

このガイドの中で、あなたは見ることができる:
- PHPでHTMLを解析すると便利な理由
- 記事の目標に着手するための前提条件
- PHPでHTMLを解析する方法
DomHTMLDocument- シンプルなHTML DOMパーサー
- symfony の
DomCrawler
- 3つのアプローチの比較表
さあ、飛び込もう!
なぜPHPでHTMLを解析するのか?
PHP における HTML の解析では、HTML コンテンツを DOM(Document Object Model) 構造に変換します。DOM 形式に変換すると、HTML コンテンツを簡単に操作できるようになります。
特に、PHPでHTMLを解析する理由のトップは以下の通りです:
- データ抽出:HTML要素のテキストや属性など、ウェブページから特定のコンテンツを収集する。
- 自動化:HTMLコンテンツからのコンテンツスクレイピング、レポート作成、データ集計などのタスクを自動化します。
- サーバーサイドのHTMLコンテンツ処理:アプリケーションに表示する前に、サーバー上でHTMLを解析し、ウェブコンテンツを操作、クリーニング、フォーマットします。
前提条件
コーディングを始める前に、お使いのマシンにPHP 8.4+ がインストールされていることを確認してください。以下のコマンドを実行することで確認できます:
php -v
出力は次のようになるはずだ:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
次に、依存関係の管理を簡単にするために、Composerプロジェクトを初期化したい。Composerがシステムにインストールされていない場合は、ダウンロードしてインストール手順に従ってください。
まず、PHP HTMLプロジェクト用の新しいフォルダを作成します:
mkdir php-html-parser
ターミナルでそのフォルダに移動し、composer initコマンドを使ってその中のComposerプロジェクトを初期化する:
composer init
この過程で、いくつかの質問が表示されます。デフォルトの答えでもかまいませんが、必要であればあなたの PHP HTML パースプロジェクトについてより具体的な情報を追加してください。
次に、お気に入りの IDE でプロジェクトフォルダを開きます。Visual Studio Code (PHP 拡張モジュール付き)やIntelliJ WebStormは、PHP の開発に適した選択肢です。
次に、空のindex.phpファイルをプロジェクトフォルダに追加します。プロジェクトの構造はこのようになるはずです:
php-html-parser/
├── vendor/
├── composer.json
└── index.php
index.phpを開き、以下のコードを追加してプロジェクトを初期化する:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...
このファイルには、PHPでHTMLをパースするためのロジックが含まれています。
このコマンドでスクリプトを実行できる:
php index.php
素晴らしい!これで、PHP で HTML をパースするための準備はすべて整いました。ここから、必要な HTML の取得やパースのロジックをスクリプトに追加していきます。
PHPによるHTML検索
PHP で HTML をパースする前に、パースする HTML が必要です。このセクションでは、PHPでHTMLコンテンツにアクセスするための2つの異なるアプローチを見ていきます。
CURLで
PHP はcURL をネイティブにサポートしています。これは、HTTP リクエストを実行する際によく使われる HTTP クライアントです。cURL 拡張モジュールを有効にするか、Linux にインストールします:
sudo apt-get install php8.4-curl
cURLを使ってオンラインサーバーにHTTP GETリクエストを送信し、サーバーから返されたHTMLドキュメントを取得することができます。
以下は、単純なGETリクエストを行い、HTMLコンテンツを取得するスクリプトの例である:
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;
上記のスニペットをindex.phpに追加して起動します。以下のようなHTMLコードが生成されます:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>
詳細はPHP の cURL GET リクエストガイド を参照ください。
ファイルから
HTMLコンテンツを取得するもうひとつの方法は、専用のファイルに保存することです。それには
- ブラウザで好きなページにアクセスする
- ページ上で右クリック
- ページソースを表示」オプションを選択
- HTMLをコピーしてファイルに貼り付ける
あるいは、独自のHTMLロジックをファイルに書くこともできます。
この例では、ファイル名をindex.htmlとする。このファイルには、以前にcURLを使って取得した、Scrape This Siteの“Hockey Teams “ページのHTMLが含まれています:
PHPでHTMLを解析する:3つのアプローチ
このセクションでは、PHP で HTML をパースするために 3 つの異なるライブラリを使用する方法を学びます:
- バニラPHPで
DomHTMLDocumentを使う - Simple HTML DOM Parserライブラリの使用
- symfony の
DomCrawlerコンポーネントを使う
この3つのケースでは、cURL経由で取得したHTML文字列、またはローカルのindex.htmlファイルから読み込んだHTMLコンテンツのいずれかを解析する方法を説明する。
それから、それぞれのPHP HTML解析ライブラリが提供するメソッドを使って、ページ上のすべてのホッケーチームのエントリーを選択し、そこからデータを抽出する方法を学びます:
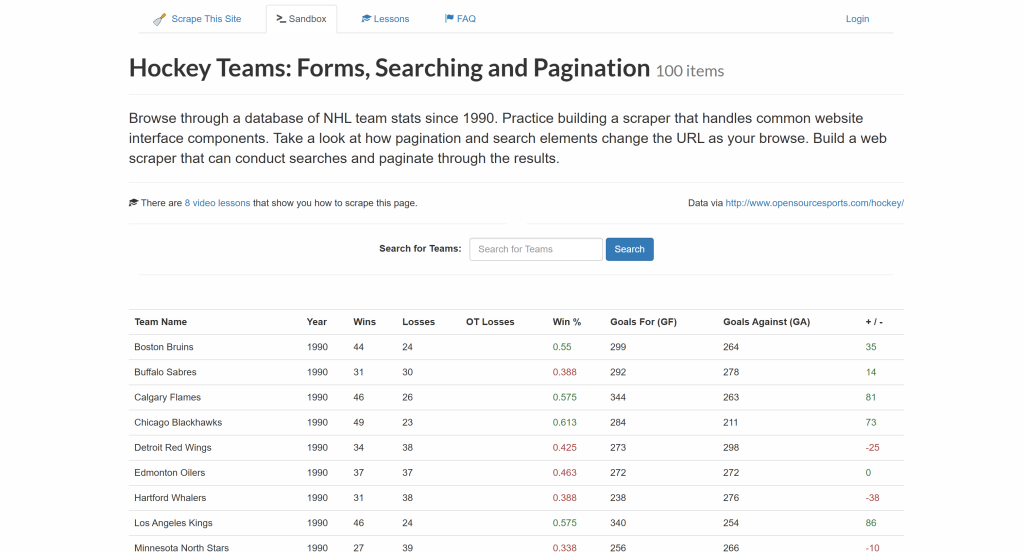
最終的な結果は、以下の詳細を含むホッケーチームのエントリーリストとなる:
- チーム名
- 年
- 勝利
- 損失
- 勝率
- ゴールフォー(GF)
- 対戦ゴール (GA)
- 得点差
この構造でHTMLテーブルから抽出することができる:
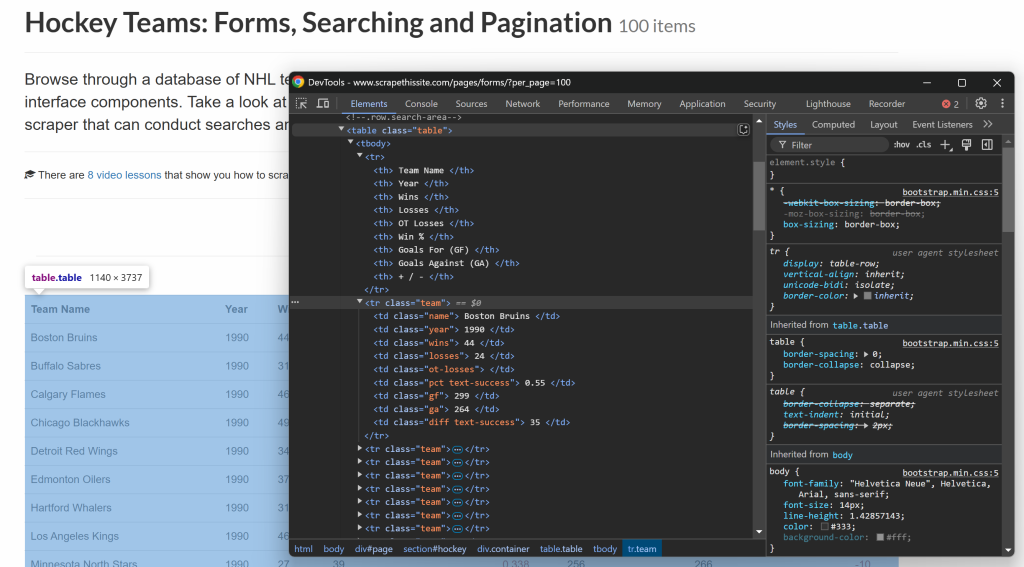
ご覧のように、テーブル行の各列には特定のクラスがあります。CSSセレクタとしてクラスを使用して要素を選択し、そのテキストにアクセスして内容を取得することで、そこからデータを抽出することができます。
HTMLの解析は、ウェブスクレイピングスクリプトの一段階に過ぎないことを覚えておいてください。より深く掘り下げるには、PHPによるWebスクレイピングのチュートリアルをお読みください。
では、PHPでHTMLをパースするための3つの異なるアプローチを調べてみましょう。
アプローチ1:DomHTMLDocumentを使う
PHP 8.4+ には組み込みのDomHTMLDocumentクラスがあります。これは HTML ドキュメントを表し、HTML コンテンツをパースしたり DOM ツリーを移動したりすることができます。PHP で HTML をパースするための使い方を参照ください!
ステップ1:インストールとセットアップ
DomHTMLDocumentはPHP 標準ライブラリの一部です。しかし、DOM 拡張モジュールを使用するには、DOM 拡張モジュールを有効にするか、この Linux コマンドでインストールする必要があります:
sudo apt-get install php-dom
これ以上の操作は必要ありません。これで、PHP でDomHTMLDocument を使用して HTML をパースする準備ができました。
ステップ2:HTMLの解析
HTML文字列は以下のようにパースできる:
$dom = DOMHTMLDocument::createFromString($html);
同じように、index.htmlファイルを解析するには次のようにする:
$dom = DOMHTMLDocument::createFromFile("./index.html");
domは、データ解析に必要なメソッドを公開するDomainHTMLDocumentオブジェクトです。
ステップ3:データ解析
ホッケーチームのエントリをすべて選択するには、次のようにします:
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
}
DOMHTMLDocumentは高度なクエリ・メソッドを提供していません。そのため、getElementsByTagName() のようなメソッドと手動による反復に頼らざるを得ません。
以下はその内訳である:
getElementsByTagName():ドキュメント内の指定されたタグ (<table>,<tr>,<td>など) のすべての要素を取得する。item():getElementsByTagName()によって返された要素のリストから個々の要素を返します。textContent:このプロパティは、要素の生のテキストコンテンツを提供し、目に見えるデータ(チーム名、年など)を抽出することができます。
また、trim()を使って、テキスト・コンテンツの前後の余分な空白を取り除き、よりきれいなデータにした。
index.phpに上記のスニペットを追加すると、このようになります:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
)
アプローチ2:シンプルなHTML DOMパーサーを使う
Simple HTML DOM Parserは軽量な PHP ライブラリで、HTML コンテンツを簡単に解析・操作できます。このライブラリは活発にメンテナンスされており、GitHubには880以上のスターがあります。
ステップ1:インストールとセットアップ
Simple HTML Dom ParserはComposer経由でインストールできます:
composer require voku/simple_html_dom
あるいは、simple_html_dom.phpファイルを手動でダウンロードし、プロジェクトにインクルードすることもできます。
そして、index.phpに以下のコードでインポートする:
use vokuhelperHtmlDomParser;
ステップ2:HTMLの解析
HTML文字列をパースするには、file_get_html()メソッドを使う:
$dom = HtmlDomParser::str_get_html($html);
index.htmlのパースには、代わりにfile_get_html()を書く:
$dom = HtmlDomParser::file_get_html($str);
これにより、HTMLコンテンツが$domオブジェクトにロードされ、DOMを簡単にナビゲートできるようになります。
ステップ3:データ解析
Simple HTML DOM Parserを使用して、HTMLからホッケーチームのデータを抽出します:
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("n");
}
上記で使用したSimple HTML DOM Parserの機能は以下の通りです:
findMulti():指定した CSS セレクタで識別されるすべての要素を選択します。findOne():指定した CSS セレクタにマッチする最初の要素を探します。プレーンテキスト:HTML要素内の生のテキスト内容を取得する属性。
今回は、より完全で堅牢なロジックを持つCSSセレクタを使用した。それでも、結果は最初のHTML解析PHPアプローチと同じになる。
アプローチ #3: symfony の DomCrawler コンポーネントを使う
symfony のDomCrawlerコンポーネントはHTML ドキュメントを解析してデータを抽出する簡単な方法を提供します。
注: このコンポーネントはsymfony フレームワークの一部ですが、このセクションで行うようにスタンドアロンで使うこともできます。
ステップ1:インストールとセットアップ
このComposerコマンドでsymfonyのDomCrawlerコンポーネントをインストールします:
composer require symfony/dom-crawler
そして、index.phpファイルにインポートする:
use SymfonyComponentDomCrawlerCrawler;
ステップ2:HTMLの解析
HTML文字列を解析するには、html()メソッドでCrawlerインスタンスを作成する:
$crawler = new Crawler($html);
ファイルを解析するには、file_get_contents() を使用し、クローラー・インスタンスを作成する:
$crawler = new Crawler(file_get_contents("./index.html"));
上記の行は、HTMLコンテンツを$crawlerオブジェクトに読み込み、データをトラバースして抽出する簡単なメソッドを提供する。
ステップ3:データ解析
DomCrawlerコンポーネントを使用してホッケーチームのデータを抽出します:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
});
使用されているDomCrawlerのメソッドは以下の通り:
each():選択された要素のリストを繰り返し処理する。フィルタを使用します:CSS セレクタに基づいて要素を選択します。text():選択された要素のテキスト内容を抽出します。
素晴らしい!これであなたもPHPのHTML解析マスターだ。
PHPでHTMLを解析する:比較表
PHPでHTMLを解析するための3つのアプローチを、以下の表で比較することができます:
| DOMHTMLドキュメント | シンプルなHTML DOMパーサー | symfony の DomCrawler | |
|---|---|---|---|
| タイプ | ネイティブPHPコンポーネント | 外部図書館 | symfony コンポーネント |
| ギットハブ・スターズ | – | 880+ | 4,000+ |
| XPathサポート | ❌ | ✔️ | ✔️ |
| CSSセレクタのサポート | ❌ | ✔️ | ✔️ |
| 学習曲線 | 低い | 低~中 | ミディアム |
| シンプルな操作性 | ミディアム | 高い | 高い |
| API | ベーシック | リッチ | リッチ |
結論
この記事では、PHPでHTMLをパースするための3つのアプローチについて学びました。
これらの解決策はすべて機能しますが、対象となるウェブページがレンダリングにJavaScriptを使用している可能性があることに留意してください。その場合、上で紹介したような単純なHTML解析アプローチは機能しない。代わりに、Scraping Browserのような高度なHTML解析機能を備えた本格的なスクレイピング・ブラウザが必要です。
HTMLの解析をスキップして、すぐにデータを取得したいですか?何百ものウェブサイトをカバーする、すぐに使えるデータセットをご覧ください!
今すぐBright Dataの無料アカウントを作成し、無料トライアルでデータとスクレイピングソリューションをお試しください!




