

この記事では、以下の内容をご紹介します:
- Bright DataがDatabricks上で提供する製品
- – Databricksアカウントの設定方法と、プログラムによるデータ取得・探索に必要な全認証情報の取得方法
- Databricksのを使用してBright Dataデータセットをクエリする方法
- REST API
- CLI
- SQLコネクタ
さあ、始めましょう!
Databricks上のBright Dataのデータ製品
Databricksは、エンタープライズグレードのデータ、アナリティクス、AIソリューションを大規模に構築、デプロイ、共有、維持するためのオープンなアナリティクスプラットフォームです。ウェブサイトでは複数のプロバイダーのデータ製品を見つけることができ、これが最高のデータマーケットプレイスの1つと見なされる理由です。
Bright Dataは最近、データ製品プロバイダーとしてDatabricksに参画し、すでに40以上の製品を提供しています:
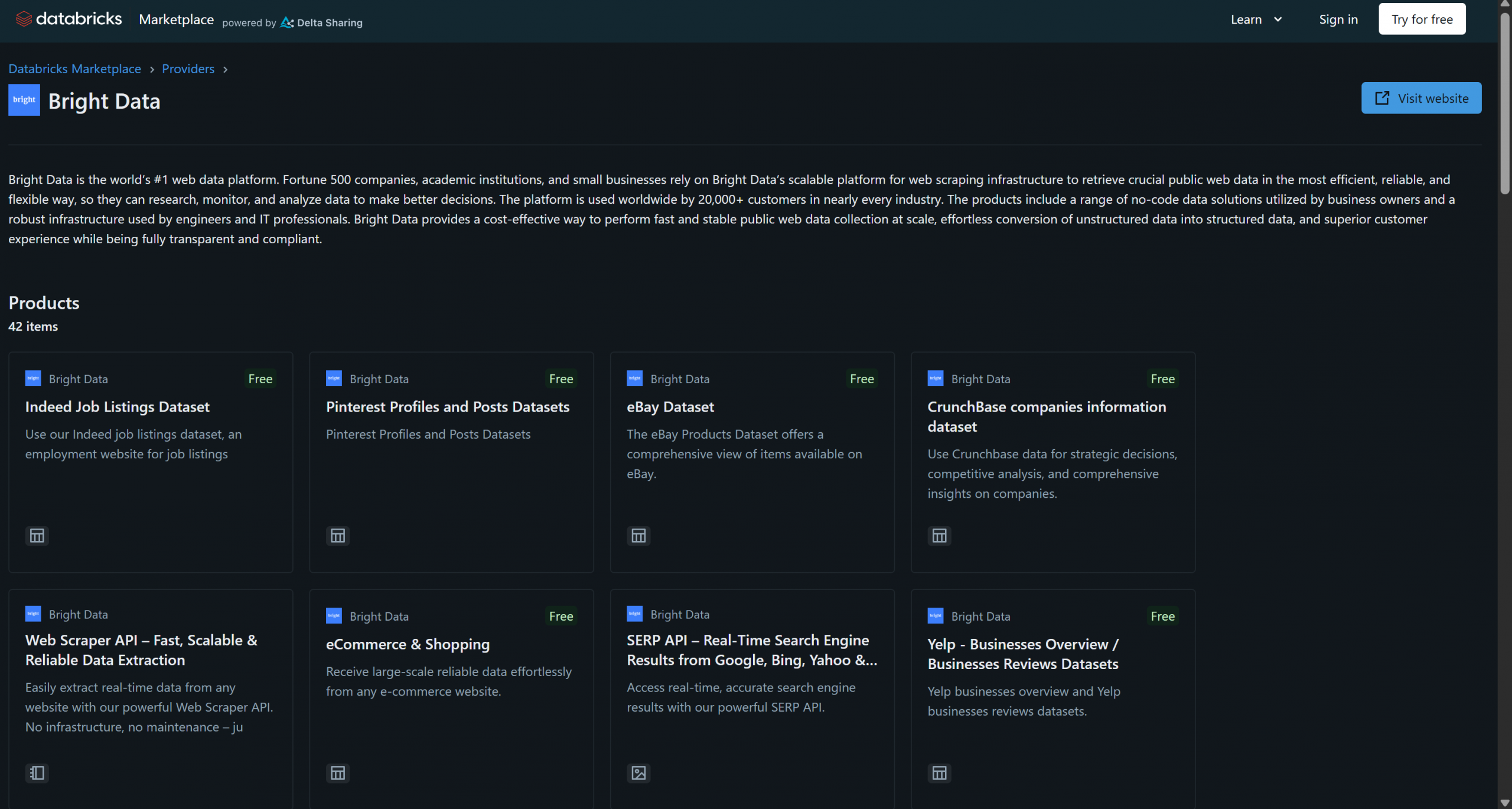
これらのソリューションには、B2Bデータセット、企業データセット、金融データセット、不動産データセットなどが含まれます。さらに、スクレイピングブラウザや Web Scraper APIなど、Bright Dataのインフラを通じて、より一般的なウェブデータ取得やウェブスクレイピングソリューションにもアクセスできます。
このチュートリアルでは、Databricks API、CLI、専用SQLコネクタライブラリを使用して、これらのBright Dataデータセットのいずれかからプログラム的にデータをクエリする方法を学びます。さっそく始めましょう!
Databricks の開始
APIまたはCLI経由でDatabricksからBright Dataデータセットをクエリするには、まずいくつかの設定が必要です。以下の手順に従ってDatabricksアカウントを設定し、Bright Dataデータセットへのアクセスと統合に必要なすべての認証情報を取得してください。
このセクションの終わりまでに、以下の準備が整います:
- 設定済みのDatabricksアカウント
- Databricksアクセストークン
- Databricks ウェアハウス ID
- Databricksホスト文字列
- Databricksアカウント内の1つ以上のBright Dataデータセットへのアクセス権
前提条件
まず、Databricksアカウント(無料アカウントで十分です)をお持ちであることを確認してください。お持ちでない場合はアカウントを作成してください。お持ちの場合は、ログインしてください。
Databricksアクセストークンの設定
Databricksリソースへのアクセスを許可するには、アクセストークンが必要です。以下の手順に従って設定してください。
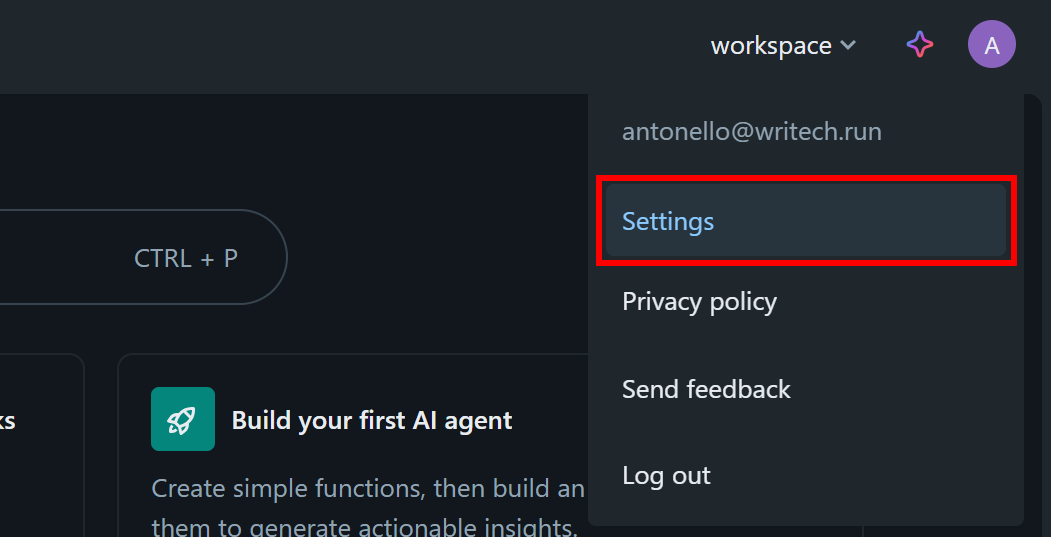
Databricksダッシュボードでプロフィール画像をクリックし、「設定」オプションを選択します:
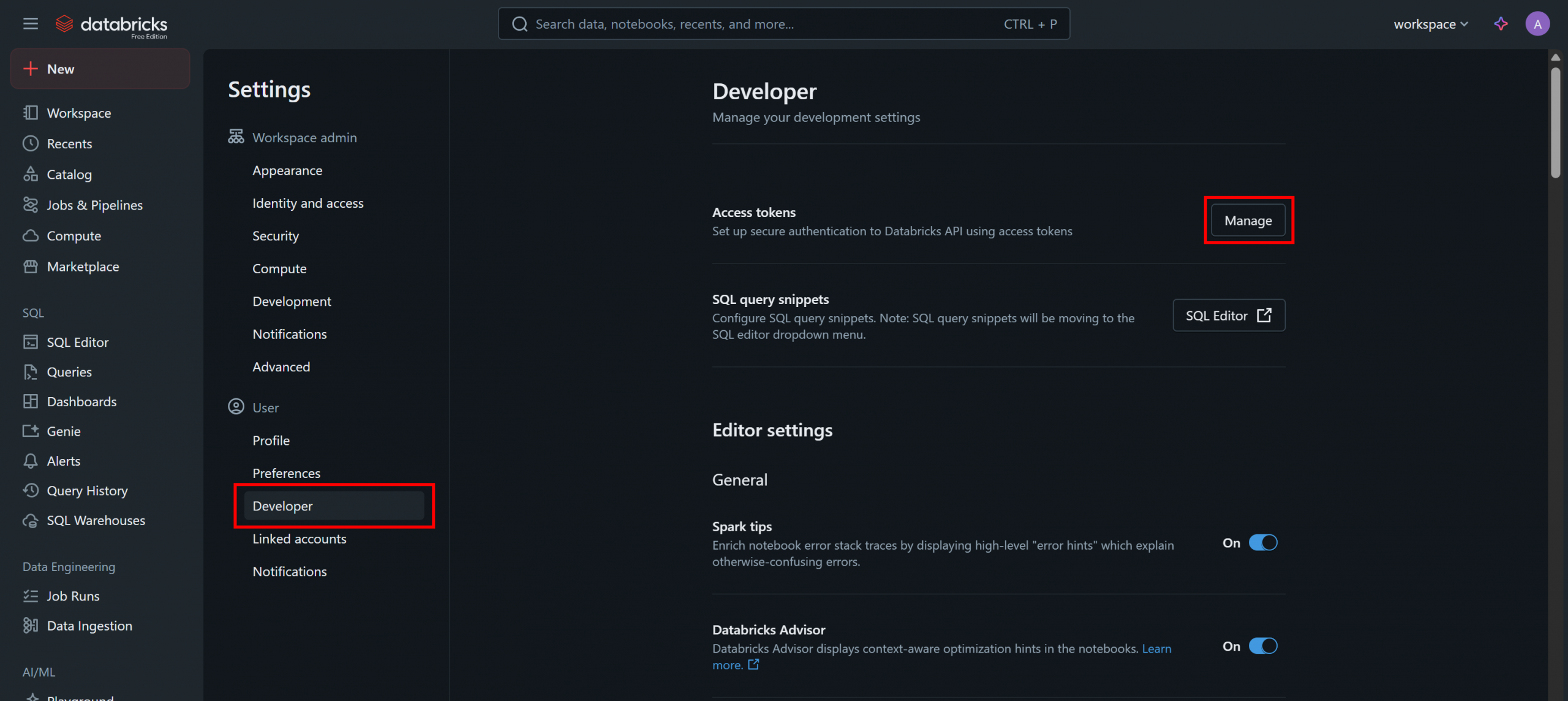
「設定」ページで「開発者」オプションを選択し、「アクセストークン」セクションの「管理」ボタンをクリックします:
「アクセストークン」ページで「新しいトークンを生成」をクリックし、モーダル内の指示に従ってください:
Databricks API アクセストークンが発行されます。すぐに必要となるため、安全な場所に保管してください。
Databricks ウェアハウス ID の取得
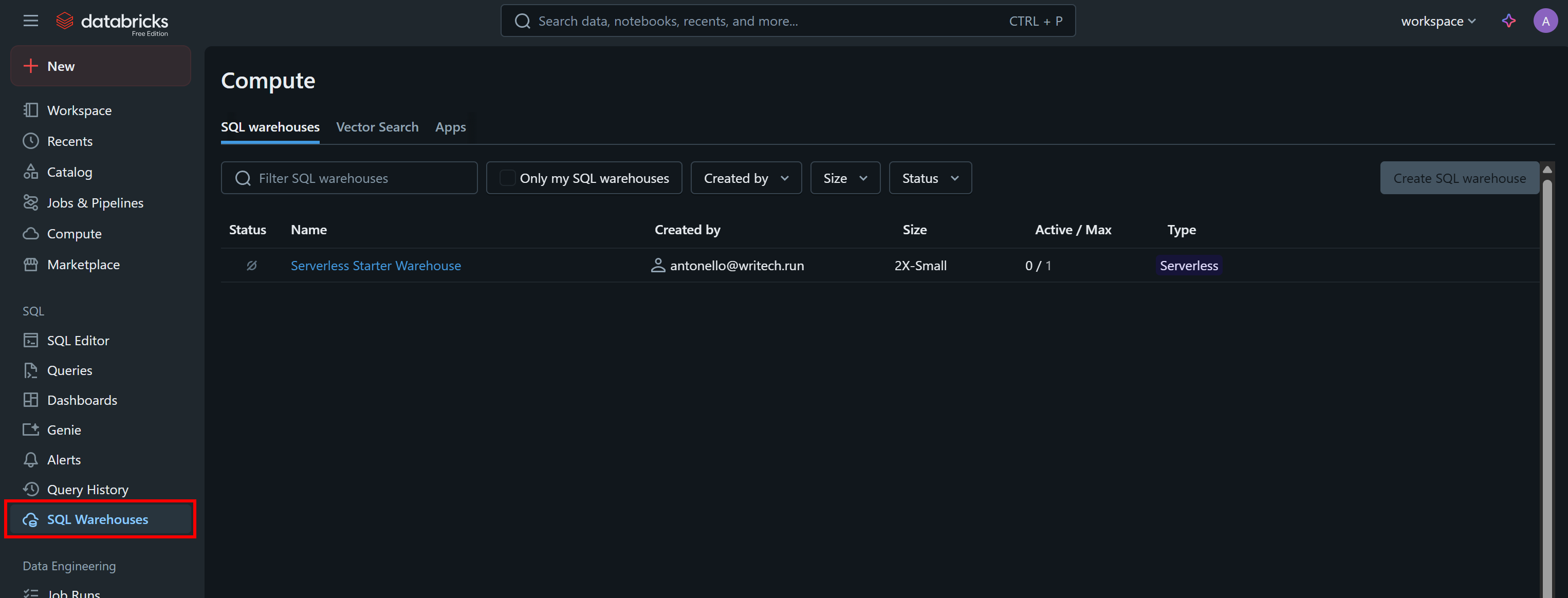
APIをプログラムで呼び出したり、CLI経由でデータセットをクエリしたりするには、DatabricksのウェアハウスIDも必要です。取得するには、メニューから「SQL Warehouses」オプションを選択します:
利用可能なウェアハウス(この例では「Serverless Starter Warehouse」)をクリックし、「概要」タブに移動します:
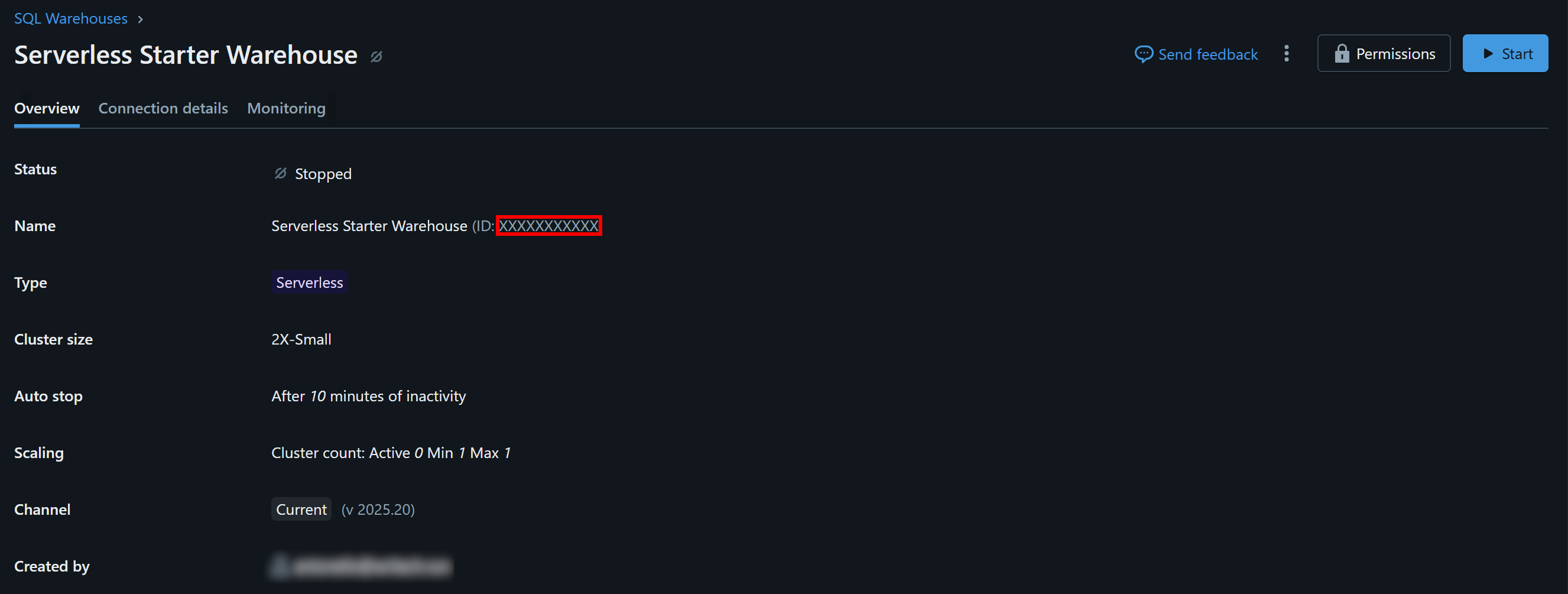
「Name」セクションに、Databricks ウェアハウス ID が表示されます(括弧内の「ID:」の後にあります)。これをコピーして安全な場所に保管してください。すぐに必要になります。
Databricksホストの特定
Databricksのコンピューティングリソースに接続するには、Databricksのホスト名を指定する必要があります。これはDatabricksアカウントに関連付けられたベースURLに対応し、以下のような形式です:
https://<ランダム文字列>.cloud.databricks.comこの情報は、DatabricksダッシュボードのURLから直接コピーして確認できます:

Bright Dataデータセットへのアクセス権取得
API、CLI、またはSQLコネクタ経由でクエリを実行できるように、Databricksアカウントに1つ以上のBright Dataデータセットを追加する必要があります。
「マーケットプレイス」ページに移動し、左側の設定ボタンをクリックして、関心のあるプロバイダーとして「Bright Data」のみを選択します:
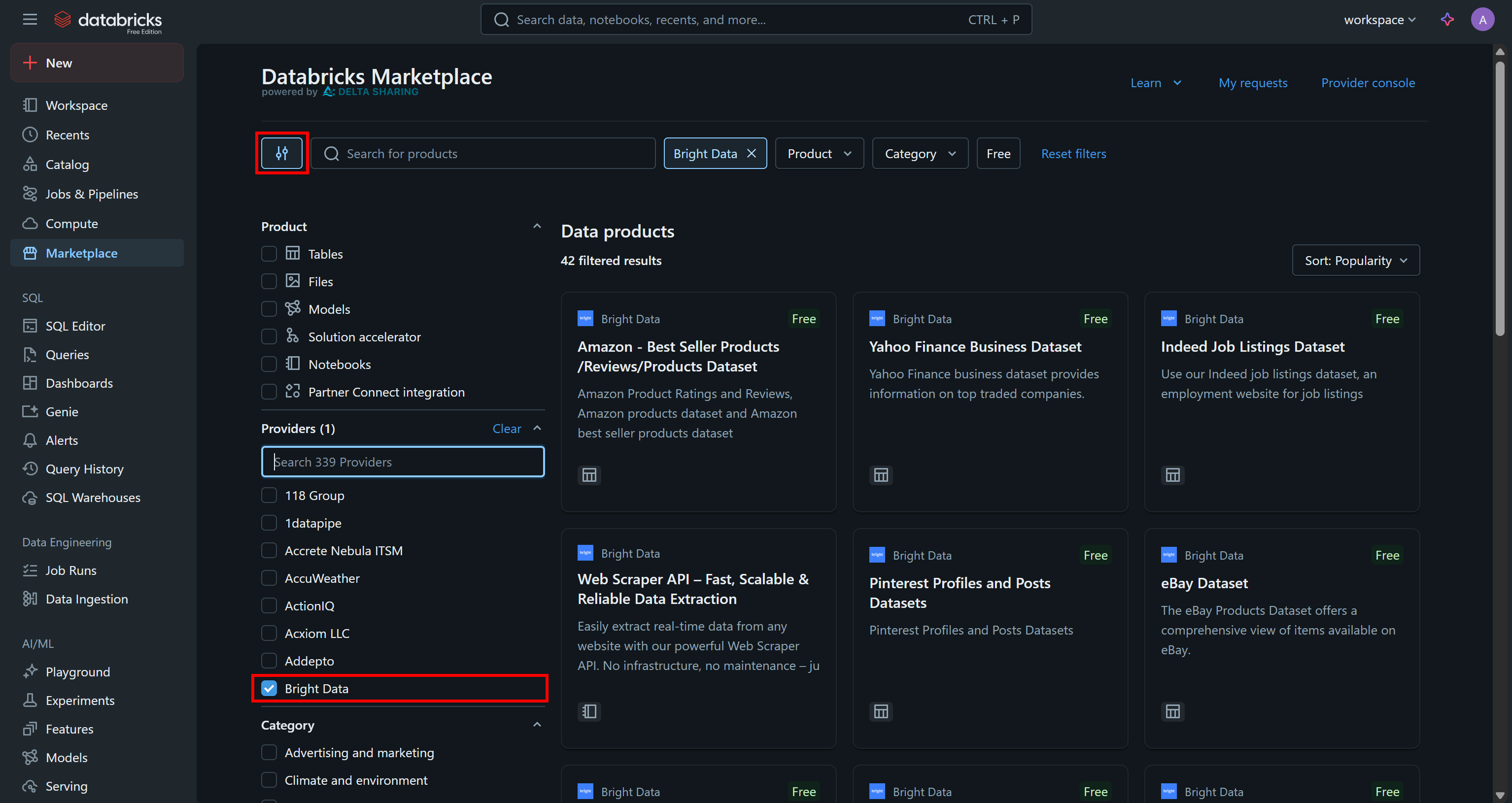
これにより、利用可能なデータ製品がBright Data提供かつDatabricks経由でアクセス可能なものに絞り込まれます。
この例では、「Zillow Properties Information Dataセット」に興味があると仮定します:
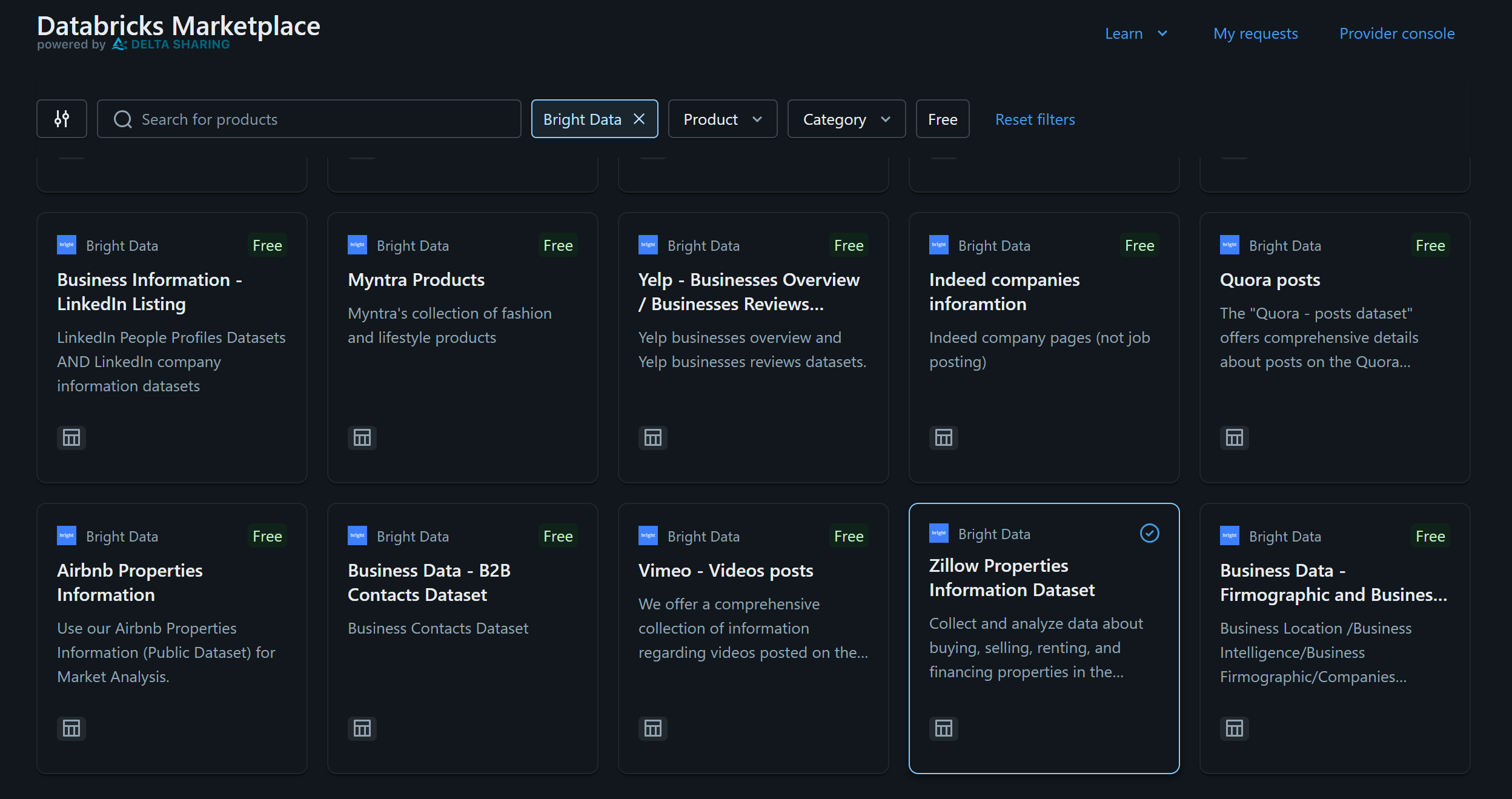
データセットカードをクリックし、「Zillow Properties Information Dataset」ページで「Get Instances Access」を押してDatabricksアカウントに追加します:
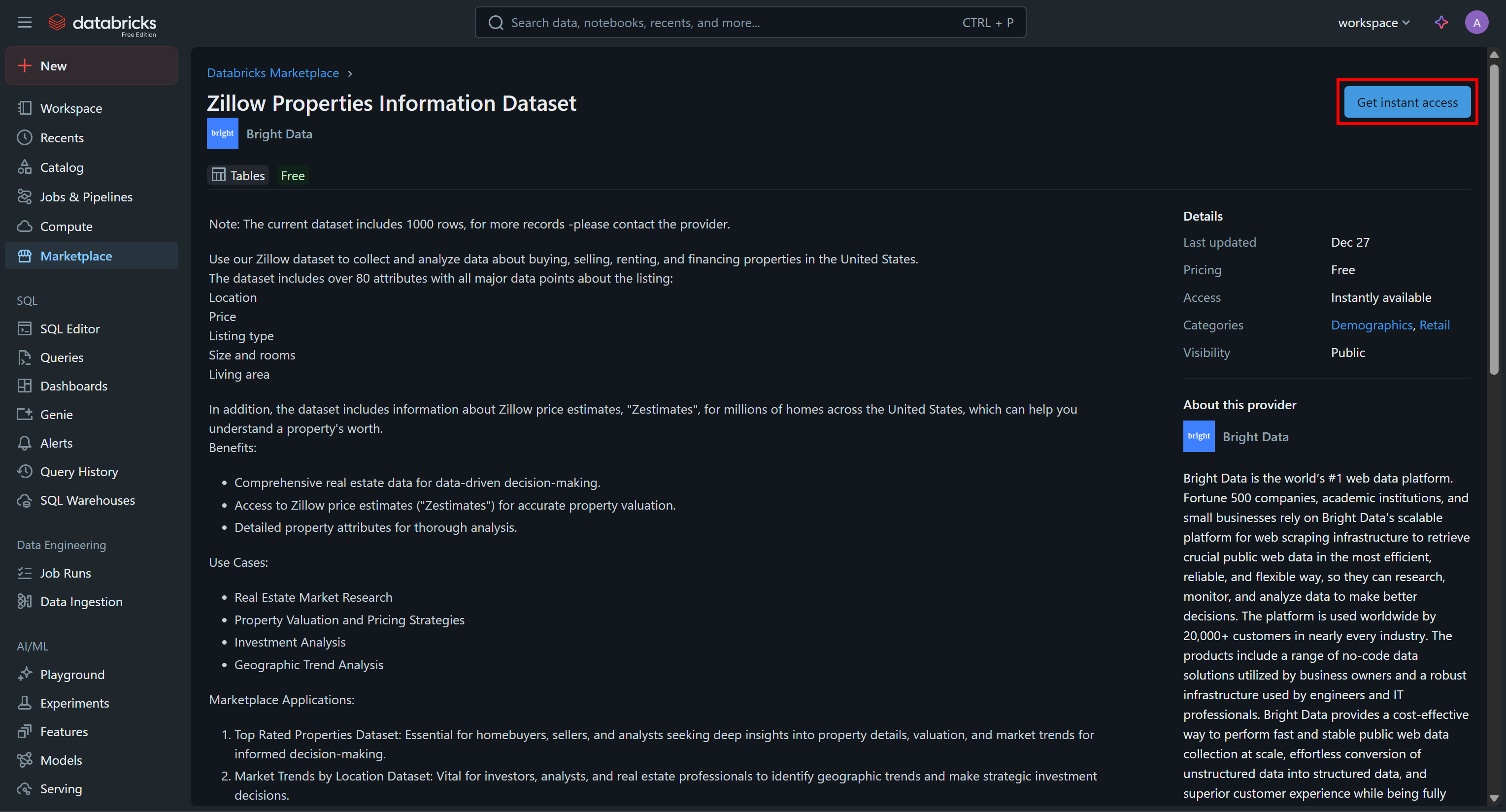
データセットがアカウントに追加され、Databricks SQL経由でクエリを実行できるようになります。このデータの出典が気になる場合、答えはBright DataのZillowデータセットです。
「SQLエディター」ページに移動し、次のようなSQLクエリでデータセットをクエリして確認してください:
SELECT * FROM bright_data_zillow_properties_information_dataset.データセット.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;結果は以下のようなものになるはずです:
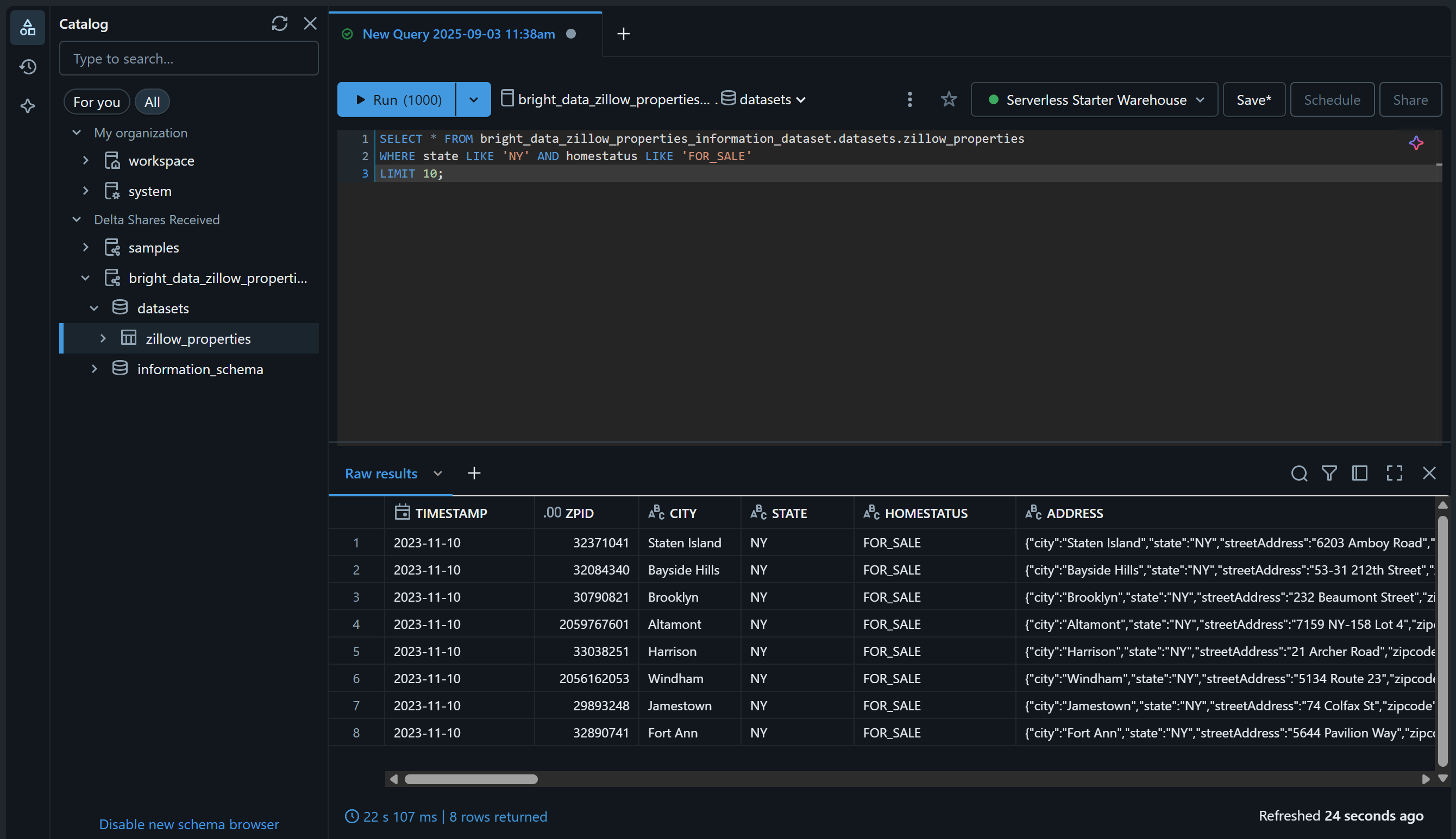
素晴らしい!選択したBright Dataデータセットの追加と、Databricks経由でのクエリ実行に成功しました。他のBright Dataデータセットも同様の手順で追加できます。
次のセクションでは、このデータセットのクエリ方法を学びます:
- Databricks REST API経由
- Python用Databricks SQLコネクタを使用
- Databricks CLI 経由
Databricks REST API 経由での Bright Data データセットのクエリ方法
Databricksは、アカウント内で利用可能なデータセットのクエリ機能を含む、一部の機能をREST API経由で公開しています。Bright Dataが提供する「Zillow Properties Information Dataset」をプログラムでクエリする方法を、以下の手順で確認してください。
注:以下のコードはPythonで記述されていますが、他のプログラミング言語に簡単に適応したり、cURLを介してBashで直接呼び出したりできます。
ステップ #1: 必要なライブラリのインストール
リモートDatabricksウェアハウスでSQLクエリを実行するには、REST APIエンドポイント/api/2.0/sql/statements を使用します。任意のHTTPクライアントからPOSTリクエストで呼び出せます。本例ではPythonのRequestsライブラリを使用します。
インストール方法:
pip install requests次に、スクリプト内でインポートします:
import requests詳細については、Python Requestsに関する専用ガイドをご覧ください。
ステップ #2: Databricks 認証情報とシークレットの準備
HTTPクライアントを使用してDatabricks REST APIエンドポイント/api/2.0/sql/statementsを呼び出すには、以下を指定する必要があります:
- Databricks アクセストークン: 認証用。
- Databricksホスト: 完全なAPI URLを構築するため。
- Databricks ウェアハウス ID: 正しいウェアハウス内の正しいテーブルをクエリするため。
以前に取得したシークレットをスクリプトに次のように追加します:
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"ヒント: 本番環境では、これらのシークレットをスクリプトにハードコーディングしないでください。代わりに、セキュリティ強化のため、これらの認証情報を環境変数に保存し、python-dotenvを使用して読み込むことを検討してください。
ステップ #3: SQL文実行APIを呼び出す
Requests を使用して、適切なヘッダーとボディを伴い、/api/2.0/sql/statementsエンドポイントにPOST HTTP リクエストを送信します:
# 指定されたデータセットで実行するパラメータ付きSQLクエリ
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.data sets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# SQLクエリに設定するパラメータ
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# POSTリクエストを送信し、データセットをクエリする
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Databricks認証用
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)ご覧の通り、上記のスニペットは事前準備されたSQLステートメントに依存しています。ドキュメントで強調されている通り、DatabricksはSQLステートメントのベストプラクティスとしてパラメータ化されたクエリの使用を強く推奨しています。
言い換えれば、上記スクリプトの実行は、先程と同様にbright_data_zillow_properties_information_dataset.data sets.zillow_propertiesテーブルに対して以下のクエリを実行することに相当します:
SELECT * FROM bright_data_zillow_properties_information_dataset.データセット.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;素晴らしい!あとは出力データの管理のみです
ステップ #4: クエリ結果のエクスポート
以下のPythonロジックでレスポンスを処理し、取得したデータをエクスポートします:
if response.status_code == 200:
# 出力 JSON データにアクセス
result = response.json()
# 取得したデータを JSON ファイルにエクスポート
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"クエリ成功!結果を '{output_file}' に保存しました")
else:
print(f"エラー {response.status_code}: {response.text}")リクエストが成功した場合、このスニペットはクエリ結果を含むzillow_properties.jsonファイルを作成します。
ステップ #5: 全てを統合する
最終的なスクリプトには以下を含める必要があります:
import requests
import json
# Databricksの認証情報(適切な値に置き換えてください)
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"
# 指定されたデータセットで実行するパラメータ付きSQLクエリ
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.data sets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# SQLクエリに代入するパラメータ
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# POSTリクエストを送信し、データセットをクエリする
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Databricks認証用
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# レスポンスの処理
if response.status_code == 200:
# 出力されたJSONデータへのアクセス
result = response.json()
# 取得したデータをJSONファイルにエクスポート
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"クエリ成功!結果を '{output_file}' に保存しました")
else:
print(f"エラー {response.status_code}: {response.text}")実行すると、プロジェクトディレクトリにzillow_properties.jsonファイルが生成されます。
出力の最初には利用可能なカラムを理解するためのカラム構造が含まれます。その後、data_arrayフィールドにクエリ結果のデータがJSON文字列として表示されます:
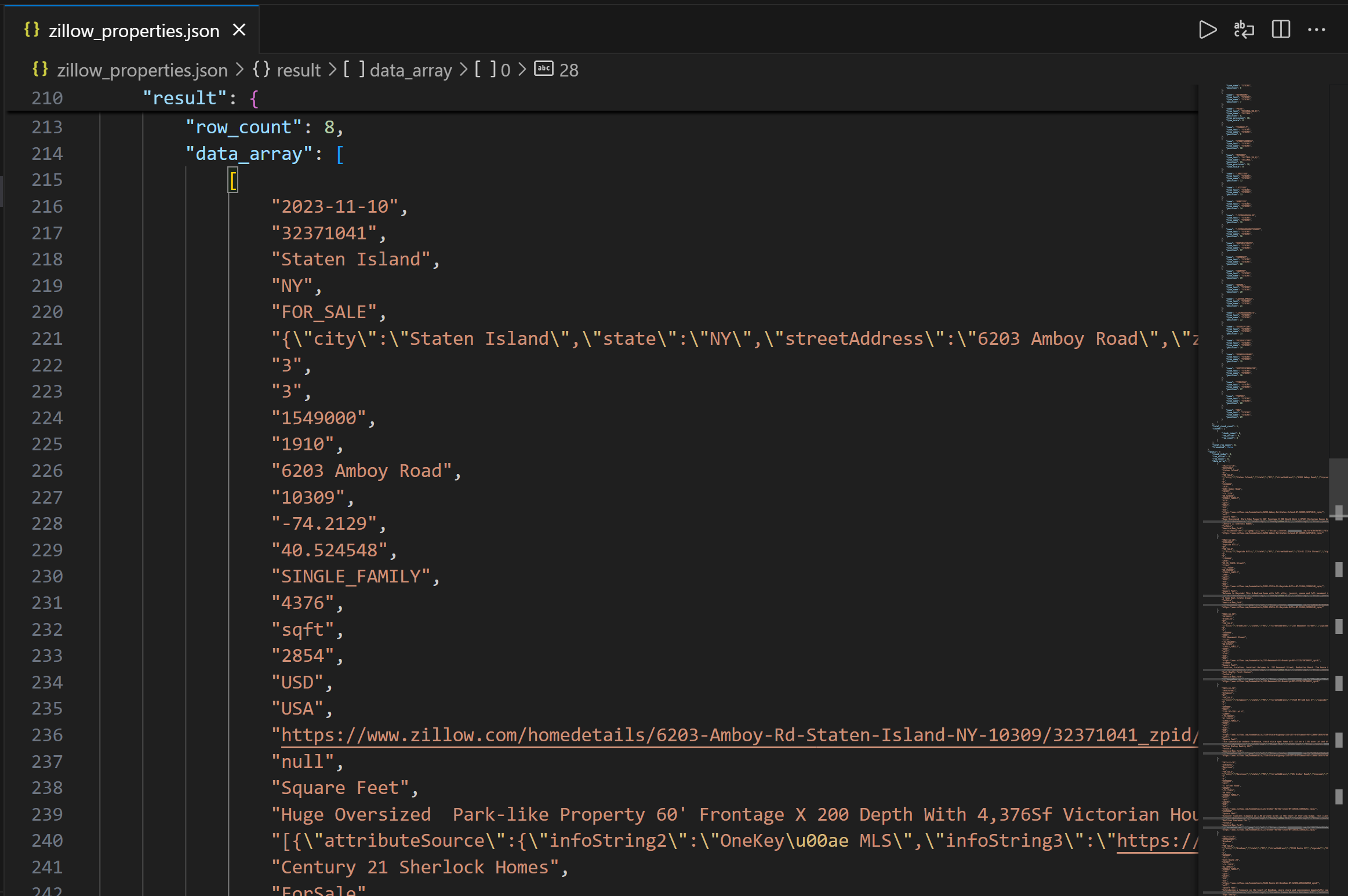
ミッション完了!Bright Dataが提供するZillow物件データをDatabricks REST API経由で取得しました。
Databricks CLIを使用したBright Dataデータセットへのアクセス方法
Databricksでは、Databricks CLIを通じてデータウェアハウス内のデータをクエリすることも可能です。これは内部でREST APIを利用しています。その使用方法を学びましょう!
ステップ #1: Databricks CLI のインストール
Databricks CLIは、ターミナルから直接Databricksプラットフォームとやり取りできるオープンソースのコマンドラインツールです。
インストールするには、お使いのオペレーティングシステムに対応したインストールガイドに従ってください。正しく設定されていれば、`databricks -v` コマンドを実行すると以下のような出力が表示されます:

完璧です!
ステップ #2: 認証用の設定プロファイルを定義する
Databricks CLIを使用して、Databricks個人アクセストークンで認証する「DEFAULT」という名前の設定プロファイルを作成します。以下のコマンドを実行してください:
databricks configure --profile DEFAULT次に、以下の情報を入力するよう求められます:
- Databricksホスト
- Databricksアクセストークン
両方の値を貼り付けてEnterキーを押すと設定が完了します:

これで、--profile DEFAULTオプションを指定することでCLIAPIコマンドの認証が可能になります。
ステップ #3: データセットのクエリ
以下の CLI コマンドを使用して、API postコマンド経由でパラメータ化されたクエリを実行します:
databricks API post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataセット.データセット.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parameters": [
{ "name": "state", "value": "NY", "type": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
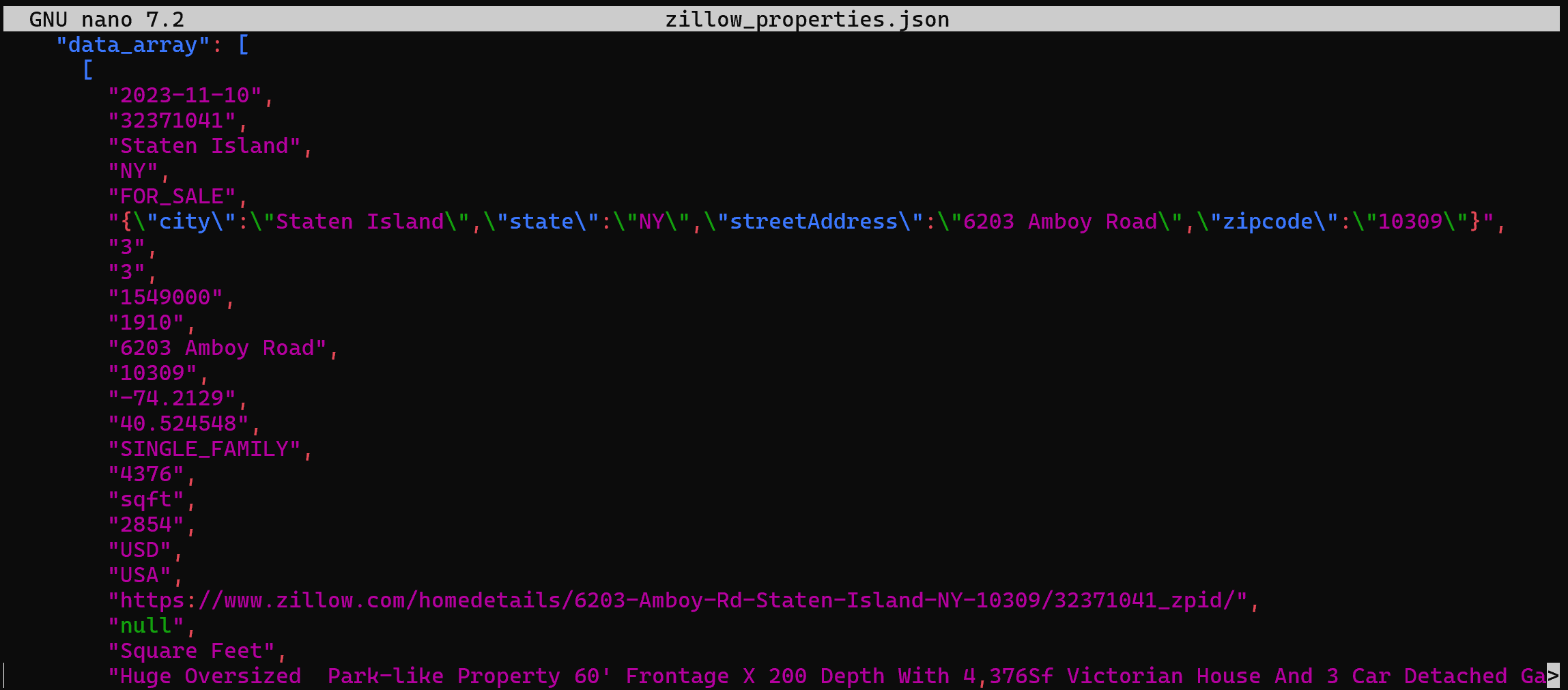
> zillow_properties.json<YOUR_DATABRICKS_WAREHOUSE_ID>プレースホルダーを、実際の Databricks SQL ウェアハウスの ID に置き換えてください。
内部的には、これは以前Pythonで行った操作と同じことを行います。具体的には、Databricks REST SQL APIへのPOSTリクエストを発行します。結果は、以前と同じデータを含むzillow_properties.jsonファイルとなります:
Databricks SQLコネクタを介したBright Dataからのデータセットクエリ方法
Databricks SQLコネクタは、DatabricksクラスターおよびSQLウェアハウスに接続するためのPythonライブラリです。特に、Databricksインフラストラクチャへの接続とデータ探索のための簡素化されたAPIを提供します。
このガイドセクションでは、Bright Dataの「Zillow物件情報データセット」をクエリするためにこのコネクタを使用する方法を学びます。
ステップ #1: Python 用 Databricks SQL コネクタのインストール
Databricks SQL Connector は、databricks-sql-connectorPython ライブラリを通じて利用可能です。以下のコマンドでインストールします:
pip install databricks-sql-connector次に、スクリプト内でインポートします:
from databricks import sqlステップ #2: Databricks SQL Connector の使用を開始する
Databricks SQL Connector は、REST API や CLI とは異なる認証情報を必要とします。具体的には以下の情報が必要です:
server_hostname: Databricksのホスト名(https://部分は除く)http_path: データウェアハウスに接続するための特別なURL。access_token: Databricksのアクセストークン。
必要な認証値とサンプルスタータースニペットは、SQL ウェアハウスの「接続詳細」タブで確認できます:
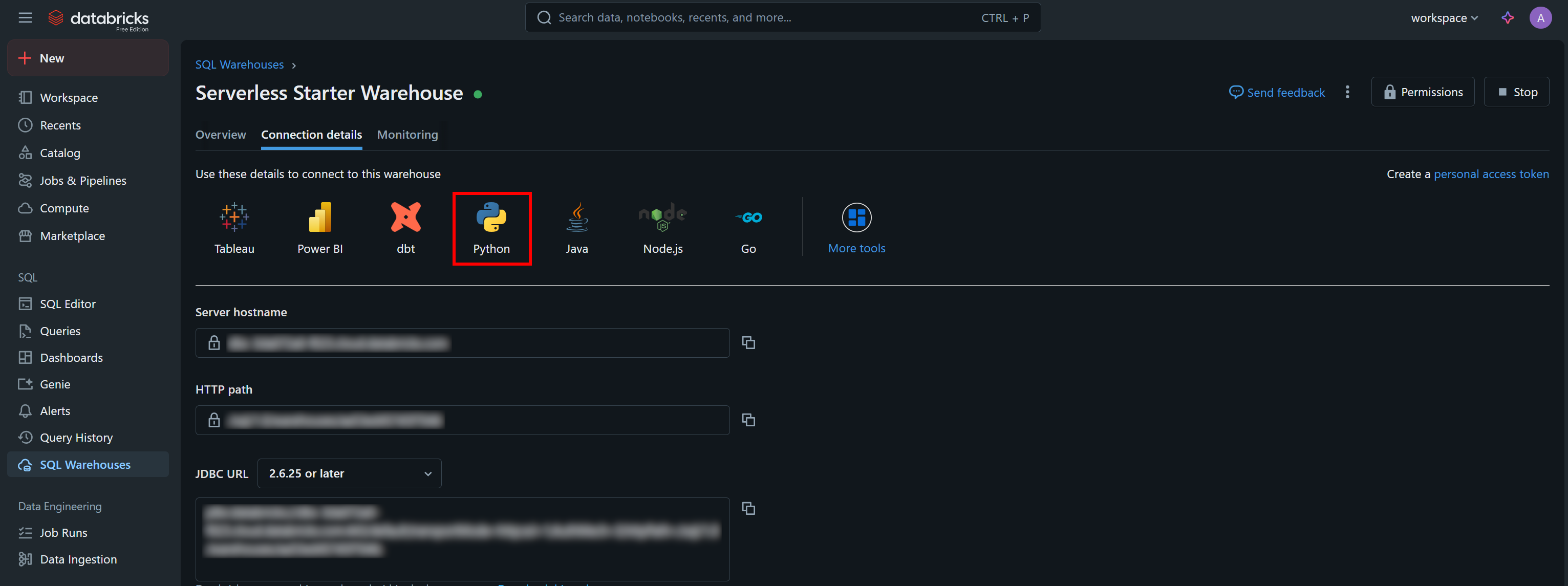
「Python」ボタンを押すと、以下の情報が表示されます:
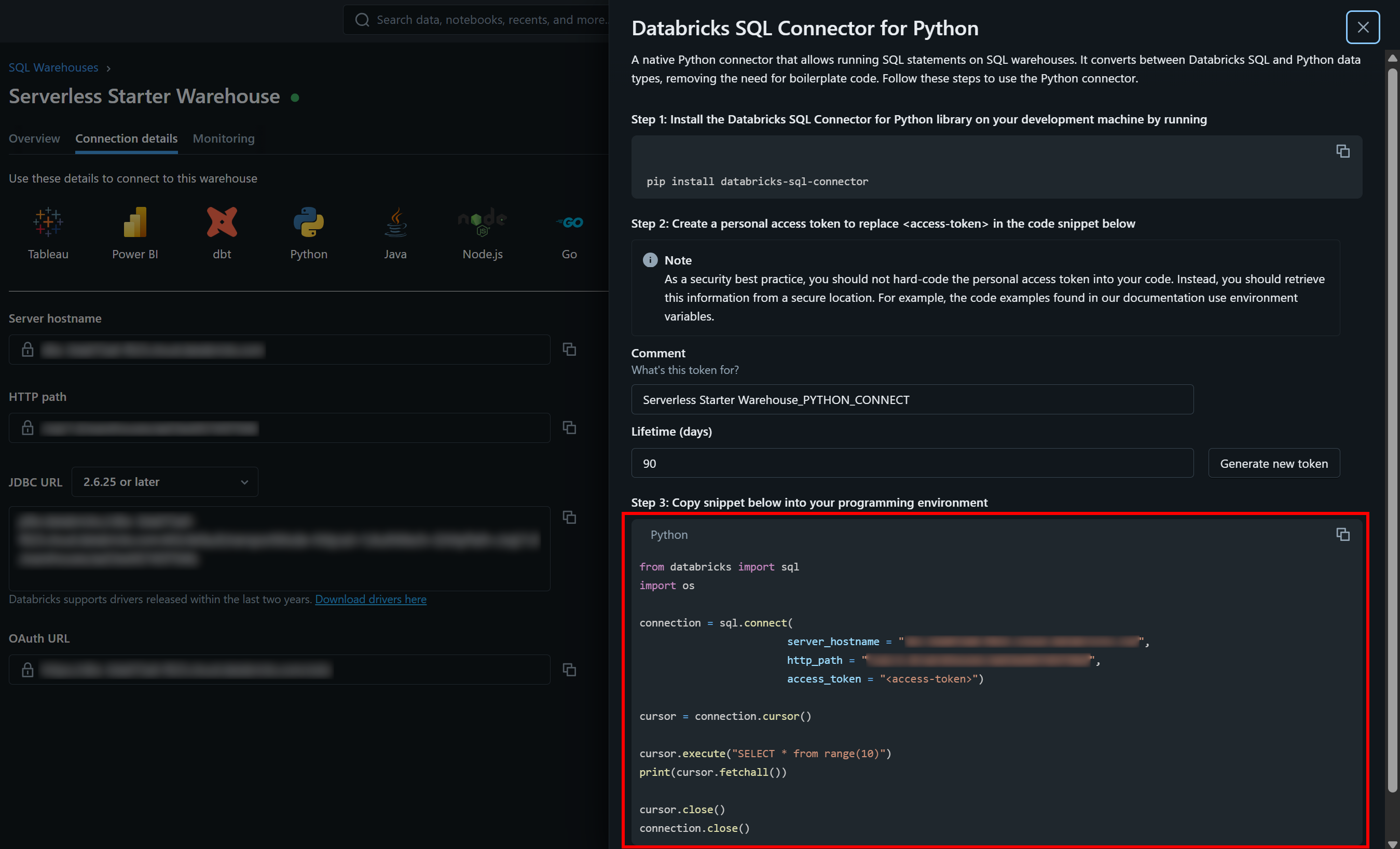
以上がdatabricks-sql-connectorの使用開始に必要な手順です。
ステップ #3: すべてを統合する
「Python用Databricks SQLコネクタ」セクションのサンプルスニペットのコードを、対象のパラメータ化クエリを実行できるよう、ご自身のウェアハウスに合わせて調整してください。最終的には以下のようなスクリプトになるはずです:
from databricks import sql
# Databricks内のSQLウェアハウスに接続(認証情報は自身の値に置き換えてください)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUSE_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# パラメータ化されたSQLクエリを実行し、結果をカーソルで取得
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.データセット.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# クエリを実行
cursor.execute(sql_query, params)
result = cursor.fetchall()
# 結果を1行ずつ出力
for row in result[:2]:
print(row)
# カーソルとSQLウェアハウス接続を閉じる
cursor.close()
connection.close()スクリプトを実行すると、次のような出力が生成されます:
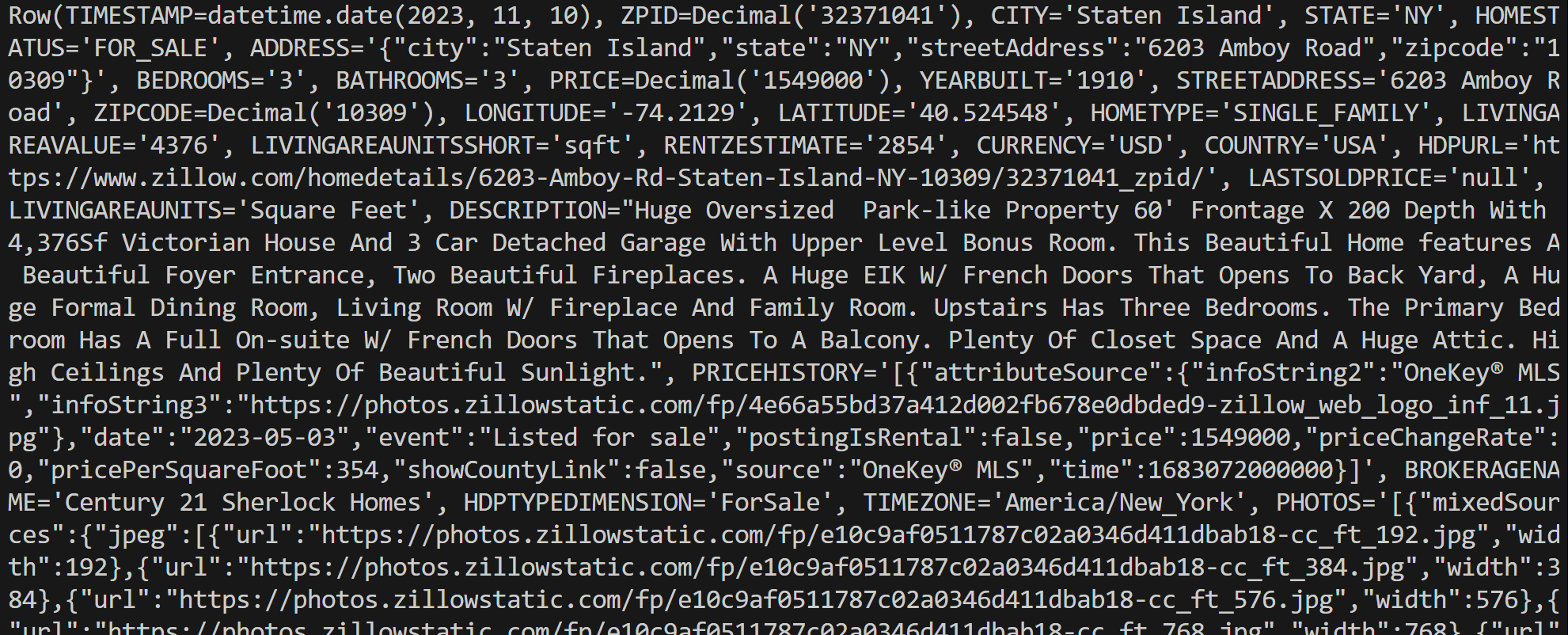
各行オブジェクトは Rowインスタンスであり、クエリ結果の単一レコードを表します。このデータを Python スクリプト内で直接処理できます。
RowインスタンスはasDict()メソッドでPythonの辞書に変換できる点に留意してください:
row_data = row.asDict()これで完了です!Databricks上でBright Dataデータセットを様々な方法で操作・クエリする方法が理解できました。
まとめ
本記事では、DatabricksからBright DataのデータセットをREST API、CLI、専用SQLコネクタライブラリを用いてクエリする方法を学びました。示した通り、Databricksはデータプロバイダー(現在Bright Dataを含む)が提供する製品とやり取りする複数の手段を提供しています。
40以上の製品が利用可能なBright Dataの豊富なデータセットを、Databricks内で直接探索し、様々な方法でデータにアクセスできます。
Bright Dataアカウントを無料で作成し、今すぐデータソリューションの活用を開始しましょう!






