

このチュートリアルでは、Kotlinによるウェブスクレイピングスクリプトの作成方法を解説します。具体的には以下の内容を学びます:
- サイトスクレイピングにKotlinが最適な理由
- 最適なKotlinスクレイピングライブラリ
- Kotlinスクレイパーをゼロから構築する方法
さあ始めましょう!
Kotlinはウェブスクレイピングに有効な選択肢か?
結論:はい、可能です!Javaよりも優れている可能性すらあります!
Kotlinは静的型付けのクロスプラットフォーム汎用プログラミング言語であり、その標準ライブラリはJavaクラスライブラリに依存しています。Kotlinの特長は、簡潔で楽しいコーディングアプローチにあります。GoogleがAndroid開発の推奨言語として採用している点も特筆すべきでしょう。
JVMとの相互運用性により、すべてのJavaスクレイピングライブラリをサポートします。つまり、Javaライブラリの膨大なエコシステムを活用しつつ、より簡潔で直感的な構文を利用できるのです。まさにWin-Winのシナリオです!
さらにKotlinにはHTMLパーサーやブラウザ自動化ライブラリなど、データ抽出を簡素化するネイティブライブラリが付属しています。代表的なライブラリをいくつかご紹介しましょう!
Kotlin向けベストウェブスクレイピングライブラリ
Kotlin向け主要ウェブスクレイピングライブラリ一覧:
- skrape{it}: HTMLパース・解釈のためのKotlinベースのHTML/XMLテスト・ウェブスクレイピングライブラリ。複数のデータフェッチャーを備え、従来のHTMLパーサーとしてだけでなく、クライアントサイドDOMレンダリング用のヘッドレスブラウザとしても機能します。
- chrome-reactive-kotlin: Chromiumベースのブラウザをプログラムで制御するための、Kotlinで書かれた低レベルDevTools Protocolクライアント。
- ksoup:Jsoupに着想を得た軽量Kotlinライブラリ。HTMLのパース、HTMLタグ・属性・テキストの抽出、HTMLエンティティのエンコード/デコードを行うメソッドを提供します。
KotlinはJavaと相互運用可能であることを忘れないでください。これは、Javaで利用可能な他のウェブスクレイピングライブラリ(最も人気のあるHTMLパーサーの一つであるJsoupなど)も使用できることを意味します。詳細は、Jsoupを使用したウェブスクレイピングガイドをご覧ください。
前提条件
以下の手順に従って、ウェブスクレイピング用のKotlin環境を設定してください。
環境のセットアップ
マシン上でKotlinアプリケーションを記述・実行するには、ローカルにJDK(Java Development Kit)がインストールされている必要があります。Oracleサイトから最新のLTS版JDKをダウンロードし、インストーラーを実行してインストールウィザードに従ってください。執筆時点ではJava 21です。
次に、依存関係を管理しKotlinアプリケーションをビルドするためのツールが必要です。GradleとMavenのどちらも優れた選択肢ですので、お好みのJavaビルドツールを選択できます。GradleはKotlinをDSL(ドメイン特化言語)としてサポートしているため、ここではGradleを採用します。Mavenユーザーでも簡単にチュートリアルを実行できる点に留意してください。
MavenまたはGradleをダウンロードしてインストールしてください。Gradleは特にJavaのバージョンに敏感です。適切なパッケージをダウンロードするようにしてください。Java 21で動作するGradleはバージョン8.5以上です。
最後に、Kotlin IDEが必要です。Visual Studio Code(Kotlin Language拡張機能付き)とIntelliJ IDEA Community Editionは、どちらも優れた無料の選択肢です。
完了!これでKotlin対応環境が整いました!
Kotlinプロジェクトの作成
Kotlinウェブスクレイピングプロジェクト用のプロジェクトフォルダを作成し、ターミナルで以下を入力します:
mkdir KotlinWebScraper
cd KotlinWebScraperここではディレクトリ名をKotlinWebScraperとしましたが、お好きな名前を付けてください
次に、プロジェクトフォルダ内で以下のコマンドを実行し、Gradleアプリケーションを作成します:
gradle init --type kotlin-applicationこの手順ではいくつかの質問が表示されます。ビルドスクリプトDSLには「Kotlin」を選択し、アプリケーションに適切なパッケージ名(例: com.kotlin.スクレイパー)を指定してください。その他の質問についてはデフォルトの回答で問題ありません。
初期化プロセスの終了時に以下のような画面が表示されます:
ビルドスクリプトDSLの選択:
1: Kotlin
2: Groovy
選択を入力 (デフォルト: Kotlin) [1..2] 1
プロジェクト名 (デフォルト: KotlinWebScraper):
ソースパッケージ (デフォルト: kotlinwebscraper): com.kotlin.scraper
Javaのターゲットバージョンを入力 (最小8) (デフォルト: 21):
新しいAPIと動作でビルドを生成しますか(次期マイナーリリースで機能が変更される可能性があります)? (デフォルト: いいえ) [はい, いいえ]
> タスク :init
Gradleの詳細はサンプルで確認できます: https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
BUILD SUCCESSFUL in 2m 10s
実行可能なタスク: 2 件中 2 件が実行されましたすばらしい!KotlinWebScraperフォルダにGradleプロジェクトが生成されました。
Kotlin IDEでフォルダを開き、必要なバックグラウンドタスクが完了するのを待った後、com.kotlin.scraperパッケージ内のメインファイルApp.ktを確認してください。以下のような内容になっているはずです:
/*
* このKotlinソースファイルはGradleの'init'タスクによって生成されました。
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}これは、ターミナルに「Hello World!」を出力するシンプルなKotlinスクリプトです。
動作確認のため、以下の Gradle コマンドでスクリプトを実行してください:
./gradlew runプロジェクトのビルドと実行が完了するまで待ちます。すると以下が表示されます:
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 3s
3 actionable tasks: 2 executed, 1 up-to-dateGradleのログメッセージは無視して構いません。代わりに「Hello World!」メッセージに注目してください。これはスクリプトから期待される出力そのものです。つまり、Kotlin環境は意図した通りに動作しています。
さあ、Kotlinでウェブスクレイピングを始めましょう!
ウェブスクレイピング用Kotlinスクリプトの作成
このステップバイステップのセクションでは、Kotlinでウェブスクレイパーを構築する方法を学びます。特に、Quotesスクレイピングサンドボックスサイトからデータを抽出する自動化されたスクリプトの定義方法を習得します。
大まかに言うと、これからコーディングするKotlinウェブスクレイピングスクリプトは以下を行います:
- 対象ページに接続する。
- ページ上の引用文HTML要素を選択する。
- それらから必要なデータを抽出する。
- サイトの全引用文に対してこの操作を繰り返し、各ページネーションページを訪問する。
- 収集したデータをCSV形式でエクスポートする。
対象サイトは次のようになっています:
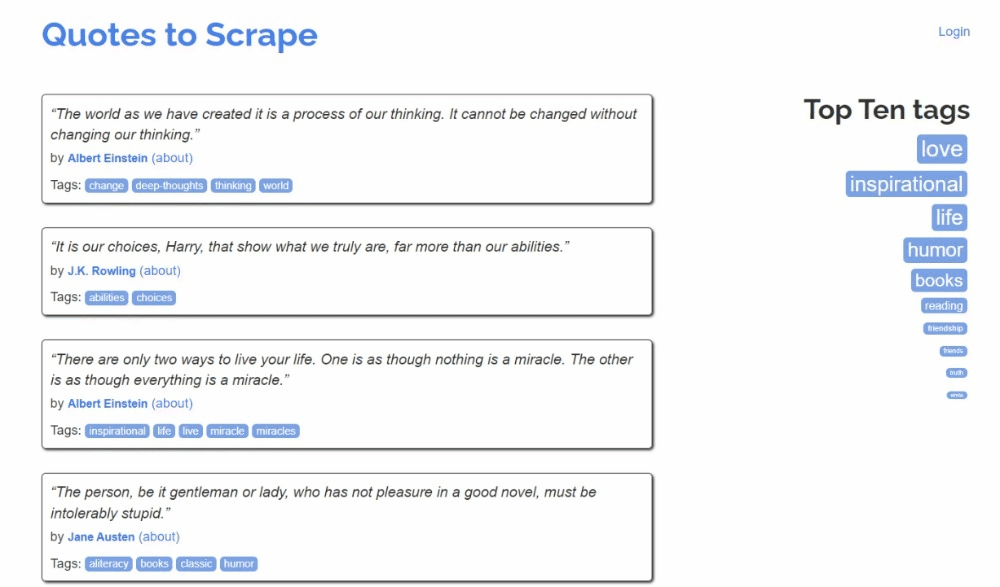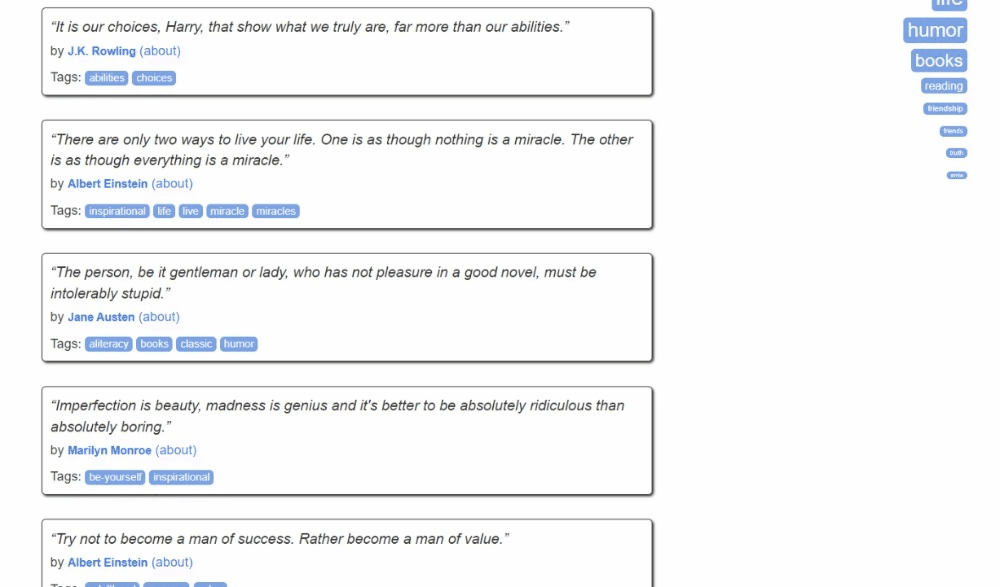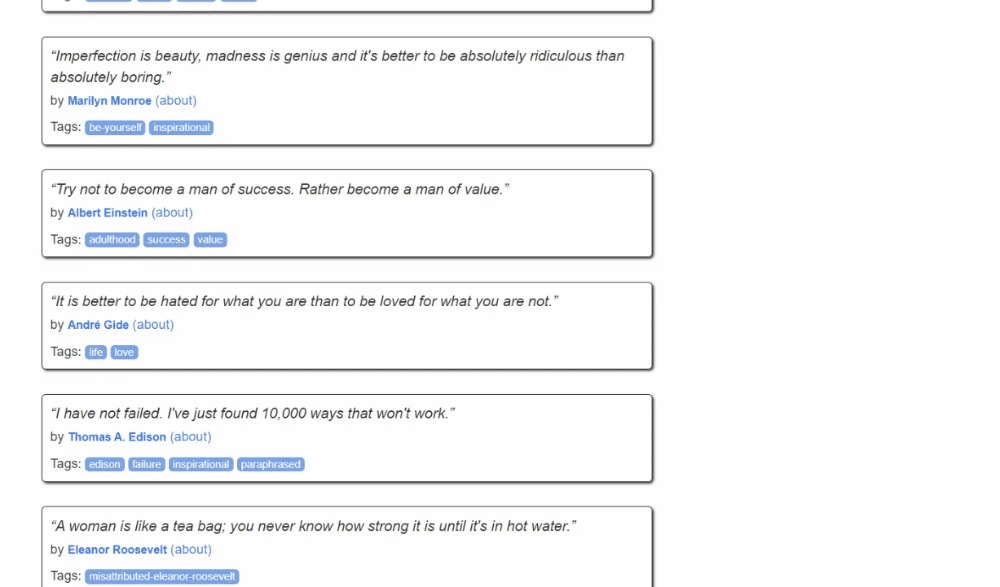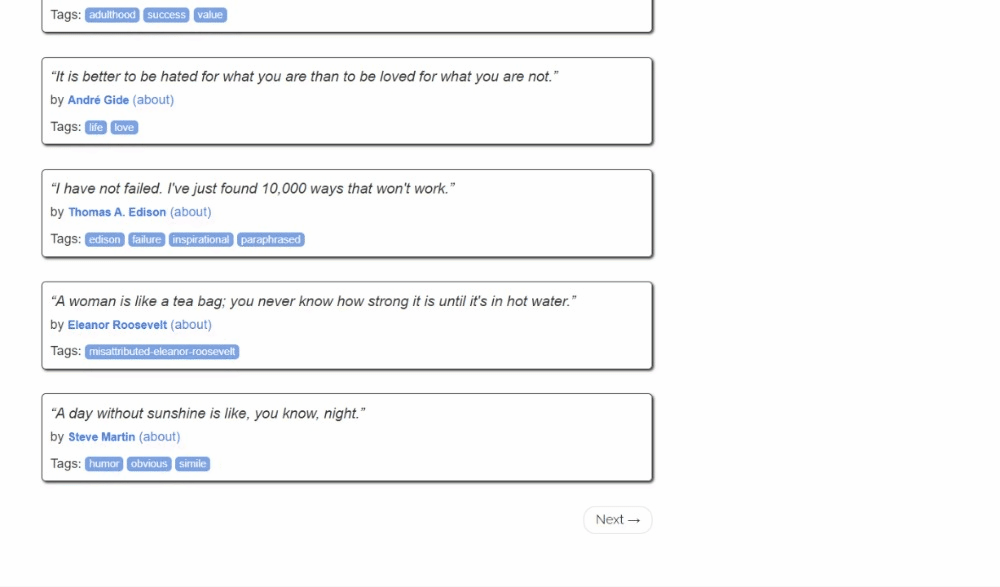
以下の手順に従い、Kotlinでのウェブスクレイピングの実行方法を学びましょう!
ステップ1: スクラッピングライブラリのインストール
まず、目的に最適なKotlinウェブスクレイピングライブラリを特定します。そのためには対象サイトを調査する必要があります。
ブラウザでQuotes To Scrapeのサンドボックスサイトにアクセスします。空白部分を右クリックし、「要素を検査」を選択して開発者ツールを開きます。「ネットワーク」タブに移動し、ページを再読み込みして「Fetch/XHR」セクションを確認してください。
以下のような表示が確認できるはずです:
AJAXリクエストは存在しません!つまり、対象ページはJavaScriptを介した動的なデータ取得を行っていません。これは、サーバーがHTMLコード内に必要なデータを全て埋め込んだ状態でページをクライアントに返していることを意味します。
したがって、HTMLパースライブラリで十分です。ブラウザ自動化ツールの使用も可能ですが、ブラウザでページを読み込みレンダリングするとパフォーマンスのオーバーヘッドが生じるだけで、実質的な利点はありません。
したがって、ウェブスクレイピングの目的を達成するにはskrape{it}が最適な選択肢となります。プロジェクトの依存関係に追加するには、build.gradle.ktsファイルのdependenciesオブジェクトに次の行を追加してください:
implementation("it.skrape:skrapeit:1.2.2")Mavenユーザーの場合は、pom.xmlの<dependencies>タグに以下の行を追加してください:
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>IntelliJ IDEAを使用している場合、IDEはプロジェクトの依存関係を再読み込みし新しいライブラリをインストールするボタンを表示します。クリックしてskrape{it}をインストールしてください。
同様に、次の Gradle コマンドで新しい依存関係を手動でインストールすることもできます:
./gradlew build --refresh-dependenciesインストールには時間がかかる場合がありますので、しばらくお待ちください。
次に、App.ktスクリプトでskrape{it}を使用する準備として、以下のインポートを追加します:
import it.skrape.core.*
import it.skrape.fetcher.*skrape{it}には多数のデータフェッチャーが付属していることに留意してください。ここでは簡略化のため全てをインポートしました。実際にはHttpFetcherのみが必要となります。これは指定されたURLへHTTPリクエストを送信し、パース済みレスポンスを返す標準的なHTTPクライアントです。
素晴らしい!これでKotlinを用いたウェブスクレイピングに必要な環境が整いました!
ステップ2: 対象ページをダウンロードしHTMLをパースする
App.ktでAppクラスを削除し、main()関数内に以下の行を追加してskrape{it}で対象ページに接続します:
skrape(HttpFetcher) {
// 指定されたURLへのHTTP GETリクエストを実行
request {
url = "https://quotes.toscrape.com/"
}
}内部では、skrape{it} は前述の HttpFetcher クラスを使用して、指定された URL に対して同期的な HTTP GET リクエストを実行します。
スクリプトが意図した通りに動作することを確認したい場合は、skrape(HttpFetcher) の定義に次のセクションを追加してください:
response {
// HTMLソースコードを取得して出力
htmlDocument {
print(html)
}
}これにより、skrape{it} はサーバーからの応答をどのように処理すべきかを理解します。具体的には、パースされた応答にアクセスし、ページの HTML コードを出力します。
App.kt Kotlin スクラッピングスクリプトには以下を含める必要があります:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// 指定されたURLへのHTTP GETリクエストを実行
request {
url = "https://quotes.toscrape.com/"
}
response {
// HTMLソースコードを取得して出力
htmlDocument {
print(html)
}
}
}
}スクリプトを実行すると以下が出力されます:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- 簡略化のため省略... -->これがまさにターゲットページのHTMLコードです。よくできました!
ステップ3: ページコンテンツの調査
次のステップはスクレイピングロジックの定義です。しかし、ページ上の要素の選択方法を知らなければ、どうやってそれを実現できるでしょうか?だからこそ、追加の手順を踏んでターゲットページの構造を調査することが重要なのです。
ブラウザで「Open Quotes To Scrape」を再度開きます。引用要素の一つを右クリックし、「要素を検査」を選択して開発者ツールを開きます(下図参照):
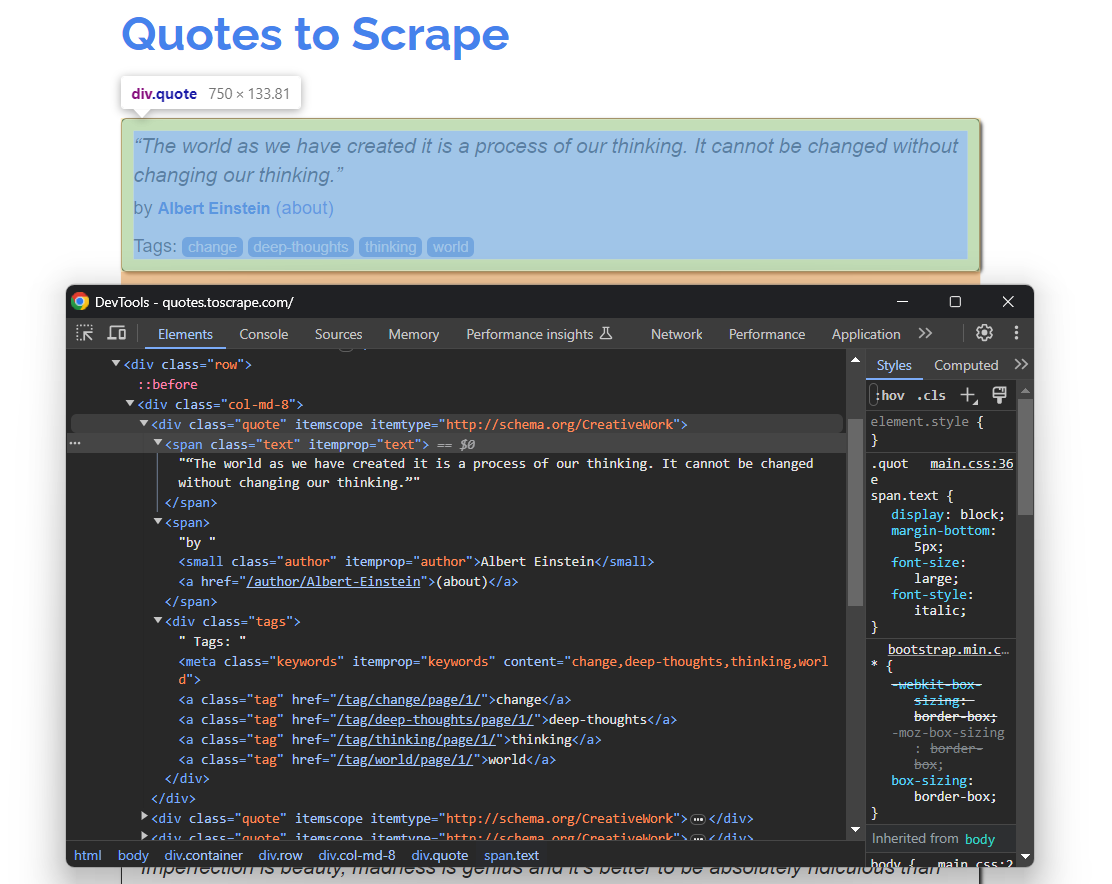
ここで、各引用カードが.quote HTML要素で囲まれていることに気づくでしょう:
- 引用文テキストを含む.text要素
- 著者の名前を含む.author要素
- 単一のタグを表示する複数の.tag要素
なお、すべての引用文にタグセクションがあるわけではありません:

上記のCSSセレクタは、ページから目的のDOM要素を選択しデータを抽出するのに役立ちます。また、このデータを格納するクラスも必要です。そのため、ウェブスクレイピングKotlinスクリプトの先頭に以下のQuoteクラス定義を追加してください:
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}ページには複数の引用が含まれるため、main()内でQuoteオブジェクトのリストをインスタンス化します:
val quotes: MutableList<Quote> = ArrayList()スクリプトの終了時には、quotesにはサイトから収集したすべての引用が含まれます。
ここで理解し定義した内容を基に、次のステップでスクレイピングロジックを実装しましょう!
ステップ4: スクラッピングロジックの実装
skrape{it}はページ上のHTMLノードを選択する独特の仕組みを持っています。ページにCSSセレクタを適用するには、htmlDocument内でCSSセレクタと同じ名前のセクションを定義する必要があります:
skrape(HttpFetcher) {
// リクエストセクション...
response {
htmlDocument {
// ページ上のすべての ".quote" HTML要素を選択
".quote" {
// スクラッピングロジック...
}
}
}
}「.quote」セクション内で、findAllセクションを定義できます。これは、指定されたCSSセレクタで選択された各引用HTMLノードに適用されるロジックを含みます。代わりにfindFirstを使用すると、最初に選択された要素のみを取得できます。
内部的には、これらのセクションはすべてKotlinラムダ関数に過ぎません。そのため、findAll内のforEachセクションで、それを使って単一のDOM要素にアクセスできます。ご存じない方のために説明すると、これはラムダの単一パラメータの暗黙の名称です。
同様のロジックを、メソッドと属性に基づいて実装します。各引用から必要なデータを抽出するスクレイピングロジックを実装し、Quoteオブジェクトをインスタンス化してquotesリストに追加するには、以下のようにします:
".quote" {
findAll {
forEach {
// 単一引用要素に対するスクレイピングロジック
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// Quoteオブジェクトを作成しリストに追加
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}text属性により、HTML要素の内部テキストを取得できます。すべての引用HTML要素にタグが含まれるわけではないため、ElementNotFoundExceptionを処理する必要があります。これは、指定されたCSSセレクタがページ上のどのノードにも一致しない場合にfindAllによって発生します。
ElementNotFoundException をインポート:
import it.skrape.selects.ElementNotFoundException
すべてのスニペットをまとめ、quotes配列に含まれるデータをログ出力します:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// Kotlinでスクレイピングデータを表現するクラスを定義
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// スクレイピングしたデータの保存先
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// 指定されたURLへのHTTP GETリクエストを実行
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// ページ上のすべての ".quote" HTML要素を選択
".quote" {
findAll {
forEach {
// 単一の引用要素に対するスクレイピングロジック
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// Quoteオブジェクトを作成しリストに追加
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// スクレイピングしたデータをログ出力
for (quote in quotes) {
println("Text: ${quote.text}")
println("Author: ${quote.author}")
println("Tags: ${quote.tags.joinToString("; ")}")
println()
}
}タグリストをカンマ区切り文字列に結合するためにjoingToString()を使用している点に注意してください。
スクリプトを実行すると、以下のような結果が得られます:
Text: “私たちが作り出した世界は、私たちの思考の産物です。私たちの思考を変えなければ、世界は変わりません。”
Author: Albert Einstein
Tags: change; deep-thoughts; thinking; world
# 簡潔にするため省略...
Text: “太陽の光のない日は、つまり、夜のようなものです。”
Author: Steve Martin
Tags: humor; obvious; simileすごい!これで、Kotlin を使ってウェブスクレイピングを行う方法を学べましたね!
ステップ 5: クロールロジックを追加する
1 ページからデータをスクレイピングしましたが、引用文のリストは複数のページにまたがっています。ページを最後までスクロールすると、次のページへのリンクである「Next →」ボタンがあります。
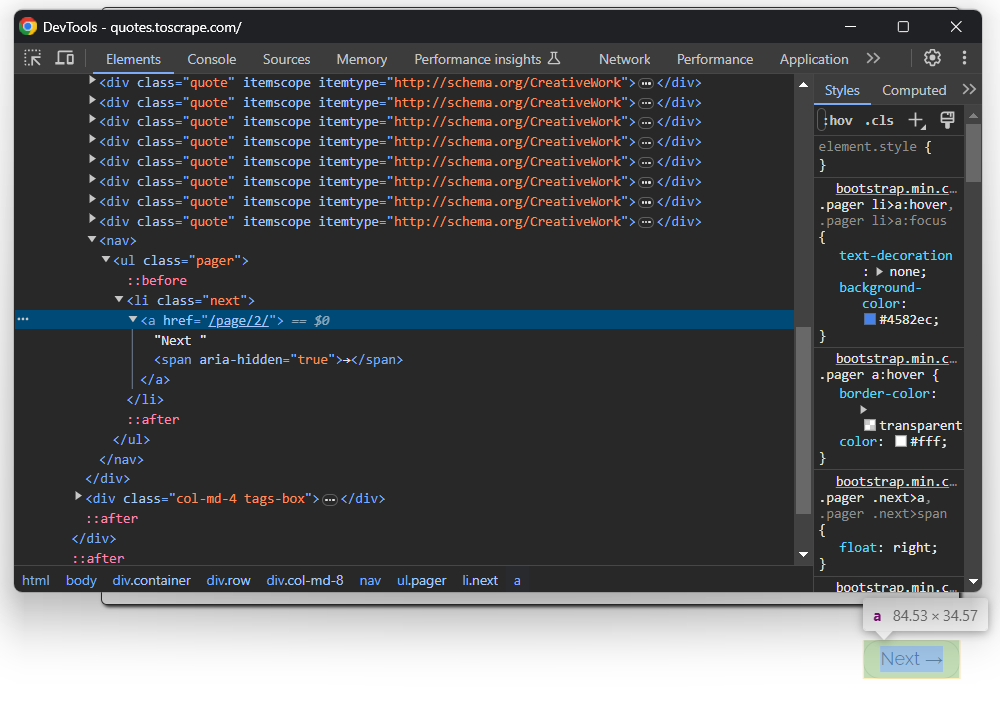
これは、最後のページを除くすべてのページに当てはまります。
Kotlin でウェブスクレイピングを実行し、サイト上の各引用をスクレイピングするには、次のことを行う必要があります。
- 現在のページからすべての引用文をスクレイピングする。
- 「次へ →」要素が存在する場合、それを選択し、次のページのURLを抽出する。
- 新しいページで最初のステップを繰り返す。
上記のアルゴリズムを以下のように実装します:
単一ページをスクレイピングして終了する代わりに、スクリプトはwhileループに依存します。これはスクレイピング対象のページがなくなるまで反復を続けます。これは.next a CSSセレクタがElementNotFoundException例外を発生させたときに発生します。これは「次へ →」ボタンがページ上に存在せず、サイトの最終ページネーションページにいることを意味します。
htmlDocumentセクションには複数のCSSセレクタセクションを含めることができます。各セクションは指定された順序で実行されます。Kotlinウェブスクレイピングスクリプトを再度実行すると、サイト上の全100件の引用文が保存されるようになります。
素晴らしい!Kotlinによるウェブスクレイピングとクローリングのロジックは完成しました。あとはデータエクスポートロジックを含むロギングコードを削除するだけです。
ステップ7: スクレイピングデータをCSVにエクスポート
収集したデータは現在、Quoteオブジェクトのリストに格納されています。ターミナルへの出力も有用ですが、CSVへのエクスポートがデータの活用に最適です。これにより、チームメンバーがデータをフィルタリング、閲覧、分析できるようになります。
KotlinはCSVファイルの作成とデータ書き込みに必要な機能をすべて備えていますが、ライブラリを使用すると作業が格段に容易になります。CSVファイルの読み書きに広く使われるKotlinネイティブライブラリがkotlin-csvです。
プロジェクトの依存関係に追加するには、build.gradle.ktsに以下を記述します:
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")Mavenを使用している場合は:
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>ライブラリをインストールし、App.ktファイルでインポートします:
import com.github.doyaaaaaken.kotlincsv.dsl.*これで、わずか数行のコードで引用文をCSVファイルにエクスポートできます:
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}List<String> は kotlin-csv で CSV レコードが表現される形式です。まずヘッダー行用のレコードを定義し、次に引用文を目的のデータに変換します。その後、CSV ライターを初期化し、quotes.csv ファイルを作成し、writeRow() と writeRows() でデータを書き込みます。
さあ、いよいよです! Kotlinウェブスクレイピングスクリプトの最終コードを確認しましょう。
ステップ8: 全てを統合する
以下がKotlinスクレイパーの最終コードです:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// Kotlinでスクレイピングデータを表現するクラスを定義
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// スクレイピングしたデータの保存先
val quotes: MutableList<Quote> = ArrayList()
// 次に訪問するページのURL
var nextUrl: String? = "https://quotes.toscrape.com/"
// 訪問するページがある限り
while (nextUrl != null) {
skrape(HttpFetcher) {
// 指定されたURLにHTTP GETリクエストを送信
request {
url = nextUrl!!
}
response {
htmlDocument {
// ページ上のすべての ".quote" HTML要素を選択
".quote" {
findAll {
forEach {
// 単一の引用要素に対するスクレイピングロジック
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// Quoteオブジェクトを作成しリストに追加
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
// クローリングロジック
try {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// "quotes.csv" ファイルを作成し、
// スクレイピングしたデータで埋める
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}信じられますか? skrape{it}のおかげで、たった100行未満のコードでサイト全体のデータを取得できるんです!
ウェブスクレイピング Kotlin スクリプトを実行するには:
./gradlew runスクレイパーが対象サイトの各ページを処理する間、しばらくお待ちください。処理が完了すると、プロジェクトのルートディレクトリにquotes.csvファイルが生成されます。開くと、次のようなデータが表示されるはずです:
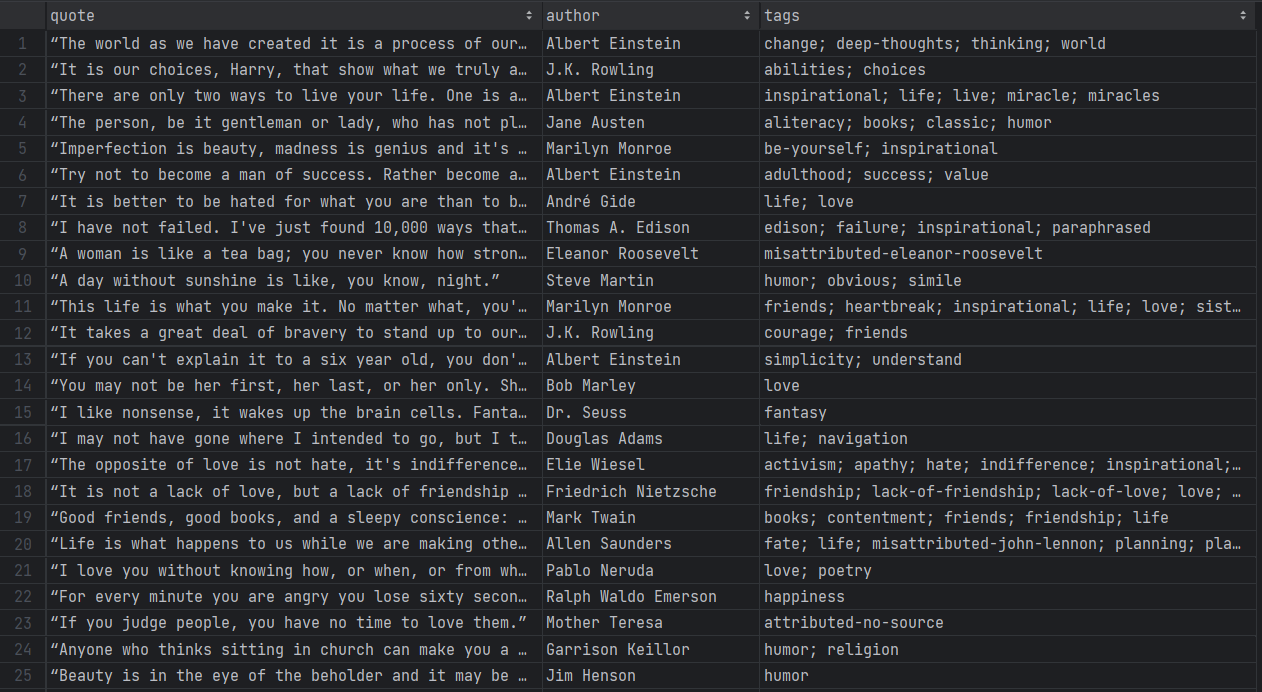
さあ、できました!オンラインページの構造化されていないデータから始まり、今では簡単に探索できるCSVファイルに!
プロキシでKotlinのIPブロックを回避
Kotlinでウェブスクレイピングを行う際、最大の課題の一つはボット対策技術によるブロックです。これらのシステムはスクリプトの自動化を検知し、IPを禁止します。これによりスクレイピング操作が停止されます。
これを回避するには? プロキシを活用しましょう!
以下の手順に従い、Bright DataプロキシをKotlinに統合する方法を学びましょう。
Bright Dataでのプロキシ設定
Bright Dataは市場最高峰のプロキシサーバーで、世界中の数千台のプロキシサーバーを監視しています。IPローテーションに関しては、レジデンシャルプロキシが最適なプロキシタイプです。
開始するには、既にアカウントをお持ちの場合はBright Dataにログインしてください。お持ちでない場合は無料でアカウントを作成してください。以下のユーザーダッシュボードにアクセスできます:
以下の「プロキシ製品を表示」ボタンをクリックしてください:
以下の「プロキシ&スクレイピングインフラ」ページにリダイレクトされます:
画面を下にスクロールし、「レジデンシャルプロキシ」カードを見つけて「開始」ボタンをクリックしてください:
レジデンシャルプロキシ設定ダッシュボードが表示されます。ガイド付きウィザードに従い、必要に応じてプロキシサービスを設定してください。設定方法に不明点がある場合は、24時間365日対応のサポートまでお気軽にお問い合わせください。
「アクセスパラメータ」タブに移動し、プロキシのホスト、ポート、ユーザー名、パスワードを以下のように取得します:
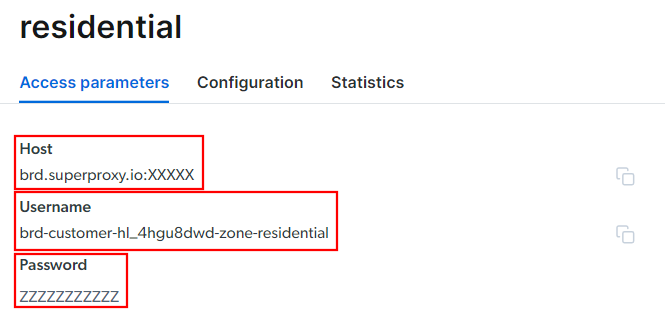
「ホスト」フィールドにはポート番号が既に含まれている点に注意してください。
これでプロキシURLを構築し、skrape{it}で使用する準備が整いました。以下の構文に従い、すべての情報を組み合わせてURLを作成してください:
<ユーザー名>:<パスワード>@<ホスト>例:
brd-customer-hl_4hgu8dwd-ゾーン-residential:[email protected]:XXXXX「Activeプロキシ」を切り替え、最後の指示に従えば準備完了です!

Kotlinでのプロキシ統合
skrape{it}でのBright Data統合スニペットは以下のようになります:
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-zone-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}ご覧の通り、プロキシと認証リクエストオプションの使用がすべてです。これ以降、skrape{it}は指定されたURLへBright Dataプロキシ経由でリクエストを送信します。IPブロックとはおさらばです!
Kotlinによるウェブスクレイピングを倫理的かつ尊重ある方法で実施しましょう
ウェブスクレイピングは様々なユースケースで有用なデータを収集する効果的な方法です。最終目標はデータを取得することであり、対象サイトを損なうことではないことを心に留めてください。したがって、適切な予防策を講じてこの作業に臨む必要があります。
責任あるKotlinウェブスクレイピングを行うためのヒント:
- 公開情報のみを対象とする: サイト上で公開されている データの取得に焦点を当ててください。 ログイン認証やその他の認可形式で保護されているページは避けてください。適切な許可なく非公開データや機密データをスクレイピングすることは非倫理的であり、法的措置につながる可能性があります。
- robots.txtファイルを尊重する:すべてのサイトには 、自動クローラーがページにアクセスする方法を定義するrobots.txtファイルが存在します。 倫理的なスクレイピングを実践するには、これらのガイドラインを遵守する必要があります。詳細は「ウェブスクレイピングのためのrobots.txtガイド」を参照してください。
- リクエスト頻度の制限: 短時間に過剰なリクエストを行うと サーバー過負荷を引き起こし、全ユーザーのサイトパフォーマンスに影響します。レート制限措置が発動され、アクセスがブロックされる可能性もあります。このため、リクエストにランダムな遅延を追加し、対象サーバーへの過剰な負荷を回避してください。
- サイトの利用規約を確認し遵守する:スクレイピング前に必ず利用規約を確認してください。著作権、知的財産権、データの利用方法・時期に関するガイドラインが記載されている場合があります。
- 信頼性が高く最新のウェブスクレイピングツールを利用すること: 評判の良いプロバイダーを選び 、適切に保守され定期的に更新されるツールやライブラリを選択してください。 そうすることで初めて、最新の倫理的なKotlinウェブスクレイピング原則に沿っていることを保証できます。疑問がある場合は、最適なウェブスクレイピングサービスの選び方に関する記事を参照してください。
結論
本ガイドでは、特にJavaと比較した場合にKotlinがウェブスクレイピングに優れた言語である理由を解説しました。また、最高のKotlinスクレイピングライブラリの一覧も紹介しました。さらに、skrape{it}を使用して実世界のサイトの複数ページからデータを抽出するスクレイパーを構築する方法を学びました。ここで体験したように、Kotlinによるウェブスクレイピングはシンプルで、わずか数行のコードで実現できます。
スクレイピング作業における主な課題は、ボット対策ソリューションです。ウェブサイトは自動化されたスクリプトからデータを保護するため、ページへのアクセス前にそれらをブロックするシステムを採用しています。これらすべてを回避することは容易ではなく、高度なツールが必要です。幸いなことに、Bright Dataが解決策を提供します!
Bright Dataが提供するスクレイピング製品の一部をご紹介します:
- WebスクレイパーAPI: 数十の主要ドメインから構造化されたウェブデータへプログラムでアクセスするための使いやすいAPI。
- スクレイピングブラウザ: JavaScriptレンダリング機能を備えたクラウドベースの制御可能ブラウザ。ブラウザフィンガープリント対策、CAPTCHA対応、自動再試行などを自動処理します。PlaywrightやPuppeteerなど主要な自動化ブラウザライブラリと統合可能です。
- Web Unlocker:あらゆるページの生のHTMLをシームレスに取得し、あらゆるウェブスクレイピング対策をかいくぐるアンロックAPI。
ウェブスクレイピング自体には関心がなく、オンラインデータのみが必要な場合でも、Bright Dataのすぐに使えるデータセットをご検討ください!




