

約25年にわたり、トリップアドバイザーはウェブ上で様々な旅行先を発見する優れた場所でした。本日はトリップアドバイザーからホテルデータをスクレイピングします。トリップアドバイザーは以下のようなスクレイパー対策技術を採用しています:
- JavaScriptによる対策
- ブラウザフィンガープリント
- 動的ページコンテンツ
以下のガイドに従えば、最終的にはトリップアドバイザーのスクレイピングを容易に実行できるようになります。
前提条件
Tripadvisorは様々なブロック技術を使用しています。簡潔に説明するため、以下のリストに分類しました。
- JavaScriptチャレンジ:トリップアドバイザーは、CAPTCHAの形で(JavaScriptによる)簡単なチャレンジをブラウザに送信します。ブラウザがこれを解決できない場合、ボットである可能性が高いです。
- ブラウザフィンガープリント: ブラウザにクッキーを送信し、それを使ってユーザーを追跡します。
- 動的コンテンツ: 最初は空白ページが表示されます。その後、一連のAPI呼び出しを行い、データを取得・レンダリングします。
Python RequestsとBeautifulSoupだけでは不十分です。実際のブラウザが必要です。Seleniumではwebdriverを使用し、Pythonスクリプト内からブラウザを制御します。Seleniumには必要な機能が全て組み込まれています。Seleniumを用いたウェブスクレイピングの詳細はこちら。
Seleniumをインストールしましょう。同時にwebdriverもインストールされていることを確認してください。webdriverの最新バージョンはこちらから入手できます。ChromedriverのバージョンがChromeのバージョンと一致していることを必ず確認してください。
以下のコマンドでバージョンを確認できます。Chromedriverのバージョンと一致していることを確認してください。
google-chrome --version
出力は以下のような形式になります。
Google Chrome 130.0.6723.116
次に、以下のコマンドでSeleniumをインストールできます。
pip install selenium
Seleniumがインストールされれば、他に何もインストールする必要はありません。Seleniumがスクレイピング関連のすべてのニーズを処理します。このチュートリアルで使用するその他のパッケージはすべてPythonに標準で含まれています。
トリップアドバイザーからスクレイピングする内容
具体的にTripadvisorからホテル情報をスクレイピングする方法を見ていきましょう。Tripadvisorで「マイアミ」の基本検索を行うと、以下のスクリーンショットのようなページが表示されます。ご覧の通り、ホテルだけでなく全カテゴリの結果が表示されています。
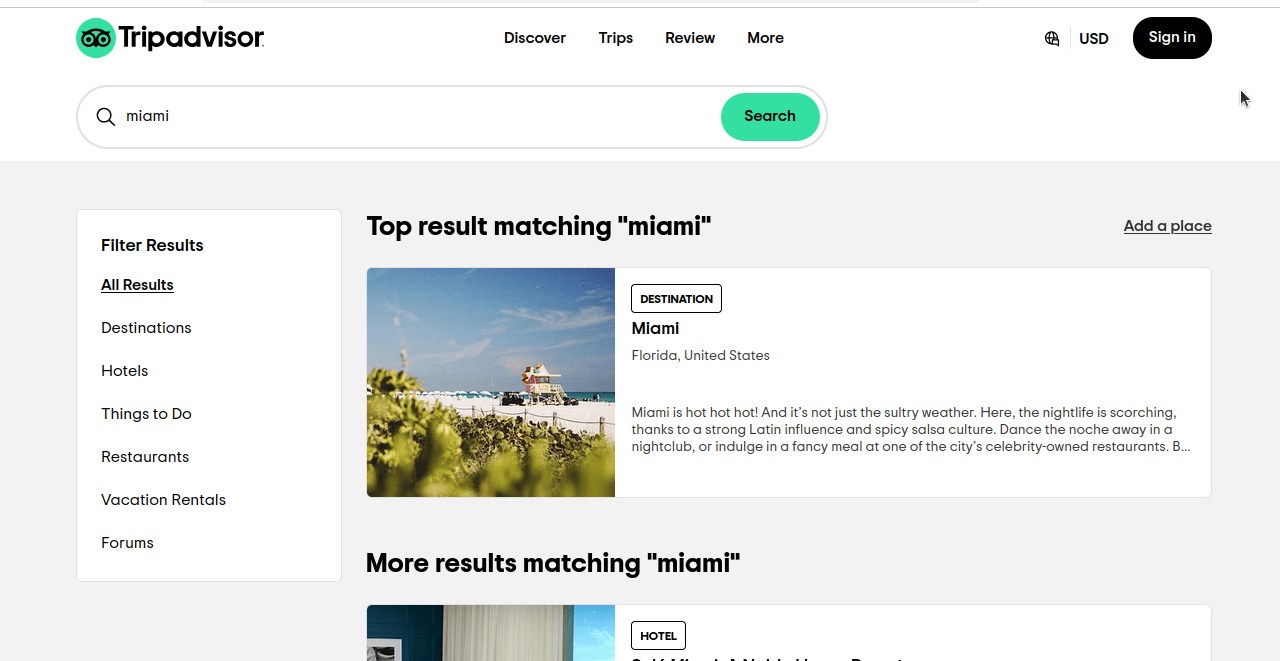
このページのURLを詳しく見てみましょう:https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0。次に「ホテル」をクリックし、URLを確認します:https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0。URLは依然として非常に似通っています。以下ではこれらのURLを確認しますが、不要な部分は削除します。
- 全検索結果:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - ホテル:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrcは結果を選択するためのクエリです。ssrc=aは 全結果用、ssrc=hは ホテル用です。このリンクhttps://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=hをクリックすると、以下のスクリーンショットのようなページが表示されるはずです。
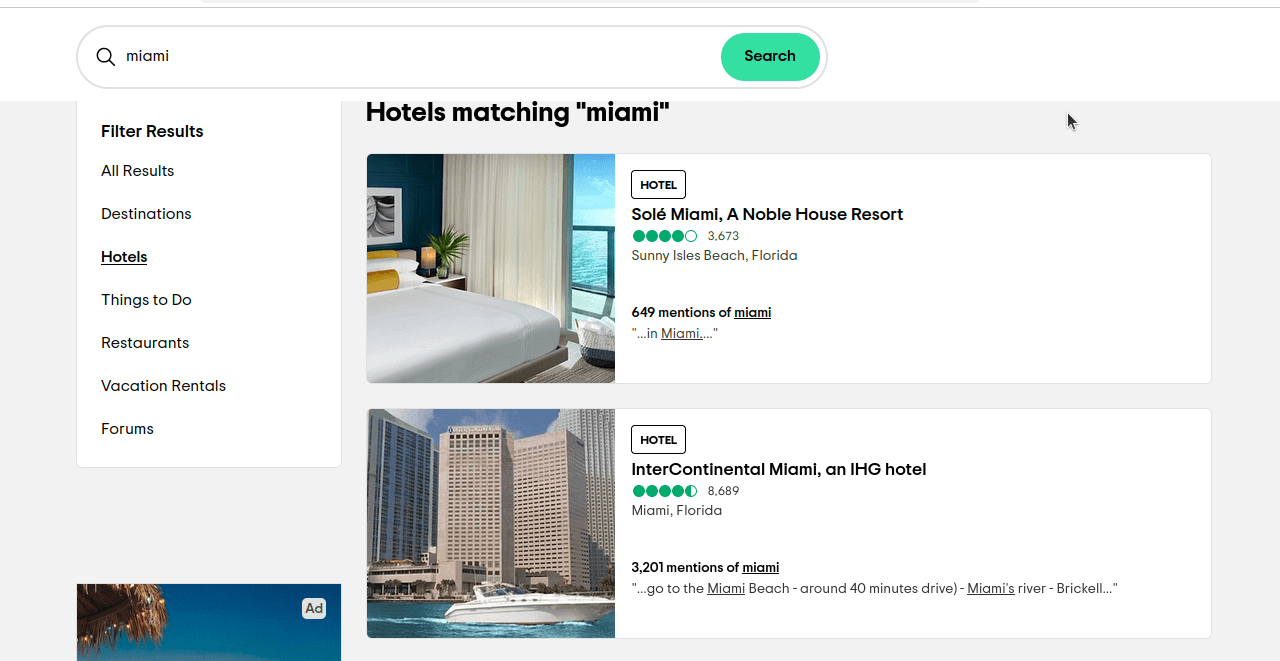
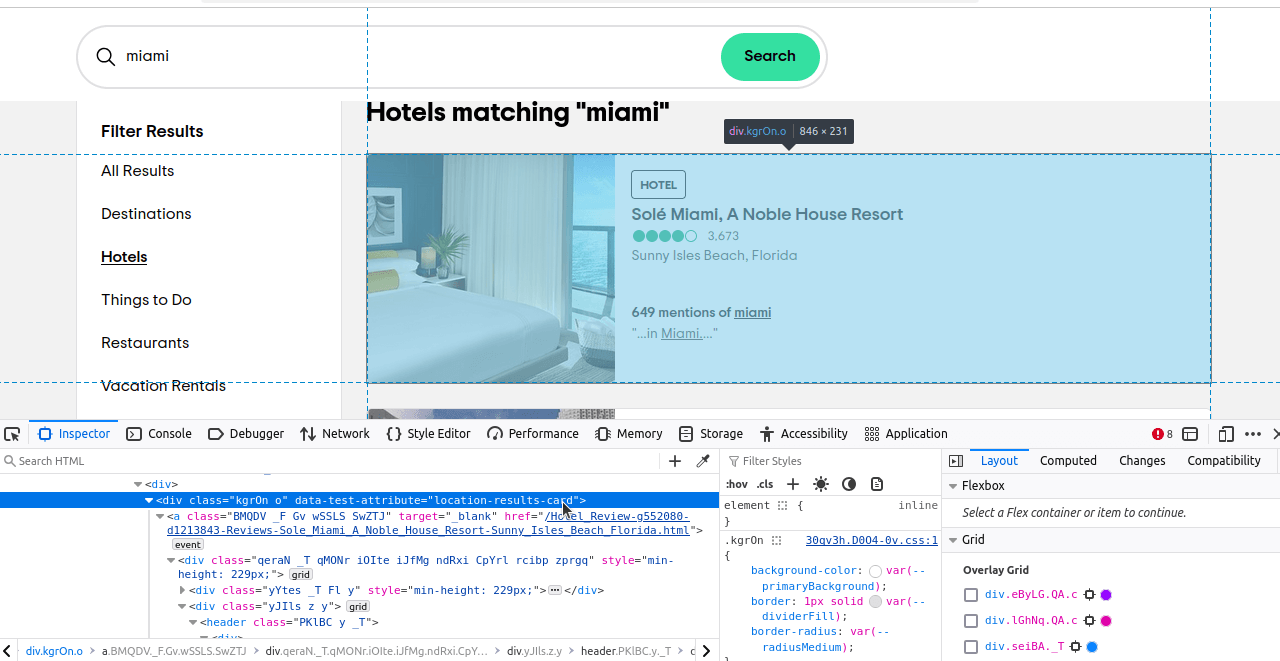
次に、特定したい要素を特定する必要があります。これらの要素を検査すると、各結果に「location-results-card」 というdata-test-attributeがあることに気づくはずです。これは非常に重要です。 この属性を使ってCSSセレクタを記述できます:div[data-test-attribute='location-results-card']。実際のページをスクレイピングする際、このセレクタに一致するページ上の全要素を検索します。
Vanilla SeleniumでTripadvisorをスクレイピング
では、シンプルなSeleniumを使ってTripadvisorのスクレイピングを試みます。全体的に非常にシンプルなスクリプトを作成します。必要な関数は2つだけです。スクレイピングを実行する関数と、データをCSVに書き出す関数です。これらを準備したら、すべてを組み合わせて完全に機能するスクリプトに仕上げます。
write_to_csv() 関数を見てみましょう。引数としてdata とpage_number を取ります。dataは書き込む辞書(dict)または辞書の配列です。page_numberはファイル名の記述に使用されます。Path(filename).exists()でファイルの存在を確認します。modeはファイルを開く際のモードです。ファイルが存在する場合はモードを 「a」(追加)に設定します。ファイルが存在しない場合はモードをデフォルトの「w」(書き込み)のままにします。この2つのモード設定により、常にファイルが存在し、既存ファイルが上書きされないことを保証します。
個々の関数
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSVへの書き込み中...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSVファイルにデータを書き込み中...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page}をCSVに正常に書き出しました...")
- 関数の先頭で、
データがリストかどうかを確認します。そうでない場合はリストに変換します。 f"tripadvisor-{page_number}.csv"でファイル名を構築します。- デフォルト
モードは"w"ですが、ファイルが存在する場合はモードを"a"に変更します。 csv.DictWriter(file, fieldnames=data[0].keys())でファイルライターを初期化します。- 書き込みモードの場合、最初のオブジェクトのキーをヘッダーとして使用します。ファイルへの追加モードの場合は、この処理は不要です。
- ファイル設定後、
writer.writerows(data)でデータをCSVファイルに書き込みます。
次に、スクレイピング関数を見てみましょう。この関数は引数を1つだけ受け取ります。page_numberです…説明不要でしょう。まずカスタムChromeOptionsを設定します。ブラウザをヘッドレスモードにし、偽のユーザーエージェントを使用する引数を追加します。これでTripadvisorの検知を回避できるはずです。次にwebdriverでブラウザを起動し、検索結果ページに移動します。 コンテンツの読み込みを5秒待つためsleep(5)を使用します。これにより通常のユーザーに近い動作を再現できます。前述の「スクレイピング対象」セクションで説明したCSSセレクタを使用します。hotel_cardsが存在しない場合、スクリーンショットを撮影し関数を早期終了します。hotel_cardsが存在する場合、データを抽出してscraped_data配列に追加します。スクレイピングが完了したら、全データをCSVに書き込みます。
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Connecting to スクレイピングブラウザ...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("接続完了!ページをスクレイピング中...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"カード {index} のスクレイピングに成功")
print(f"ページ {page_number} をスクレイピングしました")
write_to_csv(scraped_data, page_number)
トリップアドバイザーデータのスクレイピング
すべてをまとめると、以下のようなスクリプトになります。以下のコードを自由にコピーして、ご自身のPythonファイルに貼り付けてください。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSVへの書き込み中...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSVファイルへのデータ書き込み中...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page}をCSVに正常に書き出しました...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("スクレイピングブラウザに接続中...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("接続完了!ページをスクレイピング中...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"カード {index} のスクレイピングに成功しました")
print(f"ページ {page_number} をスクレイピングしました")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
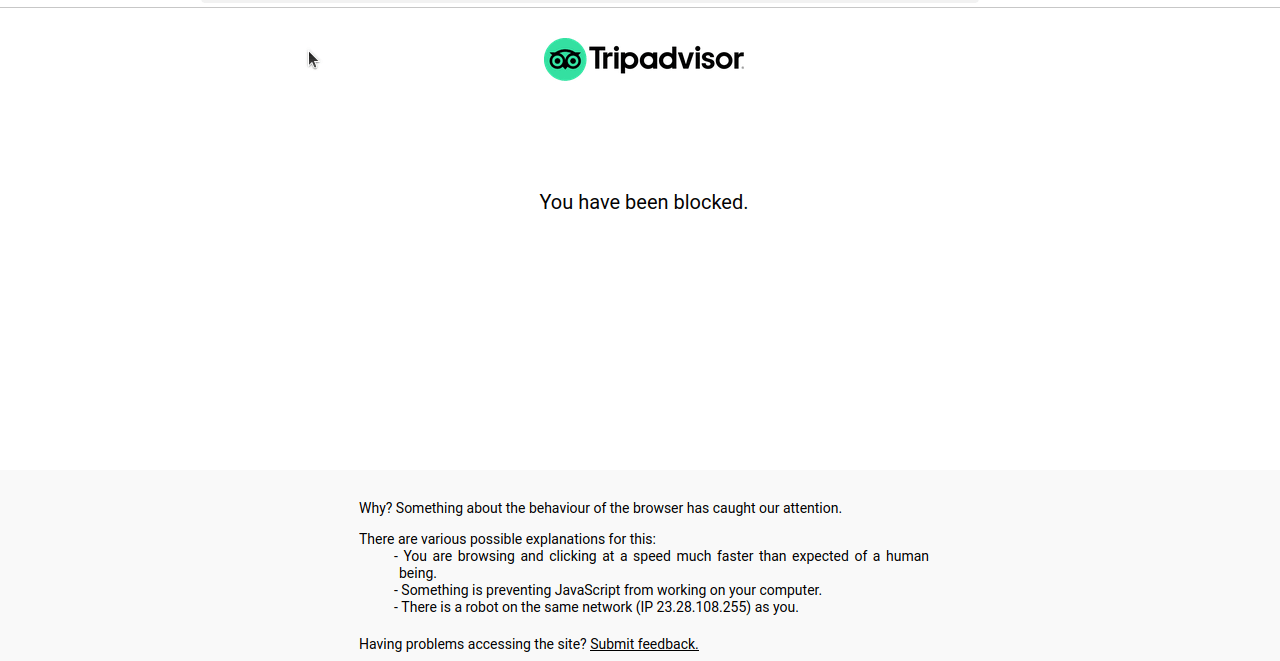
このコードを実行すると、多くの場合、以下のスクリーンショットのように画面がブロックされたり、CAPTCHAが表示されたりします。

高度なテクニック
以下に、当スクリプトで使用されている高度なテクニックの一部を紹介します。主に、ページネーションの処理方法とブロック回避のためのテクニックについて解説します。
ページネーションの処理
使用するURLを確認してください:https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}。ページネーションはoffsetパラメータで処理されます。1ページあたり30件の結果を取得します。page_number*30はページ番号に1ページあたりの結果数(30)を乗算します。 ページ0では1~30件の結果が取得されます。ページ2では31~60件の結果が保持され…以下同様です。
メイン関数も詳しく見てみましょう。PAGESにはスクレイピングしたいページ数が保持されています。最初の5ページ分のデータをスクレイピングしたい場合は、PAGES = 1をPAGES = 5 に変更するだけです。
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
ブロック対策
Vanilla Seleniumでは、ブロックされるのを防ぐためにいくつかの手法を採用しています。偽のユーザーエージェントを使用すると同時にsleep(5)を実行します。このsleep関数はページの読み込みを可能にし、複数ページをスクレイピングする際のリクエスト間隔を調整します。
以下がユーザーエージェントです。これによりトリップアドバイザーは、当ブラウザがChrome 130.0.0. 0およびSafari 537.36と互換性があると認識します。トリップアドバイザーがこれを読み取ると、サーバーはこれらのブラウザに対応したページを返します。
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36
ただし、検出される可能性やスクレイパーがブロックされるリスクは依然として存在します。ブロックを確実に回避するには、Vanilla Seleniumよりも強力な手段が必要です。
Bright Dataの利用を検討しよう
Bright Dataには、Vanilla Seleniumで遭遇したブロックを回避するためのあらゆるソリューションが揃っています。スクレイピングブラウザを使えば、Bright Dataの最高品質プロキシのみを使用して、リモート環境でSeleniumを実行できます。まず、登録プロセスを説明します。その後、以前のスクリプトをスクレイピングブラウザで実行できるように調整します。
アカウントの作成
まず、当社のスクレイピングブラウザページにアクセスしてください。「無料トライアル」をクリックします。Googleアカウント、GitHubアカウント、またはメールアドレスを使用してアカウントを作成できます。
アカウント作成後、ダッシュボードが表示されます。「追加」をクリックしてください。
下図のようなドロップダウンが表示されます。「スクレイピングブラウザ」をクリックしてください。
これでスクレイピングブラウザの設定ページに移動します。ここではデフォルト設定のまま進めます。スクレイピングブラウザにはデフォルトでCAPTCHAソルバーが組み込まれています。
最後に、スクレイピングブラウザゾーンの作成を促すメッセージが表示されます。スクレイピングブラウザを試す準備ができている場合は、「はい」をクリックしてください。
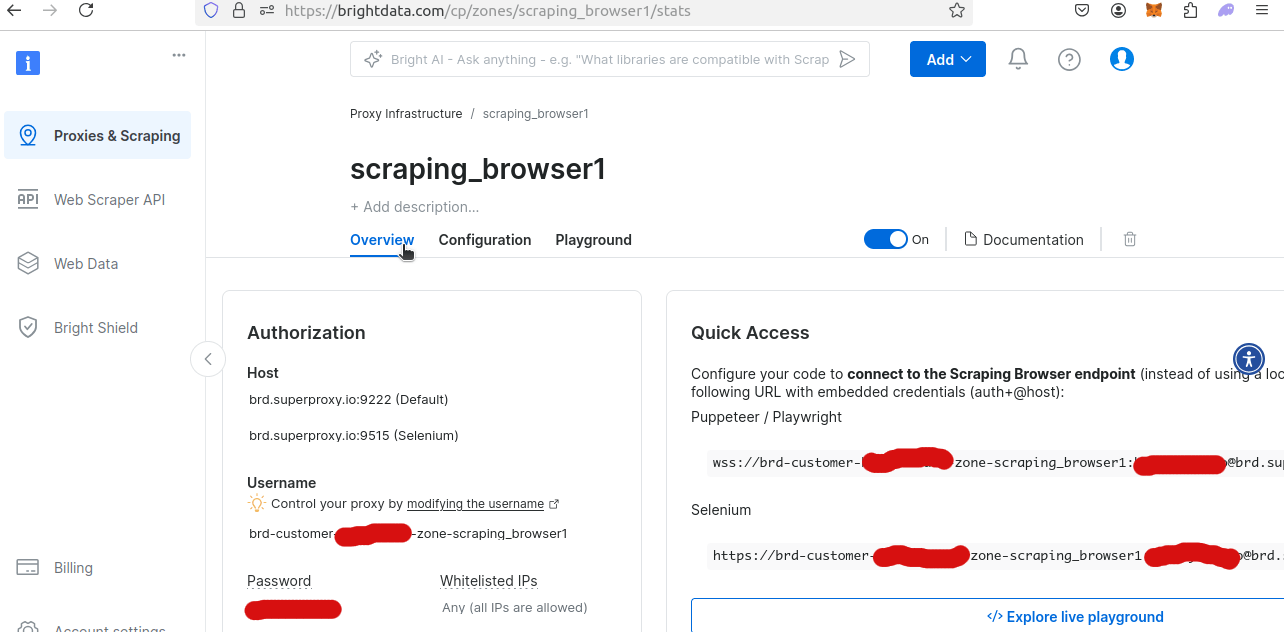
新規作成したスクレイピングブラウザゾーンの概要を確認すると、固有のユーザー名とパスワードを取得できます。Pythonスクリプト内からスクレイピングブラウザにアクセスするには、これらが必要です。
Bright Dataスクレイピングブラウザを使用したデータ抽出
以下のコード例は、スクレイピングブラウザでリモートWebDriverを使用するように修正されています。YOUR_USERNAME、YOUR_ZONE_NAME、YOUR_PASSWORDを実際のユーザー名、ゾーン名、パスワードに置き換えてください!
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-YOUR_USERNAME-ゾーン-YOUR_ZONE_NAME:YOUR_PASSWORD"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSVへの書き込み中...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSVファイルへのデータ書き込み中...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page}をCSVに正常に書き出しました...")
def scrape_page(page_number: int):
print("スクレイピングブラウザに接続中...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("接続完了!ページスクレイピング中...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("ホテルカードが見つかりません!スクリーンショットを撮って終了します。")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"カード {index} のスクレイピングに成功しました")
print(f"ページ {page_number} をスクレイピングしました")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
この例はVanilla Seleniumを使った例と非常に似ていますが、いくつかの細かい違いがあります。主に、標準のWebDriverではなくリモートWebDriverを使用している点です。
- プロキシ接続でリモートWebDriverインスタンスを設定しています:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"。 - エラー処理が若干変更されています:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")。driver.save_screenshot()の代わりにdriver.get_screenshot_as_file()を使用しています。
リモートプロキシ接続のためのいくつかの細かい調整を除けば、Seleniumを使用したスクレイピングブラウザのコードは、Vanilla Seleniumの場合と実質的に同じです。最大の違いは、スクレイピングブラウザが結果を容易に取得できる点です。
このコードを実行すると、以下のエラーが発生する可能性があります。これはリモート接続時に発生することがあります。その場合はスクリプトを再実行してください。安定した接続を確立するには複数回の試行が必要な場合があります。
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
スクリプトが正常に実行された場合、以下の出力が得られます。
スクレイピングブラウザに接続中...
-------------------------------
接続成功!ページをスクレイピング中...
カード 0 のスクレイピングに成功
カード 1 のスクレイピングに成功
カード 2 のスクレイピングに成功
カード 3 のスクレイピングに成功
カード 4 のスクレイピングに成功
カード 5 のスクレイピングに成功しました
カード 6 のスクレイピングに成功しました
カード 7 のスクレイピングに成功しました
カード 8 のスクレイピングに成功しました
カード 9 のスクレイピングに成功しました
カード 10 のスクレイピングに成功しました
カード 11 のスクレイピングに成功しました
カード 12 のスクレイピングに成功しました
カード 13 のスクレイピングに成功しました
カード14のスクレイピングに成功しました
カード15のスクレイピングに成功しました
カード16のスクレイピングに成功しました
カード17のスクレイピングに成功しました
カード18のスクレイピングに成功しました
カード19のスクレイピングに成功しました
カード20のスクレイピングに成功しました
カード21のスクレイピングに成功しました
カード22のスクレイピングに成功しました
カード23のスクレイピングに成功しました
カード24のスクレイピングに成功
カード25のスクレイピングに成功
カード26のスクレイピングに成功
カード27のスクレイピングに成功
カード28のスクレイピングに成功
カード29のスクレイピングに成功
ページ0をスクレイピング
CSVへの書き込み中...
CSVファイルへのデータ書き込み中...
0をCSVに正常に書き込みました...
以下はONLYOFFICEを使用したCSVデータのスクリーンショットです。
画像が表示されない場合の原因
- 画像ファイルが破損している可能性があります
- 画像をホストしているサーバーが利用不可
- 画像のパスが正しくない
- 画像形式がサポートされていない
代替アプローチ:データセット
スクレイパーのコーディングが好ましくない場合や、より大規模なデータが必要な場合は、構造化されたトリップアドバイザーのデータセットの活用をご検討ください。当社のデータセットは、お客様のニーズに合わせて整理された高品質なデータを提供し、旅行トレンドの分析、競合他社の価格監視、顧客体験の最適化を容易に行えます。
トリップアドバイザーのデータセットでは、ホテル名、レビュー、評価、設備、価格などの主要データポイントにアクセス可能です。柔軟な形式(例:JSON、CSV、Parquet)で提供され、ワークフローに合わせたスケジュールで更新されます。何より、これらのデータセットは100%コンプライアンスに準拠し、スケーラブルなため、正確性を確保しながら時間とリソースを節約できます。
主な利点:
- ブロックを気にせず主要なトリップアドバイザーデータポイントにアクセス可能
- フィルターやカスタムフォーマットでデータセットを特定のニーズに合わせて調整。
- Snowflake、S3、Azureなどのプラットフォームへのデータ配信を自動化。
データ収集ではなく分析に集中—難しい部分は当社にお任せください。今すぐ当社のトリップアドバイザーデータセットをご覧ください!
まとめ
JavaScriptの課題から完全な動的コンテンツまで、トリップアドバイザーのスクレイピングは非常に困難です。本ガイドを読み終えた今、少しは容易になったはずです。この時点で、Seleniumを使用してローカル環境でもリモートセッションでもブラウザを制御できることを理解できたでしょう。ヘッドレスブラウザ(Seleniumなど)を使えば、データのスクリーンショットを撮ることも可能です。これによりスクレイパーのデバッグが格段に容易になります。 ホテルデータの抽出方法と、追加インストール不要のシンプルなPythonでCSVファイルを生成する方法が理解できました!
大規模なスクレイピングを検討中なら、Bright Dataが豊富な製品で支援します。スクレイピングブラウザはあらゆるスクレイピング作業に最適なツール群を提供。お好みのヘッドレスブラウザで安定したプロキシ接続による実ブラウザ操作が可能。CAPTCHAの心配も不要です!
あるいは、データ取得の最良の方法として、すぐに使えるTripadvisorデータセットを購入することも可能です。今すぐ登録して無料トライアルを始めましょう!





