

Wikipediaは膨大かつ包括的な情報源であり、ほぼあらゆるトピックを網羅する数百万の記事を含んでいます。研究者、データサイエンティスト、開発者にとって、このデータは機械学習データセットの構築から学術研究の実施まで、無数の機会を開きます。本記事では、Wikipediaのスクレイピングプロセスを段階的に解説します。
Bright Data Wikipedia スクレイパー API の利用
Wikipediaから効率的にデータを抽出したい場合、手動でのウェブスクレイピングに代わる優れた選択肢がBright Data WikipediaスクレイパーAPIです。この強力なAPIはプロセスを自動化し、大量の情報収集を大幅に容易にします。
主な活用例:
- 幅広いトピックに関する説明の収集
- Wikipediaの情報と他のデータソースの比較
- 大規模データセットを用いた調査の実施
- Wikipedia Commonsからの画像スクレイピング
データはJSON、CSV、.gzなどの形式で取得可能。Amazon S3、Google Cloud Storage、Microsoft Azureなど多様な配信オプションをサポート。
たった1回のAPI呼び出しで、豊富なデータに素早く簡単にアクセスできます!
PythonでWikipediaをスクレイピングする方法
Python を使用してウィキペディアをスクレイピングする手順を、このチュートリアルで順を追って説明します。
1. 環境設定と前提条件
開始前に、開発環境が適切に設定されていることを確認してください:
- Pythonのインストール:公式Pythonウェブサイトから最新版をダウンロードしてインストールしてください。
- IDEの選択: PyCharm、Visual Studio Code、Jupyter NotebookなどのIDEを開発作業に使用してください。
- 基本知識:CSSセレクタに精通し、ブラウザのデベロッパーツールを使用してページ要素を検査することに慣れていることを確認してください。
Pythonが初めての方は、Pythonでのスクレイピング方法ガイドで詳細な手順を確認してください。
次に、Pythonのパッケージ管理や仮想環境の管理を簡素化する依存関係管理ツール「Poetry」を使用して新規プロジェクトを作成します。
poetry new wikipedia-スクレイパー
このコマンドにより以下のプロジェクト構造が生成されます:
wikipedia-スクレイパー/
├── pyproject.toml
├── README.md
├── wikipedia-スクレイパー/
│ └── __init__.py
└── tests/
└── __init__.py
プロジェクトディレクトリに移動し、必要な依存関係をインストールします:
cd wikipedia-スクレイパー
poetry add requests beautifulsoup4 pandas lxml
まず、BeautifulSoupはHTMLおよびXMLドキュメントのパースに使用され、ウェブページから特定の要素を簡単にナビゲートして抽出できます。requestsライブラリはHTTPリクエストの送信とウェブページの内容取得を処理します。Pandasはスクレイピングしたデータの操作と分析に強力なツールであり、特にテーブルを扱う際に有用です。最後に、lxmlはBeautifulSoupのパフォーマンスを向上させるため、パースプロセスの高速化に使用されます。
次に、仮想環境をアクティブ化し、お好みのコードエディタ(ここではVS Code)でプロジェクトフォルダを開きます:
poetry shell
code .
プロジェクトの依存関係を確認するため、pyproject.tomlファイルを開きます。内容は以下のようになります:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
最後に、スクレイピングロジックを記述するmain.pyファイルをwikipedia_scraperフォルダ内に作成します。更新後のプロジェクト構造は次のようになります:
wikipedia-スクレイパー/
├── pyproject.toml
├── README.md
├── wikipedia-スクレイパー/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
これで環境設定が完了し、WikipediaをスクレイピングするPythonコードの記述を開始できます。
2. 対象のWikipediaページへの接続
まず、目的のWikipediaページに接続します。この例では、以下のWikipediaページをスクレイピングします。
PythonでWikipediaページに接続する簡単なコードスニペットは以下の通りです:
import requests # HTTPリクエスト用
from bs4 import BeautifulSoup # HTMLコンテンツパース用
def connect_to_wikipedia(url):
response = requests.get(url) # URLへのGETリクエスト送信
# リクエストが成功したか確認
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # HTMLをパースして返す
else:
print(f"ページ取得に失敗しました。 ステータスコード: {response.status_code}")
return None # リクエスト失敗時はNoneを返す
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # 指定されたURLのsoupオブジェクトを取得
このコードでは、Pythonのrequestsライブラリを使用してURLにHTTPリクエストを送信し、BeautifulSoupでページのHTMLコンテンツをパースできます。
3. ページの検査
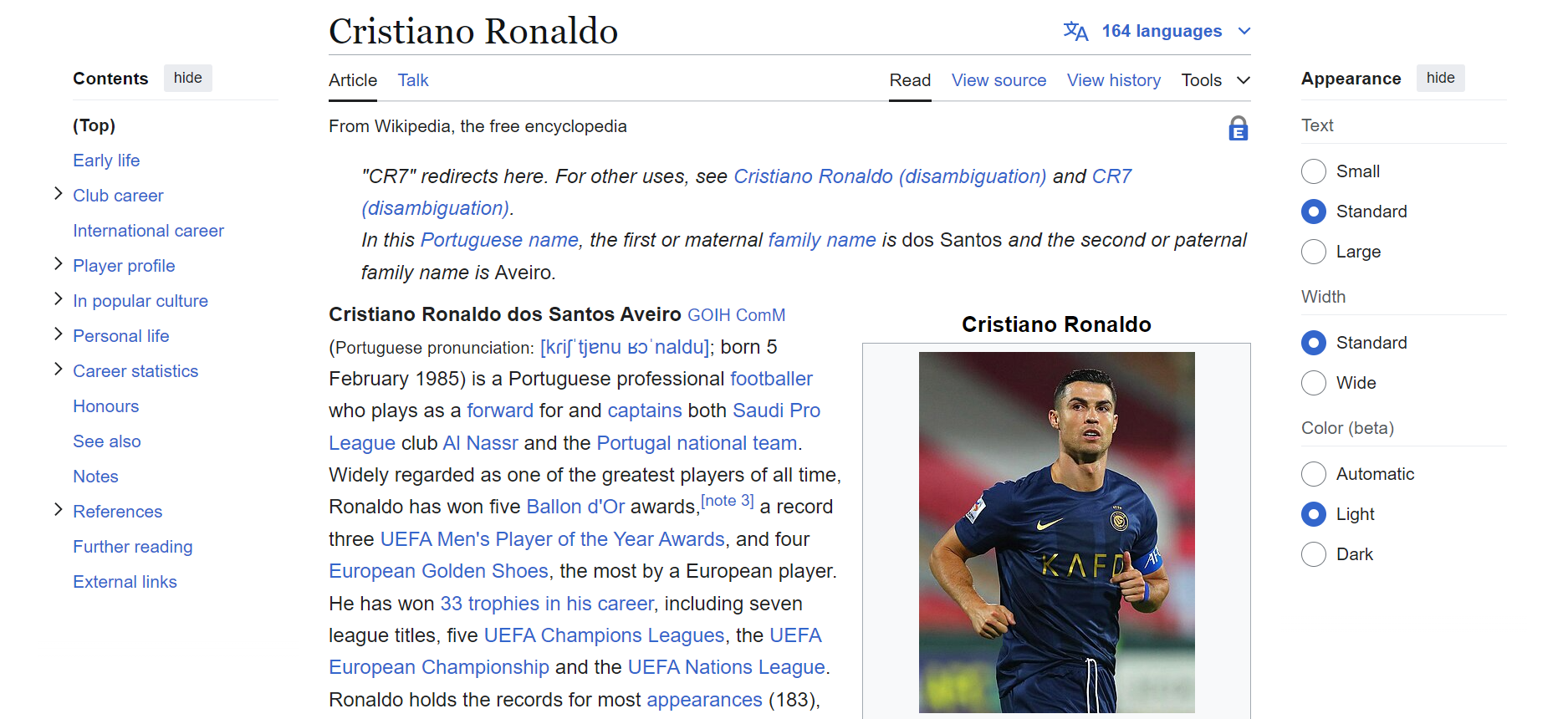
データを効果的にスクレイピングするには、ウェブページのDOM(Document Object Model)構造を理解する必要があります。例えば、ページ上の全リンクを抽出するには、以下のように<a>タグをターゲットにします:
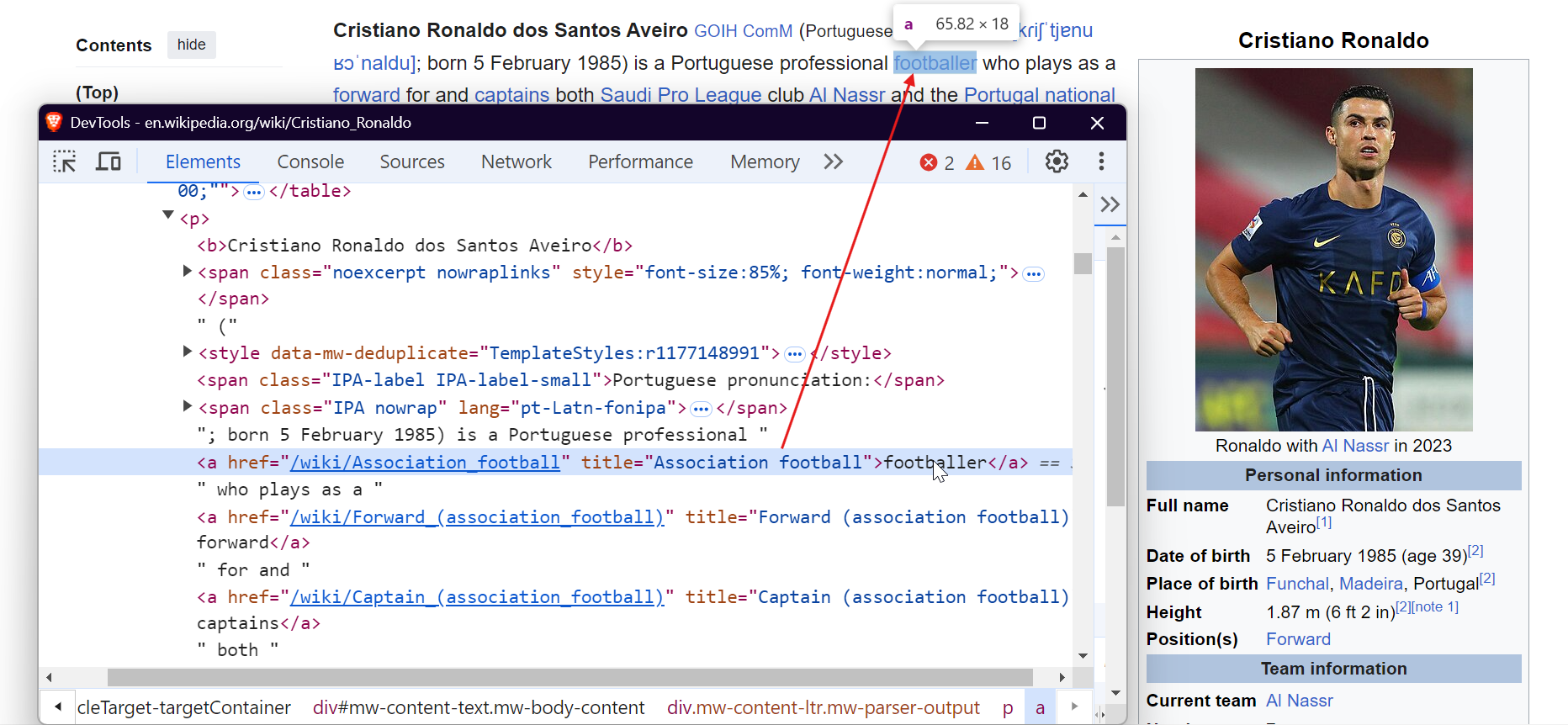
画像をスクレイピングするには、<img>タグをターゲットにし、src属性を抽出することで画像URLを取得します。
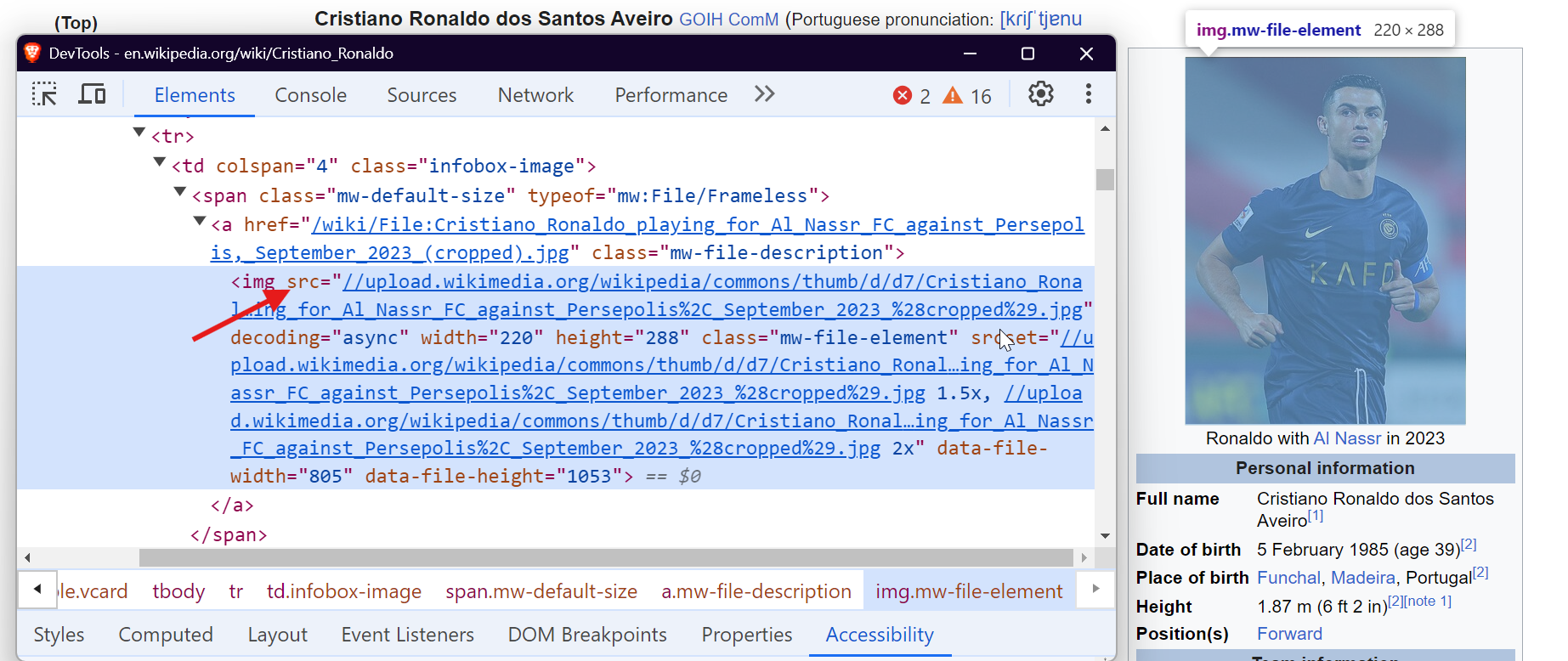
テーブルからデータを抽出するには、クラスwikitable を持つ<table>タグをターゲットにします。これにより、テーブルのすべての行と列を取得し、必要なデータを抽出できます。
段落を抽出するには、ページの主要なテキストコンテンツを含む<p>タグを単純にターゲットにします。
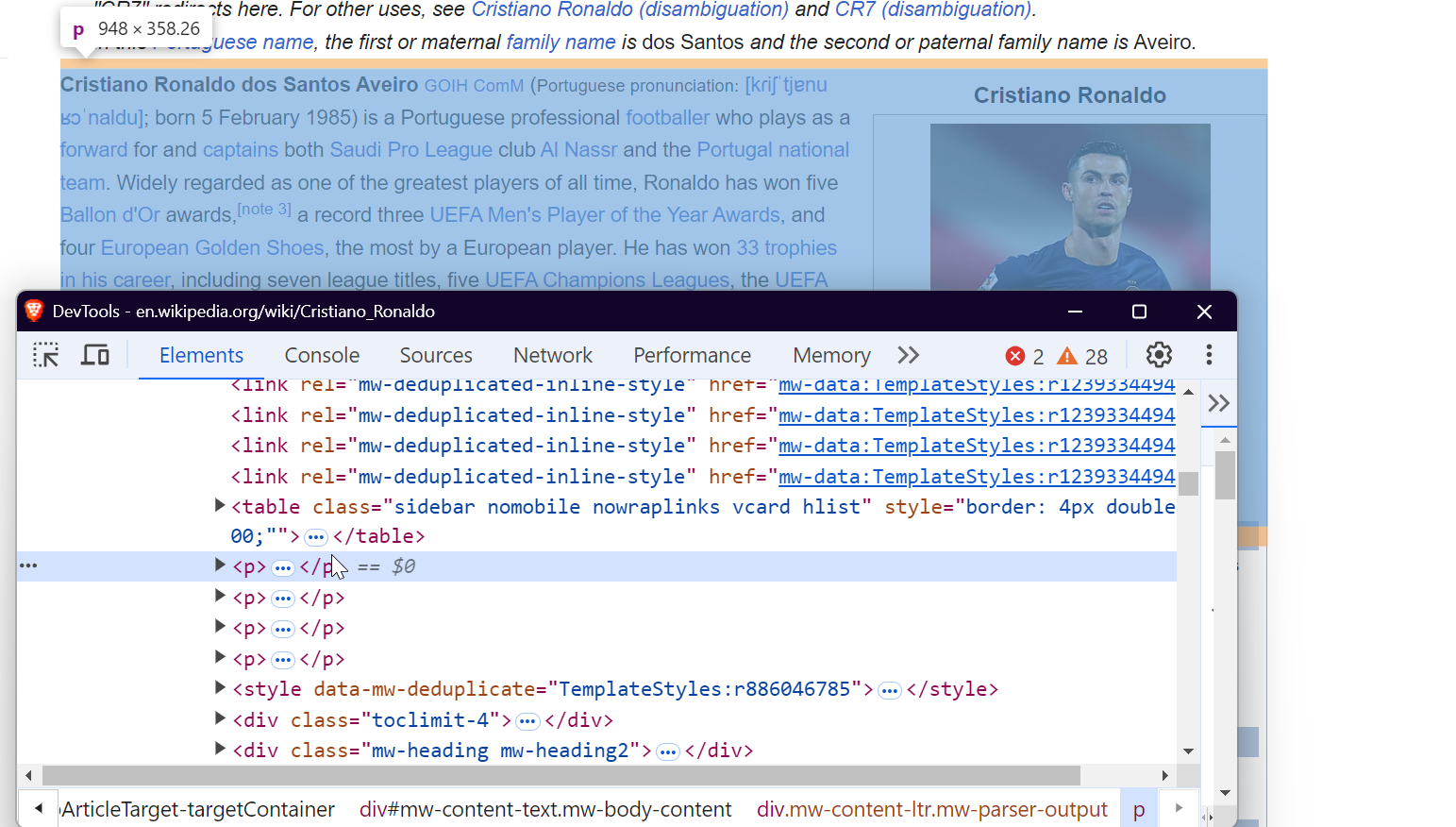
以上です!これらの特定の要素をターゲットにすることで、あらゆるWikipediaページから必要なデータを抽出できます。
4. リンクの抽出
Wikipediaの記事には、関連トピックや参考文献、外部リソースへ誘導する内部リンクと外部リンクが含まれています。Wikipediaページからすべてのリンクを抽出するには、以下のコードを使用できます:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # href属性を持つアンカータグを全て検索
url = link["href"]
if not url.startswith("http"): # URLが相対リンクか確認
url = "<https://en.wikipedia.org>" + url # 相対リンクを絶対URLに変換
links.append(url)
return links # 抽出されたリンクのリストを返す
soup.find_all('a', href=True)関数は、href属性を持つページ上の全ての<a>タグを取得します。これには内部リンクと外部リンクの両方が含まれます。また、相対 URL が適切にフォーマットされるよう処理しています。
結果は以下のような形式になります:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. 段落の抽出
ウィキペディア記事からテキストコンテンツをスクレイピングするには、本文を保持する<p>タグを対象とします。BeautifulSoupを使用した段落抽出方法は以下の通りです:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # 段落タグからテキストを抽出
return [p for p in paragraphs if p and len(p) > 10] # 10文字以上の段落を返す
この関数はページ上の全段落を取得し、引用や単一単語など無関係なコンテンツを避けるため、空の段落や極端に短い段落を除外します。
結果例:
クリスティアーノ・ロナウド・ドス・サントス・アヴェイロGOIHComM(ポルトガル語発音:[kɾiʃˈtjɐnuʁɔˈnaldu]、1985年2月5日生まれ)は、サウジ・プロリーグのアル・ナセルとポルトガル代表の両方でフォワードとしてプレーし、キャプテンを務めるポルトガル人プロサッカー選手である。 史上最高の選手の一人と広く認められ、ロナウドはバロンドールを5回[注3]、UEFA最優秀選手賞を史上最多の3回、欧州ゴールデンシューを欧州選手最多の4回受賞している。キャリア通算33のトロフィーを獲得し、そのうち7つのリーグ優勝、5つのUEFAチャンピオンズリーグ、UEFA欧州選手権、UEFAネーションズリーグが含まれる。 ロナウドは、チャンピオンズリーグ最多出場記録(183試合)、最多得点記録(140得点)、最多アシスト記録(42アシスト)、欧州選手権最多出場記録(30試合)、同大会最多アシスト記録(8アシスト)、同大会最多得点記録(14得点)、国際試合最多得点記録(133得点)、国際試合最多出場記録(215試合)を保持している。 彼はプロキャリア通算1,200試合以上に出場した数少ない選手の一人であり、フィールドプレーヤーとしては最多記録である。また、クラブと代表での公式戦通算900ゴール以上を記録し、史上最高の得点王となっている。
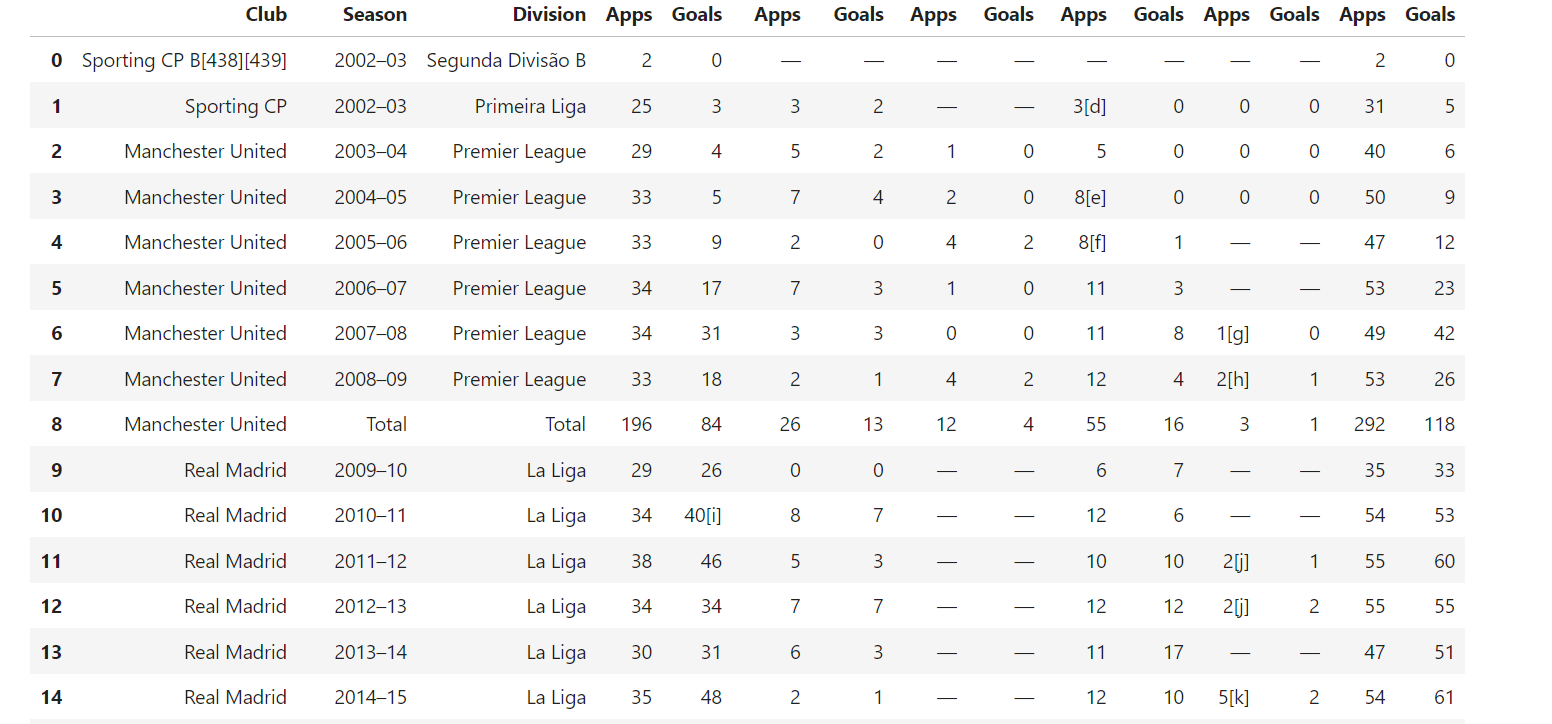
6. テーブルの抽出
Wikipediaには構造化されたデータを含む表が頻繁に掲載される。これらの表を抽出するには、以下のコードを使用する:
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # 'wikitable'クラスを持つテーブルを検索
table_html = StringIO(str(table)) # テーブルHTMLを文字列に変換
df = pd.read_html(table_html)[0] # HTMLテーブルをDataFrameとして読み込み
tables.append(df)
return tables # DataFrameのリストを返す
この関数は、クラスwikitableを持つすべてのテーブルを検索し、pandas.read_html()を使用してそれらをDataFrameに変換し、さらなる操作を可能にします。
結果例:
7. 画像の抽出
画像もWikipediaからスクレイピングできる貴重なリソースです。以下の関数はページから画像URLを取得します:
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # src属性を持つ画像タグを全て検索
img_url = img["src"]
if not img_url.startswith("http"): # 相対URLには'https:'を先頭に追加
img_url = "https:" + img_url
if "static/images" not in img_url: # 静的画像や関連性のない画像を排除
images.append(img_url)
return images # 画像URLのリストを返す
この関数はページ上の全画像(<img>タグ)を検索し、相対URLにはhttps:を追加し、コンテンツ非関連画像をフィルタリングして、関連画像のみを抽出します。
結果例:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. スクレイピングしたデータの保存
データを抽出したら、次に後で使用するために保存します。リンク、画像、段落、表を別々のファイルに保存しましょう。
def store_data(links, images, tables, paragraphs):
# リンクをテキストファイルに保存
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# 画像をJSONファイルに保存
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# 段落をテキストファイルに保存
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# 各表を個別のCSVファイルとして保存
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
store_data関数はスクレイピングしたデータを整理します:
- リンクはテキストファイルに保存されます。
- 画像URLはJSONファイルに保存されます。
- 段落は別のテキストファイルに保存されます。
- テーブルはCSVファイルに保存されます。
この整理方法により、後でデータにアクセスしたり操作したりするのが容易になります。
PythonでデータをパースしJSONにシリアライズする方法の詳細については、ガイドをご覧ください。
すべてを統合する
では、すべての関数を組み合わせて、Wikipediaページからデータを抽出して保存する完全なスクレイパーを作成しましょう:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# ページから全リンクを抽出
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# ページから画像URLを抽出
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # 不要な静的画像を排除
images.append(img_url)
return images
# ページから全てのテーブルを抽出
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # HTMLテーブルをDataFrameに変換
tables.append(df)
return tables
# ページから段落を抽出
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in paragraphs if p and len(p) > 10] # 空または短い段落を除外
# 抽出したデータを別々のファイルに保存
def store_data(links, images, tables, paragraphs):
# リンクをテキストファイルに保存
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# 画像をJSONファイルに保存
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# 段落をテキストファイルに保存
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# 各表をCSVファイルとして保存
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# ウィキペディアページをスクレイピングし、抽出データを保存するメイン関数
def scrape_wikipedia(url):
response = requests.get(url) # ページコンテンツを取得
soup = BeautifulSoup(response.text, "html.parser") # BeautifulSoupでコンテンツをパース
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# 抽出データを全てファイルに保存
store_data(links, images, tables, paragraphs)
# 使用例: クリスティアーノ・ロナウドのWikipediaページをスクレイピング
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
スクリプトを実行すると、ディレクトリ内に以下のファイルが作成されます:
wikipedia_images.json: すべての画像URLを含むwikipedia_links.txt: ページ内の全リンクを格納。wikipedia_paragraphs.txt:抽出された段落を保持。- ページ内の各表に対応するCSVファイル(例:
wikipedia_table_1.csv,wikipedia_table_2.csv)。
結果は以下のようになります:

以上です!ウィキペディアからデータをスクレイピングし、個別ファイルに保存することに成功しました。
Bright Data WikipediaスクレイパーAPIの設定
Bright Data WikipediaスクレイパーAPIの設定と使用は簡単で、わずか数分で完了します。以下の手順に従って、すぐに開始し、簡単にWikipediaからデータを収集しましょう。
ステップ1: Bright Dataアカウントの作成
Bright Dataのウェブサイトにアクセスし、アカウントにサインインします。アカウントをお持ちでない場合は、新規作成してください(無料で利用開始できます)。手順は以下の通りです:
- Bright Dataのウェブサイトにアクセスします。
- 「無料トライアルを開始」をクリックし、指示に従ってアカウントを作成します。
- ダッシュボードにアクセスしたら、左サイドバーのクレジットカードアイコンから「請求」ページを開きます。
- 有効な支払い方法を追加してアカウントを有効化します。
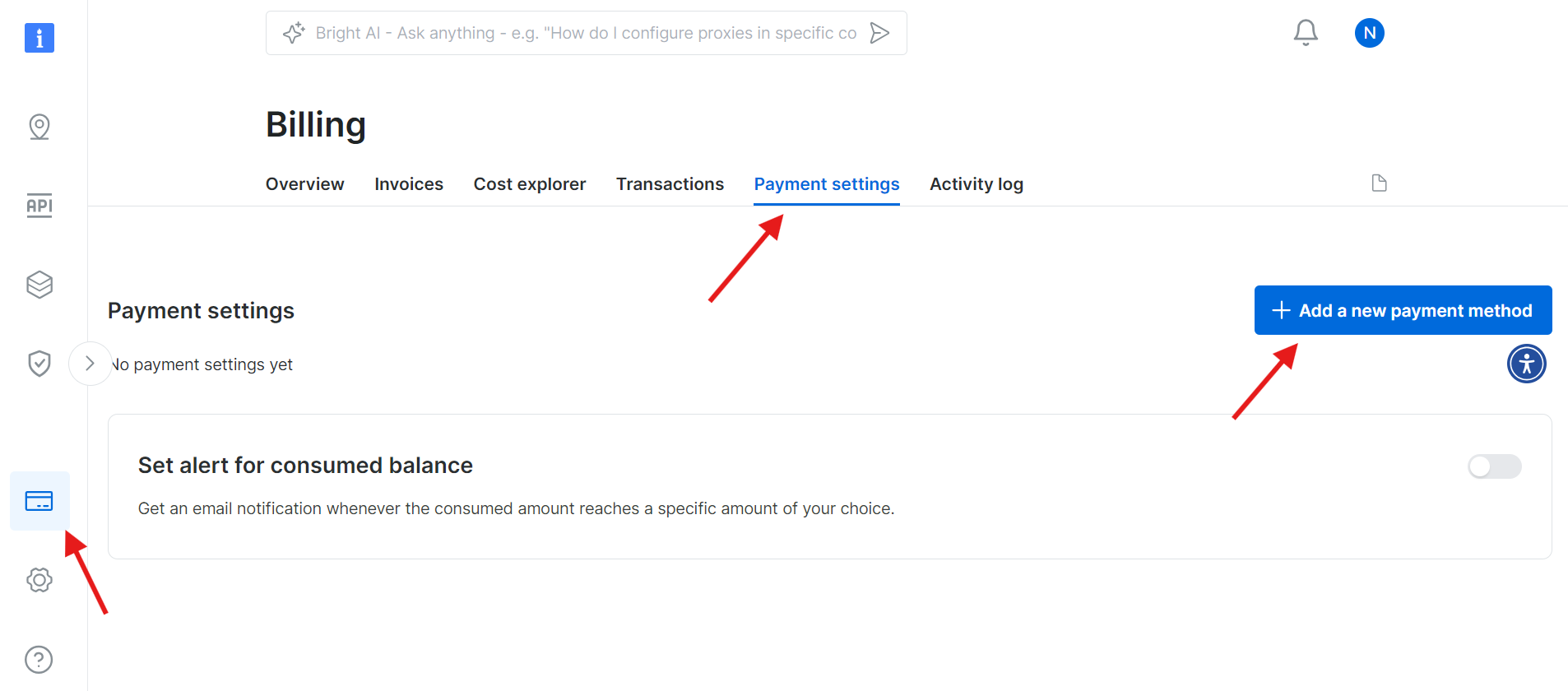
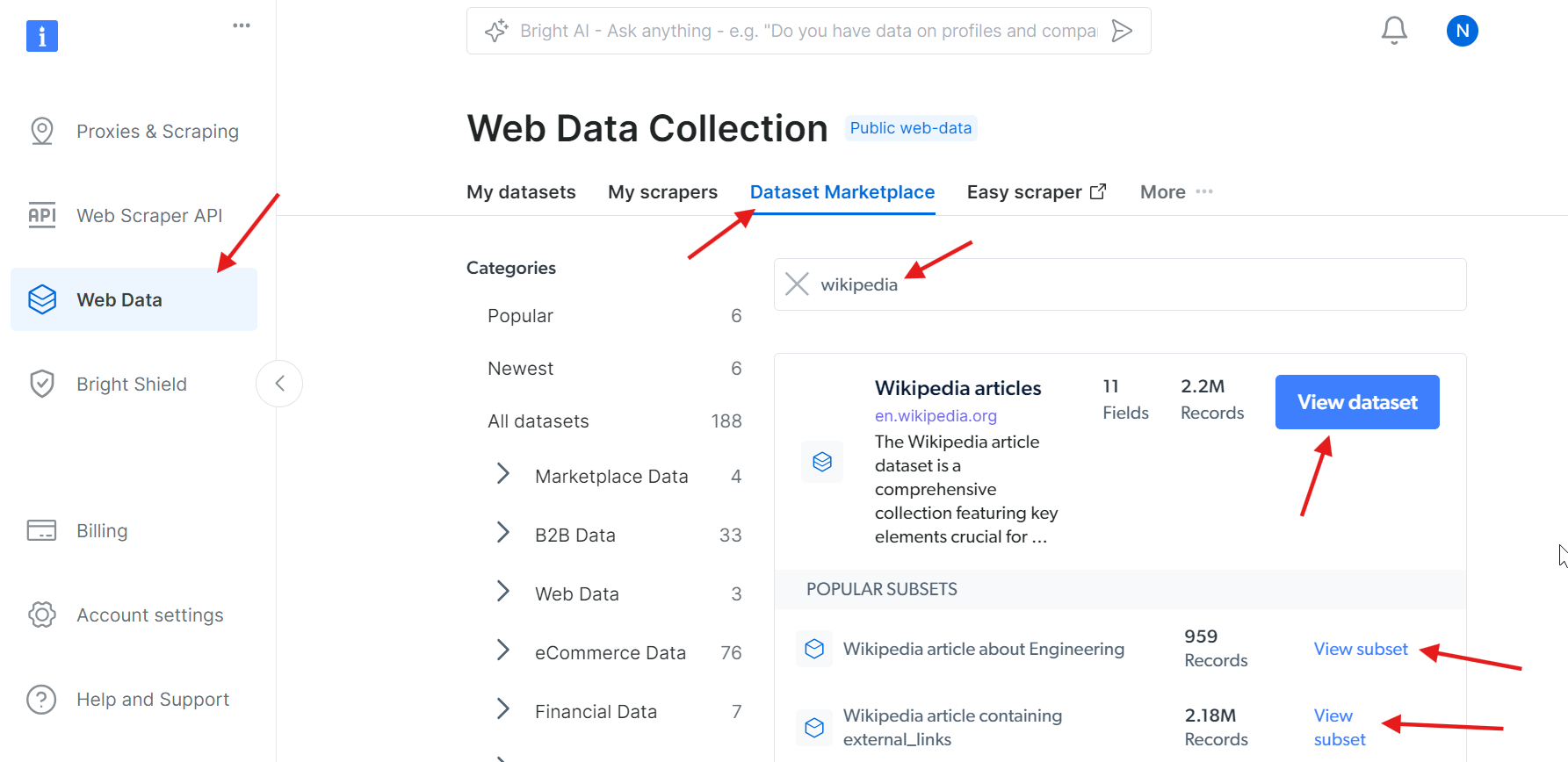
アカウントの有効化が完了したら、ダッシュボードの「WebスクレイパーAPI」セクションに移動します。ここでは、使用したいWebスクレイパーAPIを検索できます。今回の目的では「Wikipedia」を検索してください。
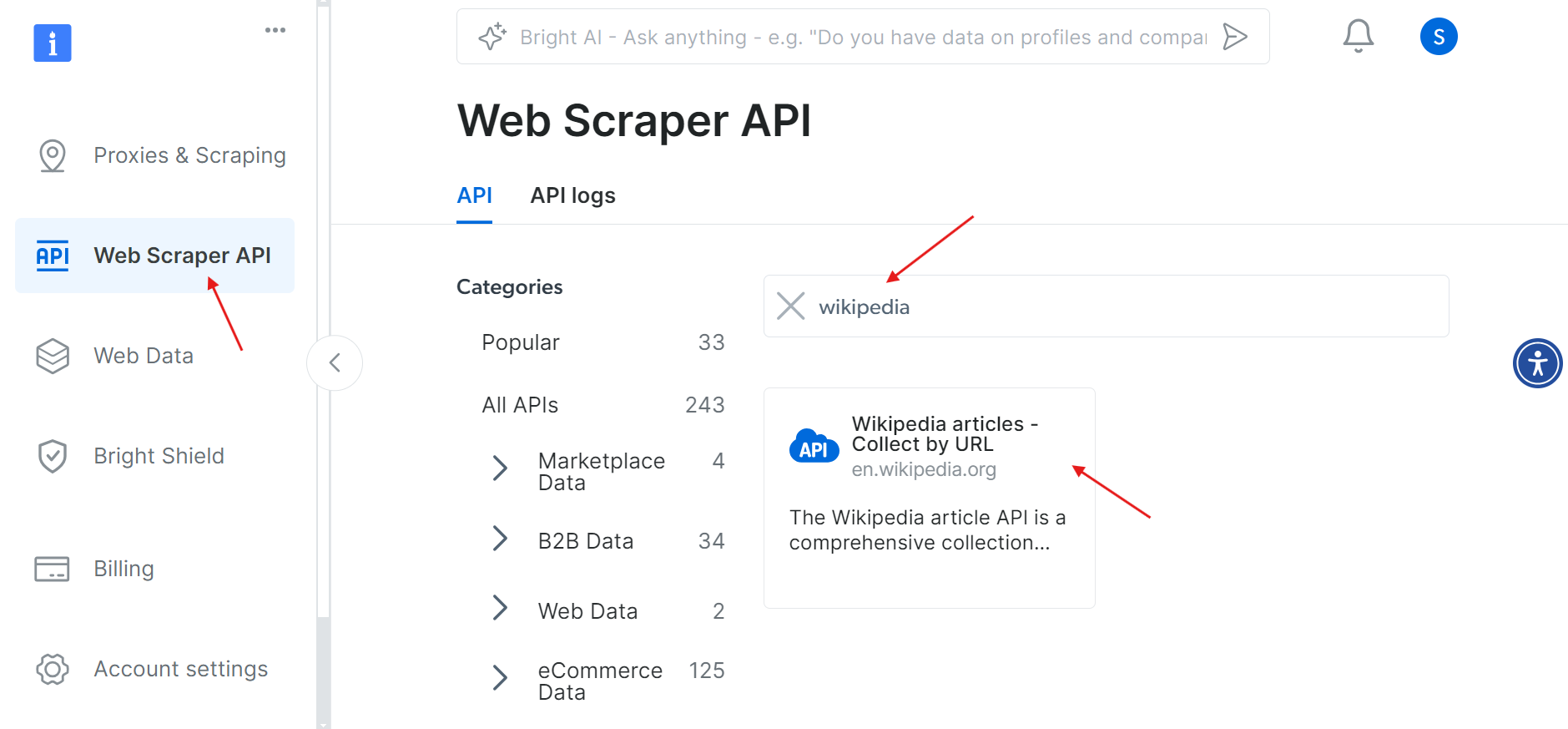
「Wikipedia articles – Collect by URL」オプションをクリックします。これにより、URLを指定するだけでWikipedia記事を収集できます。
ステップ2: API呼び出しの設定を開始
クリックすると、API呼び出しを設定できるページに移動します。
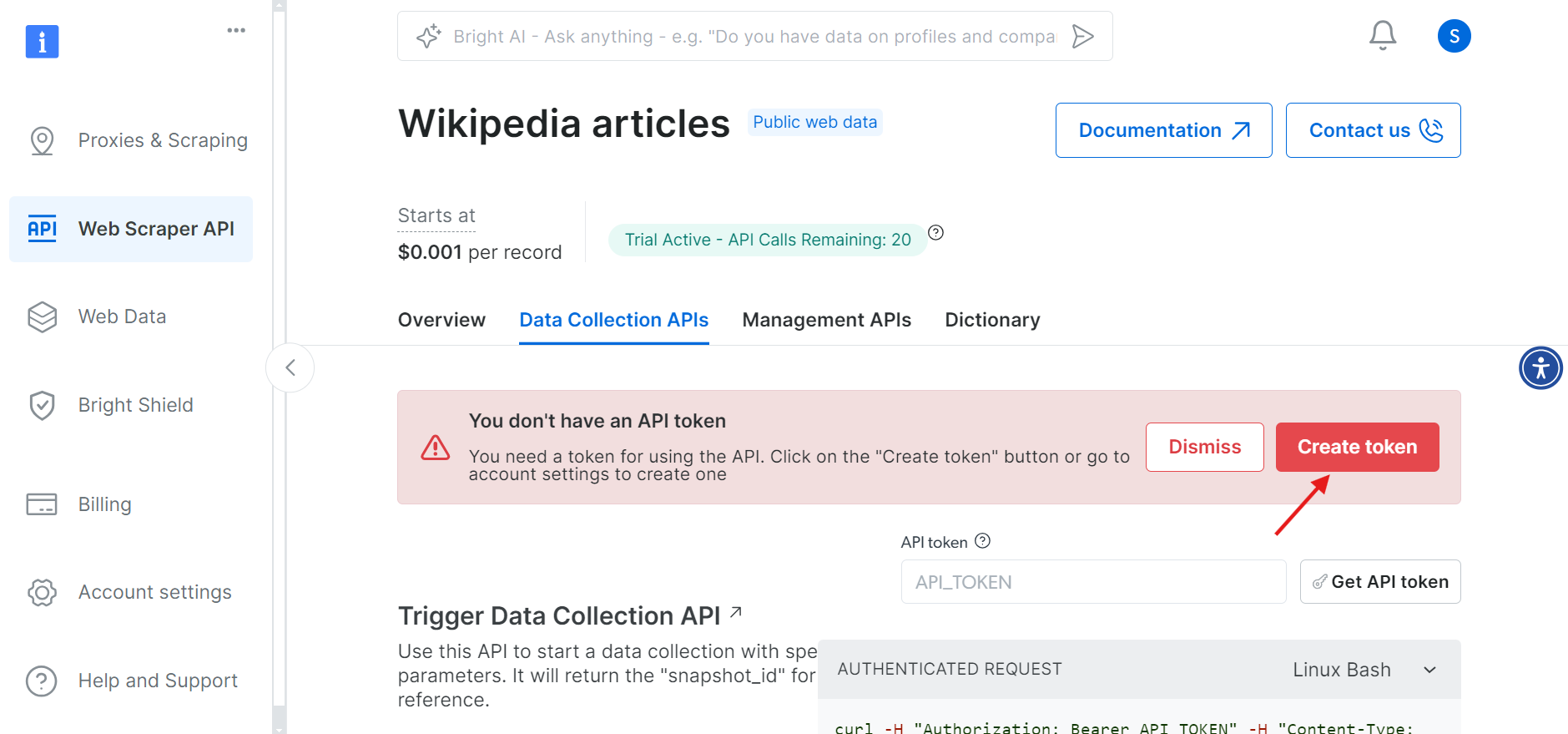
先に進む前に、API呼び出しを認証するためのAPIトークンを作成する必要があります。「トークンを作成」ボタンをクリックし、生成されたトークンをコピーしてください。このトークンは後で必要になるため、安全に保管してください。
ステップ3: パラメータ設定とAPIコール生成
トークンが準備できたので、API呼び出しの設定に移ります。スクレイピングしたいウィキペディアページのURLを入力すると、右側にその入力に基づいて生成されたcURLコマンドが表示されます。
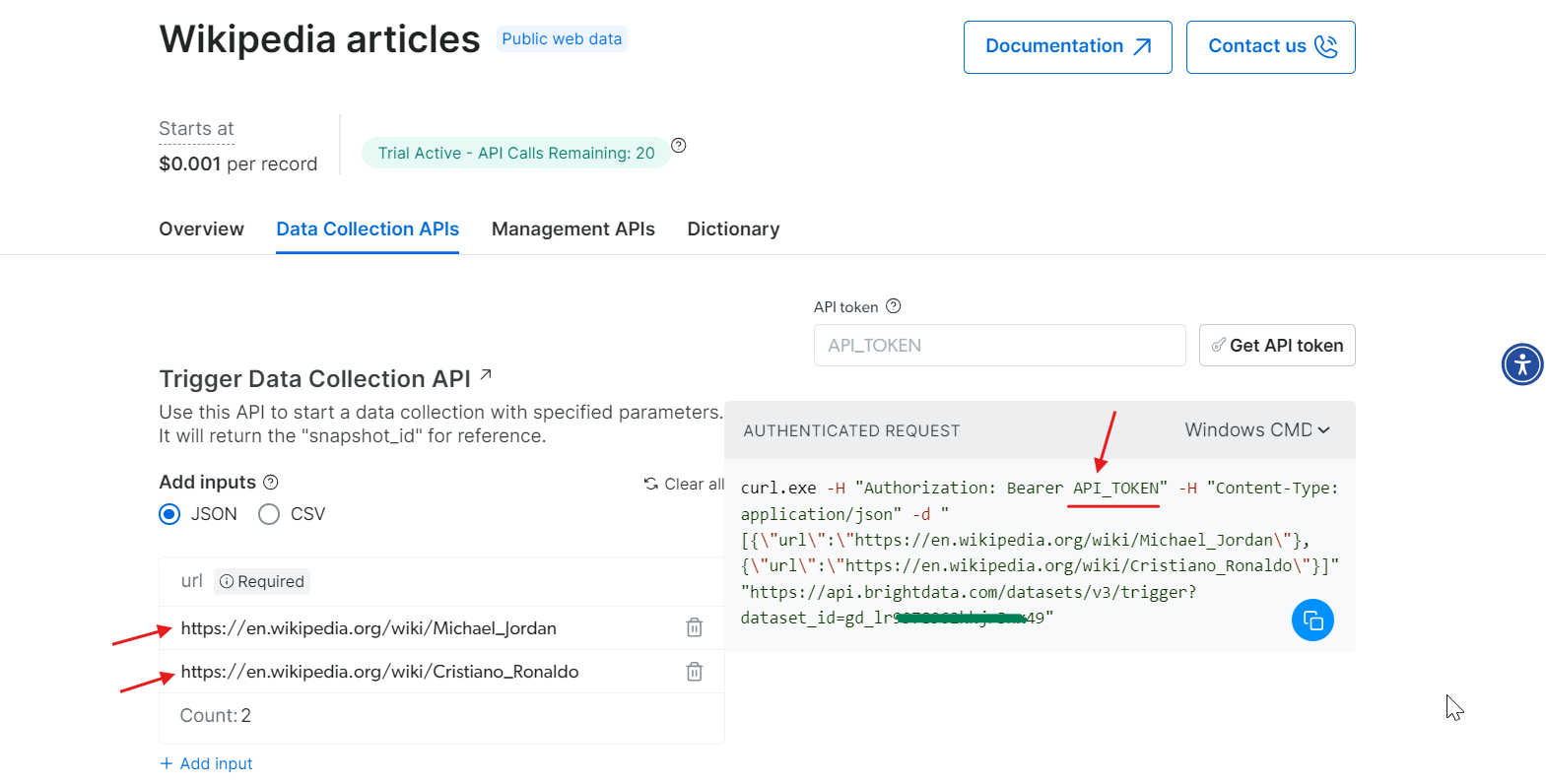
cURLコマンドをコピーし、API_Tokenを実際のトークンに置き換えてターミナルで実行します。これによりスナップショットIDが生成され、これがスクレイピングしたデータを取得するために使用されます。
ステップ4: データの取得
生成したsnapshot_idを使用してデータを取得できます。このIDを「スナップショットID」フィールドに貼り付けると、APIが自動的に右側に新しいcURLコマンドを生成します。このコマンドを使用してデータを取得できます。さらに、データのファイル形式(JSON、CSVなど利用可能なオプション)を選択することも可能です。
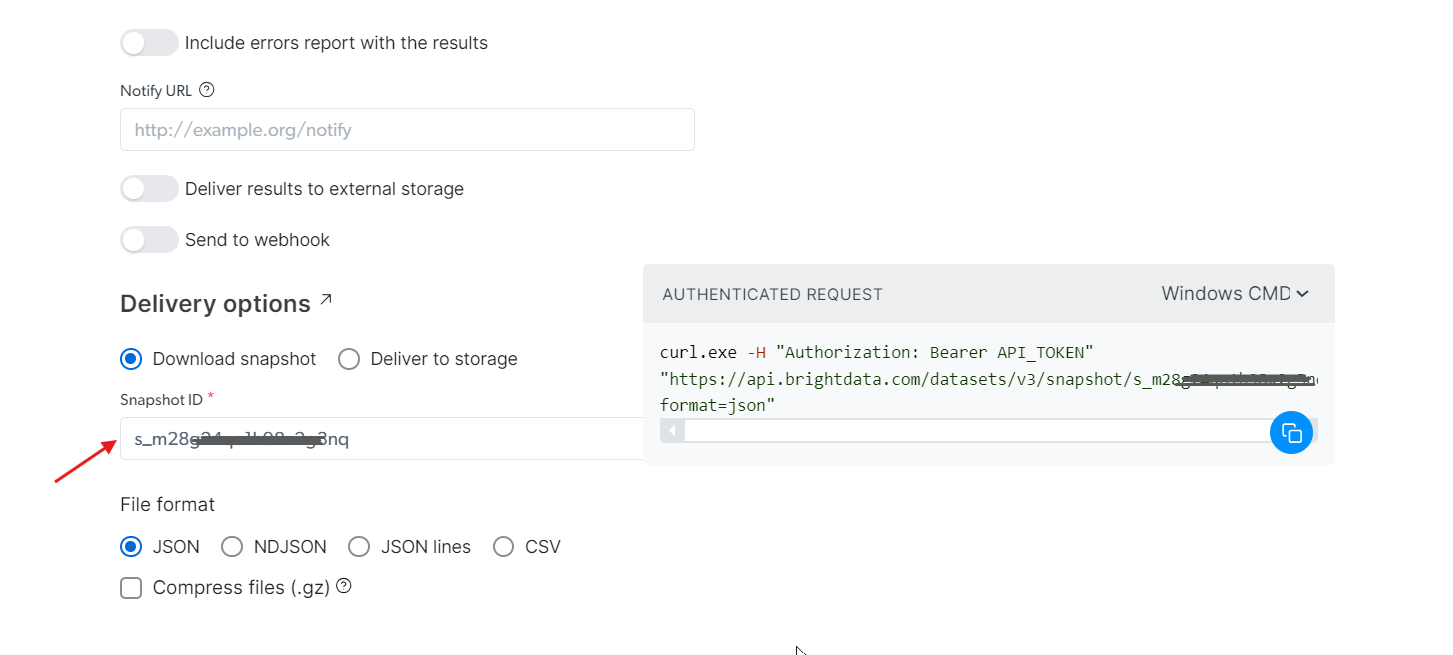
Amazon S3、Google Cloud Storage、Microsoft Azure Storageなどの各種ストレージサービスへのデータ配信も選択可能です。
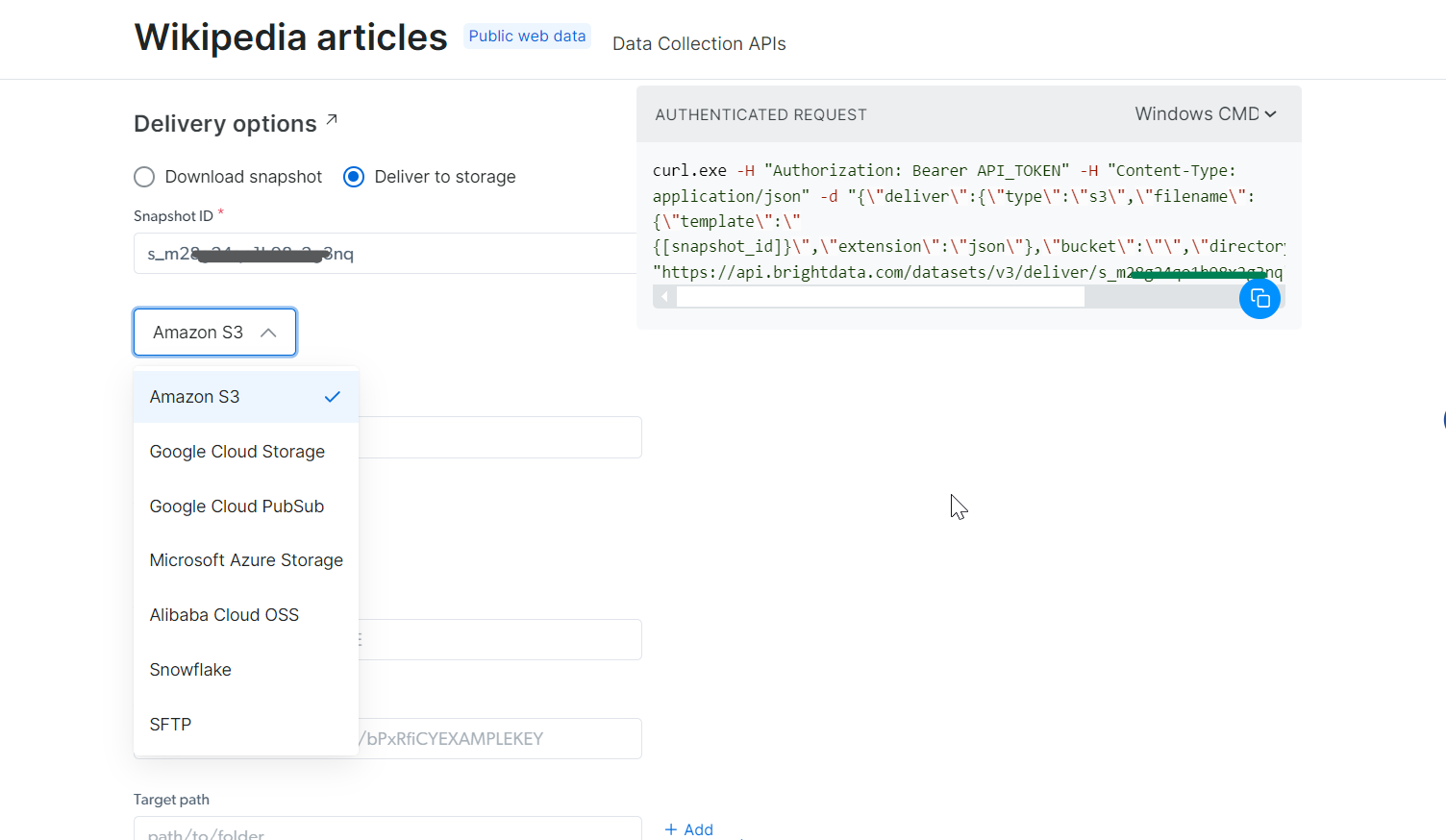
ステップ5: コマンドの実行
この例では、データをJSONファイルで取得すると仮定します。ファイル形式としてJSONを選択し、生成されたcURLコマンドをコピーします。データを直接ファイルに保存したい場合は、cURLコマンドの末尾に-o my_data.jsonを追加するだけです。このデータをローカルマシンに保存したい場合は、-oを追加すると指定したファイルに自動的に保存されます。
ターミナルで実行すると、わずか数秒で抽出された全データが取得できます!
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "<HTTPS://api.brightdata.com/データセット/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>" -o my_data.json
ウィキペディアのウェブスクレイピングを自分で処理したくないが、データは必要ですか?代わりにウィキペディアデータセットの購入をご検討ください。
はい、それだけです!
まとめ
この記事では、Pythonを使用したWikipediaスクレイピングを始めるために必要なすべてを網羅しました。画像URL、テキストコンテンツ、表、内部リンクや外部リンクなど、様々なデータを抽出することに成功しました。しかし、より高速で効率的なデータ抽出には、BrightDataのWikipediaスクレイパーAPIを利用するのが最も簡単な解決策です。
他のウェブサイトのウェブスクレイピングをお考えですか?今すぐ登録してWeb Scraper APIをお試しください。無料トライアルを今日から始めましょう!





