

このガイドで、あなたは学ぶだろう:
- Pipedreamとは何か、なぜ使うのか。
- 内蔵のスクレイピング・プラグインと統合すべき理由。
- PipedreamとBright Dataスクレイピングアーキテクチャを統合するメリット。
- PipedreamでWebスクレイピングのワークフローを作成するステップバイステップのチュートリアルです。
さあ、飛び込もう!
一目でわかるPipedream:自動化と統合を簡単に
Pipedreamは、様々なアプリケーションやサードパーティプロバイダーを接続するワークフローを構築・実行するためのプラットフォームである。詳細には、ノーコードとローコードの両方の機能を提供する。これらの機能により、事前構築されたコンポーネントやカスタムコードを通じて、プロセスを自動化し、システムを統合することができる。
以下はその主な特徴である:
- ビジュアルワークフロービルダー:ビジュアル・インターフェースを使用してワークフローを定義し、一般的なアプリケーション用の事前構築済みコンポーネントを接続します。現在、2700以上のアプリケーションの統合を提供しています。
- ノーコード/ローコード:専門知識を必要としません。それでも複雑なニーズには、Pipedreamのアプリケーションにカスタムコードノードを組み込むことができます。サポートされているプログラミング言語は、Node.js、Python、Go、Bashです。
- イベント駆動型アーキテクチャ:ワークフローは、HTTP/webhook、スケジュールされた時間、受信メールなどのイベントによってトリガーされます。従って、特定のトリガーイベントが発生するまで、ワークフローは休止状態となり、リソースを消費しません。
- サーバーレス実行:Pipedreamのコア機能はサーバーレスランタイムです。つまり、サーバをプロビジョニングしたり管理したりする必要がありません。Pipedreamはスケーラブルなオンデマンド環境でワークフローを実行します。
- ワークフローを構築するAI:プロンプトを挿入するだけのカスタムエージェントの作成に特化したAI、Deal withString。Pipedreamに特に詳しくない方でも利用できます。プロンプトを記述し、AIにワークフローを構築させることができます。
なぜコード化しないのか?すぐに使えるスクレイピング統合のメリット
Pipedreamはコードアクションをサポートしています。これにより、(サポートされている言語の中から)好きな言語で完全なスクリプトをゼロから書くことができます。技術的には、これらのノードを使ってPipedream内でスクレイピングボットを構築することも可能です。
一方で、そうすることでスクレイピングのワークフローを構築するプロセスが簡素化されるとは限らない。スクレイピング対策に関連する通常の課題や障害に直面することになる。
そのため、これらの複雑な処理を代行してくれるビルトインスクレイピングプラグインに頼る方が、より実用的で効果的、かつ迅速です。PipedreamのBright Data統合はまさにそのような体験を提供してくれます。
以下は、Bright Dataスクレイピングプラグインを利用する最も重要な理由のリストです:
- 簡単認証:PipedreamはBright DataのAPIキー(認証に必要)を安全に保管し、簡単な操作性を提供します。認証のためのカスタムコードを記述する必要がなく、キーを公開することもありません。
- アンチボットシステムの克服Bright Data APIは、プロキシのローテーションやIP管理からCAPTCHAの解決やデータの解析まで、ウェブスクレイピングに関するあらゆる課題を解決します。こうすることで、Pipedreamのワークフローは一貫性のある高品質なウェブデータを確実に受け取ることができます。
- 構造化されたデータ:スクレイピング後、コードを一行も書くことなく、構造化され整理されたデータを得ることができる。このプラグインは、あなたの代わりにデータの構造化を行います。
PipedreamとBright Data Pluginを組み合わせる主な利点
Pipedreamの自動化機能とBright Dataを接続すると、以下のことが可能になります:
- 新鮮なデータにアクセスウェブスクレイピングの目的はウェブからデータを取得することですが、Bright Dataはそのお手伝いをします。しかし、データは時間とともに変化します。分析を古くしたくないのであれば、常に新鮮なデータを抽出する必要があります。そこでPipedreamの力が役に立ちます(スケジューリングトリガーなど)。
- スクレイピングのワークフローにAIを組み込む:PipedreamはChatGPTや Geminiのような複数のLLMと統合しています。これにより、手作業で何時間もかかるようなタスクを自動化することができます。例えば、ECサイトの競合商品リストを監視するRAGワークフローを構築することができます。
- 技術的なことを単純化する:ウェブサイトは、ほぼ毎週更新される高度なアンチスクレイピング・ブロック技術を採用しています。Bright Dataの統合は、ボット対策をすべて行うため、ブロックを回避することができます。
Pipedreamのスクレイピングワークフローで、Bright Dataの統合を実際に見てみましょう!
PipedreamとBright DataでAIスクレイピングワークフローを構築:ステップバイステップのチュートリアル
このガイドセクションでは、Bright Dataを使ってAmazonの 商品からデータを取得するPipedreamワークフローの構築方法を学びます。具体的には、以下のようなページを作成します:
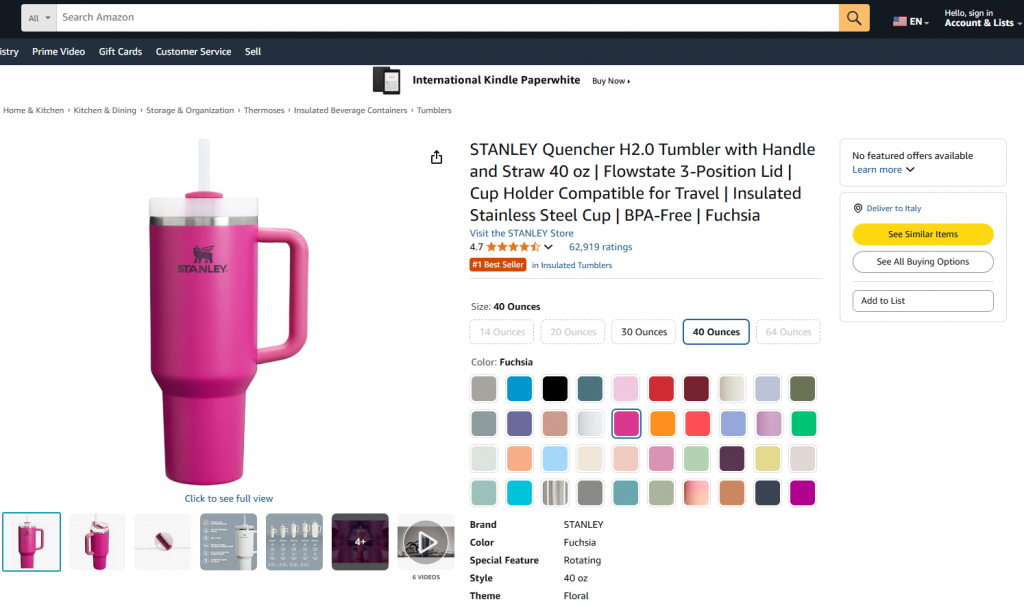
目標は、以下のようなPipedreamワークフローの作成方法を紹介することです:
- Bright Data統合を使用して、対象のWebページからデータを取得します。
- LLMにデータをインジェストする。
- LLMにデータを分析し、そこから製品概要を作成するよう依頼する。
Pipedreamでこのようなワークフローを作成し、テストし、デプロイする方法については、以下の手順に従ってください。
必要条件
このチュートリアルを再現するために必要なもの:
- Pipedreamのアカウント(無料アカウントで十分です)。
- Bright Data APIキー。
- OpenAI API キー。
まだお持ちでない方は、上記のリンクから手順に従ってセットアップしてください。
また、チュートリアルに従うためには、この知識を持っていることが助けになる:
- Bright Dataのインフラや製品(特にWeb Scraper API)に精通していること。
- AI処理(LLMなど)の基本的な理解。
- WebhookによるトリガーやAPIコールの仕組みに関する知識。
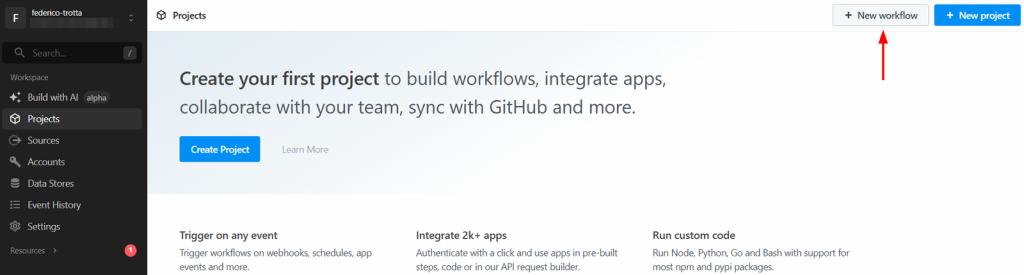
ステップ1:新しいPipedreamワークフローを作成する
Pipedreamアカウントにログインし、ダッシュボードに移動します。新規ワークフロー」ボタンをクリックし、新規ワークフローを作成します:
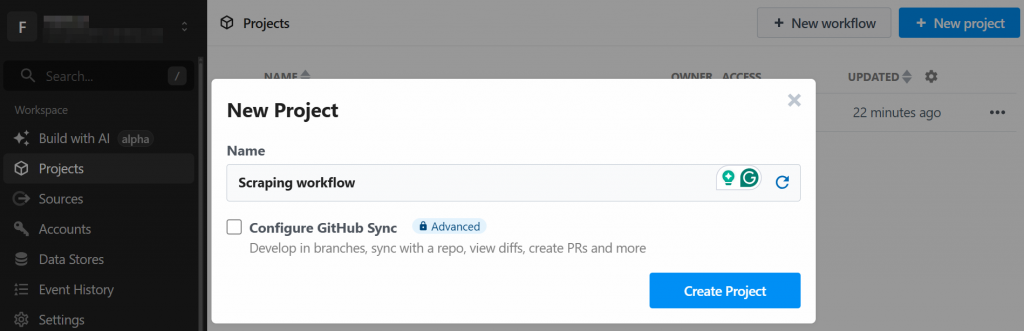
新しいプロジェクトを作成するように指示されます。名前を付けて「プロジェクトを作成」ボタンをクリックしてください:
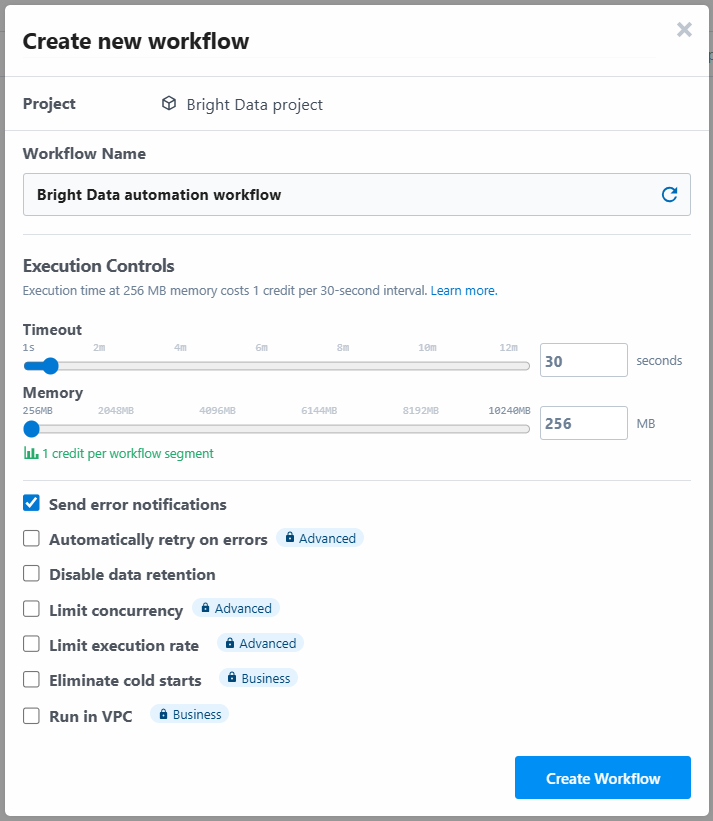
ツールは、ワークフローに名前を割り当て、その設定を定義するよう求めます。設定はそのままにして、最後に「ワークフローを作成」ボタンを押してください:
新しいワークフローのUIは以下のように表示されます:
よろしい!Pipedreamで新しいワークフローを作成しました。これで、プラグインの統合を追加する準備が整いました。
ステップ2:トリガーを追加する
Pipedreamでは、全てのワークフローはトリガーから始まります。Add trigger “をクリックすると、選択できるトリガーが表示されます:
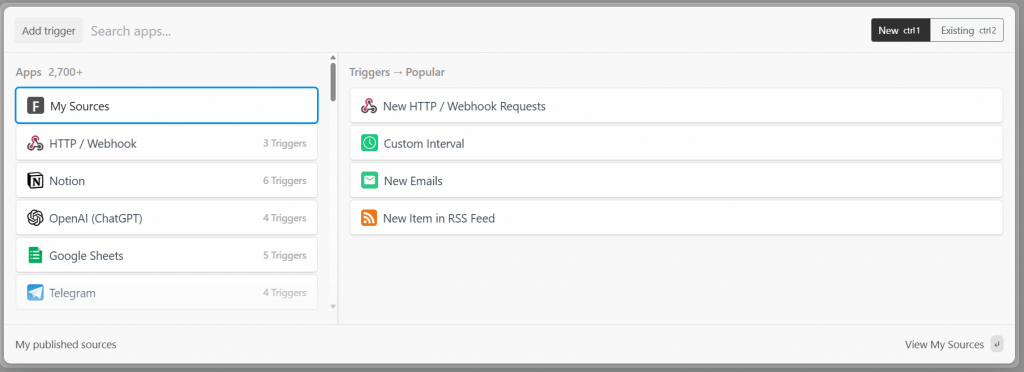
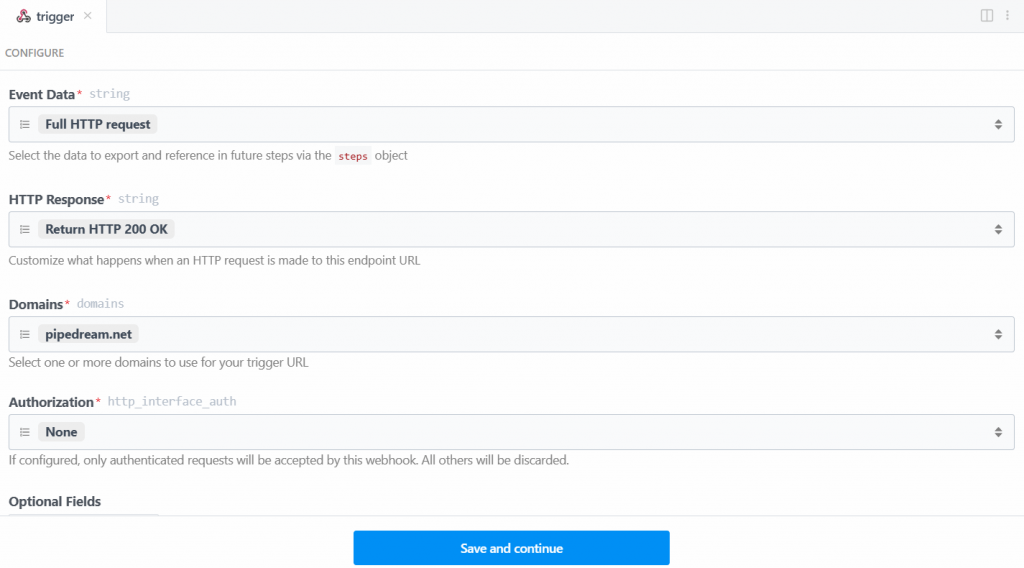
この場合、Bright Dataとの接続に必要なトリガー “New HTTP/Webhook Requests “を選択します。プレースホルダデータはそのままにして、”Save and continue “ボタンをクリックします:
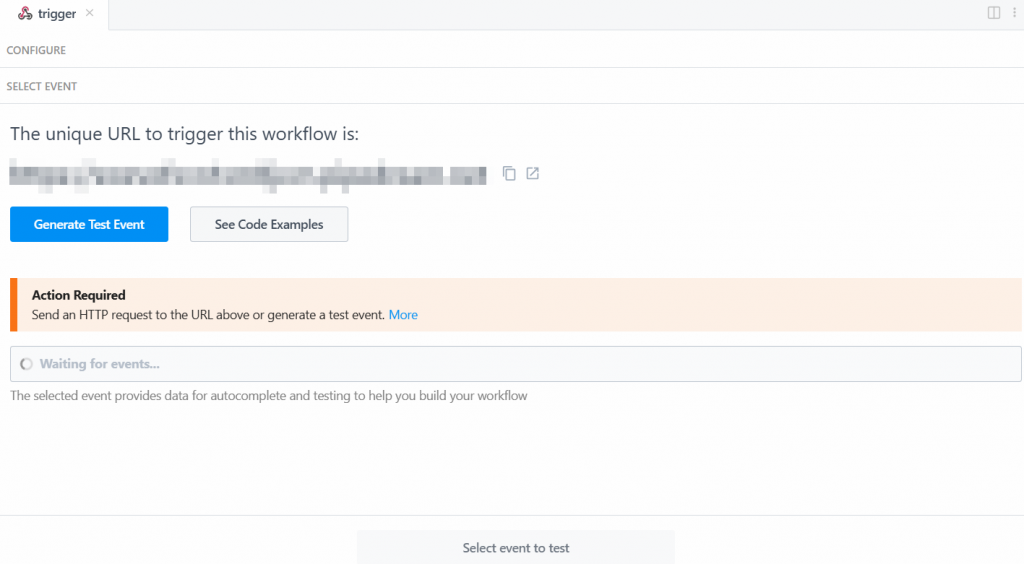
トリガーを動作させるには、イベントを生成する必要がある。そこで、”Generate Test Event “をクリックする:
システムは、以下のように、テスト・イベントの定義済みの値を提供する:
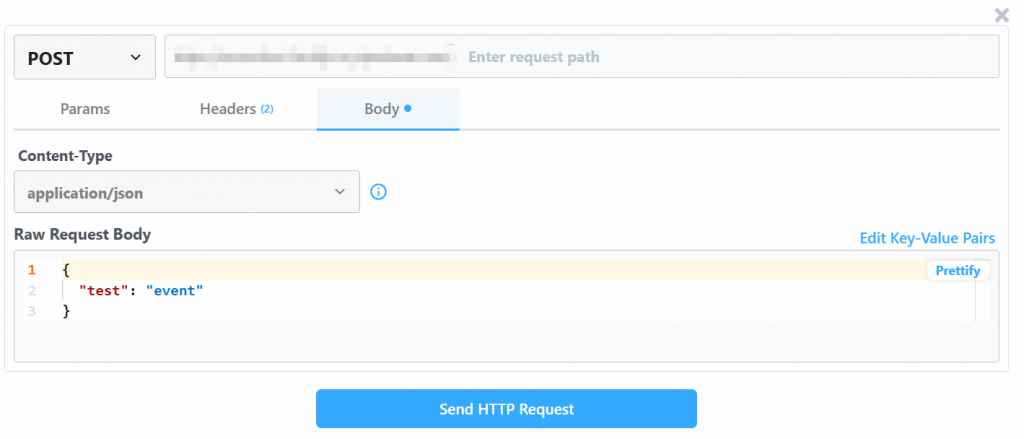
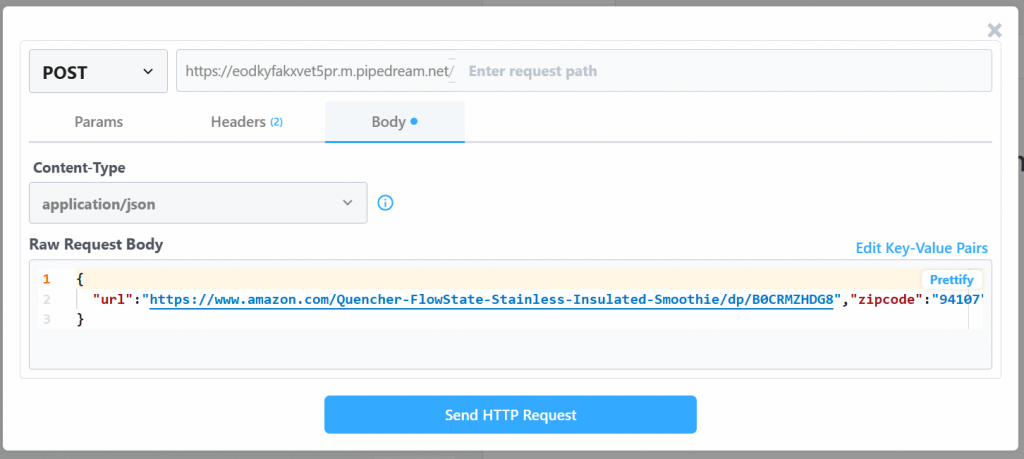
生のリクエスト・ボディ」の値を変更する:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
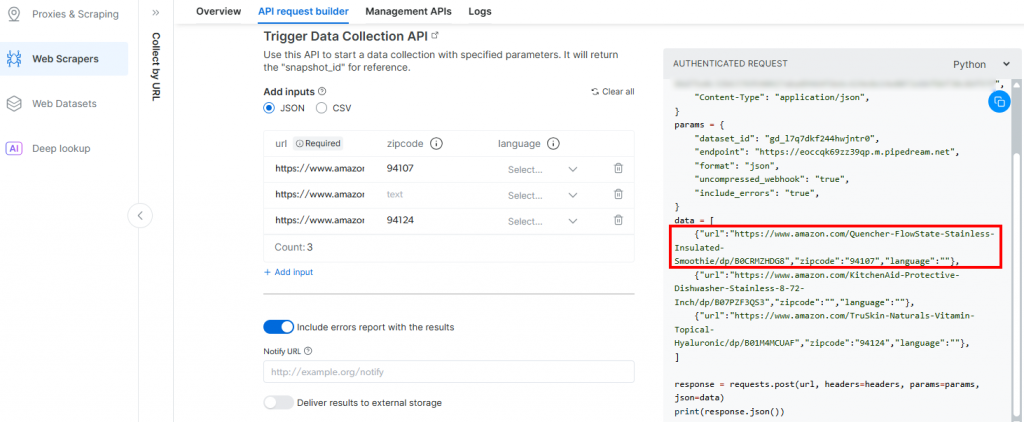
}Pipedreamによって生成されたトリガーが、Bright DataのAmazon Scraper APIへの呼び出しを開始するからだ。このエンドポイント(後で設定します)は、その特定のペイロード形式の入力データを必要とします。これは、Bright DataのAamzon Web Scrapersの “Collect by URL“スクレイパーの “API Request Builder “セクションを確認することで確認できます:
Pipedreamのウィンドウに戻り、”Send HTTP Request “ボタンをクリックします。期待通りであれば、結果欄に成功のメッセージが表示されます。トリガーの色も緑になります:
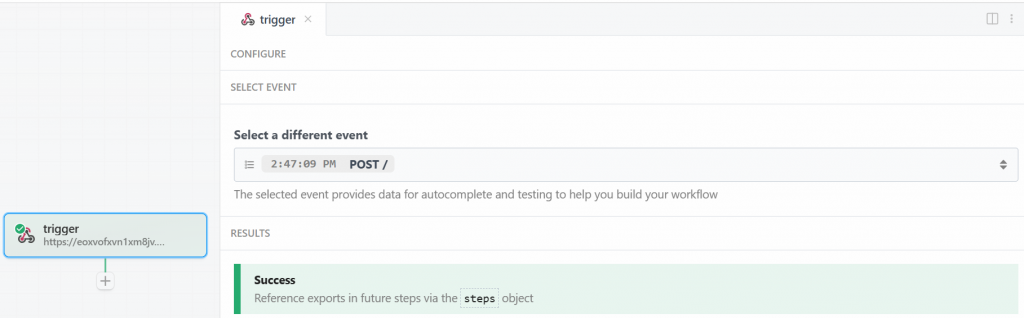
完璧です!PipedreamスクレイピングワークフローでBright Data統合を開始するトリガーが正しく設定されました。これでアクションを追加する準備ができました。
ステップ #3: Bright Dataアクションステップの追加
トリガーの後、Pipedreamワークフローにアクションステップを追加することができます。ここで必要なのは、Bright Dataステップをトリガーに接続することです。そのためには、トリガーの下にある “+”をクリックし、”bright data “を検索します:
PipedreamはBright Dataプラグインからいくつかのアクションを提供します。すべて見るには選択してください:
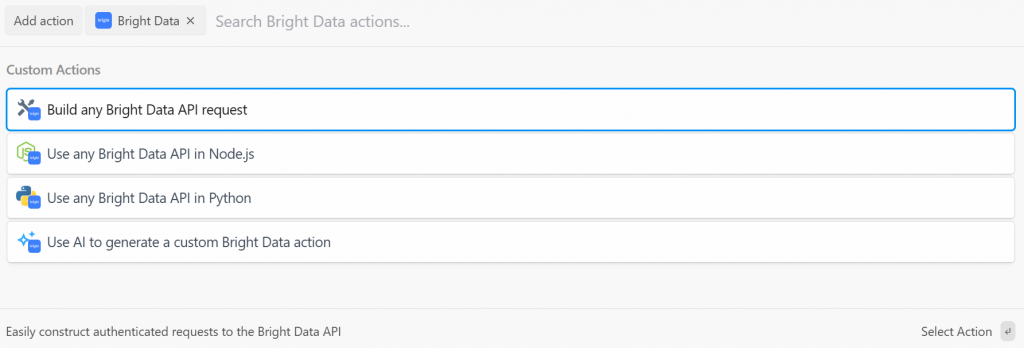
選択肢は以下の通り:
- Bright Data API リクエストを作成します:Bright Data API への認証済みリクエストを作成します。
- Node.js/Pythonで任意のBright Data APIを使用します:Bright DataアカウントをPipedreamに接続し、Node.js/Pythonでリクエストをカスタマイズします。
- AIを使ってBright Dataのカスタムアクションを生成します:AIにBright Dataのカスタムコードを生成してもらう。
このチュートリアルでは、”Use any Bright Data API in Python” オプションを選択します。このように表示されます:
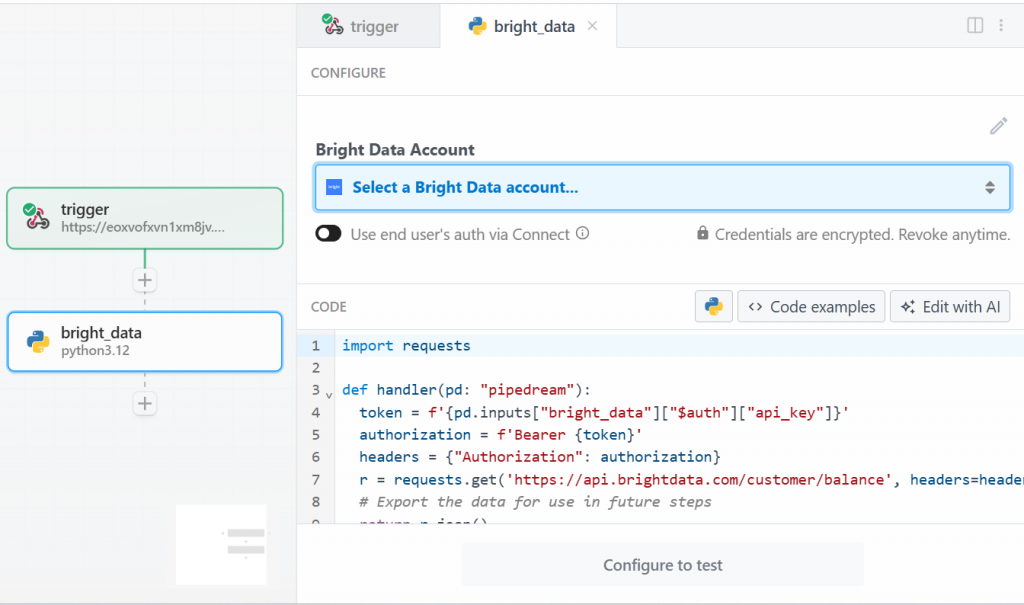
まず、「Bright Data Account」の「Select a Bright Data account」をクリックし、Bright Data APIキーを追加します。まだ行っていない場合は、必ず公式ガイドに従ってBright Data APIキーを設定してください。
次に、「CODE」セクションのコードを削除し、以下のように記述する:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}このコードは次のようなものである:
handler()関数は、Pipedream のレベルでワークフローを管理します。それは- Pipedream に保存した Bright Data API キーを取得します。
- ターゲットURL、データセットID、およびそれに必要なすべての特定のデータの側でBright Data APIリクエストを設定します。
- 応答を管理します。何か問題があれば、Pipedreamのログにエラーが表示されます。
poll_and_retrieve_snapshot()関数は、スナップショットの準備ができるまで Bright Data API をポーリングする。準備ができると、要求されたデータを返します。何か問題が発生した場合は、エラーを管理し、ログに表示します。
準備ができたら、”Test “ボタンをクリックします。RESULTS “セクションに成功のメッセージが表示され、Bright Dataアクションステップが緑色になります:
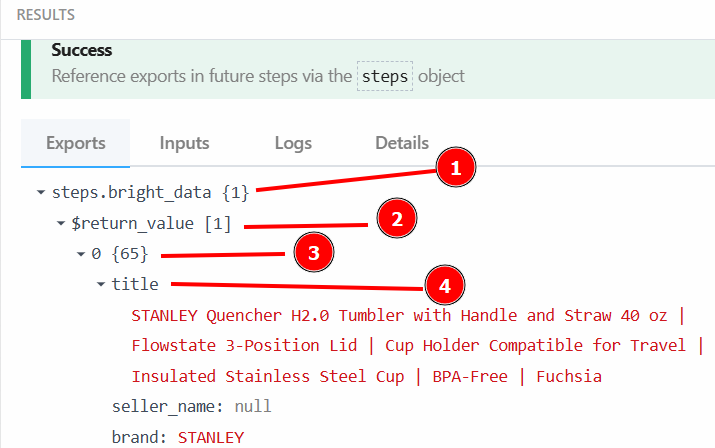
RESULTS “の下にある “Exports “セクションで、スクレイピングされたデータを見ることができる:
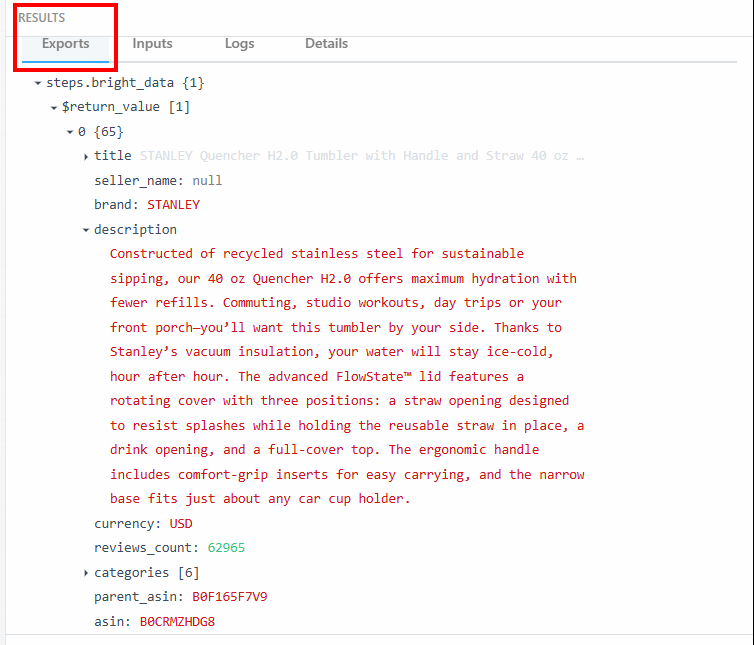
以下は、スクレイピングしたデータをテキスト化したものである:
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}このデータとその構造は、ワークフローの次のステップで使用する。
素晴らしい!PipedreamのBright Dataアクションのおかげで、対象データが正しくスクレイピングされました。
ステップ #4: OpenAIのアクションステップを追加する
Amazonの商品データは、Beight Dataインテグレーションによって正常にスクレイピングされました。さて、これをLLMにフィードすることができます。これを行うには、”+”ボタンをクリックして新しいアクションを追加し、”openai “を検索します。ここで、様々なオプションを選択することができます:

Build any OpenAI (ChatGPT) API request” オプションを選択し、”Chat” オプションを選択します:
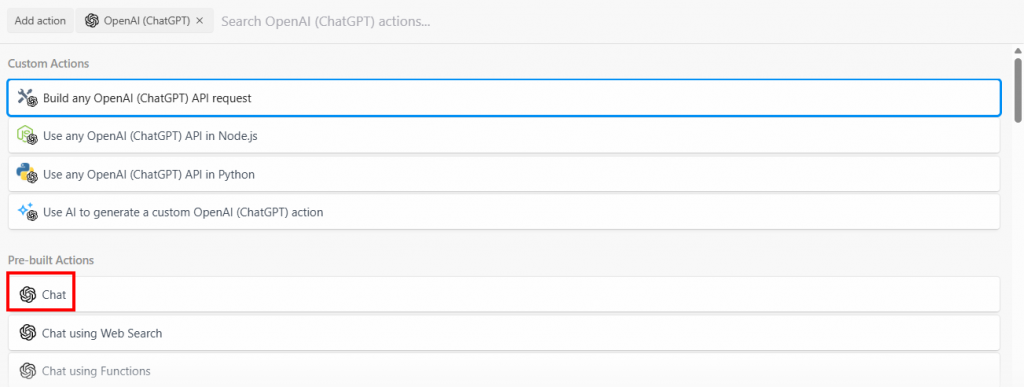
以下は、このアクションステップの設定セクションである:
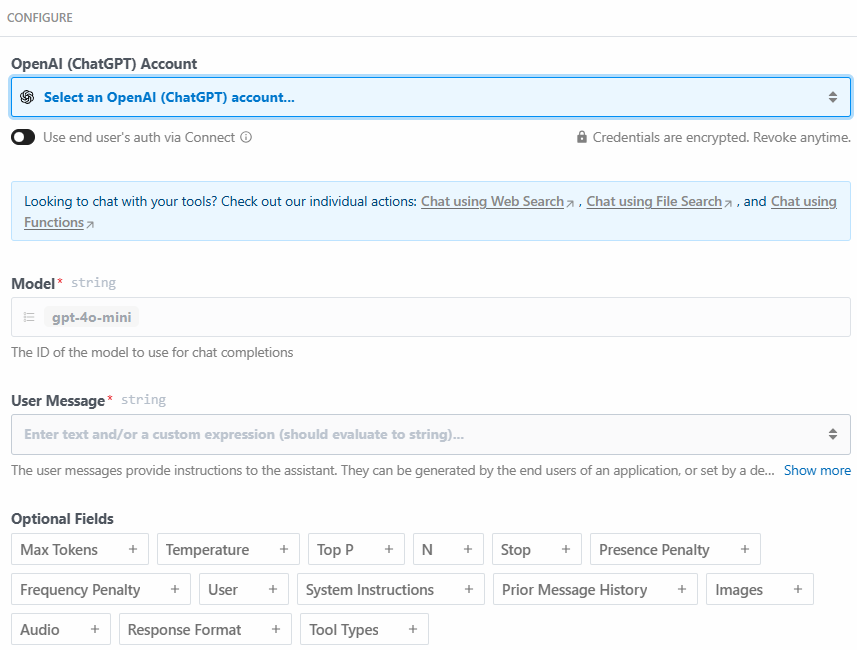
Select an OpenAI (ChatGPT) account… “をクリックして、OpenAIプラットフォームAPIキーを追加します。次に、”User Message “セクションに以下のプロンプトを記述します:
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.プロンプトはLLMに尋ねる:
- 専門的な製品アナリストとして行動しなさい。この指示により、LLMは専門的な製品アナリストとして行動することになるからである。これは、LLMがその業界に特化した回答をするのに役立つからである。
- 商品タイトルや説明文など、Bright Dataステップで抽出されたデータを考慮します。これにより、LLMは必要な特定のデータに焦点を当てることができます。
- スクレイピングされたデータに基づいて、製品の概要を記述する。このプロンプトは、要約が含まなければならない内容についても具体的に示している。ここで、商品要約のためのAI自動化の威力が発揮される。LLMはスクレイピングされたデータに基づいて、商品の専門家として商品の要約を作成する。
商品タイトルは{{steps.bright_data.$return_value[0].title}}で取得することができます:
Test “をクリックしたら、OpenAI Chat アクションステップの “Generated message” > “content “の “RESULTS “セクションで、LLM の出力を見つけます:
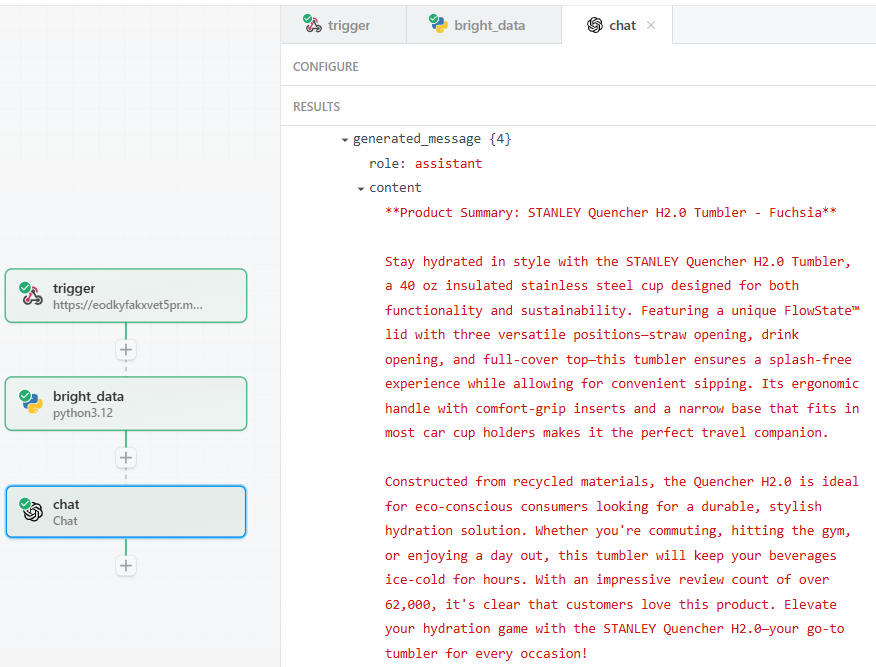
以下は、考えられるテキスト結果である:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!お分かりのように、LLMは商品の専門家として商品の概要を説明した。この要約は、プロンプトが求めていることを正確に報告している:
- 製品とは何か。
- その重要な特徴のいくつかを紹介しよう。
評価数のような正確なデータを抽出したい理由は、LLMが幻覚を見ていないことを確認するためだ。サマリーには62,000件以上のレビューがあると書かれている。正確な数を見たい場合は、結果の「コンテンツ」フィールドで確認できる:
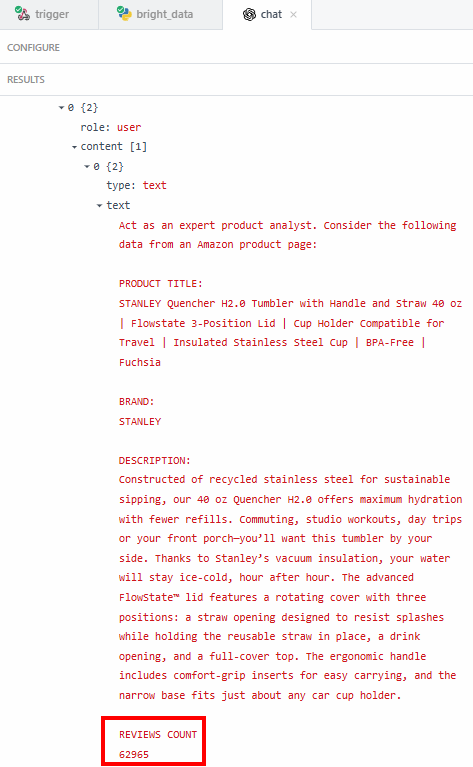
そして、その番号がアマゾンの商品ページに表示されている番号と一致するかどうかを確認する必要がある。
最後に、アマゾンのような大手eコマースサイトをスクレイピングしようとしたことがある人なら、自力でスクレイピングするのがどれほど難しいか知っているだろう。例えば、悪名高いアマゾンのCAPTCHAに遭遇するかもしれない:
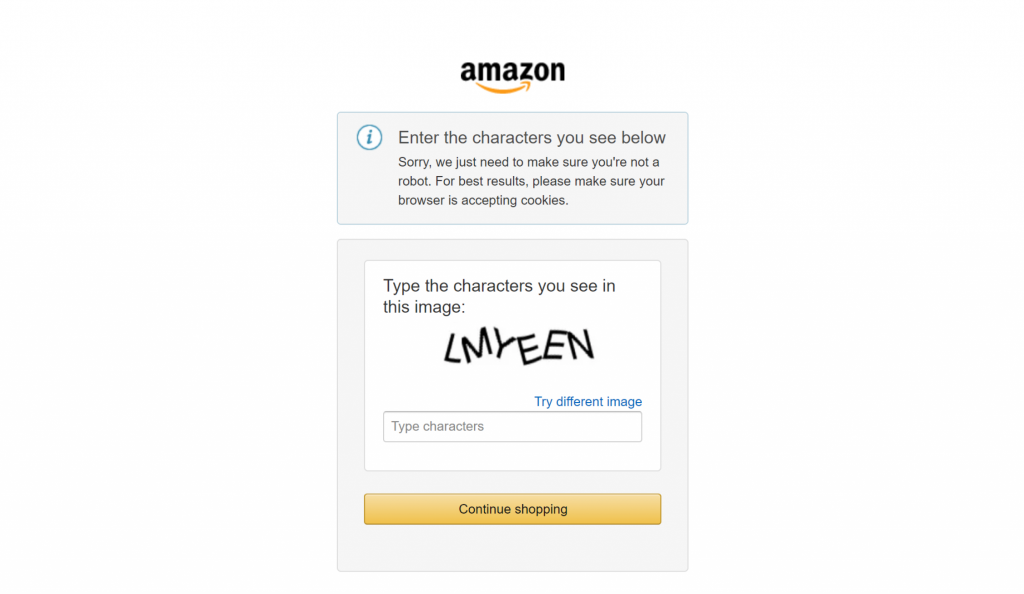
Bright Dataとの統合は、スクレイピングのワークフローを大きく変えます。裏でスクレイピング対策を行い、データ取得プロセスがスムーズに行われるようにします。
素晴らしい!LLMステップのテストに成功しました。これでワークフローをデプロイする準備ができました。
ステップ #5: ワークフローの展開
ワークフローをデプロイするには、”Deploy “ボタンのいずれかをクリックします:
以下は、配備後に表示されるものです:
ワークフロー全体を実行するには、”Generate Event “をクリックします:
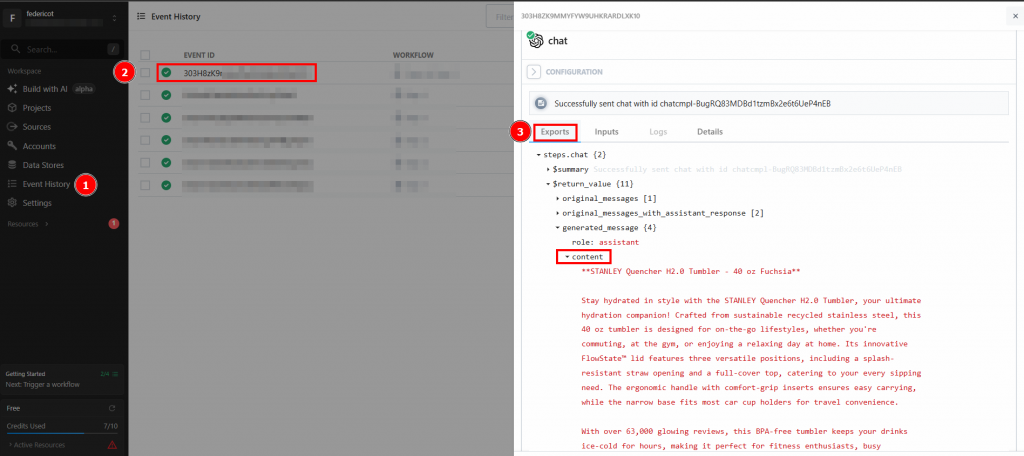
Send HTTP Request “をクリックすると、ワークフローが実行される。デプロイされたワークフローの結果を見るには、ホームページの “Events history “にアクセスする。興味のあるワークフローを選択し、”Exports “で結果を確認する:
これで完了です!Pipedream で Bright Data を使った最初のスクレイピングワークフローが完成しました。
結論
このガイドでは、Pipedreamを使って自動化されたWebスクレイピングワークフローを構築する方法を学びました。Pipedreamの直感的なインターフェースとBright Dataのスクレイピング統合により、洗練されたスクレイピングパイプラインを数分で簡単に構築することができます。
データ主導の自動化における主要な課題は、クリーンで信頼性の高いデータの一貫したフローを確保することです。Pipedreamは自動化とスケジューリングのエンジンを提供し、Bright DataのAIインフラはウェブスクレイピングの複雑さを処理し、すぐに使えるデータを提供します。この相乗効果により、データ取得の技術的なハードルではなく、データから価値を生み出すことに集中することができます。
無料のBright Dataアカウントを作成し、今すぐAI対応データツールの実験を始めましょう!






