

オンライン不動産取引サイト「Zillow」のスクラッピングは、市場分析、住宅業界の動向、競合他社の概要など、不動産市場に関する貴重な洞察を提供します。Zillowをスクラップすることで、物件価格、立地、特徴、過去の傾向に関する包括的な情報を収集でき、市場分析の実施、住宅業界の動向把握、競合他社の戦略評価、投資目標に沿ったデータ駆動型の意思決定が可能になります。
このチュートリアルでは、Beautiful Soup を使用したZillowのスクレイピング方法を学びます。有用なデータの収集方法に加え、Zillowが採用するスクレイピング対策技術と、Bright Dataがどのように役立つかについても理解を深められます。
スクレイピングを省略してデータを直接入手したいですか?当社のZillowデータセットをご覧ください。
Zillowのスクレイピング
Python初心者でも経験者でも、このチュートリアルではBeautifulSoupやRequestsなどの無料ライブラリを用いたウェブスクレイパー構築を支援します。さあ始めましょう!
前提条件
開始前に、ウェブスクレイピングとHTMLの基本的な理解があることが推奨されます。また、以下の準備が必要です:
- 公式ドキュメント
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
Zillowウェブサイトの構造を理解する
Zillowのスクレイピングを始める前に、その構造を理解することが重要です。Zillowのホームページには便利な検索バーが設置されており、住宅、アパート、様々な不動産物件を検索できます。検索を開始すると、物件のリストが価格、住所、その他の関連詳細と共に表示されたページに結果が表示されます。 これらの検索結果は、価格、寝室数、浴室数などのパラメータに基づいて並べ替えられる点に留意してください。
最初に表示された結果以外の検索結果をさらに見たい場合は、ページ下部に配置されたページネーションボタンを利用できます。各ページには通常40件の物件が掲載されており、追加の物件にアクセスできます。ページ左側に配置されたフィルターを活用することで、自身の好みや要件に基づいて検索を絞り込むことが可能です。
ウェブサイトのHTML構造を理解するには、以下の手順に従ってください:
- Zillowのウェブサイトにアクセス:www.zillow.com
- 検索バーに都市名または郵便番号を入力し、Enterキーを押す。
- 物件カード上で右クリックし、「要素を検査」を選択してブラウザの開発者ツールを開きます。
- スクレイピングしたいデータを含むタグと属性を特定するため、HTML構造を分析する。
主要データポイントの特定
Zillowから効果的に情報を収集するには、スクレイピング対象の正確なコンテンツを特定する必要があります。本ガイドでは、以下の主要データポイントを含む物件情報の抽出方法を説明します:
- 住所:物件の所在地(通り名、市区町村、州を含む)。
- 価格:物件の掲載価格。現在の市場価値を把握する手がかりとなります。
- Zestimate:Zillowによる物件の推定市場価値。Zestimateは様々な要素を考慮し、市場動向や類似物件データに基づく概算評価額を提供します。
- 寝室数:物件内の寝室の数。
- バスルーム数:物件内の浴室の数。
- 床面積:物件の総面積(平方フィート単位)。
- 建築年:物件が建設された年。
- 物件タイプ:物件の種類。一戸建て、アパート、コンドミニアム、その他関連分類などの選択肢が含まれます。
Zillowは、様々な物件情報を容易に評価・比較し、特定地域の価格動向を検討し、物件の状態を評価し、追加設備を特定するための広範な情報を提供します。さらに、過去および現在の市場データを分析することで、トレンドを把握し、不動産の購入、売却、投資に関する戦略的な意思決定を行うことが可能です。
スクレイパーの構築
スクレイピング対象を特定したところで、スクレイパーを構築します。ここではRequestsライブラリでZillowへのHTTPリクエストを送信し、Beautiful SoupでHTMLをパースし、Pythonでデータを抽出します。
データの抽出
最初のステップは、目的のデータを抽出することです。新しいファイル「scraper.py」を作成し、以下のコードを追加します:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
result['price'] = listing.find('span', {'data-test': 'property-card-price'}).get_text().strip()
details_list = listing.find('ul', {'class': 'dmDolk'})
details = details_list.find_all('li') if details_list else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)
このコードはZillow検索結果ページにHTTP GETリクエストを送信し、Beautiful SoupでHTMLをパースします。各物件のデータポイントを抽出し、全ての物件を出力します。
スクレイパーの実行
スクレイパーを実行するには、Zillow検索結果ページのURLを指定する必要があります。URLは以下のような形式です:https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/。ここで{city-or-zip}は、スクレイピング対象の都市名または郵便番号に置き換えます。
例えば、サンフランシスコで販売中の住宅情報を収集する場合、使用するウェブアドレスはhttps://www.zillow.com/homes/for_sale/San-Francisco_rb/ となります。
ウェブサイトURLを入力したら、プログラムを実行してスクレイピングを開始します。変更をscraper.pyに保存し、シェルまたはターミナルで次のコマンドを実行してください:
python3 スクレイパー.py
…出力…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745,000ドル', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': '分譲マンション'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': 'タウンハウス販売中'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]
ウェブスクレイピングは、
対象サイトのrobots.txtファイルと利用規約を遵守し、過度なスクレイピングはIPアドレスのブロックにつながる可能性があることにご留意ください。
データの保存
データを抽出したら、JSONまたはCSVファイルに保存する必要があります。ファイルに保存することで、収集したデータに基づいて処理や分析を行うことが可能になります。
データを保存するには、まずscraper.py ファイルの先頭でpandas とjson ライブラリをインポートします:
import pandas as pd
import json
次に、ファイル末尾に以下のコードを追加します:
#Jsonファイルへのデータ書き込み
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Data written to Json file')
#csvファイルへのデータ書き込み
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Data written to CSV file')
このコードは、辞書のリストであるlistings データをjson.dump()を使用してlistings .jsonという名前のJSONファイルに書き込みます。次に、listingsデータからpandas DataFrameを作成し、to_csv()メソッドを使用してlistings.csvという名前のCSVファイルに書き込みます。コードは、データがJSONファイルとCSVファイルの両方に正常に書き込まれたことを示すメッセージを出力します。
次に、シェルまたはターミナルからコードを実行します:
python3 スクレイパー.py
…出力…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745,000ドル', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': '分譲マンション'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': 'タウンハウス販売中'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]
Jsonファイルへのデータ書き込み完了
CSVファイルへのデータ書き込み完了
正常に動作した場合、プロジェクトディレクトリに2つの新規ファイルが生成されているはずです:listings.csvファイルと listings.jsonファイルです。これらの2つのファイルは、それぞれGitHubリポジトリのlistings.csvファイルと listings.jsonファイルと類似した内容を持つはずです。
コードを複数回実行すると、高い失敗率(約50%)に気付くでしょう。これはZillowが自動スクレイピングを検知すると、実際のコンテンツではなくCAPTCHAページを返すことがあるためです。Zillowのようなウェブサイトをスクレイピングする際の成功率を高めるには、異なるIP間を移動でき、CAPTCHAを回避できるツールを使用する必要があります。
Zillowが採用するスクレイピング対策技術
許可なくデータを取得されるのを防ぐため、Zillowは自社サイトからの自動データコピー(いわゆるスクレイピング)を阻止する様々な手法を採用しています。これにはCAPTCHAの使用、IPアドレスのブロック、ハニーポットトラップの設置などが含まれます。
CAPTCHAは、ユーザーが人間かコンピュータプログラムかを判別するテストです。通常、人間には容易に解けますが、プログラムには困難であり、データスクレイピングを遅延させたり、完全に停止させたりすることが可能です。
Zillowがスクレイピングを阻止する別の方法は、IPアドレスのブロックです。IPアドレスはコンピュータの住所のようなものです。スクレイピングで頻繁に発生する過剰なリクエストを送信しているコンピュータがあれば、ZillowはそのIPアドレスをブロックしてさらなるリクエストを停止できます。これらのブロックは状況の深刻度に応じて、短期間または長期間に設定されます。
さらにZillowはハニーポットトラップも使用しています。これは人間には認識できずプログラムのみが検知可能なデータやリンクです。プログラムがハニーポットトラップとやり取りした場合、Zillowはそれをボットと認識しブロックできます。
これらの対策により、Zillowからのデータスクレイピングは困難です。時間がかかり、難しく、時には不可能な場合もあります。Zillowからデータをスクレイピングしようとする者は、これらの対策を知るだけでなく、データスクレイピングに関する法的・倫理的問題を理解する必要があります。Zillowはこれらの対策の運用方法を変更する可能性があり、その際公表しない場合もあることを覚えておいてください。
より優れた代替手段:Bright DataでZillowをスクレイピング
Bright Dataは、自社開発の「スクレイピングブラウザ」により、Zillowが採用する反スクレイピング対策を回避する優れた代替手段を提供します。スクレイピングブラウザでは、Bright Dataのネットワーク上でPuppeteerスクリプトを実行可能。これにより数百万のIPアドレスにアクセスでき、Zillowの反スクレイピング技術による検知を回避します。
Bright Dataのスクレイピングブラウザを使用したZillowのスクラッピング
Bright DataのスクレイピングブラウザでZillowをスクレイピングするには、以下の手順に従ってください:
1. Bright Dataアカウントを作成する
Bright Dataアカウントをお持ちでない場合は、Bright Dataのウェブサイトにアクセスし、「無料トライアルを開始」をクリックして指示に従ってください。
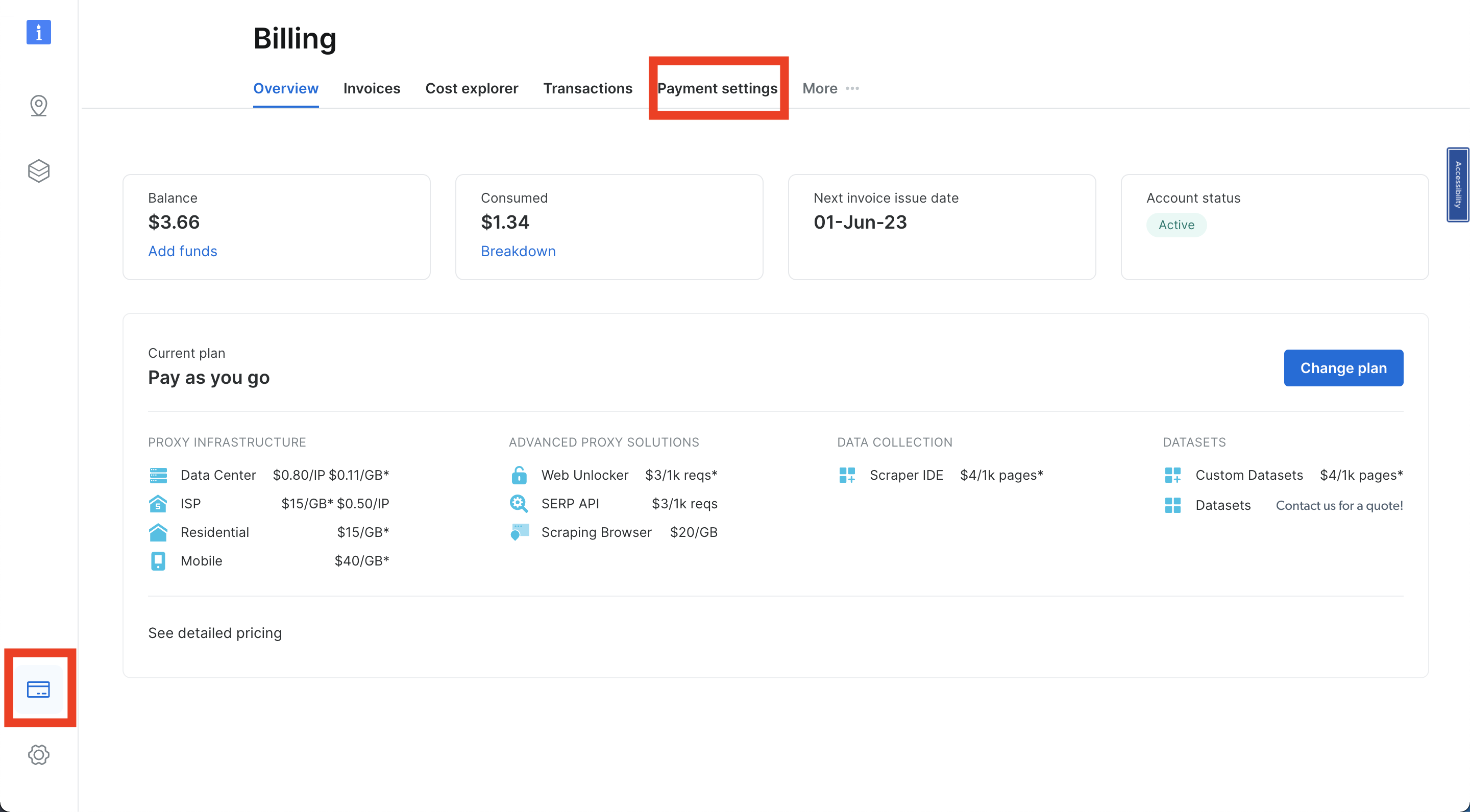
Bright Dataアカウントにログイン後、ナビゲーションバー左下のクレジットカードアイコンをクリックし「Billing」に移動します。お好みの方法で支払い方法を追加してください。追加しないとアカウントを有効化できません:
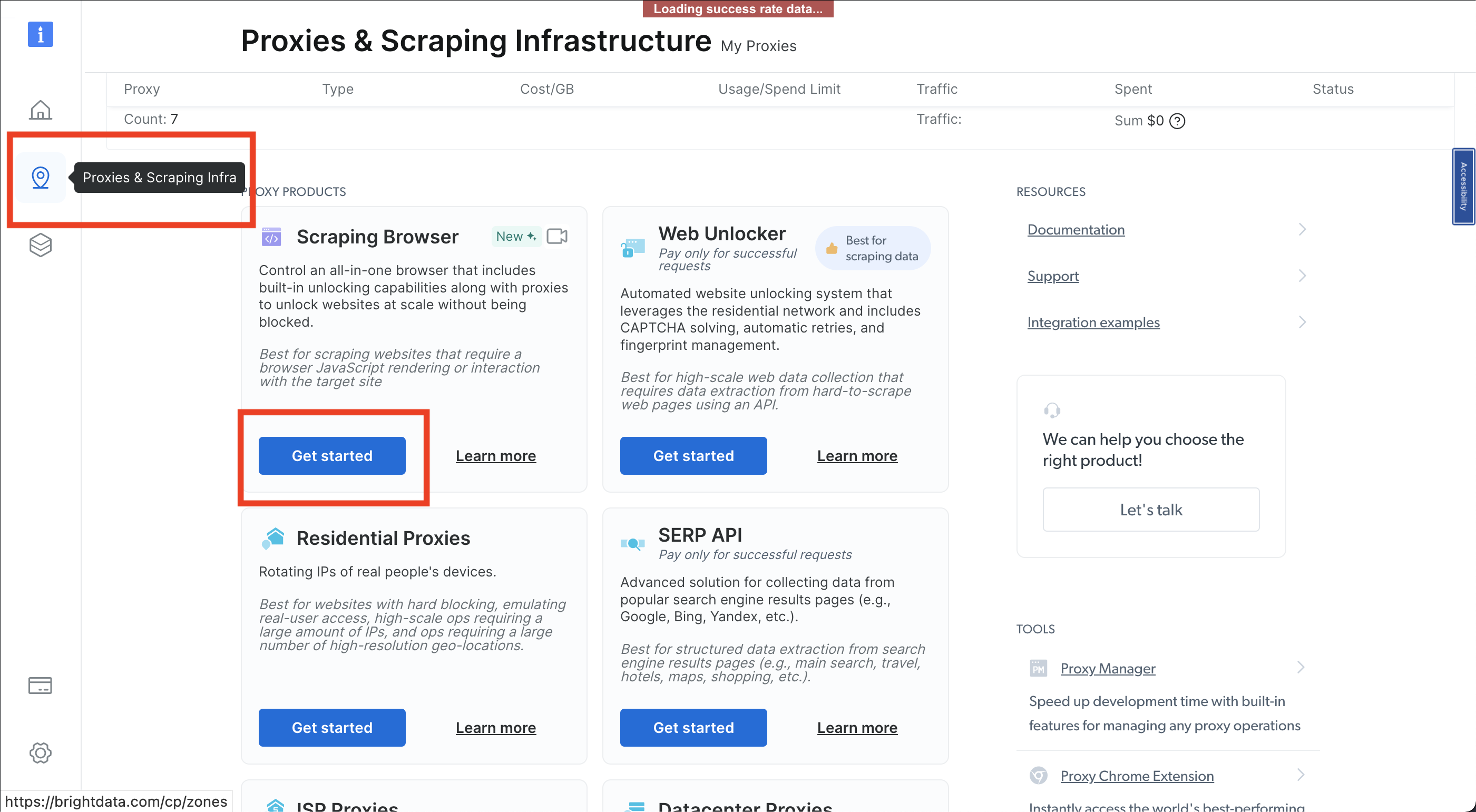
次に、ピンアイコンをクリックして「プロキシ&スクレイピングインフラ」ページを開き、「スクレイピングブラウザ」>「開始」を選択します:
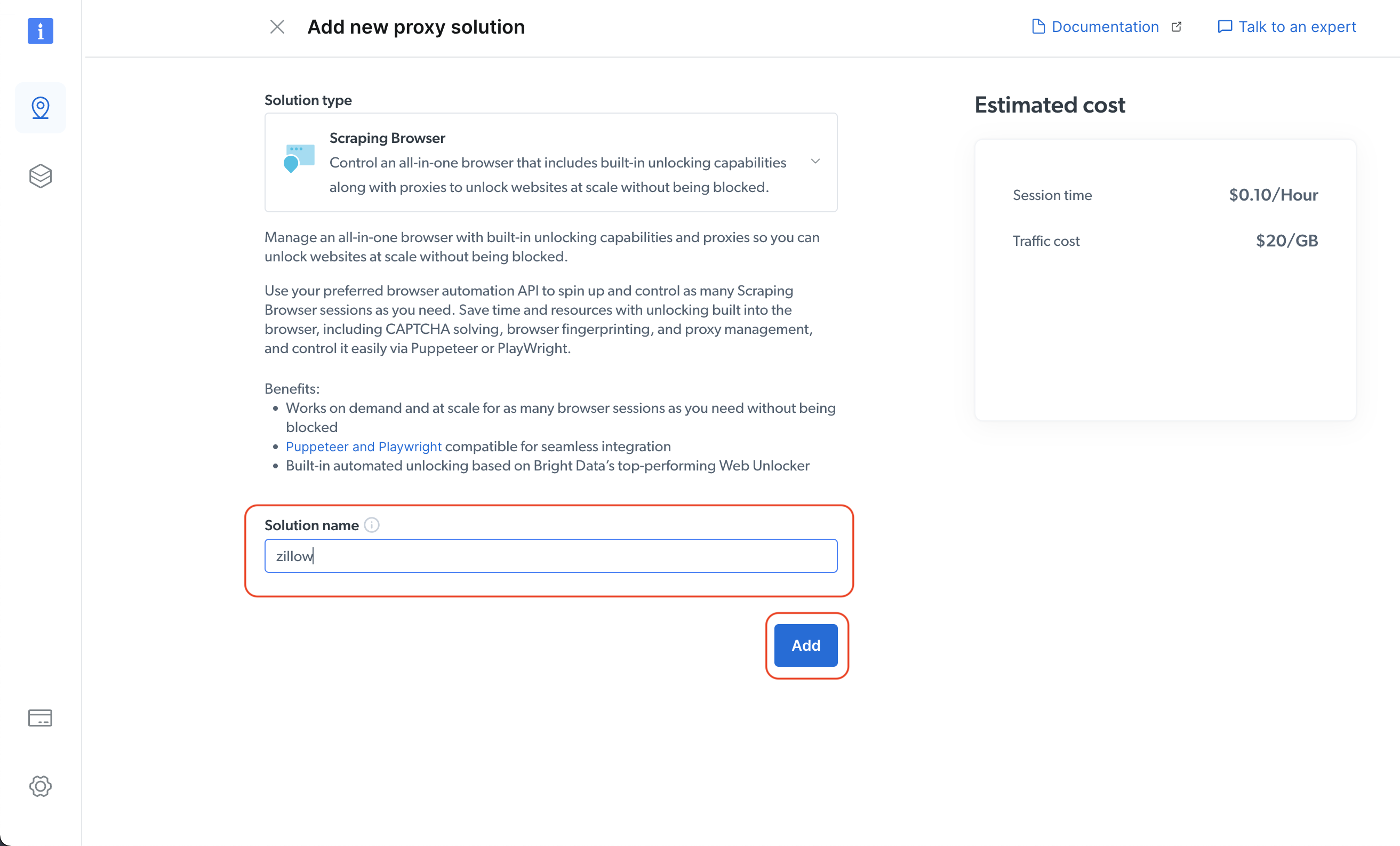
次にソリューション名を指定し、「追加」ボタンをクリックします:
「アクセスパラメータ」をクリックし、ユーザー名、ホスト、パスワードをメモしてください。これらは後続のチュートリアルで必要になります:
上記の手順を完了したら、次のステップに進む準備が整います。
2. スクレイパーの作成
新しいファイルscraper-brightdata.py を作成し、以下のコードを追加します:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('リモートブラウザに接続中...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('接続完了。新規ページを開きます...')
page = await browser.new_page()
print('Zillowに移動中...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('データスクレイピング中...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# 非同期関数の実行
listings = asyncio.run(main())
# リストの出力
for listing in listings:
print(listing)
# JSONファイルへのデータ書き込み
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('データがJSONファイルに書き込まれました')
# CSVファイルへのデータ書き込み
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('データがCSVファイルに書き込まれました')
YOUR_BRIGHTDATA_USERNAME、YOUR_BRIGHTDATA_PASSWORD、YOUR_BRIGHTDATA_HOST を実際の Bright Data アカウントの認証情報に置き換えてください。
3. スクレイパーの実行
scraper-brightdata.py の変更を保存し、シェルまたはターミナルからコードを実行します:
python3 scraper-brightdata.py
…出力…
リモートブラウザに接続中...
接続完了。新規ページを開きます...
Zillowに移動中...
データをスクレイピング中...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'address': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'price': '$1,195,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '-- sqft', 'type': ''}
{'address': '455 27th Ave, San Francisco, CA 94121', 'price': '$1,375,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,040 sqft', 'type': 'House for sale'}
{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}
{'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}
{'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}
{'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}
{'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}
{'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}
Jsonファイルに書き込まれたデータ
CSVファイルに書き込まれたデータ
このコードはBright Dataスクレイピングブラウザに接続し、Zillowの検索結果ページに移動してデータを抽出します。次に、コードは結果を出力し、その後json.dump()を使用して、辞書のリストであるlistingsデータ(listings-brightdata.jsonという名前のJSONファイル)に書き込みます。 その後、listingsデータからpandas DataFrameを作成し、to_csv()メソッドを使用してlistings-brightdata.csvという名前のCSVファイルに書き込みます。コードは、データがJSONファイルとCSVファイルの両方に正常に書き込まれたことを示すメッセージを出力します。
正常に動作した場合、listings-brightdata.csvファイルと listings-brightdata.jsonファイルの2つが確認できるはずです。これらのファイルはlistings-brightdata.jsonと listings-brightdata.csvに類似している必要があります。
このコードを複数回実行してもファイルにデータが保存されない場合、ZillowによってIPがブロックされたか、スクレイピング完了前にブラウザが閉じられたことを意味します。 スクレイピングが完了する前にブラウザが閉じられた場合は、タイムアウト値を大きくする必要があります。先ほどのコードでは、await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000) に関連しています。
ZillowによってIPがブロックされた場合は、ゾーンを変更する必要があります。幸い、Bright Dataでは複数のゾーンを利用可能です。
ゾーンを切り替えるには、ピンアイコンをクリックして「スクレイピングインフラ」に移動し、「スクレイピングブラウザ」を選択して「Access parameters」をクリックします。次に「</> Check out code and integration examples」をクリックしてください:
言語としてPythonを選択し、右側のナビゲーションにある「国」ドロップダウンリストから目的の国を選択すると、ゾーンが同時に更新されます。Pythonサンプルコード内のauth変数が変更されるのを確認できるはずです。auth変数から該当ゾーンに関連するユーザーを取得する必要があります。主に、auth変数はユーザー名とパスワードを以下の構文で保持しているため、: の前の値が該当します:username:password:
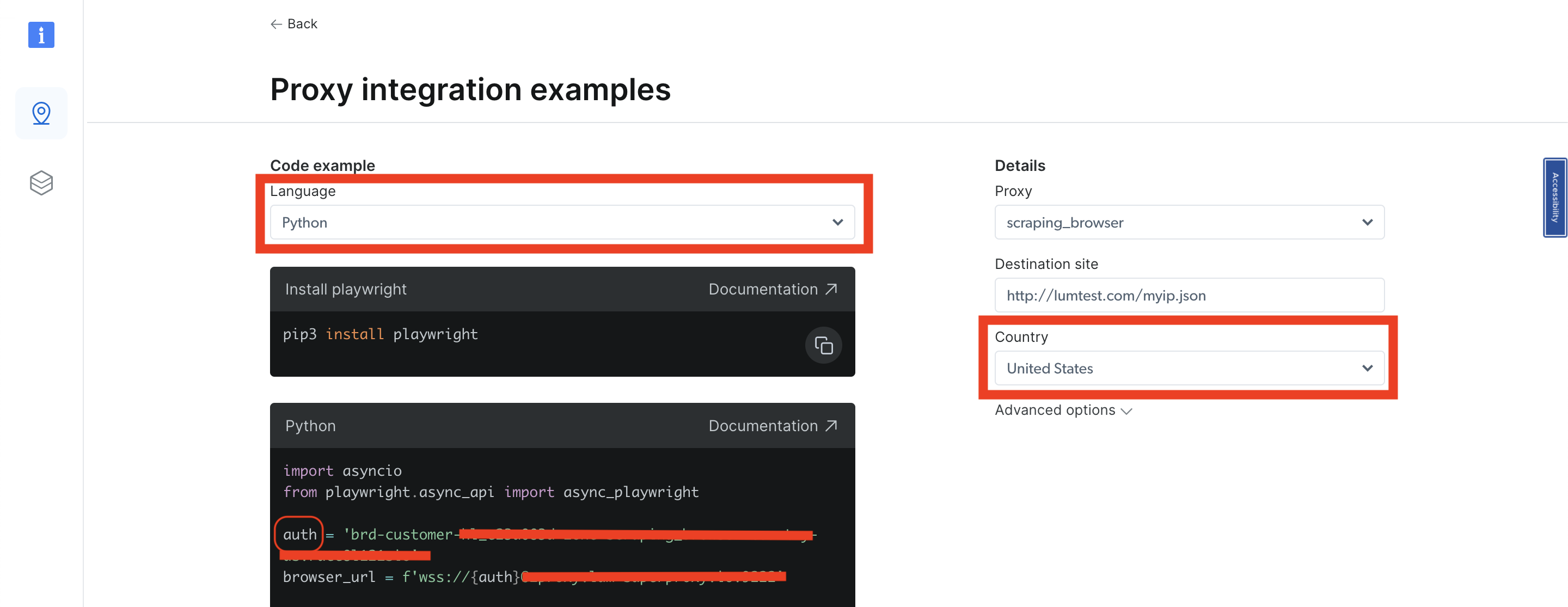
国を変更するたびに、その特定の国/ゾーンに対応する異なるユーザーを取得できます。取得したユーザー名と選択した国に基づいてユーザーを取得し、コードに組み込んで再度実行してください。
まとめ
このチュートリアルでは、Beautiful Soupを使用したZillowのスクレイピング方法を学びました。また、Zillowが採用している
Zillowが採用するスクレイピング対策技術とその回避方法についても学びました。これらの課題を解決するため、Bright Dataスクレイピングブラウザが紹介されました。これにより、Zillowのスクレイピング対策メカニズムを突破し、目的のデータをシームレスに抽出することが可能になります。
スクレイピングブラウザに加え、BrightDataのZillowスクレイパーAPIは、アンチスクレイピング対策を回避し、包括的なZillowデータへのシームレスなアクセスを提供します。
注:本ガイドは執筆時点で当社チームにより徹底的にテストされていますが、ウェブサイトは頻繁にコードや構造を更新するため、一部の手順が期待通りに機能しなくなる可能性があります。






