

すべてのデータは価値があります。集計データはウェブ上で最も需要の高いデータの一つです。Google Financeには様々な金融市場向けの膨大な集計データが含まれています。このデータは、取引ボットから一般的なレポート作成まで、あらゆる用途に有用です。
さあ始めましょう!
前提条件
適切なスキルセットがあれば、Google Financeから比較的容易にデータを抽出できます。Google Financeをスクレイピングするには以下のものが必要です。
- Python: Pythonの基本的な理解があれば十分です。変数、関数、ループの扱い方を知っている必要があります。
- Python Requests: 標準的なPython HTTPクライアントです。ウェブ上でGET、POST、PUT、DELETEリクエストを送信するために使用されます。
- BeautifulSoup: BeautifulSoupは効率的なHTMLパーサーを提供します。データ抽出にこれを使用します。
まだインストールしていない場合は、以下のコマンドでRequestsとBeautifulSoupをインストールできます。
Requestsのインストール
pip install requests
BeautifulSoupのインストール
pip install beautifulsoup4
Google Financeからスクレイピングする情報
Google Financeのフロントページの画像です。様々な市場に関する断片的な情報がすべて含まれています。私たちは断片的な情報ではなく、複数の市場に関する詳細な情報を必要としています。
少し下にスクロールすると、ページ右側に「マーケットトレンド」というセクションがあります。このセクションの各バブルは、特定の市場に関する詳細情報へのリンクです。私たちが注目するのは以下の市場です:上昇銘柄、下落銘柄、市場指数、出来高上位銘柄、暗号通貨。
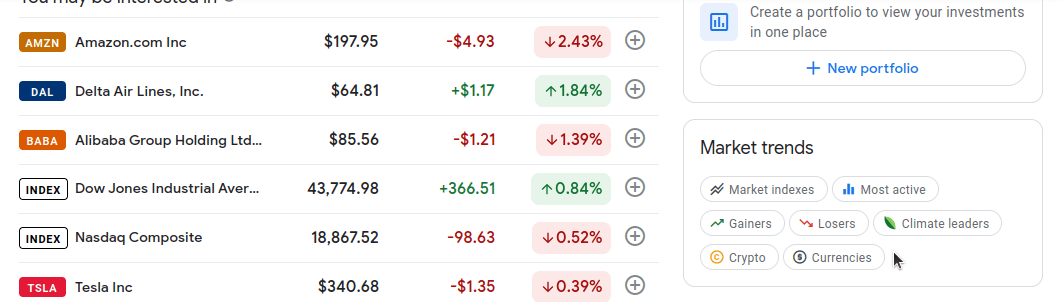
では、これらの各ページをクリックして検証します。まずは「上昇銘柄」から始めましょう。アドレスバーに表示されている通り、URLはhttps://www.google.com/finance/markets/gainers です。画面下部の開発者コンソールを見ると、データセット全体がul(無構造リスト)に埋め込まれていることがわかります。
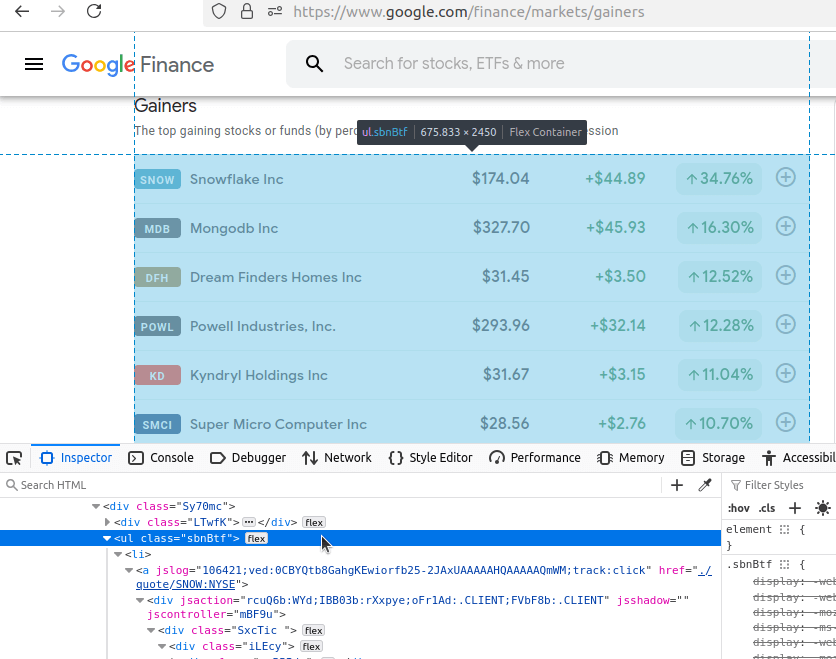
次に「下落銘柄」を確認します。URLは:https://www.google.com/finance/markets/losers。ここでもデータセットは未整理リストに埋め込まれています。
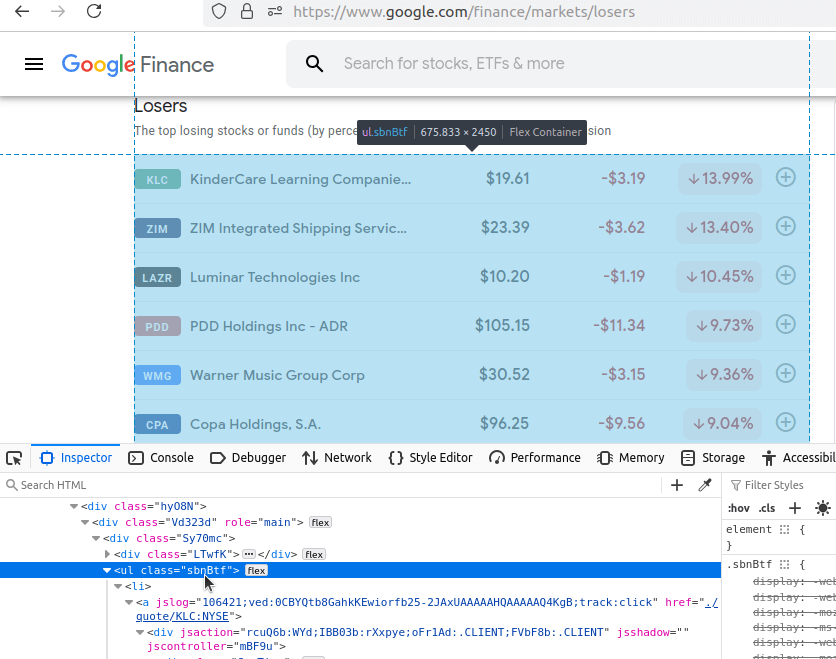
こちらは市場指数ページの同じ画面です。このページは少し特殊です。複数のul要素を含むため、コードで対応する必要があります。URLはhttps://www.google.com/finance/markets/indexesです。傾向に気づき始めていますか?
最も活発なページは以下に示します。ここでも対象データは全てul内に埋め込まれています。URLは:https://www.google.com/finance/markets/most-active。
最後に、Cryptoページを見てみましょう。おそらく予想通り、データはul内にあります。URLは:https://www.google.com/finance/markets/cryptocurrencies。
これらの各ページでは、ターゲットデータが整理されていないリスト内に埋め込まれています。データを抽出するには、これらのul要素を見つけ、それぞれからli(リスト項目)要素を抽出する必要があります。基本URLを見てみましょう:https://www.google.com/finance/markets。各ページはmarketsエンドポイントから取得されます。 URL形式は次の通りです:https://www.google.com/finance/markets/{市場名}。5つのデータセットと5つのURLが全て同じ構造です。これにより、わずかな変数で大量のデータを簡単にスクレイピングできます。
PythonでGoogle Financeを手動スクレイピング
ブロックされない限り、PythonのRequestsとBeautifulSoupでGoogle Financeをスクレイピングできます。データをスクレイピングできる必要があります。また、保存できるべきです。様々なエンドポイントがありますが、すべて同じベースURLから派生しています:https://google.com/finance/markets/。ページを取得するたびに、ul要素を見つけ、各リストからすべてのli要素を抽出する必要があります。
スクリプトで使用する基本関数を説明します。write_to_csv()とscrape_page() と呼びます。これらの名前はほぼ自明です。
個々の関数
write_to_csv() を見てみましょう。
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("CSVへの書き込み中...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSVファイルへのデータ書き込み中...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{filename} を CSV に正常に書き出しました...")
- 関数は
辞書オブジェクトのリストをCSVに書き込む必要がある。データがリストでない場合、data = [data]で変換する。 - 生成する各ファイルはGoogle Financeからのデータであるため、ファイル作成時に以下を追加します:
filename = f"google-finance-{filename}.csv" - デフォルト
モードは「w」(書き込み)ですが、ファイルが存在する場合はモードを「a」(追加)に変更します。 csv.DictWriter(file, fieldnames=data[0].keys())でファイルライターを初期化します。- 書き込みモードの場合、ファイルはまだ存在しないため、
リストの最初の辞書からヘッダーを作成します。 - セットアップが完了したら、
writer.writerows(data)でデータをファイルに追加します。
次に、実際のスクレイピング関数scrape_page()を見てみましょう。ここが真の処理の中心です。フォーマット済みURLにリクエストを送信します。その後、BeautifulSoupを使用して返されたHTMLをパースします。抽出データを保持する空のリストscraped_dataを作成します。ページ上のすべてのul要素を検索します。見つけた各ulから li要素を抽出します。ただし注意点があります。各リスト項目のテキストは複数のdiv要素にネストされています。実際にスクレイピングされる配列には重複が多数含まれます。これを回避するため、3番目、6番目、8番目、11番目の項目を抽出し、scraped_dataにappend ()で追加します。
scrape_page()関数は以下のスニペットにあります。
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- このエンドポイントにGETリクエストを送信します:
requests.get(f"https://google.com/finance/markets/{endpoint}"). レスポンスに対してBeautifulSoupのHTMLパーサーを使用します:soup = BeautifulSoup(response.text, "html.parser").- ページ上の全テーブルを検索します:
tables = soup.find_all("ul"). scraped_data = []で結果を保持する配列を作成します。- 見つかった各テーブルを反復処理し、以下の操作を行います:
- リスト項目をすべて取得します:
table.find_all("li")。 - 各リスト項目を反復処理し、
そのdiv要素を取得します。これによりdivsというリストが返されます。 divsの3番目、6番目、8番目、11番目のアイテムからテキストを取得し、辞書(dict)を作成します。- この
辞書をscraped_dataに追加します。 - 仮想通貨は取引ペアで価格が設定されるため、仮想通貨エンドポイントでは
通貨をn/aにリセットします。
- リスト項目をすべて取得します:
- ページのパースが完了したら、
scrape_dataをCSVに保存します:write_to_csv(scraped_data, endpoint)。エンドポイントをファイル名として渡します。
Google Financeデータのスクレイピング
上記の関数をスクリプトにまとめ、動作させます。これらの関数に加え、エンドポイントのリストを追加します。また、実行環境を保持するmain関数も追加します。以下のコードをコピーして試してみてください!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("CSVへの書き込み中...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSVファイルへのデータ書き込み中...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {filename} to CSV...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
上記のコードを実行すると、以下の出力が得られます。
---------------------
CSVへの書き込み中...
CSVファイルへのデータ書き込み中...
google-finance-gainers.csvをCSVに正常に書き込みました...
---------------------
CSVへの書き込み中...
CSVファイルにデータを書き込んでいます...
google-finance-losers.csv を CSV に正常に書き込みました...
---------------------
CSVに書き込み中...
CSVファイルにデータを書き込み中...
google-finance-indexes.csv を CSV に正常に書き出しました...
---------------------
CSV への書き込み中...
CSV ファイルへのデータ書き込み中...
google-finance-most-active.csv を CSV に正常に書き出しました...
---------------------
CSV への書き込み中...
CSV ファイルへのデータ書き込み中...
google-finance-cryptocurrencies.csv を CSV に正常に書き出しました...
VSCodeでスクリプトを実行すると、スクレイパーが処理を完了するにつれてCSVファイルが実際に生成される様子を確認できます。以下のスクリーンショットでハイライト表示されています。
各ファイルがONLYOFFICEでどのように表示されるかのスクリーンショットも示します。
最も活発な銘柄
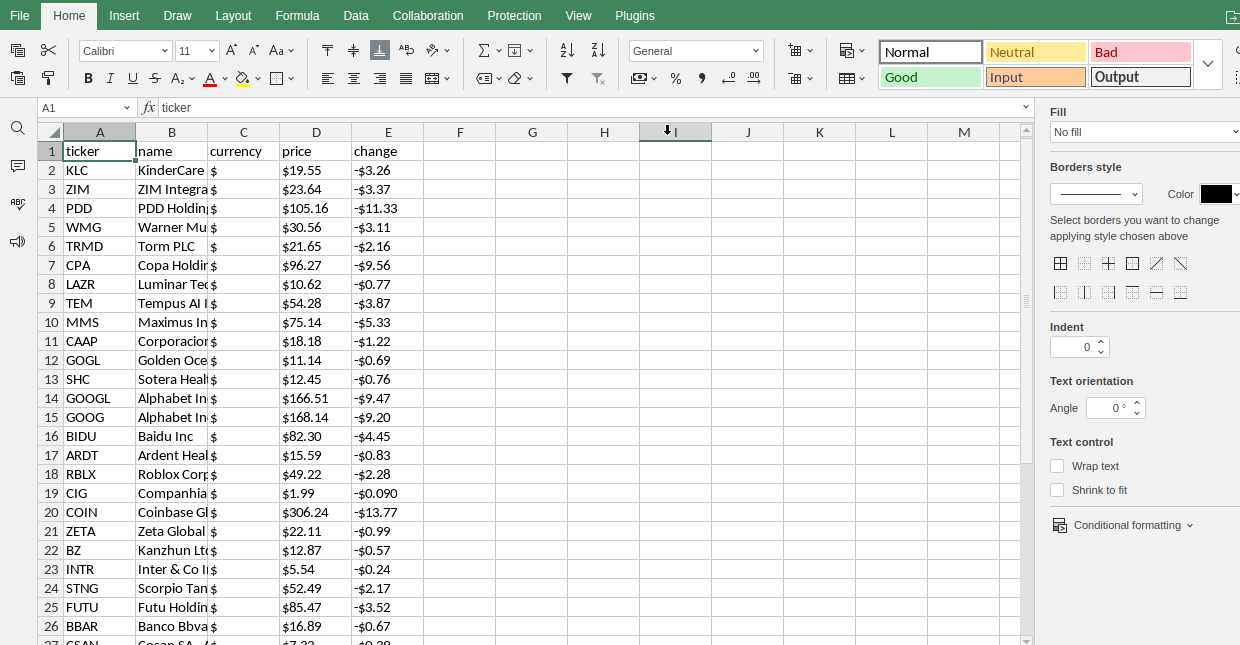
下落率上位銘柄
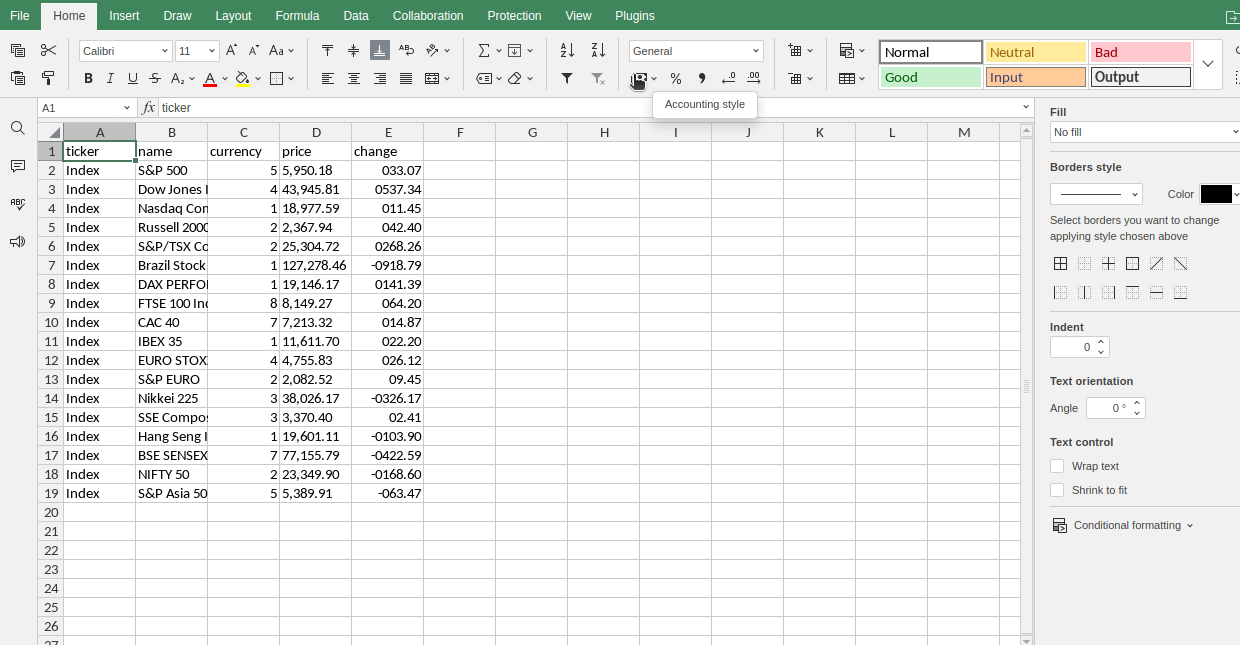
指数
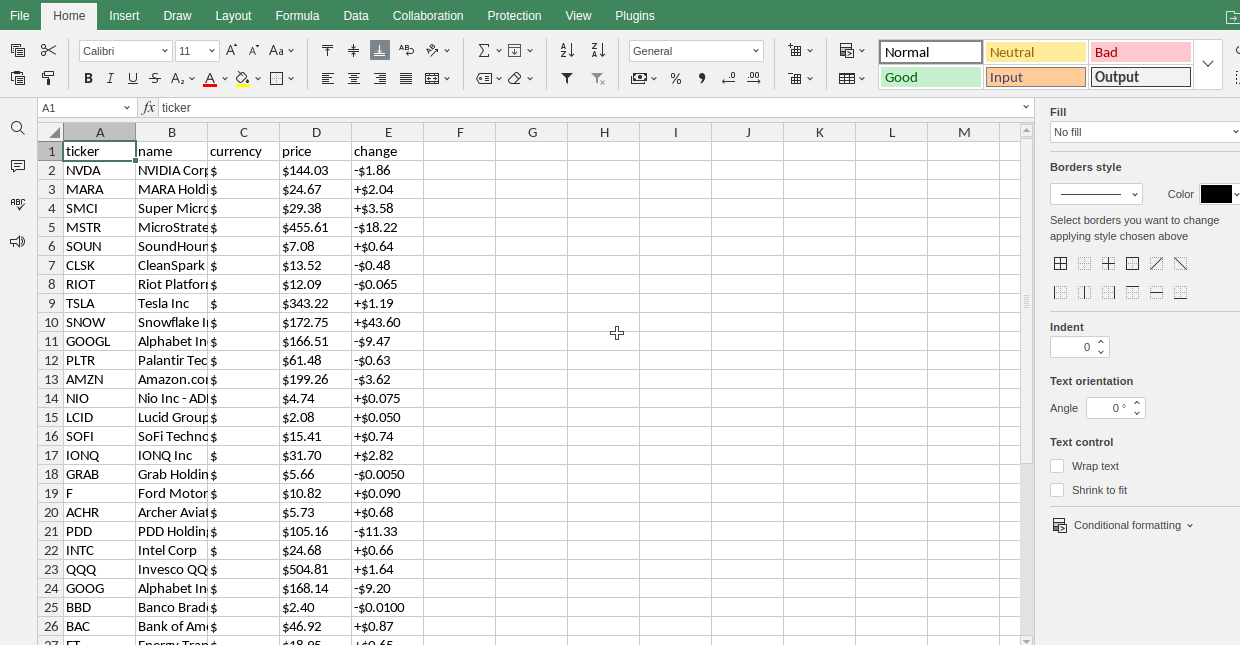
上昇銘柄
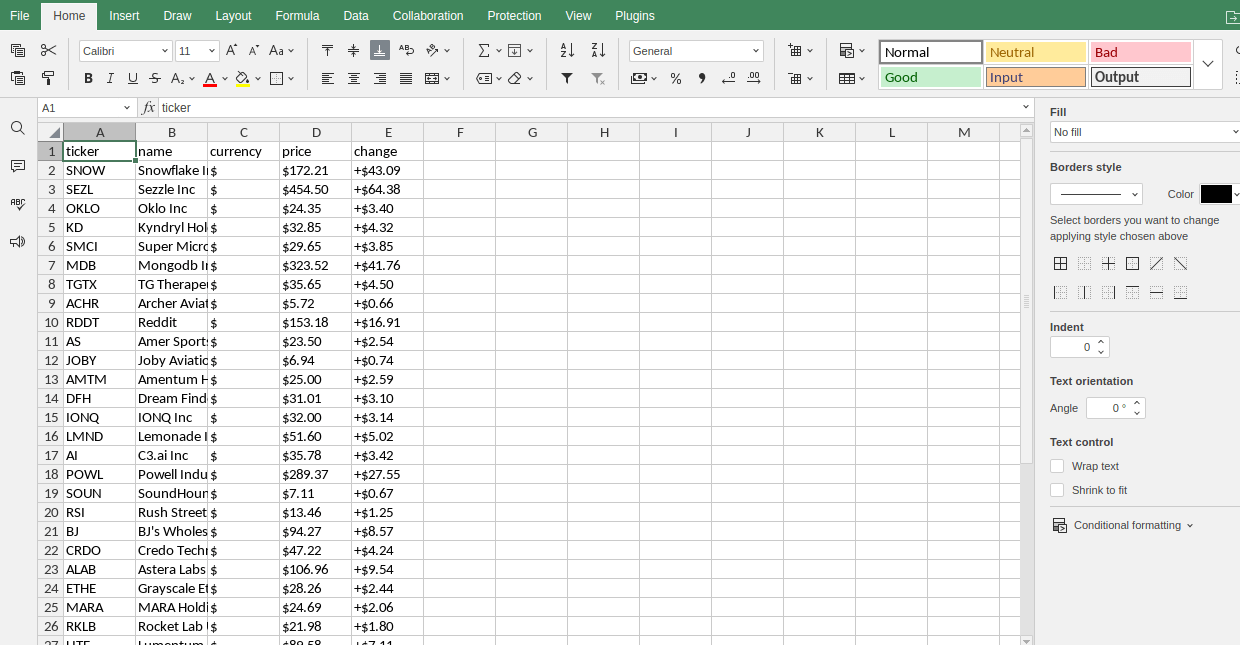
暗号通貨
高度なテクニック
ページネーションの処理
従来、ページネーションは数字を使用して処理されます。Google Financeの場合、実際にはエンドポイント配列を使用してページネーションを処理しています。エンドポイントリストの各項目は、スクレイピングしたい個々のページを表しています。このリストをもう一度確認してください。ウェブスクレイピング中のページネーション処理方法については、こちらで詳細をご覧ください。
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
では、実際の使用方法を見ていきましょう。従来のページネーションでは、数値を渡すエンドポイントかクエリパラメータのいずれかを使用します。しかし、このスクレイパーでは、代わりに各ページのエンドポイントをベースURLに渡します。
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
ブロック対策
テスト中、ブロック問題は発生しませんでした。しかし、この世界は完璧ではないため、将来的に遭遇する可能性があります。遭遇したブロックを回避するために、様々な対策が利用可能です。
偽のユーザーエージェント
ウェブサイトにリクエストを送信する際(ブラウザまたはPython Requestsを使用)、HTTPクライアントはユーザーエージェント文字列をサイトサーバーに送信します。これはリクエストを送信しているアプリケーションを識別するために使用されます。Pythonで偽のユーザーエージェントを設定するには、ユーザーエージェント文字列を作成し、ヘッダーに追加します。
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
タイミング付きリクエスト
リクエストのタイミング調整は非常に効果的です。1分間に200ページをリクエストする行為は、人間によるものではありません。レート制限を回避し、より人間らしく見せるために、スクレイパーにリクエスト間の待機を指示できます。これによりブラウジング活動がより自然に見えます。まず、timeモジュールの sleepをインポートします。
from time import sleep
次に、リクエスト間に任意の時間をスリープさせます。これによりスクレイパーの速度が低下し、より人間らしい動作に見えます。
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Bright Dataの利用をご検討ください
ウェブスクレイピングは手間がかかる作業です。Bright Dataは最高峰のデータセットプロバイダーの一つです。当社のデータセットではスクレイピングが完了済みで、レポートも用意されています。必要なのはダウンロードするだけです。ウェブスクレイピングが万人向けではないこと、単にデータを入手して利用したい方もいらっしゃることを理解しています。
Google Financeのデータセットは提供しておりませんが、Yahoo Financeのデータセットはご用意しております。Yahoo Financeは実際にはより幅広い金融データを提供しており、Google Financeのニーズを容易に満たすことができます。このデータセットの購入方法については以下でご説明します。
アカウントの作成
まずアカウントを作成する必要があります。登録ページにアクセスし、アカウントを作成してください。
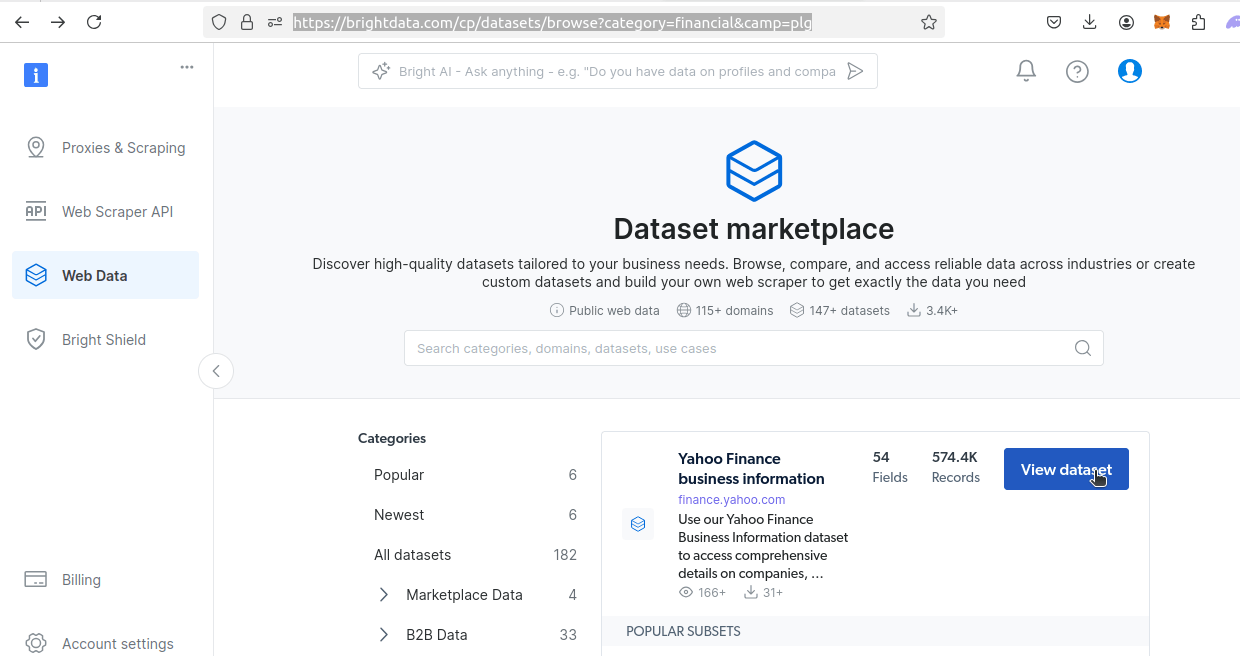
Bright Dataデータセットのダウンロード
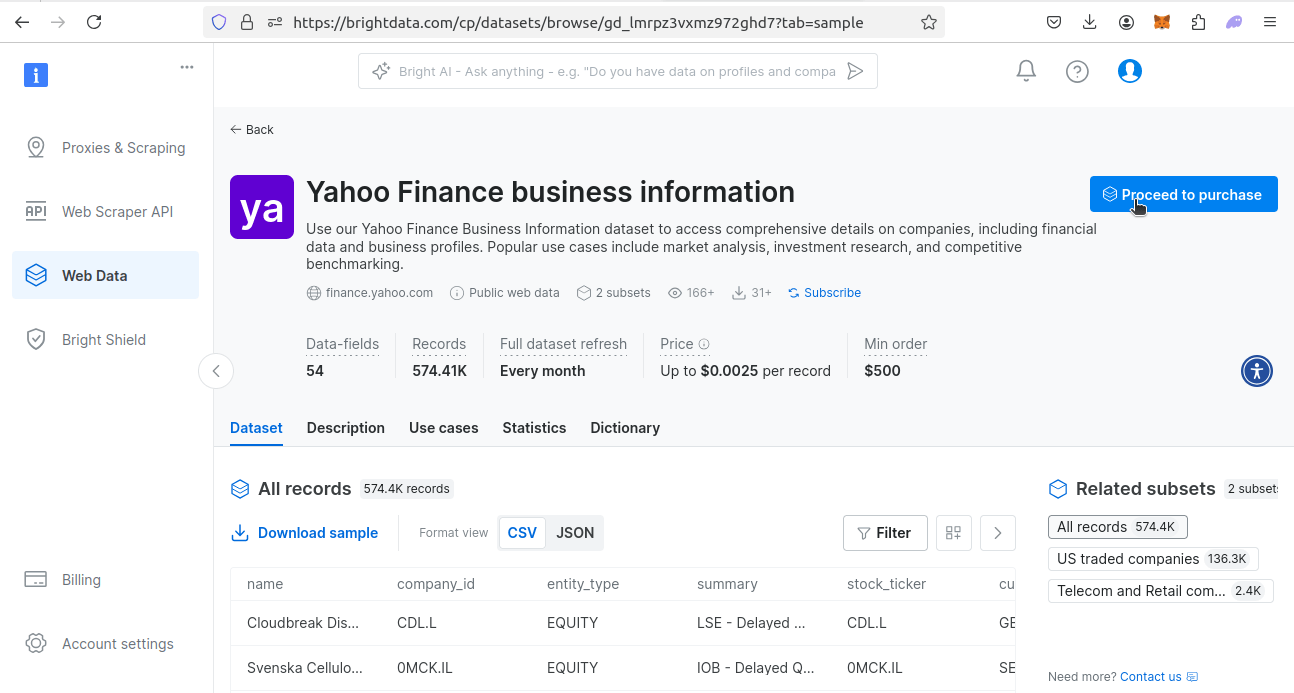
次に、金融データセットページに移動します。Yahoo Financeデータセットを見つけ、「データセットを表示」ボタンをクリックします。
データセットを表示すると、いくつかのオプションが表示されます。サンプルデータセットをダウンロードするか、データセットを購入できます。1レコードあたり0.0025ドルで、最低購入額は500ドルです。データセットが必要な場合は、「購入手続きへ進む」をクリックし、チェックアウトプロセスを進めてください。
当社の事前作成済みデータセットでは、スクレイピング作業は既に完了しています。データを入手したら、すぐに業務に取り掛かれます!
まとめ
完了です!集計データは世界中の人々にとって非常に価値あるツールです。Google Financeからのスクレイピング方法と、当社のYahoo Financeデータセットからの取得方法を習得しました。Python RequestsとBeautifulSoupを用いた基本スクレイパーの作成方法、BeautifulSoupでページオブジェクトをパースする際のfind_all ()メソッドの活用方法を理解できたはずです。
さらに高度な手法、例えばエンドポイントを用いたページネーション処理やブロック対策技術についても解説しました。この知識を活かしてスクレイパーを構築するか、あるいは当社の即利用可能なデータセットをダウンロードして時間と労力を節約しましょう。
今すぐ登録して無料トライアルを開始しましょう。無料データセットサンプルも含まれています。





