

このステップバイステップチュートリアルに従い、求人情報を自動取得するウェブスクレイピング用Pythonスクリプトの構築方法を学びましょう。
このガイドでは以下の内容を扱います:
- ウェブから求人データをスクレイピングする理由
- Indeedスクレイピング用ライブラリとツール
- Seleniumを使用したIndeedの求人データスクレイピング
なぜウェブから求人データをスクレイピングするのか?
ウェブスクレイピングで求人データを収集することは、以下の理由から有用です:
- 市場調査:企業や労働市場アナリストが業界動向に関する情報を収集できるようにします。例えば、需要の高いスキルや求人増加が見られる地域を把握できます。また、競合他社の採用活動を監視することも可能になります。
- 求人検索とマッチングの効率化:求職者が複数のソースから求人情報を検索し、自身の資格や希望に合ったポジションを見つけられるよう支援します。
- 採用と人事の最適化:採用プロセスを支援し、市場における給与動向や候補者が求める福利厚生の理解を促進します。
したがって、求人データは雇用主と求職者の双方にとって有用です。
求人リストスクレイパーに関して、強調すべき重要な点が一つあります。対象プラットフォームは公開されている必要があります。つまり、非ログインユーザーでも求人検索を行えることが必須です。ログイン壁の背後でデータをスクレイピングすると、法的トラブルに巻き込まれる可能性があるためです。
つまりLinkedInは選択肢から外れる。では他にどんな求人プラットフォームが残るか? そう、主要オンライン求人プラットフォームの一つ、Indeedだ!
Indeedスクレイピング用ライブラリとツール
Pythonは、その構文、使いやすさ、豊富なライブラリエコシステムにより、スクレイピングに最適な言語の一つと考えられています。それでは、Pythonを使ったウェブスクレイピングのガイドをご覧ください。
次に、数あるスクレイピングライブラリから適切なものを選択する必要があります。適切な判断を下すために、ブラウザでIndeedを実際に操作してみてください。サイトのデータの大半は、ユーザー操作後に取得されることに気づくでしょう。これは、ページ再読み込みなしで動的にコンテンツをロード・更新するために、サイトがAJAXを多用していることを意味します。このようなサイトでウェブスクレイピングを行うには、JavaScriptを実行できるツールが必要です。そのツールこそがSeleniumです!
SeleniumはPythonで動的ウェブサイトのウェブスクレイピングを可能にします。制御可能なウェブブラウザ内でサイトをレンダリングし、指示した操作を実行します。Seleniumのおかげで、対象サイトがレンダリングやデータ取得にJavaScriptを使用している場合でもデータをスクレイピングできます。
Indeedのようなサイトから求人情報をスクレイピングする方法を学びましょう!
SeleniumでIndeedから求人データをスクレイピング
このステップバイステップチュートリアルに従い、Indeed向けPythonウェブスクレイピングスクリプトの構築方法を学びましょう。
ステップ1: プロジェクト設定
ウェブスクレイピング作業を開始する前に、以下の前提条件を満たしていることを確認してください:
- Python 3+ がマシンにインストールされていること:インストーラーをダウンロードし、ダブルクリックしてインストールウィザードに従ってください。
- お好みのPython IDE:PyCharm Community Editionや Python拡張機能付きのVisual Studio Codeが優れた選択肢です。
これでPythonプロジェクトを設定する準備が整いました!
ターミナルを開き、以下のコマンドを実行して:
- indeed-スクレイパーフォルダーを作成
- そのフォルダに移動
- Python仮想環境で初期化
mkdir indeed-スクレイパー
cd indeed-スクレイパー
python -m venv envLinuxまたはmacOSでは、以下のコマンドを実行して環境を有効化します:
./env/bin/activate
Windowsの場合は以下を実行:
envScriptsactivate.ps1
次に、プロジェクトフォルダ内に以下の行を含むscraper.py ファイルを初期化します:
print("Hello, World!")
現時点では「Hello, World!」を出力するだけですが、まもなくIndeedのスクレイピングロジックが含まれるようになります。
動作確認のため、以下を実行します:
python スクレイパー.py
計画通りに進んだ場合、ターミナルに次のメッセージが表示されます:
Hello, World!
スクリプトが動作することを確認できたので、Python IDEでプロジェクトフォルダを開いてください。
よくできました!Pythonコードを書く準備をしましょう!
ステップ2: スクラッピングライブラリのインストール
前述の通り、Indeedからの求人情報のウェブスクレイピングにはSeleniumが非常に有効です。プロジェクトの依存関係に追加するため、アクティブなPython仮想環境で以下のコマンドを実行してください:
pip install selenium
時間がかかる場合がありますので、しばらくお待ちください。
本チュートリアルでは自動ドライバー検出機能を備えたSelenium 4.11.2を参照しています。PCに古いバージョンのSeleniumがインストールされている場合は、以下で更新してください:
pip install selenium -U
次に、scraper.py をクリアします。その後、パッケージをインポートし、以下のコマンドで Selenium スクレイパーを初期化します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 制御可能なChromeインスタンスを設定
# ヘッドレスモードで
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# スクラッピングロジック...
# ブラウザを閉じリソースを解放
driver.quit()
このスクリプトは、Chromeインスタンスをプログラムで制御するためのWebDriverインスタンスを生成します。ブラウザはバックグラウンドでヘッドレスモード(GUIなし)で開かれます。これは本番環境での一般的な設定です。代わりに、ウェブスクレイピングジョブスクリプトがページ上で実行する操作を追跡したい場合は、そのオプションをコメントアウトしてください。これは開発時に便利です。
Python IDEがエラーを報告しないことを確認してください。未使用のインポートによる警告は無視してください。これからGitHubからリポジトリデータを抽出するライブラリを使用します!
完璧です!さあ、Indeed Pythonウェブスクレイパーを構築しましょう。
ステップ3: 対象ウェブページへの接続
Indeedを開き、興味のある求人を検索してください。このガイドでは、ニューヨークのソフトウェアエンジニア向けリモート求人情報をスクレイピングする方法を紹介します。他のIndeed求人検索でも同様の手順でスクレイピングできます。スクレイピングのロジックは同じです。
執筆時点でのターゲットページのブラウザ表示は以下の通りです:
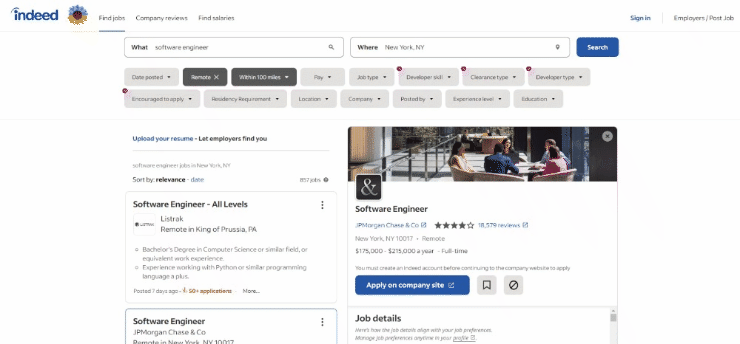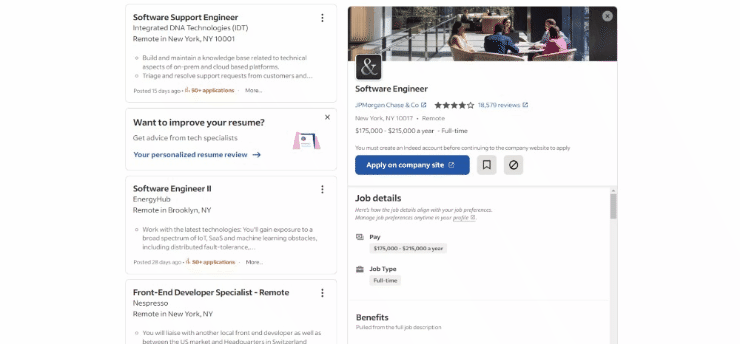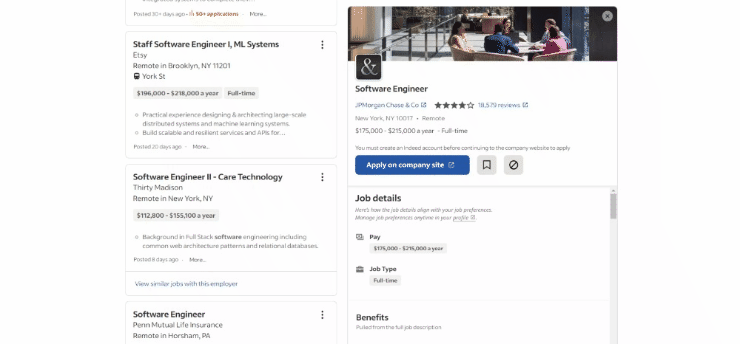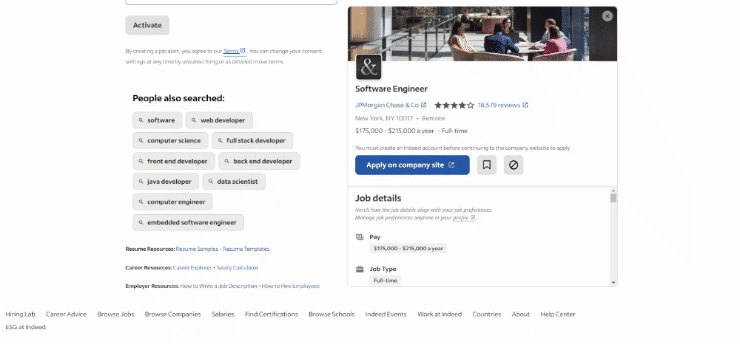
具体的には、対象ページのURLは以下のようになります:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
ご覧の通り、クエリパラメータに基づいて変化する動的URLです。
Seleniumを使用して対象ページに接続するには、以下のようにします:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
get()関数は、パラメータとして渡されたURLで指定されたページをブラウザに訪問するよう指示します。
ページを開いた後、全ての要素が表示されるようウィンドウサイズを設定します:
driver.set_window_size(1920, 1080)
現時点でのIndeedスクレイピングスクリプトは以下のようになります:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 制御可能なChromeインスタンスを
# ヘッドレスモードで設定
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# ページがレスポンシブモードでレンダリングされないよう
# ウィンドウサイズを設定
driver.set_window_size(1920, 1080)
# 対象ページをブラウザで開く
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# スクラッピングロジック...
# ブラウザを閉じてリソースを解放
driver.quit()
ヘッドレスモードを有効にするオプションをコメントアウトし、スクリプトを実行します。以下のウィンドウがほんの一瞬だけ開いた後、閉じます:
「Chromeは自動化されたソフトウェアによって制御されています」という免責事項に注意してください。これはSeleniumが正常に動作していることを保証します。
ステップ4: ページ構造の把握
スクレイピングに取り掛かる前に、もう1つ重要なステップがあります。サイトからデータをスクレイピングするには、HTML要素を選択し、そこからデータを抽出する必要があります。DOMから目的のノードを取得する方法は必ずしも簡単ではありません。効果的な選択戦略を定義する方法を理解するために、ページの構造を分析する時間を割くべき理由がここにあります。
ブラウザを開き、Indeedの求人検索ページにアクセスします。任意の要素を右クリックし、「要素を検査」オプションを選択してブラウザのDevToolsを開きます:
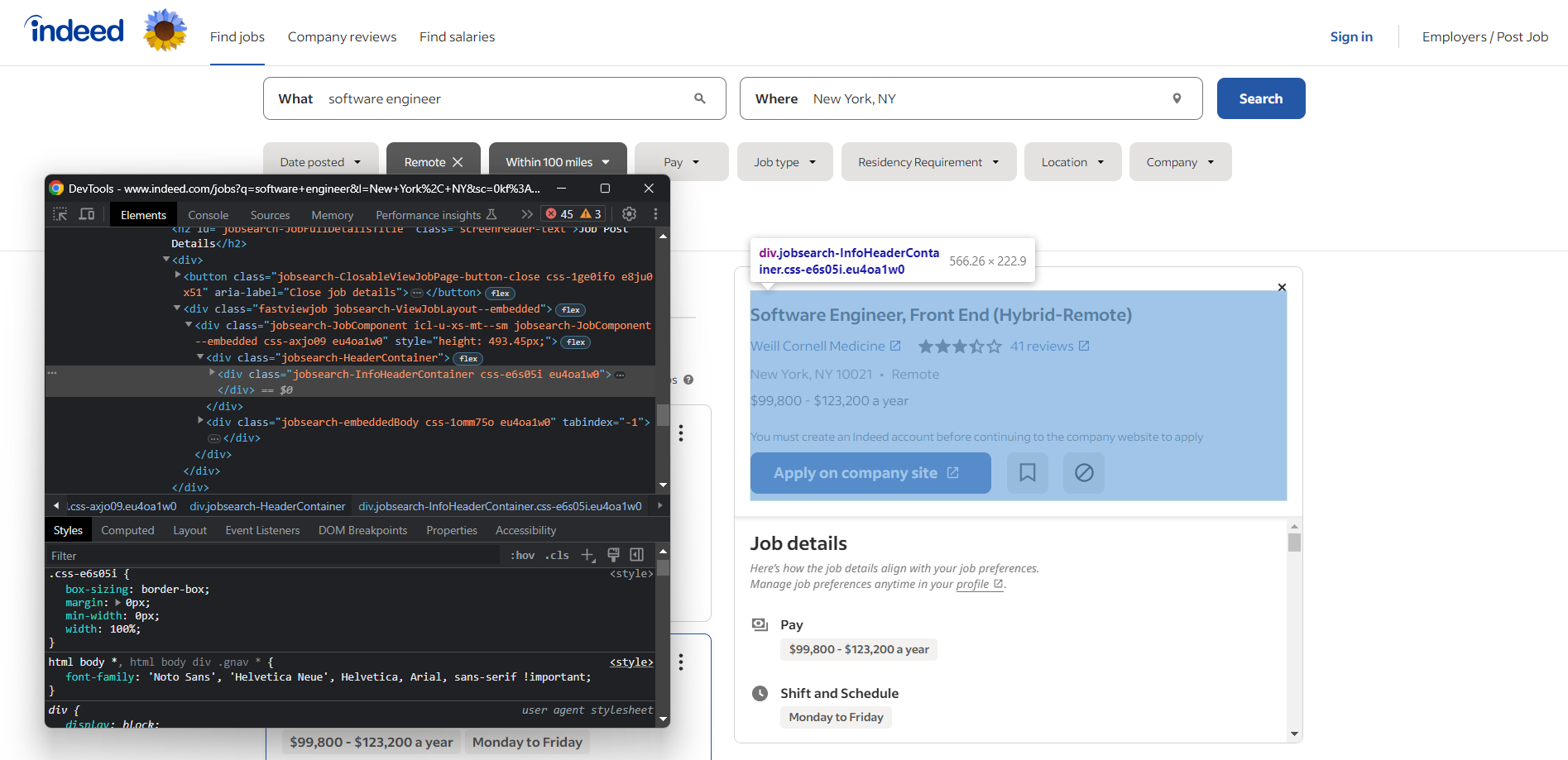
ここで、有用なデータを含む要素のほとんどが、以下のようなCSSクラスを持っていることがわかります:
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
これらはコンパイル時にランダムに生成されているように見えるため、スクレイピングに依存すべきではありません。代わりに、次のようなクラスに基づいて選択ロジックを構築する必要があります:
jobsearch-JobInfoHeader-titledatecardOutline
または以下のようなIDを使用してください:
companyRatingsapplyButtonLinkContainerjobDetailsSection
また、一部のノードには固有のHTML属性がある点に注意してください:
data-company-namedata-testid
これはIndeedからのウェブスクレイピング作業において留意すべき有用な情報です。ページと対話し、その反応や表示されるデータを研究してください。異なる求人には異なる情報属性が存在することに気付くでしょう。
次のステップに進む準備が整うまで、対象サイトを継続的に調査し、そのDOM構造に慣れ親しんでください。
ステップ5: 求人データの抽出を開始
Indeedの検索結果ページには複数の求人情報が表示されます。そのため、ページからスクレイピングした求人情報を管理するために配列が必要です:
jobs = []前のステップで気づいた通り、求人情報は.cardOutlineカードで表示されています:
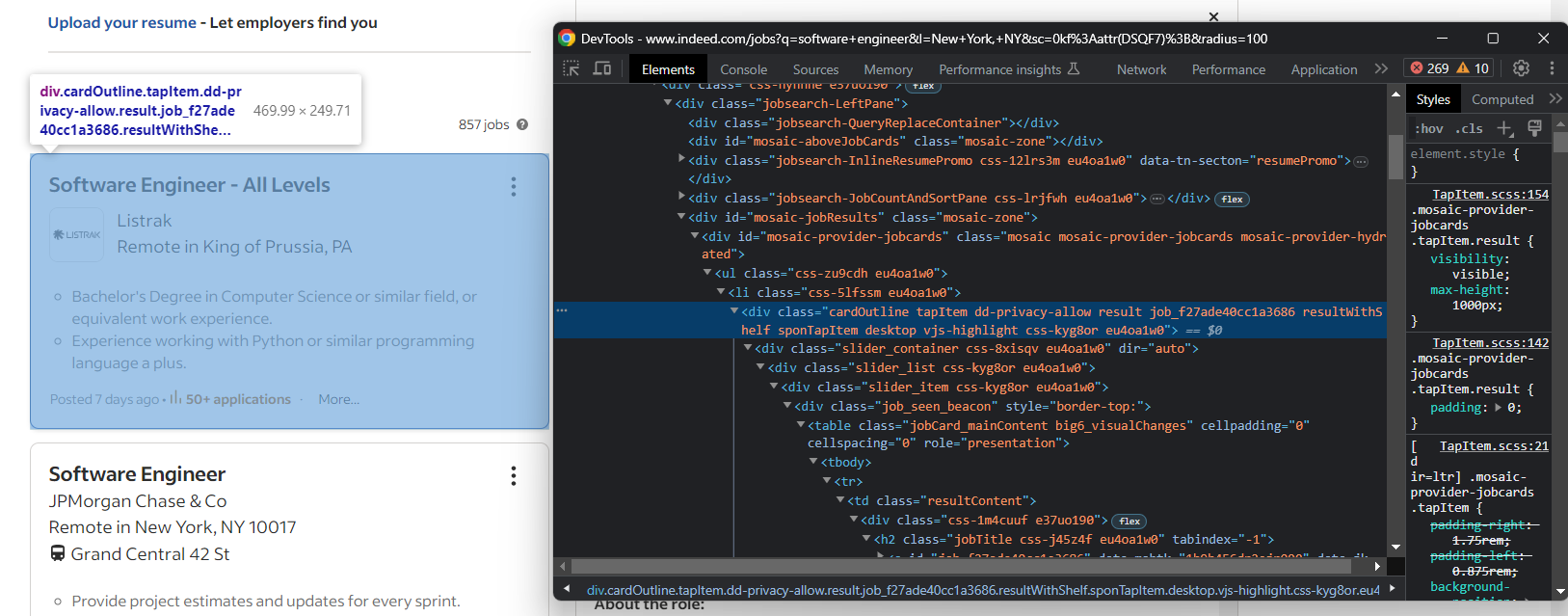
以下のコードで全てを選択します:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
Seleniumのfind_elements()メソッドは、ウェブページ上の要素を特定します。同様に、選択クエリに一致する最初のノードを取得するfind_element()メソッドも存在します。
By.CSS_SELECTOR は、CSS セレクタ戦略を使用するようドライバーに指示します。Selenium は以下もサポートしています:
By.ID:HTMLのid属性で要素を検索By.TAG_NAME: HTMLタグに基づいて要素を検索By.XPATH: XPath式による要素検索
By のインポート:
from selenium.webdriver.common.by import By
求人カードの一覧を反復処理し、求人詳細を格納するPython辞書を初期化:
for job_card in job_cards:
# スクレイピングした求人データを格納する辞書を初期化
job = {}
# 求人データ抽出ロジック...
求人投稿には複数の属性があります。必須属性はごく一部であるため、デフォルト値を持つ変数リストをすぐに初期化します:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
ページの内容を理解したところで、一部の詳細情報は概要ジョブカードに表示され、その他の情報はインタラクション時に表示される詳細タブにあることがわかります。
例えば、作成日と応募者数は概要タブにあります:
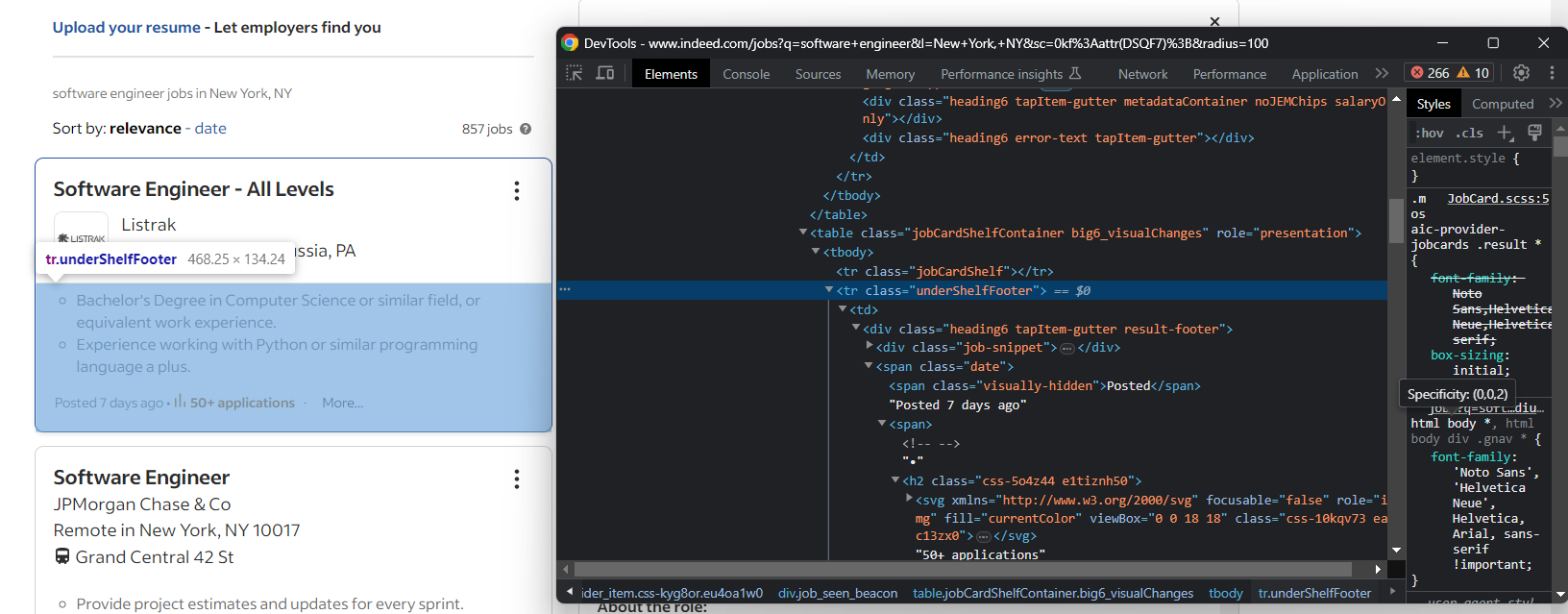
両方を抽出するには以下を実行:
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
このスニペットは、Indeedから求人情報をウェブスクレイピングする際に重要なパターンをいくつか示しています。ほとんどの情報要素はオプションであるため、以下のエラーに対する保護が必要です:
selenium.common.exceptions.NoSuchElementException: Message: no such element
Seleniumは、ページ上に存在しないHTML要素を選択しようとした際にこの例外を発生させます。
例外をインポートするには:
from selenium.common import NoSuchElementException
try ... catch構文により、対象要素がDOM上に存在しない場合でもスクリプトが正常に継続されます。
また、一部のジョブ情報は以下のような文字列に含まれています:
<info_1> • <info_2>
<info_2> が欠落している場合、文字列形式は代わりに次のようになります:
<info_1>
したがって、「•」文字の有無に基づいてデータ抽出ロジックを変更する必要があります。
HTML要素に対しては、text属性でテキストコンテンツにアクセスできます。Pythonのreplace()関数を使用して収集した文字列をクリーンアップしてください。
ステップ6: Indeedのスクレイピング対策への対応
Indeedはボットによるデータアクセスを防ぐため、いくつかの技術を採用しています。例えば、求人カードとのやり取り中に、以下のようなモーダルが頻繁に表示される傾向があります:
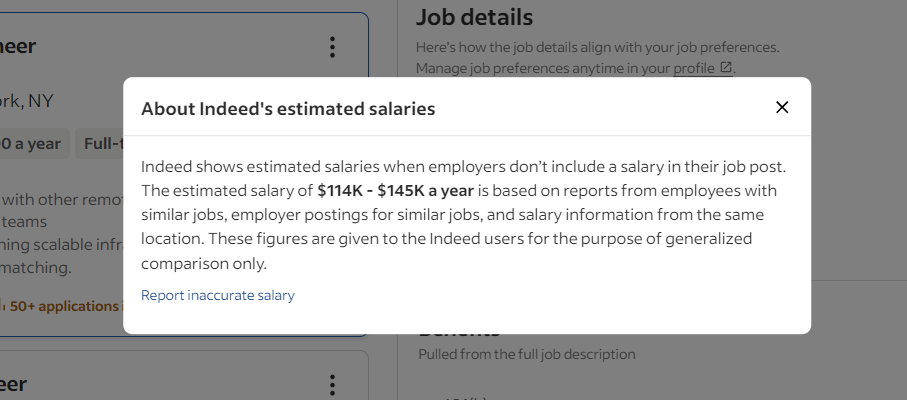
このポップアップは操作をブロックします。適切に対処しないと、Selenium Indeedスクリプトが停止します。開発者ツールでこれを検査し、閉じるボタンに注目してください:
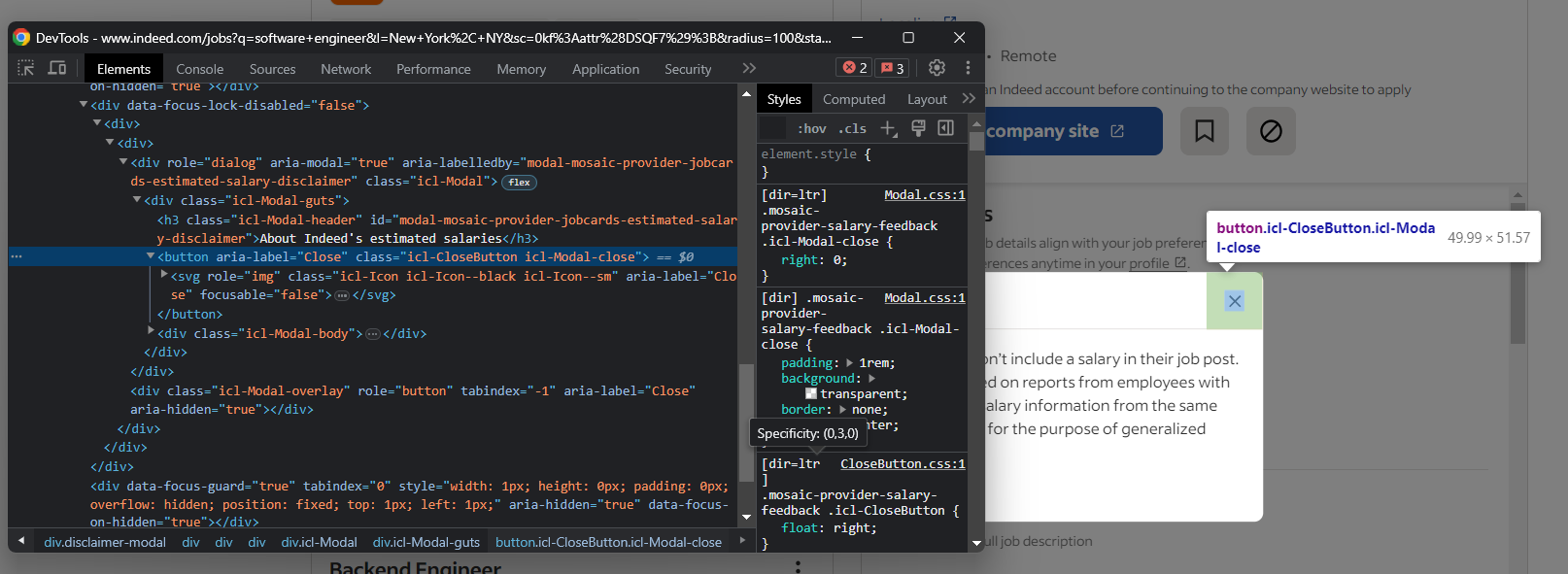
Seleniumでこのモーダルを閉じるには以下を実行:
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
Seleniumのclick()メソッドを使用すると、制御対象のブラウザ内で選択した要素をクリックできます。
これでポップアップが閉じられ、操作を続行できます。
真剣に考慮すべきもう一つのデータ保護技術がCloudflareです。ページとのやり取りが過剰になりリクエストが多すぎると、Indeedはこのボット対策画面を表示します:
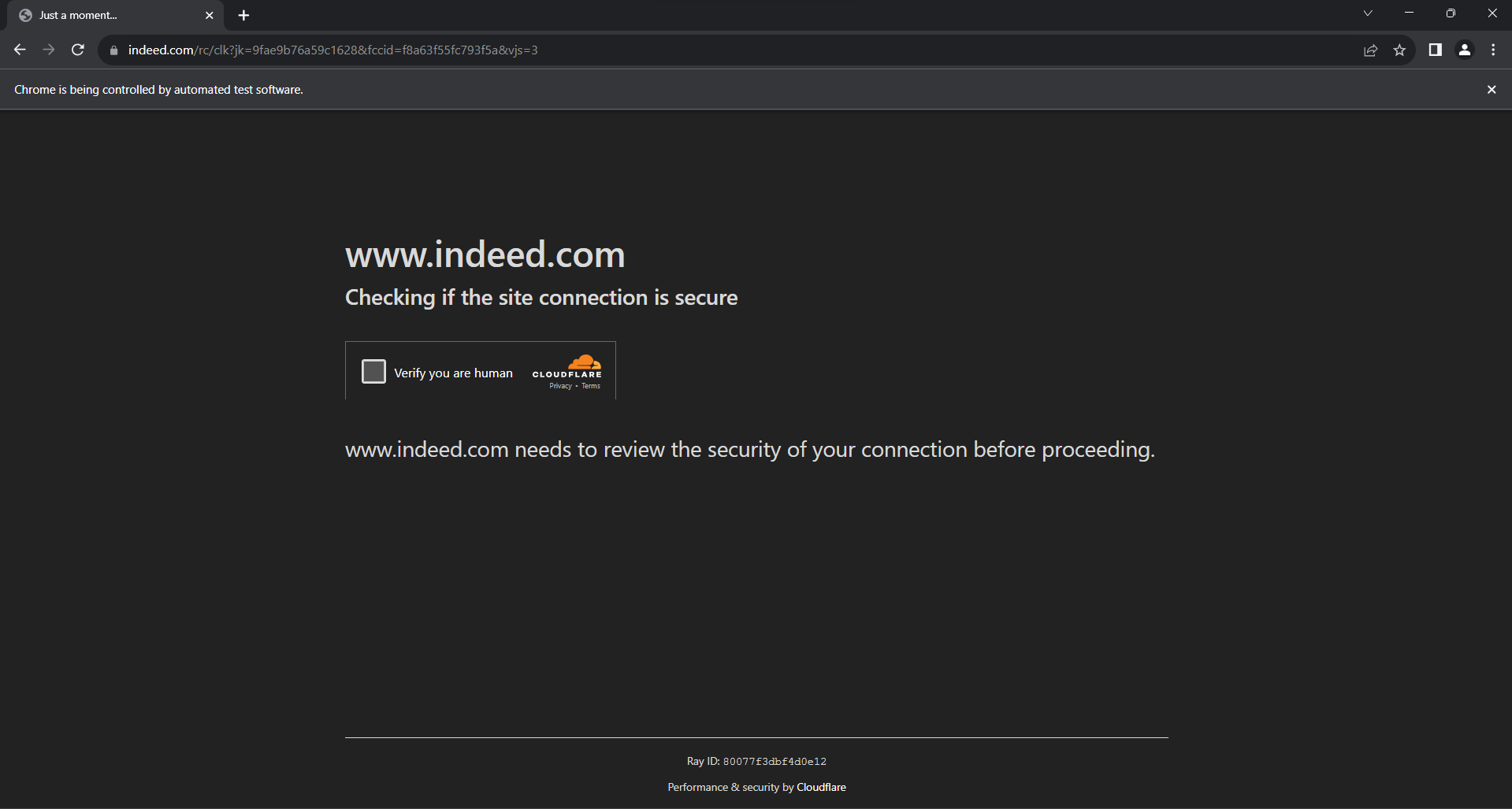
SeleniumからCloudflareのCAPTCHAの解決は非常に困難な作業であり、有料製品が必要です。結局のところ、Indeedのスクレイピングはそれほど簡単ではありません。幸い、スクリプトにランダムな遅延を導入することで回避できます。
forループの最終操作を必ず以下のように設定してください:
time.sleep(random.uniform(1, 5))
これによりスクリプトは1~5秒の間でランダムな時間停止します。
必要なパッケージをPython標準ライブラリからインポートします:
import random
import time
これで完了です!自動化されたスクリプトがIndeedからスクレイピングするのを止めるものは何もありません。
ステップ7: 求人詳細カードを開く
概要ジョブカードをクリックすると、IndeedはAJAX呼び出しを実行し、その場で詳細を取得します。このデータを待つ間、ページにはアニメーション付きのプレースホルダーが表示されます:
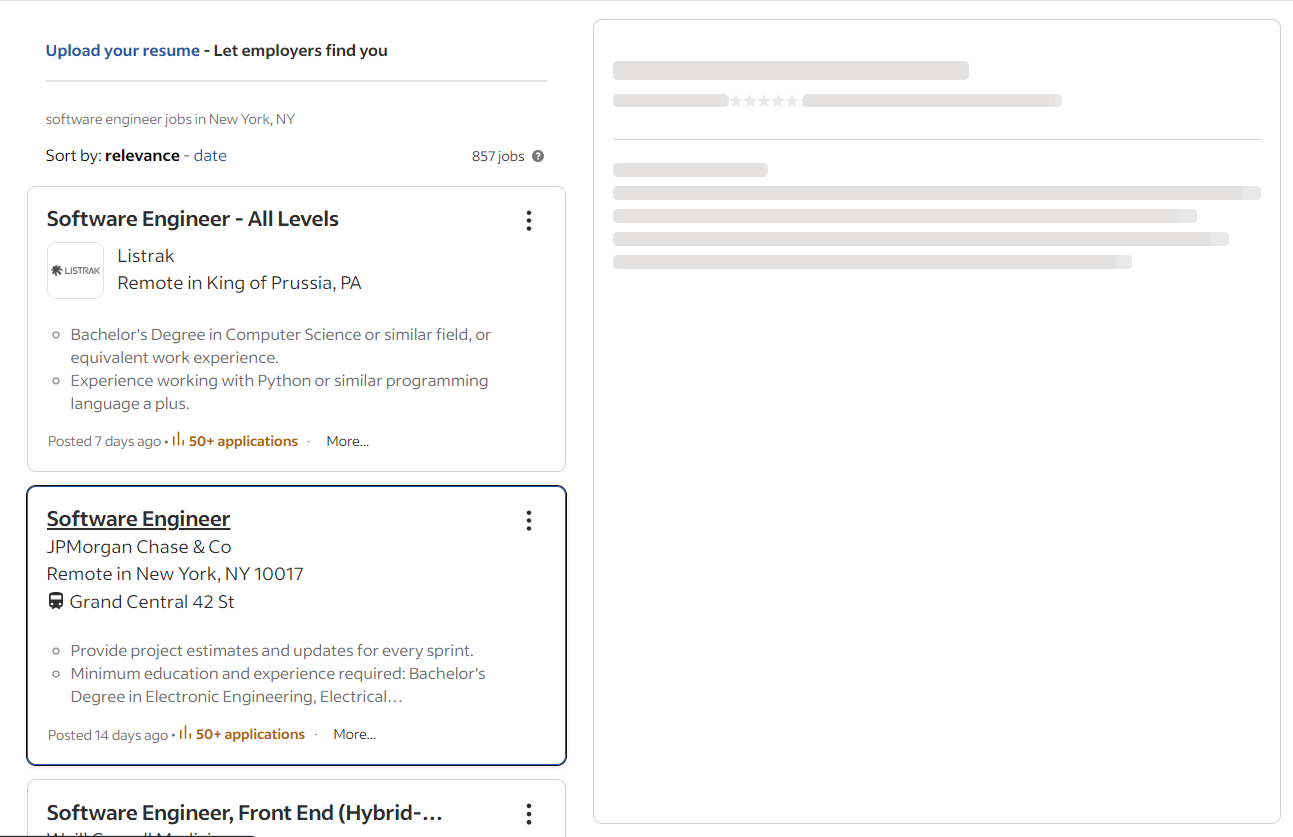
以下の要素がページ上に表示された時点で、詳細セクションが読み込まれたことを確認できます:
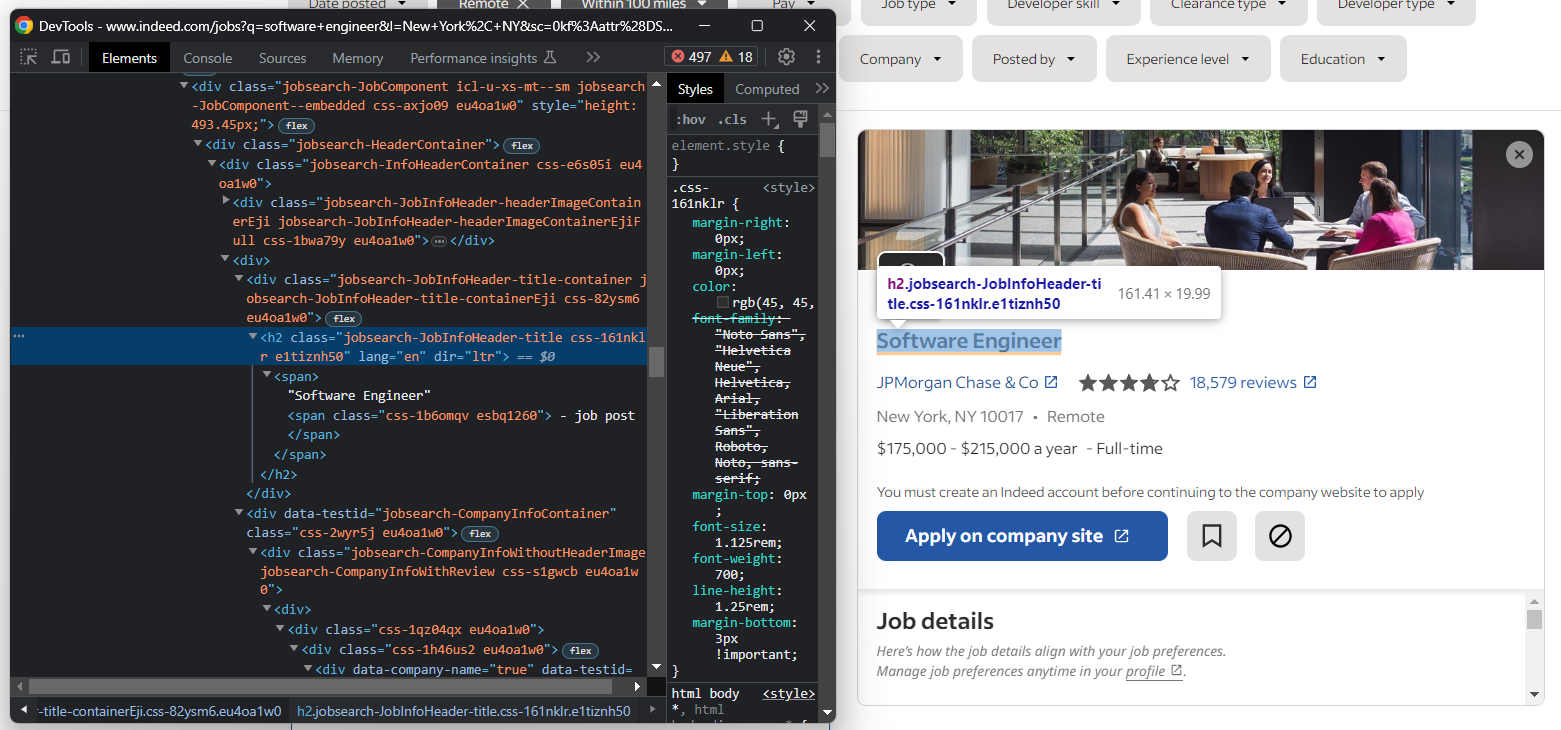
したがって、Seleniumで求人詳細データにアクセスするには以下の操作が必要です:
- クリック操作を実行する
- 対象データがページに表示されるまで待機
これを実現するには:
job_card.click()
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
SeleniumのWebDriverWaitオブジェクトは、特定の条件が発生するまで待機することを可能にします。この場合、スクリプトは.jobsearch-JobInfoHeader-titleがページ上に表示されるまで最大5秒間待機します。その後、TimeoutExceptionをスローします。
なお、上記のスニペットでは求人情報のタイトルも取得しています。
WebDriverWaitとECをインポート:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
以降、注目すべき要素はこの詳細列です:
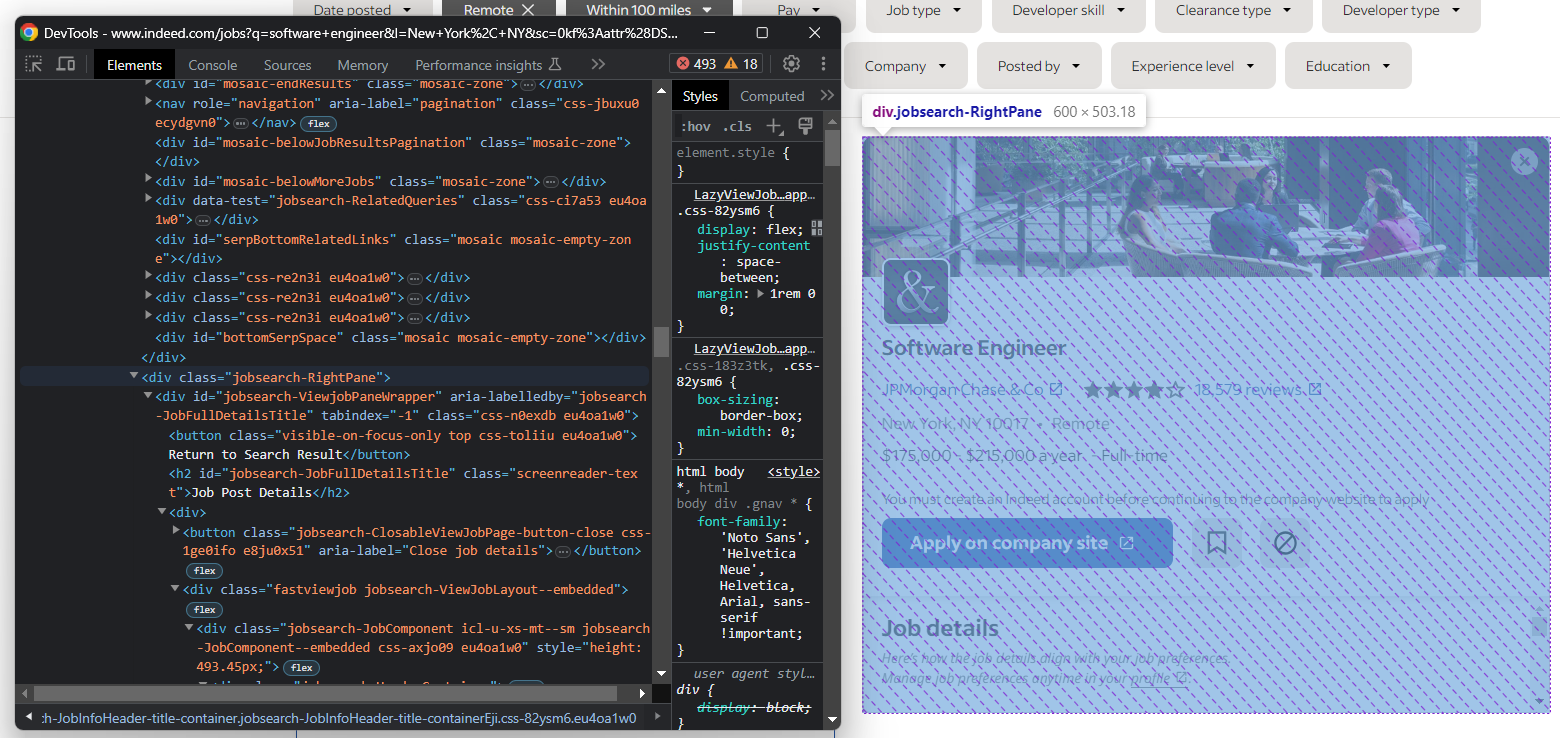
以下で選択します:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
素晴らしい!これで求人データのスクレイピング準備が整いました!
ステップ8: 求人詳細の抽出
ステップ4で定義した変数に求人データを格納しましょう。
求人情報を掲載している企業の名前を取得します:
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
次に、企業のユーザー評価とレビュー数を抽出します:
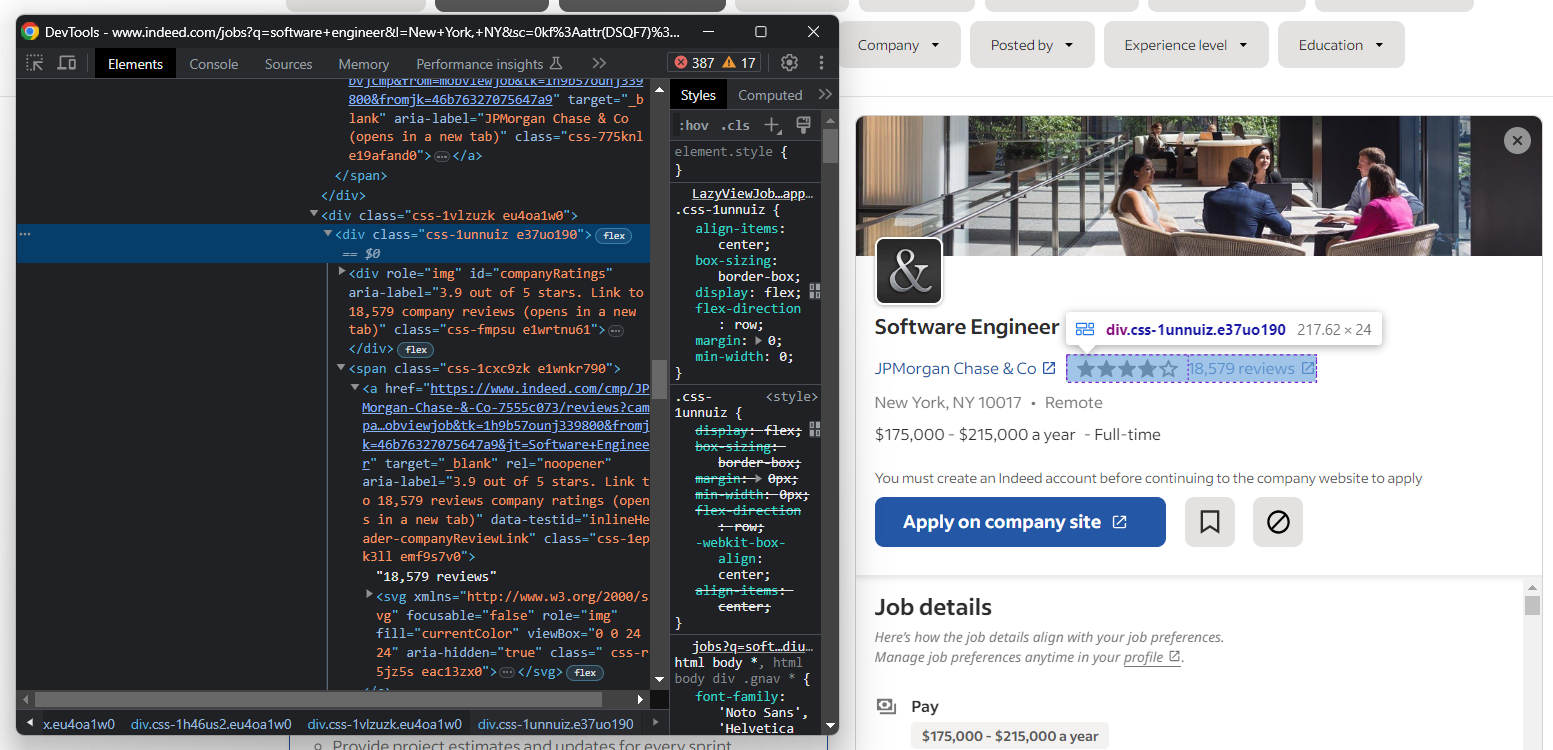
ご覧の通り、レビュー数を保持する要素に簡単にアクセスする方法はありません。
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
次に、会社の所在地に焦点を当てます:
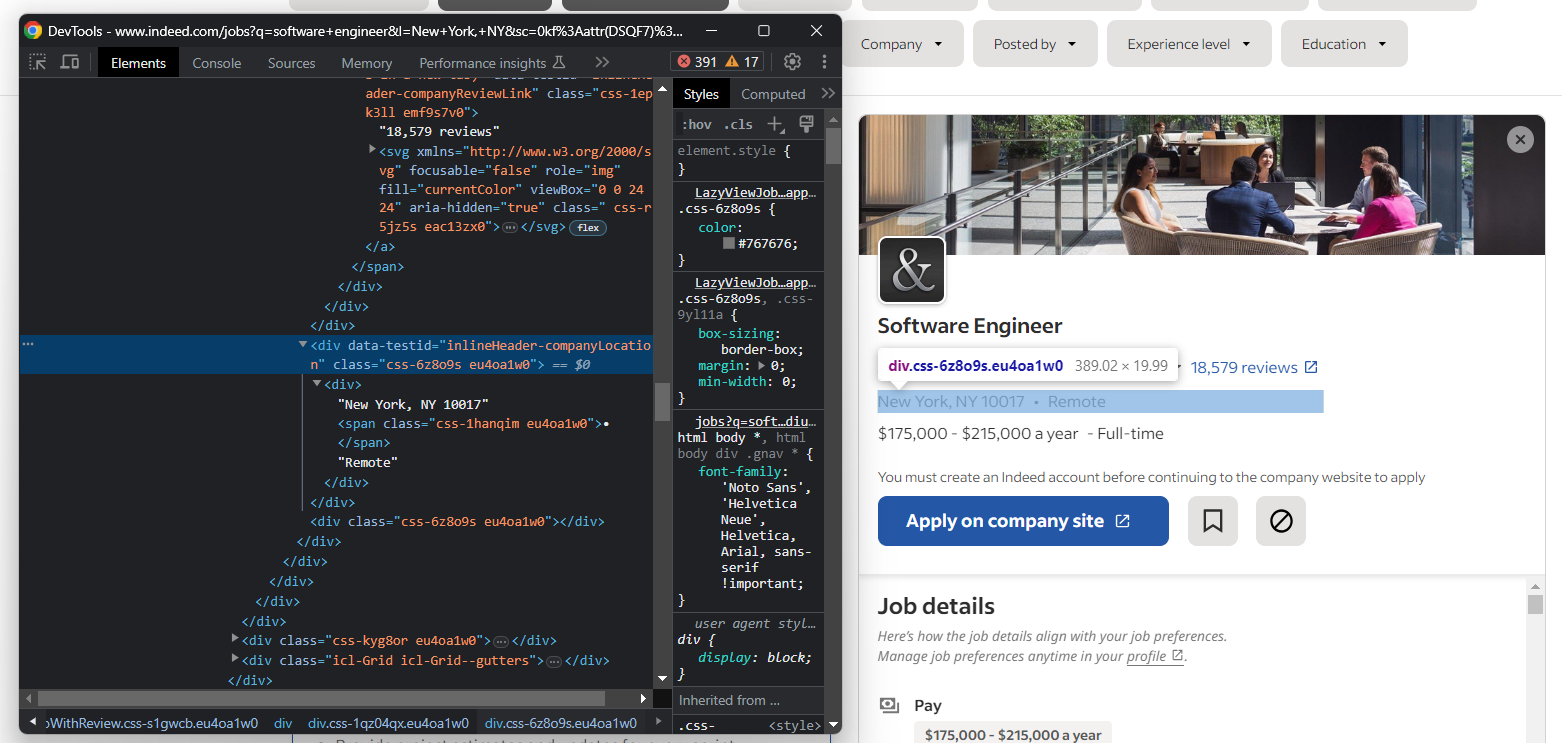
ここでも、ステップ4で述べた「``•``」パターンを適用する必要があります:
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
すぐに応募したい場合は、Indeedの「企業サイトで応募」ボタンもご確認ください:
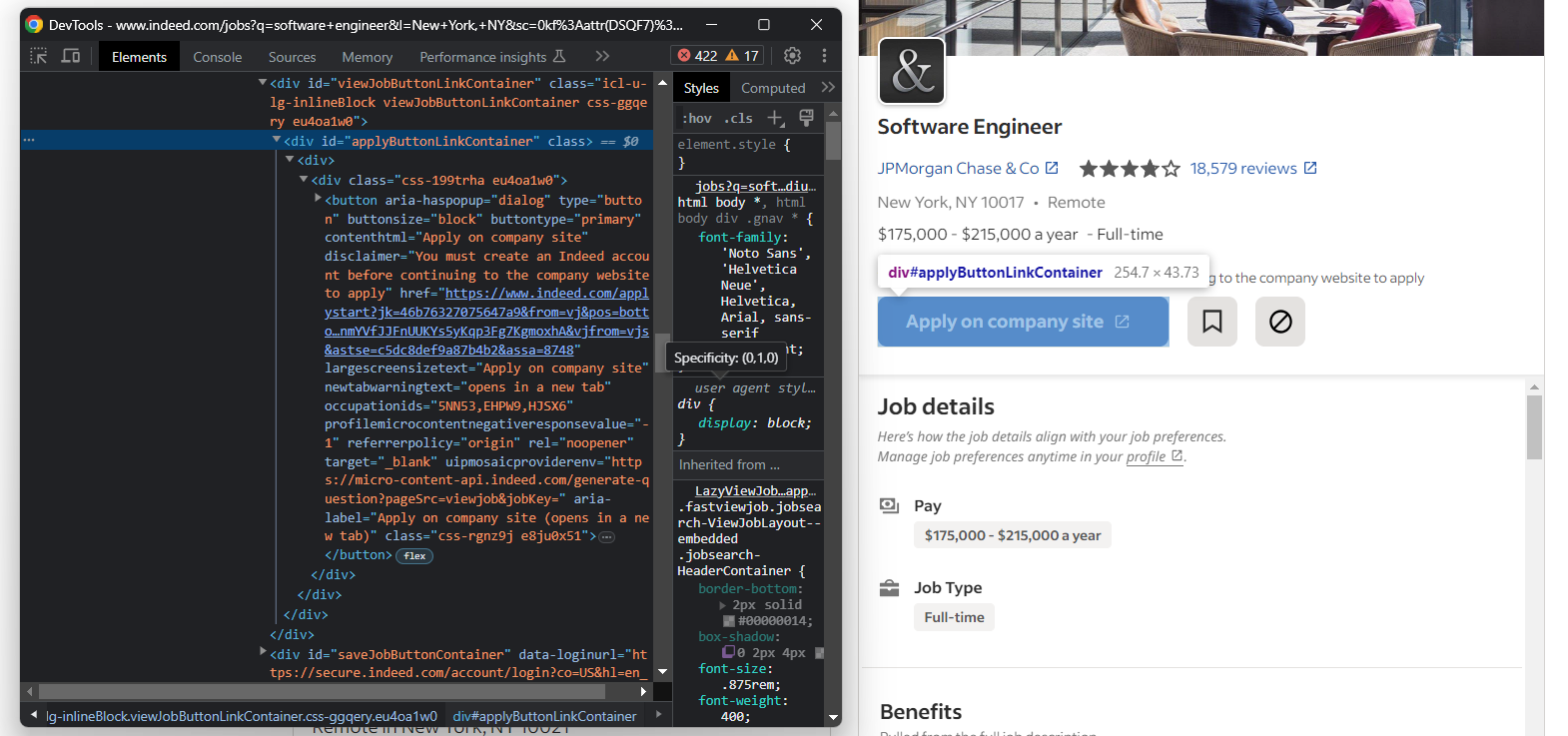
ボタンのターゲットURLを取得するには:
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
Seleniumのget_attribute()は指定されたHTML属性の値を返します。
ここからが難しい部分です。
「Job details」セクションを調査すると、給与と職種要素を簡単に選択する方法がないことに気づくでしょう:
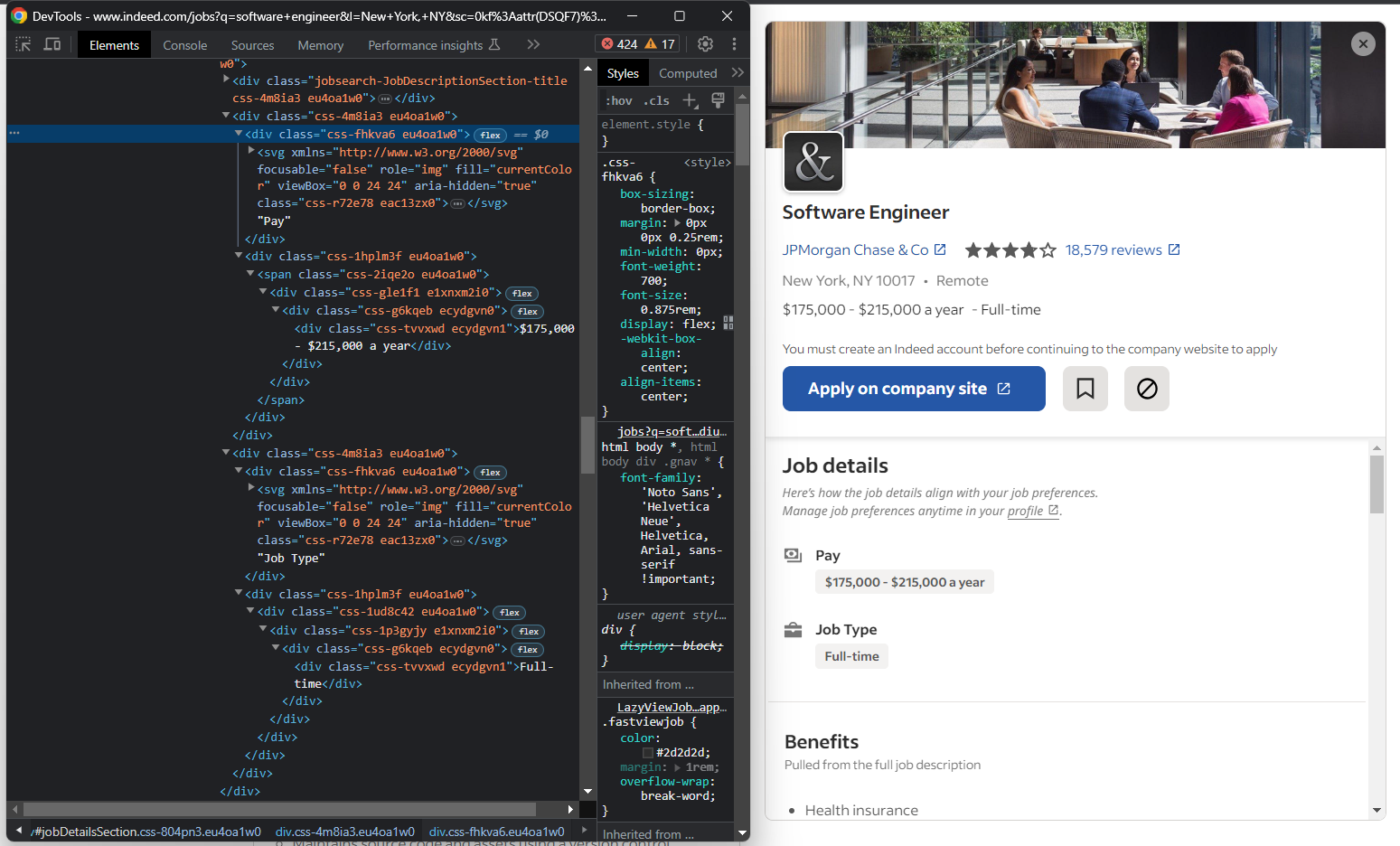
実行可能な方法は次の通りです:
- 「Job details」
<div>内の全ての<div>を取得する - それらを反復処理する
- 現在の
<div>のテキストに「給与」または「職種」が含まれる場合、次の直下の子要素を取得 - 目的のデータを抽出する
つまり、以下のロジックを実装する必要があります:
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
Seleniumはノードの兄弟要素にアクセスするユーティリティメソッドを提供していません。代わりに、following-sibling::* XPath式を使用できます。
次に、職務の福利厚生に焦点を当てます。通常、複数の項目が存在します:
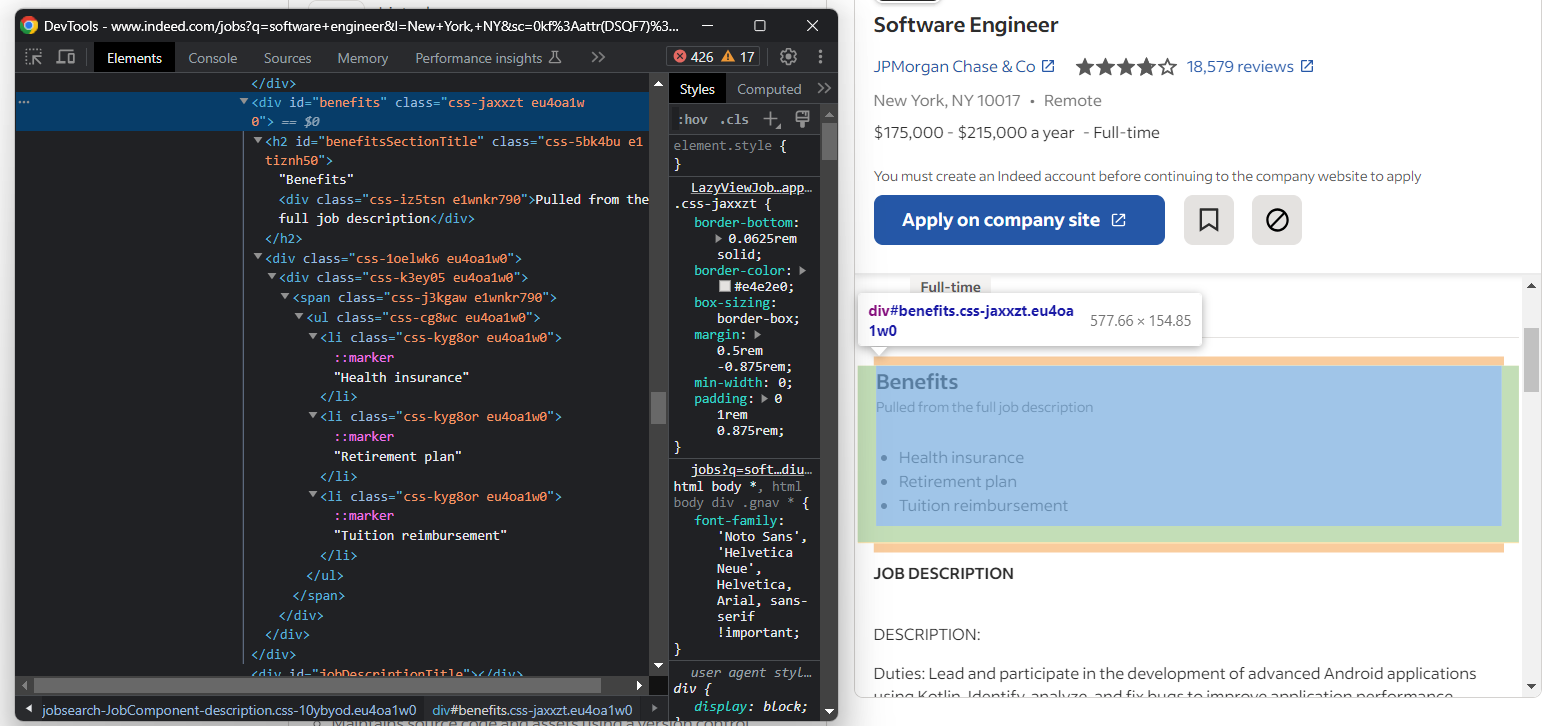
これらをすべて取得するには、リストを初期化し、以下のように要素を追加します:
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
最後に、生の職務内容を取得します:
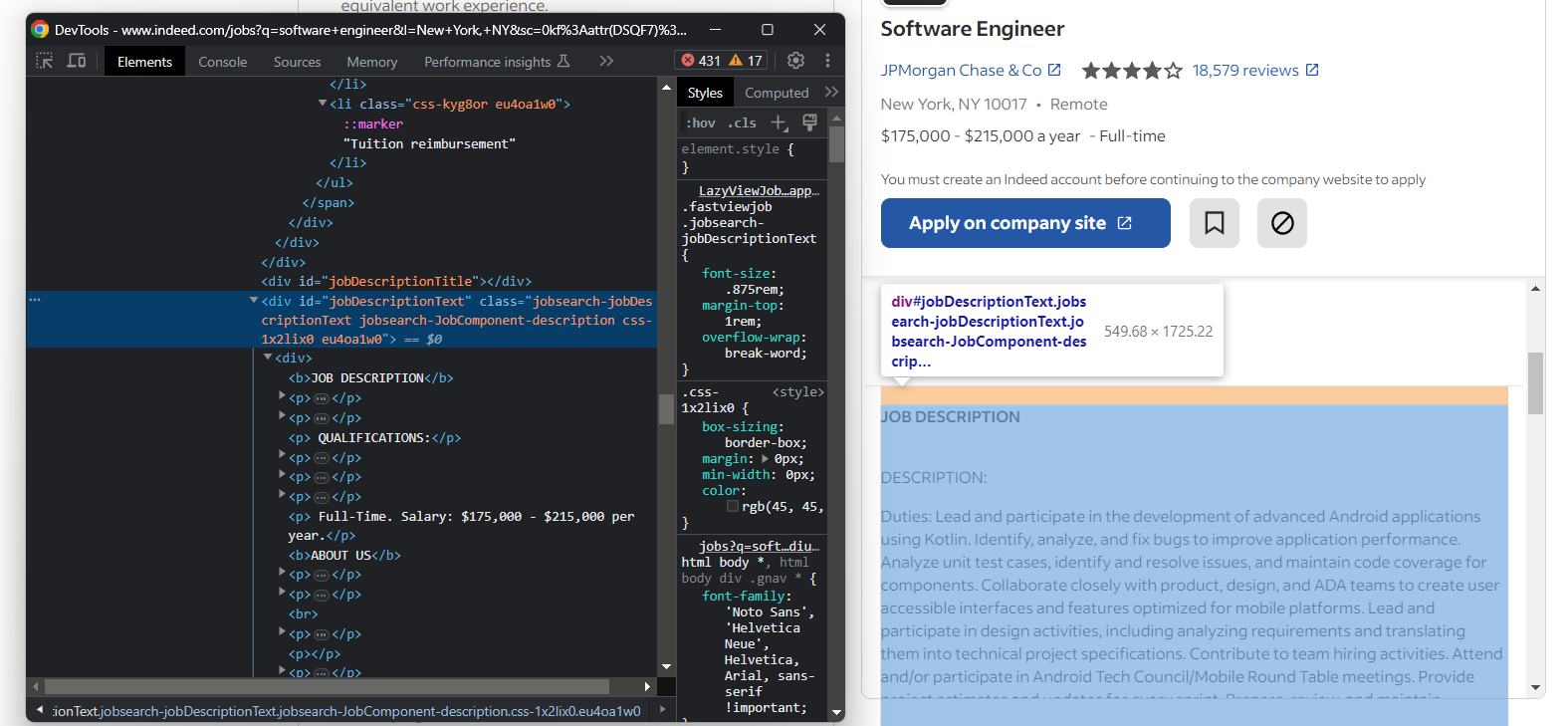
説明文のテキストを抽出します:
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
求人辞書にデータを格納し、求人リストに追加:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
スクリプトが期待通りに動作することを確認するためのログ出力も追加できます:
print(job)
スクリプトを実行:
python スクレイパー.py
出力例:
{'posted_at': '17 days ago', 'applications': '50+', 'title': 'Software Support Engineer', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3.5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'location_type': 'Remote', 'apply_link': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '年俸80,000~100,000ドル', 'job_type': 'フルタイム', 'benefits': ['401(k)', '401(k) マッチング', '歯科保険', '健康保険', '有給育児休暇', '有給休暇', '育児休暇', '視力保険'], 'description': "Integrated DNA Technologies (IDT) はカスタムオリゴヌクレオチドおよび独自技術の主要メーカーであり(簡略化のため省略...)"}
さあ、これでウェブサイトから求人情報をスクレイピングする方法がわかりました。
ステップ9: 複数の求人情報ページをスクレイピングする
Indeedでの典型的な求人検索では、数十件の結果がページ分割されたリストで表示されます。各ページのスクレイピング方法を確認しましょう!
まず、ページを検証し、Indeedの動作を確認しましょう。具体的には、次のページが存在する場合、以下の要素が表示されます。
次のページが存在しない場合、この要素は欠落します:
Indeedは数百件の求人リストを返す可能性があることに留意してください。スクリプトが無限に実行されないよう、スクレイピングするページ数に制限を設けることを検討しましょう。
SeleniumでIndeedのウェブクローリングを実装するには:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# スクレイピング処理...
pages_scraped += 1
# 最終ページでない場合、次のページへ移動
# そうでない場合、whileループを終了
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
Indeedスクレイパーは、最終ページに到達するか5ページ分処理するまでループを継続します。
ステップ10: スクレイピングしたデータをJSONにエクスポート
現在、スクレイピングされたデータはPythonの辞書リストに格納されています。共有や読み取りを容易にするため、JSON形式でエクスポートします。
まず出力オブジェクトを作成します:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
求人掲載日が「<X>日前」という形式で表示されるため、日付属性は必須です。データをスクレイピングした日付の文脈がなければ、理解が困難になります。
datetimeのインポートを忘れないでください:
from datetime import datetime
次に、以下のようにエクスポートします:
import json
# スクレイピングロジック...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
上記のスニペットはopen() でjobs.json出力ファイルを初期化し、json.dump()でJSONデータを書き込んでいます。PythonでのJSONデータパース・シリアライズの詳細は当記事を参照してください。
jsonパッケージはPython標準ライブラリに含まれるため、目的を達成するために追加の依存関係をインストールする必要すらありません。
すごい!ウェブページに含まれる生の求人データから始まり、今では半構造化JSONデータを得ました。これでIndeedのPythonウェブスクレイピングスクリプト全体を確認する準備が整いました。
ステップ11: 全体を統合する
以下が完全なscraper.py ファイルです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# 制御可能なChromeインスタンスを設定
# ヘッドレスモードで実行
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# ブラウザで対象ページを開く
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# ページがレスポンシブモードでレンダリングされないようウィンドウサイズを設定
driver.set_window_size(1920, 1080)
# ページからスクレイピングした求人情報を格納するデータ構造
jobs = []
pages_scraped = 0
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# ページ上の求人カードを選択
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# スクレイピングした求人データを格納する辞書を初期化
job = {}
# スクレイピング対象の求職属性初期化
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# アウトラインカードから一般的な求人データを取得
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
# アンチスクレイピングモーダルを閉じる
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# 求人詳細カードを読み込む
job_card.click()
# クリック後、求人詳細セクションの読み込みを待機
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
# 求人詳細を抽出
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
# スクレイピングしたデータを保存
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# レート制限によるブロックを回避するため、1~5秒の間でランダムな秒数待機
time.sleep(random.uniform(1, 5))
# スクレイピングカウンターをインクリメント
pages_scraped += 1
# 最終ページでない場合、次のページへ移動
# そうでない場合、whileループを終了
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# ブラウザを閉じてリソースを解放
driver.quit()
# 出力オブジェクトを生成
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# JSON形式でエクスポート
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
わずか200行未満のコードで、Indeedから求人データをウェブスクレイピングする完全な機能を備えたスクレイパーを構築しました。
以下のコマンドで実行します:
python スクレイパー.py
スクリプトが完了するまで数分待ちます
スクレイピング終了後、プロジェクトのルートフォルダにjobs.jsonファイルが生成されます。開くと以下が表示されます:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 days ago",
"applications": "50+",
"title": "Software Engineer - All Levels",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"ジム会員権",
"有給休暇"
],
"description": "Listrakについて:n当社はSaaS企業であり、1,000社以上の主要小売業者やブランドから信頼される統合デジタルマーケティングプラットフォームを提供しています。メール、テキストメッセージマーケティング、アイデンティティ解決、行動トリガー、クロスチャネルオーケストレーションに対応しています。本社は(簡略化のため省略...)にあります。"
},
// 簡略化のため省略...
{
"posted_at": "9日前",
"applications": null,
"title": "ソフトウェアエンジニア(フロントエンド)(ハイブリッド勤務)",
"company_name": "ワイル・コーネル・メディシン",
"company_rating": "3.4",
"company_reviews": "41",
"location": "New York, NY 10021",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
"pay": "$99,800 - $123,200 a year",
"job_type": null,
"benefits": null,
"description": "Title: Software Engineer, Front End (Hybrid-Remote)nTitle: ソフトウェアエンジニア、フロントエンド(ハイブリッド・リモート)n勤務地:アッパーイーストサイドn所属組織:オリビエ・エレメント研究所n勤務日:月曜日~金曜日n免除ステータス:免除n給与範囲:$99,800.00 ~ $123,200.00n(省略...)"
}
}
おめでとう!PythonでIndeedをスクレイピングする方法が学べました!
まとめ
このチュートリアルでは、Indeedがウェブ上で最高級の求人ポータルである理由と、そこからデータを抽出する方法を理解しました。特に、Indeedから求人情報を取得できるPythonスクレイパーの構築方法を学びました。
ここで示した通り、Indeedのスクレイピングは最も簡単な作業ではありません。このサイトには、スクリプトをブロックする可能性のある巧妙な反スクレイピング対策が施されています。このようなサイトに対処するには、CAPTCHA、フィンガープリンティング、自動リトライなどを自動的に処理できる制御可能なブラウザが必要です。これこそが、当社の新しいスクレイピングブラウザソリューションの真髄です!
ウェブスクレイピング自体には関心がなく、求人データのみが必要な方へ。当社のIndeedデータセットおよび求人情報データセットをご検討ください。今すぐ登録して無料トライアルを開始しましょう。
注:本ガイドは執筆時点で当社チームにより徹底的にテストされていますが、ウェブサイトはコードや構造を頻繁に更新するため、一部の手順が期待通りに機能しなくなる可能性があります。



