

この記事では以下の内容を解説します:
- Indeedスクレイパーとは何か、その仕組み
- Indeedから自動抽出可能なデータの種類
- Pythonを使用したIndeedスクレイピングスクリプトの構築方法
- より高度なソリューションが必要な場合とその理由
それでは始めましょう!
Indeedスクレイパーとは?
Indeedスクレイパーは、Indeedウェブサイトから求人情報を関連データと共に自動的に抽出します。求人検索ページをナビゲートする人間の操作を模倣して動作します。その後、職種、企業名、勤務地、説明文などの特定要素を識別します。最後に、スクレイピングボットがそれらからデータを抽出し、分析用にエクスポートします。
Indeedで取得可能なデータ
Indeedは求人関連データの宝庫であり、市場分析、採用活動、研究目的において非常に貴重な情報源となります。以下はスクレイピング可能な主要データポイントの一覧です:
- 職種名:求人掲載で募集されている役職またはポジション。
- 企業名:雇用主の詳細情報(企業概要を含む)。
- 勤務地:求人の所在する都市、州、または国。
- 職務内容:役職、責任範囲、要件に関する詳細情報。
- 給与範囲:掲載されている給与水準(利用可能な場合)。
- 雇用形態:正社員、パートタイム、契約社員、インターンシップなど。
- 掲載日:求人情報が公開された日付。
- タグと属性:「緊急募集」や「リモート勤務」などのキーワード。
- 評価とレビュー:雇用主の評価と従業員のフィードバック。
- 応募方法:「簡単応募」機能の有無などの指標。
求人ポジションに焦点を当てている場合は、求人情報のスクレイピング方法に関するガイドに従ってください。
Indeedのスクレイピング方法:ステップバイステップガイド
このチュートリアルセクションでは、Indeedスクレイパーの作成方法を解説します。Pythonスクリプトを構築し、Indeedの「データサイエンティスト」求人ページをスクレイピングする手順をガイドします:
手順に従って、Indeedのスクレイピング方法を学びましょう!
ステップ #1: プロジェクト設定
開始前に、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ダウンロードしてインストールしてください。
次に、ターミナルで以下のコマンドを実行し、プロジェクト用のディレクトリを作成します:
mkdir indeed_scraper
indeed_scraperディレクトリにはPython用Indeedスクレイパーが格納されます。
ターミナルで入力し、その中に仮想環境を初期化します:
cd indeed_scraper
python -m venv env
次に、お気に入りのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトディレクトリ内にscraper.py ファイルを作成します。これで以下のファイル構成が整います:

scraper.pyには、すぐに必要なスクレイピングロジックが記述されます。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは次のコマンドを実行:
./env/bin/activate
Windowsでは同等の操作として以下を実行します:
env/Scripts/activate
素晴らしい!Indeedウェブスクレイピング用のPython環境が整いました。
ステップ #2: 適切なスクレイピングライブラリの選択
次のステップは、Indeedが動的ページと静的ページのどちらに依存しているかを判断することです。そのためには、ブラウザのシークレットモードでIndeedのターゲットページを開き、操作してみてください。簡単にわかるように、ページ上のほとんどのデータは動的に読み込まれています:
このことから、Indeedを効果的にスクレイピングするにはSeleniumのようなブラウザ自動化ツールが必要だと判断できます。このプロセスに関する詳細なガイダンスは、Seleniumウェブスクレイピングガイドを参照してください。
Seleniumを使用すると、ウェブブラウザをプログラムで制御し、ユーザー操作をシミュレートしたり、JavaScriptによってレンダリングされたコンテンツをスクレイピングしたりできます。さあ、インストールして始めましょう!
ステップ #3: Selenium のインストールと設定
アクティブな仮想環境で、以下のコマンドを実行してSeleniumをインストールします:
pip install -U selenium
scraper.pyでSeleniumをインポートし、WebDriverオブジェクトを設定します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 制御可能なChromeインスタンスを設定
driver = webdriver.Chrome(service=Service())
上記のコードは、Chromeインスタンスを制御するために必要なものを初期化します。
注: Indeedはヘッドレスブラウザによるページアクセスを阻止するアンチスクレイピング対策を実施しています。したがって、--headlessフラグを設定するとスクリプトは失敗します。代替アプローチとして、Playwright Stealthを検討してください。
スクリプトの最終行では、Webドライバーを閉じることを忘れないでください:
driver.quit()
素晴らしい!これでIndeedのスクラッピング環境が完全に整いました。
ステップ #4: 対象ページへのアクセス
Seleniumのget()メソッドを使用して、制御対象のブラウザにターゲットページへのアクセスを指示します:
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
scraper.pyには以下のコードが含まれるようになります:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 制御可能なChromeインスタンスを設定
driver = webdriver.Chrome(service=Service())
# 対象ページをブラウザで開く
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# logcのスクレイピング...
# Webドライバーを閉じる
driver.quit()
最終行にデバッグ用ブレークポイントを追加してください。デバッガーでスクリプトを実行すると、以下のような結果が表示されるはずです:
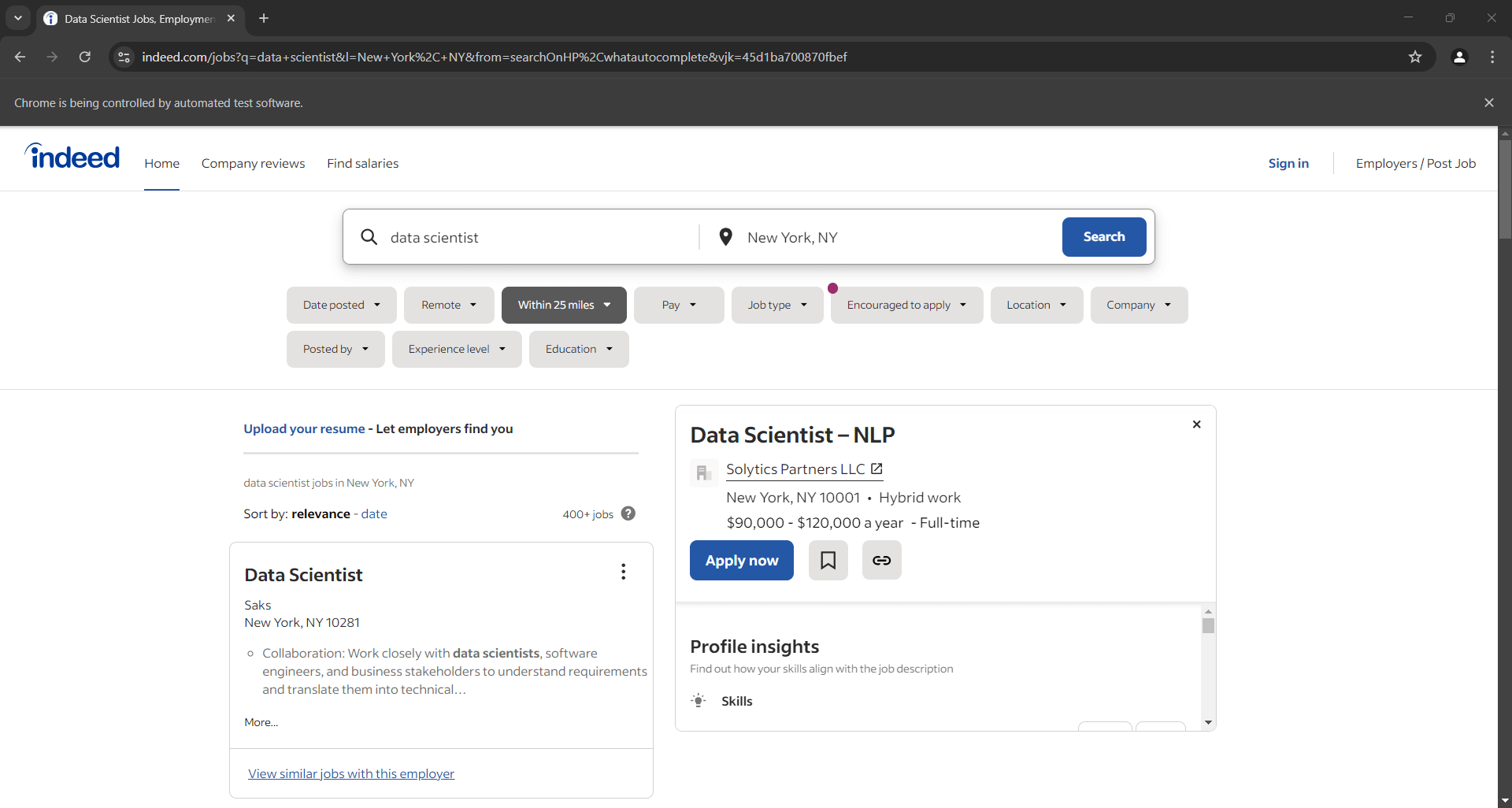
注: 「Chrome は自動テストソフトウェアによって制御されています」という通知は、Selenium が想定通り Chrome を制御していることを示しています。
よくできました!
ステップ #5: 求人情報要素の選択
Indeedの求人検索ページには多数の求人が表示されます。これら全てをスクレイピングするため、スクレイピングしたデータを格納する配列を初期化します:
jobs = []
次に、ページの求人のHTML要素を調査し、選択方法を理解します:
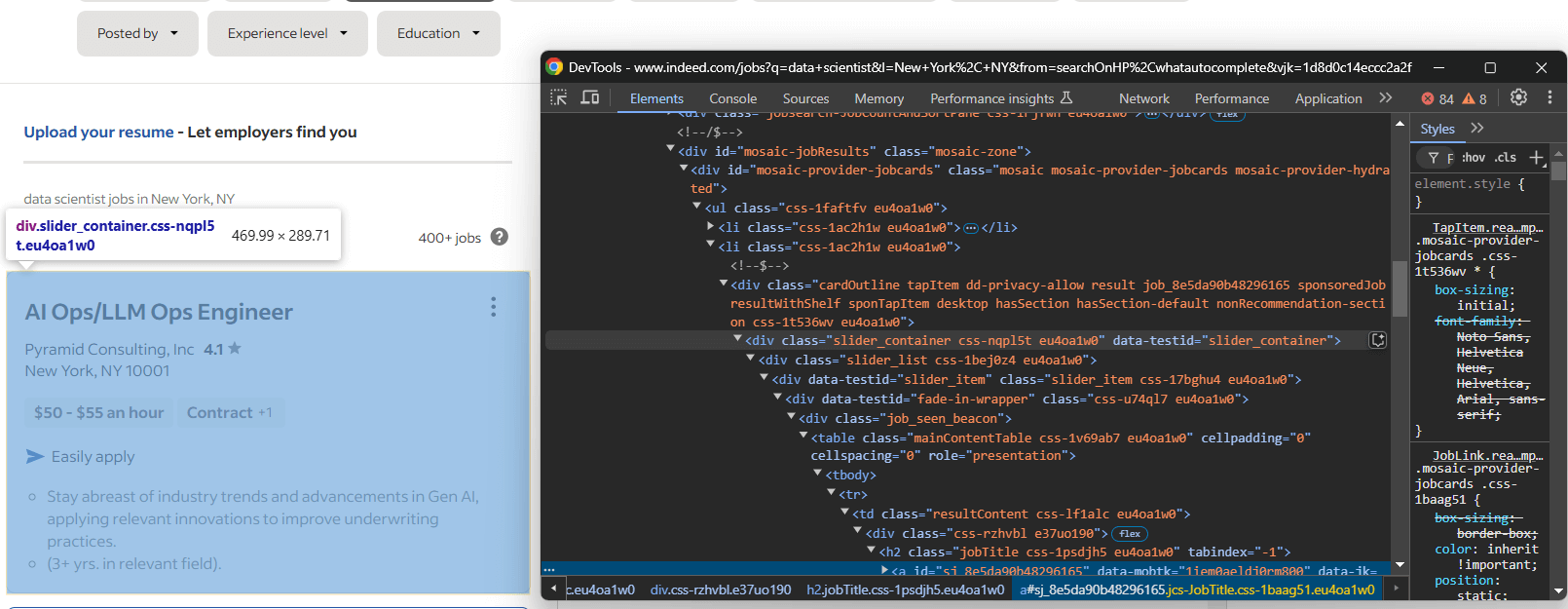
ここでは、各求人要素は#mosaic-provider-jobcardsコンテナ内のslider_itemノードです。
通常、ページ上の要素選択にはCSSクラスを使用します。しかし、これらのクラスは(おそらくビルド時に)ランダムに生成されているようです。安定性を確保するため、頻繁に変更されにくいid属性 とdata-testid属性をターゲットにする方が良いでしょう。
Seleniumを使用して求人要素を選択します:
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
find_elements()メソッドは、指定されたセレクタ戦略を適用してページから一致する要素をすべて取得します。この場合、セレクタ戦略はCSSセレクタです。
動作させるにはBy のインポートを必ず行ってください:
from selenium.webdriver.common.by import By
次に、選択された要素を反復処理し、各要素からデータをスクレイピングする準備をします:
for job_element in job_elements:
# 各求人からデータをスクレイピング
素晴らしい!Indeedから求人情報をスクレイピングする準備が整いました。
ステップ #6: 求人メイン情報のスクレイピング
カード要素を検査し、カード上部セクションの情報に焦点を当てます:
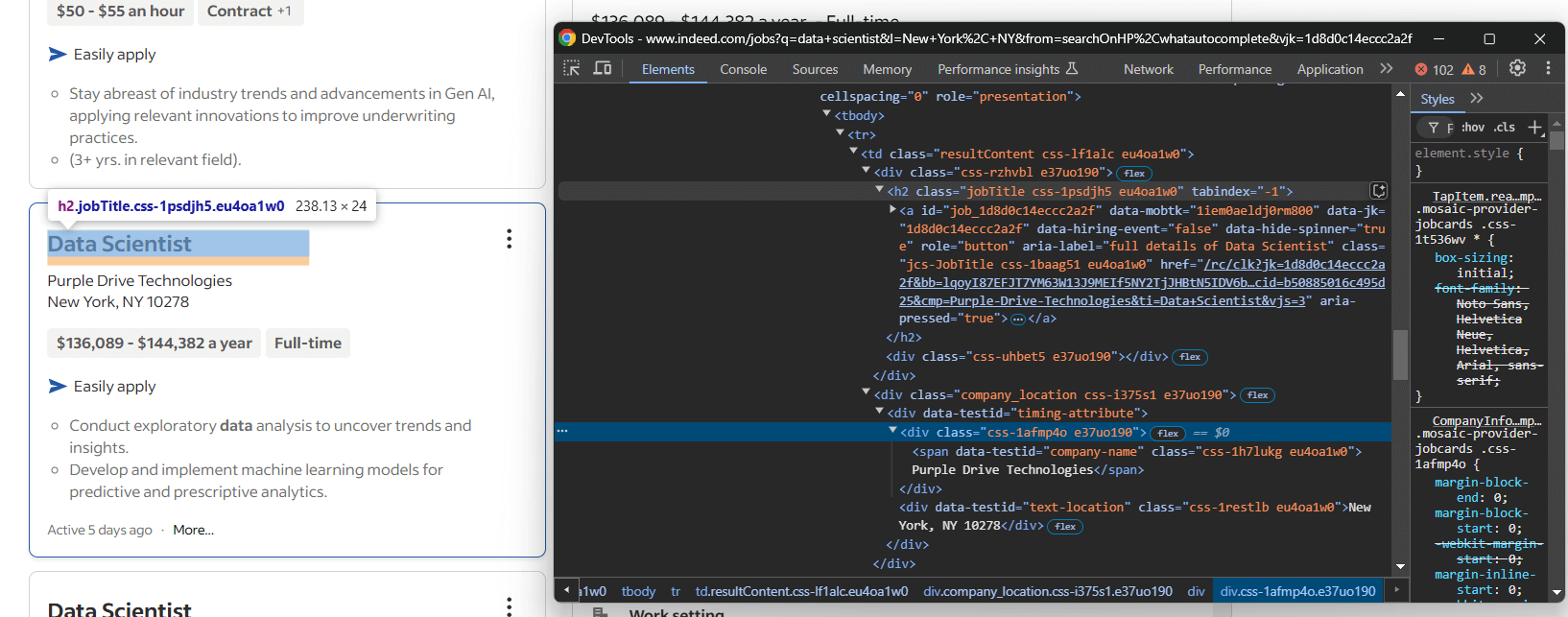
ここでスクレイピングできるのは以下の情報です:
<h2>タグ内の職種名- タイトル
<h2>内の<a>から求人ページURL [data-testid="company-name"]ノードから会社名[data-testid="text-location"]要素から会社の所在地
上記の情報をスクレイピングロジックで以下のように変換します:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
find_element() は指定されたセレクタに一致する最初の要素を選択します。ノードを取得したら、text属性でそのテキストコンテンツにアクセスできます。ノードのHTML属性の値を取得するには、get_attribute()メソッドを使用する必要があります。
いいね!Indeedスクレイピングロジックの基礎は整ったけど、まだスクレイピングすべき有用なデータが残ってるよ。
ステップ #7: 求人詳細のスクレイピング
求人ポジションカードの詳細セクションに注目します:
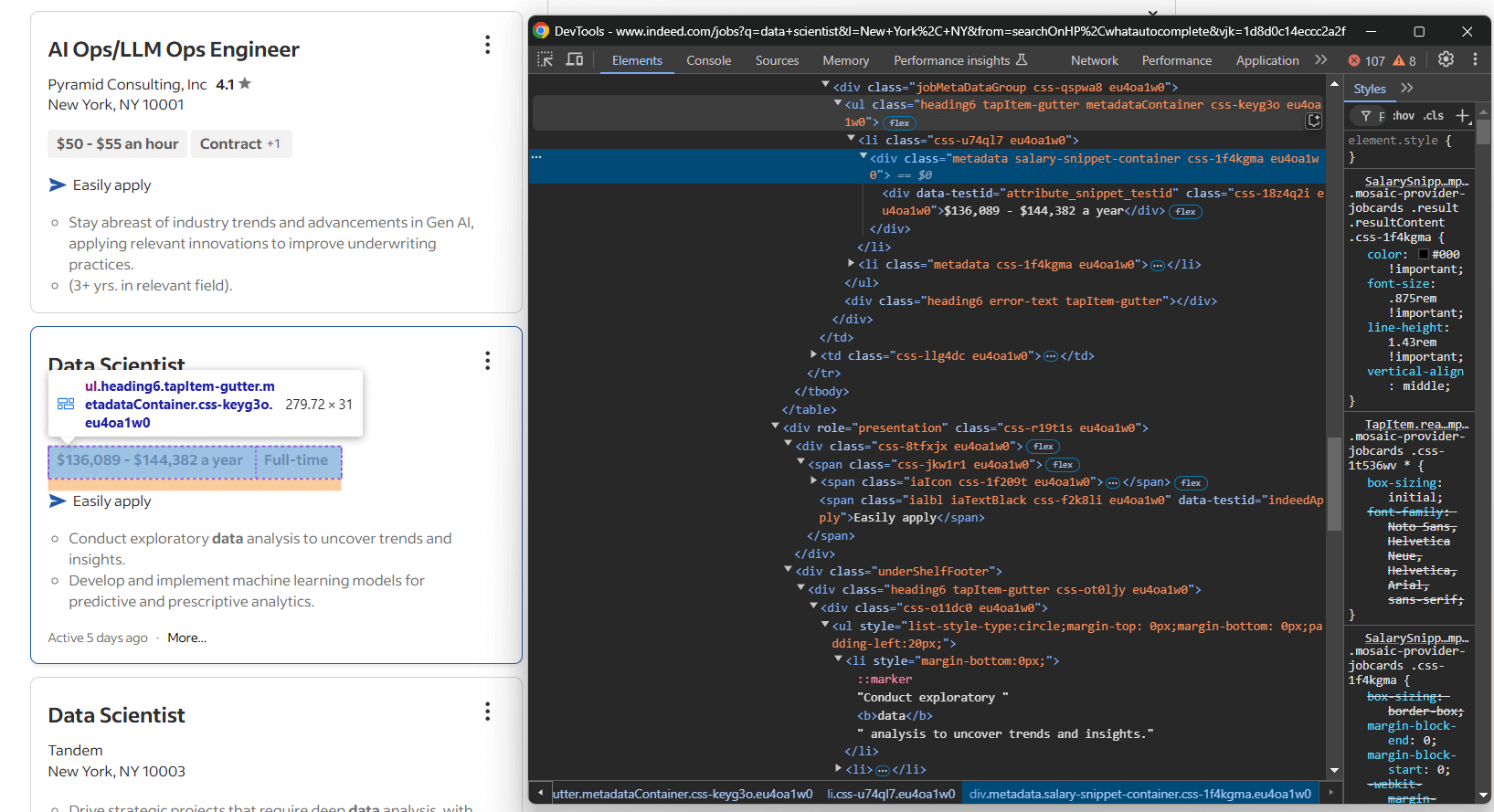
今回スクレイピングする情報は以下の通りです:
.jobMetaDataGroup<div>内の1つ以上の[data-testid="attribute_snippet_testid"]要素に含まれる求人タグ- Indeed経由で簡単に応募できるオプションの有無
[role="presentation"]<div>内の1つ以上のul li要素にある説明項目
まずはタグの抽出から始めましょう。以下のコードで全て取得できます:
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
まず、取得したタグをすべて格納する配列を初期化する必要があります。これは、単一の求職カードに複数のタグが含まれる可能性があるためです。タグを選択した後、それらを反復処理し、テキストを抽出して配列に追加します。
「簡単に応募」情報のスクレイピングも難しいです。問題は、その可能性を示すHTML要素が全ての求人に存在しないことです。明らかに、「簡単に応募」オプションがサポートされている場合のみ存在します。
ページ上に存在しない要素を選択しようとすると、SeleniumはNoSuchElementExceptionを発生させます。この特性を活用すれば、「簡単に応募」チェックボックスを効果的にスクレイピングできます:
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
[data-testid="indeedApply"]ノードがページ上に存在しない場合、SeleniumはNoSuchElementExceptionを発生させます。これはインターセプトされ、easily_applyは Falseに設定されます。
説明項目については、タグと同様に一括スクレイピングが可能です:
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# 空の説明文字列は無視
if (description_item_text != ""):
description.append(description_item_text)
わあ!Indeedスクレイパーがほぼ完成しました。
ステップ #8: スクレイピングしたデータの収集
各求人ポジションからスクレイピングしたデータで、求人辞書を作成します:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
次に、jobs配列に追加します:
jobs.append(job)
forループ終了時、productsには以下のような内容が含まれるはずです:
[{'title': 'Data Scientist', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'New York, NY', 'tags': [], 'easily_apply': False, 'description': ['業界のトレンドや新興技術に常に目を向け、競争優位性を確保します。', '統計学や機械学習の手法を応用し、投資の改善を図ります…']},
# 簡略化のため省略...
{'title': 'データサイエンティスト、金融犯罪対策 - USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'ニューヨーク州ニューヨークでのハイブリッド勤務', 'tags': [], 'easily_apply': False, 'description': ['金融犯罪データサイエンティストとして、機械学習、分析、可視化技術を活用し、当社の…を強化する重要な役割を担います。']}]
素晴らしい!このデータをより良い形式に変換するだけです。
ステップ #9: スクレイピングしたデータを CSV にエクスポート
スクレイピングしたデータをアクセス可能かつ共有可能な状態にするには、人間が読める形式(例:CSVファイル)にエクスポートするのが効果的です。以下のコード行を使用してください:
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": job["easily_apply"] == True: "Yes", False: "No",
"description": ";".join(job["description"])
})
open()関数は出力CSVファイルを作成し、csv.DictWriterでデータを書き込む。タグと説明フィールドは配列であるため、join()を使用して要素をセミコロンで区切った単一の文字列に平坦化する。
Python標準ライブラリのcsvをインポートすることを忘れないでください:
import csv
さあ、始めましょう!Indeedスクレイパーが完成しました。
ステップ #10: 全てを統合する
最終的なscraper.py ファイルの内容は以下の通りです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# 制御可能なChromeインスタンスを設定
driver = webdriver.Chrome(service=Service())
# 対象ページをブラウザで開く
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# スクレイピングした求人情報を格納するデータ構造
jobs = []
# ページ上の求人要素を選択
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
# ページ上の各求人情報をスクレイピング
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# "Easy Apply" 要素がページ上にあるか確認
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# 空の説明文字列は無視
if (description_item_text != ""):
description.append(description_item_text)
# スクレイピングしたデータを保存
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# スクレイピングしたデータを出力CSVファイルにエクスポート
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": job["easily_apply"] == True: "Yes", False: "No",
"description": ";".join(job["description"])
})
# WebDriverを閉じる
driver.quit()
わずか100行未満のコードで、PythonによるIndeedスクレイパーを作成しました!
以下のコマンドでスクレイパーを起動します:
python3 script.py
Windowsの場合:
python script.py
プロジェクトフォルダ内にjobs.csvファイルが生成されます。開くと以下が表示されます:
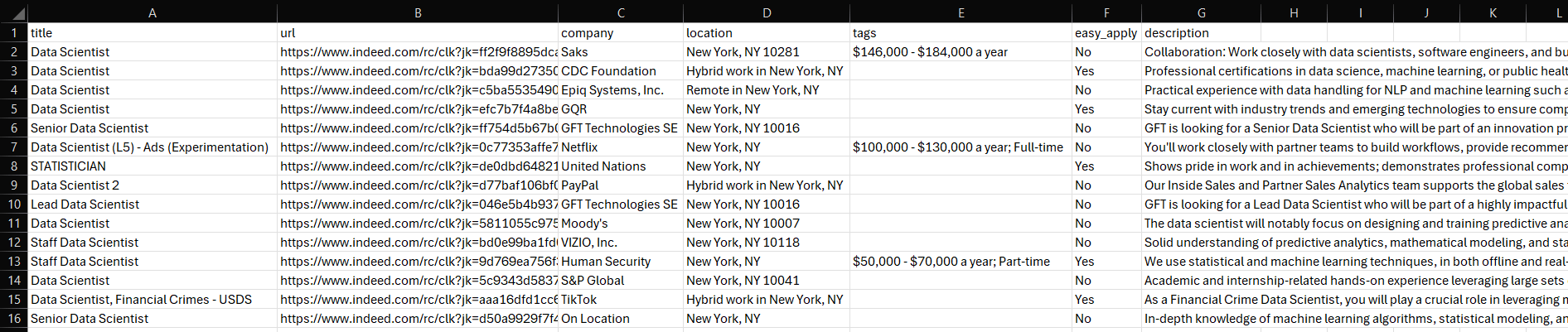
これで完了です!ミッション達成。
Indeedデータの活用を容易に
Indeedは自社データの価値を十分に認識しており、強固な保護策を講じています。そのため、Seleniumのようなブラウザ自動化ツールでページを操作する際、CAPTCHAに遭遇する可能性が高いです:
まずはPythonでCAPTCHAを回避する方法に関するガイドを参照してください。ただし、サイトが追加のボット対策で試行をブロックする可能性がある点に留意が必要です。ボット対策技術に関するウェビナーでそれらをすべて発見してください。
こうした課題は、適切なツールなしでのIndeedスクレイピングがいかに迅速に非効率的で苛立たしいものになるかを浮き彫りにします。さらに、ヘッドレスブラウザが使用できないことで、スクレイピングスクリプトはより遅く、より多くのリソースを消費するようになります。
解決策は?BrightDataのIndeedスクレイパーAPIです。このツールを使えば、シンプルなAPI呼び出しでIndeedからシームレスにデータを取得できます。CAPTCHAもブロックも煩わしさも一切なし!
まとめ
このステップバイステップガイドでは、Indeedスクレイパーの定義、取得可能なデータの種類、Pythonでの構築方法を学びました。わずか100行程度のコードで、Indeedから自動的にデータを収集するスクリプトを作成しました。
とはいえ、Indeedのスクレイピングには課題も伴います。プラットフォームはCAPTCHAを含む厳格なボット対策を実施しており、これらを回避するのは困難でスクレイピング処理を遅延させ、効率を低下させます。当社のIndeedスクレイパーAPIなら、こうした課題をすべて解消できます。
ウェブスクレイピングは得意ではないが求人データには興味があるという方は、すぐに使える当社のIndeedデータセットをご検討ください!
スクレイパーAPIをお試しいただくか、データセットを閲覧するには、今すぐBright Dataの無料アカウントを作成してください。





