

このチュートリアルでは次の内容を確認します:
- 予約スクレイパーの定義
- – スクレイパーで抽出可能なデータ
- PythonでBooking.comスクレイピングスクリプトを構築する方法
さあ、始めましょう!
Bookingスクレイパーとは?
Booking.comスクレイパーとは、Booking.comのページから自動的にデータを抽出するツールです。これにより、宿泊施設の詳細ページからホテル名、価格、口コミ、評価、設備、空室状況などの情報を取得できます。このデータは、市場分析、価格比較、旅行関連データセットの構築など、様々な目的に利用可能です。
Booking.comからスクレイピング可能なデータ
以下は、Booking.comから取得可能なデータポイントのリストです:
- 施設詳細:ホテル名、住所、ランドマークからの距離(例:都心部、ダウンタウンなど)
- 価格情報:通常価格、割引価格(利用可能な場合)
- レビューと評価:レビュースコア、レビュー数、ゲストのフィードバック
- 空室状況:利用可能な客室タイプ、予約オプション(例:無料キャンセル、朝食付き)、空室のある日付
- メディア:施設画像、客室画像
- 設備:提供施設(例:Wi-Fi、駐車場、プール)、客室固有のアメニティ
- プロモーション:特別オファーや割引、期間限定キャンペーン
- ポリシー:キャンセル規定、チェックイン・チェックアウト時間
- 追加情報:施設説明、近隣の観光スポット、特定日程の空室数
PythonでBooking.comをスクレイピングする:ステップバイステップガイド
このガイドセクションでは、Booking.comスクレイパーの構築方法を学びます。
目的は、宿泊施設リストページから自動的にデータを収集するPythonスクリプトを作成することです:
以下の手順に従ってください!
ステップ #1: プロジェクト設定
開始前に、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ダウンロードし、実行ファイルを起動してインストールウィザードに従ってください。
次に、以下のコマンドを使用してプロジェクト用フォルダを作成します:
mkdir booking-スクレイパー
booking-scraperディレクトリは、Python Booking.comスクレイパースクリプトのプロジェクトフォルダです。
その中に入り、仮想環境を初期化します:
cd booking-スクレイパー
python -m venv env
お好みのPython IDEでプロジェクトフォルダを読み込みます。Python拡張機能付きのVisual Studio Code やPyCharm Community Editionが優れた選択肢です。
プロジェクトフォルダ内にスクレイパー.pyファイルを作成します。ファイル構造は以下の通りです:
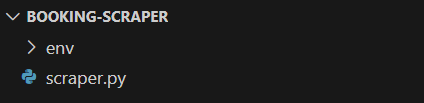
scraper.py は現時点では空の Python スクリプトですが、まもなくスクレイピングロジックが記述されます。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは、次のコマンドを実行してください:
./env/bin/activate
Windowsでは同等の操作として以下を実行します:
env/Scripts/activate
これでウェブスクレイピング用のPython環境が整いました!
ステップ #2: スクラッピングライブラリの選択
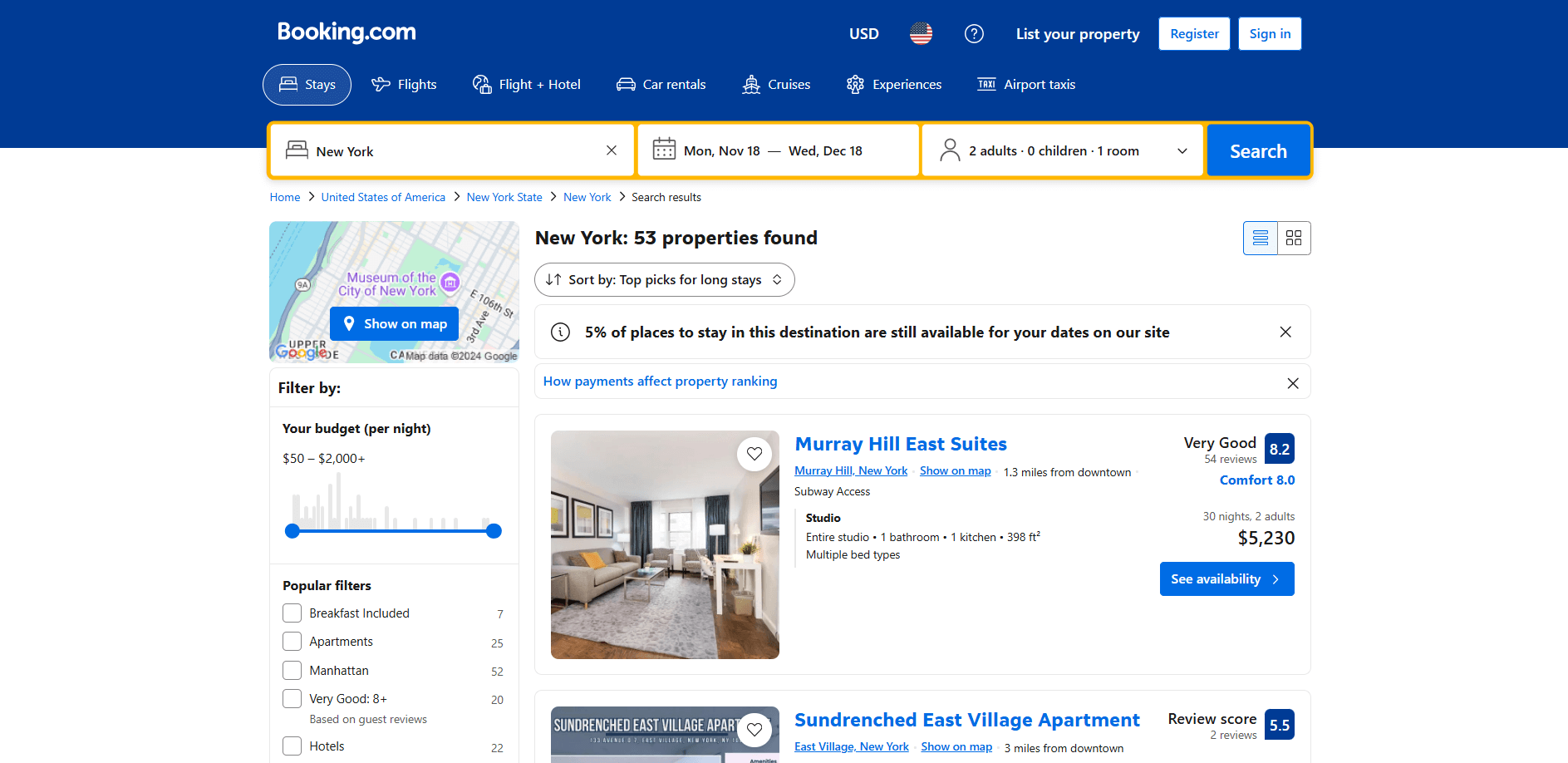
Booking.comが静的サイトか動的サイトかを判断し、それに応じて適切なスクレイピングライブラリを選択します。サイトの動作を調査することで判断できます。まずブラウザでBooking.comを開きます。検索を実行し、宿泊施設のページに移動してください:
ページをスクロールすると、新しいデータが動的に読み込まれることに気づくでしょう:
このパターンは無限スクロールとして知られ、動的サイトの特徴です。動的サイトでのウェブスクレイピング手法について詳しく学びましょう。
サーバーから返されるドキュメントのHTMLコードを解析したり、開発者ツールのネットワークタブを確認したり(サイトの静的/動的判断で一般的な手順)しなくても、Booking.comが動的サイトであることは既に結論付けられます。
動的コンテンツサイトのスクレイピングに最適なアプローチは、ブラウザ自動化ツールの使用です。これらのソリューションにより、ブラウザを制御し、ページ上で特定の操作を実行してデータを効率的に抽出できます。
Python向けの最も強力なブラウザ自動化ツールの一つがSeleniumであり、Booking.comのスクレイピングに最適です。このタスクの主要ライブラリとなるため、インストール準備を整えましょう!
ステップ #3: Selenium のインストールと設定
Pythonでは、Seleniumはselenium pipパッケージを通じて利用可能です。アクティブなPython仮想環境内で、以下のコマンドでインストールしてください:
pip install selenium
ツールの使用方法については、Seleniumを用いたウェブスクレイピングチュートリアルを参照してください。
scraper.pyでSeleniumをインポートし、Chromeインスタンスを制御するWebDriverオブジェクトを初期化します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service())
上記のコードはChromeブラウザを制御 するChromeWebDriverインスタンスを初期化します。Booking.comはヘッドレスブラウザをブロックする反スクレイピング技術を使用しているようです。そのため、--headlessフラグの設定は避けてください。代替ソリューションとして、Playwright Stealthに関するガイドを参照してください。
スクレイパーの最終行では、必ずWebDriverを閉じることを忘れないでください:
driver.quit()
素晴らしい!これでBooking.comのスクラッピングを開始する準備が整いました。
ステップ #4: 対象ページにアクセス
Booking.comのページには、検索を絞り込むための数多くのインタラクティブ機能があります:
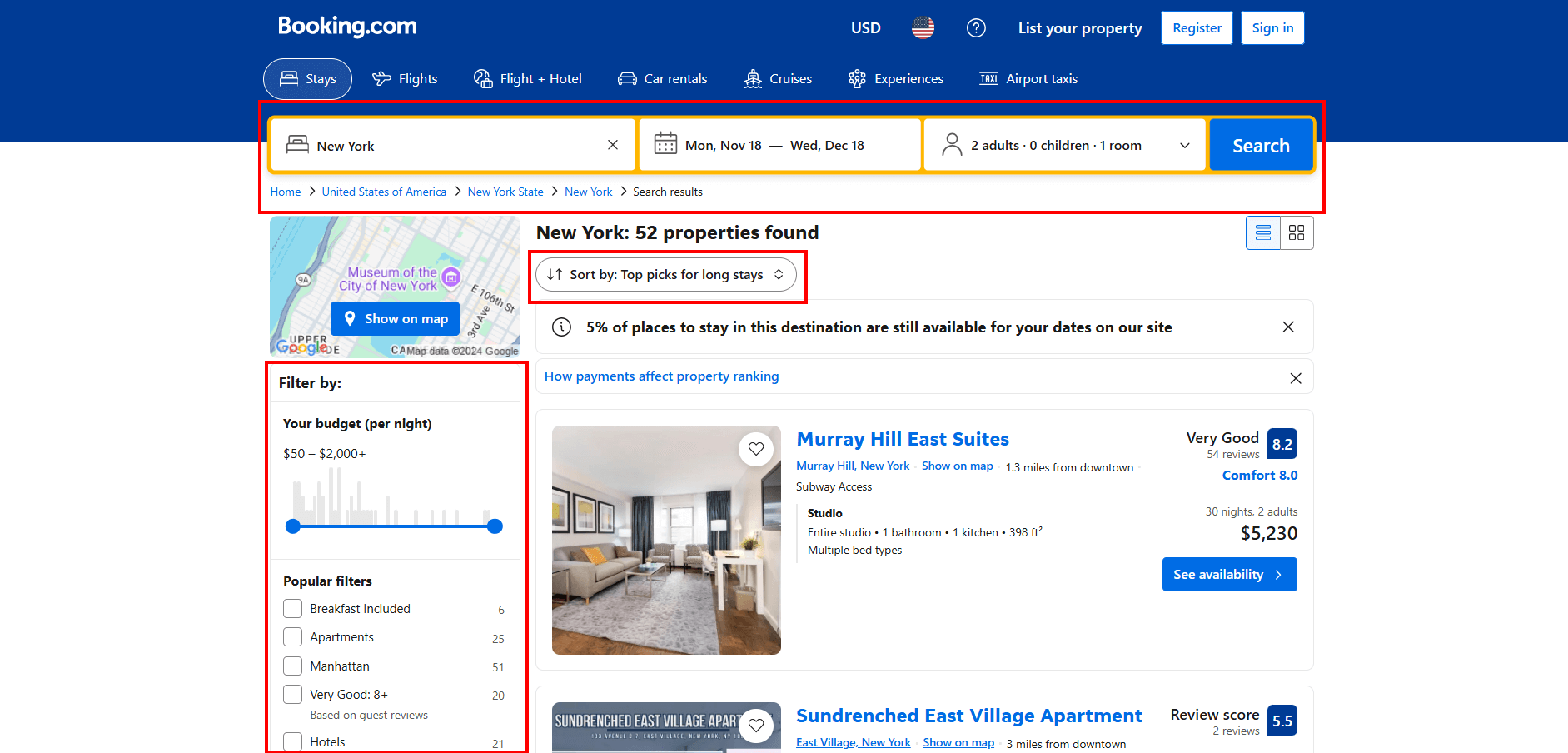
Seleniumでこれら全ての操作をプログラムでシミュレートするのは複雑で時間がかかります。そのため、簡略化とスピードアップのために、まずブラウザ上で手動で操作を行ってください。
関心のある検索クエリを設定したら、ブラウザのアドレスバーから結果ページのURLをコピーします。
例えば、上記のURLは「11月18日から12月18日までのニューヨークのアパートメント、大人2名」の検索を表しています。
このURLをコピーし、Seleniumのget()メソッドに渡しします:
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
スクレイピングスクリプトは自動的に目的のBooking.comページに接続します。
scraper.pyファイルには以下のコードが含まれます:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service())
# 対象ページに接続
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# スクラッピングロジック...
# WebDriverを終了しリソースを解放
driver.quit()
最終行にデバッグブレークポイントを設定し、スクリプトを実行します。以下が表示されるはずです:
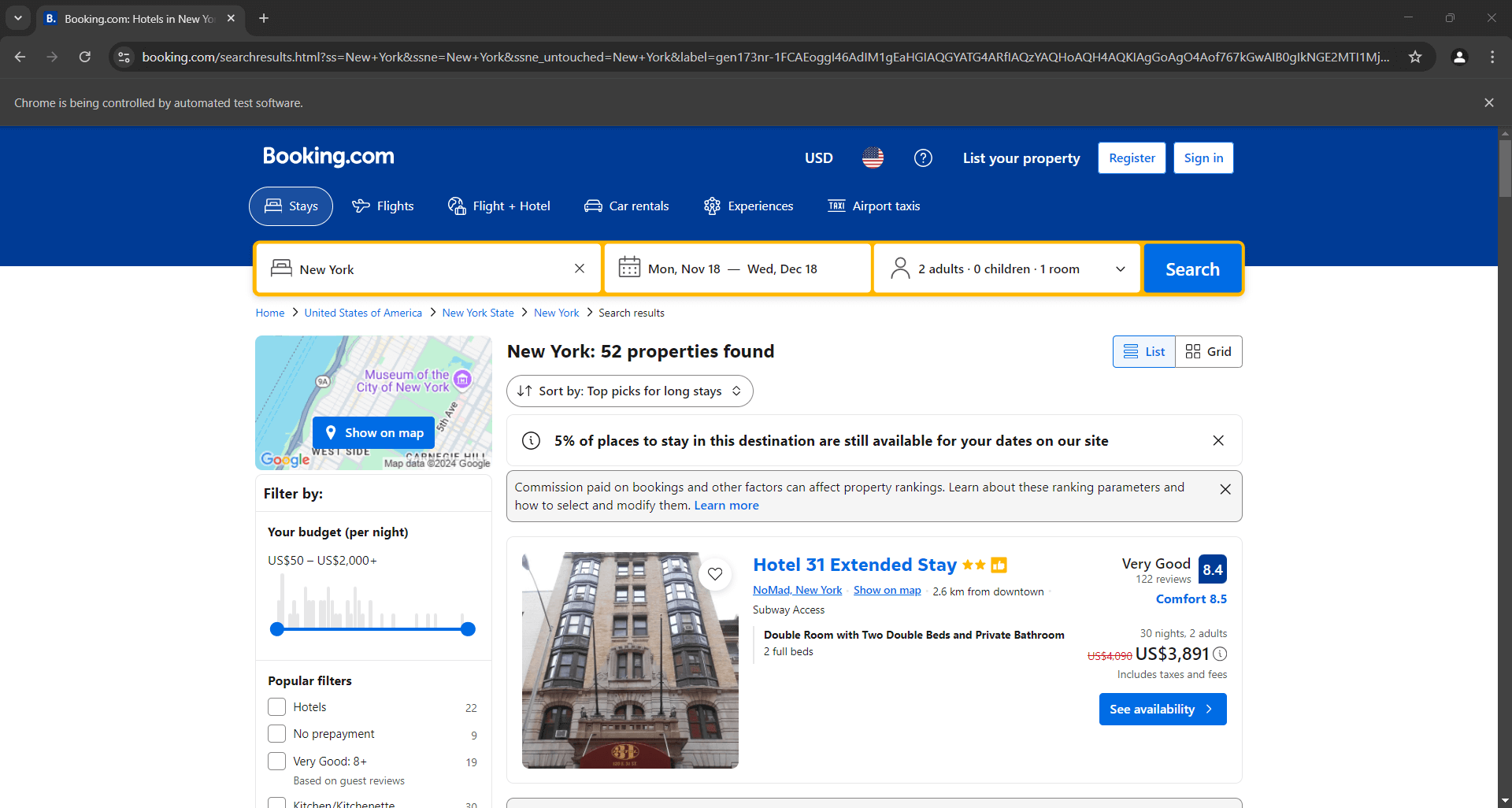
「Chrome は自動テストソフトウェアによって制御されています。」というメッセージは、Selenium が意図した通り Chrome 上で動作していることを確認します。よくできました!
ステップ #5: ログインアラートの処理
ブラウザでBooking.comを初めて訪問すると、20秒以内にログインアラートが表示されることがよくあります。これによりページコンテンツへのアクセスがブロックされ、ウェブスクレイピングが困難になります:
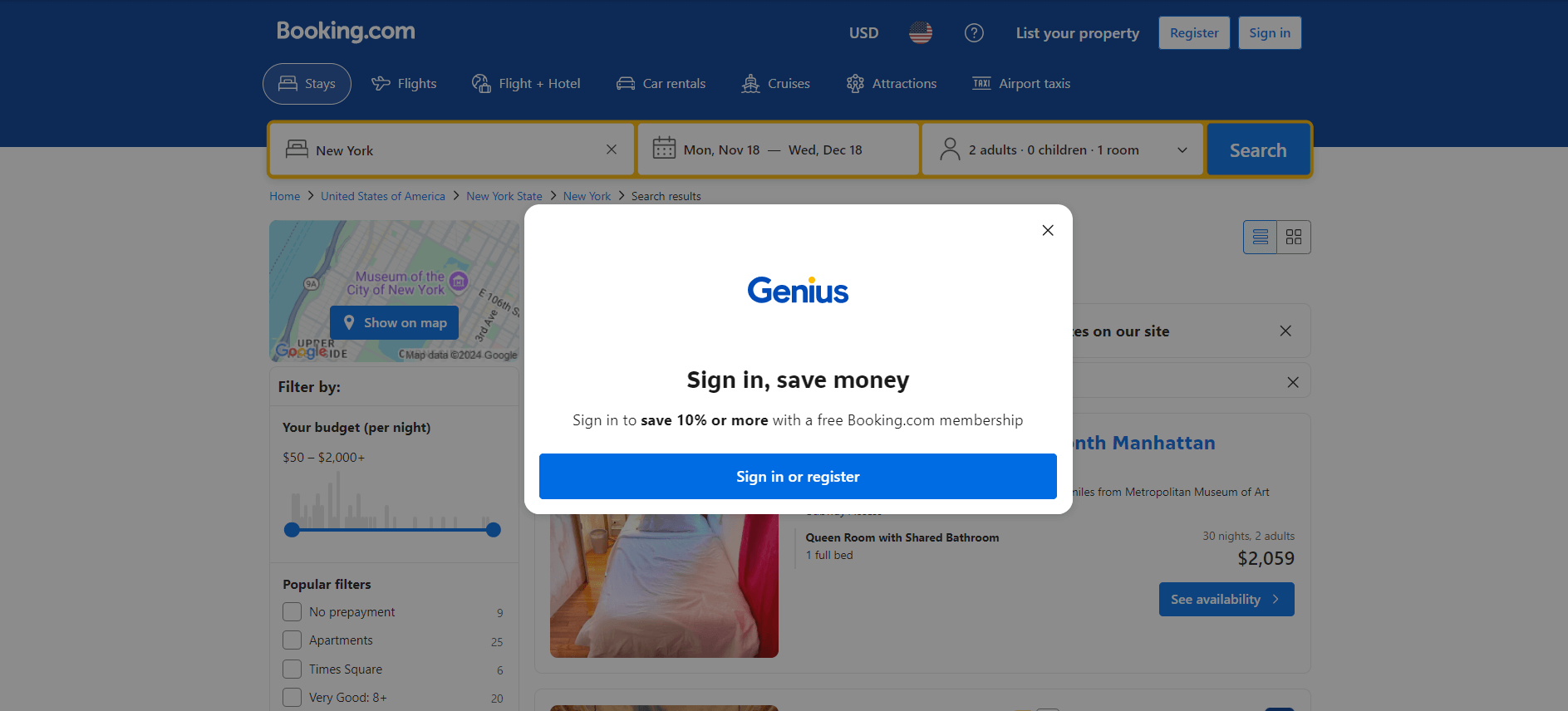
このアラートを操作するまで、下層ページのコンテンツにアクセスできません。
このアラートに対処するには、Seleniumで閉じます。閉じるボタンを右クリックし、コンテキストメニューから「Inspect」オプションを選択します:
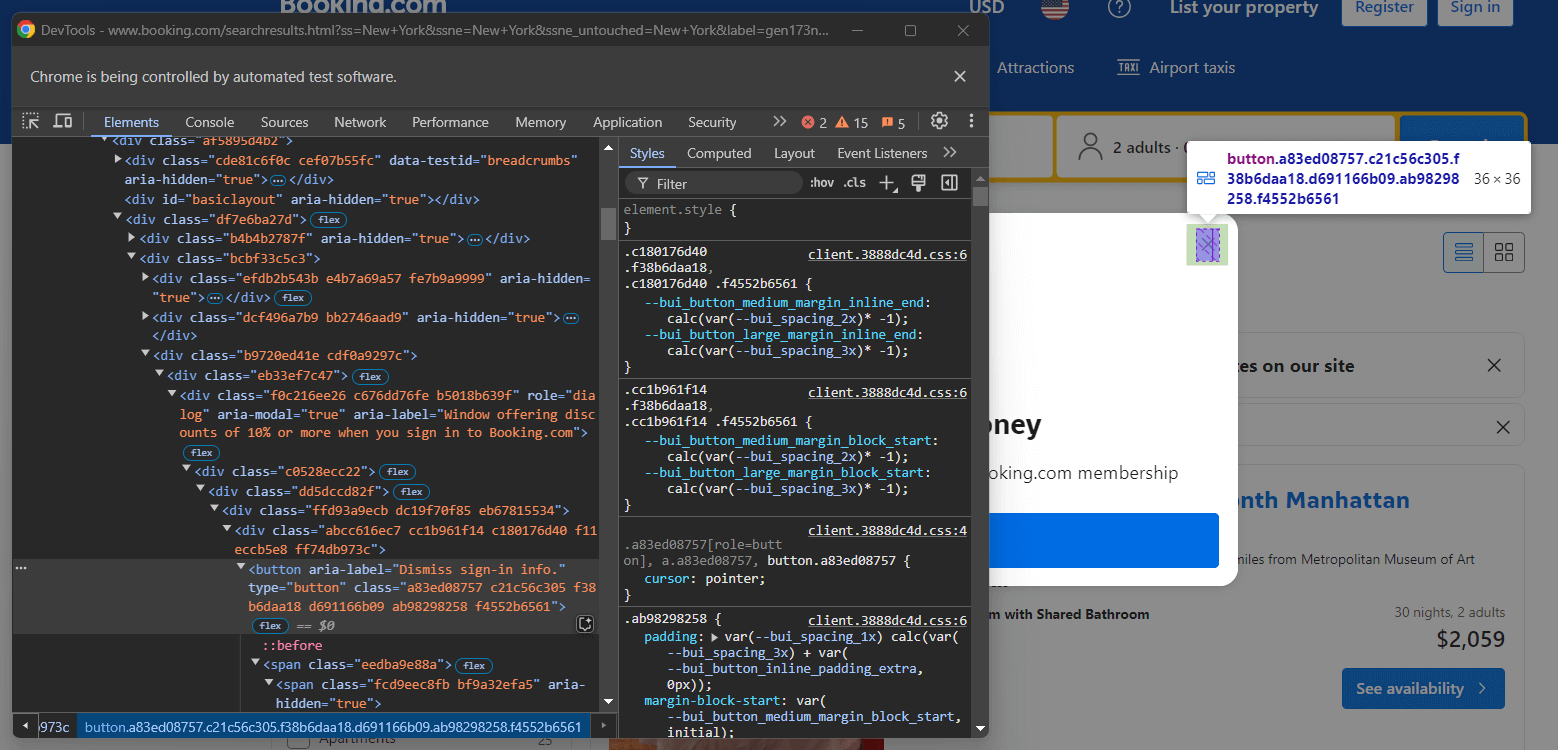
以下のCSSセレクターでボタンを選択するとモーダルを閉じられます:
[role="dialog"] button[aria-label="Dismiss sign-in info."]
次に、アラートが表示されるまで最大10秒待機するようSeleniumに指示します。表示されたら、閉じるボタンをクリックして閉じます。モーダルが常に表示されるとは限らないため、このロジックをtry...exceptブロックで囲むのが適切です:
try:
# サインインアラートが表示されるまで最大20秒待機
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# 閉じるボタンをクリック
close_button.click()
except TimeoutException:
print("サインインモーダルが表示されませんでした。続行します...")
WebDriverWaitは、ページ上の指定条件が満たされるまでスクリプトを一時停止するSeleniumの特殊クラスです。上記の例では、アラートの閉じるボタンがページ上に表示されるまで最大10秒待機します。
アラートが表示されない場合、SeleniumはTimeoutException例外を発生させます。以下のようにWebDriverWait、EC、Byと共にインポートしてください:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
素晴らしい!ログインアラートはもはや問題ではありません。
ステップ #6: Booking.com のアイテムを選択
スクレイピング対象のBooking.comページには複数のアイテムが含まれています。これら全てをスクレイピングするため、取得データを格納する配列を初期化します:
items = []
次に、これらのアイテムに関連する HTML 要素の選択方法を理解する必要があります。ブラウザで Booking.com を開き、検索を実行して、プロパティアイテムの 1 つを検査します:
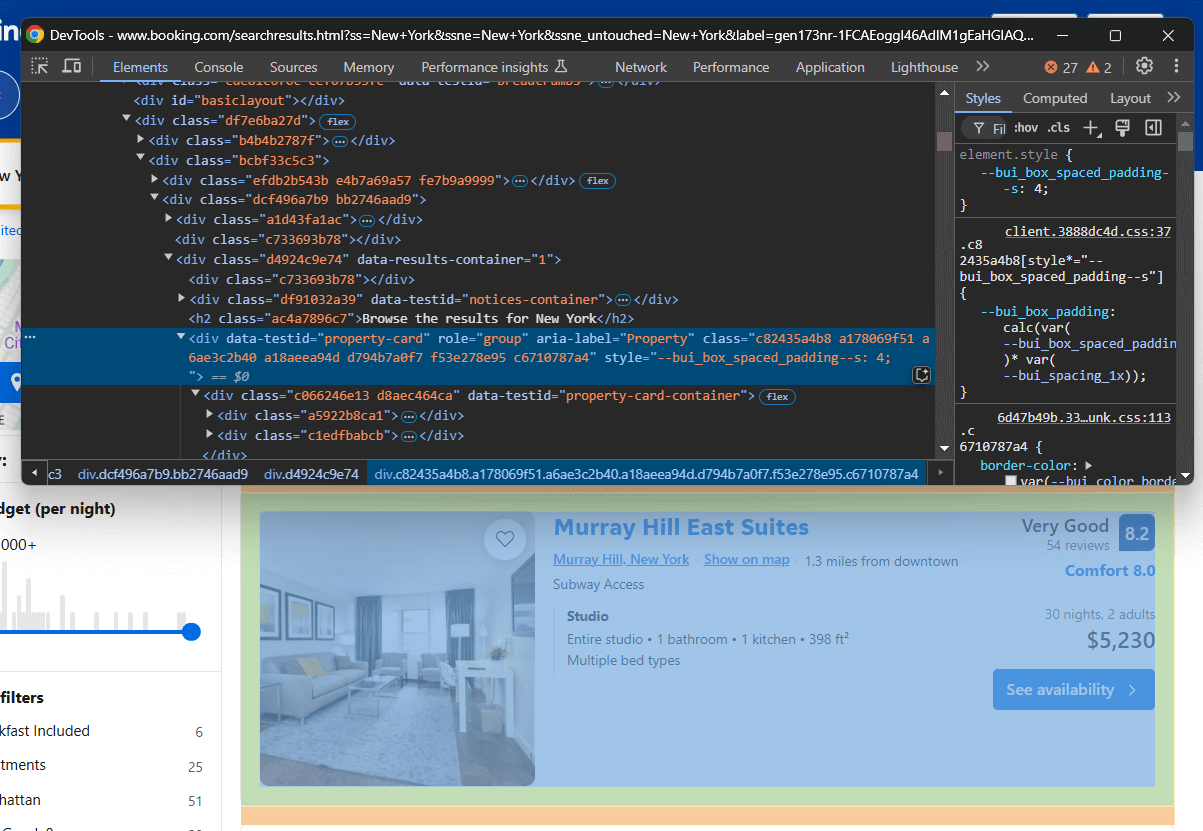
HTML要素のクラスはランダムに生成されているように見えます。これはサイトデプロイのたびに変更される可能性が高く、要素選択には信頼性が低いことを意味します。代わりに、data-testidのようなより安定した属性に焦点を当てましょう。
data-*属性はウェブスクレイピングの優れたターゲットです。
Seleniumのfind_elements()メソッドを使用して、ページ上でCSSセレクタを適用し、目的の要素を選択します:
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
プロパティ項目を反復処理し、Booking.comスクレイパーでデータを抽出する準備をします:
for property_item in property_items:
# スクラッピングロジック...
素晴らしい!次のステップはこれらの要素からデータをスクレイピングすることです。
ステップ #7: Booking.comアイテムのスクレイピング
ページ上のプロパティ項目を確認すると、含まれる要素に一貫性がないことに気づくでしょう:
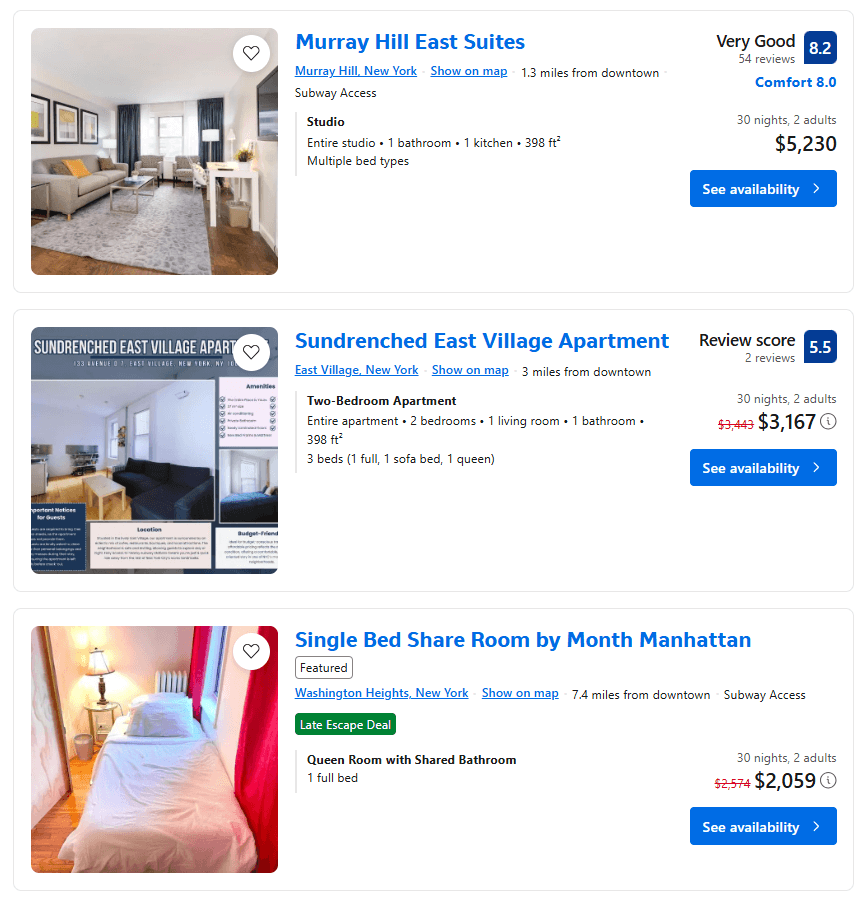
レビュースコアがあるアイテムもあれば、ないアイテムもあります。同様に、割引価格が表示されているアイテムもあれば、ないアイテムもあります。
こうした差異により、全ての物件アイテムに対して一貫したスクレイピングロジックを記述するのは困難です。ページ上に存在しない要素を選択しようとすると、SeleniumはNoSuchElementExceptionを発生させます。したがって、このシナリオを処理する関数を定義するのが合理的です:
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
上記の関数はラムダ関数を受け取り、実行を試みます。NoSuchElementExceptionが発生した場合、例外をキャッチしてNoneを返します。これにより、Booking.comスクレイピングスクリプトは中断せずに継続できます。
NoSuchElementException のインポート:
from selenium.common import NoSuchElementException
すべての要素(レビュースコア、割引価格など)を含むプロパティ項目を検査します:
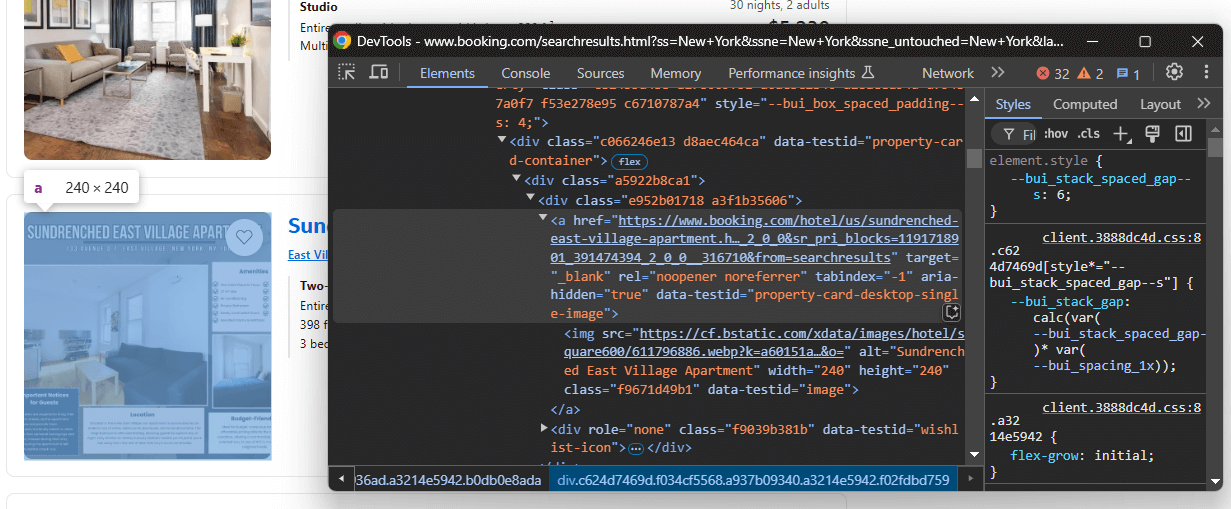
抽出可能な要素:
a[data-testid="property-card-desktop-single-image"]から物件リンクを抽出- プロパティ画像:
img[data-testid=image]
forループ内で、現在のロジックを適用してそれらの要素を選択し、そこからデータを抽出します:
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
find_element() はページ上の単一ノードを選択し、get_attribute() は指定された HTML 属性内のコンテンツを取得します。データ抽出の指示は、NoSuchElementException を処理するためにhandle_no_such_element_exception でラップされていることに注意してください。
同様に、タイトルセクションとその直下の情報に注目してください:
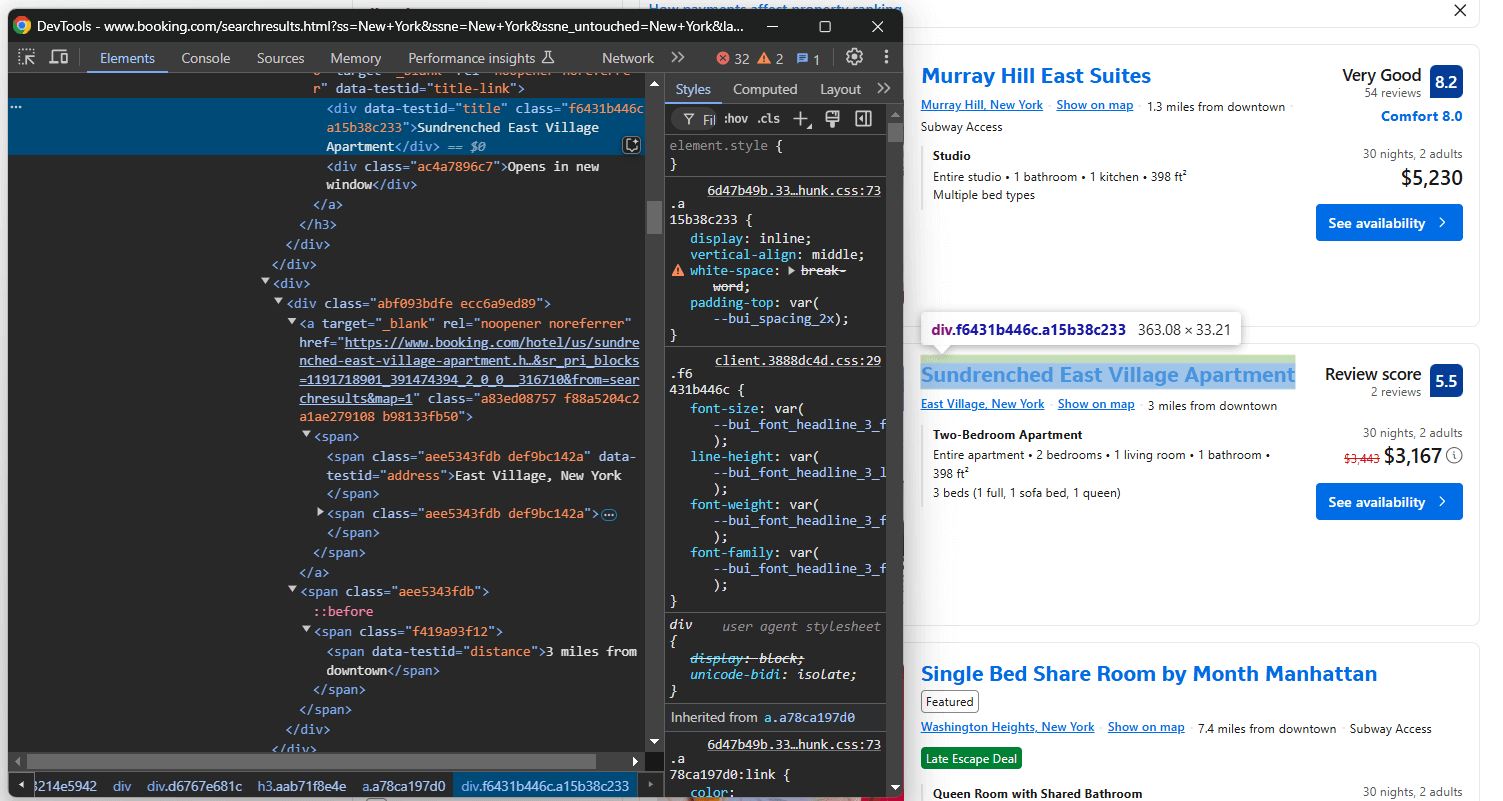
ここでは以下を取得できます:
[data-testid="title"]から物件タイトルを取得[data-testid="address"]からaddressプロパティ[data-testid="distance"]からdistanceプロパティ
これらすべてをスクレイピングするには:
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
text属性は選択された要素内のテキストを含みます。
次に、レビュースコアノードに焦点を当てます:
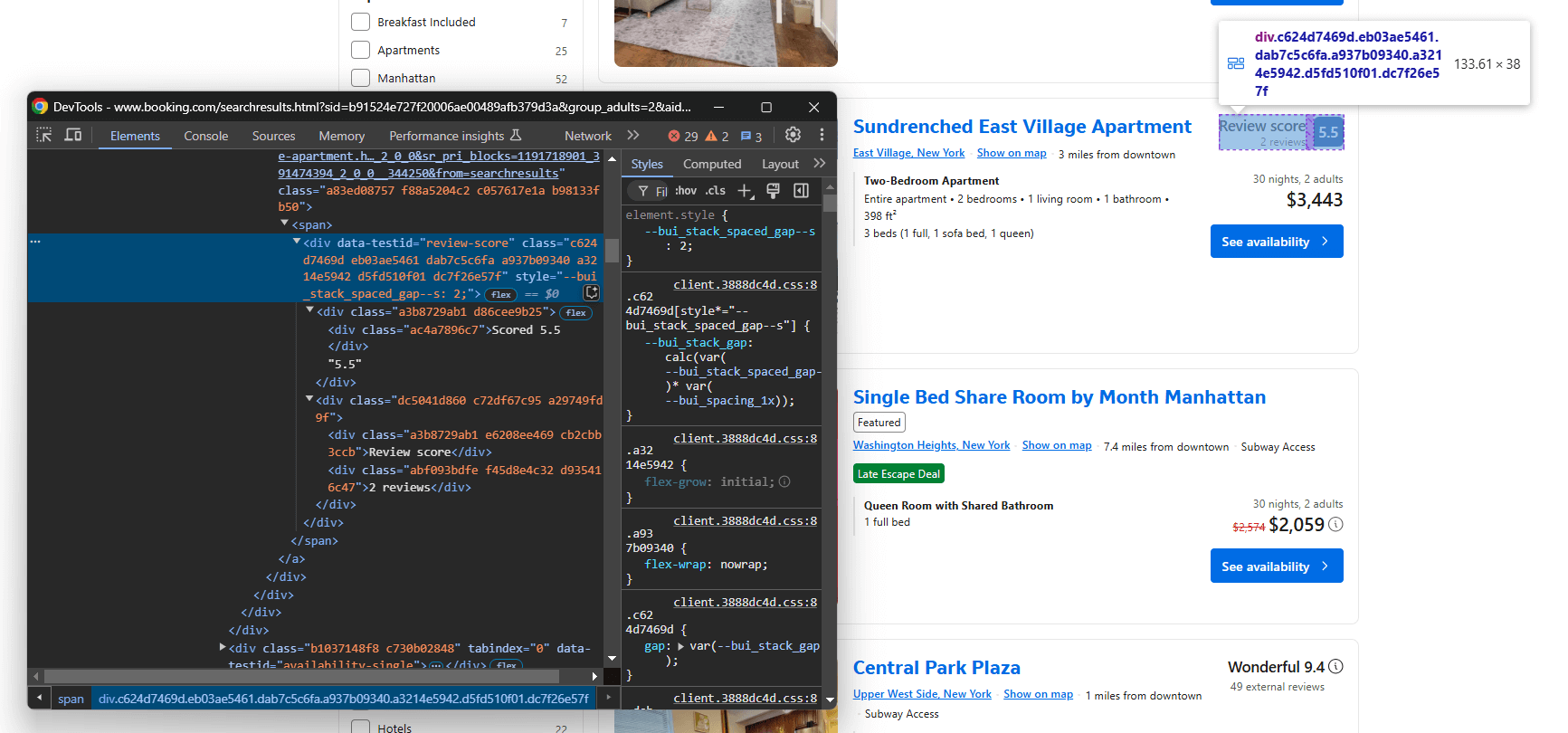
data-testid="review-score" で選択し、テキストを抽出します。テキストは特別な形式を持つことに注意してください。例:
'Scored 8.4n8.4nVery Goodn120 reviews'
カスタムロジックを用いて、レビュースコアとレビュー件数を抽出できます:
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# レビュー文字列を改行で分割
parts = review_text.split("n")
# 各部分を処理
for part in parts:
part = part.strip()
# 数値(レビュースコア候補)かどうか確認
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# "reviews" 文字列を含むか確認
elif "reviews" in part:
# "reviews" の前の数字を抽出
review_count = int(part.split(" ")[0].replace(",", ""))
説明要素をターゲットにする:
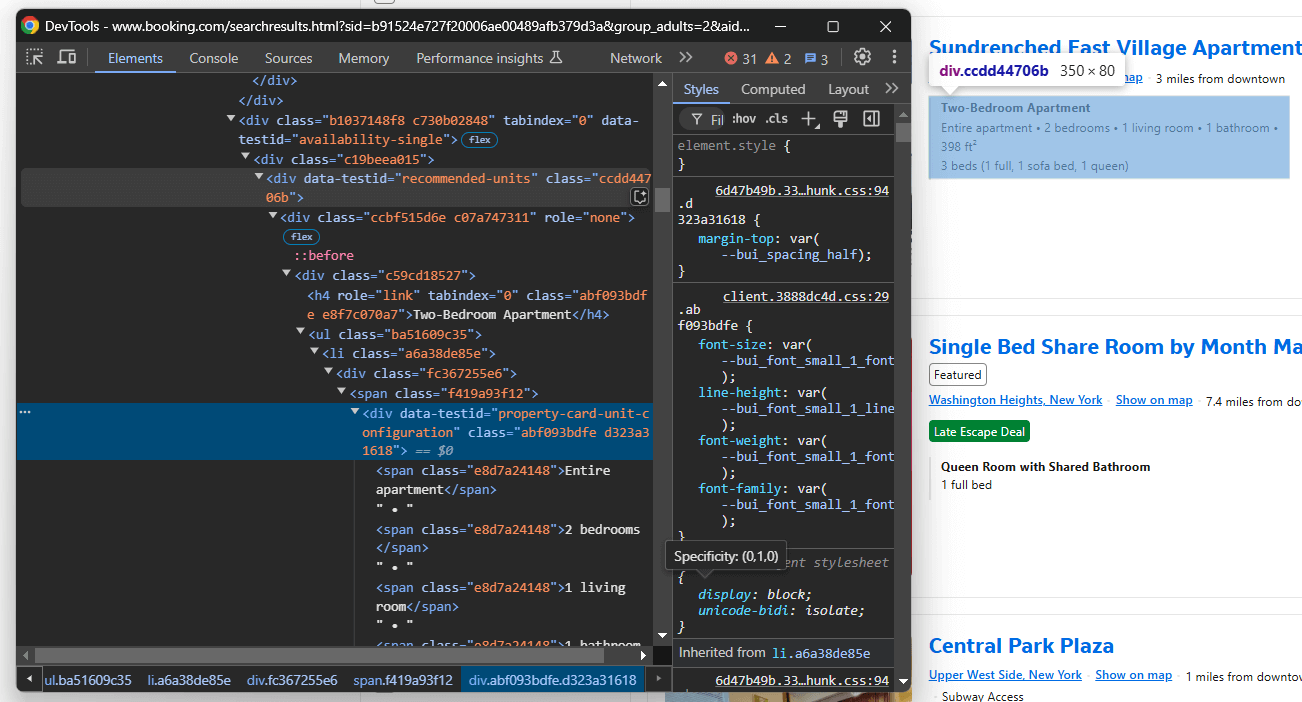
data-testid="recommended-units" で選択し、説明文をスクレイピング:
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
最後に、価格要素に焦点を当てる:
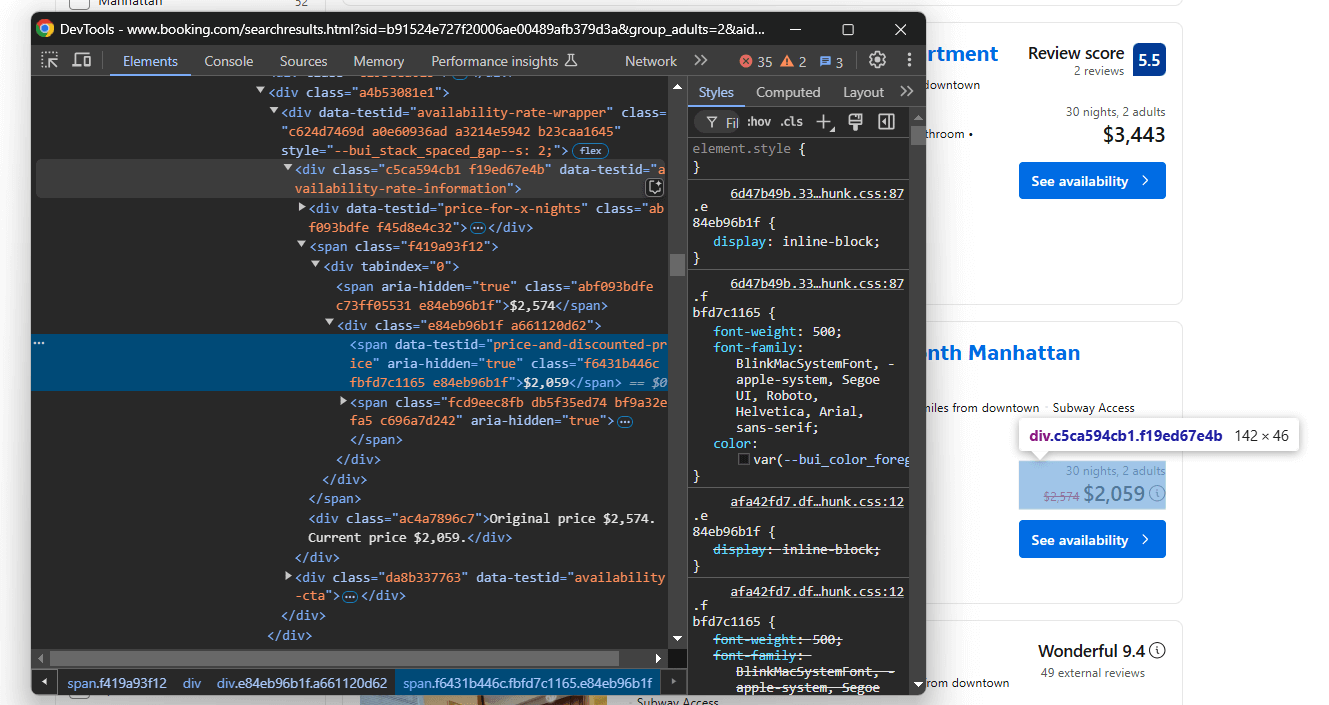
data-testid="availability-rate-information" 要素から選択:
aria-hidden="true"属性を持ち、data-testid属性を有さないノードから元の価格を取得data-testid="price-and-discounted-price"属性を持つ要素から割引/現在の価格を取得
価格抽出ロジックを以下のように記述します:
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
すごい!Booking.comのスクラッピングロジックがほぼ完成しました。
ステップ #7: スクレイピングしたデータの収集
forループ内で複数の変数に分散したスクレイピングデータを取得しました。新しいitemオブジェクトを作成し、そのデータで初期化してitems配列に追加します:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"description": description,
"original_price": original_price,
"price": price
}
items.append(item)
forループの終了時点で、itemsにはスクレイピングした全データが含まれます。itemsを出力して確認してください:
print(items)
これにより、以下のような出力が得られます:
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'マレーヒル イースト スイーツ', 'address': 'マレーヒル, ニューヨーク', 'distance': 'ダウンタウンから1.3マイル', 'review_score': 8.2, 'review_count': 54, 'description': 'スタジオタイプ • バスルーム1室 • キッチン1室 • 398平方フィートnベッドタイプ複数', 'original_price': None, 'price': '$5230'},
# 簡略化のため省略...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': 'Manhattan, New York', 'distance': 'ダウンタウンから0.6マイル', 'review_score': 8.4, 'review_count': 2209, 'description': 'キングルーム(キングサイズベッド1台)', 'original_price': '$20060', 'price': '$18054'}]
素晴らしい!あとはこの情報をCSVのような人間が読める形式のファイルにエクスポートするだけです。
ステップ #8: CSV へのエクスポート
Python標準ライブラリのcsvパッケージをインポートします:
import csv
次に、このパッケージを使ってアイテムをCSVファイルにエクスポートします:
# 出力CSVファイル名を指定
output_file = "properties.csv"
# アイテムリストをCSVファイルにエクスポート
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
# CSVライターオブジェクトを作成
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# ヘッダー行を書き込む
writer.writeheader()
# 各アイテムをCSVの行として書き込む
writer.writerows(items)
このスニペットは、items配列のデータを使用してproperties.csvという名前のCSVファイルを生成します。上記で使用されている主な関数は以下の通りです:
open(): 指定したファイルをUTF-8エンコーディングで書き込みモードで開く。csv.DictWriter():指定されたフィールド名でCSVライターを作成します。writeheader(): 指定されたフィールド名に基づいてCSVファイルにヘッダー行を書き込みます。writer.writerow(): 各辞書項目をCSVの行として書き込む。
ステップ #9: 全てを統合する
scraper.pyには以下の行が含まれるはずです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service())
# 対象ページへの接続
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# サインインアラートの処理
try:
# サインインアラートが表示されるまで最大20秒待機
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# 閉じるボタンをクリック
close_button.click()
except e:
print("サインインモーダルが表示されませんでした、続行します...")
# スクレイピングしたデータの保存先
items = []
# ページ上の全物件アイテムを選択
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# 物件アイテムを反復処理し
# データを抽出
for property_item in property_items:
# スクレイピングロジック...
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# レビュー文字列を改行で分割
parts = review_text.split("n")
# 各部分を処理
for part in parts:
part = part.strip()
# この部分が数値(潜在的なレビュースコア)かどうかを確認
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# "reviews" 文字列を含むかどうかを確認
elif "reviews" in part:
# "reviews"前の数値を抽出
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
# スクレイピングしたデータで新しいアイテムを生成
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"decription": decription,
"original_price": original_price,
"price": price
}
# 新規アイテムをスクレイピング済みアイテムリストに追加
items.append(item)
# 出力CSVファイルの名前を指定
output_file = "properties.csv"
# アイテムリストをCSVファイルにエクスポート
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
# CSVライターオブジェクトを作成
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# ヘッダー行を書き込む
writer.writeheader()
# 各アイテムをCSVの行として書き込む
writer.writerows(items)
# WebDriverを閉じ、リソースを解放する
driver.quit()
信じられますか?わずか110行ほどで、PythonのBooking.comスクレイパーを構築しました。
動作確認のため、スクレイピングスクリプトを実行してください。Windowsでは以下のコマンドでスクレイパーを実行します:
python スクレイパー.py
同様に、LinuxまたはmacOSでは以下を実行します:
python3 スクレイパー.py
スクリプトの実行が完了するまで待ちます。プロジェクトのルートディレクトリにproperties.csvファイルが生成されます。ファイルを開いて抽出されたデータを確認してください:
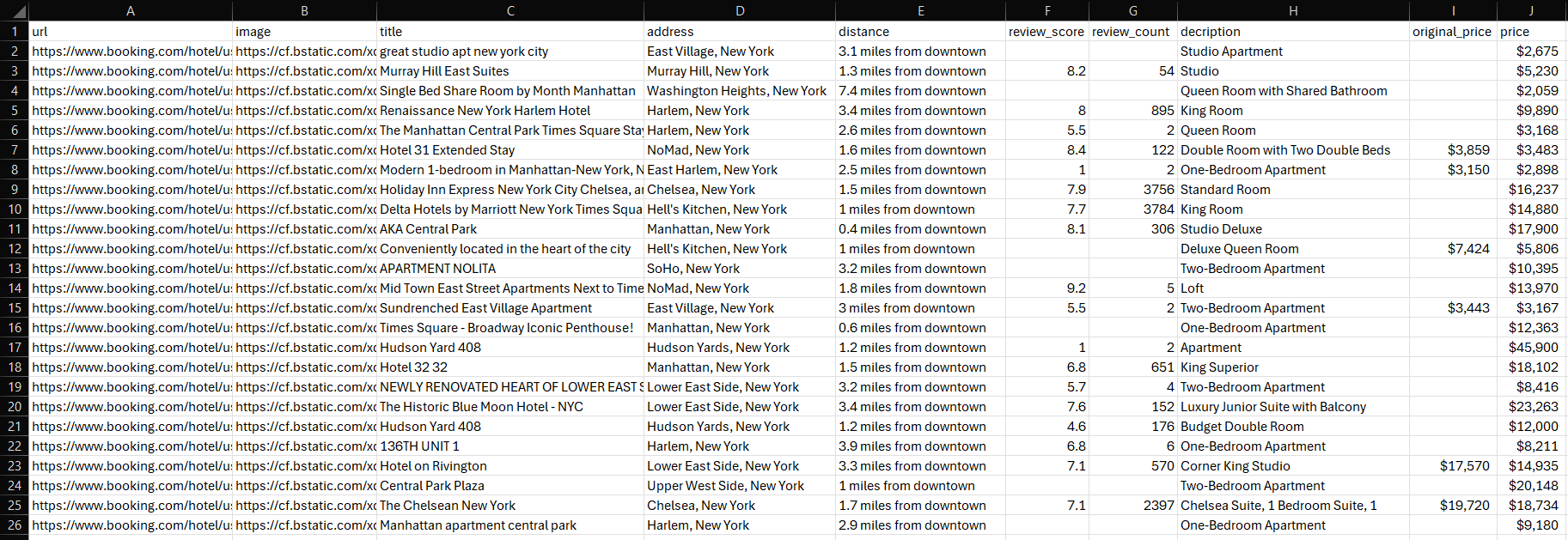
おめでとうございます、ミッション完了です!
まとめ
このチュートリアルでは、Booking.comスクレイパーの概念とPythonを用いた構築方法を学びました。示した通り、Booking.comからデータを自動取得する基本スクリプトの作成には、わずか数行のコードで十分です。
ただし、ここで紹介した例では、Booking.comのスクレイピングで遭遇する可能性のある多くの課題には対応していません。アンチヘッドレスブラウザ対策、検索結果生成のためのユーザー操作の処理、無限スクロールへの対応といった問題は、スクレイピング作業を急速に複雑化させます。
より簡単で、フル機能を備えた強力なスクレイパーソリューションをお探しですか?Bright DataのBooking Scraper APIをお試しください!
BookingスクレイパーAPIは、公開されているホテルデータ、レビュー、評価などをスクレイピングするための強力なエンドポイントを提供します。シンプルなAPI呼び出しで、データをJSONまたはHTML形式で取得できます。
既成ソリューションをお求めですか?BrightDataではBooking.comデータセットも提供中です!
今すぐBright Dataの無料アカウントを作成し、スクレイパーAPIをお試しいただくか、データセットをご覧ください。






