

この記事では以下を学びます:
- Azure Synapse Analyticsの概要と提供機能
- Azure Synapse AnalyticsでBright DataのSERP APIを統合する戦略的優位性
- Bright DataのSERP APIを使用してウェブ検索データを収集・変換・分析するAzure Synapseパイプラインの構築方法。
それでは始めましょう!
Azure Synapse Analyticsとは?
Azure Synapse Analyticsは、データ統合、エンタープライズデータウェアハウジング、ビッグデータ処理を単一のワークスペースに統合したクラウドベースの分析プラットフォームです。パイプラインオーケストレーション、Apache Sparkプール、専用SQLプールとサーバーレスSQLプールの両方を提供し、単一の統合環境から大規模なデータの取り込み、変換、クエリを可能にします。
その主な目的は、生データからビジネスインサイトへの転換を支援することです。これは、データ取り込み用のパイプラインエンジン(Azure Data Factory上に構築)、コードベースの変換用Apache Sparkノートブック、クエリおよび分析対応データセットをダッシュボード、機械学習モデル、下流アプリケーションに提供するSQLプールを組み合わせることで実現されます。
Azure Synapse Analytics と Azure AI Foundry の違いとは?
SERP APIとAzure AI Foundryの統合ガイドを既にご覧になった方は、Synapse Analyticsとの違いについて疑問に思われるかもしれません。両者は根本的に異なる目的を果たします:
- Azure AI Foundryは、AIアプリケーション、エージェント、プロンプトフローの構築・デプロイ・管理に特化した統合AI開発プラットフォームです。Azure OpenAI、Meta、MistralなどからのLLMカタログへのアクセスを提供し、プロンプトエンジニアリング、モデルの微調整、RAGワークフローを含むAIファースト開発向けに設計されています。
- Azure Synapse Analyticsは、大量データの取り込み、複雑な変換の実行、大規模な構造化分析の提供に焦点を当てたデータ分析・ウェアハウジングプラットフォームです。ETL/ELTパイプライン、Sparkによるビッグデータ処理、SQLベースのビジネスインテリジェンスに優れています。
要するに、Azure AI FoundryはAI駆動アプリケーションとプロンプトフローを構築する場であり、Azure Synapse Analyticsは分析とレポートのためのデータ収集・変換・倉庫化を行うデータパイプラインを構築する場です。
両者は実に完璧に補完し合います。Synapseでデータ基盤を構築し、ウェブデータを大規模に収集・倉庫化した後、その精選されたデータをAI Foundryに供給してLLMを活用した分析を行うことが可能です。このチュートリアルでは、Synapse AnalyticsがBright DataのSERP APIと統合され、検索結果を収集しSparkで変換し、SQL経由で分析を提供する完全なウェブデータパイプラインを構築する方法を紹介します。
Bright DataのSERP APIをAzure Synapse Analyticsに統合する理由
Azure Synapse Analyticsのパイプラインエンジンには強力なRESTコネクタが備わっており、任意のREST APIを呼び出して結果を直接Azure Data Lake Storageに保存できます。これにより、外部データソースを分析ワークフローに取り込むことが可能になります。しかし、データウェアハウスにリアルタイムのウェブ検索データを注入するには、信頼性が高くスケーラブルな構造化データソースが必要です。
そこでBrightDataのSERP APIが活躍します。SERP APIはGoogle、Bing、DuckDuckGo、Yandexなどの検索エンジンでクエリをプログラム的に検索し、完全なSERPコンテンツを取得できます。パース済みJSON、生のHTML、AI対応Markdownなど複数の形式でデータを返すため、信頼性の高い最新かつ検証可能なデータソースを提供します。
このアプローチは特に以下に有用です:
- SEOキーワード追跡パイプライン:数千のキーワードにおける検索順位を毎日監視し、時間の経過に伴う傾向を特定します。
- 競合情報倉庫:競合他社の可視性データを収集し、内部指標と結合して戦略的分析を行う。
- 業界・地域・期間を横断した検索結果トレンドを集約し、大規模レポート作成に活用する市場調査データセット。
- コンテンツパフォーマンス分析:ターゲットキーワードにおけるコンテンツの順位を追跡し、SEO施策の効果を測定します。
Azure Synapseのパイプラインオーケストレーションとデータウェアハウジング機能にBright DataのSERP APIを組み合わせることで、スクレイピングインフラを一切維持することなく、ウェブ検索データを大規模に継続的に収集・変換・分析するデータパイプラインを構築できます。
Bright Dataを使用したAzure SynapseにおけるSERPデータパイプラインの構築方法
このガイドセクションでは、毎日のキーワード順位トラッカーの一部として、Bright DataのSERP APIをAzure Synapseパイプラインに統合する方法をご紹介します。このパイプラインは主に5つのステップで構成されています:
- ワークスペース設定:リンクされたData Lake Storageアカウントを持つAzure Synapseワークスペースを作成します。
- データソース設定:セキュアな認証情報ストレージを備えた、Bright DataのSERP APIを指すRESTリンクサービスを作成します。
- 取り込みパイプライン:Synapseパイプラインが追跡対象キーワード群のSERP APIを呼び出し、生のJSON結果をデータレイクに格納します。
- Spark変換: Apache Sparkノートブックが生のSERPデータを平坦化・正規化し、分析可能なDeltaテーブルに変換します。
- SQL分析: サーバーレスSQLクエリでランキング動向を分析し、Power BIダッシュボード用のビューを作成します。
注:これは一例に過ぎず、SERP APIは他にも多くのシナリオやユースケースで活用できます。例えば、価格監視のパイプライン構築や、機械学習モデルへのSERPデータ供給なども可能です。
以下の手順に従い、Azure Synapse Analytics内でBright DataのSERP APIを活用したWebデータパイプラインを構築しましょう!
前提条件
このチュートリアルセクションを実践するには、以下の環境が整っていることを確認してください:
- Microsoftアカウント
- Azure サブスクリプション(無料トライアルでも可)。
- 有効なSERP APIゾーンとAPIキー(管理者権限付き)を持つBright Dataアカウント。
公式のBright Dataドキュメントに従って、SERP APIゾーンを設定し、APIキーを取得してください。APIキーとゾーン名はすぐに必要になりますので、安全な場所に保管してください。
ステップ1: Azure Synapseワークスペースの作成
Azure SynapseパイプラインはSynapseワークスペース内でのみ利用可能です。そのため、最初にワークスペースを作成します。
Azureアカウントにログインし、Azureポータル上部の検索バーで「Azure Synapse Analytics」を検索します:
Synapse Analytics管理ページで[作成]をクリックします。作成フォームに入力します:
- Azure サブスクリプションを選択します。
- 既存のリソースグループを選択するか、新規作成します。
- ワークスペースに名前を付けます(例:
bright-data-serp-pipeline)。 - お近くのリージョンを選択します。
- Data Lake Storage Gen2 の場合、[新規作成]を選択し、ストレージ アカウント名を入力します(すべて小文字、3~24 文字、グローバルに一意である必要があります。例:
serppipelinelake)。rawという名前の新しいファイル システムを作成します。
[確認 + 作成]、[作成] の順にクリックしてデプロイを開始します。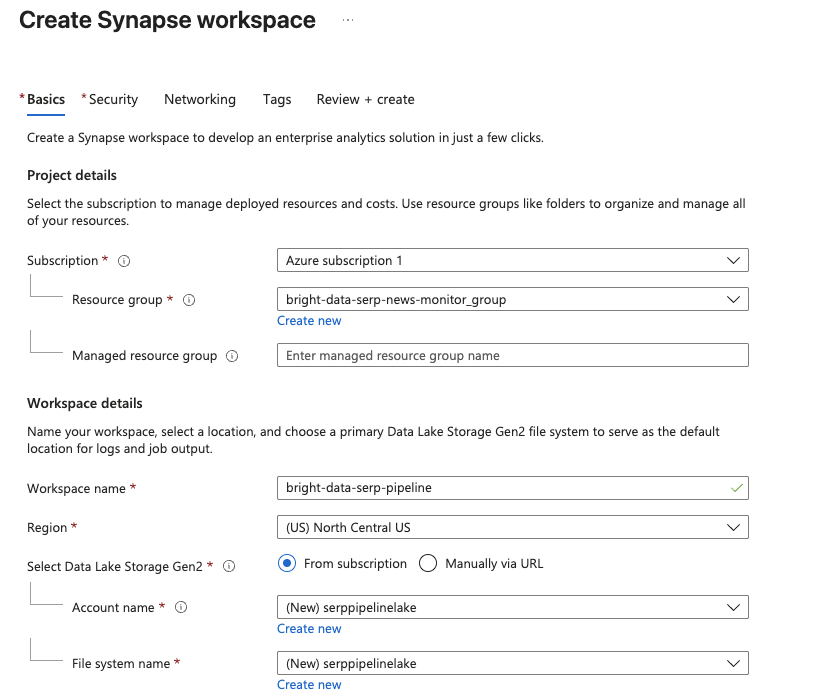
初期化プロセスには数分かかる場合があります。完了すると確認ページが表示されます。「リソースに移動」をクリックし、「Synapse Studioを開く」をクリックしてWebベースの開発環境を起動します。
これでパイプラインの構築、Sparkノートブックの作成、SQLクエリの実行が可能なSynapseワークスペースが利用可能になります。
ステップ 2: Apache Spark プールを作成する
このチュートリアルの後半で変換ノートブックを実行するには、ワークスペースに Apache Spark プールが必要です。
- Synapse Studio で、[管理] > [Apache Spark プール] >[新規] に移動します。
- プールに名前(例:
sparkpool)を付けます。 - ノードサイズを「Small(4 vCores / 32 GB)」に設定します。これは SERP データの変換には十分なサイズです。
- オートスケールを有効にし、範囲を3~5 ノードに設定します。
- [確認 + 作成]、次に [作成] をクリックします。
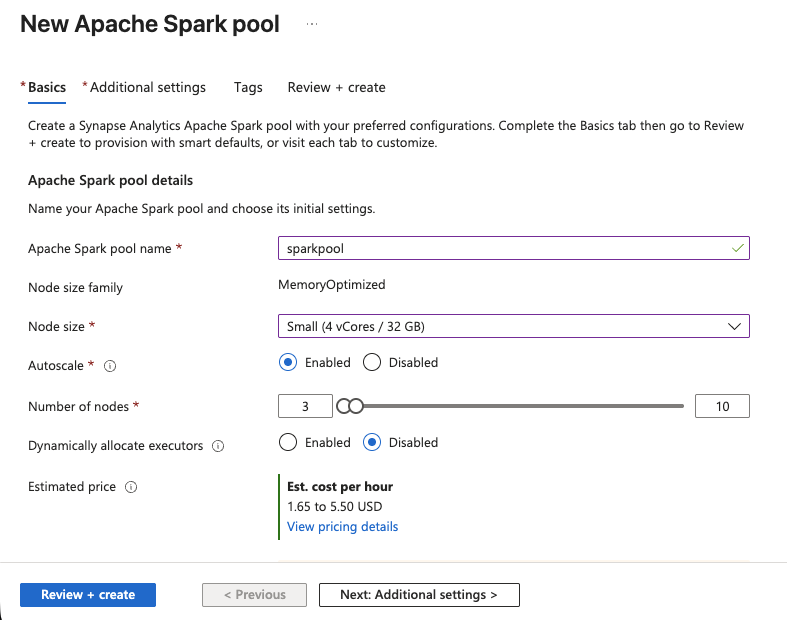
Sparkプールは数分で準備が整います。これでPySparkノートブックを実行するためのコンピューティングリソースが利用可能になります。
ステップ3: 取り込みパイプラインの構築
追跡対象キーワードのセットについて Bright Data の SERP API を呼び出し、結果をデータレイクに保存する Synapse パイプラインを作成します。
新しいパイプラインを作成します
- [統合] >[+]>[パイプライン] に移動します。
IngestSERPDataと名前を付けます。
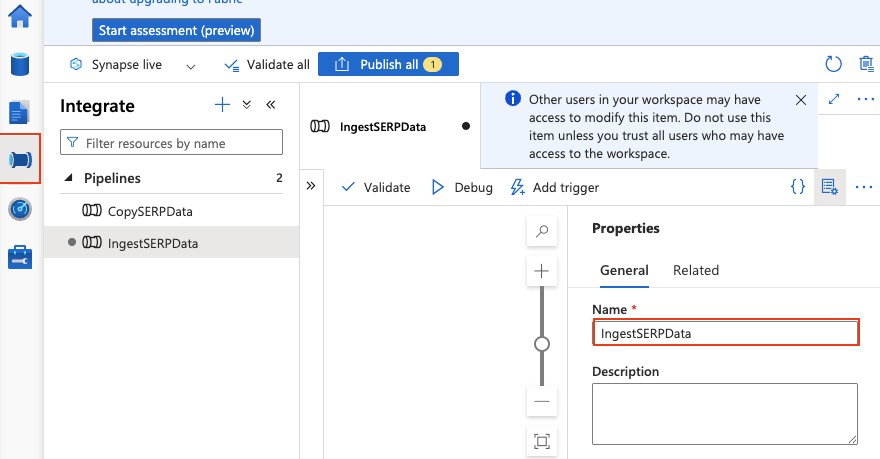
パイプラインパラメータを追加
パイプラインキャンバスの背景をクリックしてパイプラインのプロパティを開きます。「パラメータ」タブに移動し、以下を追加します:
| 名前 | 型 | デフォルト値 |
|---|---|---|
キーワード |
配列 | ["ウェブスクレイピングツール", "プロキシサービス", "データ抽出API"] |
これらは、ランキングを追跡したいキーワードです。このリストはいつでも変更できます。
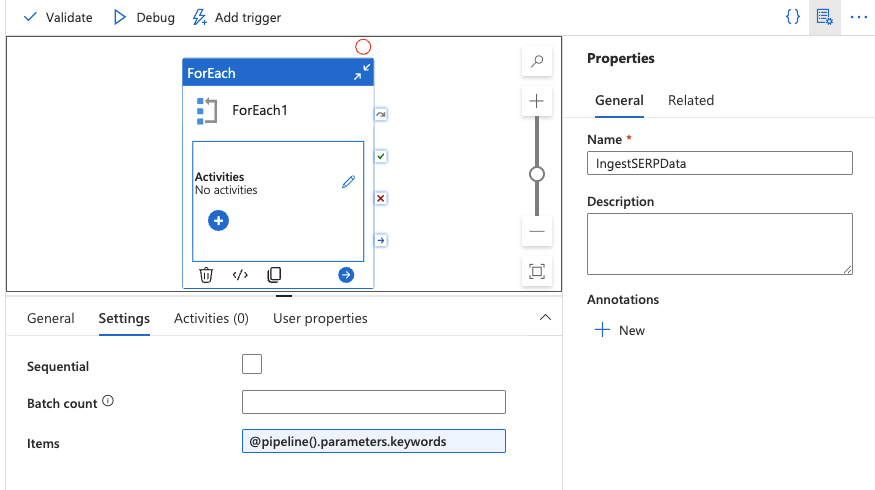
ForEachアクティビティを追加
- アクティビティパネルからForEachアクティビティをキャンバスにドラッグします。
- 設定タブで、[項目] フィールドを次のように設定します:
@pipeline().parameters.keywords
これにより配列内の各キーワードが反復処理されます。
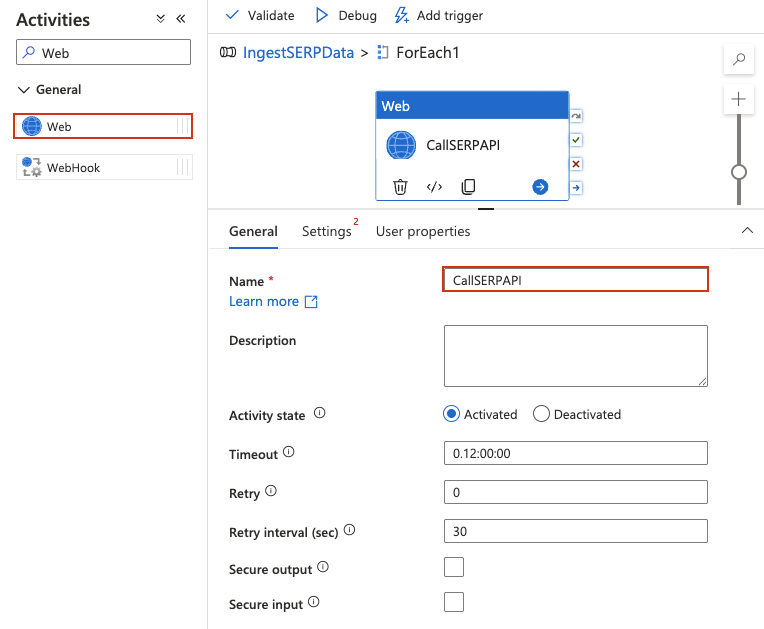
ForEach内部にWebアクティビティを追加
WebアクティビティはREST APIを直接呼び出します。リクエスト自体にデータセットやリンクされたサービスは不要です。
- ForEach アクティビティをダブルクリックして内部キャンバスを開きます。デザイナーのヘッダーが ForEach スコープ内であることを示すように変更されるはずです(パンくずリスト形式の
IngestSERPData > ForEach1)。 - 左側の [アクティビティ] パネルで、[一般] を展開し、Webアクティビティを内部キャンバスにドラッグします。
CallSERPAPIなどの名前を付けます。
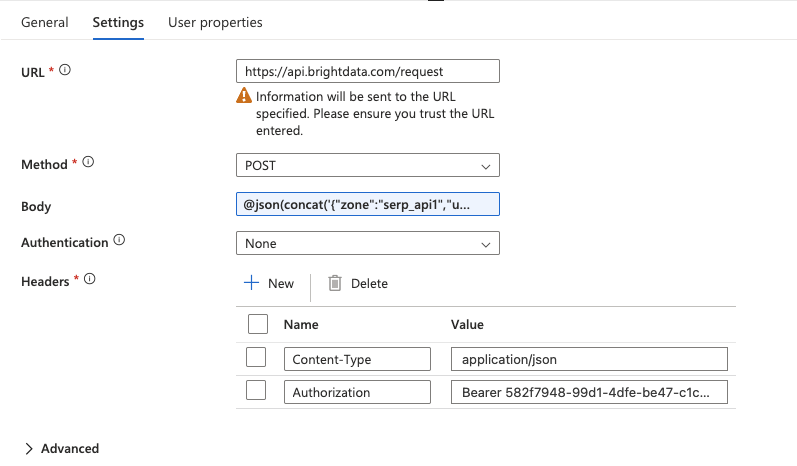
Webアクティビティの設定
Webアクティビティをクリックして選択し、[設定]タブで以下を設定します:
- URL: フィールドに完全なAPIエンドポイントを直接入力します:
https://api.brightdata.com/request- メソッド: ドロップダウンから「
POST」を選択します。 - ヘッダー: 「+ ヘッダーを追加」を2回クリックして以下を追加:名前 値
Content-Typeapplication/jsonAuthorizationBearer YOUR_BRIGHT_DATA_API_KEY - Body: ここでは、ForEachループから取得した現在のキーワードを含むSERP APIリクエストを渡します。Bodyフィールドに直接以下の式を入力してください(「動的コンテンツを追加」ポップアップは使用しないでください):
@concat('{"ゾーン":"YOUR_SERP_API_ゾーン","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')YOUR_SERP_API_ZONE をBright Data ダッシュボードの実際のゾーン名に置き換えてください。
重要:フィールドの先頭文字は必ず
「@」とし、先頭にスペースを入れないでください。これによりSynapseはテキストを式として評価します。正しく入力されると、フィールド内で式がハイライト表示されます。プレーンテキストとして表示される場合は、@が位置0にあることを確認し、削除して再入力してください。動作説明:
item()関数はForEachループから現在のキーワード(例:"ウェブスクレイピングツール")を返します。replace()関数はスペースを+文字に置換し、有効なURLクエリパラメータを形成します。concat()関数は完全なJSONリクエストボディを単一の文字列として構築します。
- 認証:
Noneに設定(認証は既に Authorization ヘッダー経由で処理済み)。
スケジュールトリガーを追加
- メインのパイプラインキャンバスに戻り、[トリガーの追加] > [新規/編集]をクリックします。
- [新規]を選択し、毎日繰り返し(例:UTC 6:00 AM)を設定します。
- [OK] をクリックし、[すべて公開] をクリックしてパイプラインを保存およびデプロイします。
すぐにテストするには、[今すぐトリガー]>[OK] をクリックします。[監視] >[パイプラインの実行] に移動して実行を確認します。パイプラインが成功し、データレイクのraw/serp/パス下に JSON ファイルが存在するはずです。
メインパイプラインキャンバスに戻る
デザイナー上部のブレッドクラムにあるパイプライン名(IngestSERPData)をクリックしてメインキャンバスに戻ります。ForEachアクティビティに子アクティビティが含まれていることを示すインジケーターが表示されているはずです。
スケジュールトリガーの追加
- パイプラインデザイナー上部で [トリガーの追加] > [新規/編集] をクリックします。
- ドロップダウンから [新規] を選択します。
- トリガーに名前を付け(例:
DailySERPTrigger)、タイプをスケジュールに設定し、以下を構成します:
- 開始日: 今日の日付
- 繰り返し間隔:毎日
- 時刻:
6(UTC 6:00 AM)
- [OK]をクリックし、トリガーのパラメータを確認します。
- Synapse Studioの上部にある「すべて公開」をクリックして、すべてを保存およびデプロイします。
パイプラインをテストする
スケジュールされたトリガーを待たずにパイプラインを即時実行するには:
- パイプラインデザイナー上部の[今すぐトリガー]>[OK]をクリックします。
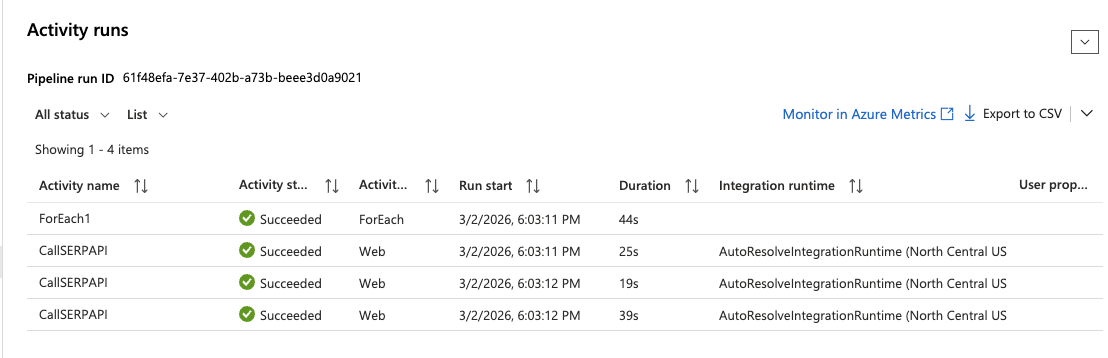
- 左メニューで [Monitor] >[Pipeline runs] に移動します。
- 実行が完了するまで待ちます。緑色の「成功」ステータスが表示されるはずです。
- 実行をクリックし、ForEachアクティビティを展開して各Webアクティビティの実行を確認します。任意の
CallSERPAPI反復をクリックすると、出力セクションにAPIレスポンス全体が表示されます。
ステップ4: Apache Sparkによるデータ収集と変換
ステップ3のWebアクティビティでは、SERP APIの統合が機能することと、スケジューリングによるパイプラインのオーケストレーションが実証されました。データ収集と変換のステップでは、Pythonを使用してSERP APIを直接呼び出し、生のレスポンスをデータレイクに保存し、分析可能なDeltaテーブルに変換するApache Sparkノートブックを使用します。
このアプローチはデータエンジニアリングの標準です。パイプラインがオーケストレーションとスケジューリングを担当し、ノートブックが実際のデータ処理ロジックを担当します。
Sparkノートブックの作成
- [開発]>[+]> [ノートブック] に移動します。
- 名前を
TransformSERPDataとします。 sparkpoolApache Spark プールにアタッチします。- 言語としてPySpark (Python)が選択されていることを確認します。
セル1: SERPデータを収集しデータレイクに保存
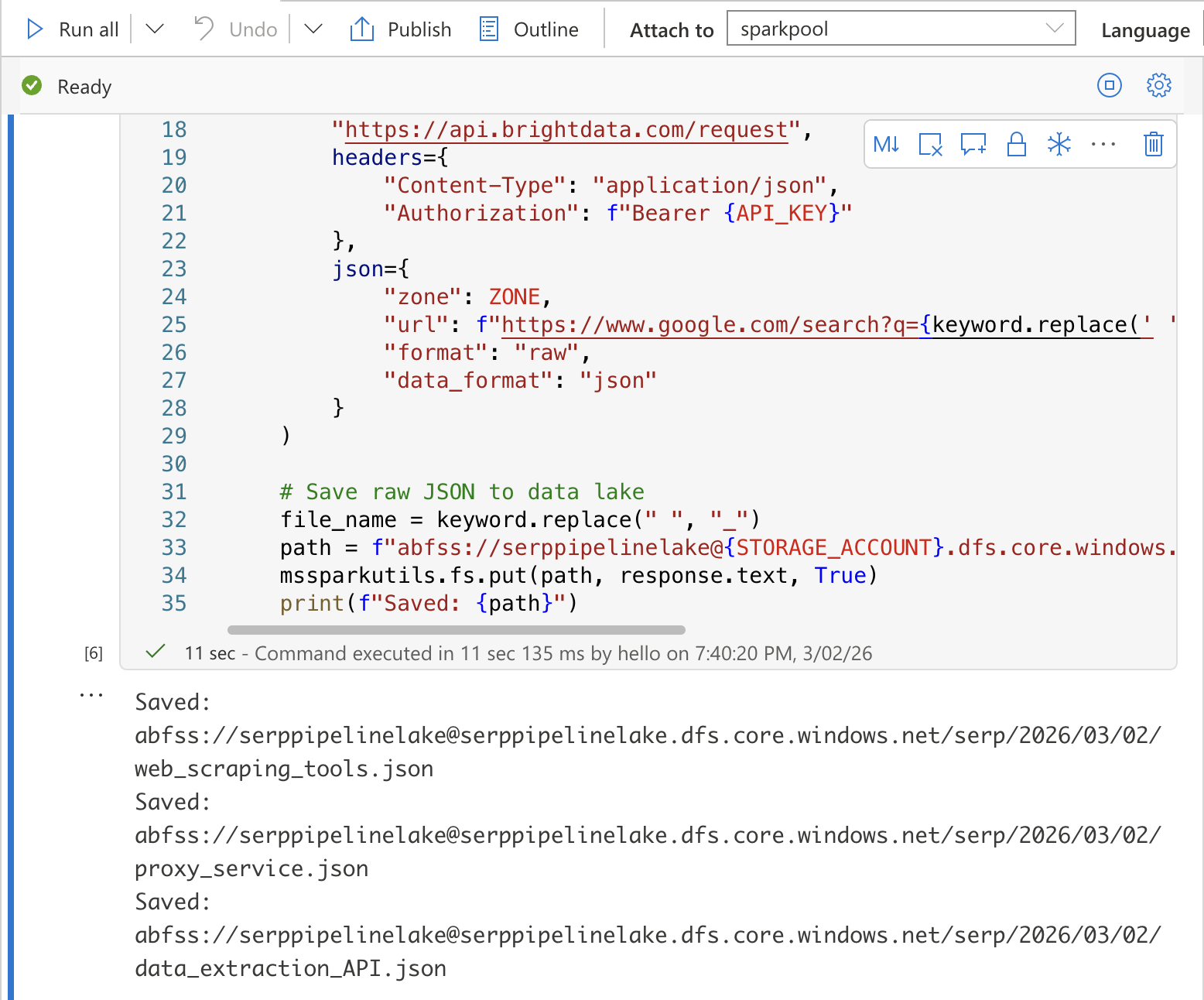
最初のセルに以下のコードを追加します。各キーワードに対してBright Data SERP APIを呼び出し、生のJSONレスポンスをデータレイクに保存します:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# 設定
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
ZONE = "YOUR_SERP_API_ZONE"
STORAGE_ACCOUNT = "YOUR_STORAGE_ACCOUNT"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# 各キーワードのSERPデータを収集
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Bright Data SERP APIを呼び出す
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"ゾーン": ZONE,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# 生JSONをデータレイクに保存
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"保存済み: {path}")YOUR_BRIGHT_DATA_API_KEY、YOUR_SERP_API_ZONE、YOUR_STORAGE_ACCOUNTは実際の値に置き換えてください。
セキュリティ上の注意点: 本番環境では、APIキーをAzure Key Vaultに保管し、
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")を使用して取得してください。ハードコーディングは避けてください。
Shift + Enter を押してセルを実行します。各ファイルがデータレイクに保存されたことを確認する出力が表示されるはずです。
セル2: SERPデータの変換とフラット化
新しいセルに、生のJSONを読み込み構造化されたテーブルに平坦化する変換コードを追加します:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# データレイクから生のSERPデータを読み込み
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# フラット化: general.queryからキーワードを抽出し、オーガニック結果を爆発処理
serプ_フラット化 = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
# プレビューを表示
display(serp_flattened)セルを実行してください。キーワード、順位、タイトル、URL、スニペット、収集時刻の列を持つ、平坦化されたSERP結果のプレビューテーブルが表示されるはずです。
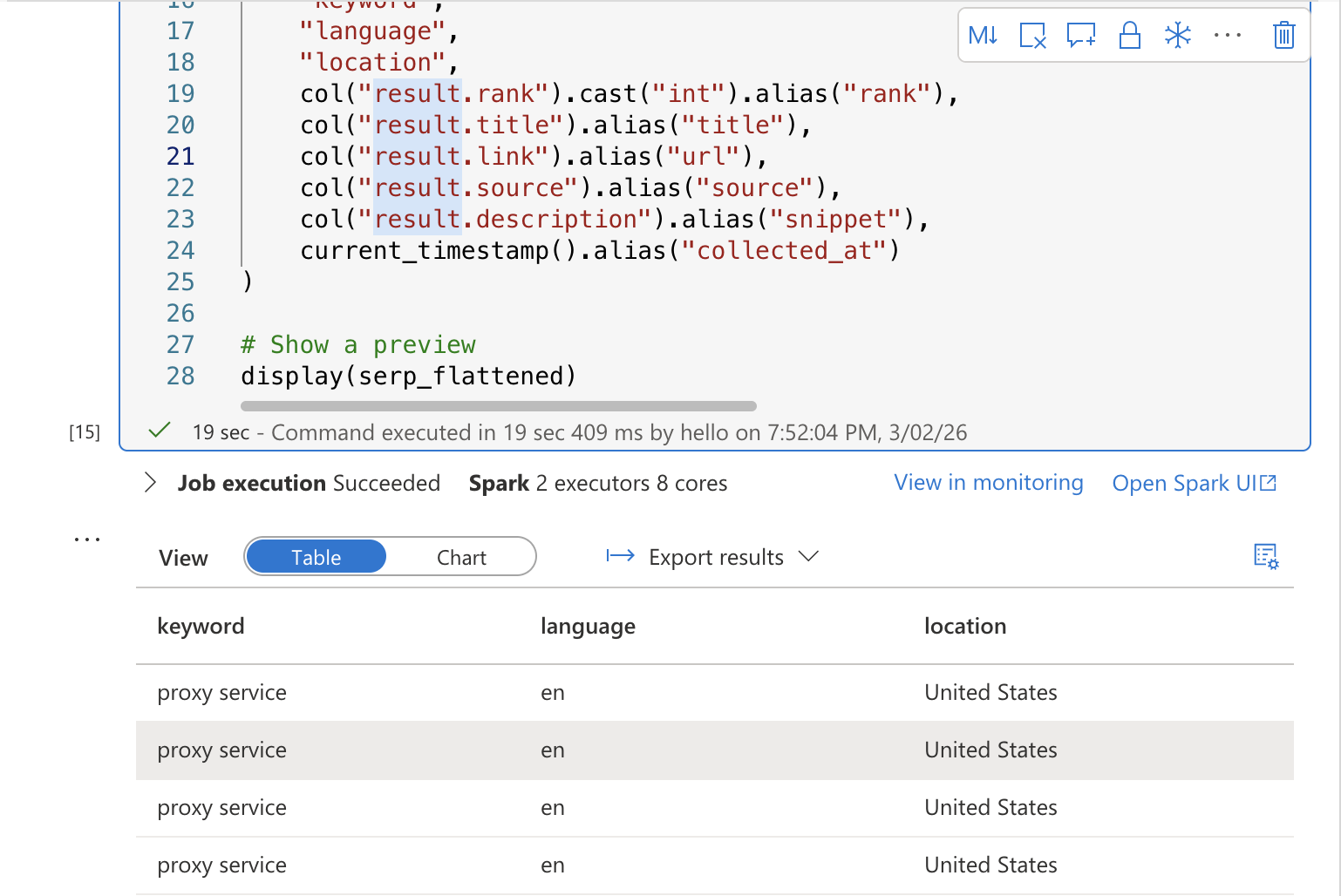
セル3: Deltaテーブルへの保存
3つ目のセルで、変換したデータをSQL分析用にDeltaテーブルに書き込みます:
# 変換済みデータをデルタテーブルとしてデータレイクに書き込み
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("curated/serp_rankings にデータが書き込まれました") 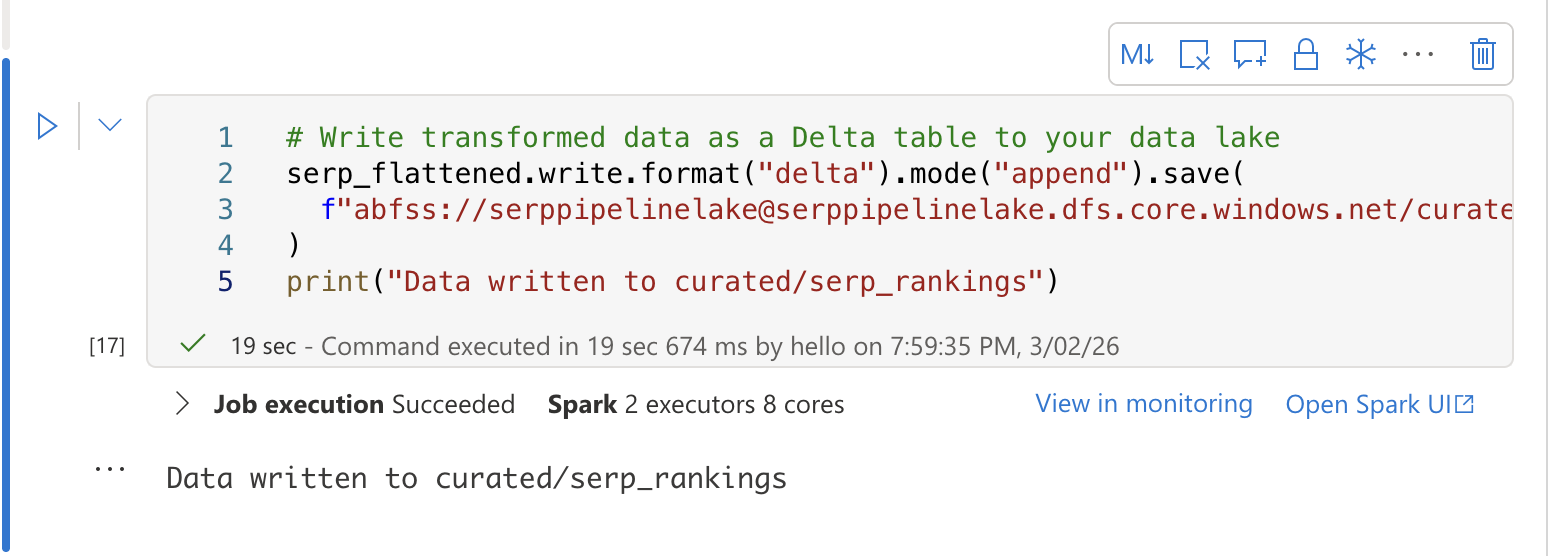
ノートブックをパイプラインに追加
- IntegrateハブのIngestSERPDataパイプラインに戻
ります。 - キャンバス上にノートブックアクティビティをドラッグし、ForEachアクティビティの外側かつ後方に配置します。
- 設定タブで
TransformSERPDataノートブックを選択し、sparkpoolに接続します。 - ForEachアクティビティとNotebookアクティビティを成功依存関係(緑の矢印をドラッグ)で接続します。
- すべてを公開をクリックして保存します。
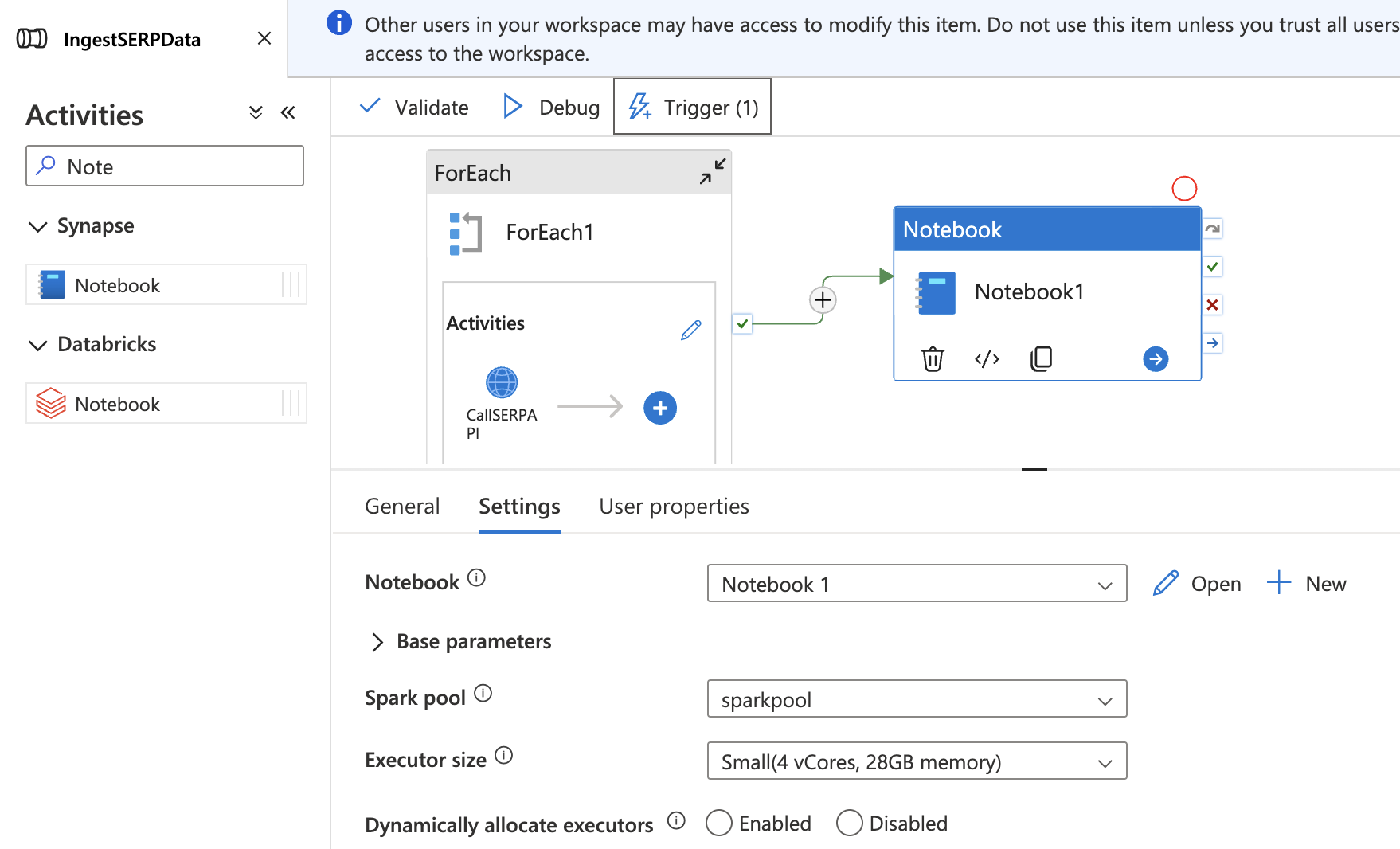
これでパイプライン全体がエンドツーエンドで実行されます:SERPデータを収集 → データレイクに格納 → Deltaテーブルに変換。
ステップ5: SQLでランキングを分析
データが Delta テーブルに格納されたら、Synapseのサーバーレス SQL プールを使用して直接クエリを実行できます。追加のプロビジョニングは不要です。サーバーレス SQL プールは、OPENROWSET関数を使用してデータレイクから Delta ファイルを直接読み取ります。
データベースを作成
[開発] >[+]>[SQLスクリプト] に移動します。スクリプトエディタ上部のSQLプールで「組み込み(サーバーレス)」が選択されていることを確認してください。以下のコマンドを実行して、SERP分析専用のデータベースを作成します:
CREATE DATABASE serp_analytics;データベース作成後、スクリプトエディタ上部のデータベースドロップダウンから「serp_analytics」を選択して切り替えます。
時間の経過に伴うランキング変化の追跡
新しいSQLスクリプトを作成(または既存のスクリプトをクリア)し、以下のクエリを実行します。これはOPENROWSETを使用してデータレイクから直接Deltaテーブルを読み込みます:
-- 各キーワードとURLの順位が日ごとにどう変動するかを確認
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = 'ウェブスクレイピングツール'
ORDER BY collected_at DESC, rank ASC;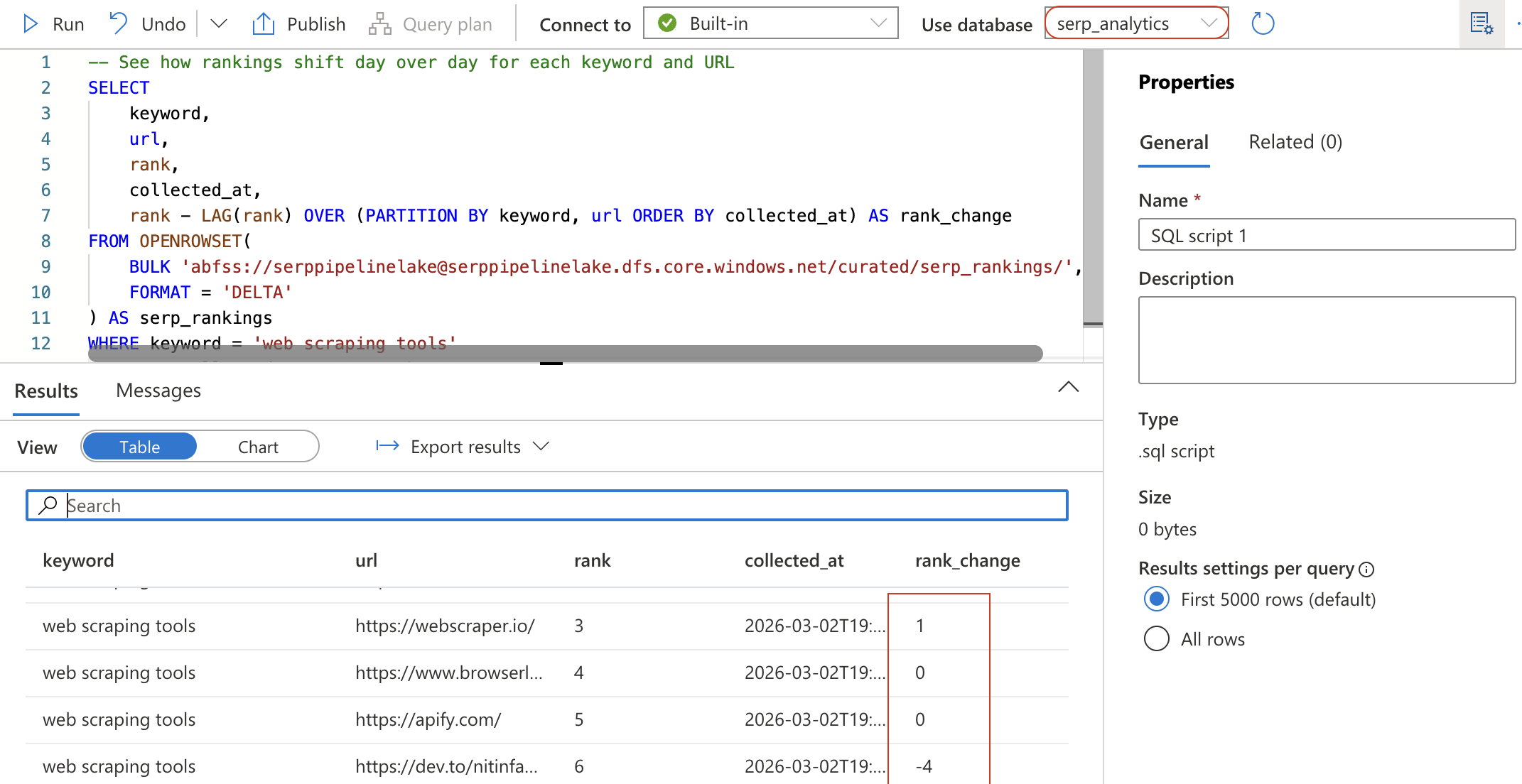
このクエリはLAGウィンドウ関数を使用し、前回の収集以降に各URLの順位がどのように変化したかを算出します。rank_changeが負の値の場合、そのURLは順位を上げたことを意味します。
Power BI 用のサマリービューを作成する
Power BIでデータを容易に利用できるようにするため、キーワードごとの日次ランキングを要約するビューを作成します:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
GROUP BY keyword, CAST(collected_at AS DATE);実行をクリックします。これによりビュー(名前で参照可能な保存済みクエリ)が作成されます。動作を確認するには以下を実行します:
SELECT * FROM daily_serp_summary;キーワードごとに1日あたり1行が表示され、結果総数、平均順位、最高順位が確認できるはずです。
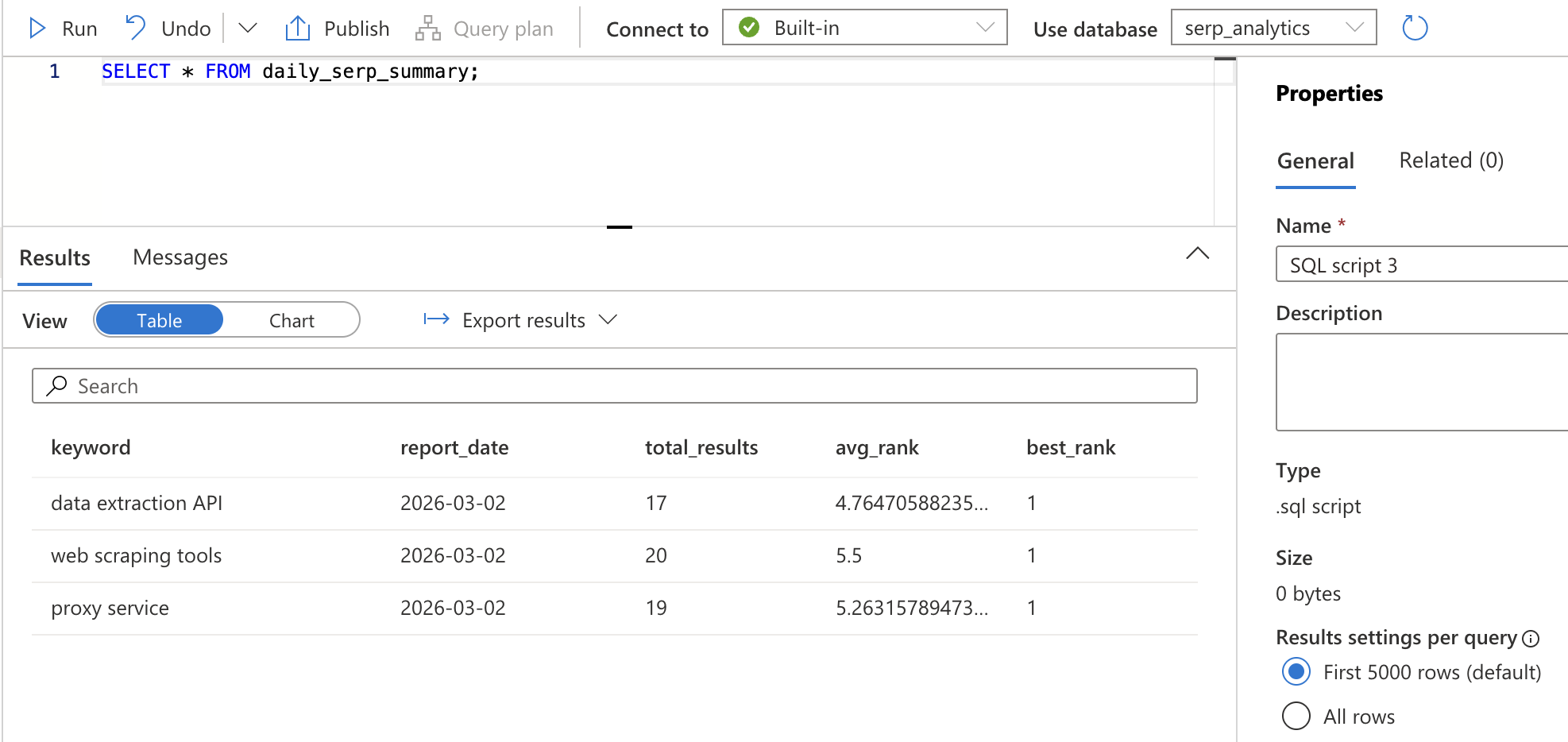
ステップ6: 結果の確認
パイプライン全体が実行された後、Synapse Studioから各ステージを確認できます。
[Monitor] >[Pipeline runs] に移動し、最新の実行をクリックして確認します。各ステップの視覚的表現が表示され、以下が確認できます:
- 各キーワードの反復処理を行うForEachアクティビティと Web アクティビティの結果。
- Sparkジョブの実行詳細を含むNotebookアクティビティ。
ForEachアクティビティを展開し、各キーワードのSERPデータが正常に取得されたことを確認します。任意のCallSERPAPIWebアクティビティの実行をクリックすると、入力セクションと出力セクションでリクエスト/レスポンスの詳細を確認できます。
データ>リンク> ストレージアカウントに移動し、raw/serp/フォルダー内の生のJSONファイルを参照します。日付で分割されたフォルダーが確認でき、キーワードごとに1つのJSONファイルが存在します。
最後に、開発ハブを開き、TransformSERPDataノートブックに移動し、次のクエリを実行してデルタテーブルを確認します:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;キーワード、順位、タイトル、URL、スニペット、収集タイムスタンプを含む構造化された行が表示されます。これは生の SERP 結果から構築された、クリーンで分析準備が整ったデータです。Bright Data の SERP API は、大規模な Google 検索結果の信頼性の高い取得、ボット対策やレートリミッターの回避、パイプラインにすぐに使える構造化データの返却という難しい部分を処理しました。
さらなる応用
この例はキーワード順位トラッカーを示していますが、Synapseパイプラインは様々な方向へ拡張可能です:
- SERP API呼び出しをBright DataのWeb Scraper APIに置き換え、製品価格・レビュー・求人情報などを収集し、競合情報ダッシュボードを構築できます。
- 2つ目のSparkノートブックを追加し、SERPスニペットの感情分析を実行して、各結果を肯定的または否定的な表現でスコアリングします。
- キュレーションされたDeltaテーブルをAzure Machine Learningに接続し、ランキング変動の予測や新興検索トレンドの特定といった予測分析を実行します。
- SERPデータをAzure Data Lakeに保存しつつ、機密性の高い内部データはオンプレミスに保持するハイブリッドクラウドアーキテクチャを構築し、Synapseがフェデレーテッドクエリで両方を照会できるようにします。
- 変換されたデータをAzure AI Foundryのプロンプトフローに転送し、LLMを活用した分析を実行。SynapseのデータエンジニアリングとAI FoundryのAI機能を統合。
- LangChainやCrewAIなどのツールと連携し、キュレーション済みSERPデータを活用するエージェント型ワークフローを構築します。
可能性は事実上無限大です!
まとめ
このブログ記事では、Bright DataのSERP APIを使用してGoogleから最新の検索結果を取得し、Azure Synapse Analytics内の完全なデータパイプラインに統合する方法を学びました。
ここで示したパイプラインは、SERPデータを継続的に収集し、分析可能なテーブルに変換し、SQLクエリやPower BIダッシュボードを通じてインサイトを提供する自動化されたキーワードランキングトラッカーを構築したい方に最適です。AIファーストのプロンプトエンジニアリングやRAGワークフローに理想的なAzure AI Foundryのアプローチとは異なり、Azure Synapse Analyticsはビジネスインテリジェンスや分析のための大規模なデータ取り込み、変換、ウェアハウジングに優れています。
より高度なデータパイプラインを作成するには、ライブWebデータの取得・検証・変換を実現するBright Dataのウェブスクレイピングツール一式をご活用ください。データパイプラインのアーキテクチャパターンに関する詳細な解説は、Bright Dataブログで基礎から解説しています。
今すぐBright Dataの無料アカウントに登録し、AI対応のWebデータソリューションを実際に試してみましょう!






