

Google Trendsは、人々がオンラインで検索している内容に関する洞察を提供する無料ツールです。これらの検索トレンドを分析することで、企業は新たな市場動向を特定し、消費者行動を理解し、売上とマーケティング活動を促進するためのデータ駆動型の意思決定を行うことができます。Google Trendsからデータを抽出することで、企業は戦略を調整し、競争に先んじることができます。
この記事では、Pythonを使用してGoogle Trendsからデータをスクレイピングする方法、およびそのデータを効果的に保存・分析する方法を学びます。
Googleトレンドをスクレイピングする理由
Googleトレンドデータのスクレイピングと分析は、以下のような様々な場面で有用です:
- キーワード調査:コンテンツ制作者やSEO専門家は、自社ウェブサイトへのオーガニックトラフィック増加のため、注目度が高まっているキーワードを把握する必要があります。Googleトレンドは地域・カテゴリ・期間別にトレンド検索語句を探索でき、変化するユーザー関心に基づいたコンテンツ戦略の最適化を可能にします。
- 市場調査:マーケターは顧客の関心事を理解し、需要の変化を予測して意思決定を行う必要があります。Google Trendsデータのスクレイピングと分析により、顧客の検索パターンを理解し、時間の経過に伴うトレンドを監視できます。
- 社会調査:地域・国際的な出来事、技術革新、経済変動、政治動向など、様々な要因が世間の関心や検索トレンドに大きく影響します。Googleトレンドのデータは、こうした変化するトレンドを時系列で把握する貴重な洞察を提供し、包括的な分析と将来予測を可能にします。
- ブランド監視:企業やマーケティングチームは、市場における自社ブランドの認知度を監視する必要があります。Google Trendsデータをスクレイピングすることで、競合他社とのブランド認知度を比較し、世論の変化に迅速に対応できます。
Google Trendsスクレイピングの代替手段:Bright DataのSERP API
Google Trendsを手動でスクレイピングする代わりに、Bright DataのSERP APIを活用して検索エンジンからのリアルタイムデータ収集を自動化しましょう。SERP APIは検索結果やトレンドなどの構造化データを提供し、正確な地域ターゲティングが可能で、ブロックやCAPTCHAのリスクもありません。成功したリクエストに対してのみ課金され、データはJSONまたはHTML形式で提供されるため、容易に統合できます。
このソリューションはより高速でスケーラブル、複雑なスクレイピングスクリプトが不要です。無料トライアルを開始し、Bright DataのGoogleトレンドスクレイパーでデータ収集を効率化しましょう。
Googleトレンドからデータをスクレイピングする方法
Google Trendsはトレンドデータスクレイピング用の公式APIを提供していませんが、pytrendsなどのサードパーティAPIやライブラリを利用できます。pytrendsはPythonライブラリで、Google Trendsからレポートを自動ダウンロードする使いやすいAPIを提供します。ただしpytrendsは使いやすい反面、動的にレンダリングされたデータやインタラクティブ要素の背後にあるデータにアクセスできないため、提供データが限定されます。 この問題を解決するには、SeleniumとBeautiful Soupを活用してGoogleTrendsをスクレイピングし、動的にレンダリングされたウェブページからデータを抽出できます。Seleniumは、JavaScriptを使用してコンテンツを動的に読み込むウェブサイトとの対話およびスクレイピングを行うオープンソースツールです。Beautiful SoupはスクレイピングされたHTMLコンテンツのパースを支援し、ウェブページから特定のデータを抽出することを可能にします。
このチュートリアルを始める前に、お使いのマシンにPythonがインストールされ設定されている必要があります。また、次のセクションで作成するPythonスクリプト用の空のプロジェクトディレクトリを作成する必要があります。
仮想環境の作成
仮想環境は、Pythonパッケージを別々のディレクトリに分離し、バージョン間の競合を回避します。新しい仮想環境を作成するには、ターミナルで次のコマンドを実行します:
# コマンド実行前にプロジェクトディレクトリのルートに移動
python -m venv myenv
このコマンドにより、プロジェクトディレクトリ内にmyenvというフォルダが作成されます。仮想環境を有効化するには、次のコマンドを実行します:
source myenv/bin/activate
以降のPythonやpipコマンドもこの環境で実行されます。
依存関係をインストールする
前述の通り、ウェブページのスクレイピングとパースにはSeleniumとBeautiful Soupが必要です。さらに、スクレイピングしたデータの分析と可視化には、pandasとMatplotlibのPythonモジュールをインストールする必要があります。以下のコマンドでこれらのパッケージをインストールしてください:
pip install beautifulsoup4 pandas matplotlib selenium
Google Trends検索データのクエリ
Google Trendsダッシュボードでは、地域、日付範囲、カテゴリ別に検索トレンドを調査できます。例えば、以下のURLは過去7日間の米国におけるコーヒーの検索トレンドを示しています:
https://trends.google.com/trends/explore?date=now%207-d&geo=US&q=coffee
このウェブページをブラウザで開くと、データがJavaScriptを使用して動的に読み込まれることがわかります。動的コンテンツをスクレイピングするには、クリック、入力、スクロールなどのユーザー操作を模倣するSelenium WebDriverを使用できます。
PythonスクリプトでWebDriverを使用し、ブラウザウィンドウにウェブページを読み込み、コンテンツが読み込まれた後にページソースを抽出できます。動的コンテンツを処理するには、ページソースを取得する前にすべてのコンテンツが読み込まれるよう、明示的なtime.sleepを追加します。動的コンテンツ処理のさらなるテクニックについては、こちらのガイドを参照してください。
プロジェクトのルートにmain.py ファイルを作成し、以下のコードスニペットを追加します:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def get_driver():
# Chromeバイナリの場所へのパスを更新
CHROME_PATH = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
options = Options()
# options.add_argument("--headless=new")
options.binary_location = CHROME_PATH
driver = webdriver.Chrome(options=options)
return driver
def get_raw_trends_data(
driver: webdriver.Chrome, date_range: str, geo: str, query: str)
-> str:
url = f"https://trends.google.com/trends/explore?date={date_range}&geo={geo}&q={query}"
print(f"{url} からデータを取得中")
driver.get(url)
# 初期の 429 エラー後のページソース取得のための回避策
driver.get(url)
driver.maximize_window()
# ページ読み込み完了を待機
time.sleep(5)
return driver.page_source
get_raw_trends_dataメソッドは日付範囲、地理的地域、クエリ名をパラメータとして受け取り、Chrome WebDriverを使用してページコンテンツを取得します。URLが最初に読み込まれる際にGoogleから返される初期の429エラーを修正するための回避策として、driver.getメソッドが2回呼び出されている点に注意してください。
このメソッドは、後続のセクションでデータを取得するために使用します。
Beautiful Soup を使用したデータパース
検索語句のトレンドページには「地域別関心度」ウィジェットが含まれており、0~100の値を持つページ分割された記録が格納されています。これは場所に基づく検索語句の人気度を示しています。以下のコードスニペットを使用して、Beautiful Soupでこのデータをパースします:
# インポート追加
from bs4 import BeautifulSoup
def extract_interest_by_sub_region(content: str) -> dict:
soup = BeautifulSoup(content, "html.parser")
interest_by_subregion = soup.find("div", class_="geo-widget-wrapper geo-resolution-subregion")
related_queries = interest_by_subregion.find_all("div", class_="fe-atoms-generic-content-container")
# 抽出データを格納する辞書
interest_data = {}
# 地域名と関心度パーセンテージを抽出
for query in related_queries:
items = query.find_all("div", class_="item")
for item in items:
region = item.find("div", class_="label-text").text.strip()
interest = item.find("div", class_="progress-value").text.strip()
interest_data[region] = interest
return interest_data
このコードスニペットは、クラス名を使用してサブ地域データに対応するdiv要素を検索し、結果を反復処理してinterest_data辞書を生成します。
クラス名は将来変更される可能性があるため、Chrome DevToolsの要素検査機能を使用して正しい名前を見つける必要がある場合があることに注意してください。
ヘルパーメソッドを定義したので、次のコードスニペットで「coffee」のデータをクエリします:
# パラメータ
date_range = "now 7-d"
geo = "US"
query = "coffee"
# 生データを取得
driver = get_driver()
raw_data = get_raw_trends_data(driver, "now 7-d", "US", "coffee")
# 地域別の関心度を抽出
interest_data = extract_interest_by_sub_region(raw_data)
# 抽出データを表示
for region, interest in interest_data.items():
print(f"{region}: {interest}")
出力例:
ハワイ: 100
モンタナ: 96
オレゴン: 90
ワシントン: 86
カリフォルニア: 84
データページネーションの管理
ウィジェット内のデータはページ分割されているため、前のセクションのコードスニペットはウィジェットの最初のページからのデータのみを返します。より多くのデータを取得するには、Selenium WebDriverを使用して「次へ」ボタンを見つけクリックします。さらに、スクリプトではクッキー同意バナーを処理し、「同意する」ボタンをクリックして、バナーがページ上の他の要素を妨げないようにする必要があります。
クッキーとページネーションを処理するため、main.pyの末尾に以下のコードスニペットを追加します:
# インポート追加
from selenium.webdriver.common.by import By
all_data = {}
# クッキーを承諾
driver.find_element(By.CLASS_NAME, "cookieBarConsentButton").click()
# ページネーションされた興味データを取得
while True:
# データが利用可能な場合、md-buttonをクリックして追加データをロード
try:
geo_widget = driver.find_element(
By.CSS_SELECTOR, "div.geo-widget-wrapper.geo-resolution-subregion"
)
# クラス名 "md-button" と aria-label "Next" の追加読み込みボタンを検索
load_more_button = geo_widget.find_element(
By.CSS_SELECTOR, "button.md-button[aria-label='Next']"
)
icon = load_more_button.find_element(By.CSS_SELECTOR, ".material-icons")
# ボタンが disabled 状態か確認(class-name に arrow-right-disabled を含むかチェック)
if "arrow-right-disabled" in icon.get_attribute("class"):
print("読み込むデータはありません")
break
load_more_button.click()
time.sleep(2)
extracted_data = extract_interest_by_sub_region(driver.page_source)
all_data.update(extracted_data)
except Exception as e:
print("読み込むデータがありません", e)
break
driver.quit()
このスニペットは既存のドライバーインスタンスを使用し、クラス名と一致させることで「次へ」ボタンを検索・クリックします。要素に「arrow-right-disabled」クラスが存在するかを確認し、ボタンが無効化されている場合(ウィジェットの最終ページに到達したことを示す)にループを終了します。
データの可視化
スクレイピングしたデータに簡単にアクセスし、さらに分析するために、csv.DictWriter を使用して抽出されたサブリージョンデータを CSV ファイルに永続化できます。
まずmain. pyでsave_interest_by_sub_regionを定義し、all_data辞書をCSVファイルに保存します:
# インポート追加
import csv
def save_interest_by_sub_region(interest_data: dict):
interest_data = [{"Region": region, "Interest": interest} for region, interest in interest_data.items()]
csv_file = "interest_by_region.csv"
# CSVファイルを書き込みモードで開く
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["Region", "Interest"])
writer.writeheader() # ヘッダーを書き込む
writer.writerows(interest_data) # データを書き込む
print(f"データが {csv_file} に保存されました")
return csv_file
次に、pandasを使用してCSVファイルをDataFrameとして開き、特定の条件によるデータのフィルタリング、グループ化操作によるデータ集計、プロットによる傾向の可視化などの分析を実行できます。
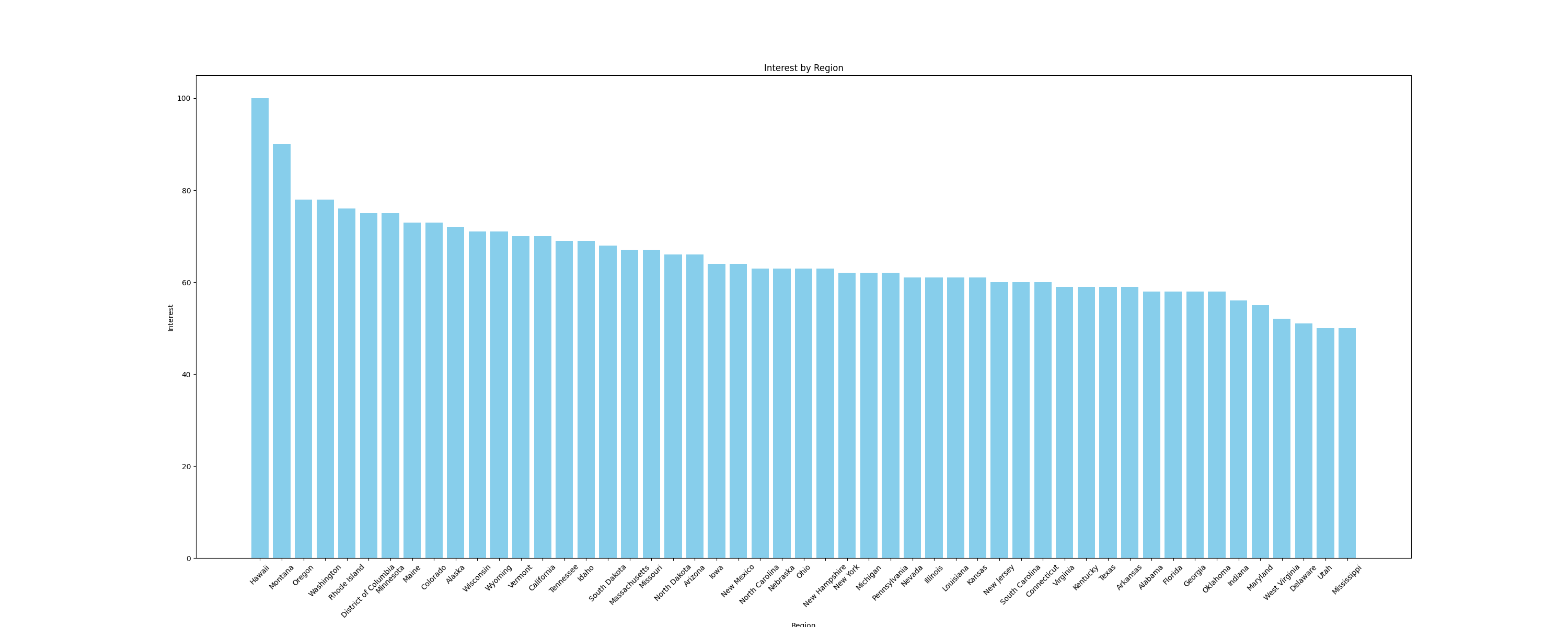
例えば、サブ地域別の関心を比較するため、データを棒グラフで可視化してみましょう。プロット作成には、DataFrameとシームレスに連携するPythonライブラリmatplotlibを使用します。棒グラフを作成し画像として保存する以下の関数をmain.pyファイルに追加します:
# インポートを追加
import pandas as pd
import matplotlib.pyplot as plt
def plot_sub_region_data(csv_file_path, output_file_path):
# CSVファイルからデータを読み込み
df = pd.read_csv(csv_file_path)
# 地域別比較用棒グラフの作成
plt.figure(figsize=(30, 12))
plt.bar(df["Region"], df["Interest"], color="skyblue")
# タイトルとラベルを追加
plt.title('地域別関心度')
plt.xlabel('地域')
plt.ylabel('関心度')
# 必要に応じてx軸ラベルを回転
plt.xticks(rotation=45)
# プロットを表示
plt.savefig(output_file_path)
main.pyファイルの末尾に以下のコードスニペットを追加し、前述の関数を呼び出します:
csv_file_path = save_interest_by_sub_region(all_data)
output_file_path = "interest_by_region.png"
plot_sub_region_data(csv_file_path, output_file_path)
このスニペットは以下のようなプロットを作成します:
このチュートリアルの全コードは、こちらのGitHubリポジトリで公開されています。
スクレイピングの課題
このチュートリアルではGoogle Trendsから少量のデータをスクレイピングしましたが、スクリプトの規模や複雑さが増すにつれ、IP禁止やCAPTCHAといった課題に直面する可能性があります。
例えば、このスクリプトでウェブサイトへのトラフィック頻度を高めると、多くのウェブサイトがボットトラフィックを検知・ブロックする対策を施しているため、IPブロックに直面する可能性があります。これを回避するには、手動でのIPローテーションや優れたプロキシサービスの利用が有効です。どのプロキシタイプを使用すべきか迷う場合は、ウェブスクレイピングに最適なプロキシタイプを解説した記事をご参照ください。
CAPTCHAやreCAPTCHAの出現も、ボットトラフィックや異常を検知・疑ったウェブサイトが採用する一般的な対策です。回避策としては、リクエスト頻度の低減、適切なリクエストヘッダーの使用、あるいはこれらの課題を解決するサードパーティサービスの利用が挙げられます。
結論
本記事では、SeleniumとBeautiful Soupを用いたPythonによるGoogle Trendsデータのスクレイピング手法を解説しました。
ウェブスクレイピングを続ける中で、IP禁止やCAPTCHAなどの課題に直面するかもしれません。複雑なスクレイピングスクリプトを管理する代わりに、Bright DataのSERP APIの利用をご検討ください。このAPIはGoogle Trendsを含む正確なリアルタイム検索エンジンデータの収集プロセスを自動化し、動的コンテンツや地域ベースのターゲティングに対応し、高い成功率を保証することで、時間と労力を節約します。
今すぐ登録して、SERP APIの無料トライアルを始めましょう!





