





- APIベースのスクレイパー
APIリクエスト構築用インターフェース - 大規模な自動化
頻度を制御する独自のスケジューラーを構築 - 配信
データを指定のストレージに配信、またはダウンロード
- APIやノーコードでオンデマンド対応
- 専任のアカウントマネージャー
- 大量リクエストの処理、最大5K URLsまで
- 結果を複数のフォーマットで取得
世界中の20,000+人のお客様から信頼されています。
SEOおよびGEOデータ収集を瞬時にスケール
ハイパーグロース向けに構築されたインフラにプラットフォームを接続。単一のプロキシやパーサーを管理することなく、Google AI、ChatGPT、Gemini全体にわたる複雑なクエリをシームレスに実行できます。
- 1つのプラットフォームですべてのLLMから回答を抽出
- ワークフローを選択:APIまたはノーコードダッシュボード
- ローカライズされた結果のために任意の国をターゲットに
- CSVでプロンプトリストをアップロードして即時一括収集
- 1プロンプトから100万リクエストまでシームレスにスケール
Grokデータを簡単にスクレイピング

完全管理オプション
当社のマネージドサービスで、手間のかからないデータをお楽しみください
ウェブスクレイパーAPI
利用可能なAIウェブスクレイパー
ソース、引用、コンテキストなどの関連メタデータを含む、高度なAIモデルからの構造化されたレスポンスを簡単にキャプチャします。
 305+
305+ 260+
260+AI検索プレイグラウンド
コード例
Grok スクレイパーAPI料金
正常に配信されたものにのみ課金。隠れた手数料なし、配信失敗への課金なし。
これらの支払い方法を受け付けています:
すべてのプランで完全アクセス可能 - スケールに応じて1レコードあたりのコストを削減
データ収集
- 自動プロキシ管理
- 完全なブラウザレンダリング
- CAPTCHA解決
大規模なパフォーマンス
- 無制限の同時実行性
- バッチ&スケジュール収集
- ジョブ管理API
データ配信
- データ検証&発見
- データ解析(JSONまたはCSV)
- WebhookまたはAPI配信
新機能!AI検索エンジン向けウェブスクレイパーAPI
Grok、ChatGPT、Gemini、PerplexityなどのAI生成検索結果におけるブランドのプレゼンスを追跡
AI生成検索結果における言及、推薦、競合比較をリアルタイムで追跡し、ブランドが正確に表現されていることを確認します。

Grok、OpenAIのGPT、Perplexity AIなどのAI検索エンジン全体で、動的なAI駆動の検索ランキングとブランド言及を監視し、競争力を維持します。

AI検索エンジンがあなたのブランドと競合他社をどのようにランク付けするかを分析し、可視性の最適化とAI生成推薦におけるポジショニング改善を支援します。

新機能!AI検索エンジン向けウェブスクレイパーAPI
Grok、Gemini、ChatGPT、Perplexityなどのai生成検索結果におけるブランドのプレゼンスを追跡
AI検索の可視性
AI生成検索結果における言及、推薦、競合比較をリアルタイムで追跡し、ブランドが正確に表現されていることを確認します。
検索と収集
- あらゆるウェブサイトからリアルタイムデータを検索・抽出。
- LLMベースのクエリを使用して最も関連性の高いレコードを取得。
- 手動作業を最小限に抑えながら大規模なデータセットを効率的にフィルタリング。
- スケジュール抽出でデータ取得を自動化。
発見とインタラクション
- ウェブ自動化とAI駆動のユースケース向けに構築。
- 動的ページのナビゲートにUIフォールバックを備えたAPIファーストアプローチ。
- リアルタイムでデータ抽出を検索、フィルタリング、精製。
- 関連データのためにウェブサイト全体または特定のセクションをクロール。
より迅速な導入
1回の API 呼び出し。大量のデータ。
データディスカバリー
データの構造とパターンを検出し、効率的で的を絞ったデータ抽出を行います。
一括要求処理
サーバーの負荷を軽減し、大規模なスクレイピングタスクのデータ収集を最適化します。
データ解析
未加工のHTMLを構造化データに効率的に変換し、データの統合と分析を容易にします。
データ検証
データの信頼性を確保し、手作業での確認と前処理にかかる時間を節約できます。
仕組み
プロキシとCAPTCHAの心配はもう不要
- 自動IP ローテーション
- CAPTCHAソルバー
- ユーザーエージェントのローテーション
- カスタムヘッダー
- JavaScriptレンダリング
- レジデンシャルプロキシ
最高峰の DX
簡単に開始可能。容易にスケーリング可能。
比類のない安定性
世界をリードするプロキシインフラストラクチャを利用することで、一貫したパフォーマンスを確保し、障害を最小限に抑えることができます。
Web スクレイピングをシンプルに
本番環境に対応した API でスクレイピングを自動化することで、リソースを節約し、メンテナンスの手間を減らせます。
無限のスケーラビリティ
最適なパフォーマンスを維持しつつ、データ需要に合わせてスクレイピングプロジェクトを簡単にスケーリングできます。
シームレスなGrokデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
シームレスなGrokデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
ワークフローに合わせたカスタマイズ
WebhookまたはAPI配信を通じて、JSON、NDJSON、またはCSVファイルで構造化データを取得。
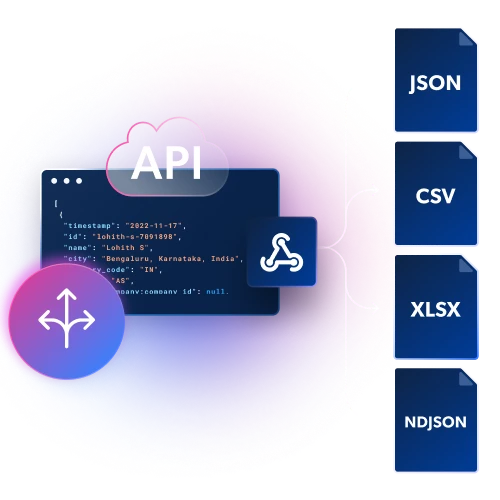
組み込みのインフラとブロック解除
プロキシとブロック解除インフラを維持することなく、最大限のコントロールと柔軟性を実現。CAPTCHAやブロックを回避しながら、あらゆる地域からデータを簡単にスクレイピング。

実績あるインフラ
Bright Dataのプラットフォームは世界中の20,000社以上を支え、99.99%の稼働率と195カ国をカバーする1億5,000万以上の実ユーザーIPへのアクセスで安心を提供。

業界をリードするコンプライアンス
当社のプライバシー慣行は、EUデータ保護規制フレームワーク、GDPR、CCPAを含むデータ保護法に準拠しています。

シームレスなGrokデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
フレキシブル
ワークフローに合わせたカスタマイズ
WebhookまたはAPI配信を通じて、JSON、NDJSON、またはCSVファイルで構造化データを取得。スケーラブル
組み込みのインフラとブロック解除
プロキシとブロック解除インフラを維持することなく、最大限のコントロールと柔軟性を実現。CAPTCHAやブロックを回避しながら、あらゆる地域からデータを簡単にスクレイピング。安定
実績あるインフラ
Bright Dataのプラットフォームは世界中の20,000社以上を支え、99.99%の稼働率と195カ国をカバーする1億5,000万以上の実ユーザーIPへのアクセスで安心を提供。準拠
業界をリードするコンプライアンス
当社のプライバシー慣行は、EUデータ保護規制フレームワーク、GDPR、CCPAを含むデータ保護法に準拠しています。Grokスクレイパーのユースケース
Scrape Grok to stay updated on user queries and AI response trends.
Monitor Grok conversations for emerging topics and AI developments.
Scrape Grok data to analyze response quality and user satisfaction.
Access Grok logs for in-depth research and insights.
20,000+社のお客様がBright Dataを選ぶ理由
100%準拠
スクレイピングされたデータは倫理的に取得され、すべてのプライバシー法に準拠しています。
24時間365日グローバルサポート
データの専門家チームが専任でサポートいたします。
完全なデータカバレッジ
400 million+のグローバルIPにアクセスして、あらゆるウェブサイトからデータをスクレイピング。
比類なきデータ品質
高品質なデータのための高度な技術と検証手法。
強力なインフラ
ブロックされることなく大量データをスクレイピング。
カスタムソリューション
独自のニーズと目標に合わせたソリューションを提供。
Bright Dataは世界トップブランドに利用されています
安全でスケーラブル、柔軟なデータ管理でビジネスの成長をサポートします。
 私は、あらゆる企業、特に金融業界の企業には、Bright Dataの製品の利用をお勧めします。Bright Dataは信頼性が高く、コンプライアンスも遵守しており、 サービスは素晴らしく、製品は完璧で、ネットワークは高速かつ安定しています。
私は、あらゆる企業、特に金融業界の企業には、Bright Dataの製品の利用をお勧めします。Bright Dataは信頼性が高く、コンプライアンスも遵守しており、 サービスは素晴らしく、製品は完璧で、ネットワークは高速かつ安定しています。 Xiaolong ShiCrawler Engineer at Bitget
Xiaolong ShiCrawler Engineer at Bitget- インターネットから公開ウェブデータを収集する機能なしでは、ブランドがすべての媒体に向けて紹介されたこと、またその展開先を知りえることはできず、また、Bright Dataのサポートなしでは急成長を遂げることはできなかったでしょう。今すぐ観る
 Sarah MelvilleData Science Specialist
Sarah MelvilleData Science Specialist  インターネットから公開ウェブデータを収集する機能なしでは、ブランドがすべての媒体に向けて紹介されたこと、またその展開先を知りえることはできず、また、Bright Dataのサポートなしでは急成長を遂げることはできなかったでしょう。 Sarah MelvilleMedia Director at YouGov Sport
インターネットから公開ウェブデータを収集する機能なしでは、ブランドがすべての媒体に向けて紹介されたこと、またその展開先を知りえることはできず、また、Bright Dataのサポートなしでは急成長を遂げることはできなかったでしょう。 Sarah MelvilleMedia Director at YouGov Sport 私の経験から言えば、Bright Dataのサービスは極めて貴重なものでした。Bright Dataのおかげで、当社のニーズを満たすのに十分な公開ウェブデータを収集することができ、また同社のサポートおよび開発スタッフのおかげで、多くのプロセスを最適化することができました。
私の経験から言えば、Bright Dataのサービスは極めて貴重なものでした。Bright Dataのおかげで、当社のニーズを満たすのに十分な公開ウェブデータを収集することができ、また同社のサポートおよび開発スタッフのおかげで、多くのプロセスを最適化することができました。 Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.
Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.- データの質 と量を最大限に確保することが最も重要であり、そこでBright Dataとtgndataの組み合わせが威力を発揮します。今すぐ観る
 George KoutsoudopoulosCEO at tgndata
George KoutsoudopoulosCEO at tgndata  信頼性に非常に感銘を受けており、Bright Dataには全体的に大変満足しています。アカウントマネージャーとは定期的な連絡ルートがあり、非常に協力的です。
信頼性に非常に感銘を受けており、Bright Dataには全体的に大変満足しています。アカウントマネージャーとは定期的な連絡ルートがあり、非常に協力的です。 Yorgos PanzarisCTO at Convert Group
Yorgos PanzarisCTO at Convert Group Bright Dataとの提携には大変満足しております。全てが順調で、ネットワークは非常に安定しており、カスタマーサービスにも満足しています。サポートスタッフは当社にとって最高です。
Bright Dataとの提携には大変満足しております。全てが順調で、ネットワークは非常に安定しており、カスタマーサービスにも満足しています。サポートスタッフは当社にとって最高です。 Cheddi RaiCEO at AdRetreaver
Cheddi RaiCEO at AdRetreaver


Grokスクレイパー APIよくある質問
Grokスクレイパーとは何ですか?
GrokスクレイパーAPIは、GrokウェブサイトからのデータExtractを自動化するために設計された強力なツールであり、ユーザーがさまざまなユースケースのために大量のデータを効率的に収集・処理できます。
GrokスクレイパーAPIはどのように機能しますか?
GrokスクレイパーAPIは、Grokウェブサイトに自動リクエストを送信し、必要なデータポイントを抽出して、構造化された形式で提供することで機能します。このプロセスにより、正確かつ迅速なデータ収集が保証されます。
GrokスクレイパーAPIで収集できるデータポイントは何ですか?
スクレイパーAPIを使用して公開Grokチャットから収集できるデータポイントには、プロンプトテキスト、レスポンス内容、会話URL、ソース、引用、タイムスタンプなど多数があります。
GrokスクレイパーAPIはデータ保護規制に準拠していますか?
はい、GrokスクレイパーAPIはGDPRやCCPAを含むデータ保護規制に準拠するよう設計されています。すべてのデータ収集活動が倫理的かつ合法的に行われることを保証します。
GrokスクレイパーAPIを競合分析に使用できますか?
もちろんです!GrokスクレイパーAPIは競合分析に最適で、Gemini全体での競合のインタラクション、プロンプトトレンド、レスポンス戦略、コンテンツパフォーマンスに関するインサイトを収集できます。
GrokスクレイパーAPIを既存システムと統合するにはどうすればよいですか?
GrokスクレイパーAPIはさまざまなプラットフォームやツールとのシームレスな統合を提供します。既存のデータパイプライン、CRMシステム、または分析ツールと組み合わせて、データ処理能力を向上させることができます。
GrokスクレイパーAPIの使用制限はありますか?
GrokスクレイパーAPIには特定の使用制限はなく、必要に応じてスケールできる柔軟性を提供します。価格はレコードあたり$0.001からで、ウェブスクレイピングプロジェクトのコスト効率の高いスケーラビリティを保証します。
GrokスクレイパーAPIのサポートはありますか?
はい、GrokスクレイパーAPIの専用サポートを提供しています。サポートチームはAPIの使用中に発生する質問や問題をサポートするために24時間365日対応しています。
利用可能な配信方法は何ですか?
Amazon S3、Google Cloud Storage、Google PubSub、Microsoft Azure Storage、Snowflake、およびSFTP。
利用可能なファイル形式は何ですか?
JSON、NDJSON、JSONライン、CSV、および.gzファイル(圧縮)。