

この記事では、Pythonを使用してGoogle Scholarからデータをスクレイピングする方法を段階的に学びます。スクレイピング手順に入る前に、前提条件と環境設定の方法を確認しましょう。さあ始めましょう!
Google Scholarの手動スクレイピングに代わる方法
Google Scholarの手動スクレイピングは困難で時間がかかります。代替手段として、Bright Dataのデータセットの利用をご検討ください:
- データセットマーケットプレイス:すぐに使える事前収集済みデータにアクセスできます。
- カスタムデータセット:ご要望に合わせた特注データセットをリクエストまたは作成。
Bright Dataのサービスを利用すれば、手動スクレイピングの複雑さを回避しつつ、正確で最新の情報を効率的に入手できます。それでは、本題へ進みましょう!
前提条件
このチュートリアルを始める前に、以下の項目をインストールする必要があります:
- Pythonの最新バージョン
- お好みのコードエディター(例:Visual Studio Code)
さらに、スクレイピングプロジェクトを開始する前に、スクリプトが対象ウェブサイトのrobots.txtファイルに準拠していることを確認し、制限区域をスクレイピングしないようにしてください。本記事で使用するコードは学習目的のみを意図しており、責任を持ってご利用ください。
Python仮想環境の設定
Python仮想環境を設定する前に、プロジェクトを配置したい場所へ移動し、新しいフォルダ「google_scholar_scraper」を作成します:
mkdir google_scholar_scraper
cd google_scholar_scraper
google_scholar_scraperフォルダを作成したら、以下のコマンドでプロジェクト用の仮想環境を作成します:
python -m venv google_scholar_env
仮想環境を有効化するには、Linux/Macで次のコマンドを実行します:
source google_scholar_env/bin/activate
ただし、Windowsの場合は以下を使用します:
.google_scholar_envScriptsactivate
必要なパッケージのインストール
venvを有効化したら、Beautiful Soupとpandasをインストールする必要があります:
pip install beautifulsoup4 pandas
Beautiful SoupはGoogle ScholarページのHTML構造をパースし、記事・タイトル・著者などの特定データ要素を抽出するのに役立ちます。pandasは抽出したデータを構造化された形式に整理し、CSVファイルとして保存します。
Beautiful Soupとpandasに加えて、Seleniumの設定も必要です。Google Scholarのようなウェブサイトは、過負荷を避けるため自動リクエストをブロックする対策を実施していることがよくあります。Seleniumはブラウザ操作を自動化しユーザー行動を模倣することで、これらの制限を回避するのに役立ちます。
Seleniumをインストールするには以下のコマンドを使用します:
pip install selenium
ChromeDriverをダウンロードする必要がないよう、Seleniumの最新バージョン(執筆時点では4.6.0)を使用していることを確認してください。
Google ScholarにアクセスするPythonスクリプトの作成
環境をアクティブ化し、必要なライブラリをダウンロードしたら、Google Scholarのスクレイピングを開始します。
google_scholar_scraperディレクトリ内にgscholar_scraper.pyという名前の新しいPythonファイルを作成し、必要なライブラリをインポートします:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
次に、Selenium WebDriverを設定してChromeブラウザをヘッドレスモード(グラフィカルユーザーインターフェースなし)で制御します。これにより、ブラウザウィンドウを開かずにデータをスクレイピングできます。Selenium WebDriverを初期化する以下の関数をスクリプトに追加します:
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
WebDriverを初期化したら、Selenium WebDriverを使用してGoogle Scholarに検索クエリを送信する別の関数をスクリプトに追加する必要があります:
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # ページ読み込み完了まで最大10秒待機
# ページソース(HTMLコンテンツ)を返す
return driver.page_source
このコードでは、driver.get(base_url + params) が Selenium WebDriver に構築された URL への移動を指示します。また、ページ上の全要素の読み込み完了まで最大10秒待機した後、パースを行うよう WebDriver を設定しています。
HTMLコンテンツのパース
検索結果ページのHTMLコンテンツを取得したら、必要な情報を抽出するためのパース関数が必要です。
記事の適切なCSSセレクタと要素を取得するには、Google Scholarページを手動で調査する必要があります。ブラウザの開発者ツールを使用し、著者、タイトル、スニペット要素の固有のクラスまたはIDを探します(例: タイトル用のgs_rt、以下の画像参照)。
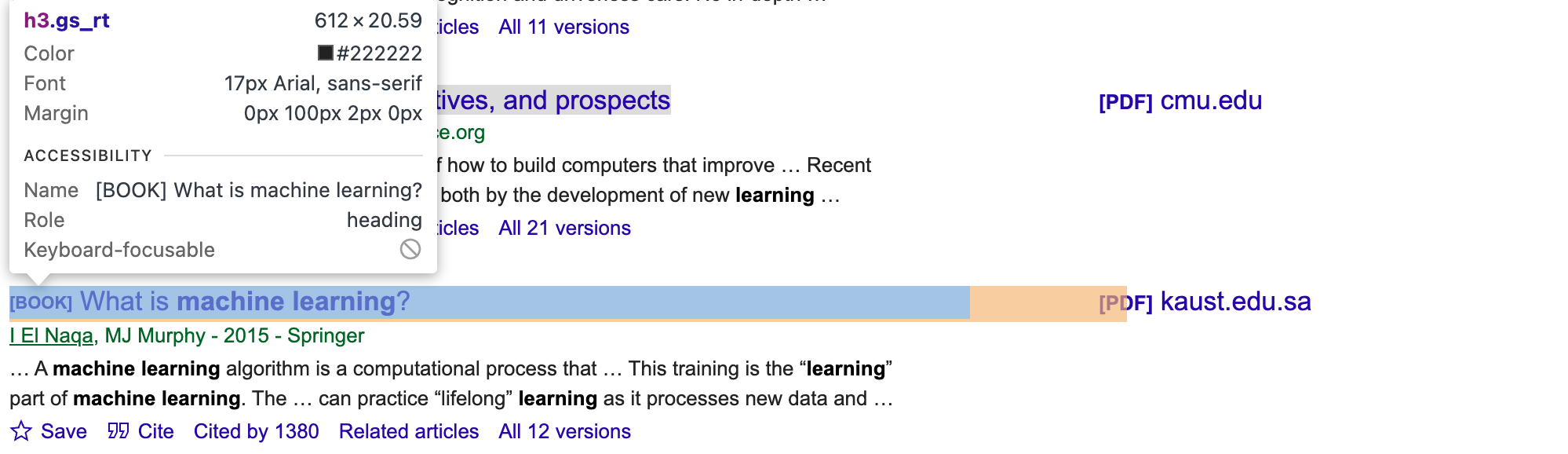
その後、スクリプトを更新します:
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
この関数はBeautifulSoupを使用してHTML構造をナビゲートし、記事情報を含む要素を特定し、各記事のタイトル、著者、スニペットを抽出し、それらを辞書のリストにまとめます。
更新されたスクリプトには、Google Scholarページ上の各検索結果項目に一致するCSSセレクタである.select(.gs_ri)が含まれていることに気づくでしょう。その後、コードはより具体的なセレクタ(.gs_rt、.gs_a、.gs_rs)を使用して、各結果のタイトル、著者、スニペット(簡単な説明)を抽出します。
スクリプトの実行
スクレイパースクリプトをテストするため、以下の_main_コードを追加し「machine learning」で検索を実行します:
if __name__ == "__main__":
search_query = "machine learning"
# Selenium WebDriverを初期化
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
fetch_search_results関数は検索結果ページのHTMLコンテンツを抽出します。その後、parse_results関数がHTMLコンテンツからデータを抽出します。
完全なスクリプトは以下の通りです:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Selenium WebDriverでページを取得
driver.get(params)(base_url + params)
# ページ読み込みを待機
driver.implicitly_wait(10) # 最大10秒間待機
# ページソース(HTMLコンテンツ)を返す
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Selenium WebDriverの初期化
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
スクリプトを実行するにはpython gscholar_scraper.py を実行してください。出力は次のようになります:
% python3 scrape_gscholar.py
title authors snippet
0 [PDF][PDF] Machine learning algorithms-a review B Mahesh - International Journal of Science an... … Here‟sa quick look at some of the commonly u...
1 [BOOK][B] 機械学習 E Alpaydin - 2021 - books.google.com MIT が機械学習に関する簡潔な入門書を発表...
2 機械学習:トレンド、展望、および... MI Jordan、TM Mitchell - Science、2015 - scien... … 機械学習は、h... の問題に対処します。
3 [書籍][B] 機械学習とは? I El Naqa、MJ マーフィー - 2015 - Springer … 機械学習アルゴリズムは、計算...
4 [書籍][B] 機械学習
検索クエリをパラメータにする
現在、検索クエリはハードコードされています。スクリプトをより柔軟にするには、スクリプトを変更せずに検索用語を簡単に切り替えられるように、それをパラメータとして渡す必要があります。
まず、スクリプトに渡されるコマンドライン引数にアクセスするためにsys をインポートします。
import sys
次に、クエリをパラメータとして使用するように__main__ ブロックスクリプトを更新します。
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Selenium WebDriverを初期化
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
指定した検索クエリと共に以下のコマンドを実行してください:
python gscholar_scraper.py <検索クエリ>
この時点で、ターミナルからあらゆる検索クエリを実行できます(例:「人工知能」、「エージェントベースモデリング」、「感情学習」)。
ページネーションを有効化
通常、Google Scholarは1ページあたり数件(約10件)の検索結果しか表示せず、不十分な場合があります。より多くの結果をスクレイピングするには、複数の検索結果ページを調査する必要があります。つまり、追加ページをリクエストしてパースするスクリプトの修正が必要です。
fetch_search_results関数を修正し、取得するページ数を制御するstartパラメータを追加できます。Google Scholarのページネーションシステムでは、このパラメータは各ページごとに10ずつ増加します。
https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5 のような典型的な Google Scholar ページリンクの最初のページを閲覧する場合、URL 内のstart パラメータによって表示される結果のセットが決まります。 例えば、start=0 で最初のページ、start=10 で2ページ目、start=20 で3ページ目…と取得されます。
この処理に対応するようスクリプトを更新します:
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Selenium WebDriverでページを取得
driver.get(base_url + params)
# ページ読み込み待機
driver.implicitly_wait(10) # 最大10秒待機
# ページソース(HTMLコンテンツ)を返却
return driver.page_source
次に、複数ページのスクレイピングを処理する関数を作成します:
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
for i in range(num_pages):
start = i * 10 # 各ページには10件の結果が含まれる
html_content = fetch_search_results(driver, query, start=start)
articles = parse_results(html_content)
all_articles.extend(articles)
return all_articles
この関数は指定されたページ数(num_pages)を反復処理し、各ページのHTMLコンテンツをパースして、すべての記事を単一のリストに収集します。
メインスクリプトでこの新関数を使用するよう更新することを忘れないでください:
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Usage: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Selenium WebDriverを初期化
driver = init_selenium_driver()
try:
all_articles = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(all_articles)
df.to_csv('results.csv', index=False)
finally:
driver.quit()
このスクリプトには、集計データをターミナルに出力するだけでなく保存するための行 (df.to_csv('results.csv', index=False)) も含まれています。
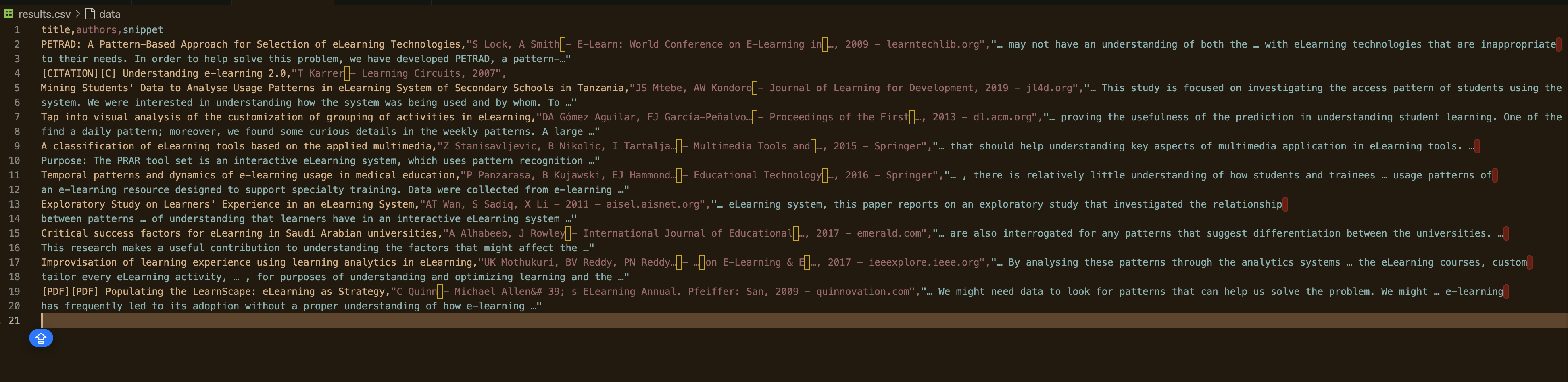
では、スクリプトを実行し、スクレイピングするページ数を指定します:
python gscholar_scraper.py "understanding elearning patterns" 2
出力は次のようになります:
IPブロック回避方法
ほとんどのウェブサイトは、スクレイピングを防ぐため、自動リクエストのパターンを検知するボット対策を実施しています。ウェブサイトが異常な活動を検知した場合、あなたのIPがブロックされる可能性があります。
例えば、このスクリプト作成中に、返されるレスポンスが空データのみとなる現象が発生しました:
空のデータフレーム
列: []
インデックス: []
この現象が発生した場合、IPアドレスは既にブロックされている可能性があります。この状況では、IPアドレスがフラグ付けされないように回避策を見つける必要があります。以下に、IPブロックを回避するためのいくつかの手法を示します。
プロキシの利用
プロキシサービスを利用すると、リクエストを複数のIPアドレスに分散できるため、ブロックされる可能性が低くなります。例えば、プロキシ経由でリクエストを転送すると、プロキシサーバーがリクエストを直接ウェブサイトにルーティングします。これにより、ウェブサイトはあなたの実際のIPアドレスではなく、プロキシのIPアドレスからのリクエストのみを認識します。プロジェクトにプロキシを実装する方法については、こちらの記事を参照してください。
IPアドレスのローテーション
IPブロック回避のもう一つの手法は、一定数のリクエスト後にIPアドレスをローテーションするスクリプトを設定することです。手動で行うか、自動的にIPをローテーションするプロキシサービスを利用できます。これにより、リクエストが異なるユーザーからのように見えるため、ウェブサイトがIPを検知してブロックするのが難しくなります。
仮想プライベートネットワーク(VPN)の活用
仮想プライベートネットワーク(VPN)は、インターネットトラフィックを別の場所にあるサーバー経由でルーティングすることでIPアドレスを隠蔽します。異なる国にサーバーを設置したVPNを設定すれば、様々な地域からのトラフィックをシミュレートできます。これにより実際のIPアドレスが隠され、ウェブサイトがIPに基づいて活動を追跡・ブロックすることが困難になります。
まとめ
本記事ではPythonを用いたGoogle Scholarからのデータスクレイピング手法を解説しました。仮想環境の構築、Beautiful Soup/pandas/Selenium等の必須パッケージ導入、検索結果取得・パーススクリプトの作成を実施。ページネーションによる複数ページスクレイピングを実現し、プロキシ利用・IPローテーション・VPN導入といったIPブロック回避技術についても論じました。
手動でのスクレイピングも成功する可能性はありますが、IP禁止や継続的なスクリプトメンテナンスの必要性といった課題が伴うことがよくあります。データ収集作業を簡素化し強化するには、Bright Dataのソリューションの活用をご検討ください。当社のレジデンシャルプロキシネットワークは高い匿名性と信頼性を提供し、スクレイピングタスクを中断なく円滑に実行します。さらにWeb Scraper APIはIPローテーションとCAPTCHAの解決を自動処理し、時間と労力を節約します。すぐに使えるデータが必要な場合は、様々なニーズに合わせた豊富なデータセットをご覧ください。
データ収集を次のレベルへ——Bright Dataの無料トライアルに今すぐ登録し、プロジェクトに最適な効率的で信頼性の高いスクレイピングソリューションを体験してください。





