

このチュートリアルでは、以下の内容を学びます:
- BabyAGIとは何か、そしてそれが真にユニークなAIエージェント構築フレームワークである理由。
- – Bright DataサービスでBabyAGIを拡張することで、多様な興味深いシナリオの可能性が広がる理由
- カスタム関数を通じてBright DataをBabyAGIに統合する方法。
さあ、始めましょう!
BabyAGIとは?
BabyAGIは、ユーザー定義の目標を達成するためにタスクを生成・優先順位付け・実行できる自律型AIエージェントを構築するための実験的なPythonフレームワークです。
これは最小限の自己改善型タスクマネージャーのように機能し、推論にはOpenAIのモデルなどのLLMを、記憶にはベクトルデータベースを活用します。一般的に、複雑なワークフローを自動化するインテリジェントループで動作します。
中核となるのは、データベースからの関数の保存・管理・実行を行う「functionz」と呼ばれる関数ベースのフレームワークです。これらの関数はコード生成もサポートし、AIエージェントが新規関数を登録・呼び出し、自律的に進化することを可能にします。
さらに、組み込みダッシュボードでは関数の管理、実行状況の監視、シークレットの登録が可能です。インポート、依存関数、認証シークレットを追跡するグラフベース構造を備え、自動ロードと詳細なロギング機能を有しています。
BabyAGIの特筆すべき点は、そのシンプルさ、自己構築能力、そしてユーザーフレンドリーなウェブダッシュボードです。中核となる考え方は、最小限の構造で自己拡張可能な自律エージェントこそが最も効果的であるというものです。
BabyAGIはオープンソースで活発にメンテナンスされており、GitHubで22,000以上のスターを獲得しています。
ウェブデータアクセスによる自律構築型AIエージェントの強化
LLMは、その学習に使用された静的データによって本質的に制限されており、それが幻覚やその他の一般的なLLMの問題につながることがよくあります。
BabyAGIは自己構築機能フレームワークを通じてこれらの制約を克服します。LLMを用いてカスタム関数を記述し、それをエージェントの能力拡張ツールとして再提供します。
しかし、これらの関数を生成するロジックは、LLMの古い知識によって依然として制限されています。この大きな制限に対処するため、BabyAGIにはウェブを検索し、正確で最新の情報を取得する能力が必要です。これにより、より信頼性の高い関数を生成できるようになります。
これを可能にするのが、Bright Dataサービスとの連携です。具体的には:
- SERP API: Google、Bingなどの検索エンジン結果を大規模に収集し、ブロックされることなく取得。
- Web Unlocker API:単一リクエストで任意のウェブサイトにアクセスし、プロキシ・ヘッダー・CAPTCHAを自動処理したクリーンなHTMLまたはMarkdownを取得。
- ウェブスクレイピングAPI:Amazon、LinkedIn、Instagram、Yahoo Financeなどの人気プラットフォームから構造化・パース済みデータを取得。
- その他ソリューション…
これらの統合機能とBabyAGIの自己構築アーキテクチャを組み合わせることで、AIは自律的に進化し、新機能を追加し、標準的なLLMが単独で達成できる範囲をはるかに超えた複雑なワークフローを処理できます。
Bright DataでBabyAGIのWebデータ取得機能を拡張する方法
このステップバイステップセクションでは、カスタム関数を通じてBright DataをBabyAGIに統合する手順をガイドします。これらはBright Dataの2つの製品、SERP APIとWeb Unlocker APIに接続します。
以下の手順に従って開始してください!
前提条件
このチュートリアルを実行するには、以下の環境が必要です:
- ローカルにインストールされたPython 3.10以上
- OpenAI APIキー。
- SERP APIゾーン、Web Unlocker APIゾーン、有効なAPIキーが設定済みのBright Dataアカウント。
Bright Dataアカウントがまだ設定されていなくても心配はいりません。専用のステップでこのプロセスをガイドします。
ステップ #1: BabyAGIプロジェクトの設定
ターミナルを開き、BabyAGIプロジェクト用の新規フォルダを作成します。例:babyagi-bright-data-app と命名:
mkdir babyagi-bright-data-appbabyagi-bright-data-app/ディレクトリには、BabyAGIダッシュボードを起動し、Bright Data統合機能を定義するPythonコードが含まれます。
次に、プロジェクトディレクトリに移動し、その内部で仮想環境を初期化します:
cd babyagi-bright-data-app
python -m venv .venvプロジェクトルートにmain.pyという新しいファイルを追加し、以下のように記述します:
babyagi-bright-data-app/
├── .venv/
└── main.pymain.pyにはBabyAGIの起動と拡張ロジックが含まれます。
お好みのPython IDE(Python拡張機能付きVisual Studio CodeやPyCharm Community Editionなど)でプロジェクトフォルダを読み込みます。
次に、先ほど作成した仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を実行:
source .venv/bin/activateWindowsでは同等の操作として以下を実行します:
.venv/Scripts/activate仮想環境が有効化された状態で、必要なPyPIライブラリをインストールします:
pip install babyagi requestsこのアプリケーションの依存関係は次のとおりです:
babyagi: BabyAGI本体とすべての必要ライブラリをインストールし、ダッシュボードを起動できるようにします。requests: Bright Dataサービスへの接続に必要なHTTPリクエストを送信します。
完了!これでBabyAGIにおける自己エージェント開発用のPython環境が整いました。
ステップ #2: BabyAGI ダッシュボードを起動する
main.pyファイルに以下のコードを追加し、BabyAGIダッシュボードを初期化・起動します:
import babyagi
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)これにより、BabyAGIはダッシュボードアプリケーションを以下のURLで公開します:
http://localhost:8080/dashboardアプリケーションが動作することを確認するには、以下を実行します:
python main.pyターミナルには、ダッシュボードがhttp://localhost:8080/dashboard で待機中であることを示すログが表示されるはずです:
ブラウザでこのURLにアクセスしてダッシュボードを表示します: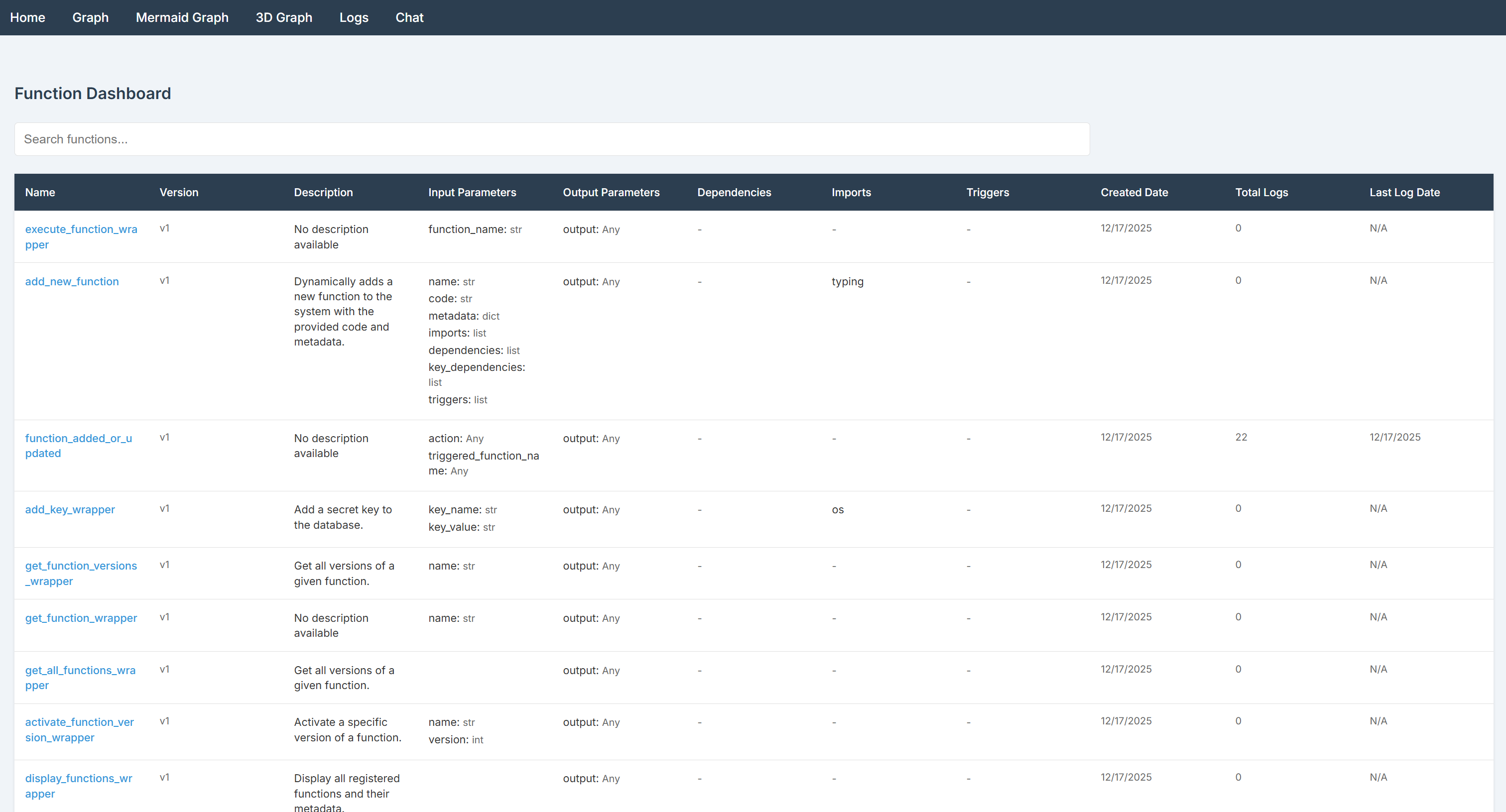
BabyAGIダッシュボードのホームページには利用可能な全関数が一覧表示されます。デフォルトでは、ライブラリには以下の2つの事前ロード済み関数パックが同梱されています:
- デフォルト関数:
- 関数実行: 関数とそのバージョンの実行、追加、更新、取得
- キー管理: 秘密鍵の追加と取得
- トリガー: 他の関数に基づいて関数を実行するトリガーを設定します。
- ログ: オプションのフィルター付きで実行ログを取得します。
- AI関数:
- AIの説明と埋め込み: 関数の説明と埋め込みを自動生成します。
- 関数選択: プロンプトに基づいて類似関数を検索または推奨します。
BabyAGIダッシュボードは、機能管理、実行監視、シークレット処理、トリガー設定、依存関係可視化のためのユーザーフレンドリーなインターフェースを提供します。利用可能なページを探索し、その機能とオプションに慣れましょう!
ステップ #3: シークレット管理の設定
BabyAGIエージェントはOpenAIやBright Dataなどのサードパーティサービスに接続します。これらの接続は外部APIキーで認証されます。main.pyファイルにAPIキーを直接ハードコーディングするのはセキュリティ上の問題を引き起こす可能性があるため、ベストプラクティスではありません。代わりに環境変数から読み込むべきです。
BabyAGIには、追加の依存関係なしで環境変数またはローカルの.envファイルからシークレットを読み取る組み込みメカニズムが備わっています。この機能を使用するには、プロジェクトディレクトリに.envファイルを追加してください:
babyagi-bright-data-app/
├── .venv/
├── .env # <----
└── main.py.envファイルに変数を追加後、コード内で以下のようにアクセスできます:
import os
ENV_VALUE = os.getenv("ENV_NAME")これで完了です!スクリプトはハードコードされた値ではなく、環境変数からサードパーティ統合のシークレットを安全に読み込みます。
別の方法として、ダッシュボードから直接シークレットを設定することも可能です。まず、OpenAI APIキーを設定する必要があります(詳細は次のステップで説明します)。設定が完了したら、ダッシュボードの「Chat」ページに移動します。関数セレクターからadd_key_wrapper関数を選択し、次のようなメッセージでシークレットを定義するようにプロンプトします:
ENV_NAME シークレットを定義し、その値を ENV_VALUE とする。プロンプトを送信すると、以下のような結果が表示されます:
表示の通り、シークレットは正常に作成されました。get_all_secrets_keys関数を追加して呼び出し、シークレットの存在を確認してください。
ステップ #4: BabyAGI を OpenAI モデルに接続する
BabyAGIダッシュボードの「Chat」ページでは、関数を選択し対話型インターフェースを通じて呼び出せます: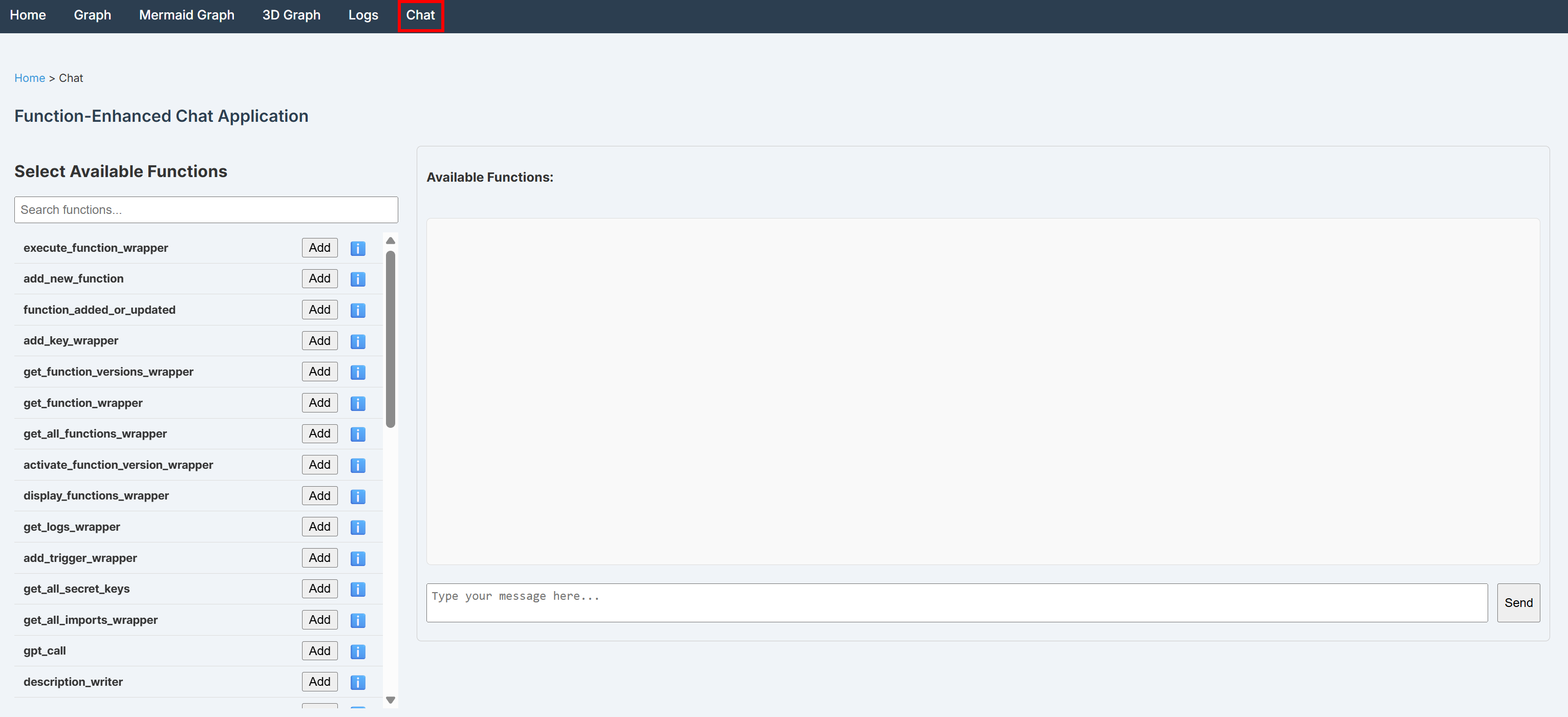
このインターフェースは、OpenAI 統合を通じてLiteLLMによって裏でサポートされています。このため、シークレットに OpenAI API キーを設定する必要があります。
OPENAI_API_KEYシークレットが欠落している場合、Chatページ経由で送信されたメッセージは以下のようなエラーで失敗します:
{"error":"litellm.AuthenticationError: AuthenticationError: OpenAIException - The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable"}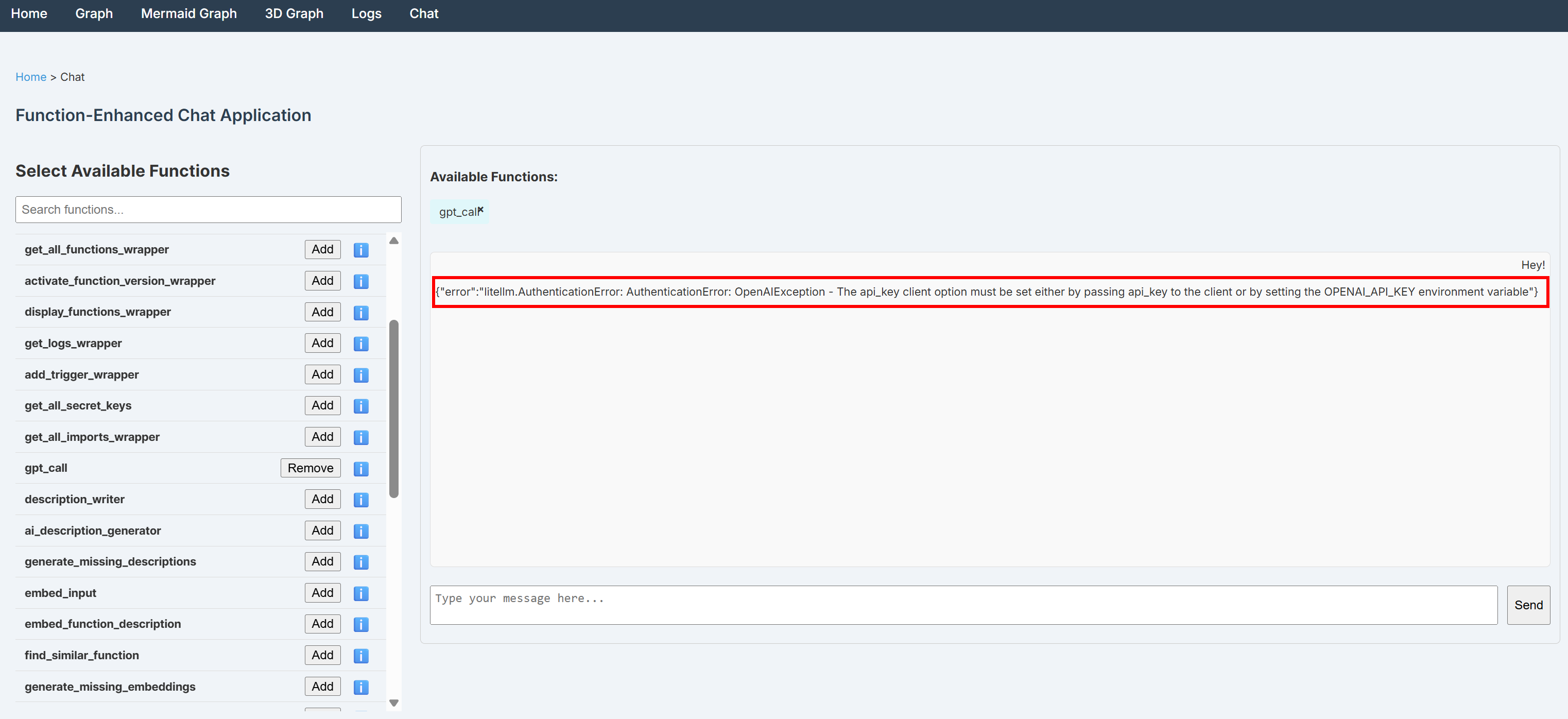
これを解決するには、.env ファイルにOPENAI_API_KEY環境変数を追加してください:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"ファイルを保存後、BabyAGIを再起動してください。統合が機能していることを確認するには、ダッシュボードの「Chat」ページを再度開きます。設定済みのOpenAIモデルを直接呼び出すget_call関数を選択し、「Hey!」などの簡単なメッセージを送信してください。
以下のような応答が返されるはずです: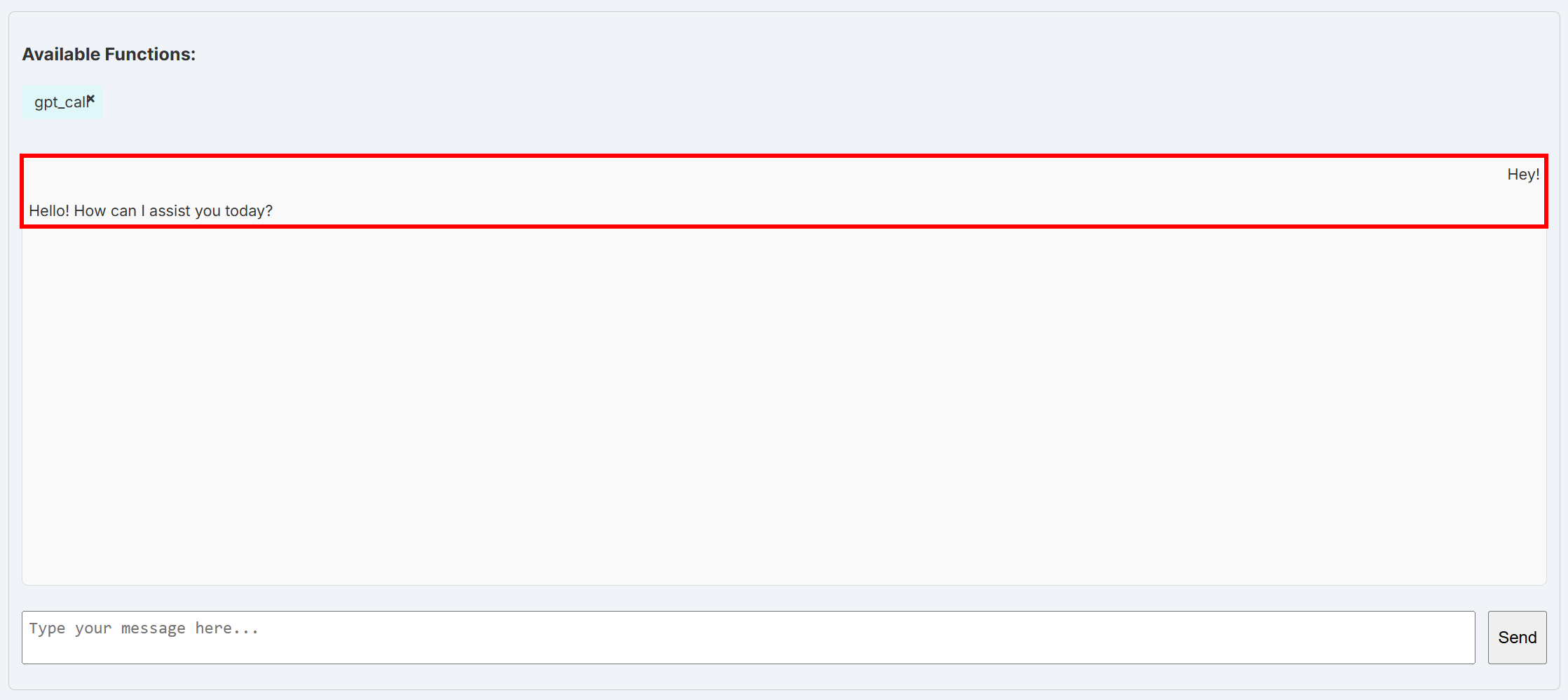
これで、基盤となるLiteLLMレイヤーがデフォルトのOpenAIモデルに正常に接続できる状態になりました。これは、LiteLLMが環境変数OPENAI_API_KEYから自動的にOpenAI APIキーを読み取るためです。
素晴らしい!これでBabyAGIアプリケーションがOpenAIモデルに正しく接続されました。
あるいは、コード内でキーを直接定義しても同じ結果が得られます:
babyagi.add_key_wrapper("openai_api_key", "<YOUR_OPENAI_API_KEY>")これはadd_key_wrapper関数を呼び出します。これはダッシュボード経由でキーを定義するのと同じです。ただし、OpenAI統合が設定される前はダッシュボード方式を使用できない点に注意してください。ダッシュボード自体が機能するにはOpenAI接続に依存しているためです。
ステップ #5: Bright Data の利用開始
BabyAGIでSERP APIとWeb Unlockerサービスを利用するには、SERP APIゾーンとWeb Unlocker APIゾーンの両方が設定されたBright DataアカウントとAPIキーが必要です。さっそく設定しましょう!
Bright Dataアカウントをお持ちでない場合は新規作成してください。お持ちの場合はログイン後、ダッシュボードに移動します。次に「Proxies & Scraping」ページへ進み、「My Zones」テーブルを確認してください:
このテーブルにWeb Unlocker APIゾーン(例:unlocker)とSERP APIゾーン(例:serp)が既に存在する場合、準備は完了です。これら2つのサービスは、カスタムBabyAGI関数経由でWeb UnlockerとSERP APIサービスを呼び出すために使用されます。
いずれか一方または両方のゾーンが存在しない場合は、作成する必要があります。「アンブロッカーAPI」と「SERP API」カードまでスクロールし、「ゾーンを作成」ボタンをクリックしてください。ウィザードに従って両方のゾーンを追加します: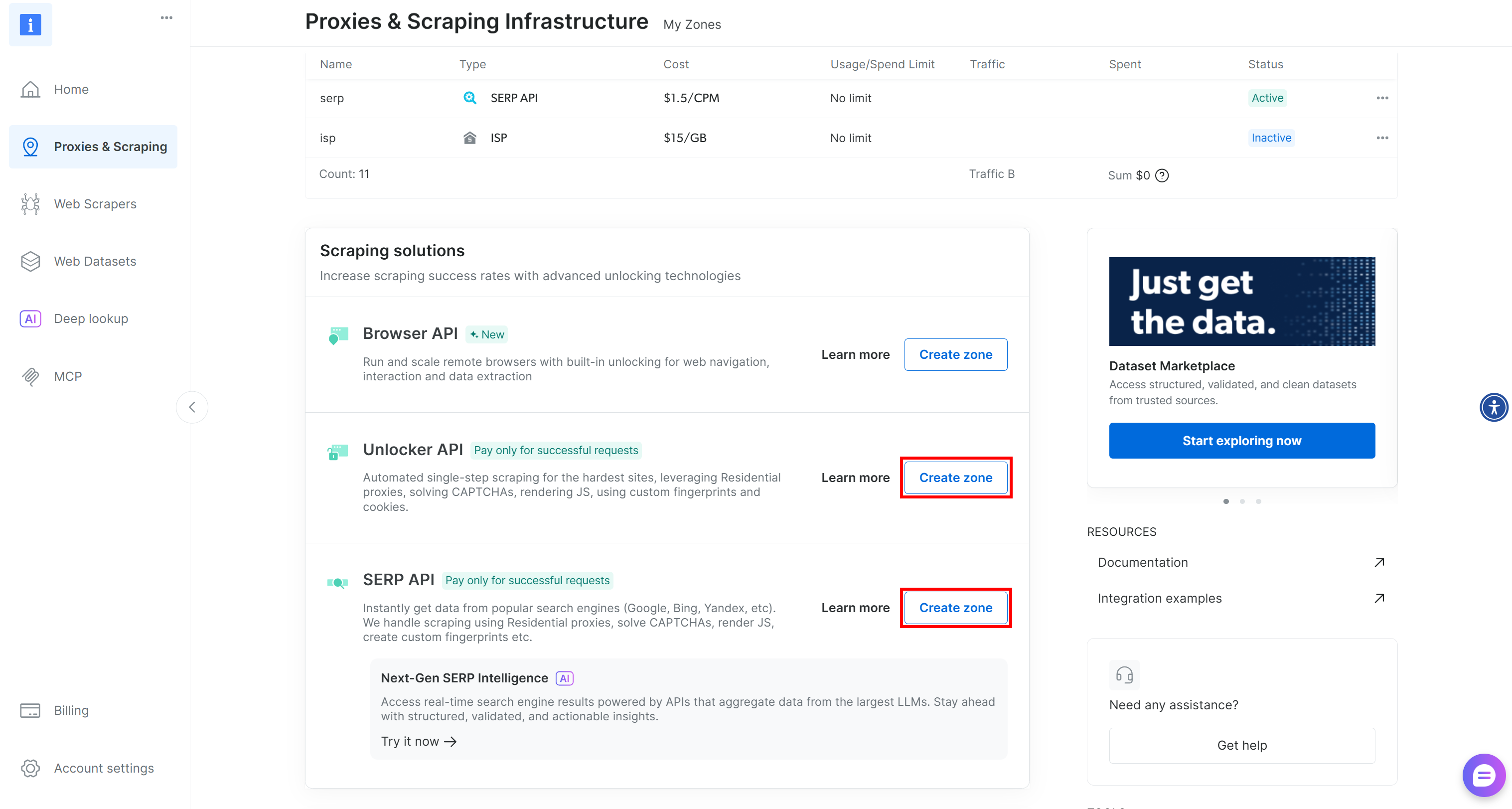
詳細な手順については、以下のドキュメントページを参照してください:
次に、Web Unlocker APIとSERP APIのゾーン名を.envファイルに以下のように追加します:
SERP_API_ZONE="serp"
WEB_UNLOCKER_ZONE="unlocker"重要: この例では、SERP API ゾーンが「serp」、Web Unlocker API ゾーンが「unlocker」という名前であると仮定しています。実際のゾーン名(異なる場合)に置き換えてください。
最後に、Bright Data APIキーを生成し、環境変数として.envに保存します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"これらの3つの環境変数は、カスタムBabyAGI関数によって読み取られ、Bright Dataアカウント内のSERP APIおよびWeb Unlocker APIサービスへの接続に使用されます。これでBabyAGI内で定義・使用できる準備が整いました!
ステップ #6: SERP API 関数の定義
Bright Data SERP API を使用してウェブ検索を実行する BabyAGI 関数の定義から始めます:
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Bright DataのSERP APIを使用して、指定されたクエリでウェブを検索します。"}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# Bright Data APIキーを環境変数から読み込み
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data SERP APIへのリクエスト作成
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textこの関数はRequests HTTPクライアントを利用して、SERP APIゾーンへのPOST HTTPリクエストを送信します。具体的には、Googleにクエリを送信し、Bright Dataを通じてパースされたSERP結果を取得します。詳細はBright Data SERP APIドキュメントを参照してください。
BabyAGI関数は@babyagi.register_functionデコレータを使用して登録する必要があることに注意してください。これは以下のフィールドを受け付けます:
imports: 関数が依存する外部ライブラリのリスト。BabyAGI関数は隔離された環境で実行されるため、これらは必須です。dependencies: この関数が依存する他のBabyAGI関数のリスト。key_dependencies: 関数の動作に必要なシークレットキーのリスト。この場合、必要なシークレットは「bright_data_api_key」と「serp_api_zone」であり、これらは.envファイルで先に定義したBRIGHT_DATA_API_KEYとSERP_API_ZONE環境変数に対応します。metadata["description"]: 関数の動作を人間が理解できる形で説明します。これによりOpenAIモデルがその目的を理解しやすくなります。
素晴らしい!これでBabyAGIアプリケーションにbright_data_serp_api関数が追加され、Bright Data SERP APIを介してウェブ検索が可能になりました。
ステップ #7: Web Unlocker API 関数の定義
同様に、Web Unlocker API を呼び出すカスタム関数を定義します:
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Bright Data Web Unlocker APIを通じてウェブページコンテンツを取得します。"}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# 環境変数から Bright Data API キーを読み取る
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data Web Unlocker API にリクエストを送信
url = "https://api.brightdata.com/request"
data = {
"ゾーン": os.getenv("web_unlocker_ゾーン"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textこの関数はbright_data_serp_api関数と同様に動作しますが、主な違いはWeb Unlocker APIを呼び出す点です。このAPIで使用可能なパラメータやオプションの詳細については、Bright Dataのドキュメントを参照してください。
この関数は、ステップ#5で定義された環境変数WEB_UNLOCKER_ZONEに対応するweb_unlocker_zoneシークレットに依存していることに注意してください。また、data_format引数は 自動的にmarkdownに設定されます。これにより、特別な「Scrape as Markdown」機能が有効になり、指定されたウェブページからスクレイピングされたコンテンツを最適化されたMarkdown形式で返します。これはLLMへの取り込みに理想的です。
ヒント:同様の設定により、ウェブスクレイピングAPIなど他のAPIベースのBright DataソリューションをBabyAGIに統合できます。
ミッション完了! 目的のBright Data機能を活用した機能がBabyAGIに追加されました。
ステップ #8: 完全なコード
main.pyファイルの最終コードは以下の通りです:
import babyagi
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Bright DataのSERP APIを使用して、指定されたクエリでウェブを検索します。"}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# 環境変数からBright Data APIキーを読み込む
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data SERP APIへのリクエスト作成
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Bright Data Web Unlocker APIを介してウェブページのコンテンツを取得します。"}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# Bright Data APIキーを環境変数から読み込み
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data Web Unlocker APIへのリクエストを発行
url = "https://api.brightdata.com/request"
data = {
"ゾーン": os.getenv("web_unlocker_ゾーン"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)代わりに、.envファイルには以下が含まれます:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
SERP_API_ZONE="<YOUR_SERP_API_ZONE_NAME>"
WEB_UNLOCKER_ZONE="<YOUR_WEB_UNLOCKER_ZONE_NAME>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"BabyAGIダッシュボードを起動するには:
python main.pyブラウザでhttp://localhost:8080/dashboardを開き、「Chat」ページに移動して「bright_data」を検索してください。Bright Data 統合用にコードで定義された 2 つの関数が確認できます: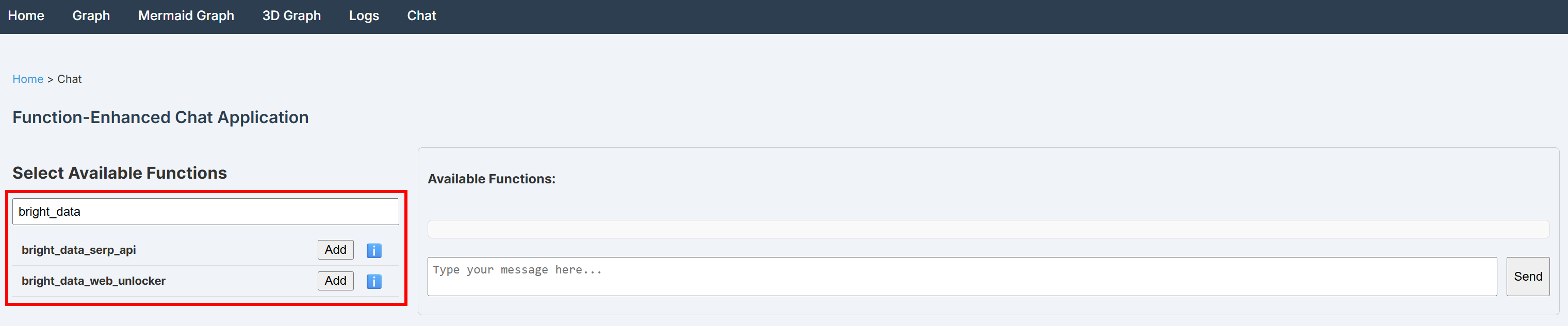
素晴らしい!2つのカスタム関数が正しく登録されました。
ステップ #9: BabyAGI + Bright Data 統合のテスト
デフォルトのchat_with_functions関数を使用してBrightData関数をテストし、BabyAGIアプリケーションが動作することを確認します。これによりLiteLLMに接続したチャット対話が開始され、関数データベースから選択した関数が実行されます。
まずbright_data_serp_apiとbright_data_web_unlocker関数を選択し、次にchat_with_functionsを選択します:
次に、ウェブ検索とデータ抽出の両方をトリガーするプロンプトを使用する必要があります。例えば、以下を試してみてください:
ウェブ上で最新のGoogle AI発表(2025年)を検索し、信頼性の高いニュース記事またはブログ記事を上位3件選択。各記事にアクセスし、Google AIの将来に関する主要な洞察を要約(出典記事のURLを明記)注:外部ツールによるウェブアクセス機能を持たない標準的なLLMでは、このタスクを完了できません。
チャットでプロンプトを実行すると、以下のような出力が表示されるはずです: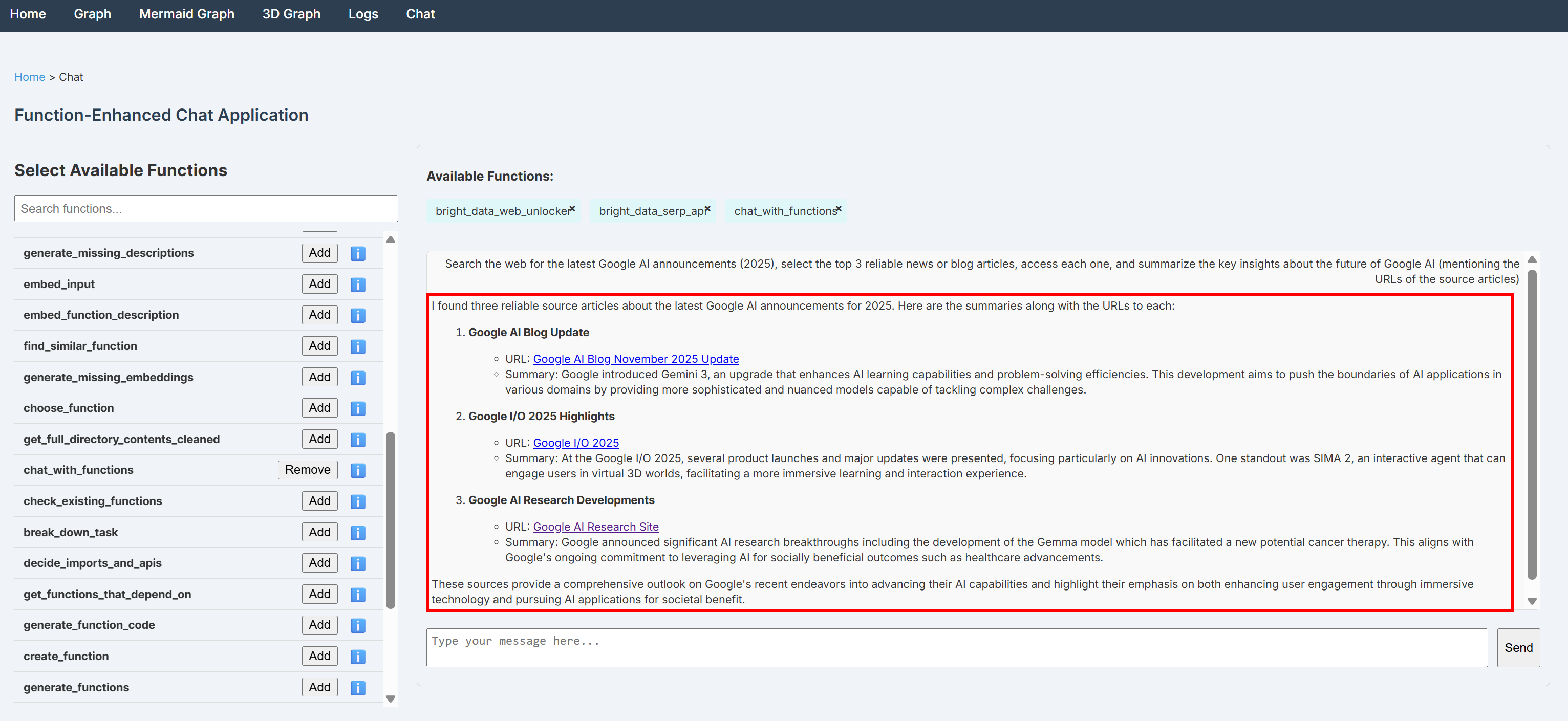
出力には、SERP APIを介したGoogle検索とWeb Unlocker APIによる選定ニュースページのスクレイピングで取得した根拠に基づく洞察が含まれている点に注目してください。
エージェントが現在のウェブコンテンツと対話し学習できることを確認できたため、これはエージェントが自己構築機能を持ち、他のサービスのドキュメントにアクセスして当初知らなかった技術的詳細を学習し、それらと対話できる能力を有することを意味します。BabyAGIドキュメントで説明されている自己AIエージェント構築のためのself_build関数を通じてこれをテストしてください。
様々な入力プロンプトやその他のBabyAGI機能を自由に試してみてください。Bright Dataの機能により、BabyAGIの自己構築エージェントは多様な実世界のユースケースに対応できます。
さあ、どうぞ! Bright DataとBabyAGIを組み合わせた威力を体感いただけたはずです。
結論
本ブログ記事では、SERP APIとWeb Unlocker APIを呼び出すカスタム関数を通じて、BabyAGIでBright Data機能を有効化する方法を解説しました。
この設定により、あらゆるウェブページからのコンテンツ取得やリアルタイムのウェブ検索が可能になります。ライブウェブフィードへのアクセスやウェブ操作の自動化など、機能をさらに拡張するには、BabyAGIをBright DataのAIのためのデータを含むサービススイート全体と統合してください。
自己構築型AIエージェントの真の潜在能力を解き放ちましょう!
今すぐBright Dataアカウントを無料で登録し、AI対応のウェブデータソリューションの実験を始めましょう!





