

この記事では以下を学びます:
- Langfuseとは何か、その提供内容
- – 企業がAIエージェントの監視・追跡にLangfuseを必要とする理由
- – LangChainで構築された複雑な実世界のAIエージェントへの統合方法(Bright Dataと連携しウェブ検索・ウェブスクレイピング機能を実現)
それでは始めましょう!
Langfuseとは?
Langfuseは、大規模言語モデル(LLM)アプリケーションのデバッグ、監視、改善を支援するオープンソースのクラウドベースLLMエンジニアリングプラットフォームです。AI開発ワークフロー全体をサポートする可観測性、トレース、プロンプト管理、評価ツールを提供します。
主な機能は以下の通りです:
- 可観測性とトレース:トレース、セッション概要、コスト・レイテンシー・エラー率などのメトリクスにより、LLMアプリケーションを詳細に可視化。パフォーマンスの理解と問題診断に不可欠です。
- プロンプト管理:コードベースに触れることなく、プロンプトの作成、管理、共同での反復作業を可能にするバージョン管理システム。
- 評価:アプリケーションの挙動を評価するツール群。人間によるフィードバック収集、モデルベースのスコアリング、データセットに対する自動テストなどを含む。
- コラボレーション: アノテーション、コメント、共有インサイトによるチームワークフローをサポート。
- 拡張性:完全オープンソースで、異なる技術スタック間での柔軟な統合オプションを提供。
- デプロイオプション:ホスト型クラウドサービス(無料プランあり)または、データとインフラを完全に管理したいチーム向けのセルフホスト型インストールとして利用可能。
LangfuseをAIエージェントに統合する理由
LangfuseによるAIエージェントの監視は、特に企業にとって不可欠です。これにより初めて、本番環境が要求するレベルの可観測性、制御性、信頼性を達成できます。
実際のシナリオでは、AIエージェントは機密データ、複雑なビジネスロジック、外部APIとやり取りします。したがって、エージェントの動作、コスト、信頼性を正確に追跡・把握する手段が必要です。
Langfuseはエンドツーエンドのトレース、詳細なメトリクス、デバッグツールを提供し、(技術的知識のない)チームでもプロンプト入力からモデルの決定、ツール呼び出しに至るAIワークフローの全工程を監視可能にします。
企業にとってこれは、死角の減少、インシデント解決の迅速化、内部ガバナンスと外部規制へのより強固なコンプライアンスを意味します。さらにLangfuseはプロンプト管理と評価もサポートし、チームが大規模にプロンプトのバージョン管理、テスト、最適化を可能にします。
LangChainとBright Dataで構築したコンプライアンス追跡AIエージェントのトレース方法
Langfuseのトレース・監視機能を実証するには、まず計測対象となるAIエージェントが必要です。そこで本稿では、LangChainを用いて実世界のAIエージェントを構築し、Bright Dataのウェブ検索・ウェブスクレイピングソリューションで駆動させます。
注:LangfuseとBright Dataは幅広いAIエージェントフレームワークをサポートしています。ここでは説明の簡素化と実証目的でLangChainを選択しました。
このエンタープライズ対応のAIエージェントは、コンプライアンス関連タスクを以下のように処理します:
- 企業プロセス(例:データ処理ワークフロー)を記述した内部PDF文書の読み込み。
- LLMを用いて文書を分析し、主要なプライバシーおよび規制上の側面を特定する。
- Bright Data SERP APIを使用した関連トピックのウェブ検索を実行。
- Bright Data Web Unlocker APIを介して、政府ウェブサイトを優先した上位ページをMarkdown形式で取得。
- 収集した情報を処理し、規制上の問題を回避するための最新インサイトを提供します。
次に、このエージェントはLangfuseに接続され、実行時情報、メトリクス、その他の関連データを追跡します。
本プロジェクトのハイレベルなアーキテクチャについては、以下の概略設計図を参照してください: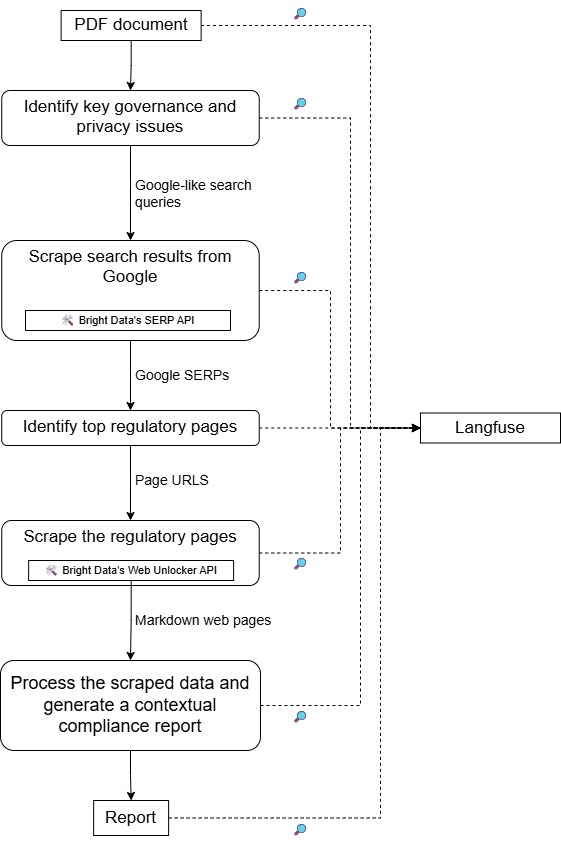
以下の手順に従ってください!
前提条件
開始前に、以下の環境が整っていることを確認してください:
- Python 3.10 以降がマシンにインストールされていること。
- OpenAI APIキー。
- SERP API および Web Unlocker API ゾーンが設定済みで、API キーが発行されたBright Data アカウント。
- 公開APIキーと秘密APIキーの両方が設定済みのLangfuseアカウント。
Bright DataとLangfuseアカウントの設定は、以下の手順でガイドされますので、現時点では心配する必要はありません。また、Langfuseが実行時データを追跡・管理する仕組みを理解するためには、AIエージェントの計測に関する基本的な知識があると役立ちます。
ステップ #1: LangChain AI エージェントプロジェクトの設定
ターミナルで以下のコマンドを実行し、LangChain AIエージェントプロジェクト用の新規フォルダを作成します:
mkdir compliance-tracking-AI-agentこの`compliance-tracking-ai-agent/`ディレクトリがAIエージェントのプロジェクトフォルダとなり、後ほどLangfuseを介して計測機能を実装します。
フォルダに移動し、その内部にPython仮想環境を作成します:
cd compliance-tracking-AI-agent
python -m venv .venvお好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharmなどが有効な選択肢です。
プロジェクトフォルダ内にagent.py という名前の Python スクリプトを作成します:
compliance-tracking-AI-agent/
├─── .venv/
└─── agent.py # <------------現在、agent.pyは空です。ここに後でLangChainを通じてAIエージェントを定義します。
次に仮想環境を有効化します。LinuxまたはmacOSではターミナルで以下を実行:
source venv/bin/activateWindowsでは同等の操作として以下を実行:
venv/Scripts/activateアクティベート後、以下のコマンドでプロジェクトの依存関係をインストールします:
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuseこれらのライブラリは以下の範囲をカバーします:
langchain、langchain-openai、langgraph: OpenAIモデルを活用したAIエージェントの構築と管理langchain-brightdata: LangChainを公式ツールでBright Dataサービスと統合します。langchain-communityとpypdf: 基盤となるpypdfライブラリを通じて PDF ファイルを読み取り処理するための API を提供します。python-dotenv: サードパーティプロバイダーのAPIキーなどのアプリケーションシークレットを.envファイルから読み込むため。langfuse: AIエージェントを計測し、クラウドまたはローカル環境で有用なトレースとテレメトリを収集します。
完了!これでAIエージェント構築用のPython開発環境が完全に整いました。
ステップ #2: 環境変数読み取りの設定
AIエージェントはOpenAI、Bright Data、Langfuseなどのサードパーティサービスに接続します。スクリプトへの認証情報のハードコーディングを回避し、企業利用に向けた本番環境対応を実現するため、.envファイルから読み込むよう設定します。これがpython-dotenvを導入した理由です!
agent.pyに以下のインポートを追加します:
from dotenv import load_dotenv次に、プロジェクトフォルダ内に.envファイルを作成します:
compliance-tracking-AI-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------このファイルには、すべての認証情報、APIキー、シークレットを保存します。
agent.py 内で、以下のコード行を使用して.envから環境変数をロードします:
load_dotenv()これでスクリプトが.envファイルから安全に値を読み込めるようになりました。
ステップ #3: Bright Data アカウントの準備
LangChain Bright Dataツールは、アカウントで設定されたBright Dataサービスに接続して動作します。具体的には、このプロジェクトに必要な2つのツールは以下の通りです:
BrightDataSERP: 関連する規制関連ウェブページを見つけるため、検索エンジンの結果を取得します。BrightDataのSERP APIに接続します。BrightDataUnblocker: 地理的制限やボット対策が施された公開ウェブサイトにもアクセス可能。エージェントが個々のウェブページからコンテンツをスクレイピングし学習することを可能にします。BrightDataのWeb Unblocker APIに接続します。
つまり、これら2つのツールを使用するには、SERP APIとWeb Unblocker APIの両方のゾーンが設定されたBright Dataアカウントが必要です。設定しましょう!
Bright Dataアカウントをお持ちでない場合は、まずアカウントを作成してください。お持ちの場合はログインします。ダッシュボードに移動し、「プロキシ&スクレイピング」ページへ進みます。そこで「マイゾーン」テーブルを確認してください: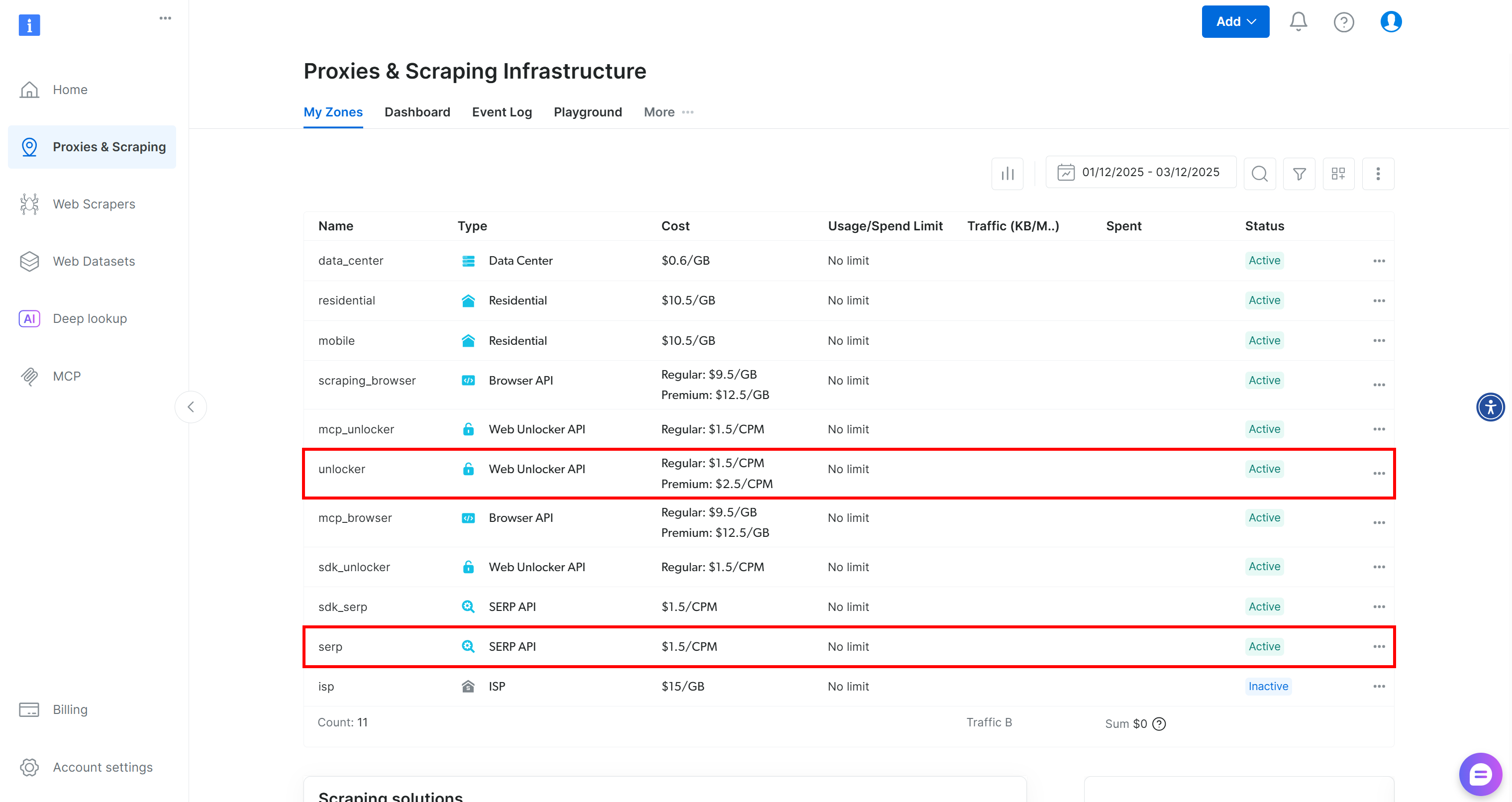
このテーブルに既に「unlocker」というWeb Unlocker APIゾーンと「serp」というSERP APIゾーンが存在する場合、準備は完了です。その理由は:
BrightDataSERPLangChainツールは自動的に「serp」という名前のSERP APIゾーンに接続します。BrightDataUnblockerLangChainツールは、web_unlockerという名前のWeb Unblocker APIゾーンに自動的に接続します。
詳細は、Bright Data x LangChain ドキュメントを参照してください。
これらの必須ゾーンがまだ存在しない場合は、簡単に作成できます。「Unblocker API」および「SERP API」カードを下にスクロールし、「ゾーンを作成」ボタンを押して、ウィザードに従い必要な名前で2つのゾーンを追加してください: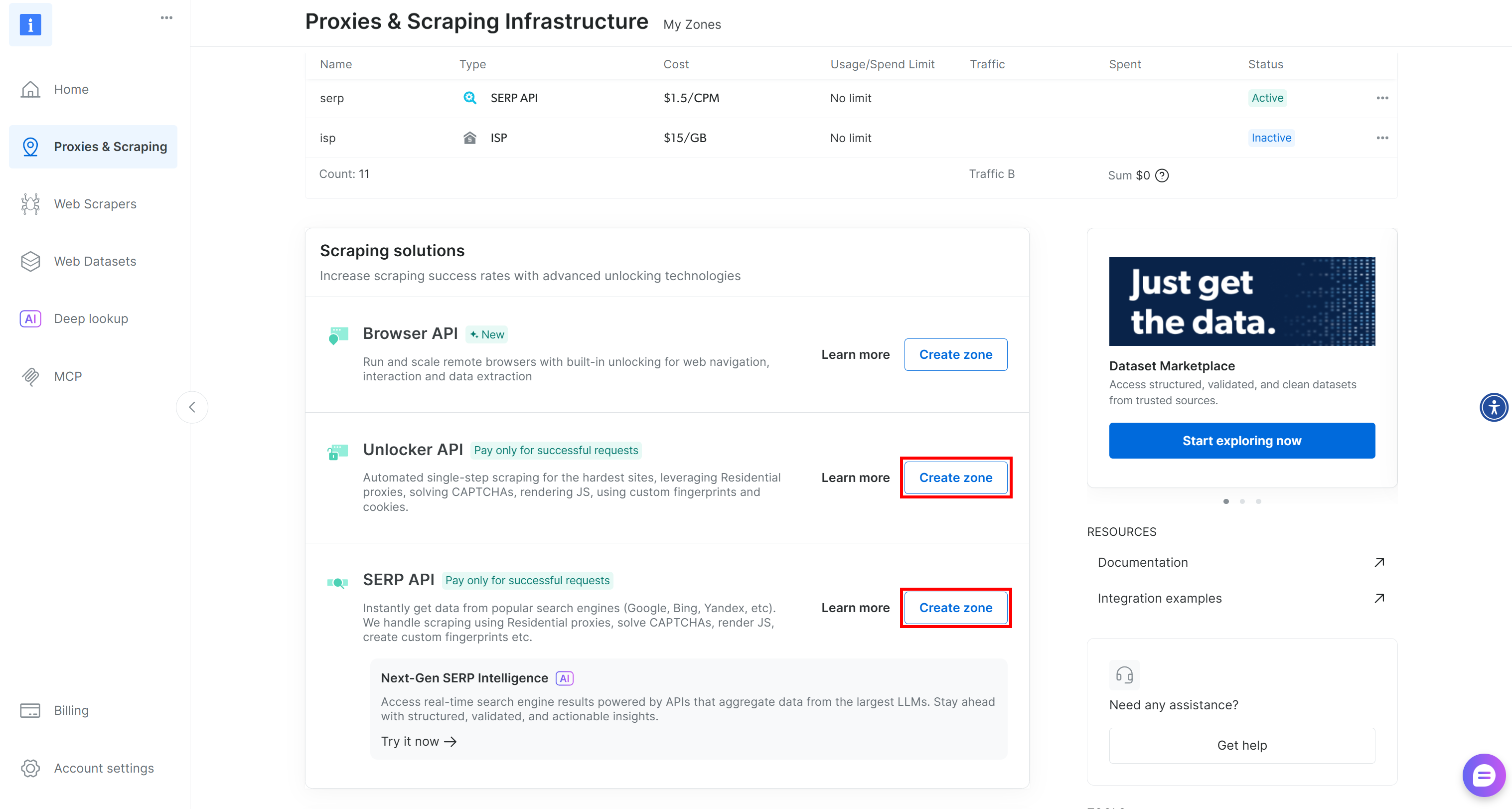
手順の詳細については、以下の2つのドキュメントページを参照してください:
最後に、LangChain Bright Dataツールにアカウント接続方法を指定する必要があります。これは認証に使用するBright Data APIキーで行います。
Bright Data APIキーを生成し、.envファイルに以下のように保存します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"これで完了です!公式ツールを介してLangChainスクリプトをBright Dataソリューションに接続するためのすべての準備が整いました。
ステップ #4: LangChain Bright Data ツールの設定
agent.pyファイル内で、LangChain Bright Dataツールを以下のように準備します:
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker() 注: Bright Data APIキーを手動で指定する必要はありません。両ツールは、以前に.envファイルで設定したBRIGHT_DATA_API_KEY環境変数から自動的に読み込もうとします。
ステップ #5: LLM の統合
コンプライアンス追跡用AIエージェントには、LLMモデルに相当する「頭脳」が必要です。この例ではOpenAIをLLMプロバイダーとして選択します。まず.envファイルにOpenAI APIキーを追加します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"次に、agent.pyファイルでLLM統合を以下のように初期化します:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
) 注: ここで設定されているモデルはGPT-5 Miniですが、他のOpenAIモデルも使用可能です。
OpenAIを使用しない場合は、公式のLangChainガイドに従って他のLLMプロバイダーに接続してください。
これで LangChain AI エージェントを定義するために必要な準備が整いました。
ステップ #6: AIエージェントの定義
LangChainエージェントには、LLM、いくつかのオプションツール、およびエージェントの動作を定義するシステムプロンプトが必要です。
これらのコンポーネントを次のようにLangChainエージェントに統合します:
from langchain.agents import create_agent
# コンプライアンスとプライバシーに重点を置いたタスクをエージェントに指示するシステムプロンプトを定義
system_prompt = """
あなたはコンプライアンス追跡の専門家です。規制やプライバシーに関する潜在的な問題を文書から分析することが役割です。
分析にはBright Dataのツール(SERP APIやWeb Unlockerを含む)を活用し、オンラインで更新された規則や権威ある情報源を調査します。
正確で企業利用可能な洞察を提供し、すべての発見事項が元の文書と権威ある外部情報源からの引用で裏付けられていることを保証してください。
"""
# AIエージェントが利用可能なツール一覧
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# AIエージェントの定義
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)create_agent()関数はLangGraphを用いてグラフベースのエージェントランタイムを構築します。グラフはノード(ステップ)とエッジ(接続)で構成され、エージェントの情報処理方法を定義します。エージェントはこのグラフを移動しながら様々なタイプのノードを実行します。詳細は公式ドキュメントを参照してください。
基本的に、agent変数はコンプライアンス追跡と分析のためのBright Data統合を備えたAIエージェントを表します。素晴らしい!
ステップ #7: エージェントの実行
エージェントを起動する前に、コンプライアンス追跡タスクと分析対象文書を記述したプロンプトが必要です。
入力PDFドキュメントの読み込みから開始します:
from langchain_community.document_loaders import PyPDFDirectoryLoader
# 入力フォルダから全てのPDF文書を読み込む
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# 入力フォルダ内の全PDFから全ページを読み込み
docs = loader.load()
# 分析用にPDFの全ページを単一の文字列に結合
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])これはLangChainのpypdfコミュニティドキュメントローダーを使用し、入力フォルダ内のPDFから全ページを読み込み、テキストを単一の文字列変数に集約します。
プロジェクトディレクトリ内にinput/フォルダを追加:
compliance-tracking-AI-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .envこのフォルダには、エージェントがプライバシー、規制、コンプライアンス関連の課題を分析するPDFファイルが格納されます。
input/フォルダに単一の文書が含まれていると仮定すると、internal_document_to_analyze変数はその全文を保持します。これをプロンプトに埋め込み、エージェントに分析タスクを明確に指示できます:
from langchain_core.prompts import PromptTemplate
# エージェントをワークフローに導くプロンプトテンプレートを定義
prompt_template = PromptTemplate.from_template("""
以下のPDFコンテンツを前提として:
1. LLMに分析させ、プライバシーの観点で調査に値する主要な重要点を特定させる。
2. それらの要素を、Googleに適した非常に短い(5語以内)、簡潔で具体的な検索クエリ(最大3つ)に変換する。
3. Bright DataのSERP APIツールを使用して、それらのクエリでウェブ検索を実行する(英語のページを検索、米国に限定)。
4. Bright DataのWeb Unlockerツールで、上位5件までのウェブページ(PDFを除く、政府系サイトを優先)をMarkdownデータ形式で取得する。
5. 収集した情報を処理し、規制上の問題を回避するため、原文からの引用とウェブスクレイピングしたページからの知見を含む最終的な簡潔なレポートを作成する。
PDF CONTENT:
{pdf}
""")
# PDFの内容でテンプレートを埋める
prompt = prompt_template.format(pdf=internal_document_to_analyze)最後にプロンプトをエージェントに渡して実行:
# Langfuseで各ステップを追跡しながらエージェントの応答をストリーム出力
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()ミッション完了! Bright Data搭載のLangChain AIエージェントが、エンタープライズレベルの文書分析や規制調査タスクに対応可能になりました。
ステップ #8: Langfuse の導入
AIエージェントの実装が完了した段階です。通常、この時点でLangfuseを導入し、本番環境での追跡と監視を開始します。結局のところ、既に稼働しているエージェントに計測機能を実装するのが一般的だからです。
まずLangfuseアカウントを作成します。「Organizations」ページにリダイレクトされるので、新しい組織を作成してください。「New Organization」ボタンをクリックします: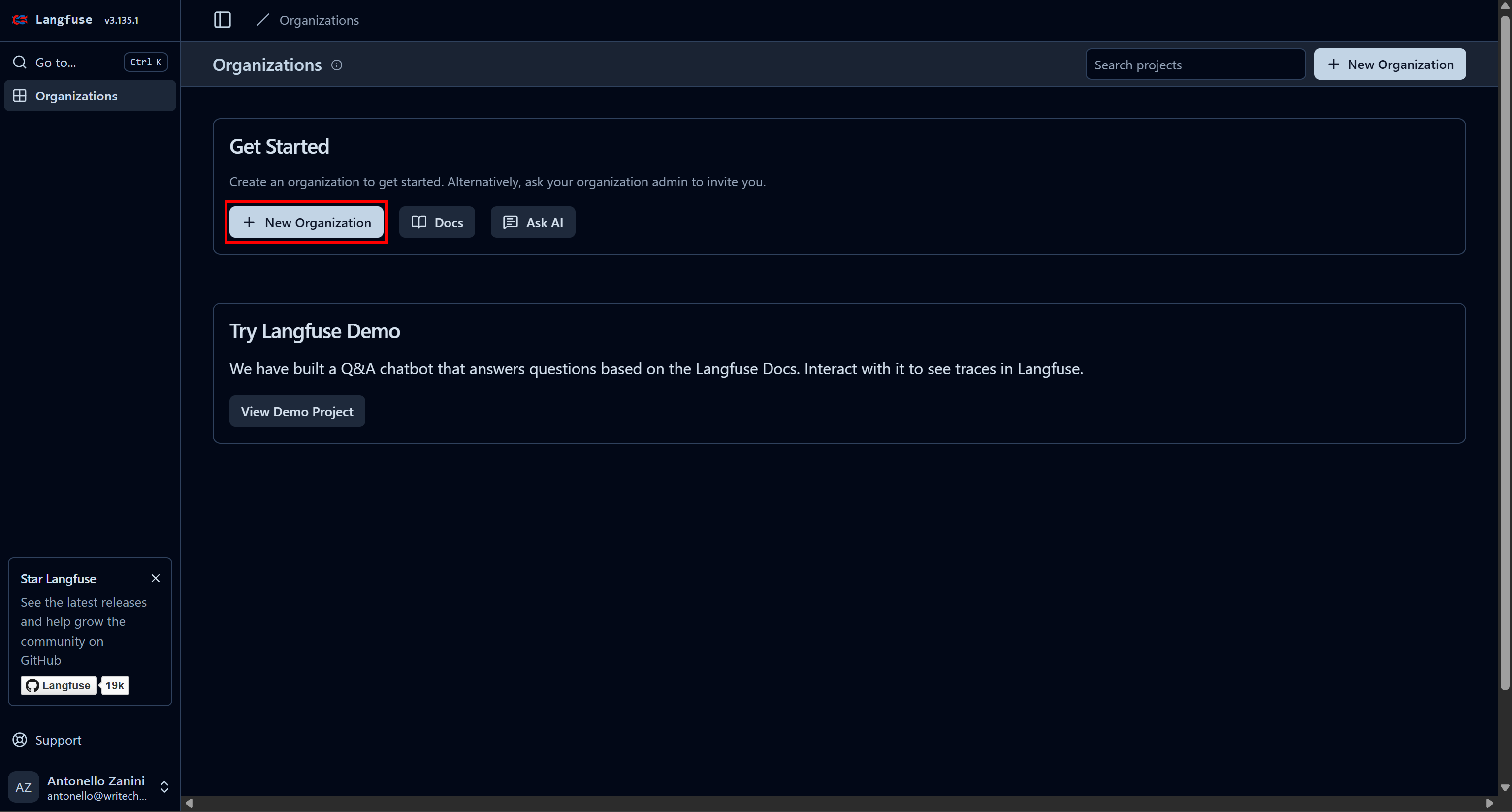
組織に名前を付け、ウィザードを進めて最終ステップ「プロジェクトを作成」まで進みます: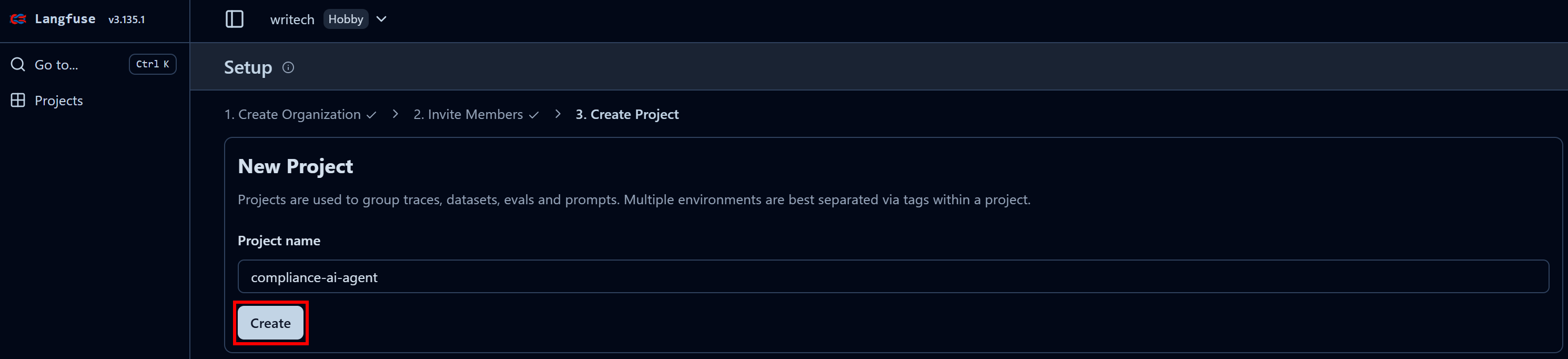
最終ステップでプロジェクト名を「compliance-tracking-AI-agent」のように命名し、「作成」ボタンを押します。その後「プロジェクト設定」ビューにリダイレクトされます。そこから「APIキー」ページに移動します: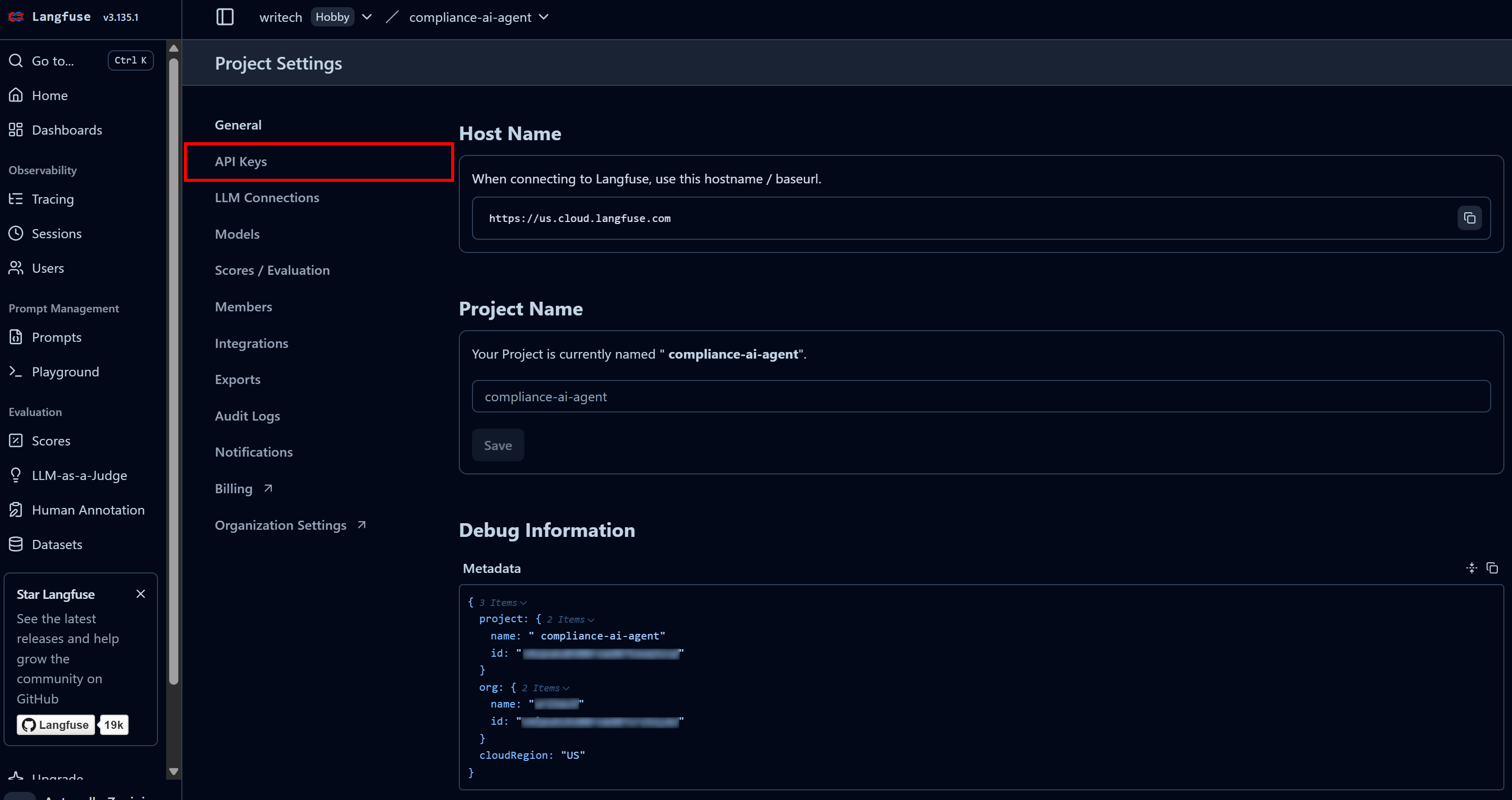
「プロジェクトAPIキー」セクションで「新しいAPIキーを作成」をクリックします: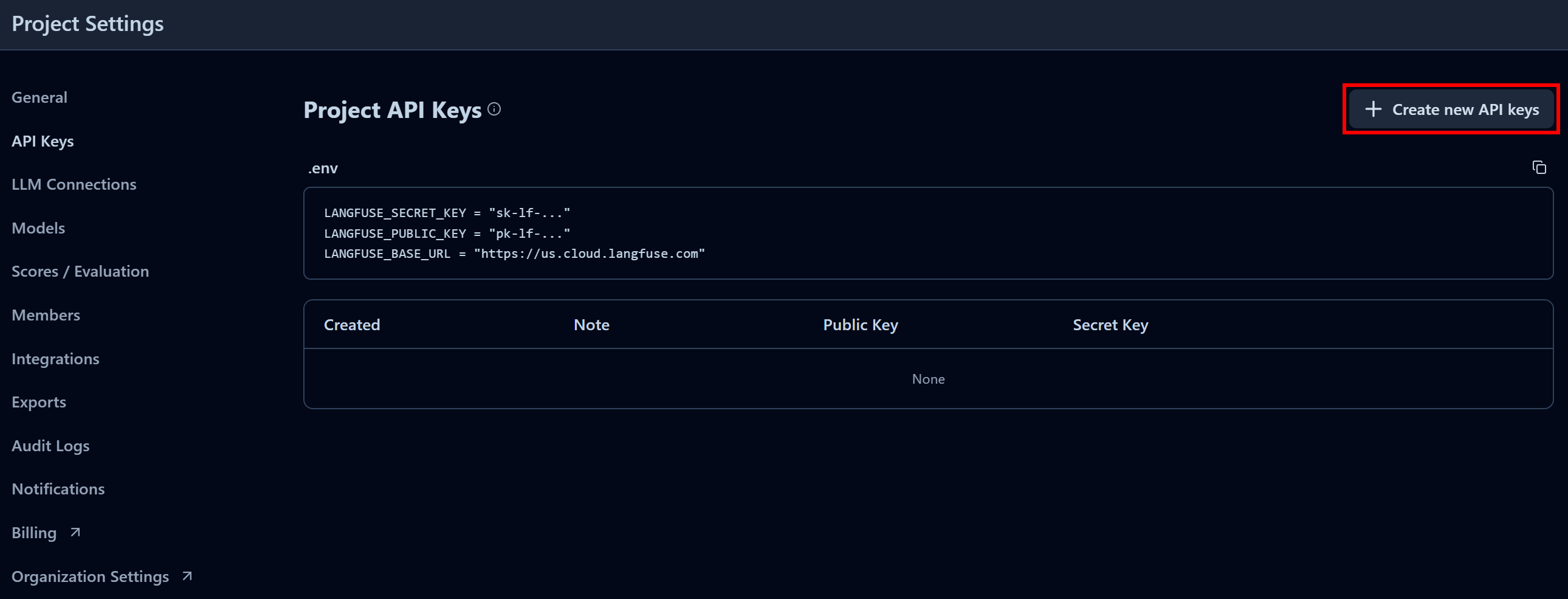
表示されるモーダルでAPIキーに名前を付け、「APIキーを作成」をクリックします: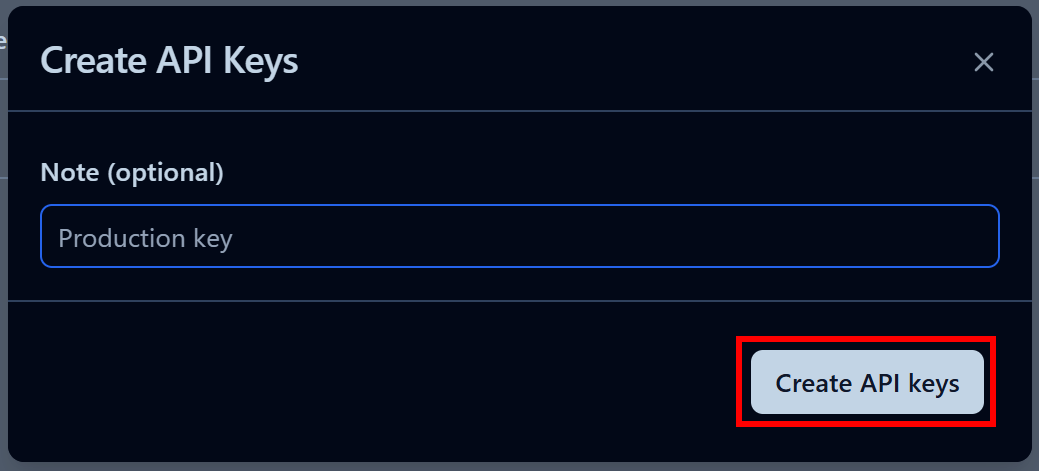
公開APIキーと秘密APIキーが発行されます。迅速な統合のため、「.env」セクションの「クリップボードにコピー」ボタンをクリックしてください: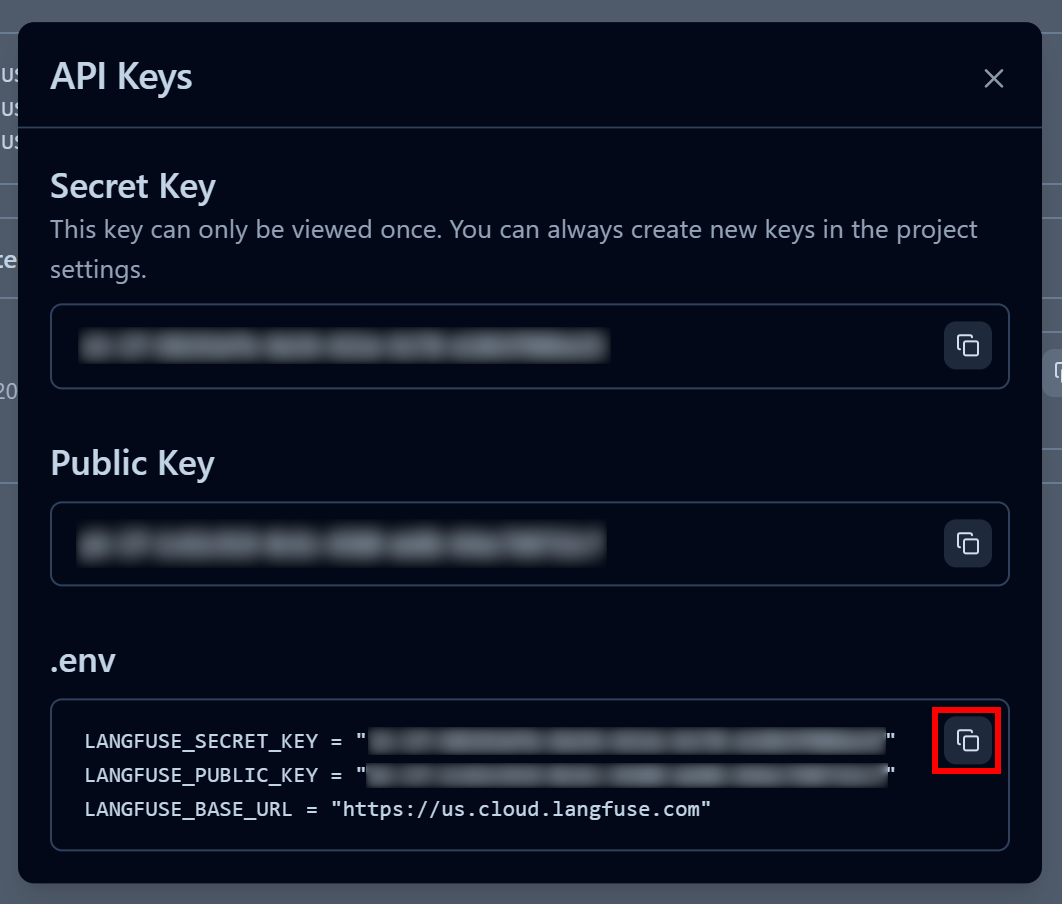
次に、コピーした環境変数をプロジェクトの.envファイルに貼り付けます:
LANGFUSE_SECRET_KEY = "<YOUR_LANGFUSE_SECRET_KEY>"
LANGFUSE_PUBLIC_KEY = "<YOUR_LANGFUSE_PUBLIC_KEY>"
LANGFUSE_BASE_URL = "<YOUR_LANGFUSE_BASE_URL>"これで完了です!スクリプトがLangfuse Cloudアカウントに接続し、監視と可観測性のための有用なトレース情報を送信できるようになりました。
ステップ #9: Langfuse トラッキングの統合
LangfuseはLangChain(その他多くのAIエージェント構築フレームワークも)を完全にサポートしているため、カスタムコードは不要です。
LangChain AIエージェントをLangfuseに接続するには、Langfuseクライアントを初期化しコールバックハンドラを作成するだけです:
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# .envファイルから環境変数をロード
load_dotenv()
# 追跡と可観測性のためのLangfuseクライアントを初期化
langfuse = get_client()
# LangchainエージェントのインタラクションをキャプチャするLangfuseコールバックハンドラを作成
langfuse_handler = CallbackHandler()
次に、エージェントを呼び出す際にLangfuseコールバックハンドラを渡します:
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse 統合
):
step["messages"][-1].pretty_print()これで完了です! LangChain AIエージェントが完全に計測可能になりました。すべての実行時情報がLangfuseに送信され、Webアプリで確認できます。
ステップ #10: 最終コード
agent.pyファイルの内容は以下の通りです:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# .envファイルから環境変数をロード
load_dotenv()
# 追跡と可観測性のためのLangfuseクライアントを初期化
langfuse = get_client()
# Langchainエージェントのやり取りをキャプチャするLangfuseコールバックハンドラーを作成
langfuse_handler = CallbackHandler()
# Bright Dataツールを初期化
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# 大規模言語モデルを初期化
llm = ChatOpenAI(
model="gpt-5-mini",)
# コンプライアンスとプライバシーに焦点を当てたタスクをエージェントに指示するシステムプロンプトを定義
system_prompt = """
あなたはコンプライアンス追跡の専門家です。あなたの役割は、文書を分析して潜在的な規制およびプライバシー上の問題を特定することです。
分析には、SERP APIやWeb Unlockerを含むBright Dataのツールを活用し、オンラインで更新された規則や権威ある情報源を調査します。
正確で企業利用可能な洞察を提供し、すべての発見事項が原文と権威ある外部情報源からの引用で裏付けられていることを保証してください。
"""
# AIエージェントが利用可能なツール一覧
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# AIエージェントを定義
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# 入力フォルダから全てのPDF文書を読み込む
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# 入力フォルダ内の全PDFから全ページを読み込む
docs = loader.load()
# 分析用にPDF全ページの文字列を結合
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])
# エージェントのワークフローを導くプロンプトテンプレート定義
prompt_template = PromptTemplate.from_template("""
以下のPDFコンテンツを前提とする:
1. LLMに分析させ、プライバシーの観点から調査価値のある主要なポイントを特定させる。
2. それらのポイントを、Google検索に適した非常に短い(5語以内)、簡潔で具体的な検索クエリ(最大3つ)に変換する。
3. Bright DataのSERP APIツールを使用して、それらのクエリでウェブ検索を実行する(英語のページを対象に、米国に限定)。
4. Bright DataのWeb Unlockerツールで、上位5件までのウェブページ(PDFを除く、政府系サイトを優先)をMarkdownデータ形式で取得する。
5. 収集した情報を処理し、規制上の問題を回避するため、原文からの引用とウェブスクレイピングしたページからの知見を含む最終的な簡潔なレポートを作成する。
PDF CONTENT:
{pdf}
""")
# PDFの内容でテンプレートを埋める
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Langfuseで各ステップを追跡しながらエージェントの応答をストリーム処理
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse 統合
):
step["messages"][-1].pretty_print()すごい!LangChain、Bright Data、Langfuseのおかげで、わずか75行ほどのPythonコードで、規制・コンプライアンス分析向けのエンタープライズ対応AIエージェントを構築できました。
ステップ #11: エージェントの実行
AIエージェントはPDFファイルを処理対象とします。本例では、以下の文書で規制分析を実行すると仮定します:
これは、企業向けスタイルのサンプル文書であり、企業によるユーザーデータ処理の実践を概説したものです。
user-data-processing-workflow.pdfとして保存し、プロジェクトディレクトリのinput/フォルダ内に配置してください: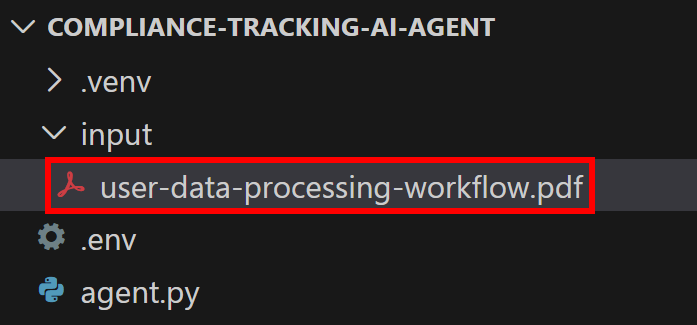
これにより、スクリプトがファイルにアクセスし、エージェントのプロンプトに埋め込むことが可能になります。
LagnChain AIエージェントを以下で実行します:
python agent.py ターミナルには、Bright Dataツール呼び出しのトレースが以下のように表示されます: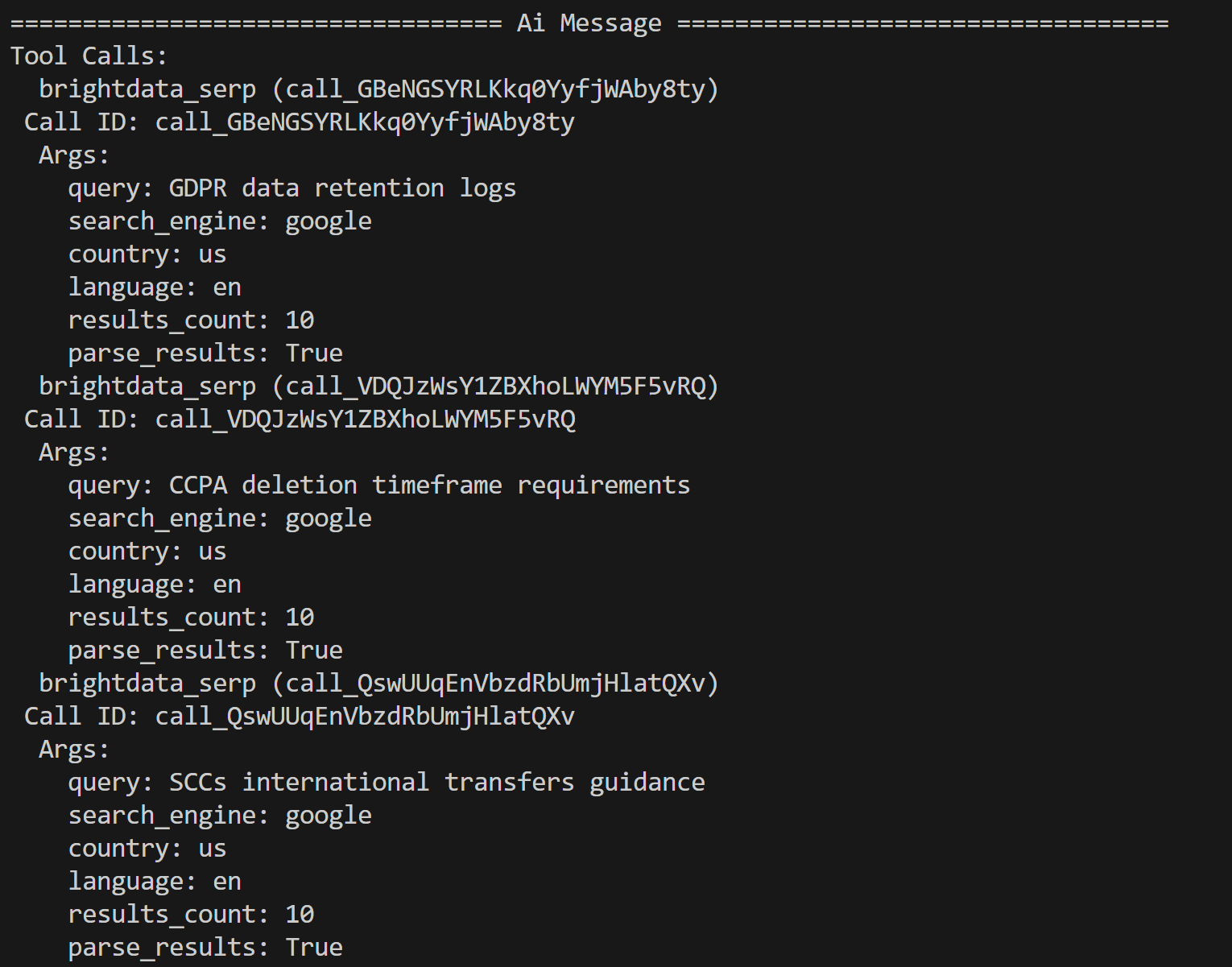
AIエージェントはPDFの内容に基づき、以下の3つの検索クエリをさらなる調査対象として特定しました:
- 「GDPRデータ保持ログ」
- 「CCPA削除期間要件」
- 「SCCsによる国際移転ガイダンス」
これらのクエリは、入力文書内でLLMが指摘した潜在的な規制・プライバシー問題に関連する文脈に基づいています。
Bright Data SERP API(これらのクエリに対するGoogle検索結果を含む)から返された結果から、エージェントは上位ページを選択し、Web Unblocker APIツールを介してウェブスクレイピングします: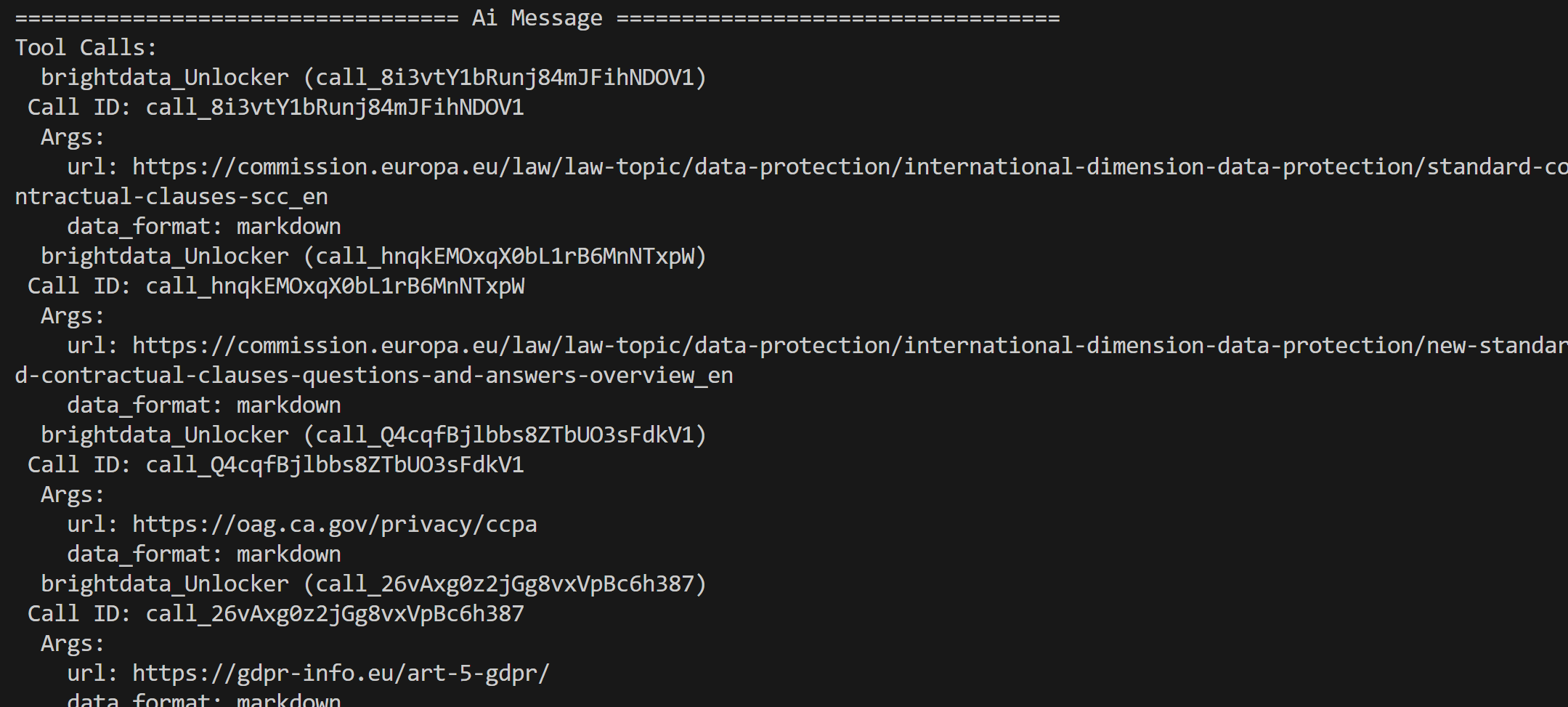
これらのページのコンテンツは処理され、最終的な規制分析レポートに要約されます。
さあ、AIエージェントが見事に機能しました。Langfuse統合の効果を可観測性と追跡の観点から確認しましょう。
ステップ #12: Langfuse でエージェントのトレースを検査
AIエージェントがタスクを実行し始めると、Langfuseダッシュボードにデータが表示されます。特に「トレース」数が0から1に増加し、モデルコストが上昇する様子に注目してください: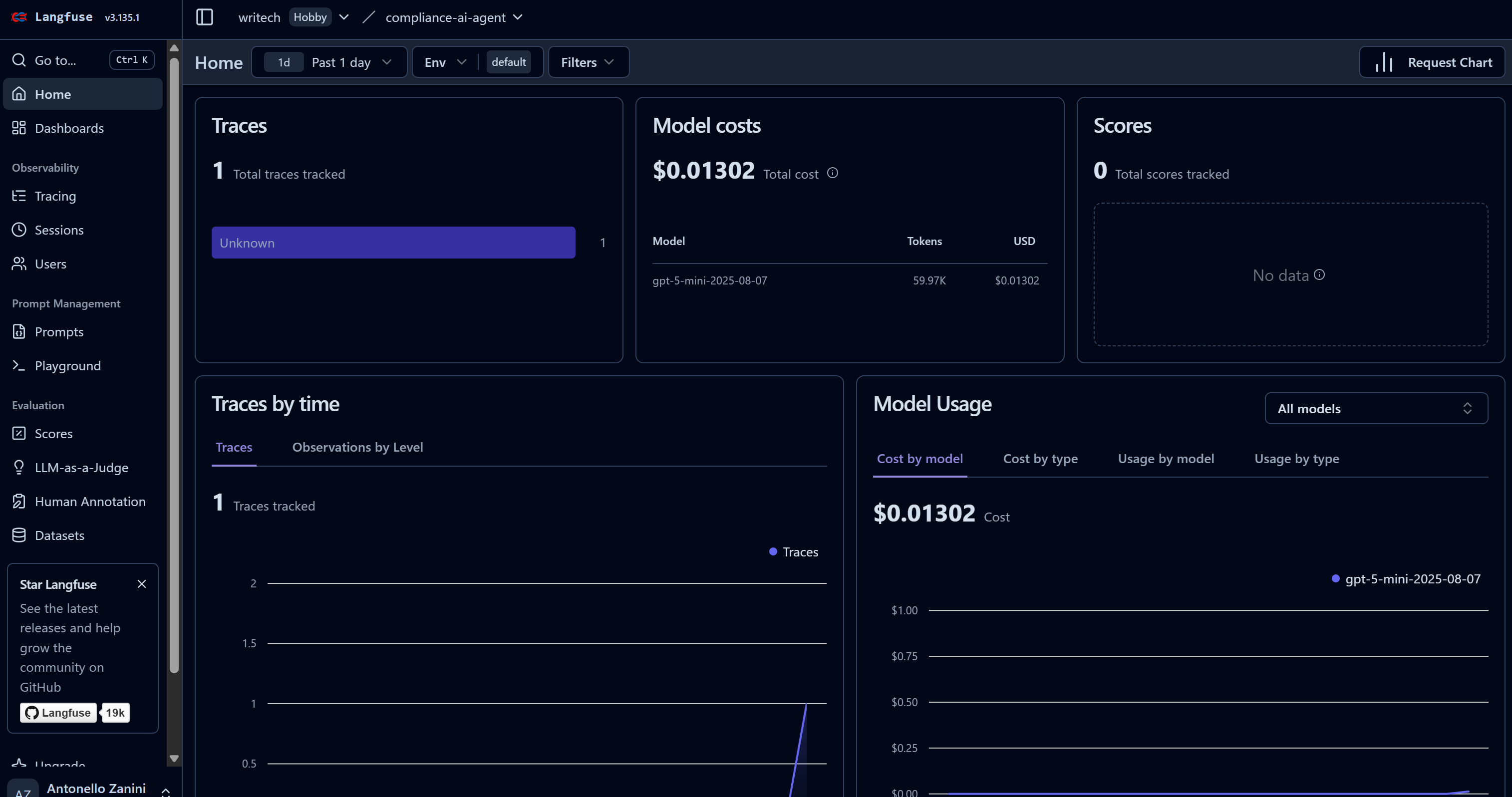
このダッシュボードではコストに加え、多くの有用な指標を監視できます。
特定のエージェント実行に関する全情報を確認するには、「トレース」ページに移動し、該当するエージェントのトレース行をクリックします: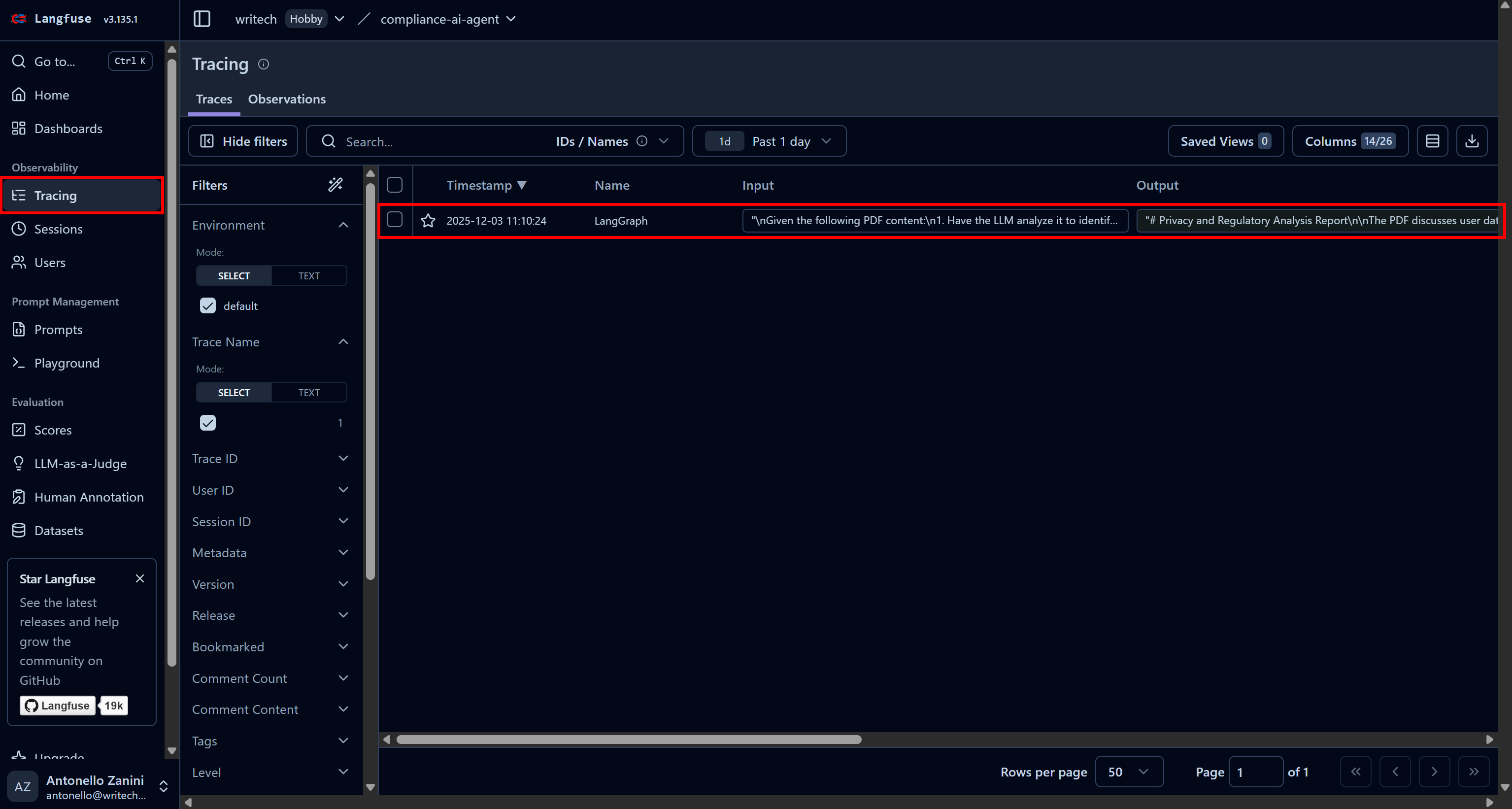
ウェブページの左側にパネルが開き、エージェントが実行した各ステップの詳細情報が表示されます。
最初の「ChatOpenAI」ノードに注目してください。これはエージェントが既にBright Data SERP APIを3回呼び出している一方、Web Unlocker APIはまだ呼び出されていないことを示しています: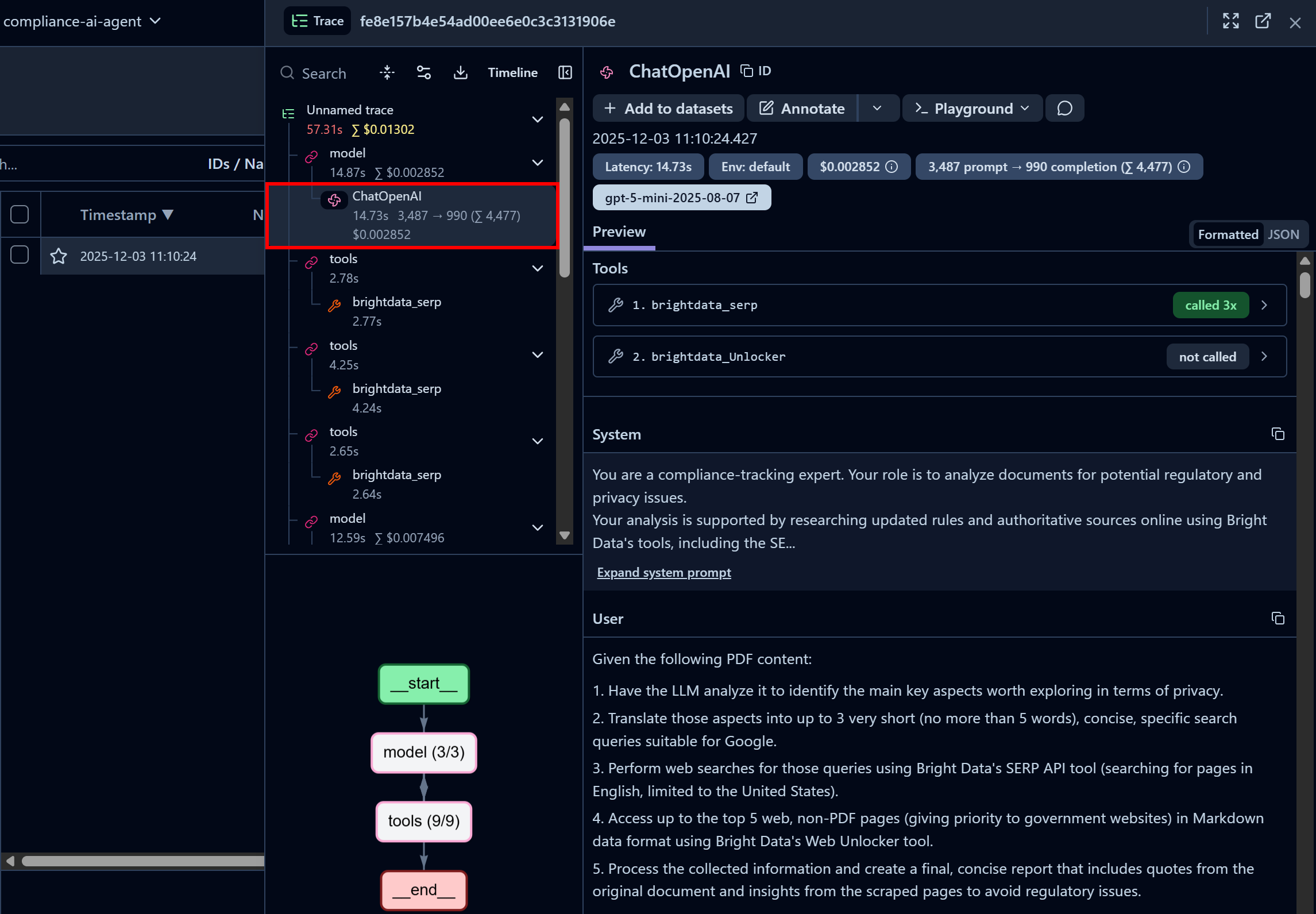
ここでは、コードで設定されたシステムプロンプトやエージェントに渡されたユーザープロンプトも確認できます。さらに、レイテンシー、コスト、タイムスタンプなどの情報にもアクセス可能です。加えて、左下隅のインタラクティブなフローチャートにより、エージェントの実行をステップごとに可視化して探索できます。
次に、Bright Data SERP APIツール呼び出しノードを確認します: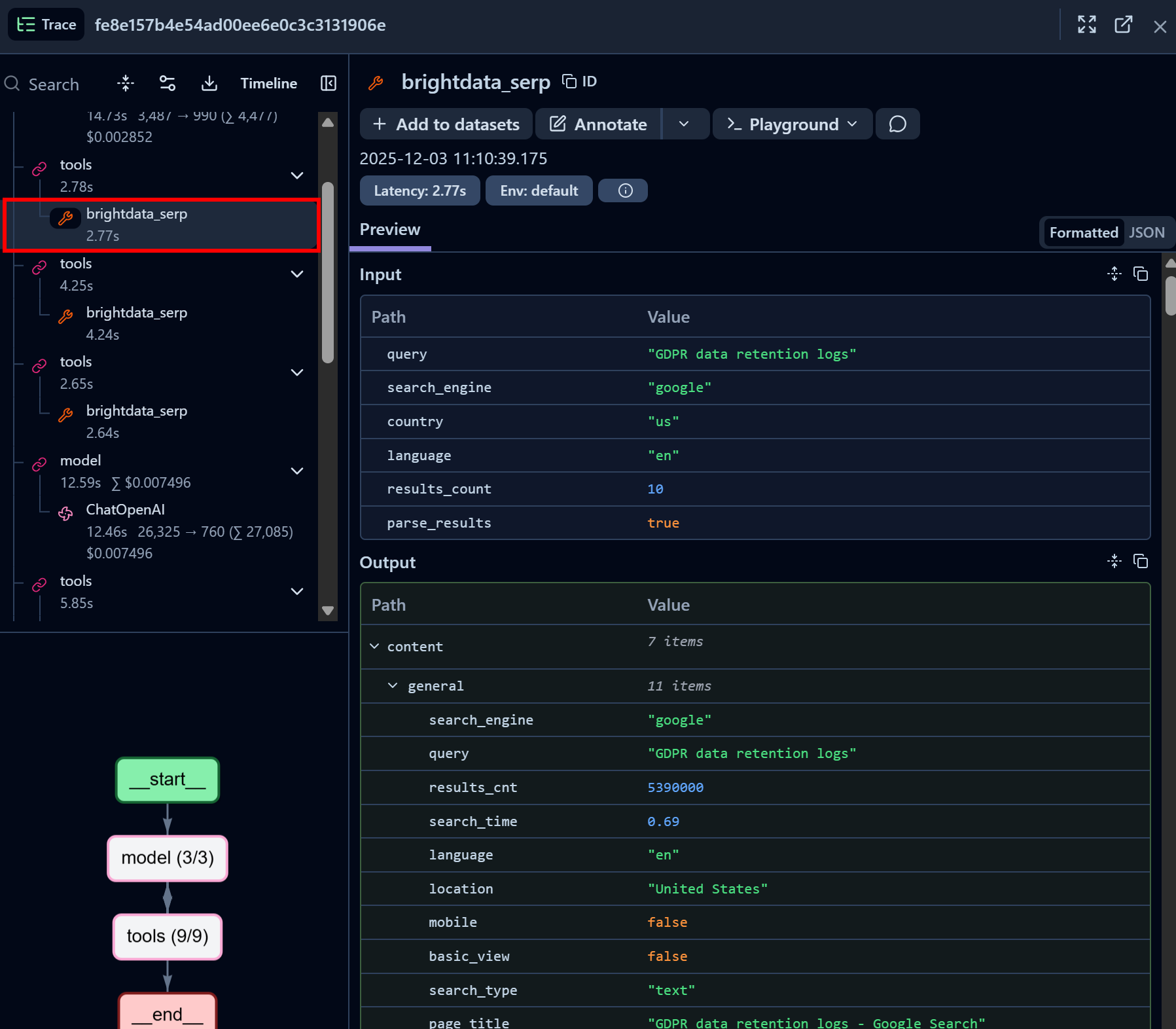
Bright Data SERP API LangChainツールが、指定された検索クエリのSERPデータをJSON形式で正常に返している点に注目してください(AIエージェントでのLLM取り込みに最適です)。これはBright Data SERP APIとの連携が完璧に機能していることを示しています。
PythonでGoogle検索結果のスクレイピングを試みたことがある方なら、その難しさを理解しているでしょう。Bright DataのSERP APIのおかげで、このプロセスは即時的、高速、そして完全にAI対応となりました。
同様に、Bright Data Web Unlocker APIツール呼び出しノードに注目してください: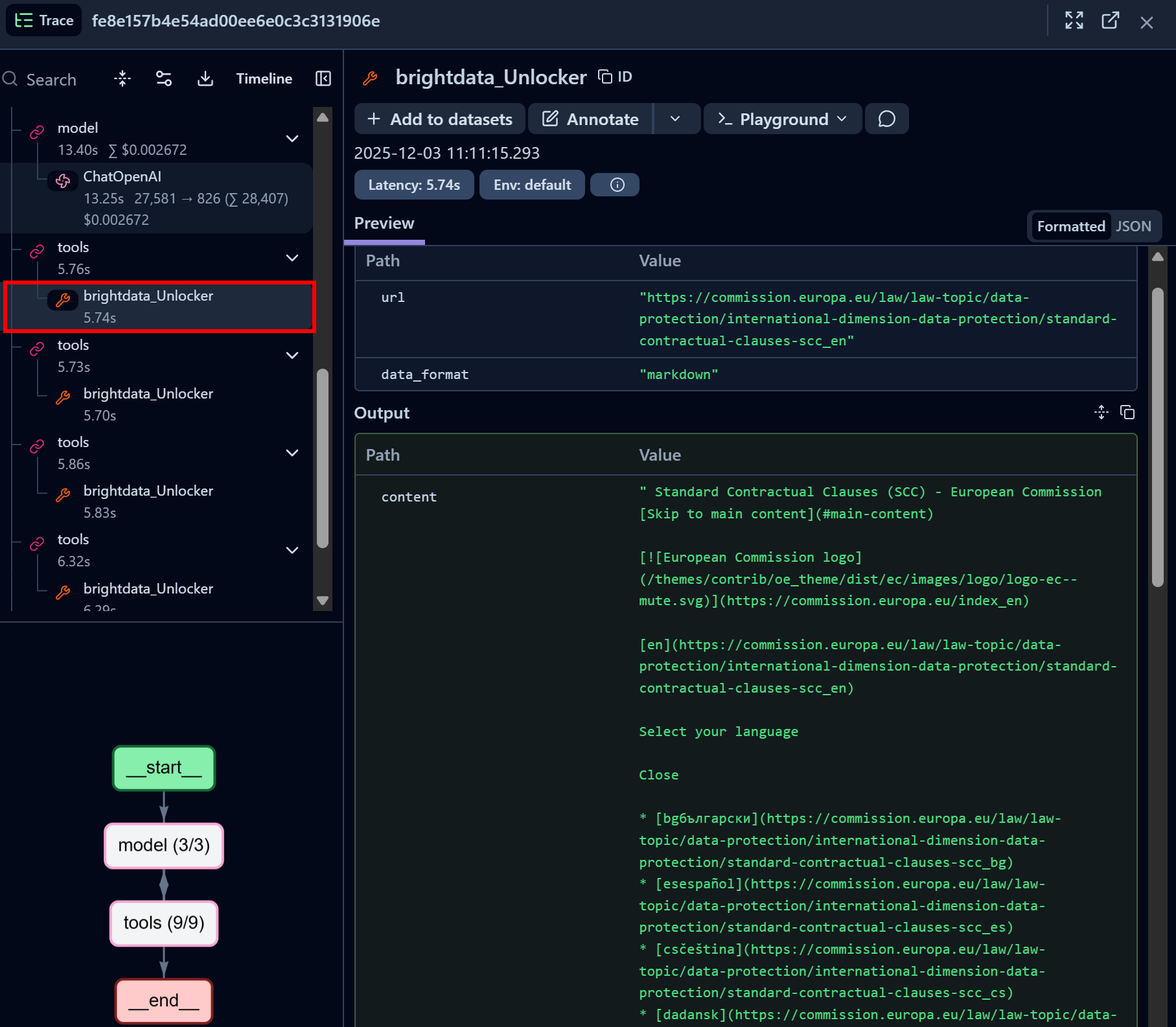
Bright Data Web Unlocker LangChainツールは対象ページへのアクセスに成功し、Markdown形式で返却しました。
Web Unlocker APIは、AIエージェントがブロックを気にせずあらゆるガバナンスサイト(またはその他のウェブページ)にプログラム的にアクセスする能力を提供し、結果としてLLMの取り込みに適したAI最適化バージョンのページを取得します。
素晴らしい!Langfuse + LangChain + Bright Dataの統合が完了しました。Langfuseは他の多くのAIエージェント構築ソリューションとも統合可能で、これら全てがBright Dataによってサポートされています。
次のステップ
このLangfuse連携AIエージェントをさらにエンタープライズグレードにするには、以下の点を検討してください:
- プロンプト管理の追加:Langfuseのプロンプト管理機能を活用し、LLMアプリケーション向けプロンプトの保存・バージョン管理・取得を実現します。
- レポートのエクスポート:最終レポートを生成し、ディスクへの保存、共有フォルダへの格納、または関係者にメール送信のいずれかを選択できます。
- カスタムダッシュボードの定義:Langfuseダッシュボードをカスタマイズし、チームや関係者に必要な指標のみを表示するように設定します。
まとめ
本チュートリアルでは、Langfuseを用いたAIエージェントの監視・追跡方法を学びました。具体的には、Bright DataのAI対応Webアクセスソリューションで駆動するLangChain AIエージェントの計測手法を確認しました。
前述の通り、Langfuseと同様にBright Dataはオープンソースツールからエンタープライズ対応プラットフォームまで、幅広いAIソリューションと連携します。これにより、強力なウェブデータ取得・閲覧機能でエージェントを強化しつつ、Langfuseを通じてそのパフォーマンスと動作を監視することが可能になります。
Bright Dataに無料で登録し、AIのためのウェブデータソリューションを今すぐお試しください!






