
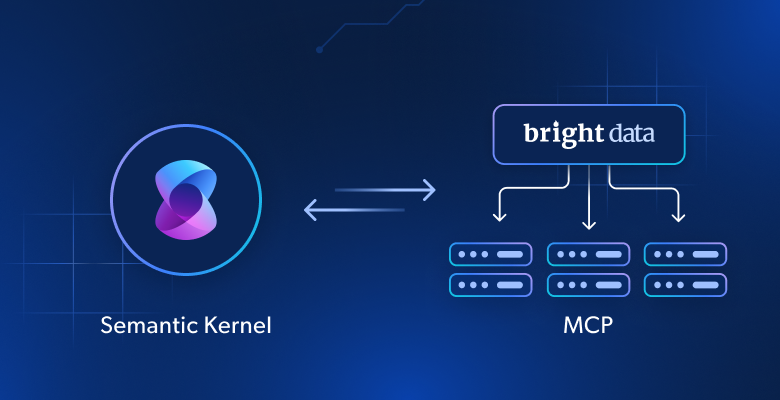
このチュートリアルでは
- Semantic Kernelとは何か、どのような機能を提供するのか、どのように機能するのか。
- MCPで拡張することでさらに強力になる理由。
- Semantic Kernelを使用したBright Data Web MCP統合によるAIエージェントの構築方法。
さっそく見ていきましょう!
セマンティック・カーネルとは?
Semantic Kernelはマイクロソフトが開発したオープンソースのSDKで、AIモデルやLLMをアプリケーションに統合し、AIエージェントや高度なGenAIソリューションを構築するのに役立ちます。複数のAIサービスへのコネクタを提供し、セマンティック(プロンプトベース)とネイティブ(コードベース)の両方の関数実行を可能にする、プロダクション対応のミドルウェアとして機能します。
SDKはC#、Python、Javaで利用可能です。テキストを生成したり、チャットの補完を実行したり、外部のデータソースやサービスに接続したりするための柔軟なソリューションだ。この記事を書いている時点で、プロジェクトのGitHubリポジトリには26k以上のスターがあります。
主な機能
Semantic Kernelが提供する主な機能は以下の通り:
- AIモデルの統合:OpenAIやAzure OpenAIのようなサービスと、チャット補完やテキスト生成などの統一されたインターフェイスで接続。
- プラグインシステム:AI機能を拡張するためのセマンティック関数(プロンプト)とネイティブ関数(C#、Python、Java)によるプラグインをサポート。
- AIエージェント:ユーザーのリクエストを解釈し、複数のプラグインやサービスを調整して複雑なタスクを解決するエージェントを構築できます。
- プランニングと関数呼び出し:適切なプラグインや関数を選択することで、エージェントが複数ステップのタスクを分解して実行できるようにします。
- 検索拡張世代(RAG):検索とデータコネクタを使用して実際のデータをプロンプトに統合し、より正確で最新の応答を実現します。
セマンティック・カーネルの仕組み
ライブラリがどのように動作するかを理解するには、その主要コンポーネントを知ることが役立ちます:
- コア・カーネル:AIサービスとプラグインのオーケストレーション
- AIサービス・コネクター:共通のインターフェースを介して、アプリケーションコードをさまざまなAIモデルやサービスにリンクする。
- プラグイン:エージェントの機能を拡張するセマンティック関数とネイティブ関数を含む。
- AIエージェント:カーネルの上に構築され、プラグインを使用してリクエストを処理し、ワークフローを実行する。
MCP統合でセマンティックカーネルを拡張する理由
セマンティックカーネルはモデルにとらわれないSDKで、複雑なAIエージェント、ワークフロー、さらにはマルチエージェントシステムを構築、オーケストレーション、デプロイすることができます。アーキテクチャがどんなに洗練されても、これらのワークフローやエージェントが機能するためには、基盤となるAIモデルが必要です。
それがOpenAIであれ、Azure OpenAIであれ、他のLLMであれ、すべてのモデルは同じ基本的な制限を共有しています。
LLMは、時間のスナップショットを表すデータでトレーニングされるため、その知識はすぐに古くなります。さらに重要なことに、LLMは生きたウェブサイトや外部データソースとネイティブにやり取りすることができません。
セマンティックカーネルのプラグインによる拡張性が大きな違いを生む。Bright DataのWeb MCPと統合することで、AIエージェントを静的知識以外にも拡張することができ、新鮮で高品質なデータをウェブから直接取得することができます。
オープンソースのWeb MCPサーバーは、60以上のAIのためのツールへのアクセスを提供し、これらはすべてBright Dataのウェブインタラクションとデータ収集のためのインフラストラクチャによって支えられています。
無料版でも、AIエージェントはすでに2つの強力なツールを使用できます:
| ツール | ツール |
|---|---|
検索エンジン |
Google、Bing、Yandexの検索結果をJSONまたはMarkdownで取得します。 |
scrape_as_markdown |
ボット検知やCAPTCHAを回避して、あらゆるウェブページをきれいなMarkdown形式でスクレイピングします。 |
それ以外にも、Web MCPはAmazon、LinkedIn、Yahoo Finance、TikTokなどのプラットフォームで構造化されたデータ収集のための数多くの特別なツールをアンロックします。詳細は公式GitHubページで。
つまり、Semantic KernelとWeb MCPを組み合わせることで、静的なワークフローが、ライブのウェブサイトと対話し、ウェブデータにアクセスして現実世界に根ざした洞察を生成できる動的なAIのためのエージェントに変わるのです。
Bright DataのWeb MCPに接続するSemantic KernelでAIエージェントを構築する方法
このガイドセクションでは、Bright DataのWeb MCPをC#で書かれたSemantic Kernel AIエージェントに接続する方法を学びます。特に、RedditアナライザーAIエージェントを構築するために、この統合を使用します:
- Bright Data Web MCP ツールを使用して、Reddit の投稿から情報を取得します。
- OpenAI GPT-5 モデルを使用して、取得したデータを処理します。
- 結果をMarkdownレポートで返します。
注:以下のコードは.NET 9を使ってC#で書かれています。しかし、サポートされている他の2つのプログラミング言語であるPythonやJavaに簡単に変換することができます。
以下の手順に従ってください!
前提条件
始める前に、以下を確認してください:
- .NET 8.0以上がローカルにインストールされていること(このチュートリアルでは.NET 9を参照します)
- OpenAI APIキー
- APIキーが準備されたBright Dataアカウント
Bright Data アカウントの設定については、後のステップで説明しますので、心配しないでください。
ステップ #1: .NET C#プロジェクトのセットアップ
SK_MCP_Agentという新しい .NET コンソールプロジェクトを初期化します:
dotnet new console -n SK_MCP_Agent次に、プロジェクトフォルダに入ります:
cd SK_MCP_Agent次のようなファイル構造になります:
SK_MCP_Agent/
├── Program.cs
├── SK_MCP_Agent.csproj
├── obj/
├── project.assets.json
├── project.nuget.cache
├── SK_MCP_Agent.csproj.nuget.dgspec.json
├── SK_MCP_Agent.csproj.nuget.g.props
└── SK_MCP_Agent.csproj.nuget.g.targetsProgram.csには、現在デフォルトの “Hello, World “プログラムが含まれています。このファイルにセマンティックカーネルのAIエージェントロジックを配置します。
Visual Studioや Visual Studio Codeなどの.NET C# IDEでプロジェクトフォルダを開いてください。IDEのターミナルで、必要な依存関係を以下のコマンドでインストールします:
dotnet add package Microsoft.Extensions.Configuration
dotnet add package Microsoft.Extensions.Configuration.EnvironmentVariables
dotnet add package Microsoft.Extensions.Configuration.UserSecrets
dotnet add package Microsoft.SemanticKernel --prerelease
dotnet add package Microsoft.SemanticKernel.Agents.Core --prerelease
dotnet add package ModelContextProtocol --prerelease
dotnet add package System.Linq.AsyncEnumerable --prerelease必要なNuGetパッケージは以下のとおりです:
Microsoft.Extensions.Configuration.*:環境変数と.NETユーザー・シークレットから設定を読み取るためのキー値ベースのコンフィギュレーションを提供します。Microsoft.SemanticKernel.*: AI LLMを従来のプログラミング言語と統合するための軽量なSDKで、エージェント開発用のツールが含まれています。ModelContextProtocol:Bright Data Web MCPへの接続に使用される公式MCP C#クライアント。System.Linq.AsyncEnumerable:IAsyncEnumerable<T>の LINQ 拡張メソッド一式を公開します。
メモ:dotnet add packageの--prereleaseフラグは、NuGet パッケージの最新(プレリリース)バージョンをインストールするように .NET CLI に指示します。これは、まだ開発中または実験段階であるため、一部のパッケージで必要です。
完了です!あなたの.NET開発環境は、Bright Data Web MCP統合で、Semantic Kernelを使用してC#でAIのためのエージェントを構築するように設定されています。
ステップ #2: シークレットローディングの設定
AIエージェントは、OpenAIモデルやBright Data Web MCPサーバーなどのサードパーティーコンポーネントに依存します。これらの統合はどちらもAPIキートークンによる認証を必要とします。これらのキーをコード内で直接公開するのを避けるために、.NET ユーザーシークレットストレージシステムまたは環境変数を使用して安全に保存します。
これを構成するには、まず構成パッケージをインポートします:
Microsoft.Extensions.Configurationを使用してください;次に、configオブジェクトに秘密をロードします:
var config = new ConfigurationBuilder()
.AddUserSecrets<Program>()
.AddEnvironmentVariables()
.Build();これで、次のようなコードでシークレットにアクセスできるようになります:
config["<secret_name>"] のようにします。プロジェクト・フォルダで次のコマンドを実行して、ユーザー秘密ストレージを初期化します:
dotnet user-secrets initこれで、秘密(つまりAPIキー)のための安全なローカル・ストレージが作成されます。
これで完了です!これであなたのC#プログラムは、ソースコードに機密情報を公開することなく、安全に認証情報を扱えるようになりました。
ステップ #3: Bright DataのWeb MCPをテストする
エージェントでBright DataのWeb MCPに接続する前に、まずマシンがMCPサーバを実行できることを確認します。
Bright Dataアカウントをまだお持ちでない場合は、新規アカウントを作成してください。お持ちの場合は、ログインしてください。簡単なセットアップのために、ダッシュボードの “MCP “セクションに移動し、指示に従ってください:
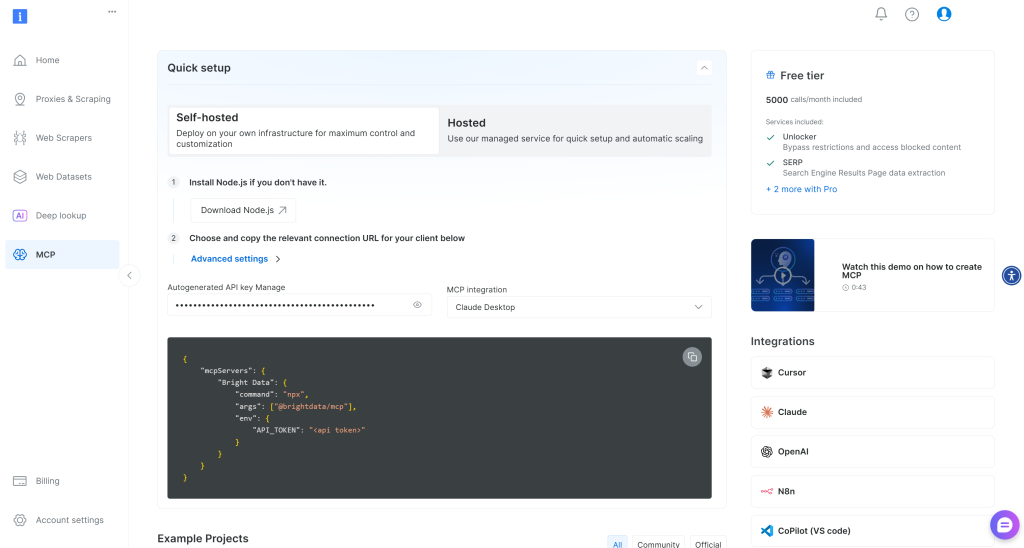
そうでない場合は、Bright Data APIキーの生成から始めてください。すぐに必要になるので、安全な場所に保管してください。このセクションでは、API キーが管理者権限を持っていると仮定します。
以下のコマンドを実行して、Web MCPをシステムにグローバルにインストールします:
npm install -g @brightdata/mcp次に、以下のコマンドを実行して、ローカルのMCPサーバーが動作することを確認します:
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpまたは、Linux/macOSの場合:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>を実際のBright Data APIトークンに置き換えてください。このコマンドは必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを通してWeb MCPを起動します。
成功すると、このようなログが表示されます:

初回起動時に、Web MCPは自動的にBright Dataアカウントに2つのデフォルトゾーンを作成します:
mcp_unlocker:mcp_unlocker:Web Unlocker用のゾーンです。mcp_browser:mcp_unlocker: Web Unlocker用のゾーン。
MCPサーバーはこの2つのゾーンに依存して、60以上のすべてのツールを動かします。
ゾーンが作成されたことを確認するには、Bright Dataダッシュボードにログインします。プロキシ&スクレイピングインフラフラ“ページに移動し、ゾーンテーブルに表示されているはずです:
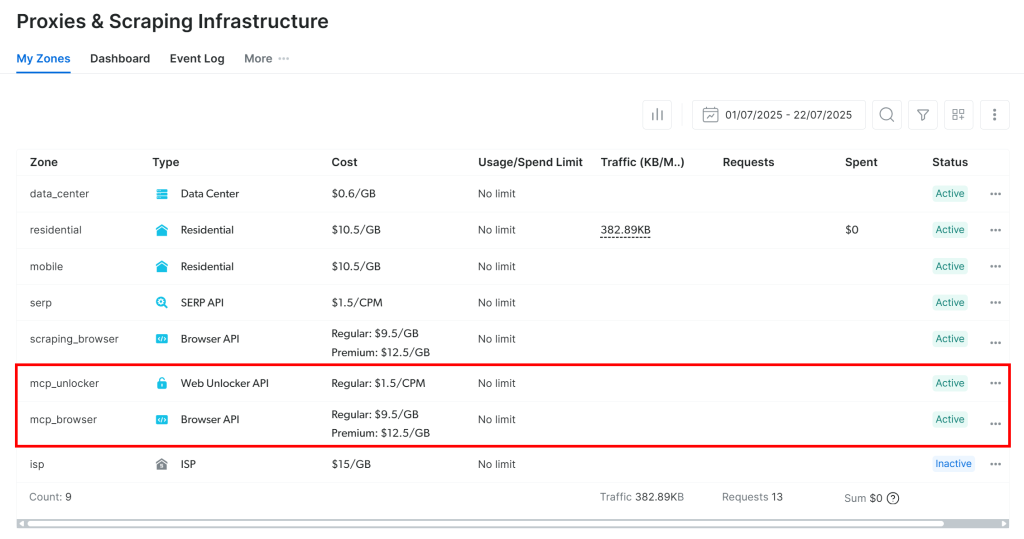
API トークンに管理者権限がない場合、これらのゾーンは作成されません。その場合、ダッシュボードで手動で作成し、環境変数で名前を設定する必要がある(詳細はGitHubページを参照)。
重要:デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツール(とそのバッチ版)のみを公開しています。これらのツールは、Web MCPの無料版に含まれています。
ブラウザの自動化や構造化データ・フィードなどの高度なツールのロックを解除するには、Proモードを有効にする必要があります。これを行うには、Web MCPを起動する前に環境変数PRO_MODE="true "を設定します:
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpまたは、Linux/macOSの場合:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpプロ・モードは60以上のツールのロックを解除しますが、無料版には含まれておらず、追加料金が発生します。
成功しました!これで、Web MCPサーバーがマシン上で実行されていることが確認できました。次のステップでは、Semantic Kernelエージェントがサーバーを起動し、サーバーに接続するように設定します。
ステップ#4: Web MCPインテグレーションを設定する
マシンがWeb MCPを実行できるようになったので、ユーザーシークレットに先ほど取得したBright Data APIキーを追加することから始めます:
dotnet user-secrets set "BrightData:ApiKey" "<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_BRIGHT_DATA_API_KEY>プレースホルダーを実際のAPIキーに置き換えます。このコマンドは、プロジェクトのsecretsストレージにキーを安全に保存します。
APIキーを環境変数として設定することで、同じ結果を得ることができることを覚えておいてください:
Env:BrightData__ApiKey="<YOUR_BRIGHT_DATA_API_KEY>"または、macOS/Linuxの場合:
export BrightData__ApiKey="<YOUR_BRIGHT_DATA_API_KEY>"注:Microsoft.Extensions.Configurationが BrightData__ApiKeyを BrightData:ApiKeyに変換します。
次に、ModelContextProtocolパッケージの McpClientFactoryを使用して MCP クライアントを定義し、Web MCP に接続します:
await using var mcpClient = await McpClientFactory.CreateAsync(new StdioClientTransport(new())
{
Name = "BrightDataWebMCP"、
コマンド = "npx"、
引数 = ["-y", "@brightdata/mcp"]、
EnvironmentVariables = new Dictionary<string, string?
{
{ "API_TOKEN", config["BrightData:ApiKey"].},
// { "PRO_MODE", "true" }, // <-- オプション:プロモードを有効にする
}
}));上記の設定により、前のセットアップ手順で見たのと同じnpxコマンドが、必要な環境変数とともに実行される。PRO_MODEはオプションであり、API_TOKENは先に定義したBrightData:ApiKeysecretから読み込まれることに注意してください。
次に、利用可能なすべてのツールのリストを読み込みます:
var tools = await mcpClient.ListToolsAsync().ConfigureAwait(false);このスクリプトは、npxコマンドを実行して Web MCP をローカル・プロセスとして起動し、Web MCP に接続して、Web MCP が公開しているツールにアクセスします。
すべてのツールをログに記録することで、Web MCP への接続が機能し、そのツールにアクセスできることを確認できます:
foreach (var tool in tools)
{
Console.WriteLine($"{tool.Name}: {tool.Description}");
}今スクリプトを実行すると、このような出力が表示されるはずです:

これらは、無料層の Web MCP で公開されている 2 つのデフォルト・ツール (+ 2 つのバッチ・バージョン) です。Proモードでは、60以上のすべてのツールにアクセスできます。
素晴らしい!上記の出力から、Web MCPの統合が完璧に機能していることが確認できる!
ステップ#5: MCPツールにアクセスできるカーネルを構築する
Semantic Kernelでは、カーネルはAIアプリケーションの実行に必要なすべてのサービスとプラグインを管理する依存性注入コンテナとして機能します。一度カーネルにサービスやプラグインを提供すれば、AIは必要な時にいつでもそれらを使うことができます。
さて、いよいよMCP経由のツール呼び出しをサポートしたOpenAI統合用のカーネルを作成します。ユーザ・シークレットにOpenAIのAPIキーを追加することから始めましょう:
dotnet user-secrets set "OpenAI:ApiKey" "<YOUR_OPENAI_KEY>"前述したように、これをOpenAI__ApiKey という環境変数として設定することもできます。
次に、OpenAI に接続する新しいカーネルを定義します:
var builder = Kernel.CreateBuilder();
builder.Services
.AddOpenAIChatCompletion(
modelId:"gpt-5-mini"、
apiKey: config["OpenAI:ApiKey"] ).
);
Kernel kernel = builder.Build();この例では、カーネルはユーザ・シークレットに保存されたAPIキーを使ってgpt-5-miniモデルに接続します(しかし、他のOpenAIモデルを設定することもできます)。
次に、ツールを使用するためのプラグインをカーネルに追加します:
kernel.Plugins.AddFromFunctions("BrightData", tools.Select(aiFunction => aiFunction.AsKernelFunction()));このコード行は、MCPツールを、指定されたAIモデルによって呼び出されるカーネル対応関数に変換します。
このセクションで必要なインポートは以下のとおりです:
usingMicrosoft.SemanticKernel.Function();
usingMicrosoft.SemanticKernel.Connectors.OpenAI.Perfect!完璧です!これで、Semantic Kernel AIアプリケーションのコアとなるカーネルが完全に構成されました。
ステップ #6: AIエージェントの定義
SemanticKernelから Agentクラスをインポートすることから始める:
Microsoft.SemanticKernel.Agents.Agentクラスを使ってください;次に、カーネルを使用して、自動的にツールを呼び出すように設定された新しいAIエージェントを初期化します:
var executionSettings = new OpenAIPromptExecutionSettings()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto() // LLMの自動関数呼び出しを有効にする。
};
var agent = new ChatCompletionAgent()
{
Name = "RedditAgent"、
カーネル = kernel、
引数 = new KernelArguments(executionSettings)、
};基本的に、ここで作成されたエージェントは、Bright Data Web MCPによって公開されたツールを実行することができます。AIモデルが、入力プロンプトに記述されたことを達成するために、1つ以上のツールが必要であると判断するときはいつでも実行されます。
このチュートリアルは、Reddit に焦点を当てたエージェントを作成することに焦点を当てているため、エージェントは “RedditAgent” と命名されていることに注意してください。別の目的でセマンティック・カーネルAIエージェントを作成する場合は、自分のプロジェクトに合わせて名前を変更してください。
クール次のステップは、エージェントを使ってプロンプトを実行するだけです。
ステップ #7: エージェントでタスクを実行する
Bright Data Web MCPによって提供されるツールで強化されたAIのためのデータ検索機能をテストするには、適切なプロンプトが必要です。例えば、以下のようにAIエージェントに特定のsubredditから情報を取得するように依頼することができます:
var prompt = @"
以下のsubredditからページをスクレイピングしてください:
https://www.reddit.com/r/webscraping/
スクレイピングされたコンテンツから、以下を含むMarkdownレポートを生成する:
- サブレディットの公式説明と主な統計情報(コミュニティタイプ、作成日)
- 最新の投稿~10件のURLリスト
"; これはウェブ検索機能をテストする理想的なタスクです。標準的なOpenAIのモデルは、このようなプロンプトを求められると失敗します。なぜなら、リアルタイムデータを取得するためにRedditのページにプログラムでアクセスできないからです:

注:上記の出力は信頼性に欠け、コンテンツの大半は嘘か完全に捏造されたものです。OpenAIのモデルは、Bright Dataが提供するような外部ツールなしでは、ウェブから新鮮なウェブデータを確実に取得することができません。
Web MCPで利用可能なツールのおかげで、エージェントは必要なRedditデータを取得し、正確な結果を提示することができます。タスクを実行し、結果をターミナルに表示します:
ChatMessageContent response = await agent.InvokeAsync(prompt).FirstAsync();
Console.WriteLine($"♪Response:♪Response.Content}");これは、1つのプロンプトをテストするのに十分です。実世界のシナリオでは、一般的に、以前のインタラクションを追跡するためのメモリを持つREPLループを実装することによって、エージェントを実行し続け、コンテキストを認識し続けたいと思うでしょう。
これで完成だ!あなたのRedditエキスパートAIエージェントは、Semantic Kernelで構築され、Bright Data Web MCPと統合され、完全に機能するようになりました。
ステップ #8: 全てをまとめる
Program.csの最後のコードは以下の通りです:
using Microsoft.Extensions.Configuration;
using ModelContextProtocol.Client;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Microsoft.SemanticKernel.Agents.OpenAI; using Microsoft.SemanticKernel.Connectors.OpenAI; using Microsoft.SemanticKernel.Connectors.OpenAI
// APIキーのユーザーシークレットと環境変数をロードする
var config = new ConfigurationBuilder()
.AddUserSecrets<Program>()
.AddEnvironmentVariables()
.Build();
// Bright Data Web MCP サーバー用の MCP クライアントを作成します。
await using var mcpClient = await McpClientFactory.CreateAsync(new StdioClientTransport(new())
{
Name = "BrightDataWebMCP"、
コマンド = "npx"、
引数 = ["-y", "@brightdata/mcp"]、
EnvironmentVariables = new Dictionary<string, string?
{
{ "API_TOKEN", config["BrightData:ApiKey"].},
// { "PRO_MODE", "true" }, // <-- オプション:プロモードを有効にする
}
}));
// Bright Data Web MCPサーバーで利用可能なツールのリストを取得する。
var tools = await mcpClient.ListToolsAsync().ConfigureAwait(false);
// セマンティック・カーネルを構築し、MCPツールをカーネル関数として登録する
var builder = Kernel.CreateBuilder();
builder.Services
.AddOpenAIChatCompletion(
modelId:"gpt-5-mini"、
apiKey: config["OpenAI:ApiKey"] です。
);
Kernel kernel = builder.Build();
// MCPツールからプラグインを作成し、カーネルのプラグインコレクションに追加します。
kernel.Plugins.AddFromFunctions("BrightData", tools.Select(aiFunction => aiFunction.AsKernelFunction()));
// LLMの自動関数呼び出しを有効にする
var executionSettings = new OpenAIPromptExecutionSettings()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// MCP統合AIエージェントの定義
var agent = new ChatCompletionAgent()
{
Name = "RedditAgent"、
Kernel = kernel.Arguments = new KernelArguments(executionSettings)、
Arguments = new KernelArguments(executionSettings), // MCPツールコールの設定を渡す
};
// subredditスクレイピングプロンプトでAIエージェントをテストする。
var prompt = @"
以下のsubredditからページをスクレイピングしてください:
https://www.reddit.com/r/webscraping/
スクレイピングされたコンテンツから、以下を含むMarkdownレポートを生成する:
- サブレディットの公式説明と主な統計情報(コミュニティタイプ、作成日)
- 最新の投稿~10件のURLリスト
";
ChatMessageContent response = await agent.InvokeAsync(prompt).FirstAsync();
Console.WriteLine($"♪Response:♪Response.Content}");すごい!わずか65行のC#で、Bright Data Web MCP統合のSemantic Kernel AIエージェントを構築しました。
エージェントを
dotnet run出力はこのようになります:
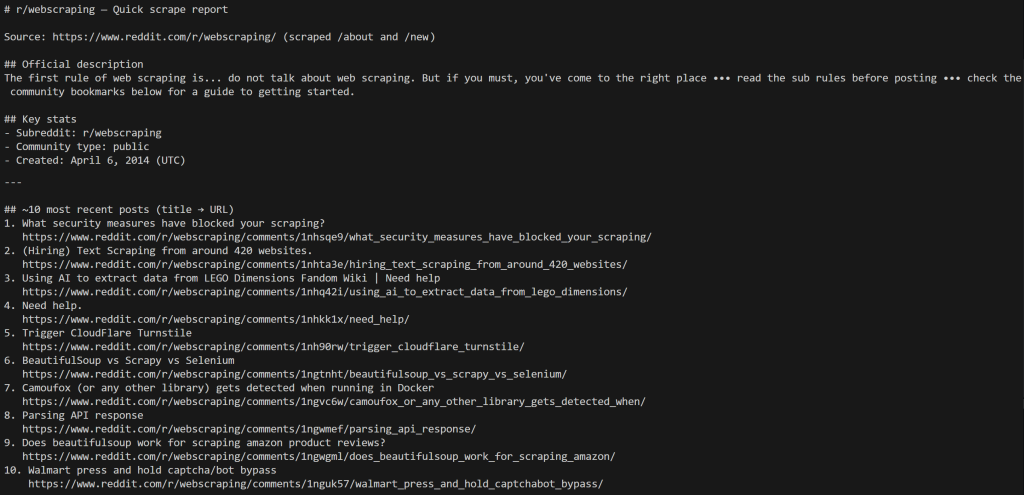
エージェントがサブレディット情報を取得するために/aboutページをスクレイピングし、最新の投稿を取得するために/newページをスクレイピングしたことに注目してください。
サブレディットの/aboutページにアクセスすれば確認できるように、出力に表示されているデータはすべて正しい:
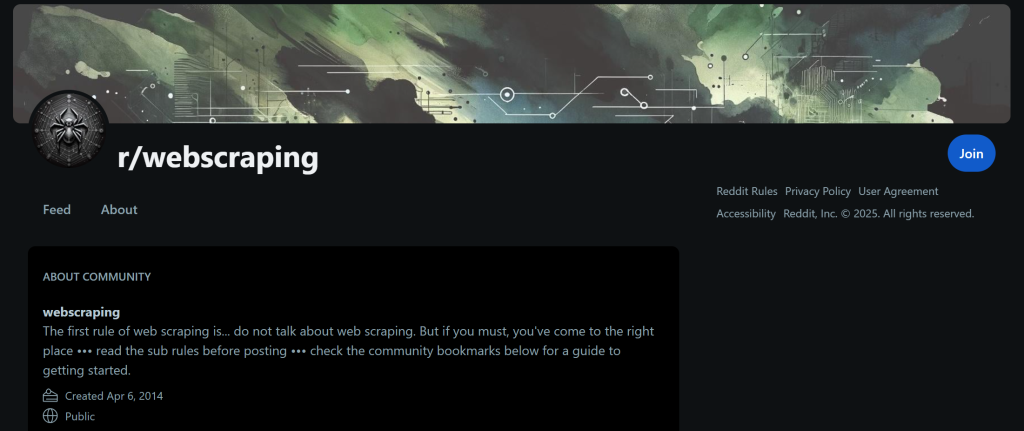
AIエージェントの出力データは、このページに表示されているものと完全に一致している。最新の投稿も同様で、サブレディットの/newページで確認できる。
唯一の違いは投稿の順番で、これはRedditのフロントエンドによって決定されるため、ここでは関係ない。
Redditのスクレイピングは、自動化されたリクエストをブロックするアンチボットシステムによって保護されているため、難しい。Bright Data Web MCPサーバーが提供するアンチボットバイパスのウェブスクレイピング機能のおかげで、AIエージェントはウェブデータの検索、対話、検索のための強力なツールセットを利用することができます。
この例は、可能なシナリオのほんの一例です。セマンティックカーネルを通じて利用可能な幅広いBright Dataツールにより、他の多くのユースケースに適応する、より複雑なエージェントを構築することができます。
出来上がりです!C#のSemantic Kernel AIエージェントでBright Data Web MCP統合のパワーを体験してください。
まとめ
このブログポストでは、Semantic Kernelで構築されたAIエージェントをBright DataのWeb MCP(現在は無料ティアが提供されています!)に接続する方法を紹介しました。この統合により、エージェントはウェブ検索、データ抽出、リアルタイムのインタラクションを含む強化された機能を得ることができます。
より高度なAIエージェントを構築するためには、Bright DataのAIインフラストラクチャの広範な製品とサービス群をご覧ください。これらのツールは、多様なAIワークフローとエージェントのユースケースを強化するように設計されています。
今すぐBright Dataの無料アカウントにサインアップして、AI対応のウェブデータソリューションの実験を始めてください!





