

このガイドで、あなたは学ぶだろう:
- GeminiがAIを活用したウェブスクレイピングに最適なソリューションである理由
- Pythonでサイトをスクレイピングするガイド付きチュートリアル
- ウェブをスクレイピングするこの方法の最大の限界と、それを克服する方法
さあ、飛び込もう!
なぜWebスクレイピングにGeminiを使うのか?
GeminiはGoogleによって開発されたマルチモーダルAIモデルのファミリーであり、テキスト、画像、音声、動画、コードを分析し解釈することができる。ウェブスクレイピングにGeminiを使用すると、非構造化コンテンツの解釈と構造化を自動化することで、データ抽出が簡素化される。特にデータの解析に関しては、手作業が不要になる。
詳細には、これらはウェブスクレイピングにおけるGeminiの最も一般的な使用例である:
- 頻繁に構造が変わるページ:Geminiは、Amazonのようなeコマースサイトのように、レイアウトやデータ要素が頻繁に変更される動的なページを扱うことができます。
- 非構造化データを多く含むページ:整理されていない大量のテキストから有用な情報を抽出することに優れている。
- カスタムの解析ロジックを書くのが難しいページ:複雑な、または予測不可能な構造を持つページに対して、Geminiは複雑な構文解析ルールを必要とせずにプロセスを自動化することができます。
ウェブスクレイピングにおけるGeminiの一般的な使用シナリオは以下の通りである:
- RAG(Retrieval-Augmented Generation):リアルタイムのデータスクレイピングを組み合わせてAIの洞察を強化する。同様のAI技術を使用した完全な例については、SERPデータを使用してRAGチャットボットを作成する方法についてのチュートリアルを参照してください。
- ソーシャルメディア・スクレイピング:動的コンテンツを持つプラットフォームから構造化データを収集する。
- コンテンツの集約:複数のソースからニュース、記事、ブログ記事を収集し、要約や分析を作成すること。
詳細については、ウェブスクレイピングにAIを使用するガイドを参照してください。
PythonでGeminiを使ったWebスクレイピング:ステップバイステップガイド
このセクションのターゲット・サイトとして、「ウェブ・スクレイピングを学ぶためのEコマース・テスト・サイト」のサンドボックスから特定の商品ページを使用する:
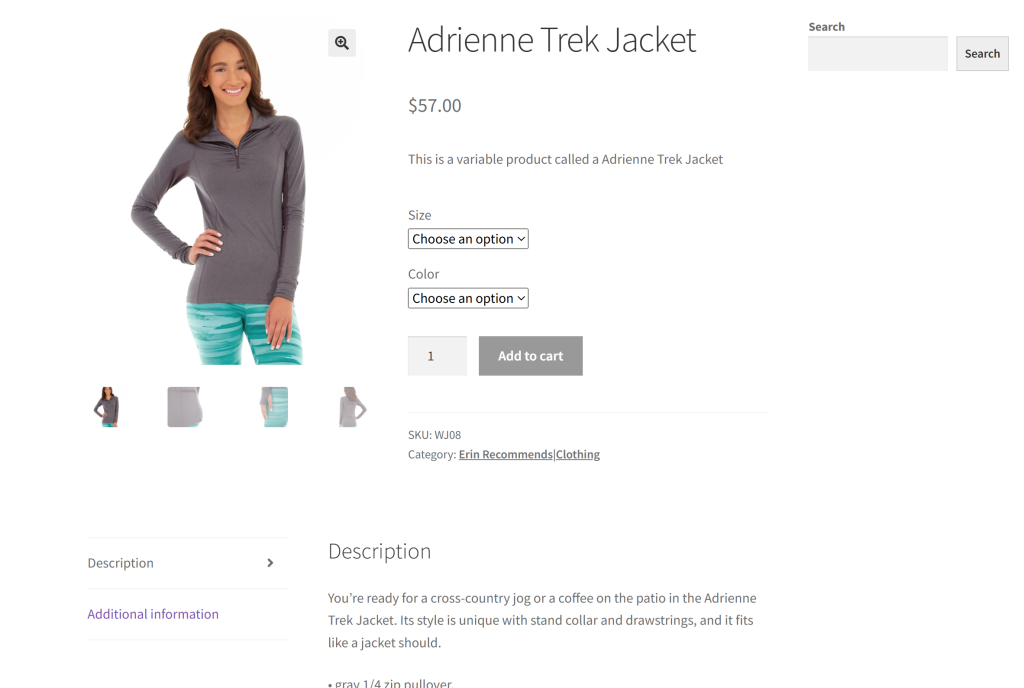
ほとんどのeコマース商品ページは、異なるタイプのデータを表示したり、様々な構造を持っているからだ。これがEコマースのウェブスクレイピングを難しくしている点であり、AIが役立つ点でもある。
私たちのGeminiを搭載したスクレイパーの目標は、AIを活用して、手作業で解析ロジックを記述することなく、ページから商品の詳細を抽出することです。AIによって取得される商品データには以下のものが含まれる:
- SKU
- 名称
- 画像
- 価格
- 説明
- サイズ
- カラー
- カテゴリー
GeminiでWebスクレイピングを実行する方法については、以下の手順に従ってください!
ステップ1:プロジェクトのセットアップ
始める前に、お使いのコンピューターにPython 3がインストールされていることを確認してください。そうでなければ、ダウンロードしてインストールウィザードに従ってください。
次に、以下のコマンドを実行して、スクレイピング・プロジェクト用のフォルダを作成する:
mkdir gemini-scrapergemini-scraperは、Python Geminiを搭載したWebスクレイパーのプロジェクトフォルダを表します。
ターミナルでそこに移動し、その中で仮想環境を初期化する:
cd gemini-scraper
python -m venv venvお気に入りのPython IDEでプロジェクトフォルダを読み込みます。Python拡張機能付きのVisual Studio Codeか PyCharm Community Editionが2つの素晴らしい選択肢です。
プロジェクトのフォルダにscraper.pyファイルを作成します:

現在のところ、scraper.pyは空白のPythonスクリプトですが、すぐに目的のLLMスクレイピングロジックを含むようになります。
IDEのターミナルで、仮想環境を有効にします。LinuxまたはmacOSでは、このコマンドを実行する:
./venv/bin/activate同様に、Windowsでは、以下を実行する:
venv/Scripts/activate素晴らしい!これでGeminiを使ったWebスクレイピングのためのPython環境が整いました。
ステップ2: Geminiの設定
Geminiは、リクエストを含む任意のHTTPクライアントを使用して呼び出すことができるAPIを提供する。それでも、Gemini API用の公式Google AI Python SDKを通して接続するのがベストである。これをインストールするには、アクティベートされた仮想環境で以下のコマンドを実行する:
pip install google-generativeaiそして、scraper.pyファイルにインポートします:
import google.generativeai as genaiSDKを動作させるには、Gemini APIキーが必要です。APIキーをまだ取得していない場合は
をまだ取得していない場合は、Googleの公式ドキュメントに従ってください。具体的には、Googleアカウントにログインし、Google AI Studioに参加します。Get API Key“ページに移動すると、以下のようなモーダルが表示されます:
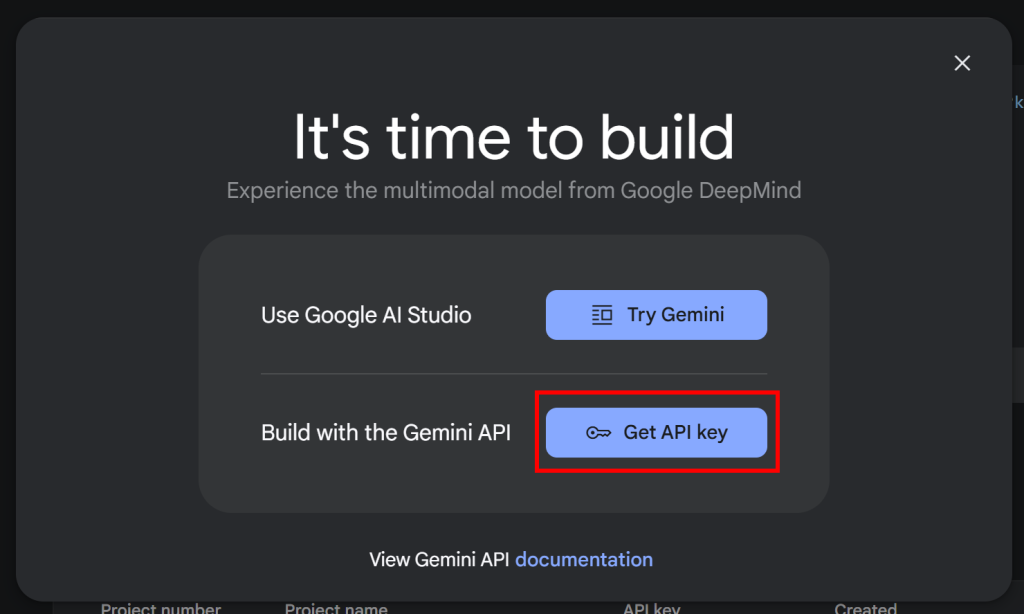
Get API key “ボタンをクリックすると、以下のセクションが表示されます:
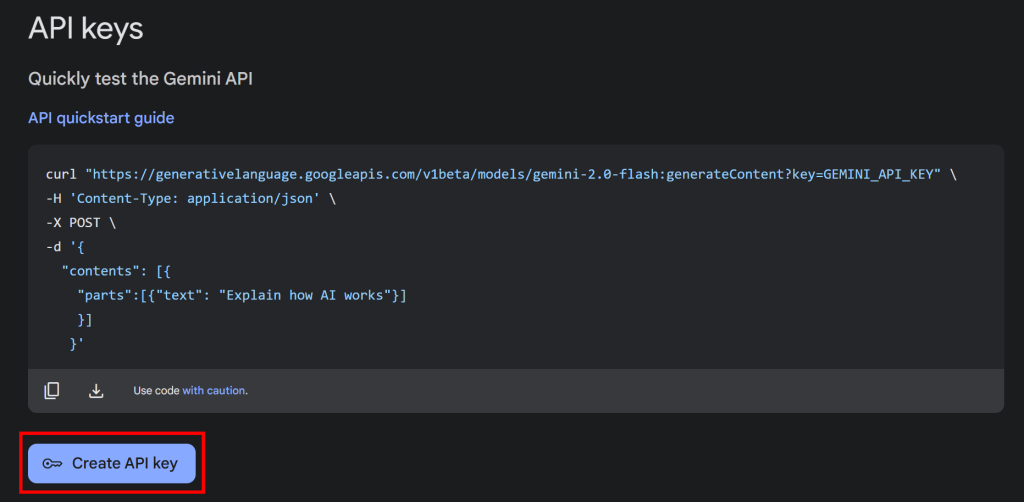
ここで、”Create API key “を押して、Gemini APIキーを生成する:
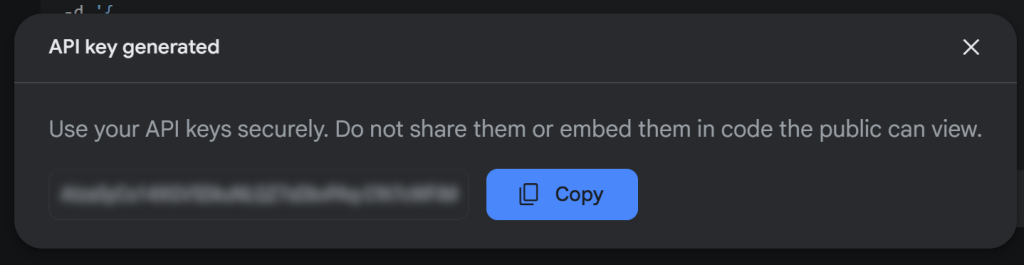
鍵をコピーして安全な場所に保管する。
注: この例では、Geminiの無料ティアで十分です。有料ティアは、より高いレート制限が必要な場合、またはプロンプトと回答がGoogle製品の改善に使用されないようにしたい場合にのみ必要です。詳細については、Geminiの課金ページを参照してください。
PythonでGemini APIキーを使用するには、環境変数として設定します:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>あるいは、Pythonスクリプトに定数として直接格納することもできます:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"そして、次のようにコンフィギュレーションとしてgenaiに渡す:
genai.configure(api_key=GEMINI_API_KEY)今回は、2番目の方法に従います。ただし、手動でAPIキーを渡さない場合、google-generativeaiは自動的にGEMINI_API_KEYからAPIキーを読み込もうとするので、どちらの方法でも動作することを覚えておいてください。
驚いた!Gemini SDKを使ってPythonでLLMにAPIリクエストができるようになりました。
ステップ #3: ターゲットページのHTMLを取得する
ターゲットサーバーに接続し、そのウェブページのHTMLを取得するために、Pythonで最も人気のあるHTTPクライアントであるRequestsを使用する。アクティベートされた仮想環境で、Requestsをインストールする:
pip install requestsそして、scraper.py でインポートします:
import requestsターゲット・ページにGETリクエストを送り、そのHTMLドキュメントを取得する:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)response.contentには、ページの生のHTMLが格納されます。これをパースして、データを取り出す準備をしよう!
ステップ#4: HTMLをMarkdownに変換する
Crawl4AIのような他のAIスクレイピング技術を比較すると、CSSセレクタを使ってHTML要素をターゲットにできることに気づくだろう。これらのライブラリは、選択された要素のHTMLをMarkdownテキストに変換する。最後に、そのテキストをLLMで処理する。
なぜだろう?その行動には2つの重要な理由がある:
- AIに送信されるトークンの数を減らし、経費を節約する(すべてのLLMプロバイダーがGeminiのように無料ではないため)。
- AIの処理を高速化する。入力データが少なければ少ないほど、計算コストが下がり、迅速な応答が可能になるからだ。
完全なウォークスルーについては、CrawlAIとDeepSeekを使用したWebスクレイピングに関するガイドを参照してください。
そのロジックを再現し、実際に意味があるかどうか試してみよう。まず、シークレット・ウィンドウ(新しいセッションを開く)でターゲット・ページを開き、検査することから始める。そして、ページのどこかを右クリックし、”Inspect “オプションを選択する。
ページの構造を見てください。関連するデータはすべて、CSSセレクタ#mainで特定されるHTML要素に含まれていることがわかります:
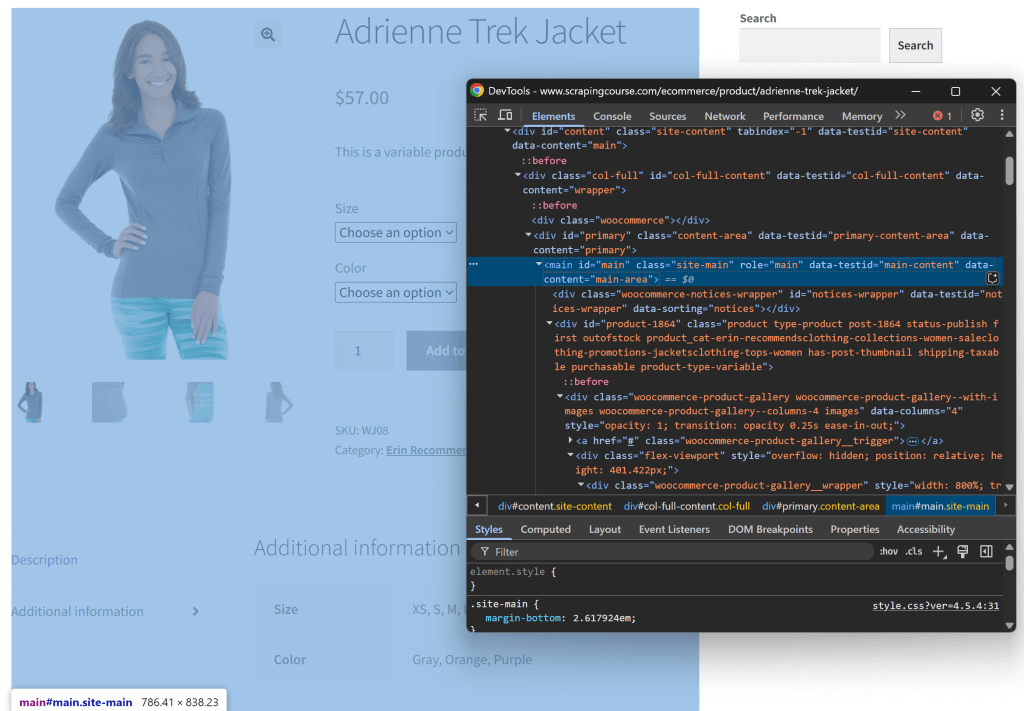
生のHTML全体をGeminiに送ることもできますが、そうすると不要な情報(ヘッダーやフッターなど)がたくさん入ってしまいます。その代わりに、#mainコンテンツだけを渡すことで、ノイズを減らし、AIの幻覚を防ぐことができる。
mainだけを選択するには、Beautiful SoupのようなPythonのHTML解析ツールが必要です。でインストールします:
pip install beautifulsoup4その構文に慣れていない場合は、Beautiful Soupウェブスクレイピングのガイドをご覧ください。
これをscraper.pyにインポートします:
from bs4 import BeautifulSoupBeautiful Soupを使って、Requests経由で取得した生のHTMLを解析し、#main要素を選択し、そのHTMLを抽出する:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)main_htmlを表示すると、次のようになる:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>ここで、このHTMLが生成するトークンの数を確認し、Geminiの有料ティアを使用する場合のコストを見積もる。これを行うには、Token Calculatorのようなツールを使用します:
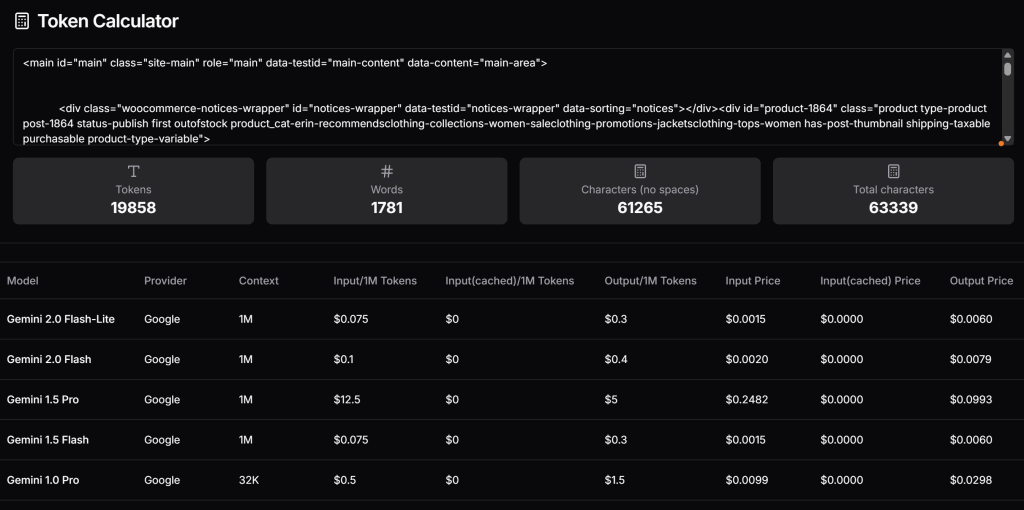
お分かりのように、このアプローチは、ほぼ20,000トークンに相当し、Gemini 1.5 Proのリクエストごとに約0.25ドルのコストがかかる。大規模なスクレイピングプロジェクトでは、これは簡単に問題になり得る!
抽出されたHTMLをMarkdownに変換してみよう-Crawl4AIがやっていることと似ている。まず、markdownifyのようなHTMLをMarkdownに変換するライブラリをインストールする:
pip install markdownifyscraper.pyに markdownifyをインポートします:
from markdownify import markdownify次に、markdownifyを使って抽出したHTMLをMarkdownに変換する:
main_markdown = markdownify(main_html)出来上がったmain_markdownの文字列は次のようになる:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |このMarkdownバージョンの入力データは、スクレイピングに必要な主要データをすべて含みながら、オリジナルの#mainHTMLよりもずっと小さい。
トークン計算機をもう一度使って、新しい入力がどれだけのトークンを消費するかを確認する:
なんと、19,858トークンを765トークンに減らすことができた!
ステップ5:LLMを使ってデータを抽出する
GeminiでWebスクレイピングを行うには、以下の手順に従ってください:
- Markdown入力から必要なデータを抽出するために、構造化されたプロンプトを書く。結果に持たせたい属性を必ず定義してください。
genaiを使用してGemini LLMモデルにリクエストを送信し、リクエストがJSONフォーマットのデータを返すように設定する。- 返されたJSONを解析する。
上記のロジックを以下のコードで実装する:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)prompt変数は、main_markdownコンテンツから構造化データを抽出するようGeminiに指示する。次に、genai.GenerativeModel()は、LLMリクエストを実行するために"gemini-2.0-flash-lite "モデルを設定します。最後に、JSON形式の生のレスポンス文字列が、json.loads()で使用可能なPython辞書に変換されます。
GeminiにJSONデータを返すように指示するための"application/json "設定に注意してください。
Python Standard Libraryからjsonをインポートすることを忘れないでください:
import jsonproduct_dataディクショナリにスクレイピングされたデータがあるので、以下の例のように、そのフィールドにアクセスしてさらにデータ処理を行うことができます:
price = product_data["price"]
price_eur = price * USD_EUR
# ...素晴らしい!WebスクレイピングにGeminiを活用したところですね。あとはスクレイピングしたデータをエクスポートするだけです。
ステップ6:スクレイピングしたデータをエクスポートする
現在、スクレイピングされたデータはPython辞書に格納されています。JSONファイルにエクスポートするには、以下のコードを使用します:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)これにより、スクレイピングされたデータをJSON形式で含むproduct.jsonファイルが作成されます。
おめでとう!Geminiを搭載したウェブスクレーパーが完成しました。
ステップ7:すべてをまとめる
以下は、Geminiスクレイピングスクリプトの完全なコードです:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)でスクリプトを起動する:
python scraper.py実行すると、product.jsonファイルがプロジェクトフォルダに表示されます。それを開くと、このように構造化されたデータが表示されます:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}出来上がり!HTMLページの非構造化データから始まり、Geminiを使ったウェブスクレイピングのおかげで、構造化されたJSONファイルになりました。
次のステップ
ジェミニ・スクレーパーを次のレベルに引き上げるために、以下の改良を検討してください:
- 再利用可能にする:プロンプトとターゲットURLをコマンドライン引数として受け付けるようにスクリプトを修正する。そうすることで、汎用的になり、さまざまな使用シナリオに適応できるようになる。
- ウェブクローリングの実装:クロールとページネーションのロジックを追加することで、複数ページのウェブサイトを処理できるようにスクレーパーを拡張する。
- 安全なAPI認証情報:GeminiのAPIキーを
.envファイルに保存し、python-dotenvを使用して読み込みます。これにより、コード内でAPIキーが公開されるのを防ぐことができます。
このウェブ・スクレイピング・アプローチの主な限界の克服
ウェブスクレイピングのこのアプローチの最大の限界は何か?リクエストによるHTTPリクエスト!
確かに、上の例では完璧に機能したが、それは対象サイトがウェブスクレイピングの遊び場に過ぎないからだ。現実には、企業やウェブサイトの所有者は、たとえそれが一般にアクセス可能なものであったとしても、自分たちのデータがどれほど貴重なものであるかを知っている。それを保護するために、自動化されたHTTPリクエストを簡単にブロックできるスクレイピング対策を導入しているのだ。
また、上記のアプローチは、JavaScriptによるレンダリングや非同期でのデータ取得に依存している動的なサイトでは機能しない。したがって、スクレイパーを止めるための高度なアンチ・スクレイピング・フレームワークは必要ない。JavaScriptベースのコンテンツ・ローディングを使えば十分なのだ。
これらすべての問題の解決策?Web Unlocking APIだ!
Web Unlocker APIはHTTPエンドポイントであり、どのHTTPクライアントからでも呼び出すことができます。重要な違いはWeb Unlocker API は、スクレイピング防止ブロックをバイパスして、URL のロックを完全に解除した HTML を返します。ターゲットのサイトがどれだけ保護されていても、Web Unlocker へのシンプルなリクエストでページの HTML を取得できます。
このツールを使ってAPIキーを取得するには、Web Unlockerの公式ドキュメントに従ってください。そして、「ステップ#3」の既存のリクエストコードを以下の行に置き換えてください:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)もうブロックも制限もない!これで、Geminiを使ってWebをスクレイピングしても、ブロックされる心配はありません。
結論
このブログ記事では、GeminiをRequestsやその他のツールと組み合わせて使用し、AIを搭載したスクレイパーを構築する方法を学んだ。Webスクレイピングの大きな課題の1つはブロックされるリスクですが、これはBright DataのWeb Unlocker APIを使って解決しました。
ここで説明されているように、GeminiとWeb Unlocker APIを組み合わせることで、カスタムの解析ロジックを必要とせずに、あらゆるサイトからデータを抽出することができます。これは、Bright Dataの製品やサービスがサポートする多くのシナリオの1つに過ぎず、AIを活用した効果的なWebスクレイピングの実装を支援します。
他のウェブスクレイピングツールもご覧ください:
- プロキシ・サービス:1億5,000万以上の家庭用IPを含む、ロケーション制限を回避する4種類のプロキシ
- ウェブスクレーパーAPI:100以上の人気ドメインから新鮮で構造化されたウェブデータを抽出するための専用エンドポイント。
- SERP API:SERPのすべての継続的なロック解除管理を処理し、1つのページを抽出するAPI
- スクレイピング・ブラウザ:Puppeteer、Selenium、Playwright互換のブラウザで、ロック解除アクティビティが組み込まれています。
今すぐBright Dataに登録し、プロキシサービスやスクレイピング製品を無料でお試しください!






