本記事では以下の内容を解説します:
- ETLパイプラインの解説
- ETLパイプラインの利点
- ビジネスにおけるETLパイプラインの実装方法
- ETLパイプライン工程の自動化
- ETLパイプラインに関するよくある質問
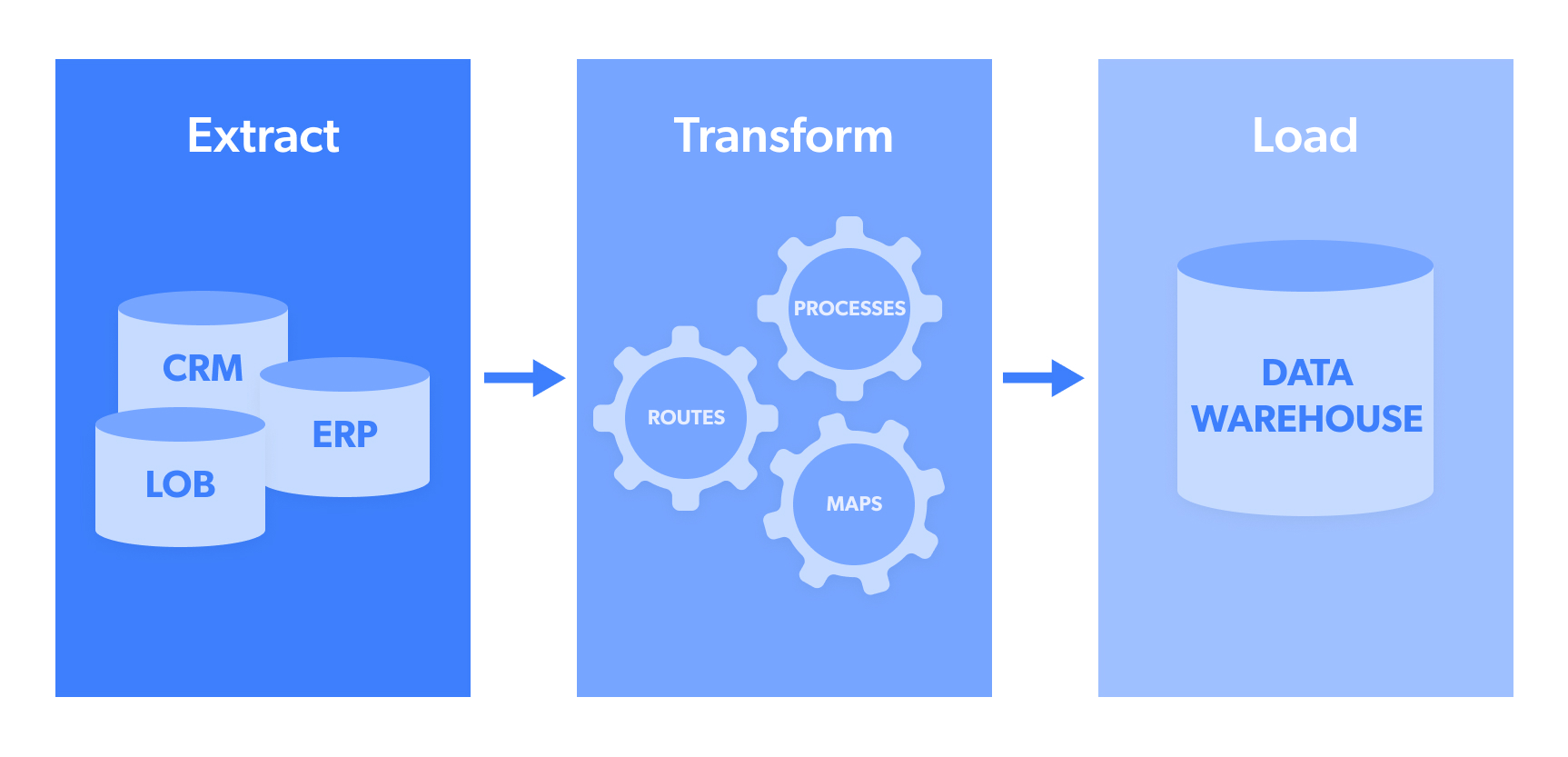
ETLパイプラインの解説
ETLの略語の意味:
- 抽出(Extract):NoSQLデータベースやソーシャルメディアのトレンド投稿といったオープンソースのターゲットウェブサイトなど、ソースまたはデータプールからのデータ抽出段階です。
- 変換(Transform):抽出された データは通常、複数の形式で収集されます。「変換」とは、このデータをターゲットシステムに送信可能な統一された形式に構造化するプロセスを指します。これにはJSON、CSV、HTML、Microsoft Excelなどの形式が含まれる場合があります。
- Load(ロード): データをデータプール/ウェアハウス、CRM、データベースへ実際に転送/アップロードする段階です。 これにより分析が可能となり、実用的な出力が生成されます。最も広く利用されるデータ送信先には、Webhook、メール、Amazon S3、Google Cloud、Microsoft Azure、SFTP、APIなどがあります。
留意点:
- ETLパイプラインは、複雑度が高い小規模データセットに特に適しています。
- 「ETLパイプライン」は「データパイプライン」と混同されがちです。後者はデータ収集アーキテクチャ全体の包括的な概念であるのに対し、前者はより特定のプロセスを指します。
ETLパイプラインの利点
ETLパイプラインの主な利点には以下が含まれます:
一つ目: 複数ソースからの生データ
急速な成長を目指す企業は、強力なETLパイプラインアーキテクチャによって視野を広げられる点で恩恵を受けられます。優れたETLデータ取り込みフローにより、企業は様々な形式の生データを複数のソースから収集し、分析のために効率的にシステムに入力できるようになるためです。これにより、意思決定が現在の消費者/競合他社の動向とより密接に連動するようになります。
二つ目:インサイト獲得までの時間短縮
あらゆる業務フローと同様に、一度稼働させれば、初期収集から実用的なインサイト獲得までの時間を大幅に短縮できます。データ専門家が各データセットを手動で確認し、必要な形式に変換して目的の宛先に送信する代わりに、このプロセスが合理化され、より迅速なインサイト獲得が可能になります。
三:企業リソースの解放
この点から派生して、優れたETLパイプラインは多層的に企業リソースを解放します。具体的には人員の解放も含まれます。実際、企業は:
「AI活用準備のためのデータクリーニングに80%以上の時間を費やしている」
ここでいうデータクリーニングとは、とりわけ「データフォーマット」を指し、堅牢なETLパイプラインがこれを処理します。
ビジネスにおけるETLパイプラインの実装方法
ビジネスにおけるETLパイプラインの実装方法を示すeコマースのユースケースを以下に示します:
デジタル小売事業者は、競争力を維持しターゲット顧客にアピールするため、様々なソースから多様なデータポイントを集約する必要があります。データソースの例としては以下が挙げられます:
- – マーケットプレイス上の競合ベンダーに対するレビュー
- 商品・サービスのGoogle検索トレンド
- 競合他社の広告(コピー+画像)
これらのデータポイントはすべて、.txt、.csv、.tab、SQL、.jpgなど様々な形式で収集されます。ターゲット情報を複数形式で保持することは、企業のビジネス目標(競合他社や消費者のインサイトをリアルタイムで導き出し、売上拡大に向けた変更を実施すること)の達成に不向きです。
このため、当該eコマースベンダーは、上記の全フォーマットを以下のいずれか(アルゴリズム/入力システムの優先度に基づく)に変換するETLパイプラインの構築を選択する可能性があります:
- JSON
- CSV
- HTML
- Microsoft Excel
例えば、競合他社の製品カタログを表示する出力形式としてMicrosoft Excelを選択したとします。これにより、営業サイクルや生産管理担当者はこれを迅速に確認し、自社デジタルカタログに追加したい競合他社の新製品を特定できます。
ETLパイプラインの一部ステップの自動化
多くの企業は、データ収集作業やETLパイプラインを手動で設定する時間、リソース、人的リソースを単純に持ち合わせていません。こうした状況では、完全に自動化されたWebデータ抽出ツールを選択します。
この種の技術により、企業は自社業務に集中しつつ、第三者が開発・運用する自律型ETLパイプラインアーキテクチャを活用できます。主な利点は以下の通りです:
- インフラ/コード不要のWebデータ抽出
- 追加の技術要員不要
- データは自動的にクリーニング、パース、統合され、選択した統一フォーマット(JSON、CSV、HTML、Microsoft Excel)で配信されます –このステップはETLパイプラインの代替機能であり、自動的に処理されます
- その後、データは企業側の消費者(例:チーム、アルゴリズム、システム)に配信されます。配信方法には、Webhook、メール、Amazon S3、Google Cloud、Microsoft Azure、SFTP、APIなどが含まれます。
自動化されたデータ抽出ツールに加え、あまり知られていない効率的で有用な近道も存在します。多くの企業は、データ収集とETLパイプラインの必要性を完全に排除することで、「データインサイト獲得までの時間」を短縮しています。これは、既に統一された形式で整えられ、社内のデータ利用者へ直接配信される、すぐに使えるデータセットの力を活用することで実現しています。
結論
ETLパイプラインは、複数のソースからのデータ収集を効率化し、データから実用的なインサイトを導き出す時間を短縮するとともに、ミッションクリティカルな人的リソースやリソースを解放する効果的な方法です。 しかし、ETLパイプラインが提供する効率性にもかかわらず、その開発と運用には依然としてかなりの時間と労力が必要です。このため、多くの企業はBright Dataのウェブスクレイピングツールなどのツールを使用して、データ収集とETLパイプラインフローの外部委託と自動化を選択しています。データプロジェクトに最適なソリューションを見つけるため、ぜひお問い合わせください。
ETLパイプラインに関するよくある質問
ETLはExtract(抽出)、Transform(変換)、Load(ロード)の略称です。これは複数のソースからデータを取得し、ターゲットシステムやアプリケーションが取り込めるように統一された形式に変換するプロセスを指します。
ロードはETLプロセスの最終段階であり、統一された形式でデータをデータプールまたはデータウェアハウスにアップロードし、その後処理・分析・インサイト抽出を行うことを意味します。主なロードの3種類は以下の通りです:1. 初期ロード 2. 増分ロード 3. フルリフレッシュ
はい、PythonでETLパイプラインを構築することは可能です。これを実現するには、ワークフロー管理のための「Luigi」、データ処理と移動のための「Pandas」など、様々なツールが必要となります。