

Perlは最も人気のある言語の一つであり、豊富なモジュール群のおかげで、ウェブスクレイパー作成に最適な選択肢です。
本記事では以下の内容を解説します:
- 以下の手法を用いたPerlによるウェブスクレイピングの方法:
LWP::UserAgentとHTML::TreeBuilderWeb::スクレイパーMojo::UserAgentとMojo::DOMXML::LibXML
- Perlによるウェブスクレイピングの課題
- 結論
Perl による ウェブスクレイピング
本記事の内容を再現するには、最新のPerlがインストールされていることを確認してください。本記事のコードはPerl 5.38.2でテスト済みです。また、cpanmを使用したPerlモジュールのインストール方法をご存知であることも前提としています。
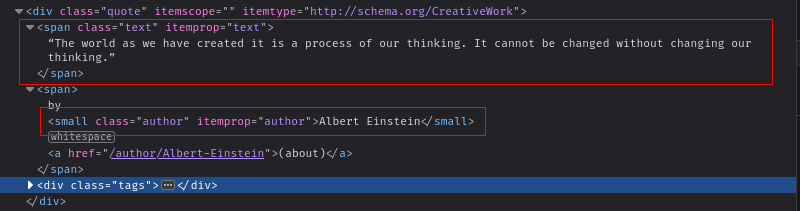
本記事では、Quotes to Scrape ウェブサイトから引用文を抽出します。ウェブサイトからデータをスクレイピングする前に、HTMLの構造を理解する必要があります。ブラウザでウェブサイトを開き、CTRL + Shift + I(Windows)またはCommand + Shift + C(Mac)を押して「要素を検査」ダイアログを開きます。
要素を検査すると、各引用文がclass=quoteのdiv内に格納されていることがわかります。各引用文には、テキストを格納するclass=textのspanと、著者名を格納するsmall要素が含まれています:
LWP::UserAgentとHTML::TreeBuilderの使用
LWP::UserAgentは、ウェブとやり取りするモジュール群であるLWP の一部です。LWP::UserAgentモジュールを使用すると、ウェブページへの HTTP リクエストを発行し、HTML コンテンツを取得できます。その後、HTML::TreeのHTML::TreeBuilderモジュールを使用して HTML をパースし、情報を抽出できます。
LWP::UserAgent とHTML::TreeBuilder を使用するには、以下のコマンドでモジュールをインストールします:
cpanm Bundle::LWP
cpanm HTML::Tree
lwp-and-tree-builder.pl という名前のファイルを作成します。ここにコードを記述します。次に、以下の2行をそのファイルに貼り付けます:
use LWP::UserAgent;
use HTML::TreeBuilder;
このコードは、PerlインタプリタにLWP::UserAgentとHTML::TreeBuilderモジュールを読み込むよう指示します。
LWP::UserAgentのインスタンスを定義し、User-Agentヘッダーを「Quotesスクレイパー」に設定します:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes スクレイパー");
対象ウェブサイトのURLを定義し、HTML::TreeBuilderのインスタンスを作成します:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
これでHTTPリクエストを実行できます:
my $request = $ua->get($url) or die "エラーが発生しました $!n";
リクエストの成功/失敗を確認するif-else文を以下に貼り付けます:
if ($request->is_success) {
} else {
print "結果をパースできませんでした。 " . $request->status_line . "n";
}
リクエストが成功した場合、スクレイピングを開始できます。
HTMLレスポンスをパースするには、HTML::TreeBuilderの parseメソッドを使用します。以下のコードをifブロック内に貼り付けてください:
$root->パース($request->content);
次に、look_downメソッドを使用してclassがquoteのdiv要素を検索します:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
引用句の配列を反復処理し、look_downでテキストと著者を検索して出力します:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
完全なコードは以下のようになります:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes スクレイパー");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "エラーが発生しました $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "結果をパースできませんでした。 " . $request->status_line . "n";
}
このコードをperl lwp-and-tree-builder.pl で実行すると、以下の出力が表示されるはずです:
"私たちが創造した世界は、私たちの思考の産物である。思考を変えずに世界を変えることはできない。":アルバート・アインシュタイン
"ハリー、私たちの本質を示すのは能力よりも、選択そのものなのだ。":J.K.ローリング
"人生を生きる方法は二つしかない。一つは、何も奇跡ではないかのように生きる方法。もう一つは、すべてが奇跡であるかのように生きる方法だ。":アルバート・アインシュタイン
「紳士であれ淑女であれ、良き小説に喜びを見出せない者は、耐え難いほど愚かなに違いない」:ジェーン・オースティン
「不完全さは美であり、狂気は天才である。そして、まったく退屈であるよりは、まったく滑稽であるほうがましだ」:マリリン・モンロー
「成功者になろうとするな。むしろ価値ある人間になれ」:アルバート・アインシュタイン
「自分ではないもので愛されるよりも、自分であるもので嫌われるほうがましだ。」:アンドレ・ジッド
「私は失敗したわけではない。ただ、うまくいかない1万通りの方法を見つけただけだ。」:トーマス・A・エジソン
「女性はティーバッグのようなもの。お湯に浸すまで、その強さはわからない」:エレノア・ルーズベルト
「太陽の光のない日は、つまり、夜のようなもの」:スティーブ・マーティン
Web::スクレイパーの使用
Web::スクレイパーは、Ruby の ScrAPI に着想を得たウェブスクレイピングライブラリです。HTML および XML ドキュメントをスクレイピングするためのドメイン固有言語 (DSL) を提供します。Ruby によるウェブスクレイピングの詳細については、こちらの記事をご覧ください。
Web::スクレイパー を使用するには、cpanm Web::スクレイパー でモジュールをインストールしてください。
web-scraper.pl という新しいファイルを作成し、以下の必要なモジュールを含めます。
use URI;
use Web::スクレイパー;
use Encode;
次に、モジュールのDSLを使用してスクレイパーブロックを定義します。DSLにより、わずか数行でスクレイパーを簡単に定義できます。$quotesという名前のスクレイパーブロックを定義することから始めます:
my $quotes = scraper {
};
スクレイパーメソッドはスクレイパーのロジックを定義し、後でscrapeメソッドが呼び出された際に実行されます。スクレイパーブロック内では、processメソッドを使用してCSSセレクタで要素を検索し、関数を実行します。
まず、quoteクラスを持つすべてのdiv要素を検索します:
# `quote`クラスを持つ全ての`div`をパース
process 'div.quote', "quotes[]" => スクレイパー {
};
このコードはquoteクラスを持つ全てのdiv要素を見つけ、quotes配列に格納します。各要素に対して、以下のように定義したスクレイパーメソッドを実行します:
# 各div内で`text`クラスを持つ`span`を検索
process_first "span.text", text => 'TEXT';
# `author`クラスを持つ`small`を取得
process_first "small", author => 'TEXT';
process_firstメソッドはCSSセレクタに一致する最初の要素を検索します。ここではtextクラスを持つ最初のspan要素を見つけ、そのテキストを抽出してtextキーに格納します。著者名については、最初のsmall要素を見つけ、テキストを抽出してauthorキーに格納します。
完全なスクレイパーブロックは以下のようになります:
my $quotes = scraper {
# クラス `quote` を持つ全ての `div` をパース
process 'div.quote', "quotes[]" => scraper {
# 各 div 内で、クラス `text` を持つ `span` を検索
process_first "span.text", text => 'TEXT';
# クラス `author` の `small` を取得
process_first "small", author => 'TEXT';
};
};
次に、scrapeメソッドを呼び出し、スクレイピングを開始するURLを渡します:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
最後に、引用文の配列を反復処理して結果を出力します:
# 配列を反復処理
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
完全なコードは以下のようになります:
use URI;
use Web::スクレイパー;
use Encode;
my $quotes = scraper {
# クラス `quote` を持つ全ての `div` をパース
process 'div.quote', "quotes[]" => scraper {
# 各 div 内で、クラス `text` を持つ `span` を検索
process_first "span.text", text => 'TEXT';
# クラス `author` の `small` を取得
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# 配列を反復処理
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
前のコードをperl web-scraper.pl で実行すると、以下の出力が得られるはずです:
"私たちが創造した世界は、私たちの思考の産物である。思考を変えずに世界を変えることはできない。":アルバート・アインシュタイン
"ハリー、私たちの本質を示すのは能力よりも、選択そのものなのだ。":J.K.ローリング
"人生を生きる方法は二つしかない。一つは、何も奇跡ではないかのように生きる方法。もう一つは、すべてが奇跡であるかのように生きる方法だ。":アルバート・アインシュタイン
「紳士であれ淑女であれ、良質な小説に喜びを見出せない者は、耐え難いほど愚かなに違いない」:ジェーン・オースティン
「不完全さは美であり、狂気は天才である。全く退屈であるよりは、全く滑稽である方がましだ」:マリリン・モンロー
「成功者になろうとするな。むしろ価値ある人間になれ」:アルバート・アインシュタイン
「自分ではないもので愛されるよりも、自分であるもので嫌われるほうがましだ。」:アンドレ・ジッド
「私は失敗したわけではない。ただ、うまくいかない1万通りの方法を見つけただけだ。」:トーマス・A・エジソン
「女性はティーバッグのようなもの。熱湯に浸けてみなければ、その強さはわからない」:エレノア・ルーズベルト
「太陽の光のない日は、まるで夜のようなもの」:スティーブ・マーティン
Mojo::UserAgent および Mojo::DOM の使用
Mojo::UserAgentおよびMojo::DOMは、Perl 用のリアルタイム Web フレームワークであるMojoliciousフレームワークの一部です。機能面では、LWP::UserAgentおよびHTML::TreeBuilder と似ています。
Mojo::UserAgent およびMojo::DOM を使用するには、次のコマンドを使用してモジュールをインストールしてください。
cpanm Mojo::UserAgent
cpanm Mojo::DOM
mojo.pl という名前の新しいファイルを作成し、Mojo::UserAgent モジュールとMojo::DOM モジュールをインクルードします:
use Mojo::UserAgent;
use Mojo::DOM;
Mojo::UserAgentのインスタンスを定義し、HTTPリクエストを実行します:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
LWP::UserAgentと同様に、リクエストが成功したかどうかを確認するために以下のif-elseブロックを使用します:
if ($res->is_success) {
} else {
print "結果をパースできませんでした。 " . $res->message . "n";
}
ifブロック内でMojo::DOMのインスタンスを初期化します:
my $dom = Mojo::DOM->new($res->body);
findメソッドを使用してquoteクラスを持つすべてのdiv要素を検索します:
my @quotes = $dom->find('div.quote')->each;
引用文の配列を反復処理し、テキストと著者名を抽出します:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
以下のコードが完全版です:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "結果をパースできません。 " . $res->message . "n";
}
このコードをperl mojo.pl で実行すると、以下の出力が得られます:
"私たちが創造した世界は、私たちの思考の産物である。思考を変えずに世界を変えることはできない。":アルバート・アインシュタイン
"ハリー、私たちの真の姿を示すのは能力よりも、選択そのものなのだ。":J.K.ローリング
"人生を生きる方法は二つしかない。一つは、何も奇跡ではないかのように生きる方法。もう一つは、すべてが奇跡であるかのように生きる方法だ。":アルバート・アインシュタイン
「紳士であれ淑女であれ、良質な小説に喜びを見出せない者は、耐え難いほど愚かなに違いない。」:ジェーン・オースティン
「不完全さは美であり、狂気は天才である。そして、完全に退屈であるよりは、完全に滑稽である方がましだ。」:マリリン・モンロー
「成功者になろうとするな。むしろ価値ある人間になれ。」:アルバート・アインシュタイン
「自分ではないもので愛されるよりも、自分であるもので嫌われるほうがましだ」:アンドレ・ジッド
「私は失敗したわけではない。ただ、うまくいかない1万通りの方法を見つけただけだ」:トーマス・A・エジソン
「女性はティーバッグのようなもの。お湯に浸けてみなければ、その強さはわからない」:エレノア・ルーズベルト
「太陽の光のない日は、まるで夜のようなもの」:スティーブ・マーティン
XML::LibXML の使用
Perl モジュールXML::LibXMLは、libxml2ライブラリをラップしたものです。XML::LibXMLモジュールは、XPath機能を備えた強力な XHTML パーサーを提供します。
cpanm を使用してモジュールをインストールします。
cpanm XML::LibXML
次に、xml-libxml.pl という新しいファイルを作成します。HTML::TreeBuilder の場合と同様に、LWP::UserAgent などのライブラリを使用して、Web サイトへの HTTP リクエストを実行し、HTML コンテンツを取得して、それをXML::LibXML に渡す必要があります。
以下のコードを貼り付けます。これはLWP::UserAgentモジュールを設定し、ウェブページのHTMLコンテンツを取得します:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes スクレイパー");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "エラーが発生しました $!n";
if ($request->is_success) {
} else {
print "結果をパースできません。 " . $request->status_line . "n";
}
ifブロック内で、load_htmlメソッドを使用してHTMLドキュメントのパースを開始します:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
recoverオプションはエラー発生時でもHTMLパースを継続するよう指定し、suppress_errorsオプションはHTMLパースエラーをコンソールに出力しないようにします。HTML文書はXHTMLほど厳密に検証されないため、致命的でないパースエラーが発生する可能性があります。これらのオプションにより、エラー発生時でもコードが動作し続けます。
HTMLのパースが完了したら、indnodesメソッドを使用してXPath式に基づいて要素を検索できます:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
完全なコードは以下のようになります:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes スクレイパー");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "エラーが発生しました $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "結果をパースできませんでした。 " . $request->status_line . "n";
}
コードをperl xml-libxml.pl で実行すると、以下の出力が表示されるはずです:
"私たちが創造した世界は、私たちの思考の産物である。思考を変えずに世界を変えることはできない。":アルバート・アインシュタイン
"ハリー、私たちの真の姿を示すのは能力よりも、選択そのものなのだ。":J.K.ローリング
"人生を生きる方法は二つしかない。一つは、何も奇跡ではないかのように生きる方法。もう一つは、すべてが奇跡であるかのように生きる方法だ。":アルバート・アインシュタイン
「紳士であれ淑女であれ、良質な小説に喜びを見出せない者は、耐え難いほど愚かなに違いない」:ジェーン・オースティン
「不完全さは美であり、狂気は天才である。そして、完全に退屈であるよりは、完全に滑稽であるほうがましだ」:マリリン・モンロー
「成功者になろうとするな。むしろ価値ある人間になれ」:アルバート・アインシュタイン
「自分ではないもので愛されるよりも、自分であるもので嫌われるほうがましだ。」:アンドレ・ジッド
「私は失敗したわけではない。ただ、うまくいかない1万通りの方法を見つけただけだ。」:トーマス・A・エジソン
「女性はティーバッグのようなもの。熱湯に浸すまで、その強さはわからない」:エレノア・ルーズベルト
「太陽の光のない日は、まるで夜のようなもの」:スティーブ・マーティン
このチュートリアルのコードはすべて、このGitHub リポジトリで見つけることができます。
Perl でのウェブスクレイピングの課題
Perl はその強力なモジュールを使用して Web ページを簡単にスクレイピングできますが、開発者はウェブスクレイピングの速度を低下させたり、完全に妨げたりするいくつかの一般的な問題にしばしば遭遇します。以下は、直面する可能性が高い課題のいくつかです。
ページネーションの処理
大量のデータを扱うウェブサイトは、多くの場合、すべてのデータを一度に送信することはありません。通常、データは複数のページで送信されるため、すべてのデータを確実に抽出するには、ページネーションを処理する必要があります。ページネーションを処理するには、2 つのステップがあります。
- 他のページが存在するかの確認。通常、ページ上の「次へ」ボタンを探すか、次のページを読み込もうとしてエラーが発生するかどうかを確認します。
- 他のページが存在する場合、次のページを読み込んでスクレイピングする。
各ページが固有のURLを持つ静的ウェブサイトの場合、ループを実行しURL内のページ番号パラメータをインクリメントして新規ページを読み込めます。あるいはWWW::Mechanizeのようなモジュールを使用している場合は、単純に「次へ」ページのURLを追跡できます。
以下はWWW::Mechanizeを用いたページネーション処理に対応した引用文スクレイパーの修正例です。follow_linkの使用に注意してください:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
JavaScriptで次ページを読み込む動的ウェブサイトの処理については、Pythonによる動的ウェブサイトのスクレイピングガイドを参照するか、読み進めてください。
ローテーションプロキシ
プロキシは、ウェブスクレイパーがプライバシーと匿名性を保護し、IPアドレスの禁止を回避するために一般的に使用されます。LWP::UserAgentのようなモジュールには、ウェブスクレイピング用にプロキシを設定するオプションがあります。しかし、単一のプロキシサーバーを使用しても、IPが禁止されるリスクは依然として存在します。そのため、複数のプロキシサーバーを使用し、それらをローテーションすることが推奨されます。LWP::UserAgent を使用した非常に簡単な例を以下に示します。
まずプロキシの配列を定義します。次にランダムに1つを選び、proxyメソッドで設定します:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
これで通常通りリクエストを送信できます。リクエストが失敗した場合、プロキシがブロックされている可能性が高いので、そのプロキシをリストから削除し、別のプロキシを選択して再試行します:
if(request->is_success) {
# スクラッピングを続行
} else {
# プロキシをリストから削除
splice(@proxies, $index, 1);
# 再試行
}
ハニーポットトラップの処理
ハニーポットトラップは、ウェブ管理者がボットやスクレイパーを捕捉するために用いる一般的な手法です。通常、表示プロパティがnoneに設定されたリンクを使用し、これにより人間のユーザーには見えなくなります。しかしボットはこれを検知してリンクを辿り、おとりウェブページに誘導され、主要製品から遠ざけられます。
この問題に対処するには、リンクを追跡する前にその表示プロパティを確認します。以下はHTML::TreeBuilderを使用した一例です:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# ハニーポットを検知!
} else {
# 安全に進行可能
}
}
CAPTCHAの解決
CAPTCHAはウェブサイトへの不正アクセスを防ぐのに役立ちます。しかし、ウェブスクレイパーがウェブページをスクレイピングするのを妨げることもあります。
CAPTCHA対策として、Bright Data Web Unlockerのようなサービスを利用できます。これは代わりにCAPTCHAを解決してくれます。
以下は、Bright Data Web Unlockerを使用してHTTPリクエストを行う例です:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-ゾーン-residential_プロキシ4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();
Web UnlockerでHTTPリクエストを行うと、自動的にCAPTCHAの解決を行い、ボット対策をかいくぐり、プロキシ管理を代行します。
動的ウェブサイトのスクレイピング
これまで学んだ例はすべて静的ウェブサイトのスクレイピングでした。しかし、シングルページアプリケーション(SPA)やその他の動的ウェブサイトには、より高度な技術が必要です。
動的ウェブサイトはJavaScriptを使用してページコンテンツをロードするため、JavaScriptを実行できるスクレイピングツールが必要です。Seleniumはブラウザをエミュレートして動的ウェブサイトを実行できるツールの一つです。以下にこのモジュールの動作を示すごく簡単なサンプルスニペットを示します:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
結論
Perlは、その堅牢なモジュール群のおかげで、ウェブスクレイピングに最適な言語です。この記事では、以下の手法を用いてPerlでウェブページをスクレイピングする方法を学びました:
LWP::UserAgentとHTML::TreeBuilderWeb::スクレイパーMojo::UserAgentとMojo::DOMXML::LibXML
しかしご覧の通り、ウェブサイト所有者がスクレイパーの侵入を阻止しようと決意している現実のシナリオでは、ウェブスクレイピングは多くの課題に直面します。本記事では、よくあるシナリオとそれらに対処する方法について解説しました。ただし、これらの課題を独自に解決しようとすると、手間がかかりエラーが発生しやすいものです。 そこでBright Dataが役立ちます。最高級のプロキシサービス、スクレイピングブラウザ、Web Unlocker、そして究極のウェブスクレイピングAPIを備えたBright Dataは、ウェブスクレイピングを容易にする包括的なソリューションです。今すぐ無料トライアルを開始しましょう!





