

Google Travelは、フライト、バケーションパッケージ、ホテル客室など、あらゆる旅行関連カテゴリについて、ウェブ上のアグリゲーター旅行データを収集します。ホテル探しは困難であり、最大の煩わしさの一つは、広告スポンサー付きリストや検索条件に全く該当しない無作為な客室が混在する混乱を整理することです。
スクレイピングに興味がない場合は、当社の既製旅行データセットをご覧ください。データセットではスクレイピング作業を代行します。スクレイピングの準備が整っている方は、読み進めてください!
前提条件
旅行データをスクレイピングするには、PythonとSelenium、Requests、またはAIOHTTPのいずれかが必要です。Seleniumを使用する場合、Google Travelから直接ホテル情報をスクレイピングします。RequestsとAIOHTTPを使用する場合は、BrightDataのBooking.com APIを利用します。
Seleniumを使用する場合は、webdriverがインストールされていることを確認してください。Seleniumに不慣れな方は、こちらのガイドを参照して素早く理解を深めましょう。
Seleniumのインストール
pip install selenium
Requestsのインストール
pip install requests
AIOHTTPのインストール
pip install aiohttp
選択したツールをインストールしたら、準備完了です。
Google Travelから抽出するデータ
Google Travelを手動でスクレイピングする場合、取得対象データを理解する必要があります。すべてのホテル検索結果はGoogleTravelのカスタムc-wiz要素に埋め込まれています。
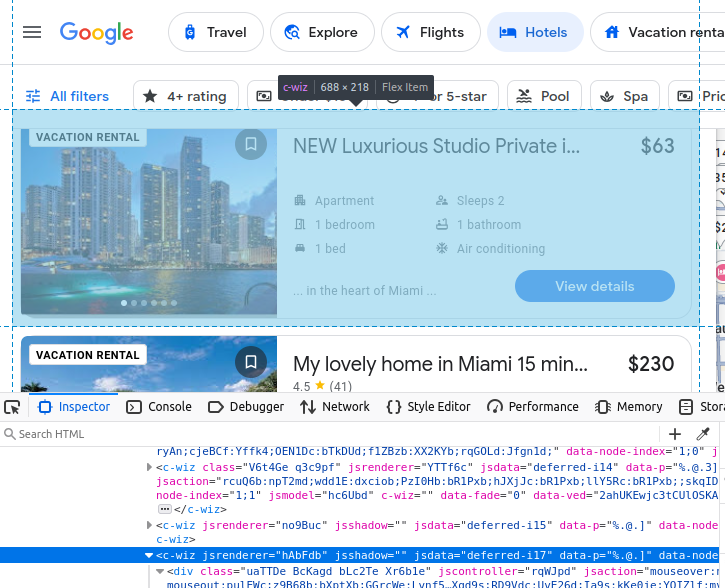
ただし、ページ上には多数のc-wiz要素が存在します。各ホテルカードには、div要素とこのc-wiz要素から直接子孫となるa要素が含まれています。これらの要素から子孫となる全てのaタグを抽出するCSSセレクタを記述できます:c-wiz > div > a。
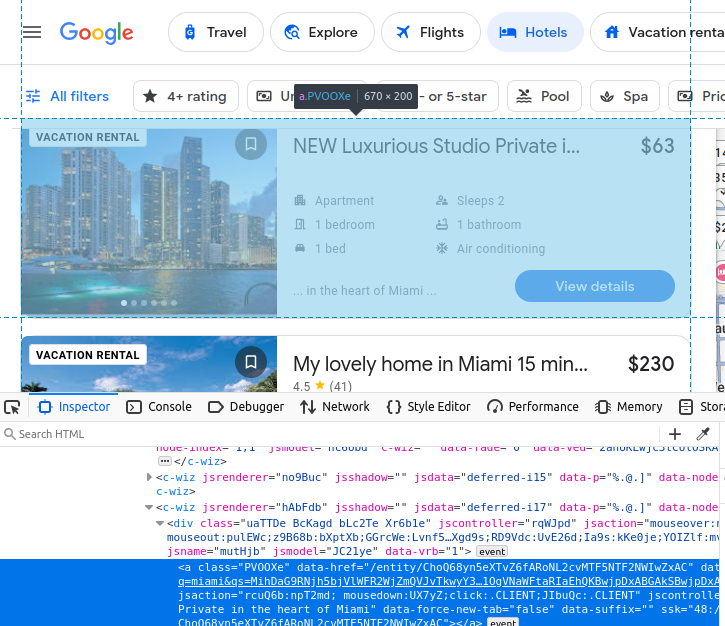
リスティング名はh2タグ内に埋め込まれています。
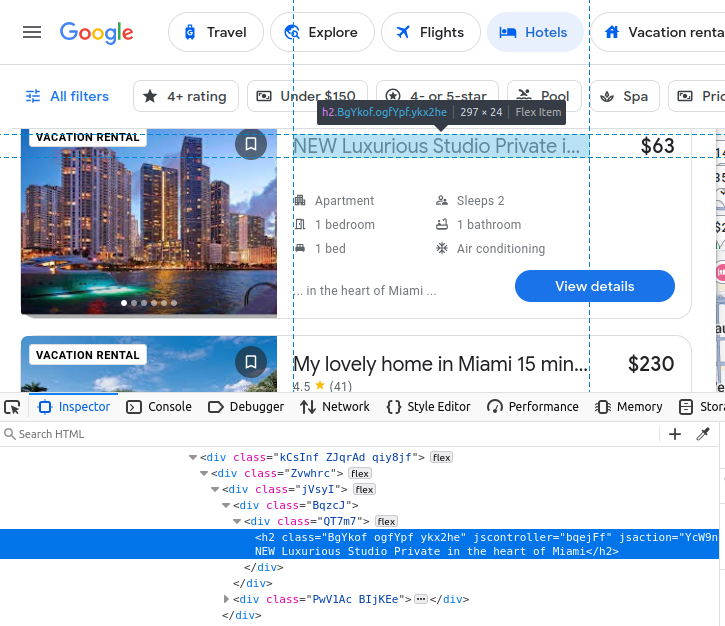
料金はspan要素に埋め込まれています。
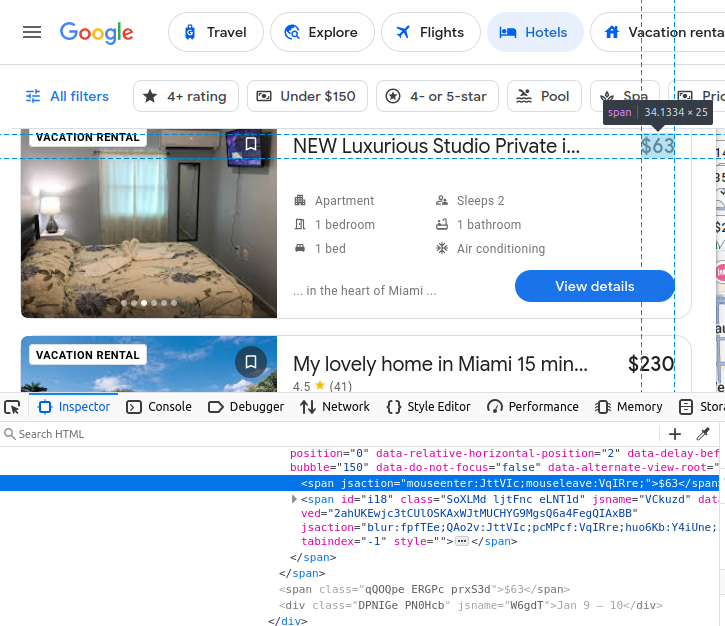
当ホテルの設備情報はli(リスト)要素内に埋め込まれています。
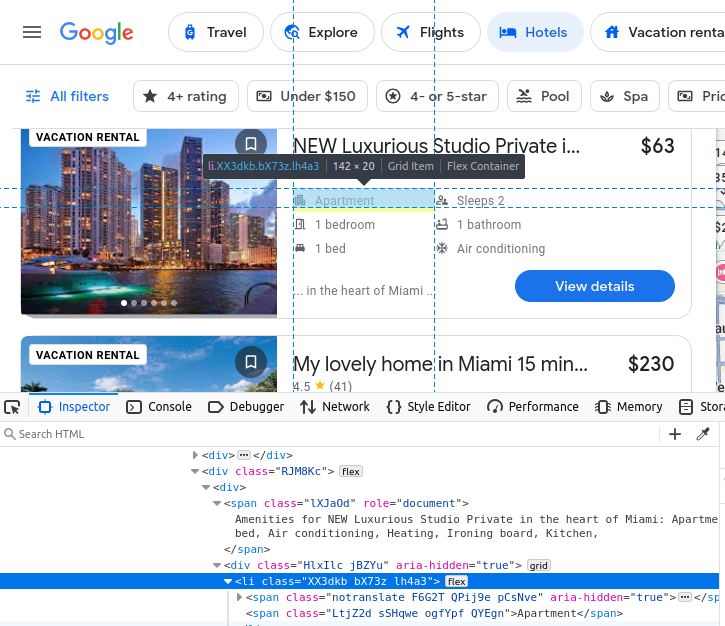
ホテルカードを見つけたら、そこから前述のデータをすべて抽出できます。
Seleniumによるデータ抽出
Seleniumでこのデータを抽出するのは、対象が分かれば比較的簡単です。ただしGoogle Travelは結果を動的に読み込むため、事前設定の待機時間、マウスクリック、カスタムウィンドウで構成される繊細なプロセスとなります。カスタムウィンドウがなければ結果は正しく読み込まれません。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------ページ {page}------------------")
print("見つかったアイテム数: ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("next button found!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- まず、
ChromeOptionsのインスタンスを作成します。これを使用して--headlessと--window-size=1920,1080引数を追加します。- カスタムウィンドウサイズを指定しないと結果が正しく読み込まれず、同じ結果を繰り返しスクレイピングすることになります。
- ブラウザ起動時にはキーワード引数
options=OPTIONSを使用します。これによりカスタムオプション付きでChromeが起動します。 ActionChains(driver) はActionChainsのインスタンスを返します。後続のスクリプトでカーソルを「次へ」ボタンに移動し、クリックするために使用します。- 実行時間を管理するために
whileループを使用します。スクレイピングが完了すると、このループから抜け出します。 hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")はページ上の全ホテルリンクを取得します。親要素はXPathで特定:hotel_card = hotel_link.find_element(By.XPATH, "..")。- 次に、先ほど確認した個々のデータを抽出します:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - 価格を取得する際、カード内に
「DEAL」や「GREAT PRICE」といった追加要素が含まれる場合があります。常に正しい価格を取得するため、span要素を配列で抽出します。配列にこれらの単語が含まれる場合、最初の要素(price_holder[0].text)ではなく2番目の要素(price_holder[1].text)を採用します。 - 評価を検索する際
にもfind_elements()メソッドを使用します。評価が存在しない場合、デフォルト値としてn/aを付与します。 hotel_card.find_elements(By.CSS_SELECTOR, "li")でアメニティホルダーを取得します。各要素のtext属性から内容を抽出します。
- url:
- 目的のページを全てスクレイピングするまでこのループを継続します。データを取得したら
doneをTrueに設定しループを終了します。 - ブラウザを閉じ、
json.dump()を使用してスクレイピングした全データをJSONファイルに保存します。
Google Travelからホテル情報をスクレイピングする際、特に大きな問題は発生しませんでしたが、あらゆる可能性はあります。問題が発生した場合、レジデンシャルプロキシとプロキシ統合型スクレイピングブラウザの両方を提供し、障害を乗り越えるお手伝いをします。
Seleniumによる結果のスクレイピングは手間がかかり繊細な作業ですが、完全に実行可能です。
Bright DataのTravel APIでデータを抽出
スクレイパーに依存したくない場合や、セレクターやロケーターの処理に一日を費やしたくない場合もあるでしょう。問題ありません!当社は複数の旅行データタイプを提供しています。Booking.com APIを使用したホテルデータの抽出も可能です。必要なのは数回のHTTPリクエストのみ。残りの処理は全て当社が担当しますので、お客様は本来の業務に集中できます。
リクエスト
以下のコードでBooking.comAPIの設定を行います。APIキー、旅行先、チェックイン日、チェックアウト日を入力するだけです。まずAPIにリクエストを送信してデータを生成し、レポートが準備できるまで10秒間隔でデータを繰り返し確認します。データを受信したら、便利なJSONファイルに保存します。
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/データセット/v3/トリガー"
#booking.com データセット
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("リクエスト成功。応答:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"エラー: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
# スナップショット URL を作成
snapshot_url = f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"スナップショットID: {snapshot_id} の取得を開始します...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("スナップショットの準備が整いました。ダウンロード中...")
snapshot_data = response.json()
#スナップショットを新しいjsonファイルに書き込む
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"スナップショットを {output_file} に保存しました")
break
elif response.status_code == 202:
print("スナップショットはまだ準備できていません。 10秒後に再試行します...")
else:
print(f"エラー: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "your-bright-data-api-key"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings() はAPI_KEY、LOCATION、DATESを受け取ります。その後、データのリクエストを行い、snapshot_idを返します。snapshot_idは非常に重要です。スナップショットを取得するために必要です。スナップショットIDが生成された後、poll_and_retrieve_snapshot()は10秒ごとにデータの準備状態を確認します。- データが準備でき次第、
json.dump()を使用して JSON ファイルに保存します。
コードを実行すると、ターミナルに以下のような出力が表示されるはずです。
リクエスト成功。応答:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
スナップショットをポーリング中: ID: s_m5moyblm1wikx4ntot...
スナップショットはまだ準備できていません。10秒後に再試行...
スナップショットはまだ準備できていません。10秒後に再試行...
スナップショットはまだ準備できていません。10秒後に再試行...
スナップショットはまだ準備できていません。10秒後に再試行...
スナップショットの準備が完了しました。ダウンロード中...
スナップショットが snapshot-data.json に保存されました
すると、以下のようなオブジェクトで埋め尽くされたJSONファイルが得られます。
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"children": null,
"rooms": 1,
"id": "55989",
"title": "Ramada Plaza by Wyndham Marco Polo Beach Resort",
"address": "19201 Collins Avenue",
"city": "Sunny Isles Beach (Florida)",
"review_score": 6.2,
"review_count": "1788",
"image": "https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
"final_price": 217,
"original_price": 217,
"currency": "USD",
"tax_description": null,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "これは地図上の直線距離です。実際の移動距離は異なる場合があります。",
"main_distance": "ダウンタウンから11.4マイル",
"display_location": "マイアミビーチ",
"beach_distance": "ビーチフロント",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2026-01-07T16:43:24.954Z"
},
AIOHTTP
AIOHTTPを使用すると、この処理を大幅に高速化できます。複数のデータセットを同時にトリガー、ポーリング、ダウンロードすることが可能です。以下のコードは、上記のRequestsの例で説明した概念を基にしていますが、代わりに強力なaiohttp.ClientSession()を使用して複数のリクエストを非同期で実行します。
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/データセット/v3/トリガー"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"リクエスト成功: {location}. 応答:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"場所: {location} のエラー。ステータス: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"スナップショットID: {snapshot_id} のポーリング中...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"{output_file} のスナップショットが準備完了。ダウンロード中...")
snapshot_data = await response.json()
# スナップショットデータをファイルに保存
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"スナップショットが {output_file} に保存されました")
break
elif response.status == 202:
print(f"{output_file} のスナップショットはまだ準備できていません。10秒後に再試行します...")
else:
print(f"{output_file} のスナップショット取得中にエラーが発生しました。ステータス: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# すべてのロケーションを並列処理
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
get_bookings()とpoll_and_retrieve_snapshot()の両方が、サーバーへの非同期リクエストを作成するためにaiohttp.ClientSessionオブジェクトを使用するようになりました。process_location()は、特定の場所に関する全データを処理するために使用されます。main()では、すべてのロケーションに対してprocess_location()を同時に呼び出せます。
AIOHTTPを使用すると、複数のデータセットを同時にトリガー、ポーリング、ダウンロードできます。これにより、次のレポートを生成する前に、1つのレポートが完了するのを不必要に待つ必要がなくなります。
出力結果をご覧ください。両レポートのトリガーが実行され、一方のダウンロード中に他方の完了待ち状態が維持されています。大規模運用では、これにより大幅な時間短縮が実現します。
ロケーション: Miami のリクエスト成功。応答:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
ロケーション: Key West のリクエスト成功。応答:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
スナップショットID: s_m5mtmtv62hwhlpyazw のポーリング中...
スナップショットID: s_m5mtmtv72gkkgxvdid のポーリング中...
snapshot-miami.json のスナップショットはまだ準備できていません。10秒後に再試行...
snapshot-key_west.json のスナップショットはまだ準備できていません。 10秒後に再試行...
snapshot-key_west.jsonのスナップショットはまだ準備できていません。10秒後に再試行...
snapshot-miami.jsonのスナップショットはまだ準備できていません。10秒後に再試行...
snapshot-key_west.jsonのスナップショットはまだ準備できていません。10秒後に再試行...
snapshot-miami.json のスナップショットはまだ準備ができていません。10秒後に再試行します...
snapshot-miami.json のスナップショットが準備完了しました。ダウンロード中...
snapshot-key_west.json のスナップショットはまだ準備ができていません。10秒後に再試行します...
スナップショットが snapshot-miami.json に保存されました
snapshot-key_west.json のスナップショットはまだ準備ができていません。 10秒後に再試行します...
snapshot-key_west.json のスナップショットはまだ準備ができていません。10秒後に再試行します...
snapshot-key_west.json のスナップショットはまだ準備ができていません。10秒後に再試行します...
snapshot-key_west.json のスナップショットの準備が完了しました。ダウンロード中...
スナップショットが snapshot-key_west.json に保存されました
Bright Dataの代替ソリューション
強力なWebスクレイパーAPIに加え、Bright Dataでは多様なニーズに対応した即利用可能なデータセットを提供しています。特に人気の高い旅行関連データセットは以下の通りです:
Bright Dataでは、完全に管理されたカスタムデータセットと自己管理型カスタムデータセットから選択でき、あらゆる公開ウェブサイトからデータを抽出し、お客様の正確な仕様に合わせてカスタマイズすることが可能です。
結論
ウェブスクレイピングを行う際、Google Travelからはホテル情報の宝庫が見つかります。Seleniumを使ったDIYモデルを好む場合でも、Booking.com APIで迅速かつ便利な結果を得たい場合でも、このデータを収集して非常に価値ある洞察を得ることができます。過去の価格を分析したい場合でも、効率的に部屋を探したい場合でも、あなたの技術スタックにまた一つ有用なスキルが加わったことになります!
Bright Dataの製品を無料で試すには今すぐ登録してください。






