

この記事では以下の内容を確認できます:
- LLMスクレイピングが重要な理由と対応可能なシナリオ
- 専用LLMチャットスクレイパーに依存する最善のアプローチの理由
- LLMスクレイピングソリューション比較における主要検討要素。
- 今年度のトップLLMスクレイパー一覧
それでは、さっそく見ていきましょう!
TL;DR:トップLLMスクレイパーのまとめ表
お急ぎの方は、以下のまとめ表でトップLLMスクレイパーを一目で比較してください。
| LLMスクレイパー | 対応LLM | 対応LLM | API | ノーコード | インフラストラクチャ | 同時実行性 | GDPR準拠 | 無料トライアル | エントリー価格 |
|---|---|---|---|---|---|---|---|---|---|
| Bright Data | APIスクレイパー + ノーコード + マネージド | ChatGPT、Perplexity、Gemini、Grok、Google AI Mode、Copilot | ✅ | ✅ | 自動アンブロック機能付きエンタープライズプロキシネットワーク(1億5000万以上のIPアドレス) | 無制限 | ✅ | ✅ | 1,000レコードあたり1.5ドル |
| スクレイピング不要 | APIスクレイパー | ChatGPT、Perplexity、Copilot、Gemini、Google AIモード、Grok | ✅ | ❌ | 統合API + 8000万以上のプロキシネットワーク | 高 | ✅ | ✅ | 月額49ドル |
| cloro | APIスクレイパー | ChatGPT、Perplexity、Copilot、Gemini、Grok、Google AIモード | ✅ | ❌ | 地理的ターゲティング機能付き統合API | 制限あり(同時ジョブ数10~100) | ✅ | ✅ | 月額100ドル |
| A-Parser | デスクトップスクレイパー + API | ChatGPT、Perplexity、Google AIモード、Copilot、DeepAI、Kimi | ✅ (管理用) | ✅ | ローカル実行 + 管理用API | 制限あり(約100~200クエリ/分) | — (非公開) | ❌ | 179ドル(1回限り) |
| Infatica | APIスクレイパー | ChatGPT、Gemini、Perplexity | ✅ | ❌ | レジデンシャルプロキシによるAPIスクレイピング | 高 | ✅ | ❌ | カスタム |
| Apify | 既製スクレイパー + API | ChatGPT、Gemini、Perplexity、Grok、その他(アクターベース) | ✅ | ✅ | プロキシ対応のサーバーレススクレイピングプラットフォーム | 制限あり(同時実行数25~256) | ✅ | ✅ | アクター依存 |
LLMスクレイピングの世界入門
最適なLLMスクレイパーを探る前に、LLMからのデータスクレイピングに関する背景知識と文脈を理解しておくことが役立ちます。
LLMスクレイパーとは?
LLMスクレイパー(LLMチャットスクレイパーやスクレイピングLLMソリューションとも呼ばれる)とは、LLMから構造化データを抽出するために特別に構築されたツールです。つまり、プロンプトを自動的に送信し、生成された応答を収集します。
多くの場合、直接的な回答だけでなく、引用、リンク、メタデータなどの追加出力も取得します。対象プラットフォームにはChatGPT、Gemini、Perplexity、Grok、および類似サービスが含まれます。
LLMスクレイピングが重要な理由
AI研究者が指摘する「データ樽」問題の深刻化に伴い、LLMからのデータスクレイピングはますます重要になっています。この概念は、オンライン上の高品質な人間によるテキストだけでは新たなモデルの訓練が不十分となり、企業が合成データやAI生成データパイプラインに依存せざるを得ない状況を示しています。
その結果、LLM生成コンテンツは現在、新モデルのトレーニングや微調整に広く採用されている。この手法は評価データセットの構築や、継続的に更新されるナレッジベースの生成に活用されている。
業界の推定によれば、多くの現代モデルは既に専門的な微調整において合成コンテンツに大きく依存している。予測では、2030年までに合成データがAIトレーニングを支配する可能性がある。
この傾向を示す注目すべき進展が複数ある。NVIDIAはMinitronアプローチで、大規模モデルからの蒸留により元のデータの3%未満でモデルを再訓練できることを実証した。これはLLMの出力が効率的な訓練素材となり得ることを示している。
一方、DeepSeekはより高度なモデルの出力で訓練することで性能向上を実現した事例である。LLMのスクラッピングは動的データ生成も支援し、例えばモデルがプロンプトに時間経過とともにどう応答するかを監視することで、プロンプトから応答までのデータセット構築を支援する。
LLMスクレイピングの利点
LLMスクレイピングがもたらす主な利点とユースケースは以下の通りです:
- 平易なクエリと結果:自然言語プロンプトによる情報取得により、パースに基づく従来のスクラッピングよりも容易なデータ収集を実現。
- モデル訓練用データセット構築:プロンプトと応答のペアを収集し、微調整、評価、ベンチマーク、またはカスタムAIモデルの訓練用データセットを構築します。
- クロスモデル比較:複数のLLMプロバイダーからの応答を比較し、差異・一致点・モデル固有の挙動を特定。
- 構造化知識抽出:リンク、引用、エンティティ、メタデータなどの構造化データを、本来非構造化であるモデル応答から抽出。
- GEO(生成型エンジン最適化)とAI検索モニタリング:ブランド、製品、トピックが、異なるモデル間で生成されるAI回答にどのように表示されるかを経時的に追跡します。
- 経時的な変化の検出:モデルのアップデートやウェブ上の情報変化に伴い、モデル応答がどのように進化するかを監視します。
専用LLMスクレイパーに依存すべき理由
API経由でモデルに直接プロンプトを送信できるため、LLMからのデータ取得自体は本質的に困難ではありません。真の難点はプロセスの標準化と大規模運用です。大半のLLMプロバイダーは料金プランに基づくAPIレート制限を設けており、プロバイダー間で応答が大幅に異なります。
専用のLLMスクレイパーを選択すれば、これらの課題を回避できます。APIやノーコードツールを介した統一されたLLMスクレイピング環境が提供され、AIモデルからのデータ取得プロセスを構造化され、安定かつ一貫した形式で標準化できます。
LLMスクレイパーは地理位置情報、一括リクエストなどの機能もサポートし、APIを直接呼び出すよりもデータ抽出を容易にします。多くの場合、大規模インフラとバックエンドのキャッシュ機構により、より高速かつコスト効率も向上します。
LLMスクレイパー評価時の考慮点
AIによるウェブスクレイピングソリューションは極めて人気が高い一方、LLMからのデータスクレイピングに特化したツールは依然として比較的珍しい。とはいえ市場は急速に成長しており、新規プレイヤーが定期的に登場している。
時間を無駄にせず、最も関連性の高いツールに集中するためには、以下のような一貫した基準で評価するための比較フレームワークが必要です:
- タイプ:ソリューションがAPI、ノーコードプラットフォーム、デスクトップアプリケーション、その他のツールのいずれであるか。
- 対応LLM:サポートされているLLMプロバイダーとプラットフォーム(例:ChatGPT、Gemini、Grokなど)。
- 含まれるデータ:LLM応答から取得可能なデータの種類(プレーンテキスト、引用、ハイパーリンクなど)。
- インフラストラクチャ:プロバイダーの拡張性、稼働時間の維持、大量のリクエスト処理能力。
- 技術要件:LLMスクレイピングソリューションの利用・統合に必要なスキルやインフラ。
- コンプライアンス:プライバシー規制(GDPRやCCPAなど)およびセキュリティのベストプラクティスへの準拠。
- 価格設定:無料トライアルや評価用クレジットを含む料金体系。
最高のLLMスクレイパー:主要ツールとソリューション
前述の基準を踏まえ、トップ6のLLMスクレイパーを探ってみましょう。
1. Bright Data
Bright Dataはプロキシプロバイダーとして始まり、プラットフォームを主要なウェブデータソリューションへと拡大しました。その豊富な提供内容には、AIシステムからデータを収集するための専用ツールが含まれます。これらのLLMスクレイパーは、API経由またはノーコードインターフェースを通じて、主要なAIモデルから構造化された応答とメタデータを一貫性と拡張性のある方法で抽出します。
具体的には、Bright DataのLLMスクレイピング向け主要ソリューションは以下の通りです:
- ChatGPTスクレイパー: ChatGPTクエリから構造化された応答、プロンプト、引用元、リンク、ランキング、会話メタデータをリアルタイムで収集。
- Perplexityスクレイパー:Perplexity検索から、AI生成の回答とソース、引用、構造化応答データを取得。
- Geminiスクレイパー:Geminiの応答からプロンプト、生成された回答、引用元、リンク、メタデータを標準化された形式で抽出します。
- Grokスクレイパー: Grokが生成した応答と、引用元、生の応答、インデックス化された出力などの構造化メタデータを収集します。
- Google AIモードスクレイパー:Google AIモードからのAI生成検索応答(プロンプト、回答、引用、リンク、インデックス結果を含む)をキャプチャします。
- Copilotスクレイパー: Copilot検索結果から構造化応答、出典、回答セクションを取得します。
これらのソリューションはすべて、1億5000万以上のIPアドレスを擁するグローバルプロキシネットワーク、自動アンブロック技術、99.99%の稼働率を備えたBright Dataのエンタープライズグレードインフラストラクチャ上で動作します。このインフラにより、運用上のオーバーヘッドなしに、信頼性の高い大規模なLLMデータ収集が可能になります。
これらの要素を総合すると、Bright DataはLLMスクレイピングにおいて最も包括的でスケーラブルなプロバイダーとなります。
🏆 理想的な用途: ノーコードまたはAPI統合による、エンタープライズグレードで高スケーラブルな同時マルチプロバイダーLLMスクレイピング。
タイプ:
- APIベースのLLMスクレイパー。
- コントロールパネル経由のノーコードLLMスクレイピングオプション。
- フルマネージドLLMデータ収集オプションを提供。
対応LLM:
- ChatGPT
- Perplexity
- Gemini
- Grok
- Google AIモード(AI概要)
- コパイロット
含まれるデータ:
- テキスト、HTML、またはMarkdown形式のモデル応答。
- JSON、NDJSON、CSVなどの構造化出力形式。
- クエリプロンプトとURL。
- 応答内容と完全なメッセージ。
- 引用と出典。
- 添付リンク。
- 推奨事項とランキング。
- タイムスタンプとメタデータ。
- 生の応答とパース済み構造化データ(プロバイダーによる)。
- 国レベルのメタデータ。
インフラストラクチャ:
- 自動IPローテーションとCAPTCHAの解決機能を備えた組み込みプロキシおよびアンブロックインフラストラクチャ。
- 195カ国にまたがる1億5000万以上のIPアドレスへのアクセス。
- 一括リクエスト対応(同時最大5,000リクエスト)。
- 99.95%の成功率。
- WebhookベースまたはAPIベースのデータ配信。
- 結果のダウンロード、またはAmazon S3やGoogle Cloud Storageなどのストレージサービスへの配信が可能。
- 99.99% の稼働率インフラ。
- 大量のデータ収集とスケーラブルなワークロード向けに設計されています。
- データパース、検証、構造検出機能。
- 無制限の同時実行数。
- 自動化されたスケジュール実行をサポート。
- 専門家チームによる24時間365日サポート。
- 70以上のAI統合が可能。
技術要件:
- LLMスクレイピングAPI接続には基本的なプログラミングスキルが必要です。
- 非技術ユーザー向けのノーコードインターフェースを提供。
- AI/MLワークフロー、パイプライン、アプリケーションへの統合には技術的スキルが必要です。
コンプライアンス:
- GDPRに完全準拠。
- CCPA準拠。
- SEC準拠。
- ISO 27001、SOC 2 Type II、CSA STAR Level 1 規格の認証を取得。
価格:
- クレジットカード不要の無料トライアルを提供。
- 従量課金制:1,000レコードあたり1.5ドルから、契約義務なし。
- 月額プラン:
- 510Kレコード:月額499ドル(1,000レコードあたり0.98ドル)
- 100万レコード:月額999ドル(1,000レコードあたり0.83ドル)
- 250万レコード:月額1,999ドル(1,000レコードあたり0.75ドル)
- カスタム価格設定のエンタープライズプランもご用意しています。
2. Scrapeless
Scrapelessは、LLMからの自動公開データ抽出を専門とするプロキシおよびウェブスクレイピング企業です。特にLLM Chat Scraperサービスは、ChatGPTやGeminiなどからリアルタイムの構造化インサイトを抽出する統一APIを提供します。引用やランキングを捕捉することで、生成型検索エコシステム内でのブランド存在感を正確に監視できます。
🏆 理想的な用途: リアルタイムのLLM応答データと引用情報を含むAI駆動型分析ダッシュボードの構築。
タイプ:
- APIベースのLLMスクレイパー
対応LLM:
- ChatGPT
- Perplexity
- コパイロット
- Gemini
- Google AIモード(AI概要)
- Grok
含まれるデータ:
- Markdownまたはテキスト形式でのモデル応答。
- 選択したプロバイダーと利用可能性に応じて:
- 引用元とコンテンツ参照情報。
- 抽出されたリンクとURL。
- 関連プロンプトおよび構造化メディアデータ(例:地図、画像、動画)。
- 位置情報(座標、住所、カテゴリ)。
- 生のHTML(Google AIモード)。
インフラストラクチャ:
- 複数AIモデルをスクレイピングするための統一API。
- 自動結果配信のためのWebhookサポート。
- 8000万以上のプロキシネットワークを通じ、195ヶ国以上・2000都市以上の国別ターゲティングをサポート。
- スクレイピングAPIインフラを支える99.98%の成功率を誇るプロキシネットワーク。
- 結果を一時保存し、探索を容易にします。
技術要件:
- タスク作成とAPI経由での結果取得に必要な基本的なプログラミングスキル。
コンプライアンス:
- GDPR準拠。
価格:
- 無料トライアルあり。
- ユーザーベースの価格設定:
- 成長プラン: $49/月
- スケール: $199/月
- ビジネス: $399/月
- カスタム:個別見積もり。
- エンタープライズ向け価格設定:
- エンタープライズ: 月額 699 ドル
- エンタープライズプラス:月額999ドル
- カスタム:カスタム価格設定。
3. cloro
cloroは、SEOおよびAI検索エコシステムを監視するためのAPI駆動型プラットフォームです。そのLLMスクレイピングソリューションは、ChatGPT、Gemini、PerplexityなどのAIインターフェースから直接構造化された応答を統一APIを通じて収集します。テキスト、引用、構造化オブジェクトを返すとともに、地理的ターゲティングをサポートします。
🏆 理想的な用途:複数のLLMプロバイダーや検索エンジンにおけるAI検索の可視性を分析するSEOチームやGEOチーム。
タイプ:
- APIベースのLLMスクレイピングソリューション
対応LLM:
- ChatGPT
- Perplexity
- コパイロット
- Gemini
- Grok
- Google AIモード
- Google AI 概要
含まれるデータ:
- テキスト、HTML、またはMarkdown形式のモデル応答。
- 対象LLMおよび利用可能な情報に応じて:
- 構造化された情報源と引用情報。
- 抽出されたエンティティと構造化オブジェクト。
- 検索クエリとクエリ拡張。
- ショッピング関連の構造化データ(例:商品カード)。
- ソースURLとメタデータ。
インフラストラクチャ:
- 複数のAIモデルを横断した構造化データ抽出のための統一API。
- 月間3億回以上のAPI呼び出しをサポート。
- 99.99%の稼働率。
- 国別の地理的ターゲティングをサポート。
- 料金プランに応じて、10~100の同時スクレイピングジョブをサポート。
技術要件:
- HTTPリクエストによるAPI統合が必要です。
- プロンプトの送信と応答処理には基本的なプログラミングスキルが必要です。
コンプライアンス:
- 欧州ユーザー向けにGDPR準拠。
価格:
- 500クレジットの無料トライアルを提供。
- クレジットベースの料金体系(月額プラン):
- ホビー: 月額100ドルで250,000クレジット。
- スターター: 月額250ドル(694,444クレジット)
- グロース: 月額500ドルで1,562,500クレジット。
- ビジネス:月額1,000ドルで3,333,333クレジット。
- エンタープライズ: カスタム価格。
4. A-Parser
A-Parserは、ウェブスクレイピングと自動化のためのウェブベースおよびデスクトップアプリケーションです。様々なプラットフォームからデータを取得するための数十種類の組み込みパーサーを備えています。具体的には、ChatGPT、Perplexity、Google、その他のAIシステムなどのサービスに対応しています。
🏆 理想的な用途:デスクトップベースのLLMスクレイピング体験。
タイプ:
- Windows、Linux、macOS(Docker経由)で利用可能なデスクトップスクレイピングソフトウェア + ウェブインターフェース。
- API経由の自動化をサポート。
対応LLM:
- ChatGPT
- Perplexity
- Google AI(GeminiベースのAIモード)
- コパイロット
- DeepAI
- Kimi
含まれるデータ:
- Markdown/テキスト形式のモデル応答。
- 応答内容および対象LLMプロバイダーに応じて:
- ソースリンク、アンカー、スニペット。
- 画像および画像メタデータ(存在する場合)。
- 構造化エクスポート(例:JSON、CSV、SQL)。
インフラストラクチャ:
- 対象LLMプロバイダーに応じて、毎分100/200クエリをサポート。
- API経由のタスクキューと自動化。
- サードパーティ製プロキシサポート(HTTP、SOCKS4/5)。
- サードパーティ製CAPTCHAの解決サービスとの連携をサポート。
技術要件:
- ノーコードデスクトップソフトウェアのインストールとローカル設定が必要です。
- API経由での管理にはプログラミングスキルが必要です。
コンプライアンス:
- 非公開。
価格:
- 1回限りのライセンス価格:
- Lite: $179
- プロ版: $299
- エンタープライズ版: $479
- 有料アップデートは別途購入可能です。
5. Infatica
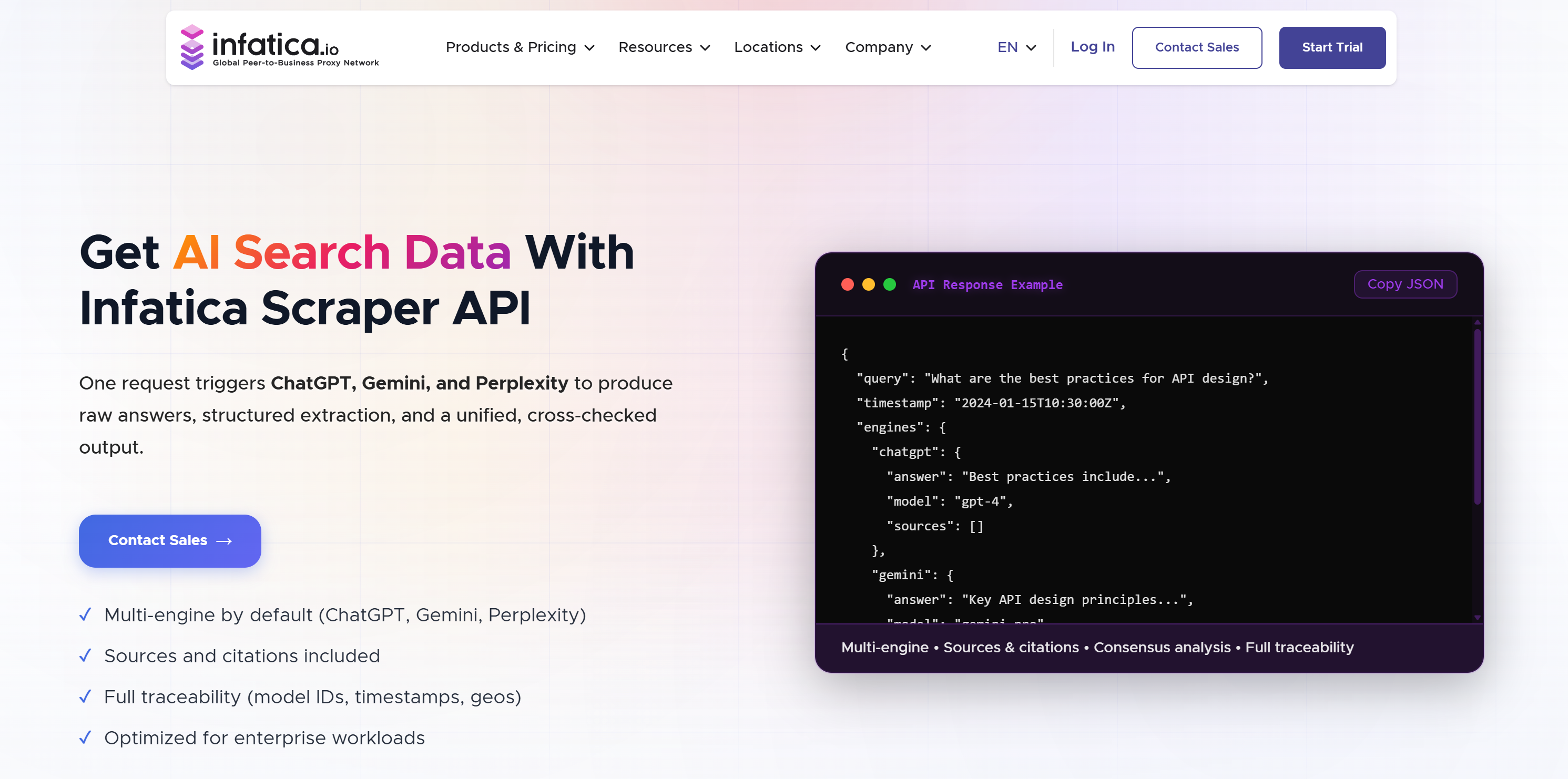
InfaticaはプロキシネットワークとスクレイピングAPIを提供するデータ収集プロバイダーです。数多くのスクレイピングAPIの中でも、AI検索データAPIを提供しています。これは単一リクエストで複数のモデルにクエリを送信するLLMスクレイピングをサポートします。回答、ソース、メタデータを含む正規化された出力を返すため、構造化された分析やモデル間比較が可能です。詳細はInfatica vs Bright Data比較記事をご覧ください。
🏆 理想的な用途:正規化された出力と合意分析による複数LLM間の応答比較。
タイプ:
- APIベースのLLMスクレイパー
対応LLM:
- ChatGPT
- Gemini
- Perplexity
含まれるデータ:
- モデルの生の回答。
- JSONまたはMarkdown形式での構造化抽出。
- モデル間のコンセンサス分析(一致スコアと差異)。
- トレーサビリティメタデータ(例:モデルID、タイムスタンプ、地理情報、バージョン)。
- 利用可能な場合、対象モデルに基づいて:
- 出典と引用情報。
- リンクおよび参照エンティティ。
インフラストラクチャ:
- ブラウザ自動化とレンダリングを備えたスクレイピングエンジン上に構築。
- 最大数百万のリクエストを処理可能。
- バッチジョブと継続的モニタリングをサポート。
- 地理的ターゲティング機能付きレジデンシャルプロキシネットワークを内蔵。
- Webhookおよびバッチパイプラインをサポート。
- モデル横断的な構造化出力の正規化。
技術要件:
- API経由でのリクエスト送信と結果処理にはプログラミングスキルが必要です。
- 簡素化された統合のためのPythonおよびNode.js用SDKを提供。
コンプライアンス:
- GDPR準拠。
- ISO認証取得済み
- コンプライアンス強化と監視のためBYOKモードをサポート。
価格設定:
- カスタム価格(営業部門へお問い合わせください)。
6. Apify
Apifyは、ウェブスクレイピング、ブラウザ自動化、AI統合のためのフルスタックプラットフォームです。コミュニティと企業によって構築された「アクター」と呼ばれる数千の既製サーバーレスアプリケーションを備えています。LLMスクレイピングに関しては、ChatGPT、GeminiなどのAIプラットフォーム向けの専用アクターが用意されています。ApifyとBright Dataの比較をご覧ください。
🏆 理想的な用途: オプションのAPI統合を備えた多数の既製LLMスクレイピングオプションを求めるチーム。
タイプ:
- ノーコードとAPIインターフェースを併せ持つ既製LLMスクレイパー。
対応LLM:
- ChatGPT
- Gemini
- Perplexity
- Grok
- その他(選択したアクターによる)
含まれるデータ:
- 選択したアクターによって異なり、単純な応答からメタデータで強化された応答まで様々。
インフラストラクチャ:
- 複数の同時リクエスト(25~256)をサポートするスケーラブルなインフラストラクチャ。
- 組み込みおよびサードパーティ製プロキシ統合のサポート。
- 各種データタイプに対応した組み込みストレージソリューション。
技術要件:
- カスタムスクリプトへのアクター統合に必要な技術スキル。
- API経由でアクターを呼び出すための基本的なプログラミングスキル。
- ウェブインターフェース経由でのLLMスクレイピングアクターの管理・起動には技術的スキル不要。
コンプライアンス:
- SOC 2 Type II 準拠。
- GDPRおよびCCPA規制に完全に準拠。
価格設定:
- 選択したアクターによって異なります。
結論
本記事では、LLMスクレイパーの定義と、人気AIモデルからのデータ取得を可能にする仕組みについて解説しました。また、モデルトレーニング、モニタリング、GEO分析をはじめとする多様なユースケースにおいて、合成データとLLMデータ抽出の重要性が高まっている現状についても考察しました。
主要なLLMスクレイパーの中でも、Bright Dataはトップクラスの選択肢として際立っています。そのエンタープライズグレードのデータ収集インフラは、1億5000万以上のIPアドレスからなるプロキシネットワークによって支えられ、99.99%の稼働率と99.99%の成功率を実現しています。
Bright Dataは複数の専用LLMスクレイピングAPIをサポートしており、以下が含まれます:
Bright Dataに今すぐ無料で登録し、LLMスクレイピングソリューションの統合を始めましょう!
よくある質問
LLMスクレイパーとLLM搭載スクレイパーの違いは何ですか?
LLMスクレイパーはプロンプトを使用してLLMプロバイダーから直接回答やデータを収集します。一方、LLM搭載スクレイパーはLLMを活用してウェブページや文書から構造化データを抽出します。つまり、LLMスクレイパーはAIサービスを対象とするのに対し、LLM搭載スクレイパーは従来のウェブスクレイピングを強化するためにAIを活用します。
スクレイパーは通常どのLLMプロバイダーを対象としますか?
LLMスクレイパーは、構造化された回答を生成する広く利用されているAIプラットフォームを対象とします。最も一般的にサポートされているプロバイダーには、ChatGPT、Gemini、Perplexity、Copilotが含まれます。一部のツールはGrokやGoogle AI OverviewsなどのAI検索機能もサポートしています。
llm-スクレイパーライブラリとは何ですか?
llm-scraperはLLMを用いてウェブページから構造化データを抽出するオープンソースのTypeScriptライブラリです。カスタムパースロジックを記述する代わりに、スキーマを定義するとLLMがページ内容を分析してそれを埋めます。つまりLLMからデータを収集するスクレイパーではなく、LLMを活用してウェブページからデータを抽出するAI駆動型ウェブスクレイピングソリューションです。 専用ガイドで実際の動作を確認してください。
AIスクレイピングと従来のSERPスクレイピングの違いは?
この文脈におけるAIスクレイピングとは、LLMプロバイダーから直接構造化された回答を収集することを指します。スクレイパーにプロンプトを送信すると、引用や強化されたコンテンツを含む応答を受け取ります。一方、従来のSERPスクレイピングは、クエリに基づいて検索結果ページから生のHTMLを抽出します。AIスクレイピングはモデルが生成した知見の取得に焦点を当てているのに対し、SERPスクレイピングは検索エンジンのリストを手動でパースすることに依存しています。2つのアプローチの詳細をご覧ください。
LLMをウェブスクレイピングに活用する方法
LLM自体をスクレイピングするのではなく、ウェブサイトからデータを抽出・処理するためにLLMを利用したい場合は、以下のチュートリアルを参照してください:
- ChatGPTを用いたウェブスクレイピング:ステップバイステップチュートリアル
- Perplexityを使用したウェブスクレイピング:ステップバイステップガイド
- Google AIモードのスクレイピング方法:完全ガイド
- Google AI概要のスクレイピング方法





