

Exaはセマンティック検索エンジンです。Bright Dataはウェブデータインフラストラクチャです。これらは根本的に異なる製品であり、どちらを使用すべきかは、AIエージェントが実際に何を行う必要があるかによって完全に決まります。
この比較では、本番環境のAIチームにとって重要なあらゆる側面(コスト、レート制限、カバレッジ、アクセス、履歴データ)について、両製品を徹底的に検証しています。曖昧な評価は一切なく、数字と事実のみを提示します。
TL;DR – Bright Data 対 Exa の概要
- Exaはセマンティック検索エンジンであり、Bright DataはWebデータインフラストラクチャです。
- Bright DataのSERP APIは1,000リクエストあたり1.50ドル、Exaは1,000リクエストあたり7ドルです。
- Exaのデフォルトの
/searchリクエスト制限は10 QPSです。Bright Dataには同時リクエスト制限がありません。 - Bright DataのWeb Unlockerは、ボット対策が施されたページもクロール可能です。Exaではできません。
- Bright Dataは50PB以上の過去のウェブデータを保有しています。Exaはリアルタイムデータのみです。
- Exaの「Find Similar」機能は独自のもので、Bright Dataには直接的な同等機能がありません。
- セマンティックディスカバリーにはExaを、大規模なグラウンドトゥルース抽出にはBright Dataをご利用ください。
Bright Data 対 Exa:直接比較
| 項目 | Bright Data | Exa |
|---|---|---|
| 製品カテゴリ | Webデータインフラ(プロキシネットワーク+スクレイピング+データセット) | Semantic search engine API |
| 検索アプローチ | SERP API経由での実際の検索エンジン(Google、Bing、Yandexなど)からのスクレイピング+Discover APIによるリアルタイム検索 | カスタム埋め込みベースのニューラルインデックス(独自インデックス) |
| クエリごとの検索結果数 | 最大1,000件(Discover API) | 最大100件(スタンダード);エンタープライズでは最大1,000件 |
| ページ全体のコンテンツ | はい、Web Unlocker によるライブ抽出、Markdown 形式で返却 | はい、/contentsエンドポイント経由(1,000ページごとに1ドルの追加料金) |
| ボット対策およびCAPTCHA回避 | はい、Web Unlockerに組み込み済み;1億5,000万以上のプロキシIP | いいえ、ログインが必要なページやボット対策の保護を突破してクロールすることはできません |
| 履歴データ | はい、50PB以上のWebアーカイブ;事前構築済みデータセット | いいえ、ライブインデックスのみ |
| レート制限 | 同時リクエスト数に制限なし(SERP API) | /searchではデフォルトで10 QPS、Enterpriseではカスタマイズ可能 |
| 料金(従量課金制) | 1,000リクエストあたり1.50ドルから(SERP API) | 1,000リクエストあたり7ドル(標準検索、1~10件の結果) |
| 対応検索エンジン | Google、Bing、DuckDuckGo、Yandex、Baidu、Naver、Yahoo | Exa独自のニューラルインデックス |
| コンプライアンス | GDPR、CCPA、SOC 2、SOC 3、ISO 27701 | SOC 2 Type II、ZDRオプション |
| MCP 統合 | はい、Bright Data MCP Server(無料、月間5,000リクエストまで無料) | はい、Exa MCPサーバー |
| フレームワーク連携 | LangChain、LlamaIndex、CrewAI、Agno、Dify、n8n、Zapier、70以上 | LangChain、LlamaIndex、CrewAI、Vercel AI SDK、20以上 |
| 無料プラン | はい、無料トライアル | あり、月間1,000リクエスト |
| エンタープライズSLA | はい、99.9%のSLA、専任アカウントマネージャー | はい、カスタムSLA、1対1のオンボーディング |
Exaとは?
Exaは、AIアプリケーション向けに特別に構築された検索エンジンです。従来のキーワードインデックス化ではなく、Exaは独自のニューラルインデックス、つまりウェブ上で学習された大規模な埋め込みモデルを構築しました。Exaにクエリを送信すると、そのインデックス全体に対してセマンティックベクトル検索を実行し、キーワードの一致度ではなく、概念的な関連性に基づいてランク付けされた結果を返します。
このアーキテクチャの選択こそが、Exaの最大の差別化要因です。「このarXiv URLと類似した論文を探して」や「半導体分野でNvidiaと同様の事業を行う企業」といった質問に対し、キーワードベースのSERPスクレイパーでは不可能な方法で回答します。 2026年3月現在、Exaのインデックスには10億件を超える人物プロフィールと7,000万件の企業エントリーが含まれており、ニュース、コード、財務報告書専用の検索モードも提供しています。Exaの代替ツールを検討している場合は、「AIウェブ検索における主要なExa代替ツール」の記事で、Bright Data、Tavily、Firecrawlを含む競合ツールの詳細な比較を確認できます。
Exaの強み
セマンティックな「類似検索」。他のAPIには、「このURLと概念的に類似したページを探して」という機能を提供するものは存在しません。これはBright Dataが埋められない、真の機能的なギャップです。
低遅延の検索結果取得。Exa Instantは200ms未満のレスポンスを実現します。標準的な検索では100~1,200msかかります。対話型チャットインターフェースやリアルタイムエージェントにとって、この速度は大きな強みとなります。
開発者体験。PythonおよびTypeScriptのSDK、LangChain、LlamaIndex、CrewAIとのネイティブ統合、MCP Serverのサポート、そして月間1,000リクエストという手厚い無料枠。ゼロから動作するエージェント統合まで、わずか数分で実現できます。
専門分野に特化したインデックス。Exaの「人物インデックス」(10億件以上のプロフィール、週5,000万件以上の更新)および「企業インデックス」(7,000万社以上)は、採用エージェント、セールスインテリジェンスパイプライン、企業情報充実ワークフロー向けに特別に構築されています。
ベンチマークにおける高い精度。Fortune 100企業による評価(2025年1月)において、WebWalkerのマルチホップ検索において、Exaは81%のスコアを記録し、Tavilyの71%を上回りました。また、8つのAPIを対象としたAIMultipleの100クエリベンチマークでは、Exaはエージェントスコア14.39で3位にランクインしました。
大規模運用におけるExaの主な制限事項
Exaのレート制限が本番環境のワークロードを制約します。デフォルトの/searchリミットは10 QPS(分あたり600リクエスト)です。これはExaの公式レート制限ドキュメントで直接確認済みです。数千の並列リサーチタスクを実行するマルチエージェントパイプラインの場合、この上限により、チームは導入当初からリトライロジックやリクエストキューイングを構築せざるを得ません。エンタープライズ顧客はより高いリミットを交渉できますが、それには別途営業担当との協議が必要です。
Exaはボット対策の防御を突破できません。Exaは独自のスケジュールで公開ウェブをクロールします。Cloudflareの背後にあるページ、ログインが必要なページ、CAPTCHAシステム、またはJavaScriptを多用したボット検出の壁を越えてページを取得することはできません。競合情報分析、価格監視、あるいは最も価値のあるページが同時に最も厳重に保護されているようなユースケースにおいては、これは致命的な制限となります。
履歴データ層がない。Exaはリアルタイムデータのみを扱います。アーカイブ製品も、過去のデータセットも存在せず、今日の結果を前四半期と比較する方法もありません。異常検知、トレンド分析、あるいはベースラインに基づいたエージェントの出力においては、これは構造的な欠陥となります。
ExaのインデックスはGoogleではありません。ExaはGoogle、Bing、Yandexではなく、独自のニューラルインデックスから結果を返します。実際のユーザーが現在Googleで何を見ているかを正確に把握する必要があるユースケース(SEOモニタリング、広告インテリジェンス、順位追跡、ブランド保護など)においては、Exaのインデックスは適切なデータソースとは言えません。
大量利用時の価格設定は非効率的です。月間100万リクエストの場合、Exaの標準検索は7,000ドル以上かかります。フルページコンテンツを含むと、その金額は8,000ドル以上に跳ね上がります。Exaは2026年3月に価格改定を行い、標準検索を1,000リクエストあたり5ドルから7ドルに引き上げ、1,000リクエストあたり12ドルの「Agentic」プランを導入しました。
Bright Dataとは?
Bright Dataはウェブデータインフラストラクチャです。独自の検索インデックスを持たず、さまざまなデータ取得パターンに合わせて設計された一連の製品を通じて、実際のライブウェブに大規模にアクセスします。
SERP APIは、195カ国のいずれからでも、都市レベルのジオターゲティングを用いて、Google、Bing、Yandex、Baidu、DuckDuckGo、Yahoo、Naverの実際の検索結果をリアルタイムでスクレイピングします。これは、インデックスが「表示すべき」と考える結果ではなく、その場所にいる実際のユーザーが今まさに目にするであろう結果を返します。
Discover APIは、SEO順位付けされたリンクの表面的なリストではなく、ライブウェブからのより広範かつ深い証拠を必要とするエージェントのワークロード向けに特別に設計されています。このAPIは、リクエストごとに最大1,000件の結果を含むライブURLを検索し、SEO順位ではなくエージェントの具体的な意図に基づいてランク付けします。また、RAGのグラウンディングや検証用に、クリーンなMarkdown形式のコンテンツをオプションで提供します。 検索エンジンやキャッシュされたインデックスとは異なり、Discoverのリクエストはすべてクエリ実行時にライブWebに対して実行されるため、競合情報分析、リスク監視、デューデリジェンスのワークフローに特に適しています。
Web Unlockerは、Cloudflare、CAPTCHA、ログイン壁、JavaScriptレンダリングの背後にあるページを含め、あらゆるウェブページを取得し、クリーンなMarkdownコンテンツを返します。195カ国にまたがる1億5,000万以上のレジデンシャルIPアドレスからなるネットワークを経由してリクエストをルーティングし、検知回避を自動的に処理します。
データセットレイヤーは、100以上のドメインにわたる事前構築済みの構造化データを提供します。Web Archive APIは、数年分遡る50PB以上の過去のWebデータを提供し、歴史的背景の把握に最適なソリューションとなります。
AIのためのWebデータに対するBright Dataのアプローチ
Bright Dataのアーキテクチャは、ある核心的な前提に基づいて構築されています。それは、「グラウンドトゥルース(真の実態)」とは、インデックスによる近似値ではなく、実際のライブWebそのものであるということです。本番システムを構築する企業のAIチームにとって、これは次のような場合に重要になります。
- エージェントが競合他社の価格ページを取得する必要があるが、そのページがスクレイパーをブロックしている場合
- エージェントが、ニューラルインデックスによる推定値ではなく、Googleが実際に表示しているキーワード検索結果を知る必要がある場合
- エージェントがレート制限の上限に達することなく、10,000件のクエリを並行して実行する必要がある場合
- エージェントが、今日の検索結果が6ヶ月前と比較して異常かどうかを把握する必要がある場合
Bright Dataは、フォーチュン500企業を含む20,000社以上の顧客から信頼されており、ガートナーの「Webデータ収集ソリューションの競合環境」レポートでも言及されています。また、GDPR、CCPA、SOC 2、SOC 3、およびISO 27701の認証を取得しています。
主な製品:SERP API、Discover API、Web Unlocker、データセット
| 製品 | 機能 | 価格 |
|---|---|---|
| SERP API | 7つの検索エンジン、195カ国を対象としたリアルタイムスクレイピング、構造化されたJSON/Markdown形式の出力 | 1,000件あたり1.50ドルから(従量課金制);月間200万件利用で1,000件あたり1.00ドル |
| Discover API | リクエストあたり最大1,000件のライブURL検出、意図に基づくランク付け、オプションでMarkdown形式のコンテンツ | 無料(ベータ版) |
| Web Unlocker | ボット対策の背後にある任意のページを取得し、クリーンなMarkdown形式で返却 | 1,000リクエストあたり1ドルから |
| データセット | 100以上のドメインから収集した構造化データ | 10万件あたり250ドルから |
| WebアーカイブAPI | 50PB以上の過去のWebデータ | HTMLページ1,000ページあたり0.20ドルから |
| MCPサーバー | AIエージェントをBright Dataの全製品スイートに直接接続 | 無料、月間5,000リクエスト |
価格比較:Bright Data 対 Exa
Exaの価格(2026年3月)
| 製品 | 価格 |
|---|---|
| スタンダード検索(1~10件の結果) | 7ドル / 1,000リクエスト |
| 10件を超える追加結果 | +1ドル / 1,000件 |
| エージェント検索 / ディープ検索 | 1,000リクエストあたり12ドル |
| 推論付きディープ検索 | 15ドル / 1,000リクエスト |
| コンテンツ(ページ全文) | 1ドル / 1,000ページ |
| 回答 API | 5ドル / 1,000回答 |
| 無料枠 | 月間1,000リクエスト |
| エンタープライズ | カスタム |
重要な注意点:Exaの料金体系は加算式です。エージェントが10件の結果に加え、ページ全体のコンテンツを必要とする場合、1,000リクエストごとに検索料金($7)とコンテンツ料金($1)を支払います。全文インライン表示を必要とするエージェントの最低実効コストは、1,000リクエストあたり$8となります。
Bright Dataの料金体系
| 製品 | 価格 |
|---|---|
| SERP API (従量課金) | 1,000件あたり$1.50 |
| SERP API (月間38万件) | 1,000件あたり 1.30ドル |
| SERP API (月間90万件) | 1,000件あたり 1.10ドル |
| SERP API(月間200万件) | 1,000件あたり1.00ドル |
| Web Unlocker | 1,000リクエストあたり1ドルから |
| データセット | 250ドル~ / 10万件 |
| Web Archive | 0.20 ドル~ / 1,000 HTML ページ |
| Discover API | 無料(ベータ版) |
| MCPサーバー | 無料(月間5,000リクエスト) |
スケールに応じたコスト:数字が物語る現実
| ボリューム | エクサ(標準検索のみ) | エクサ(検索+コンテンツ) | Bright Data SERP API |
|---|---|---|---|
| 10,000リクエスト | 70ドル | 80ドル | 15ドル |
| 100,000リクエスト | 700ドル | 800ドル | 130~150ドル |
| 1,000,000リクエスト | 7,000ドル以上 | 8,000ドル以上 | 1,000~1,500ドル |
月間100万リクエストの場合、検索機能のみで見ると、Bright DataはExaよりも5~7倍安価です。大規模なSERPおよびウェブ検索APIプロバイダーの完全な比較については、「2026年のベストSERP APIおよびウェブ検索API」をご覧ください。ページ全体のコンテンツが必要なエージェントの場合、その差はさらに広がります。Exaは1,000リクエストごとに1ドルが追加されますが、Bright Data Web Unlockerは1,000リクエストあたり1ドルから(すべて込み)で利用可能です。
Bright Dataには同時リクエスト制限がない
これは些細な違いではありません。Exaのデフォルトの/searchレート制限は10 QPS(秒間10クエリ、分間600クエリ)です。これはExaの公式レート制限ドキュメントで確認できます。
Bright DataのSERP APIには、同時リクエスト数に制限がありません。同社のFAQには次のように記載されています。「同時リクエスト数に制限はありません。SERP APIはスケーラビリティを考慮して構築されています。」
単一エージェントによる、1回に1クエリのみのワークロードであれば、これは問題になりません。しかし、数十から数百の並列リサーチタスクを実行する本番環境のAIパイプライン、競合情報システム、マルチエージェントリサーチフレームワーク、リアルタイムモニタリングスタックにおいては、この違いは根本的なものです。Exaを使用する場合、導入初日から上限を前提とした設計を余儀なくされます。
Bright DataはExaが到達できないページにもアクセス可能
Exaはオープンウェブをクロールします。以下のページにはアクセスできません:
- Cloudflareの保護下にあるページ
- ログインが必要なサイトや認証要件のあるサイト
- CAPTCHAが適用されているページ
- 生のHTTPリクエストに対してコンテンツを返さない、JavaScriptを多用するサイト
- ローカルIPアドレスを必要とする地域制限のあるコンテンツ
これは批判ではなく、単にExaの製品範囲外であるということです。
Bright DataのWeb Unlockerは、この問題に特化して開発されました。1億5,000万以上のレジデンシャルIPを経由してリクエストをルーティングし、ブラウザフィンガープリントへの対応、CAPTCHAの解決を管理し、レンダリングされたページコンテンツ全体をクリーンなMarkdown形式で返します。ボット対策の回避が何を意味するのかを包括的に理解する必要があるチームのために、ウェブスクレイピングにおけるCloudflareの回避ガイドでは、関連する手法を詳細に解説しています。 最も価値のあるデータが最も厳重に保護されたページにあることが多い競合情報において、これは極めて重要な機能です。
以下は、本番環境のエージェントが同じタスクに対してBright Data SERP APIとExaをどのように使用するかを示す最小限の例です:
# Bright Data SERP API - 実際のGoogle検索結果、レート制限なし
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # LLM対応の出力
}
)
results = response.json()
# Exa - セマンティック検索、10 QPS制限
from exa_py import Exa
exa = Exa(api_key="YOUR_EXA_KEY")
results = exa.search_and_contents(
"competitor pricing enterprise 2026",
num_results=10,
text=True
)
# $7/1k (検索) + $1/1k (コンテンツ) = $8/1k の実質コスト基本的なクエリの場合、機能的な出力は似ています。違いが現れるのは、1,000社の競合他社に対してこれを並列で実行する必要がある場合や、対象ページがExaのクローラーをブロックしている場合です。次の例をご覧ください:
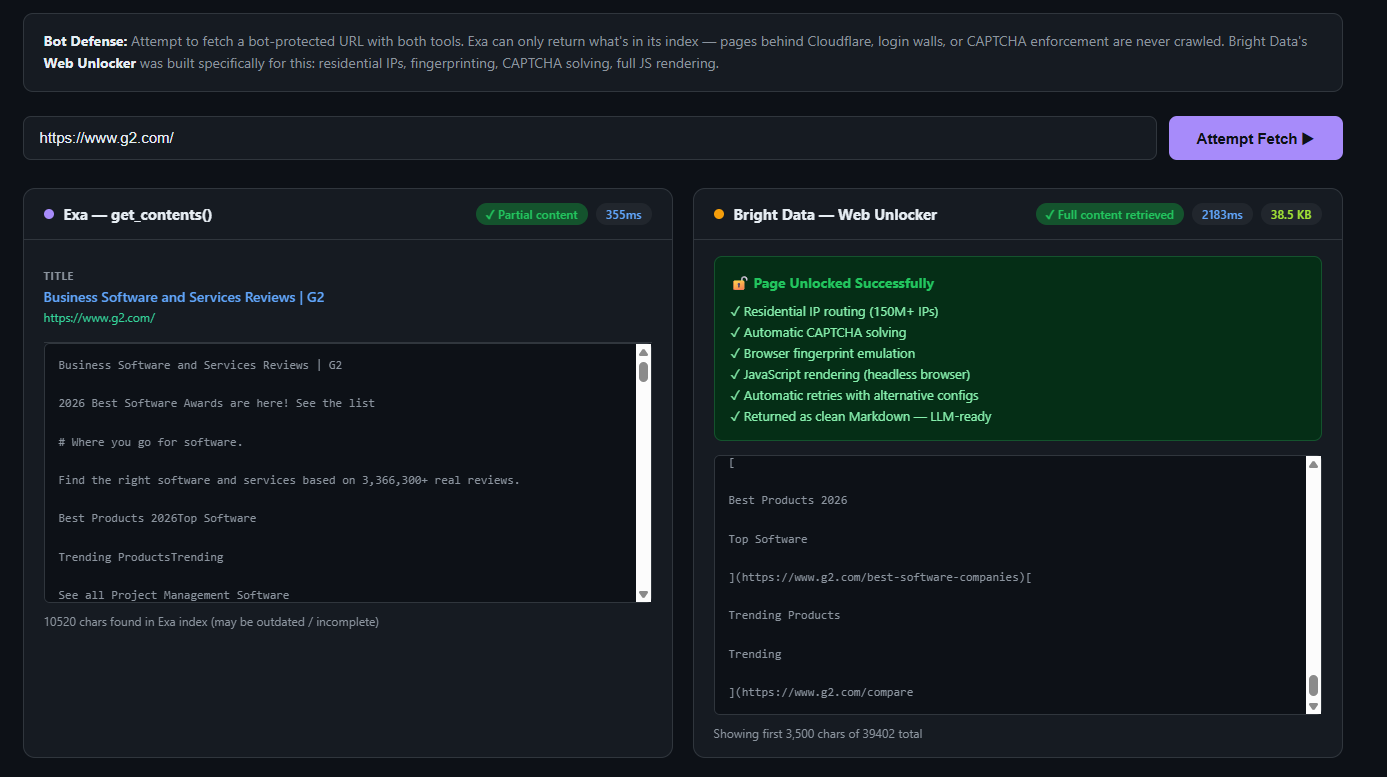
ご自身で試してみたい場合は、GitHub上のこのデモをご覧ください。
Exaには履歴データレイヤーがない
価格変動、方針転換、または市場の動きを検知するAIエージェントには、動作の基準となるベースラインが必要です。正常な状態がどのようなものかを知らなければ、何かを異常としてラベル付けすることはできません。
Exaはリアルタイムデータのみを扱います。アーカイブ製品も、履歴データセットも、時系列分析機能も備えていません。
Bright DataのWeb Archive APIは50PB以上の過去のWebデータを保有しており、日々増加しています。 あらかじめ構築された構造化データセットは100以上のドメインを網羅し、eコマース、ソーシャルメディア、不動産などの分野における過去の基準値を提供します。競合他社の価格ページが12ヶ月間でどのように変化したかを監視したり、規制当局への提出書類の推移を追跡したり、世論の変化を検知したりといった、経時的なインテリジェンス業務において、Bright Dataには必要なインフラが整っていますが、Exaにはそれがありません。
ユースケース決定ガイド
| ユースケース | 最適な選択肢 | 理由 |
|---|---|---|
| RAGプロトタイピング/ハッカソン | Exa | 高速、無料プラン、ネイティブ LangChain、最小限の設定 |
| セマンティック類似検索(「このURLに似たページを探す」) | Exa | 「Find Similar」エンドポイントに相当する機能はBright Dataにはありません |
| 人物/企業のエンリッチメント(採用エージェント、営業インテリジェンス) | Exa | 10億件以上のインデックス化されたプロフィール、構造化された企業インデックス |
| 競争力のある価格インテリジェンス(ライブページコンテンツ) | Bright Data | Web Unlockerはアンチボット対策を回避可能;Exaは保護されたページにアクセスできない |
| 1,000件以上の同時クエリに対応した本番環境向けエージェント | Bright Data | レート制限の上限なし;並列ワークロード向けに構築されたSERP API |
| 本物のGoogle SERPデータ(SEO、広告モニタリング、順位追跡) | Bright Data | SERP APIは実際のGoogleからデータを取得、Exaは独自のインデックスを使用 |
| 過去の基準値/異常検知 | Bright Data | Web Archive 50PB以上、データセット、時系列分析機能 |
| Cloudflareの背後にあるページ/ログインが必要なページ | Bright Data | Web Unlocker;Exaは保護されたコンテンツにアクセスできません |
| マルチエンジン検索(Google + Bing + Yandex) | Bright Data | SERP APIは195カ国にわたる主要7検索エンジンを網羅 |
| 低遅延のインタラクティブチャットUX | Exa | Exa Instantは200ms未満を実現 |
| 大量利用時(月間10万クエリ以上)のコスト効率に優れています | Bright Data | 1,000件あたり1~1.50ドル 対 Exaの1,000件あたり7~15ドル |
Exaを選ぶべき場合
Exaが適しているのは、次のような場合です:
- プロトタイプを構築している、または初期段階の調査を行っている場合。月間1,000件の無料リクエスト、LangChain/LlamaIndexのネイティブサポート、そしてシンプルなSDK導入により、ExaはAIエージェントにウェブ検索機能を追加する際の障壁が最も低い選択肢となります。
- 主なユースケースがセマンティック類似性である場合。「このURLのようなページを探して」という機能はExa独自です。これが主な検索パターンであれば、Exaを選択してください。
- 構造化された人物や企業データが必要な場合。Exaの10億件以上のプロフィールインデックスと7,000万件以上の企業インデックスは、営業や採用インテリジェンスエージェントのために真に最適化されています。
- レイテンシーが最大の制約となる場合。Exa Instantによる200ms未満の応答速度は、リアルタイムの対話型アプリケーションにおいて、あらゆるライブスクレイピングソリューションを上回ります。
- 月間クエリ数が5万~10万件未満であり、Googleの実際のデータや保護されたページへのアクセスが必要ない場合。
Bright Dataを選ぶべき場合
次のような場合には、Bright Dataが最適なツールです:
- 本番環境規模で運用している場合。無制限の同時リクエストと99.9%の稼働率SLAにより、レート制限に対する技術的な回避策が不要です。
- 実際のGoogle検索結果が必要な場合。SERP APIは、あらゆる国でリアルタイムに実際のGoogle(およびBing、Yandex、Baidu、Yahoo、Naver、DuckDuckGo)をスクレイピングし、ニューラルインデックスによる推定ではなく、実際のユーザーが見ているものを表示します。
- エージェントが保護されたページにアクセスする必要がある場合。Web UnlockerはCloudflare、CAPTCHA、ログインページ、JavaScriptレンダリングに対応しています。Exaでは対応できません。
- 過去のデータが必要です。Web Archive APIは、ベースラインの確立や経時的な分析のために50PB以上の過去のデータを提供します。
- 大規模な運用におけるコストも重要な要素です。月間10万件以上のリクエストにおいて、Bright DataはExaよりも5~7倍安価です。
- エンタープライズグレードのシステムを構築しているはずです。2万社以上の顧客、フォーチュン500企業での採用、ガートナーによる評価、70以上のAIフレームワークとの統合実績は、Bright Dataが既存のエンタープライズデータスタックに適合することを意味します。
結論:異なる用途に対応する2つの異なるツール
ExaとBright Dataは、同じ用途で競合しているわけではありません。
Exaは、その設計目的であるセマンティックニューラル検索、開発者の迅速なオンボーディング、個人や企業に特化したインデックスにおいて卓越しています。概念的に類似したページを見つけたり、セマンティックな近傍を探索したり、10億件のLinkedInプロフィールを検索したりする必要がある場合、Exaのアーキテクチャはそれらのタスクに最適です。
一方、Bright Dataは異なる課題群に対応するために構築されています。それは、クローラーをブロックするウェブ上の領域を含め、本番環境規模でライブウェブの「グラウンド・トゥルース(真実)」にアクセスすることです。SERP APIは、同時リクエスト数の上限なしで、1,000件あたり1.50ドルで実際のGoogle検索結果を提供します。Web Unlockerは、Exaのクローラーが到達できないページにアクセスします。Web Archiveは、ライブデータのみを提供するAPIでは得られない、過去のデータという基準線を提供します。
判断の指針は以下の通りです:
- エージェントが意味的に類似したページを検索する必要がある場合、10億件以上のプロファイルを検索する必要がある場合、または200ミリ秒以内に回答を返す必要がある場合は、Exaが最適です。
- エージェントに本番環境レベルのスケール、実際のGoogleデータ、ボット対策アクセス、履歴ベースライン、または月間10万クエリを超えるコスト効率が求められる場合は、Bright Dataが最適なインフラです。
多くの本番環境AIチームは両方を併用しています。パイプラインの初期段階での意味的発見にはExaを、大規模なライブ検証、フルページ抽出、SERPインテリジェンスにはBright Dataを使用しています。これらは互いに排他的ではありません。単に上限が異なるだけであり、エンタープライズ規模では、Exaの上限がすぐに明らかになります。AIワークフロー向けの主要MCPサーバーを幅広く評価しているチームにとって、Bright DataのMCPサーバーは、エージェントをリアルタイムのWebデータに結びつけるための最有力な選択肢として常に上位にランクインしています。
よくある質問
Bright DataとExaの違いは何ですか?
Exaはセマンティック検索エンジンAPIであり、独自のニューラルインデックスから結果を返します。Bright DataはWebデータインフラストラクチャであり、実際の検索エンジンをスクレイピングし、ボット対策の背後にあるページを抽出し、履歴データセットを提供します。これらは異なる規模で異なる問題を解決します。
Bright DataはExaより安価ですか?
はい。Bright DataのSERP APIは、従量課金制で1,000リクエストあたり1.50ドルから利用可能です。Exaの標準検索は1,000リクエストあたり7ドルです。月間100万リクエストの場合、Bright Dataは約5~7倍安くなります。
ExaはCloudflareで保護されたウェブサイトをクロールできますか?
いいえ。Exaは、Cloudflare、ログイン画面、またはCAPTCHAシステムで保護されたページをクロールできません。Bright DataのWeb Unlockerは、1億5,000万以上のレジデンシャルIPからなるネットワークを活用し、ボット対策機能を回避するために特別に構築されています。
Exaにはレート制限がありますか?
はい。Exaのデフォルトの/searchリクエスト制限は10 QPS(分あたり600リクエスト)です。エンタープライズ顧客は、より高い制限について交渉可能です。Bright DataのSERP APIには同時リクエスト制限がありません。
エンタープライズ向けAIエージェントにとって最適なExaの代替ソリューションは何ですか?
Bright Dataは、Exaに代わる主要なエンタープライズ向けソリューションです。無制限の同時リクエスト、Google/Bing/Yandexのリアルタイムウェブスクレイピング、Web Unlockerによるボット対策の回避、履歴データアーカイブ、MCPベースのAIエージェントワークフローへの対応を提供しており、すべて成功報酬型(Pay-per-success)の料金体系となっています。
Exaには履歴データがありますか?
いいえ。Exaはライブデータのみを提供しており、アーカイブやデータセット製品はありません。Bright DataのWeb Archive APIは50PB以上の過去のWebデータを保有しており、日々増加しています。




