

このガイドでは、以下の内容を扱います。
- Rでウェブスクレイピングを始める方法
Rでウェブスクレイピングを始める方法
はじめに、このRチュートリアルでどんなツールを使用するかを学びましょう。
使用するツールの理解: Rとrvest
Rは、統計解析やデータ可視化に対応した、豊富で使いやすいライブラリで、データラングリングや動的型付けのための便利なツールを提供します。
rvest(収穫を意味する「harvest」に由来)は、ウェブスクレイピング機能を提供する最も人気のあるRパッケージの1つであり、その非常にユーザーフレンドリーなインターフェースが人気の秘密でもあります。Vanilla rvestでは、1つのウェブページのみからデータを抽出することができますが、これは最初の探索に最適です。その後、politeライブラリで拡張して、複数のページをスクレイピングできます。
開発環境のセットアップ
まだRStudio内でRを使用していない場合は、こちらの指示に従ってインストールしてください。
完了したら、コンソールを開いてrvestをインストールします。
install.packages("rvest")
これはtidyverseコレクションの一部であるため、rvestの組み込み機能を、コードの可読性のためのmagrittr、およびHTMLやXMLを処理するためのxml2など、コレクション内の他のパッケージでrvestの組み込み機能を拡張することが公式に推奨されています。これは、tidyverseを直接インストールすることで行えます。
install.packages("tidyverse")ウェブページの理解
ウェブクレイピングは、法令に準拠した自動化されたプロセス内で、ウェブサイトからデータを取得する技術です。
この定義から、以下の3つの重要な考察が得られます。
- データにはさまざまな形式があります。
- ウェブサイトで情報を表示する方法は極めて多様です。
- スクレイピングしたデータに、合法的にアクセス可能でなければなりません。
URLをスクレイピングする方法を理解するには、まず、HTMLマークアップ言語とCSSシートスタイル言語を使用して、ウェブページのコンテンツがどのように表示されるかを理解する必要があります。
HTMLは、コンテンツを「タグ」で整理することで、ウェブページのコンテンツと構造を提供します。これにより、ウェブページがウェブブラウザに読み込まれると、ツリー状のDOM(Document Object Model)が作成されます。 タグは階層構造になっており、各タグには、その開始()および終了()のステートメントに含まれるすべてのコンテンツに適用される特定の機能があります。
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html><html>タグはウェブページの最小構成要素であり、その内部に<head>および<body>タグがネスト構造に配置されています。<head>および<body>自体が、それらの内部にある他のタグの「親」であり、<div>(ドキュメントセクション用)および<p>(パラグラフ用)はその代表的な「子」です。
上記のスニペットでは、各HTML「要素」に関連付けられた「属性」を見ることができます。lang、class、style はあらかじめ組み込まれており、data-で始まる属性はAmazon独自のものです。
classは、id属性とともにウェブスクレイピングにおいて特に高い関心を持たれる属性で、要素のグループと特定の要素をそれぞれターゲットにすることができます。これはもともとCSSのスタイリング用でした。
CSSは、ウェブページのスタイリングを提供します。色の設定から位置決め、サイズ調整まで、任意のHTML要素を選択し、そのスタイリングプロパティに新しい値を割り当てることができます。また、上記のスニペットで見たように、style属性を使用してHTML要素内でインラインのCSSスタイリングを適用することもできます。
<body .. style="padding-bottom: 0px;">純粋なCSSでは、これは次のように記述されます。
body {padding-bottom: 0px;}
ここで、bodyは「セレクタ」、padding-bottomは「プロパティ」、0pxは「値」です。
任意のタグ、クラス、またはidをCSSセレクタとして使用できます。
ユーザーは、プログラミング言語であるJavaScriptが提供するscriptタグの機能により、ウェブページに表示されるコンテンツと動的にやり取りすることができます。ユーザーとのやり取りの後、表示されるコンテンツが変化したり、新しいコンテンツが現れたりすることがあります。後で説明するように、高度なウェブスクレイパーはユーザーのやり取りを模倣できます。
DevToolsの理解
主要なウェブブラウザには開発者向けツールが組み込まれており、ログ記録、デバッグ、テスト、パフォーマンス分析のために、ウェブページ上の技術情報を収集し、リアルタイムで更新することができます。このチュートリアルでは、ChromeのDevToolsを使用します。
デベロッパーツールには、ブラウザの右上隅にある「その他のツール」からアクセスできます。
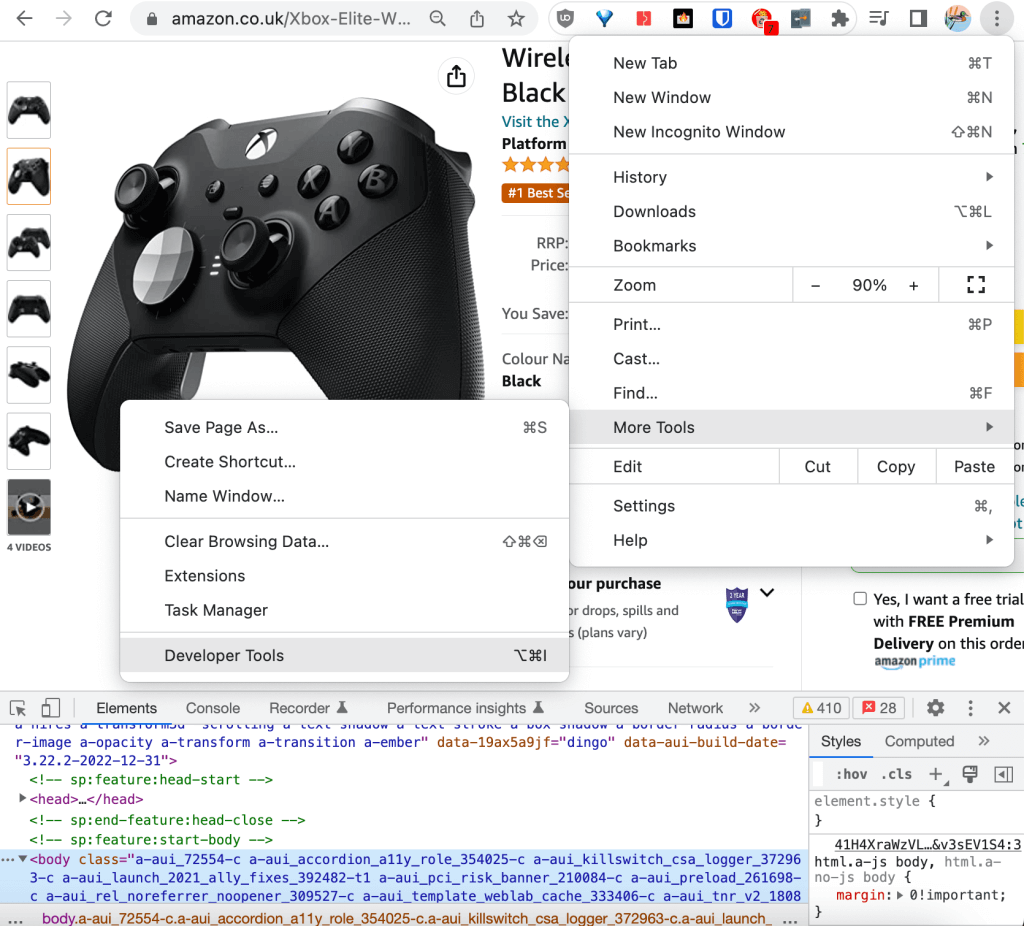
DevToolsでは、Elementsタブで生のHTMLをスクロールできます。いずれかのHTML行をスクロールすると、ウェブページにレンダリングされた対応する要素が青くハイライト表示されます。
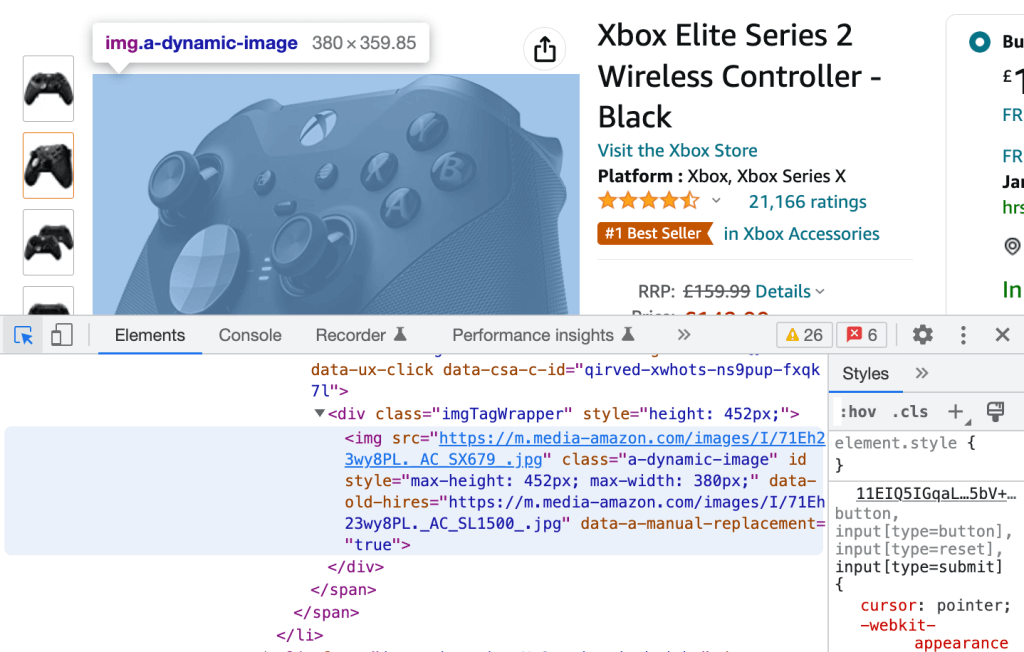
逆に、左上隅のアイコンをクリックし、ウェブページからレンダリングされた要素を選択すると、対応する生のHTML(青色でハイライト表示される)にリダイレクトされます。
この2つの処理を行うだけで、実践チュートリアルで使用するCSSディスクリプタを抽出できます。
Rによるウェブスクレイピングを深く理解する:チュートリアル
このセクションでは、Amazon URLをウェブスクレイピングして商品レビューを抽出する方法を探ります。
前提条件
以下がRstudio環境にインストールされていることを確認してください。
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
ウェブページを対話的に探索する
ChromeのDevToolsを使ってURLのHTMLを探索し、スクレイピングしたいと思う情報(商品レビュー)を含むHTML要素のすべてのクラスとIDのリストを作成できます。

各カスタマーレビューは、次の形式のidを持つdivに属します。
customer_review_$INTERNAL_ID.
上のスクリーンショットで、カスタマーレビューに対応するdivのHTMLコンテンツは以下の通りです。
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
カスタマーレビュー内でスクレイピングしたい各コンテンツには、タイトルを表すreview-title-content、本文を表わすreview-text-content、評価を表わすreview-ratingという固有のクラスがあります。
ドキュメント内でクラスが一意であることを確認し、直接「簡易セレクタ」を使用できます。より確実な方法は、代わりにCSSディスクリプタを使用することで、将来的に新しい要素にクラスが割り当てられたとしても、一意性が保たれます。
DevTools内の要素を右クリックし、「セレクタのコピー」を選択することで、CSSディスクリプタを簡単に取得できます。
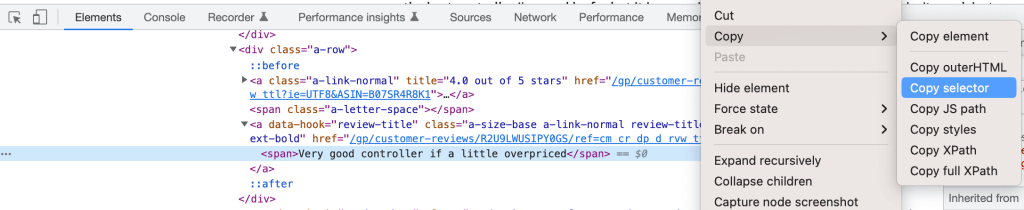
3つのセレクタを次のように定義できます。
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanタイトル用customer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > span本文用customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > span評価用 *.review-ratingを手動で追加し、より一貫性を持たせました。
ウェブスクレイピングにおけるCSSセレクタとXPath
このチュートリアルでは、ウェブスクレイピングで要素を識別するためにCSSセレクタを使用することにしました。もう1つの一般的な方法は、XPath、つまりXMLパスを使用することで、これはDOM内の要素のフルパスを通じて要素を識別します。
CSSセレクタと同じ手順で、完全なXPathを抽出できます。例えば、レビューのタイトルは以下のようになります。
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
CSSセレクタの方がわずかに高速で、XPathの方がわずかに後方互換性に優れています。これらの小さな違いを除けば、どちらを選ぶかは、技術的な意味合いよりも、個人の好みによるところが大きいでしょう。
ウェブページから情報をプログラムで抽出する
URLをウェブスクレイピングする方法を探るためにコンソールを直接使うこともできますが、ここではトレーサビリティと再現性のためにスクリプトを作成し、source()コマンドを使ってコンソールで実行します。
スクリプトを作成したら、まずはインストールしたライブラリを読み込みます。
library(”rvest”)
library(”tidyverse”)これで、興味のあるコンテンツを以下のようにプログラムで抽出できます。まず、検索するためのURLを格納する変数を作成します。
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
次に、URLからASIN(Amazon Standard Identification Number)を抽出して、一意の商品IDとして使用します。
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
ウェブスクレイピングで抽出したテキストをRegExを使ってクリーニングすることは一般的であり、データ品質を確保するために推奨されています。
次に、ウェブページのHTMLコンテンツをダウンロードします。
HTMLContent <- read_html(HtmlLink)
read_html()関数は、xml2パッケージに含まれています。
print()でコンテンツを表示すると、これまでに解析した生のHTML構造と一致していることがわかります。
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
これで、ページ上のすべての商品レビューについて、興味のある3つのノードを抽出できます。ChromeのDevToolsで提供されるCSSディスクリプタを使用し、特定のカスタマーレビュー識別子#customer_review-R2U9LWUSIPY0GSと文字列からの「>」コネクタを取り除くように修正します。また、rvestのhtml_nodes()およびhtml_text()機能を使用して、HTMLコンテンツを別々のオブジェクトに保存できます。
以下のコマンドで、レビューのタイトルを抽出します。
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
review_titleのエントリの例としては、「Very good controller if a little overpriced.」があります。
以下のコードで、レビューの本文を抽出します。
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
review_bodyのエントリの例としては、「In all honesty, I’m not sure why the price…」があります。
そして、以下のコマンドでレビュー評価を抽出できます。
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
review_ratingのエントリの例は、「4.0 out of 5 stars」です。
この変数の質を高めるために、評価「4.0」のみを抽出してintに変換します。
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
パイプ機能%>%は、magrittrツールキットによって提供されます。
これで、スクレイピングしたコンテンツをtibbleにエクスポートしてデータ分析を行う準備が整いました。 tibbleはRパッケージで、tidyverseコレクションにも属しており、データフレームの操作や印刷に使用されます。
df <- tibble(review_title, review_body, review_rating)
出力データフレームは以下の通りです。

最後に、ベストプラクティスに準拠し、複数のURLへのスケーリングに最適なコードを準備するために、関数scrape_amazon <- function(HtmlLink)にコードをリファクタリングするのは良いアイデアです。
複数のURLへの拡張
ウェブスクレイピングのテンプレートを作成できたら、ウェブクローリングとスクレイピングを通じて、Amazonにおけるトップ競合他社の商品すべてのURLのリストを作成できます。
複数のURLにスケーリングしてソリューションを本稼動させる場合、アプリケーションの技術要件を明確にしておく必要があります。
技術要件を明確にすることで、ビジネス要件を正しくサポートし、既存システムとのシームレスな統合を確実に行うことができます。
具体的な技術要件に応じ、スクレイピング機能を更新して、以下の組み合わせをサポートする必要があります。
- リアルタイムまたはバッチ処理
- 出力形式(JSON、NDJSON、CSV、XLSXなど)
- 出力対象(メール、API、webhook、クラウドストレージなど)
すでに述べたように、politeを使用してrvestを拡張し、複数のウェブページをスクレイピングできます。politeはウェブハーベスティングセッションを作成および管理しますが、それにはウェブホストのrobots.txtファイルに完全に準拠し、レート制限とレスポンスキャッシングを内蔵した3つの主要機能が利用されます。
bow()は、特定のURLのスクレイピングセッションを作成します。つまり、ウェブホストにユーザーを紹介して、スクレイピングの許可を求めます。scrape()はこのURLのHTMLにアクセスし、rvestのhtml_nodes()やhtml_text()にこの関数をパイプして、特定のコンテンツを取得できます。nod()は、セッションを再作成することなく、セッションのURLを次のページに更新します。
ウェブサイトから直接引用すると、「politeセッションの3つの柱は、許可を求めること、ゆっくりと取り組むこと、2度聞かないことです。」
次のステップ:プレビルトか、セルフビルトか?
ビジネスのために良質なデータを抽出できる最先端のウェブスクレイパーを開発するには、いくつもの機能チームを利用する必要があります。
- ウェブデータ抽出の専門知識を持つデータスペシャリストのチーム
- プロキシ管理やアンチボット回避の専門知識を持つDevOpsエンジニアのチーム(CAPTCHAを突破し、一般にアクセスしにくいウェブサイトのロック解除を可能にする)
- リアルタイムおよびバッチデータ抽出向けのインフラ構築に精通したデータエンジニアのチーム
- プライバシーに関するデータ保護法の法的要件(GDPRやCCPAなど)を理解する法律専門家のチーム
ウェブ上のコンテンツはさまざまな形式で提供されており、まったく同じ構造のウェブサイトはほとんどありません。ウェブサイトが複雑で、スクレイピングすべき機能やデータが多ければ多いほど、必要なプログラミングの知識は高度になり、ソリューションに必要な時間やリソースが増えるのは言うまでもありません。
通常、少なくとも以下のような高度な機能を実装することが望ましいとされています。
- CAPTCHAやボット検知の可能性を最小限に抑える:ここでの簡単なアプローチは、ウェブサーバーへの過負荷や規則的なリクエストパターンを回避するために、ランダムなsleep()を追加することです。より効果的な方法は、user_agentやプロキシサーバーを使用して、リクエストを異なるIP間に分散させることです。
- Javascriptを搭載したウェブサイトをスクレイピングする:Amazonの例では、特定の商品バリエーションを選択しても、URLは変わりません。これはレビューのスクレイピングには適していますが、商品仕様のスクレイピングには適しません。動的なウェブページでユーザーの操作を模倣する場合は、RSeleniumのようなツールを使ってウェブブラウザのナビゲーションを自動化できます。
限られたリソースでウェブデータにアクセスしたい、データの品質を確保したい、より高度なユースケースを実現したい場合は、プレビルトのウェブスクレイパーを選ぶとよいでしょう。
Bright Dataのウェブスクレイパーは、最先端の機能を備えた多くのウェブサイト向けのテンプレートを備えており、デモで示したAmazon Scraperのはるかに高度な実装を提供します!






