

Pythonは現在、世界中で圧倒的に主流のウェブスクレイピング言語です。しかし、常にそうだったわけではありません。1990年代後半から2000年代初頭にかけて、ウェブスクレイピングはほぼ完全にPerlと PHPで行われていました。
本日はPythonを、かつてのWeb開発界の巨人であるPHPと直接対決させます。両言語の違いを検証し、どちらが優れたウェブスクレイピング体験を提供するかを確かめていきましょう。
前提条件
実践するにはPythonとPHPのインストールが必要です。各言語のダウンロードリンクをクリックし、お使いのOSに応じた手順に従ってください。
- Python
- PHP
以下のコマンドで各言語のインストール状態を確認できます。
Python
python --version
次のような出力が表示されるはずです。
Python 3.10.12
PHP
php --version
出力は以下の通りです。
PHP 8.3.14 (cli) (built: Nov 25 2024 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
with Zend OPcache v8.3.14, Copyright (c), by Zend Technologies
両言語の基本的な理解があると便利ですが、必須ではありません。実際、私は今まで一度もPHPを書いたことがありませんでした!
ウェブスクレイピングにおけるPythonとPHPの比較
プロジェクト作成前に、各言語をもう少し詳しく見ていきましょう。
- 構文: Pythonは読みやすい構文を持ち、特にデータコミュニティで広く採用されています。
- 標準ライブラリ:両言語とも豊富な標準ライブラリを提供しています。
- スクレイピングフレームワーク:Pythonにはスクレイピングフレームワークの選択肢がはるかに豊富です。
- パフォーマンス:PHPはウェブ実行向けに設計されているため、一般的に高速です。
- 保守性:Pythonは明確な構文と強力なコミュニティサポートにより、保守が容易な傾向があります。
| 特徴 | Python | PHP |
|---|---|---|
| 使いやすさ | 初心者向けで習得が容易 | 新規開発者にはやや難しい |
| 標準ライブラリ | 豊富で機能満載 | 豊富で機能満載 |
| スクレイピングツール | 多数のサードパーティ製スクレイピングツール | はるかに小規模なエコシステム |
| データサポート | データ処理を念頭に構築 | 基本的なライブラリとツールが利用可能 |
| コミュニティ | 大規模なコミュニティとサポート | サポートが限定的な小規模コミュニティ |
| 保守性 | メンテナンスが容易で、広く普及している | 困難、プログラマーの確保が難しい |
スクレイピング対象は?
これは単なるデモであり、ベンチマーク用に一貫性を保つサイトが必要であるため、quotes.toscrape.comを使用します。このサイトは一貫したコンテンツを提供し、スクレイパーをブロックしません。テストケースに最適です。
下の画像では、ページ上の引用アイテムの一つを確認できます。これはclass=quoteの div要素です。まずこれら全てのアイテムを見つける必要があります。
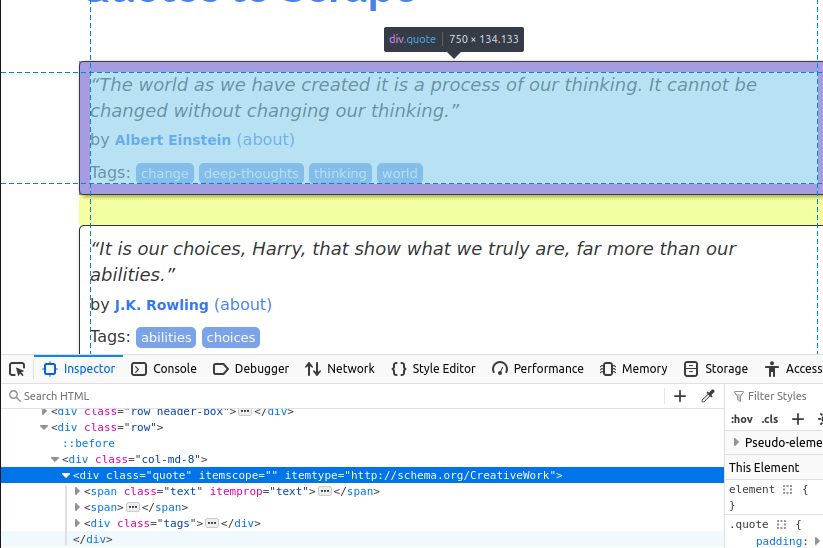
ページ上の引用カードを全て見つけたら、各カードから個々の項目を抽出する必要があります。
テキストはクラス名「text」を持つspan要素に埋め込まれています。
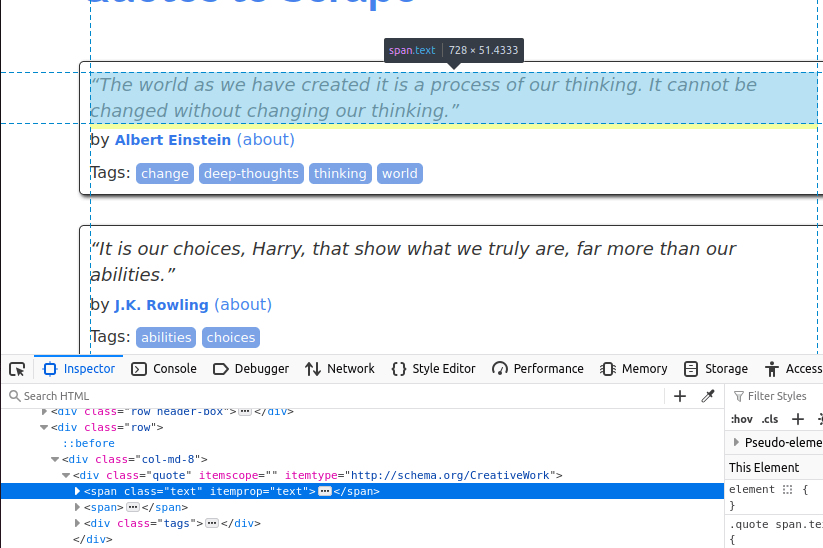
次に著者を取得します。これはクラス名「author」を持つ小さなitem要素内にあります。
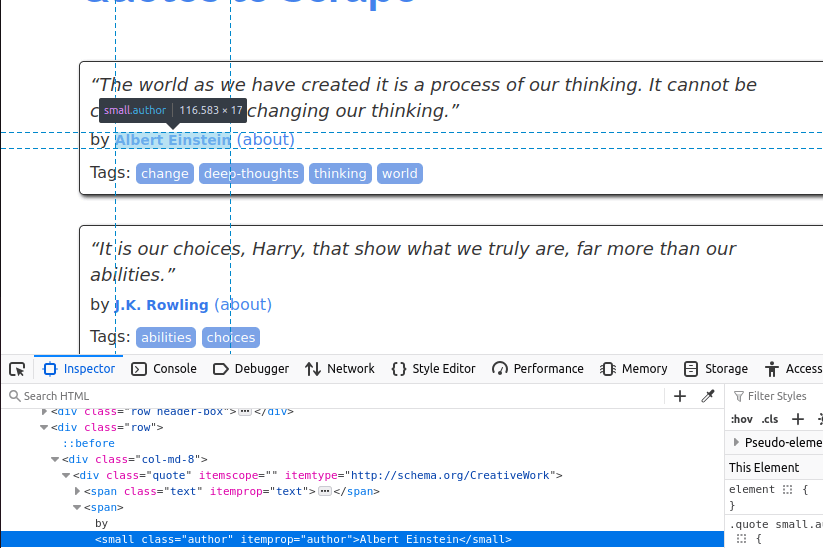
最後にタグを抽出します。これらはtagクラスを持つelement内にあります。

必要なデータが明確になったので、いよいよ実際の作業に取り掛かります。
はじめに
それでは、すべての設定を行います。PythonとPHPの両方でいくつかの依存関係が必要です。
Python
PythonではRequestsとBeautifulSoupをインストールする必要があります。
pipを使用して両方をインストールできます。
pip install requests
pip install beautifulsoup4
PHP
これらの依存関係はすべてPHPにプリインストールされているはずですが、実際に使用しようとしたところ存在しませんでした。
sudo apt install php-curl
sudo apt install php-xml
依存関係をインストールしたことで、コーディングを始める準備が整いました。
データのスクレイピング
まずPythonで以下のスクレイパーを作成しました。このコードはquotes.toscrape.comに対して一連のリクエストを実行し、各引用文からテキスト・名前・作者を抽出します。全引用文の取得が完了したら、それらをJSONファイルに書き込みます。ご自身のPythonファイルにコピー&ペーストしてご利用ください。
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("スクレイピング完了。引用文をquotes.jsonに保存しました。")
- まず、
page_numberとoutput_jsonの変数を設定します。 while page_number <= 5は、5ページ分のスクレイピングが完了するまでスクレイパーを継続させる条件です。response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")は現在表示中のページにリクエストを送信します。divs = soup.select("div[class='quote']")で対象のdiv要素をすべて検出します。divsを反復処理し、データを抽出します:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags:tag_holder要素をすべて見つけ、それぞれのテキストを個別に抽出します。
- これら全てが完了したら、
output_json配列をファイルに保存し、ターミナルにメッセージをprint()します。
以下は実行結果のスクリーンショットです。実際にはもっと多くの実行を行いましたが、簡潔にするためここでは3回の実行結果をサンプルとして使用します。
実行1は11.642秒かかりました。

実行2は11.413秒かかりました。

実行3は10.258秒かかりました。

Pythonでの平均実行時間は11.104秒です。
PHP
Pythonコードを書いた後、ChatGPTにPHPで書き直してもらいました。最初は動作しませんでしたが、少し調整したら使えるようになりました。
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "ページ $pageNumber の取得に失敗しましたn";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "スクレイピング完了。引用文をquotes.jsonに保存しました。";
- Pythonコードと同様に、
pageNumberとoutputJson変数から開始します。 - 実際のスクレイピングの実行時間を制御するために
whileループを使用します:while ($pageNumber <= 5)。 $ch = curl_init($url);でHTTPリクエストを設定します。リダイレクトを追跡するにはcurl_setopt()を使用します。$response = curl_exec($ch);でHTTPリクエストを実行します。$dom = new DOMDocument();は使用する新しいDOMオブジェクトを設定します。これは以前使用したBeautifulSoup()に類似しています。- CSSセレクタではなくXPathを使用して
divを取得します:$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";各引用文のテキストを取得します。$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";により著者を取得します。タグを取得するには、再度全てのタグ要素を検索し、ループで反復処理してテキストを抽出します。- 最後に、すべての処理が完了したら、出力結果をjsonファイルに保存し、画面にメッセージを表示します。
PHPを使用した実行結果は以下の通りです。
実行1は11.351秒かかりました。

実行 2 は 9.846 秒かかりました。

実行3は9.795秒かかりました。

PHPの平均は10.33秒でした。
さらなるテストでは、PHPは引き続き高速な結果を出力し続けました…時には7秒という速さでした!
Bright Dataの利用をご検討ください
上記の内容に共感された方は、ウェブスクレイパーを書きましょう!データ抽出を生業とするなら、上記のようなコードを日常的に書くことになるでしょう!
当社ではスクレイパーの堅牢性を高める多様な製品を提供しています。スクレイピングブラウザはプロキシ統合とJavaScriptレンダリングを内蔵したリモートブラウザを提供します。ブラウザなしでプロキシとCAPTCHAの解決のみが必要な場合はWeb Unlockerをご利用ください。
スクレイパーは万人向けではありません。
必要なデータを取得してすぐに作業を進めたい場合は、当社のデータセットをご覧ください。スクレイピング作業は当社が代行します。すぐに使えるデータセットをぜひご検討ください。最も人気のあるデータセットは、LinkedIn、Amazon、Crunchbase、Zillow、Glassdoorです。サンプルデータを無料で閲覧でき、CSVまたはJSON形式でレポートをダウンロードできます。
結論
Pythonの平均処理速度が11.104秒、PHPが10.33秒という結果から、PHPスクレイパーはPythonスクレイパーを常に上回りました。一部はサーバーのレイテンシーが影響している可能性もありますが、追加テストでもPHPはほぼ全ての実行でPythonを上回りました。
速度面ではPythonを確実に上回っていますが、構文の面では必ずしもそうとは言えません。今日では、PHPやPerlのような言語の構文に慣れている開発者は多くありません。これらは過去の脚言語です。さらに、チームがPHPに慣れていない可能性もあります。この種のコードを常に書き、レガシーアプリケーションを稼働させ続けるには、特別なタイプのコーダーが必要です。
Bright Dataでスクレイピング作業を次のレベルへ。今すぐ登録して無料トライアルを開始しましょう!





