

このチュートリアルでは、以下の内容を学びます:
- MastraがAIエージェント構築のためのソリューションとして何を提供するか。
- MastraのAIエージェントがウェブを探索できることで、なぜ大幅に強力になるのか。
- Bright DataツールとのインテグレーションによってウェブアクセスをMastra AIエージェントに組み込む方法。
- (オプション)MastraをBright Data Web MCPに接続する方法。
それでは始めましょう!
Mastraとは?
Mastraは、AIを活用したエージェントやアプリケーションを構築するための最新のTypeScriptフレームワークです。エージェント・ワークフロー・RAG・メモリ・MCP・オブザーバビリティを統合されたシステムで構築・管理するためのAPIを提供します。
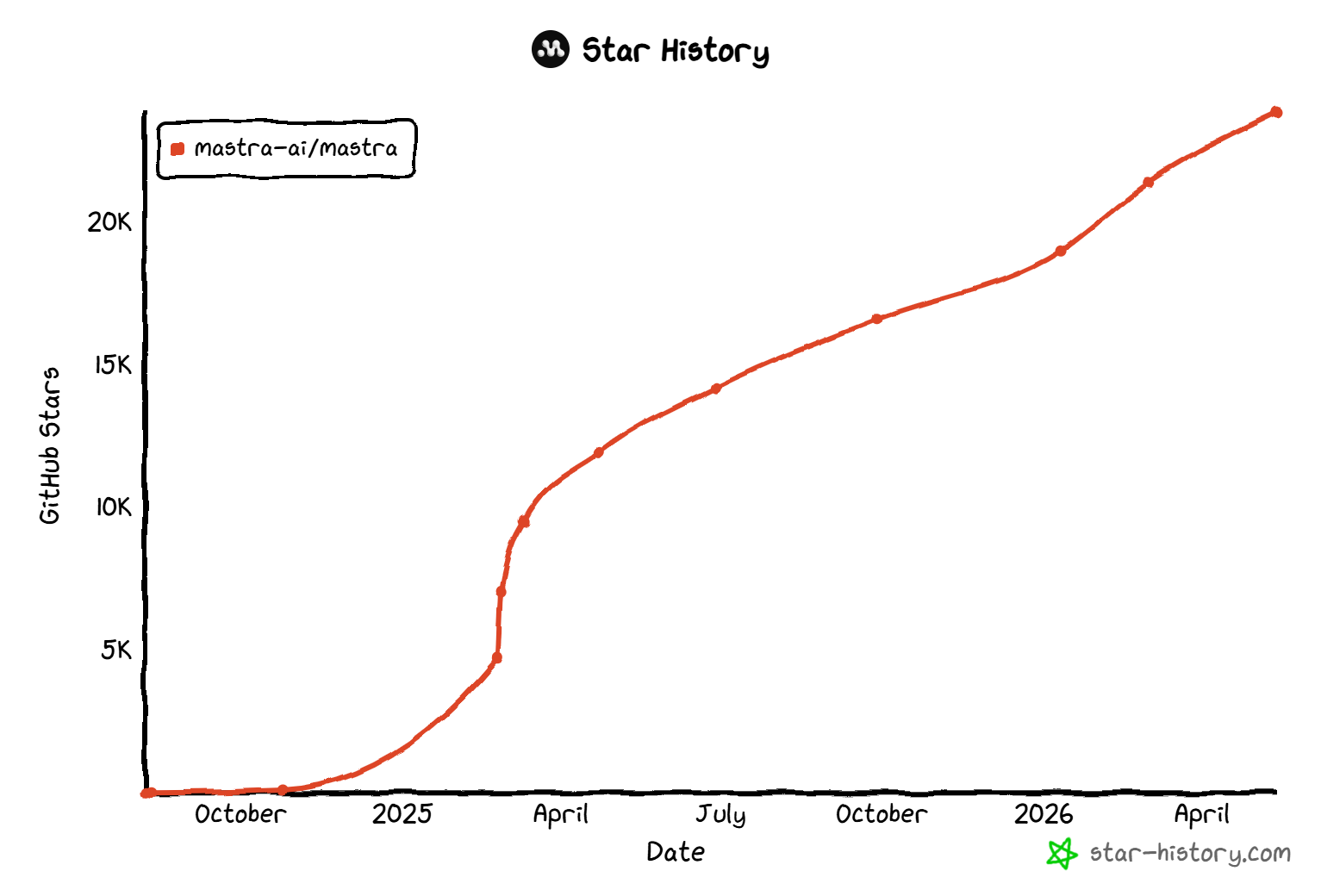
Mastraはオープンソースで広く採用されており、GitHubスターは23,800件を超えています。これはコミュニティの強い信頼とエコシステムの急速な成長を反映しています。
このソリューションが提供する主な機能は以下のとおりです:
- エージェント:推論・ツール活用・反復処理によって複雑なユーザー定義タスクを完遂する自律型AIエージェントを構築できます。
- ワークフロー:分岐・並列ステップ・制御された決定論的ロジックを備えたグラフベースの構造化実行で、マルチステッププロセスをオーケストレーションします。
- RAG:検索拡張生成パイプラインを使用して、根拠のあるコンテキスト認識型の応答を生成するために、エージェントを外部知識ソースに接続します。
- メモリ:短期・長期のコンテキストを維持することで、エージェントが会話を記憶し、インタラクション間の連続性を向上させます。
- ツール:外部API・関数・インテグレーションによってエージェントの能力を拡張し、現実世界のアクションと動的なデータアクセスを実現します。
- MCP: Model Context Protocolサーバーを統合し、ツール・エージェント・構造化リソースをシステム間で公開・利用します。
- オブザーバビリティ:ログ・トレース・メトリクス・パフォーマンス評価ツールを使用して、エージェントの動作を追跡・評価・デバッグします。
詳細は公式ドキュメントをご覧ください。
Mastra AIエージェントにウェブ検索・スクレイピングツールを拡張する理由
MastraはAI駆動のアプリケーションやエージェントを構築するための充実したフレームワークです。しかし、設計が優れたAIシステムであっても、古いまたは不完全な情報に依存している場合、品質の低い出力を生成したり精度が低下したりする可能性があります。
これはLLMの根本的な制限であり、静的なデータセットで学習されるため、リアルタイムの認識を持ちません。その結果、古いコンテキストに基づいてハルシネーションを起こしたり、誤った判断を下したりする可能性があり、精度と信頼性が低下します。
この問題を解決するには、AIアプリケーションがリアルタイムのウェブデータインフラにアクセスできる必要があります。まさにここでBright Dataの出番です!
解決策:MastraのためのBright Dataツール
Bright Dataは以下の公式ツールを通じてMastraをサポートします:
webSearch:Google・Bing・Yandexなどの検索エンジンでウェブ検索を実行します。AIエージェントですぐに利用できるJSON形式の構造化SERP結果を返します。Bright DataのSERP APIによって動作します。webFetch:Bright DataのWeb Unlocker APIを使用して、任意のウェブページのコンテンツを取得します。ボット対策やCAPTCHAシステムを回避して、あらゆるドメインからライブウェブデータにアクセスします。
このオープンソースインテグレーションにより、Mastraアプリケーションは本番グレードのウェブデータインフラにアクセスできるようになります。これにより、エージェントが新鮮な情報源を発見し、リアルタイム情報を取得し、学習データと現実との乖離を埋めることが可能になります。
Bright Dataが際立っている理由は、195カ国にわたる4億件以上の住宅用IPという広大なグローバルインフラです。99.99%のアップタイムと99.95%の成功率を維持しながら、無制限の同時接続を実現します。
ウェブデータアクセスのためにBright DataをMastra AIエージェントに接続する方法
このステップバイステップのセクションでは、Bright DataツールをインテグレーションしたMastra AIエージェントを新たにセットアップする手順を解説します。
以下の手順に従って進めてください!
前提条件
このチュートリアルを進めるには、以下が必要です:
- Gitがローカルにインストール済みであること。
- Node.js v22.13.0以降がインストール済みであること(最新のLTSバージョンを推奨)。
- MastraがサポートするAIモデルプロバイダーからのAPI key(本チュートリアルではOpenAIのAPI keyを使用します)。
- API keyが設定されたBright Dataアカウント。Bright Dataアカウントの作成とAPI keyの設定方法については、公式ドキュメントガイドをご覧ください。
ステップ#1:新しいMastraプロジェクトを初期化する
注意:すでにMastraプロジェクトが存在する場合は、このステップをスキップできます。
create-mastraユーティリティを使用して、mastra-bright-data-web-access-agentという名前の新しいMastraプロジェクトを作成します:
npx create-mastra@latest mastra-bright-data-web-access-agentプロンプトが表示されたら、AIプロバイダーを選択します。

ここでは「OpenAI」を選択し、API keyを手動で入力するオプションを選びます。プロンプトが表示されたら、OpenAIのAPI keyを貼り付けます:

次に、Mastraのオブザーバビリティを有効にするかどうか確認されます。必要に応じて選択し、残りのセットアッププロンプトを続けます。
セットアップが完了したら、プロジェクトディレクトリに移動します:
cd mastra-bright-data-web-access-agent以下のようなプロジェクト構造が確認できるはずです:
mastra-bright-data-web-access-agent/
├── .agents/ # Internal Mastra directory for agent skills, etc.
├── node_modules/
└── src/
│ └── mastra/
│ ├── index.ts # Entry point that initializes the Mastra setup
│ ├── agents/
│ │ └── weather-agent.ts # Defines the default Weather AI agent
│ ├── scorers/
│ │ └── weather-scorer.ts # Scoring logic to evaluate or rank agent outputs
│ ├── tools/
│ │ └── weather-tool.ts # External tool integrations used by the agent
│ └── workflows/
│ └── weather-workflow.ts # Logic combining tools and agents
├── .env # Environment variables (API keys, secrets, etc.)
├── .gitignore
├── AGENTS.md # Docs describing available agents and their behavior
├── package-lock.json
├── package.json
├── README.md # Main project documentation
└── skills-lock.json このフォルダにはデフォルトのMastra天気AIエージェントプロジェクトが含まれています。これはMastraでエージェント・ツール・スコアラー・ワークフローを構築する方法を示すための最小限のテンプレートです。
ファイルを探索して内容を把握してください。例えば、.envファイルを開くと、セットアップ中に設定したOpenAIのAPI keyが確認できます。また、以下のコマンドでエージェントを実行してみることもできます:
npm run devお疲れ様です!Mastraプロジェクトのセットアップができましたので、次はBright Dataツールを追加します。
ステップ#2:Bright DataツールをインストールしてConfigureする
まず、Mastra Bright DataツールとZodの依存パッケージをインストールします:
npm install @mastra/brightdata zod@mastra/brightdataパッケージはBright Data JavaScript SDKをラップし、スクレイピングとウェブ検索のメソッドをMastra互換のツールとして公開します。
Bright Data JavaScript SDKが動作するには、環境変数BRIGHTDATA_API_TOKENが必要です。.envファイルに追加してください:
BRIGHTDATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_BRIGHT_DATA_API_KEY>プレースホルダーを実際のBright DataのAPI keyに置き換えてください。API keyはSDKがBright Data APIへのリクエストを認証するために使用されます。
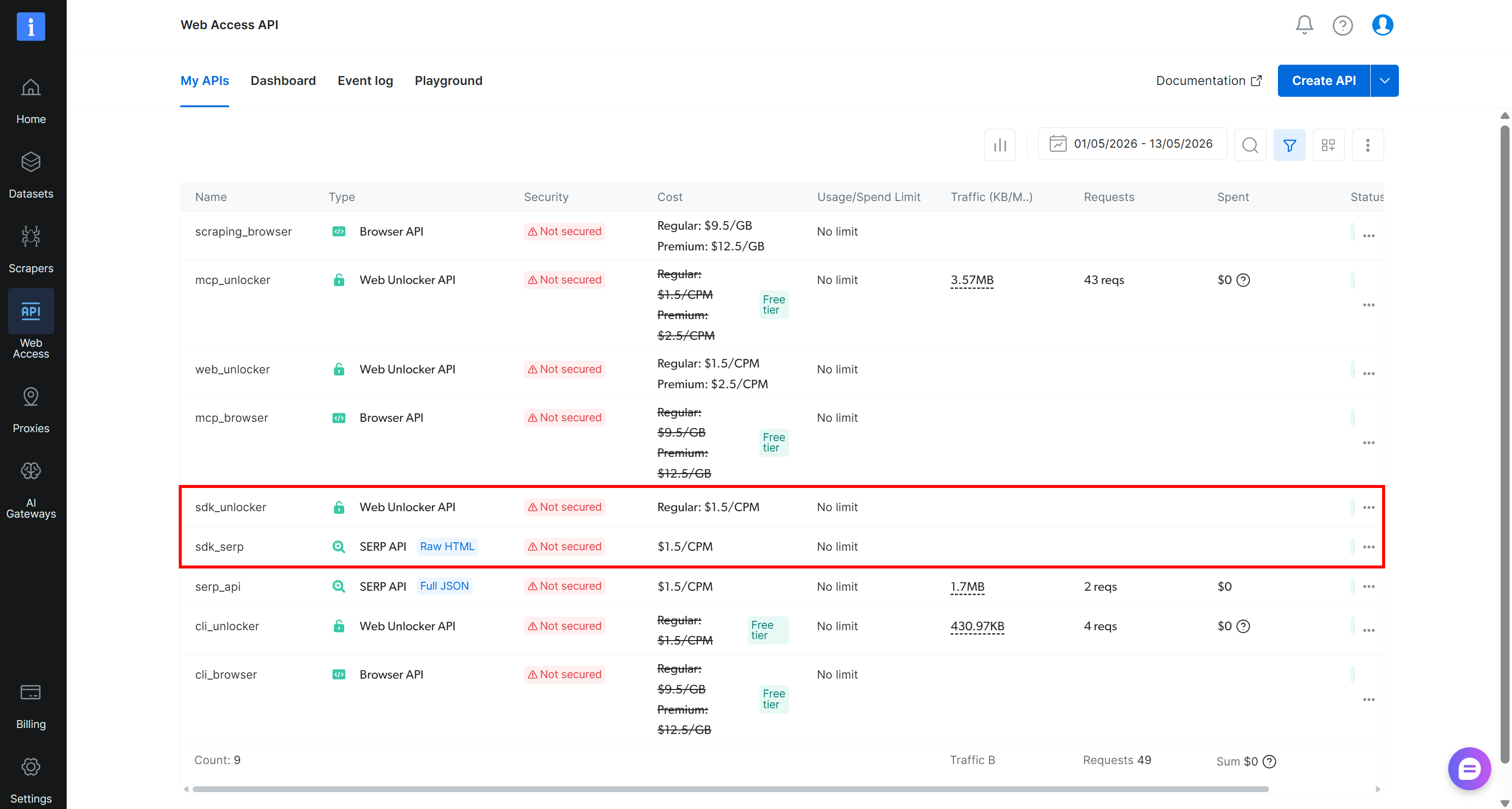
設定が完了すると、@mastra/brightdataツールがBright Dataアカウントに接続できるようになります。初回使用時に、Bright Data SDKはBright Dataダッシュボードで必要なAPIを自動的にプロビジョニングします(Web Unlocker APIとSERP APIゾーンが含まれます):
ステップ#3:Bright Dataツールを追加する
この時点でBright Data Mastraツールのインストールが完了しました。次に、AIエージェントにツールを設定して公開する必要があります。
src/mastra/tools/内に新しいweb-access.tsファイルを作成します:
// src/mastra/tools/web-access.ts
import { createBrightDataTools } from '@mastra/brightdata'
// create the web search and web fetch tools using the BrightData client options
export const { webSearch, webFetch } = createBrightDataTools({
verbose: true, // enable verbose logging for debugging purposes
})このコードは@mastra/brightdataパッケージからcreateBrightDataTools()をカスタム設定で呼び出します。必要なBright DataのAPI keyはBRIGHTDATA_API_TOKEN環境変数から自動的に読み取られます。同様に、ゾーン名はデフォルトで自動的に推論または作成されます。必要に応じて、createBrightDataTools()の追加オプションでAPI keyとゾーンを明示的に設定することもできます。
createBrightDataTools()関数は2つのMastra互換ツールを生成します:
webSearch:Bright DataのSERP APIを使用して、AIエージェントにウェブ検索機能を提供します。webFetch:Bright DataのWeb Unlocker APIを呼び出して、任意のウェブサイトのコンテンツを取得・スクレイピングします。
注意:別の方法として、createBrightDataSearchTool()とcreateBrightDataFetchTool()を使って各ツールを個別に作成・設定することもできます。よりきめ細かい制御を好む場合はこちらのアプローチが推奨されます。
これらのツールをエクスポートすることで、後からエージェント定義にインポートしてウェブアクセスを有効にできます。準備完了です!Bright DataツールはMastra AIエージェントで使用する準備ができました。
ステップ#4:ウェブアクセスAIエージェントを作成する
次に、Bright Dataツールに接続されたMastraエージェントを作成します。src/mastra/agents/パスの下にweb-access-agent.tsファイルを追加し、以下の内容を記述します:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { webFetch, webSearch } from '../tools/web-access'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
instructions: `
You are a helpful, general-purpose assistant with Bright Data web access capabilities.
Goals:
- Answer user questions by combining reasoning with fresh, tool-based information.
- Prefer tools when information may be outdated or when factual accuracy is required.
- Clearly reference tool outputs so users can trace where information comes from.
Tool usage guidelines:
- Start with the webSearch tool to gather relevant sources and context.
- Use the webFetch tool to retrieve and analyze detailed content from specific pages.
`,
model: 'openai/gpt-5-mini',
tools: {
webFetch,
webSearch,
},
memory: new Memory(),
})このスニペットはBright Dataを基盤としたウェブ検索・スクレイピング機能を持つMastra AIエージェントを定義します。エージェントが最新のオンライン情報を取得してウェブページをスクレイピングできるようになります。また、メモリサポートも含まれているため、エージェントはインタラクション間でコンテキストを維持できます。
素晴らしい!Bright Data搭載のMastra AIエージェントの準備が整いました。
ステップ#5:エージェントをインデックスに登録する
Mastraアプリケーションを完成させる最後のステップは、src/mastra/index.tsファイルにwebAccessAgentを登録することです:
// src/mastra/index.ts
import { Mastra } from '@mastra/core/mastra'
import { PinoLogger } from '@mastra/loggers'
import { LibSQLStore } from '@mastra/libsql'
import { DuckDBStore } from '@mastra/duckdb'
import { MastraCompositeStore } from '@mastra/core/storage'
import { Observability, MastraStorageExporter, MastraPlatformExporter, SensitiveDataFilter } from '@mastra/observability'
import { webAccessAgent } from './agents/web-access-agent'
export const mastra = new Mastra({
agents: { webAccessAgent },
storage: new MastraCompositeStore({
id: 'composite-storage',
default: new LibSQLStore({
id: 'mastra-storage',
url: 'file:./mastra.db',
}),
domains: {
observability: await new DuckDBStore().getStore('observability'),
}
}),
logger: new PinoLogger({
name: 'Mastra',
level: 'info',
}),
observability: new Observability({
configs: {
default: {
serviceName: 'mastra',
exporters: [
new MastraStorageExporter(),
new MastraPlatformExporter(),
],
spanOutputProcessors: [
new SensitiveDataFilter(),
],
},
},
}),
})上記のスニペットは、先に定義したウェブアクセスAIエージェントを登録してMastraアプリケーションを初期化します。LibSQLストアを使用してエージェントのメモリをローカルのmastra.dbファイルに永続化するためのコンポジットストレージも設定します。また、Pinoによる構造化ログとオブザーバビリティ(エクスポーターと機密データフィルタリング)を設定して、モニタリングとトレーサビリティを実現します。
注意:Mastraアプリケーションをシンプルに保つために、初期の天気関連のツール・ワークフロー・スコアラーを削除することを検討してください。
ステップ#6:ウェブアクセスエージェントをテストする
以下のコマンドでMastraアプリケーションを起動します:
npm run dev以下のような出力が表示されるはずです:
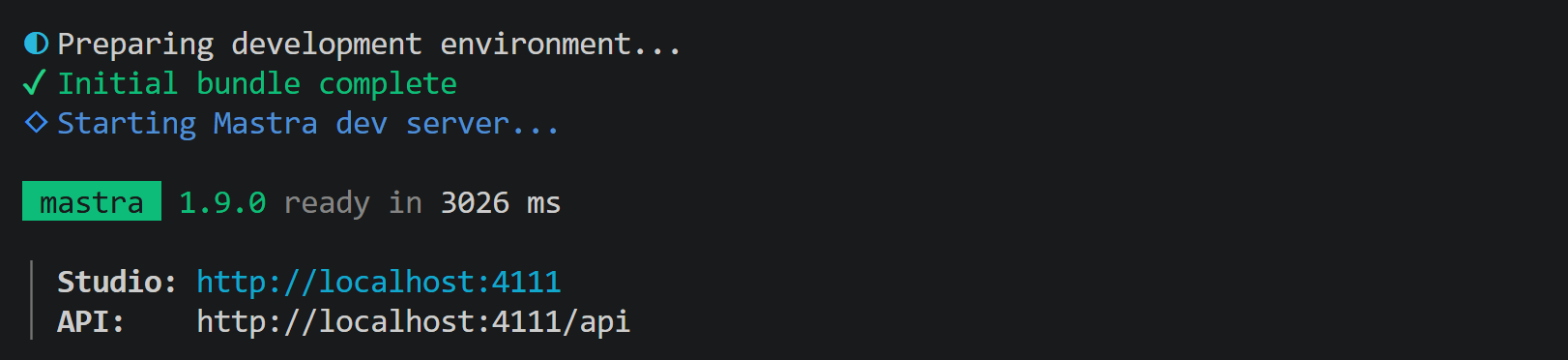
これはMastraローカルサーバーがhttp://localhost:4111で起動していることを示しています。ブラウザでそのURLを開くと、Mastraダッシュボードが表示されます:
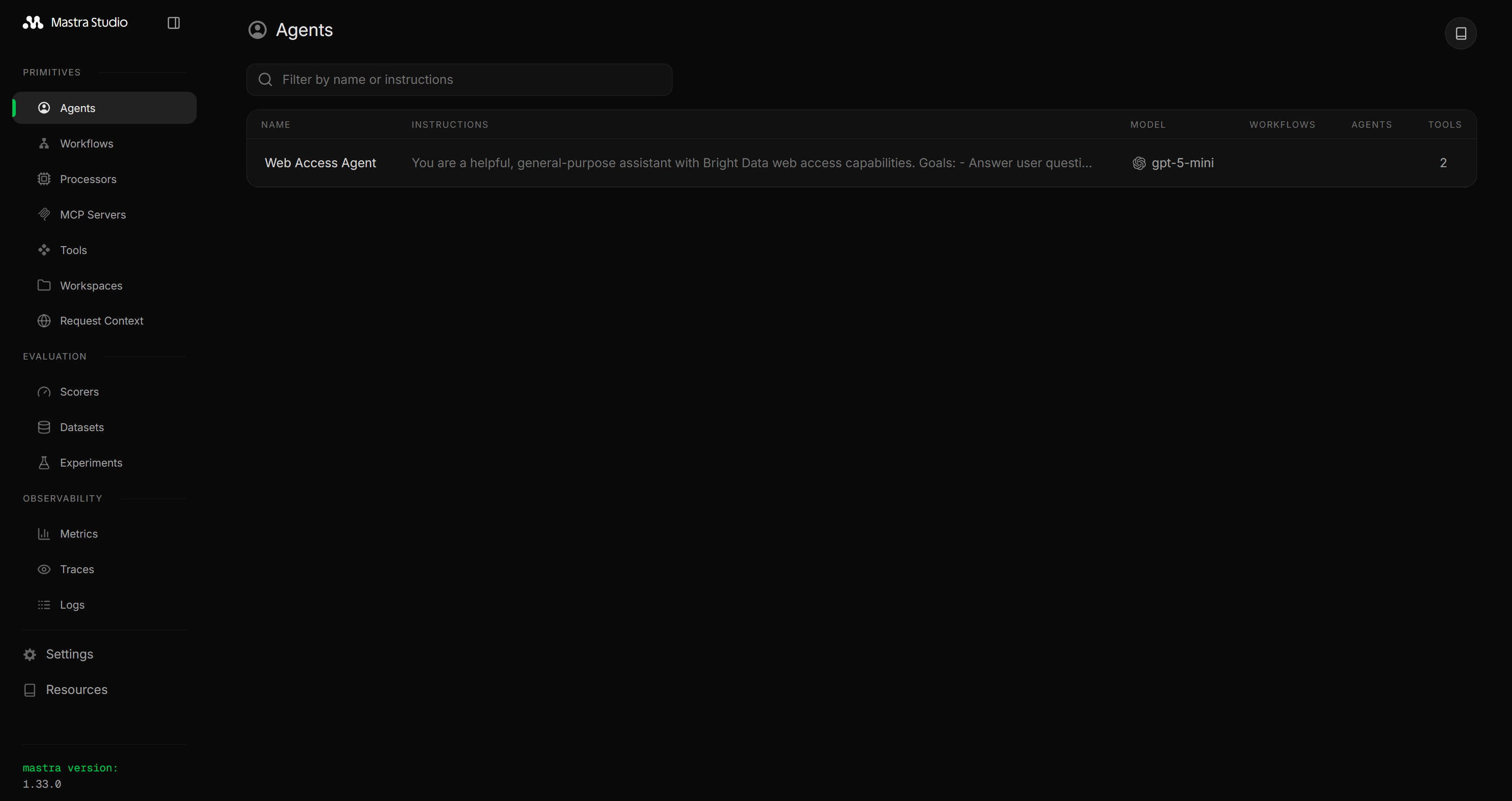
「Tools」セクションに移動すると、src/mastra/tools/web-access.tsから公開された2つのBright Dataツールが確認できます:
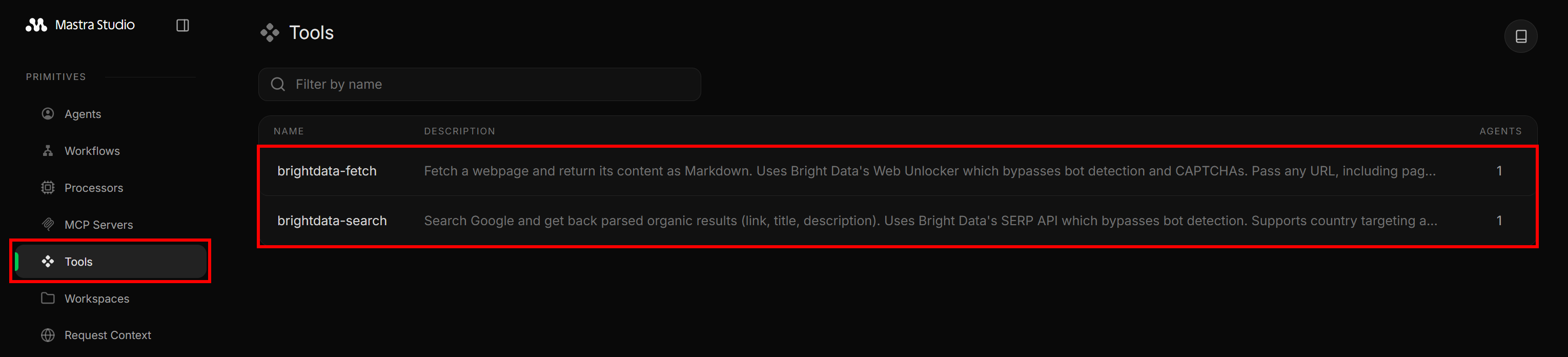
次に、「Agents」ページに移動して「Web Access Agent」エントリをクリックします:

エージェントのプロンプトUIが開き、チャットできるようになります。エージェントのウェブ探索機能を確認するために、以下のようなプロンプトを実行してみましょう:
Search for the latest stock market news on Google. Select the most relevant articles, extract and analyze their content, and return a structured Markdown report summarizing the key information, including links to learn more.実行すると、以下のような出力が表示されます:
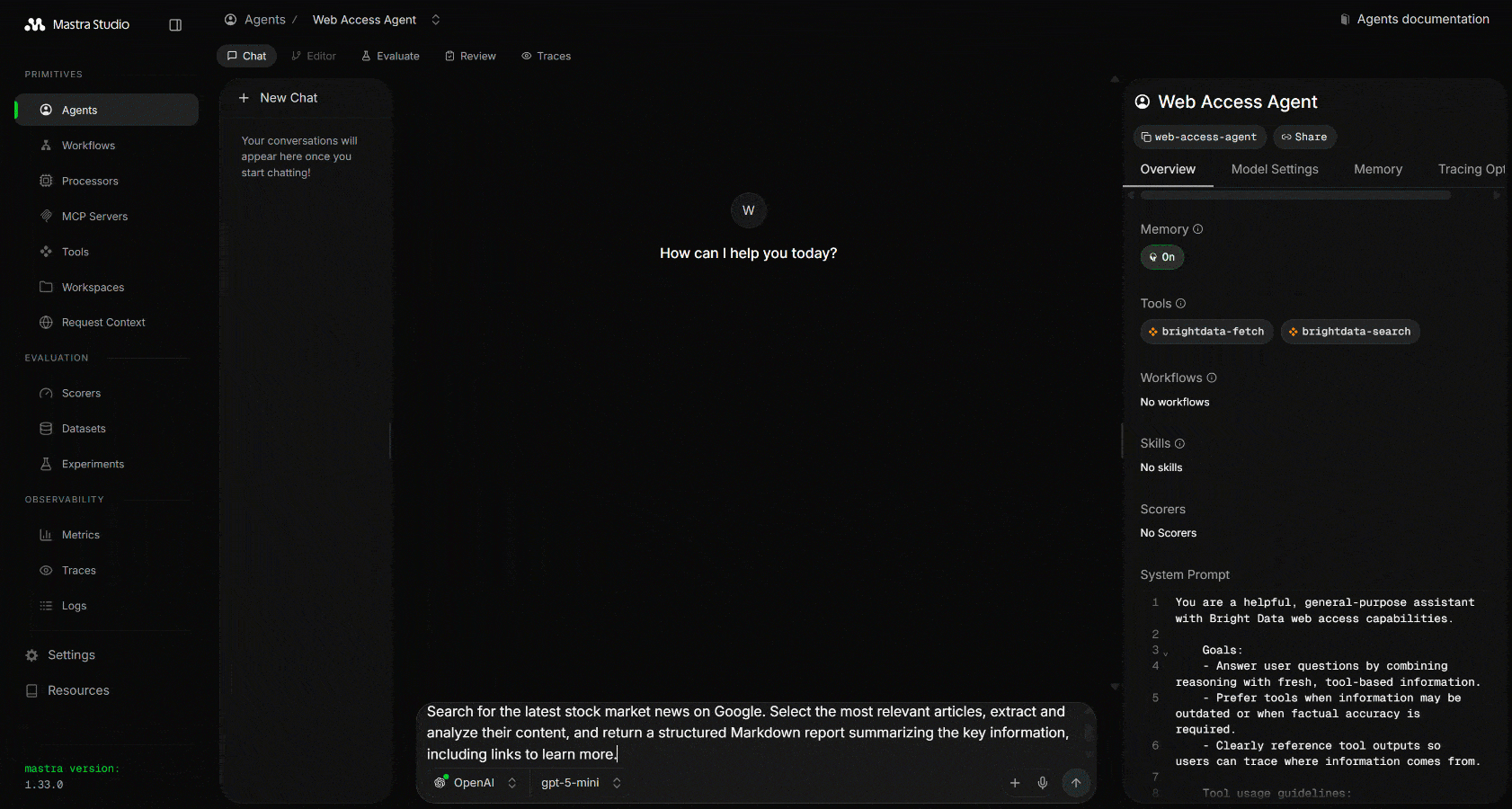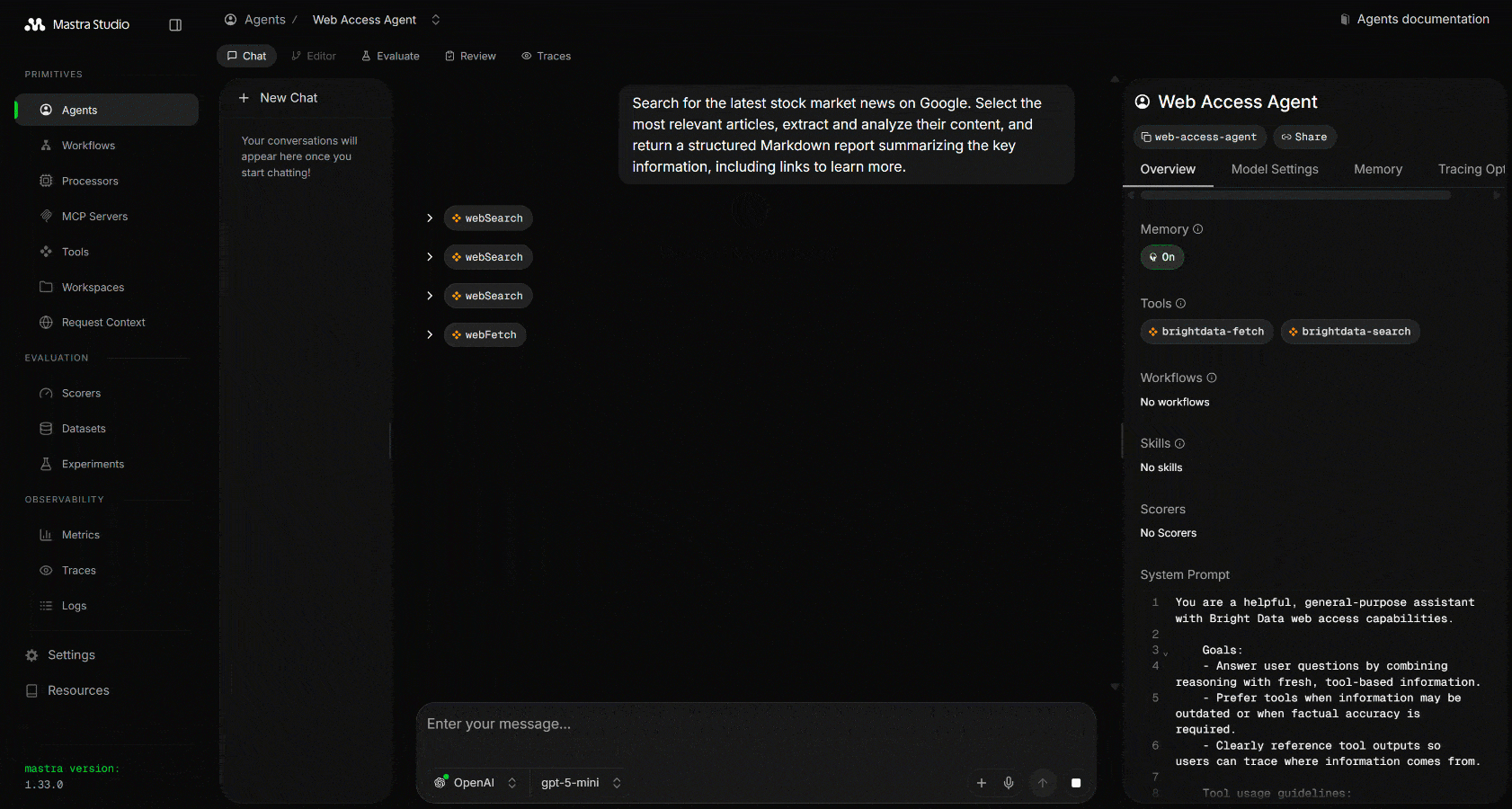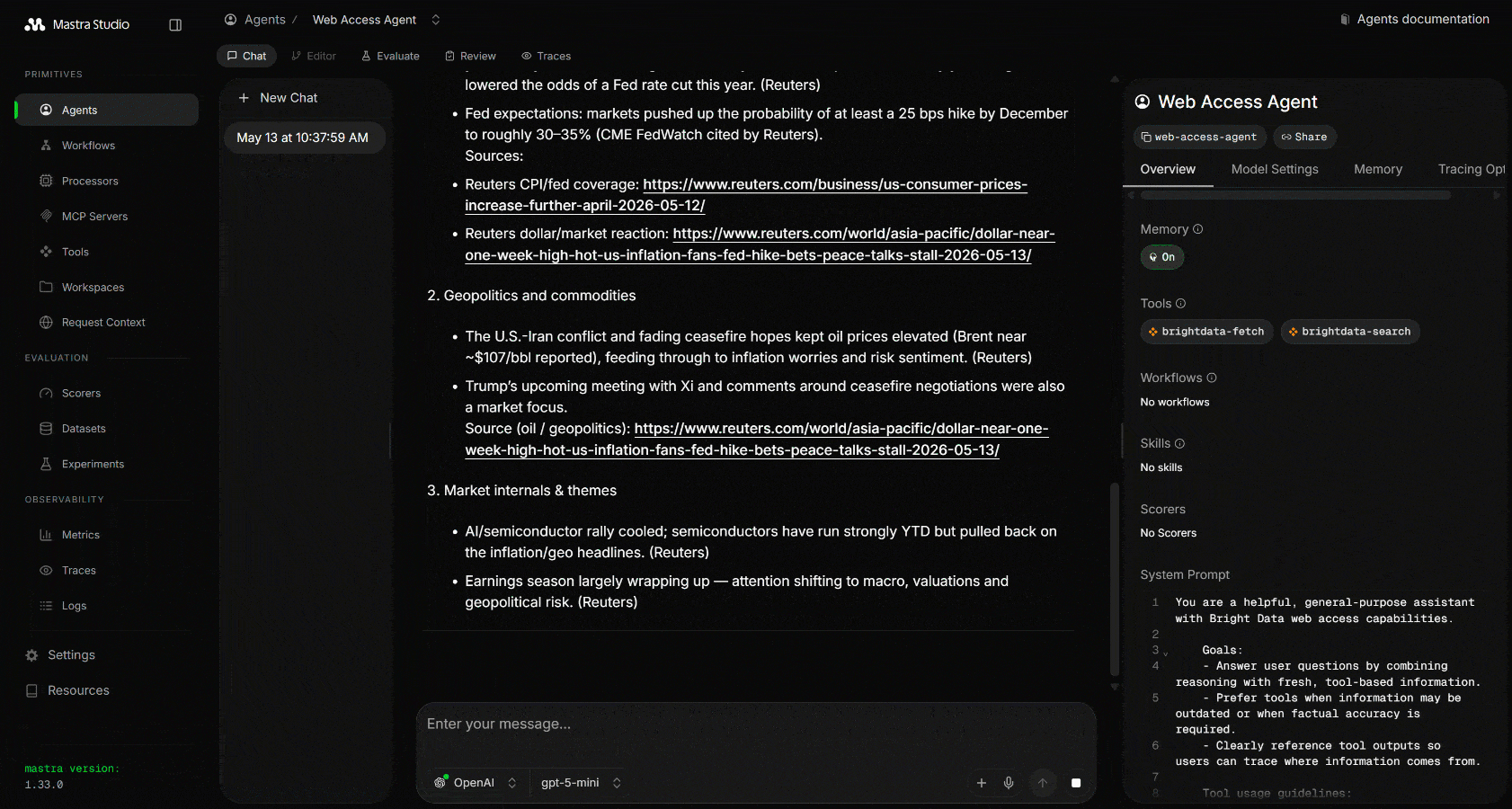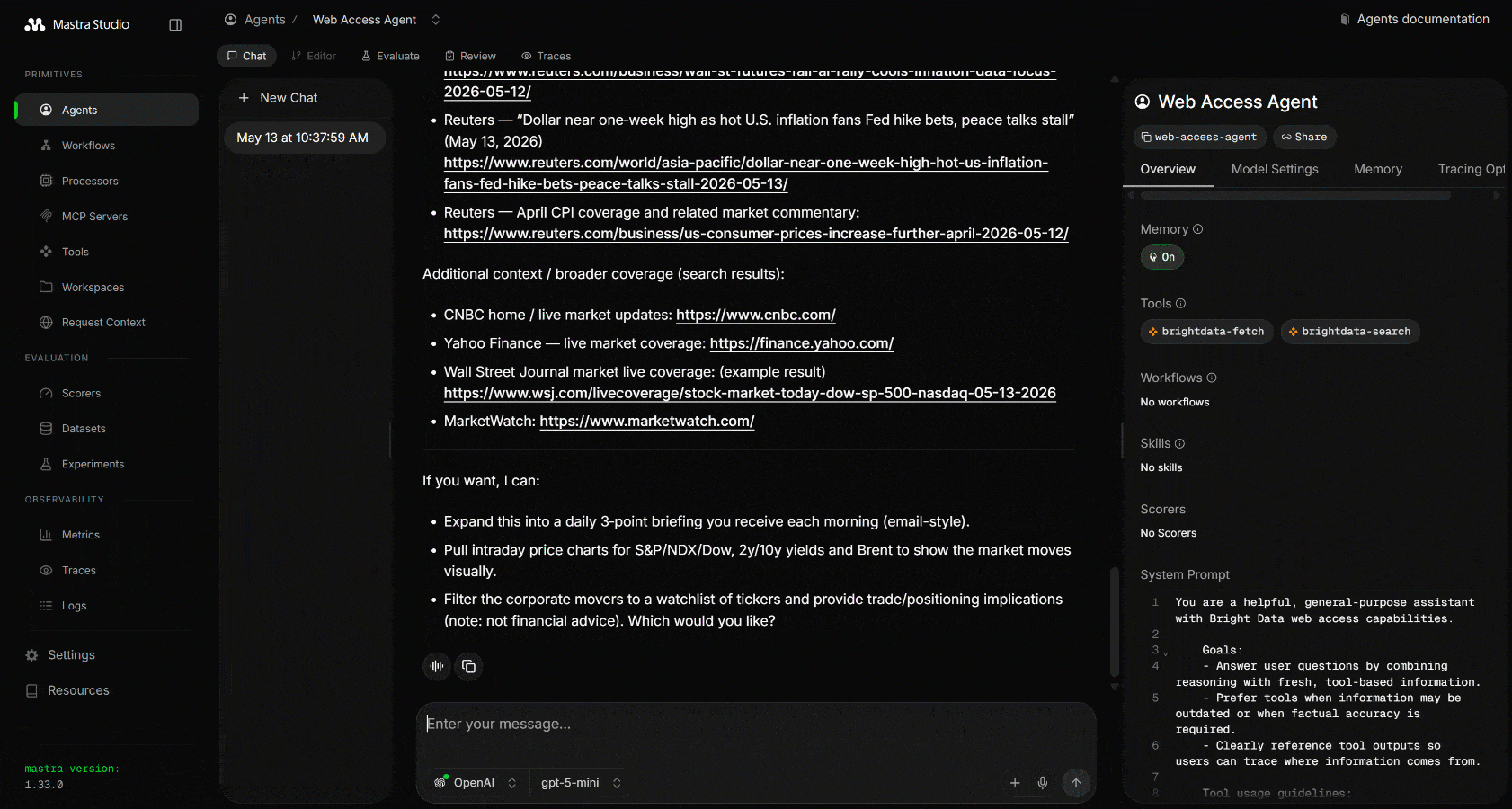
MastraがGoogleの関連検索クエリを実行するためにウェブ検索ツールを3回呼び出していることに注目してください。これらはGoogleからスクレイピングされたJSON形式の構造化SERP結果を返します:
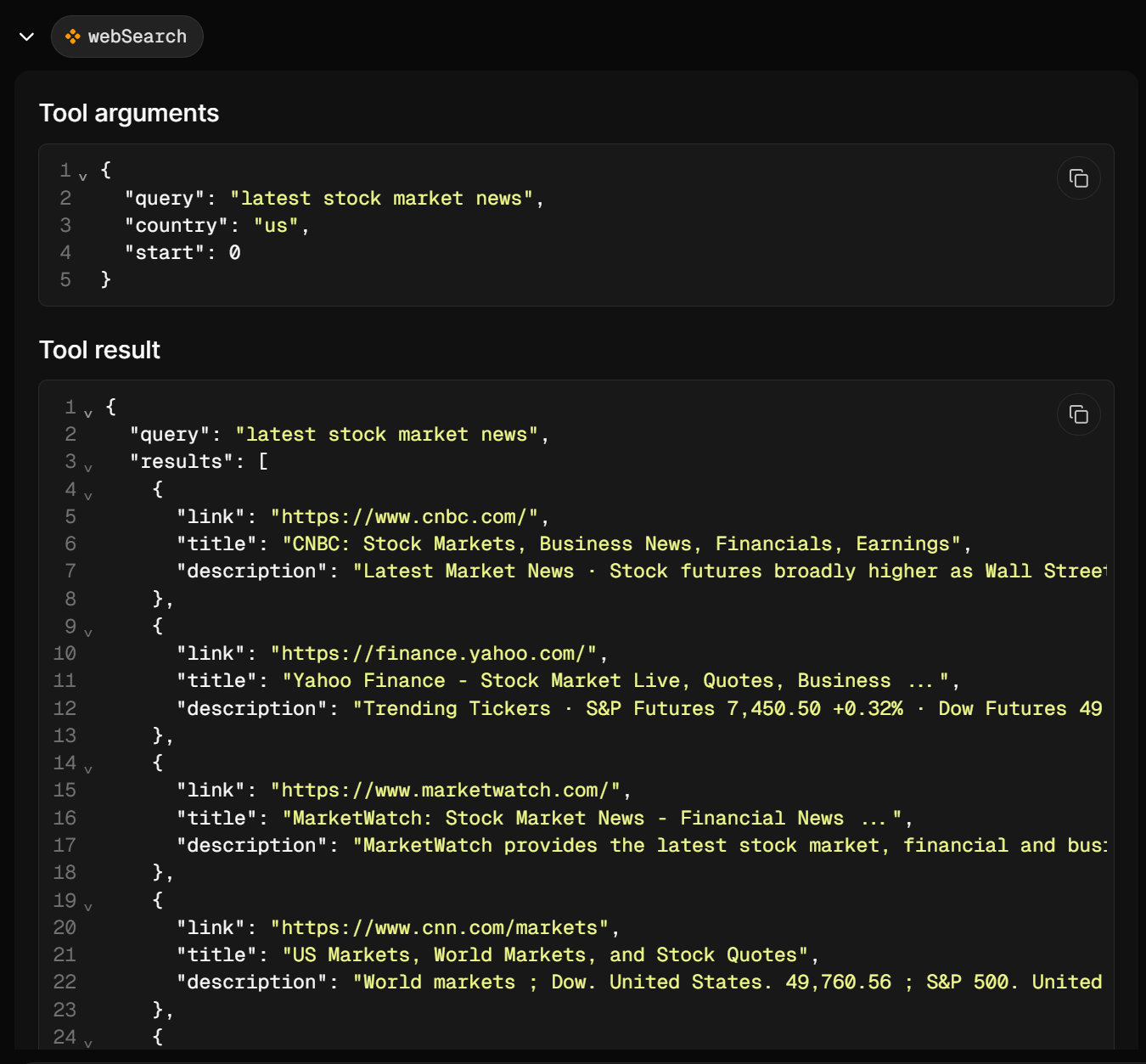
これらの結果からエージェントは最も関連性の高いリンクを選択し、webFetchを使ってそのコンテンツをスクレイピングします。最後に、今日の株式市場ニュースを要約した構造化Markdownレポートとしてすべてをまとめます。
完成です!Bright Dataとのインテグレーションにより、MastraのAIエージェントにエンタープライズグレードのウェブ検索・スクレイピング機能が追加され、より根拠のある応答が可能になりました。さまざまなプロンプトを試して、サポートされているすべてのシナリオとユースケースをテストしてみましょう!
[番外編] Mastra AIエージェントをBright Data Web MCPに接続する
MastraはMCPインテグレーションもサポートしていることを覚えておいてください。そのため、Mastra AIエージェントをBright Data Web MCPに接続することができます。
Web MCPサーバーは、ウェブ検索・スクレイピング・データ抽出・データフィード取得・ブラウザ自動化のための70以上のツールへのアクセスを提供します。また、無料プラン(月5,000リクエスト)もご利用いただけます。
MastraでMCPを使用するには、まず必要な依存パッケージをインストールします:
npm install @mastra/mcp@latest次に、以下の内容を含むsrc/mastra/mcp/bright-data-mcp-client.tsファイルを追加します:
// src/mastra/mcp/bright-data-mcp-client.ts
import { MCPClient } from '@mastra/mcp'
export const brightDataMcpClient = new MCPClient({
id: 'bright-data-mcp-client',
servers: {
'bright-data': {
command: 'npx',
args: ['-y', '@brightdata/mcp'],
env: {
'API_TOKEN': process.env.BRIGHTDATA_API_TOKEN || '',
'PRO_MODE': 'true' // remove to enable free mode
},
},
},
})これは@brightdata/mcpパッケージを通じてBright Data MCPを起動します。サーバーはAPI_TOKEN環境変数を使用してアカウントへの接続を認証します。この変数は.envファイルのBRIGHTDATA_API_TOKENにBright DataのAPI keyを設定することで使用されます。
'PRO_MODE': 'true'の設定はオプションです。有効にすると70以上のツールのフルセットにアクセスできますが、使用量に応じた料金が発生する場合があります。
Mastraエージェントファイルで、MCPサーバーのツールを使用するには、MCPClientをインポートし、toolsパラメーターで.listTools()を呼び出します:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { brightDataMcpClient } from '../mcp/bright-data-mcp-client'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
// omitted for brevity...
tools: {
...await brightDataMcpClient.listTools(),
},
memory: new Memory(),
})Mastraアプリケーションを起動すると、Bright Data Web MCPツールが表示されます:
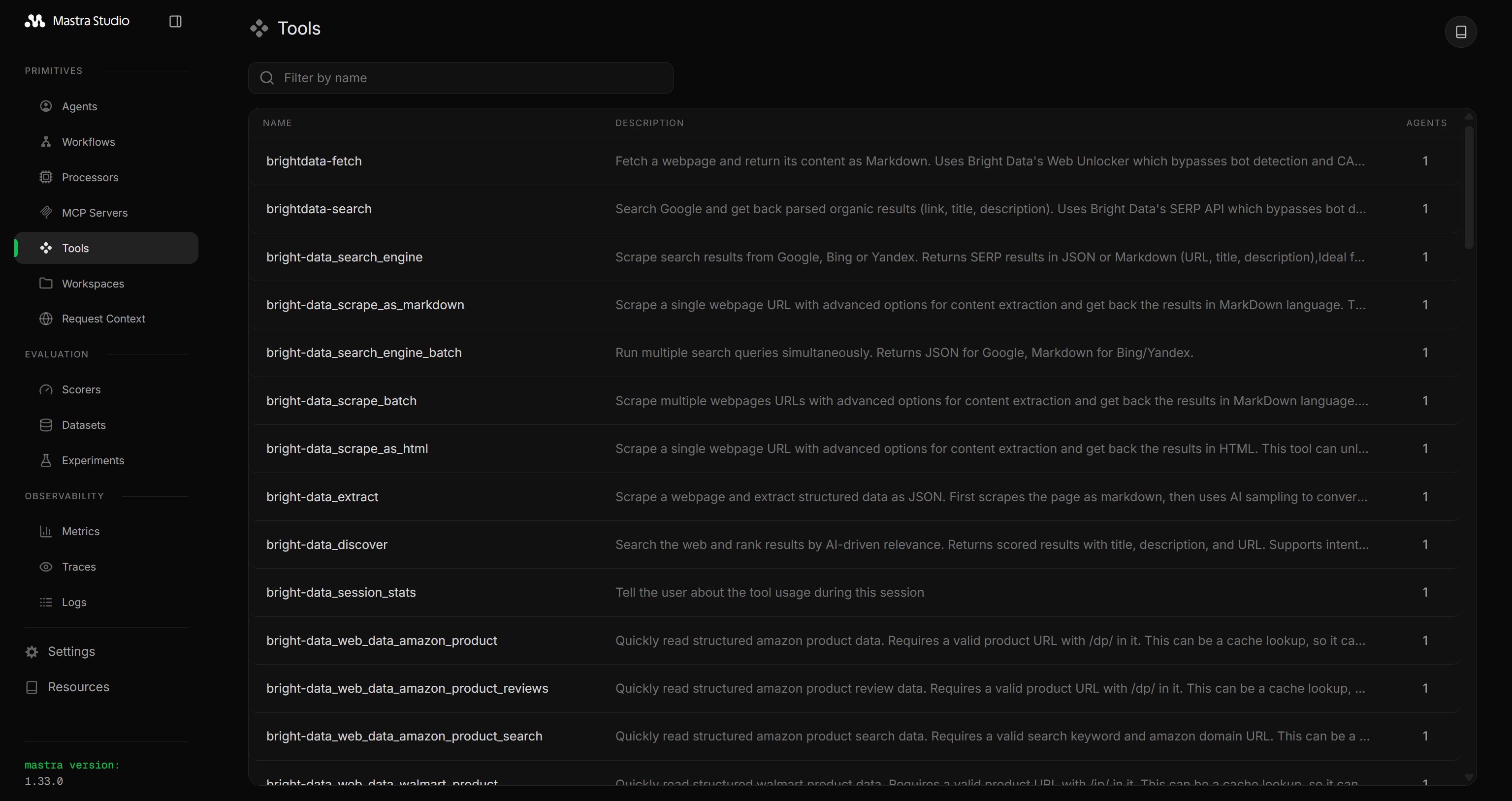
Proモードで設定された場合は70以上のツールが、Rapid(無料)モードで設定された場合は5つのツールがWeb MCPから利用可能になります。
ミッション完了!Mastra AIエージェントがMCPを通じてBright Dataインフラに接続されました。
まとめ
このブログ記事では、Mastraとはどのようなもので、どのような主要機能を提供しているかを解説しました。特に、公式Bright DataツールまたはWeb MCPを使って拡張する方法と理由を紹介しました。
このインテグレーションによってMastraエージェントはまったく新しいレベルに引き上げられます。AIエージェントはウェブ検索を実行し、構造化データを発見・抽出し、現実のウェブサイトと対話できるようになります。
今すぐ無料のBright Dataアカウントを作成して、AI対応のウェブデータツールの統合を始めましょう!




