
- アラートシステム:自社ブランドが推奨から外れた場合や競合他社の可視性が高まった場合に通知をトリガー。
- マルチリージョン監視:AI応答が地域ごとにどう異なるかを追跡し、地域別マーケティング戦略の策定に活用。
大規模なブランド評判管理を担う企業チームにとって、「自社はAIに推奨されているか?」という問いに、主要モデルすべて、関連するクエリすべて、毎日回答できる能力はもはやオプションではありません。必須のインフラです。
BrightDataのWebスクレイパーAPIは、このレベルの監視を可能にする標準化され信頼性の高いデータフィードを提供します。ChatGPT、Perplexity、Gemini、Grok、Microsoft Copilotのいずれを追跡する場合でも、統一されたスキーマにより統合の摩擦が解消され、チームはデータ処理ではなくインサイトに集中できます。
独自のAI可視化モニタリングシステム構築の準備は整いましたか?無料トライアルを開始し、Bright Dataが次世代SEO戦略をいかに強化するかをご確認ください。





