
データフィルタリングは、かつては単なるデータベースのトリックでした。現在では、AIを強化し、コンプライアンスを維持し、競合他社に打ち勝つための中核的なビジネス機能となっています。
このガイドでは、次のことを学びます:
- データフィルタリングとは何か
- データフィルタリングが重要な理由
- 自動データフィルタリングを使用する理由
- Deep Lookupがデータフィルタリングを簡単にする方法。
さっそく始めましょう!
データ・フィルタリングとは?
データ・フィルタリングとは、単にあなたが実際に関心のあるデータだけを表示することです。これは、コーヒー・フィルターを使用するようなもので、必要なものだけを表示するものです。仕組みは簡単で、あなたがルール(例えばカリフォルニアの顧客を表示する)を設定すると、システムはルールに合致しないものをすべて除外します。
私たちは皆、日常生活でデータのフィルタリングを使っている。アマゾンで「100ドル以下のワイヤレスヘッドホン」を検索するとき、あなたはフィルタリングを行っている。マーケティングチームが6ヶ月間購入していない顧客のリストを取り出すとき、彼らはフィルタリングをしている。受信トレイを送信者別に並べ替えるとき、あなたはフィルタリングをしている。
コンセプトは簡単だが、組織でデータフィルタリングを大規模に使用するには、データをしっかりと理解し、適切なツールを使用する必要がある。今日、データフィルタリングはあらゆる組織の成功にとって重要です。
データフィルタリングが重要な理由
フィルタリングは、ビッグデータの意味を理解するために必要不可欠です。
今日、ほとんどの企業は、決して使うことのないデータの宝の山に眠っている。データに価値がないからではなく、重要なものを見つけるために効率的にデータを掘り起こすことができないからだ。
こう考えてみよう。あなたの会社では、おそらく顧客一人一人について何百ものデータを集めているだろう。しかし、いざ、最も価値のあるセグメントを特定しなければならなくなったとき、本当に5万件もの顧客レコードを手作業で選別するつもりだろうか?もちろんそうではない。サンプルを取って、経験則に基づいた推測をし、最善を望むでしょう。
それこそが、フィルタリングが解決する問題なのです。効果的なデータフィルタリングが不可欠な理由は以下の通りです:
- ノイズをカットする:アナリストは無関係なデータに時間を費やすのをやめ、実際に針を動かすパターンに集中する。
- すべてをスピードアップ:データセットが小さくなれば、クエリが速くなり、洞察が深まり、意思決定が数週間から数日に短縮されます。
- 隠れたパターンの発見:雑然としたものを取り除くと、見えなかったトレンドが突然明らかになる。
- 実際のコストを削減:保存・処理するデータが減ることで、インフラコストが削減されます。さらに、チームの時間は限りなく貴重なものになります。
- コンプライアンスを維持:機密情報を自動的にフィルタリングすることで、顧客データを誤って公開することがなくなり、安心して眠れるようになります。
まとめると、データフィルタリングは生データと情報に基づいた意思決定との橋渡し役です。次に、フィルタリングの実践方法と、効果的なフィルタリングのための標準的なテクニックを紹介します。
Amazonマーケットプレイスのデータを使った手動データフィルタリングのウォークスルー
データをフィルタリングする必要があるとき、ほとんどのチームが行っていることを説明しよう。実際のAmazon商品データセット(Bright Data datasets提供)を使って、これがどのように実行されるかを具体的にお見せします。このデータセットには、様々なカテゴリーや地域の商品タイトル、ブランド、価格、評価など様々なフィールドが含まれている。
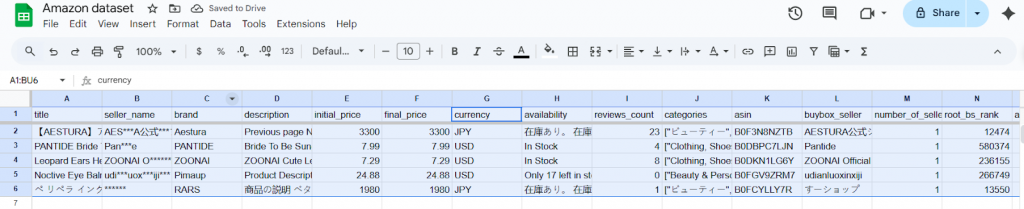
このような広範なリストを前にして、データの専門家は、有用な情報に焦点を当てるために、特定の分析に関連する製品だけを分離する必要があります。そのためには、以下のステップを踏む必要がある:
- まず、最初の関心基準を満たさない商品をフィルタリングすることから始める。実際には、これは多くの場合、ターゲットとするカテゴリーや範囲外の製品を除外することを意味する。例えば、美容製品にしか興味がない場合、他のカテゴリーに属するエントリーを除外する。
- グーグル・シートやエクセルのようなツールを使って、データ・タブに移動し、フィルターの作成をクリックする。

- すると各列にフィルターが表示されるので、それを使ってデータセットを好きなだけカスタマイズできる。
- 例えば、商品を通貨でフィルタリングし、米ドル価格の商品だけにしたい場合は、価格欄でそのフィルタを適用します。

- JPYのマークを外すと、データセットにはUSD価格の商品だけが表示されます。
初めてこの操作をしたときは、とても気持ちがいいものです。自分でコントロールでき、何が起きているのか正確に把握できる。”おや、エコフレンドリーな商品は評価が高いようだ!”
しかし、実際にはこうなる:
- 1週目:これは素晴らしい!私はこのコントロールが大好きだ。
- 4週目:さて、これは繰り返しになるが、私はまだ良いインサイトを発見している。
- 第12週:午前中いっぱい、昨日使ったのと同じフィルタを適用した。
- 24週目:前のフィルターをクリアするのを忘れたようだ。
多くの優秀なアナリストは、まさにこのようなことをして燃え尽きている。仕事に価値がないからではなく、実際の分析ではなく機械的な作業に時間の80%を費やしているからだ。
データを手動でフィルタリングする方法がわかったところで、この方法を使うことの長所と短所を見てみよう。
手動フィルタリングの長所
- 手動フィルタリングでは、結果を即座に確認し、フィルタを反復的に調整できるため、視覚的なフィードバックが即座に得られる。作業中に予期せぬパターンやデータ品質の問題を発見できる。
- また、ビジネスコンテキストの統合により、微妙な意思決定が可能になる。customers_say」や「top_review」フィールドをフィルタリングする際、人間の判断により、自動化されたシステムでは見逃してしまうような感情や懸念事項を特定することができます。
- これにより、発見主導型の分析をサポートする柔軟な探索が可能になります。climate_pledge_friendly’=TRUEの製品は評価が高く、新たな戦略的洞察につながることに気づくかもしれない。
- 参入障壁が低いため、スプレッドシートに精通したチームメンバーであれば、技術的なトレーニングや特別なツールがなくても分析を実行できる。
- フィルター・ビューを通して監査証跡を可視化し、文書化された基準によって分析の再現性とチーム・コラボレーションを保証します。
手動フィルタリングの欠点
- 規模の限界がすぐに明らかになる。Google Sheetsで10,000行以上のフィルタリングを行うと、パフォーマンスが著しく低下します。何百万ものアマゾンの商品では、ほんのわずかなサンプルしか見ることができません。
- 複雑であればあるほど、時間的な制約も大きくなる。上記の8ステップのフィルタリングプロセスを適用すると、1回の分析に15~20分かかります。これを毎日、あるいは複数のカテゴリーにわたって繰り返すのは、持続不可能になる。
- ヒューマンエラーの確率は繰り返しに比例して高くなる。誤って間違った演算子(より大きいかより小さいか)を選択したり、前のフィルターをクリアし忘れたりすると、間違った分析につながります。
- ユーザー間で一貫性がないため、相反する洞察が生まれる。2人のアナリストが「質の高い売り手」を異なる閾値で「売り手名」または「評価」をフィルタリングし、異なる解釈をするかもしれない。
- 再現性に限界があるため、自動化が不可能。手作業によるフィルタリングセッションのたびに人間の介入が必要となり、スケジュールされたレポートやリアルタイムのダッシュボードが作成できない。
- 機会損失が大きい。アナリストがデータのフィルタリングに何時間も費やしている間に、自動化ソリューションを使用している競合他社はすでに洞察に基づいて行動している。機械的なフィルタリングに費やす時間を、戦略的分析や意思決定に投資することができる。
全体として、手作業によるデータフィルタリングは、アナリストに高度なコントロールと明瞭さを提供し、ニュアンスの理解が重要な探索的分析や小規模なデータセットに適している。しかし、大規模データでは非効率でエラーのリスクもあるため、ビッグデータや定型的なワークフローには適していない。
このような場合は、自動化されたフィルタリング手法やツールに移行した方が良い。
自動データフィルタリングがより賢く、より速く、スケーラブルである理由
自動フィルタリングについて語るとき、それはスピードの問題だけではありません。自動化は、あなたが以前やっていたことをより速く行うだけでなく、文字通り手動ではできなかったことを行うのです。
73のフィールドがあるアマゾンのデータセットを覚えているだろうか?手作業では、それらのフィールドの組み合わせを5~10個調べることができるかもしれない。自動化を使えば、何千もの組み合わせを並行してテストすることができる。気候変動に配慮したバッジを付けた商品は、実際には顧客維持率が23%高いが、それは特定の価格帯で、特定のタイプのセラーが販売した場合のみであることを発見するかもしれない。
これらは、あなたが偶然発見した洞察ではない。あらゆる角度からシステマティックに探索することで見えてくる洞察であり、自動化されたデータフィルタリングによってのみ見つけることができる。
自動フィルタリングは、数百万のレコードを数秒で処理し、同時に数百のフィルタの組み合わせを適用することで、アナリストや企業にとって可能なことを根本的に変える。これは、基準を機械で実行可能なルールとして体系化し、それを継続的に実行することで実現します。
列をクリックする代わりに、宣言的なフィルターを定義し、そのフィルターを可能な限りソースに近づけ、高速で再利用可能なデータを得ることができます。自動化されたデータ・フィルタリングを使えば、何千ものフィールド・インタラクションを並行して徹底的に探索し、人間の限られた探索予算では決して収まらないパターンを浮き彫りにし、それを好きなだけ再現することができます。
| ディメンション | 手動 | 自動 |
|---|---|---|
| スピード/レイテンシー | 人間のペース:1回あたり数分から数時間 | マシンペース:数秒から数分のスケール |
| スケーラビリティ | UIとメモリによる制限 | 水平スケーリング(分散コンピュート、プッシュダウン) |
| 信頼性 | ヒューマンエラーの可能性 | 決定論的、テスト可能、べき等 |
| 鮮度 | バッチ、アドホック | スケジューリングまたはストリーミング。 |
| 一貫性 | オペレータによって異なる | バージョン管理されたロジック、再現可能なアウトプット |
| コスト | 隠れた人件費;手直し | 計算最適化;キャッシュと述語のプッシュダウン |
| ガバナンス | 監査が困難 | リネージ、ロギング、承認、アクセスコントロール |
自動化されたデータフィルタリングに使用できる最高のツールの1つは、BrightdataのDeep Lookupです。
ディープ・ルックアップの紹介平易な英語でデータをフィルタリング
Deep Lookupは、平易な英語のプロンプトを構造化された正確なデータセットに変えるBright DataのAI搭載リサーチツールです。ディープ・ルックアップを使えば、必要なものを正確に尋ね、使える表として返してもらうことができます。
ソースをつなぎ合わせたり、複雑なクエリを書いたりする代わりに、必要なエンティティ(企業、製品、人、ニュース、プロパティ)、それらが満たすべきフィルタ、および表示したい列を記述します。Deep Lookupは、フィルタリング、エンリッチメント、構造化を舞台裏で処理し、分析に適した結果を提供します。
ディープ・ルックアップの仕組み
Deep Lookupでは、以下のような2行のプロンプト形式が推奨されています:
- すべての … <エンティティと条件>を検索します 。
- 表示: <必要な列
例えば、ディープ・ルックアップの例は次のようになります:
***価格≦25ドル、評価≧4、在庫ありのAmazonビューティ&パーソナルケア製品をすべて検索します。
***表示: 商品名、ブランド、現在の価格、評価、レビュー数、商品URL
ディープ・ルックアップは、その説明を受け取って
- 必要なデータ・ソースを特定します。
- データベースレベルでフィルタを適用します(すべてをダウンロードした後ではありません)。
- 追加のコンテキストで結果を豊かにする
- すぐに使用できる、クリーンで構造化されたデータセットを返します。
より複雑なクエリの場合は、より構造化されたアプローチを使用できます:
FIND ALL: [エンティティ・タイプ]
FILTERS:
- 条件#1
- 条件#2
ショー
- 列#1 [充実度または制約条件]
- カラム#2 [エンリッチメントまたはコンストレイント]
重要な違いは、技術的な実装ではなく、ビジネスロジックを記述していることです。どのAPIエンドポイントをヒットするか、ページネーションをどのように処理するか、競合他社の価格データをどこで見つけるかを知る必要はありません。
Deep Lookupから得られるデータセットは、キュレーションされ、構造化され、ウェブセットとして配信されます。Websetsは、検証済みで完全に引用されており、カスタマイズ可能(正確なフィールドを選択)で、Deep Lookupが新しいソースをスキャンするにつれて常に最新の状態になるように設計されています。
実際の流れは
- 質問をする
- クロールと推論
- 実用的な結果を得る。
Websetsは、エンティティ、セクター、地域、およびデータフィールドによって、ユースケースに合わせてカスタマイズすることができます。
まとめ
ここまでで、データフィルタリングが、乱雑で圧倒的な情報を明確な意思決定に変える方法であることがお分かりいただけただろう。手作業によるフィルタリングは直感を養いますが、自動化はスピードと一貫性を提供し、1列ずつでは誰も見つけられないパターンを浮かび上がらせます。
ここがまさにBright Dataが役立つところです。ディープ・ルックアップを使用すると、ダッシュボード、ノートブック、またはモデルに差し込むことができる、クリーンで構造化された常に新鮮なデータセットを受け取ることができます。Bright Dataのデータセット(本ガイドのAmazonデータセットのような)と組み合わせることで、もろいパイプラインを維持することなく、アイデアから洞察、本番へと移行することができます。
自動フィルタリングがあなたのデータに何をもたらすか、試してみませんか? 無料のBright DataアカウントでDeep Lookupをお試しください。これまで手動で適用していたフィルタリングルールを使って、見逃していたインサイトを見てみましょう。






