

Google Cloud上でCloud Run、Firestore、BigQuery、Workflows、Cloud Schedulerを使用したサーバーレススクレイピングパイプライン構築の手順ガイド。
この記事では以下の内容を学びます:
- – ウェブスクレイピングパイプラインにサーバーレスアーキテクチャが適している理由
- 必要なGoogle Cloudインフラをゼロから設定する方法。
- – Cloud RunへのプライベートスクレイパーサービスとパブリックAPIサービスのデプロイ方法
- Cloud Workflowsでスクレイピング実行をオーケストレーションし、Cloud Schedulerで自動化する方法
- FirestoreとBigQueryを使用したスクレイピングデータの保存とクエリ方法
- パイプライン全体がエンドツーエンドで機能していることを検証する方法。
さあ始めましょう!
サーバーレススクレイピングパイプラインを構築する理由
ほとんどのスクラッピングチュートリアルはスクリプト作成で終わります。HTMLを取得し、いくつかのフィールドをパースする程度です。しかし本番環境でスクレイパーを運用するには、より難しい質問への答えが必要です:データはどこに保存されるのか?スケジュールで実行するには?後で結果をクエリするには?スクレイパーが稼働していない時のコストを抑えるには?
そこでサーバーレスが活躍します。Google Cloud Runはサービスがリクエストを処理している時だけ課金されます。管理すべきサーバーも、夜間にお金を燃やすアイドル状態のコンピューティングリソースも不要です。これにジョブ追跡用のFirestore、分析用のBigQuery、オーケストレーション用のCloud Workflowsを組み合わせれば、アイドル時はゼロにスケールし、オンデマンドで起動するデータパイプラインアーキテクチャが実現します。
このガイドの終わりまでに、以下の環境を構築します:
- Cloud Run 上のプライベート
スクレイパーサービス(実際のスクレイピングを実行) - データを公開するCloud Run上のパブリック
APIサービス。 - ジョブの状態と結果を追跡するFirestoreコレクション。
- 分析用にクエリ可能なBigQueryテーブル
- スクレイピング実行全体を調整するCloud Workflow。
- cronスケジュールでこれをトリガーするCloud Schedulerジョブ。
アーキテクチャの理解
コマンドの実行を始める前に、各要素の連携方法を確認しておくと理解が深まります。当初このシステムを構築する際、適切なアーキテクチャの検討に多くの時間を費やしましたので、その流れをご説明します。
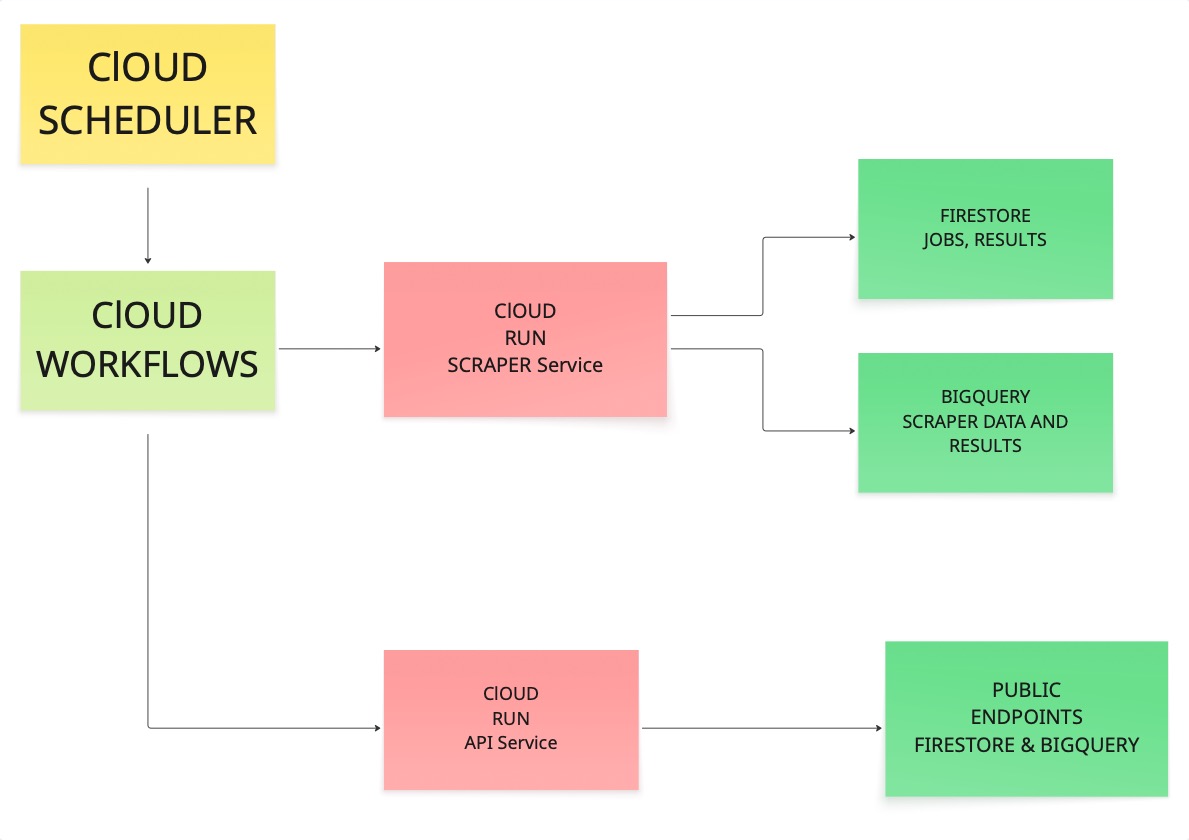
スケジューラーがワークフローをトリガーします。ワークフローがスクレイパーを呼び出します。スクレイパーがURLを訪問し、コンテンツを取得し、結果をFirestoreとBigQueryの両方に書き込みます。その後、APIサービスがそれらのストアから読み取り、パブリックエンドポイントを通じてデータを公開します。
この連鎖の各リンクが機能すれば、本番環境で信頼できるシステムが構築できます。
前提条件
開始前に、以下の準備が整っていることを確認してください:
- Googleアカウント
- 課金設定済みのGCPプロジェクト(費用は最小限ですが、課金が有効である必要があります)。
- Node.js 18 以降。
- マシンにインストール済みの
gcloudCLI。
簡単な動作確認を実行してください:
node --version
npm --version
gcloud --version3つすべてにバージョン番号が表示されれば、準備完了です。
Google Cloudプロジェクトの設定
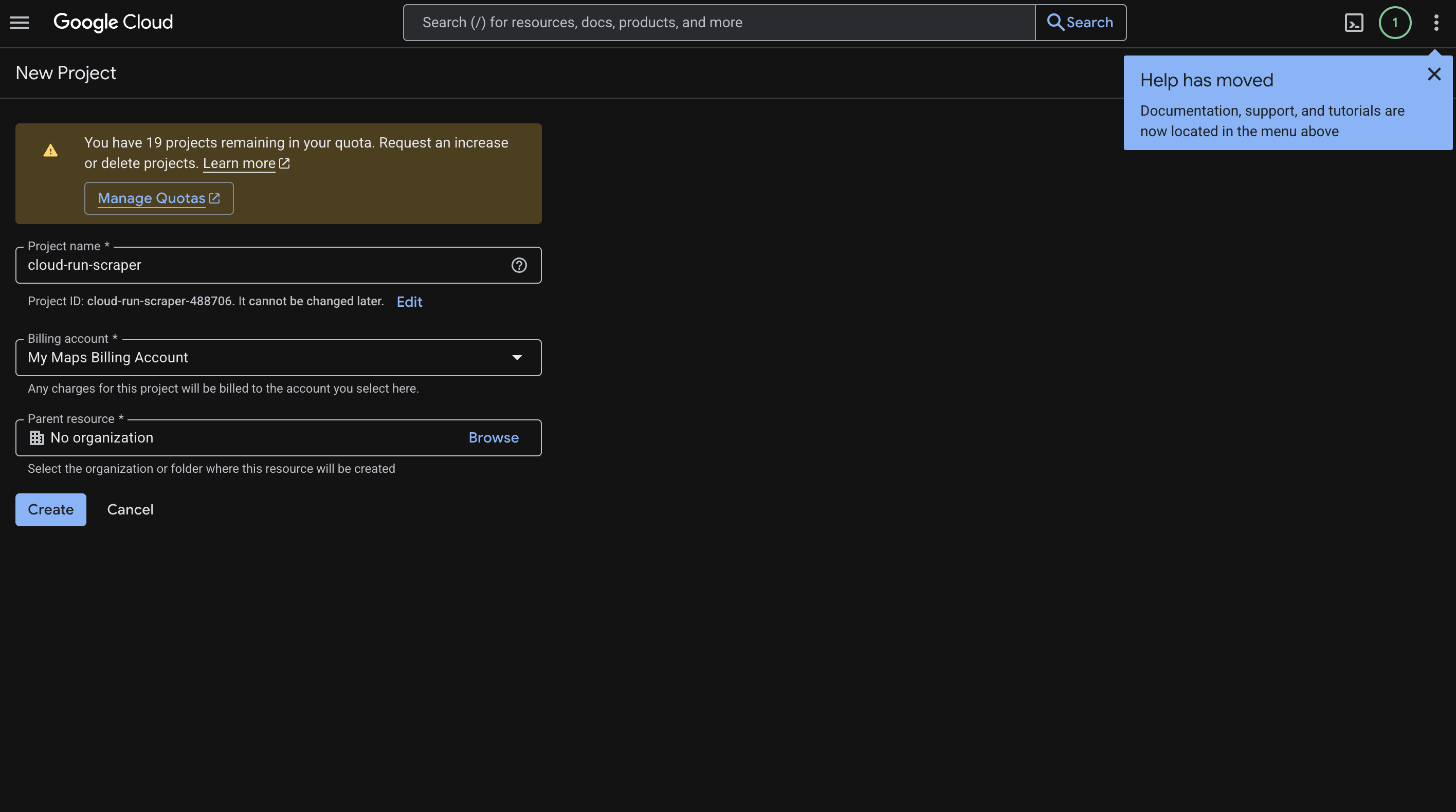
Cloud Consoleにアクセスし、新しいプロジェクトを作成します。ここではcloud-run-スクレイパー という名前を使用しましたが、ご自身のユースケースに合わせて任意の名前を付けてください。
手順は以下の通りです:
- プロジェクト名を入力します。
- [作成]をクリックします。
- 生成されたプロジェクトID(例:
cloud-run-スクレイパー-123456)をコピーします。このIDはガイド全体で必要になります。 - 「請求」に移動し、プロジェクトに請求アカウントをリンクします。
画面は次のようになります:
シェル設定
プロジェクトIDを至る所でコピー&ペーストする必要がないよう、事前にいくつかの環境変数を設定することをお勧めします。これによりコマンドが整理され、再利用可能になります:
export PROJECT_ID="YOUR_PROJECT_ID"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"次にgcloudをプロジェクトに設定します:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"認証を行います(ブラウザが開きます):
gcloud auth login
gcloud auth application-default login必要なAPIの有効化
Google Cloud で多くの人がつまずく点として、必要な API を明示的に有効化しないと何も動作しないことが挙げられます。これはブレーカーを切り替えるようなものと考えてください。以下のコマンドを一度実行すれば完了です:
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.com以下のコマンドで全てが有効化されていることを確認できます:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"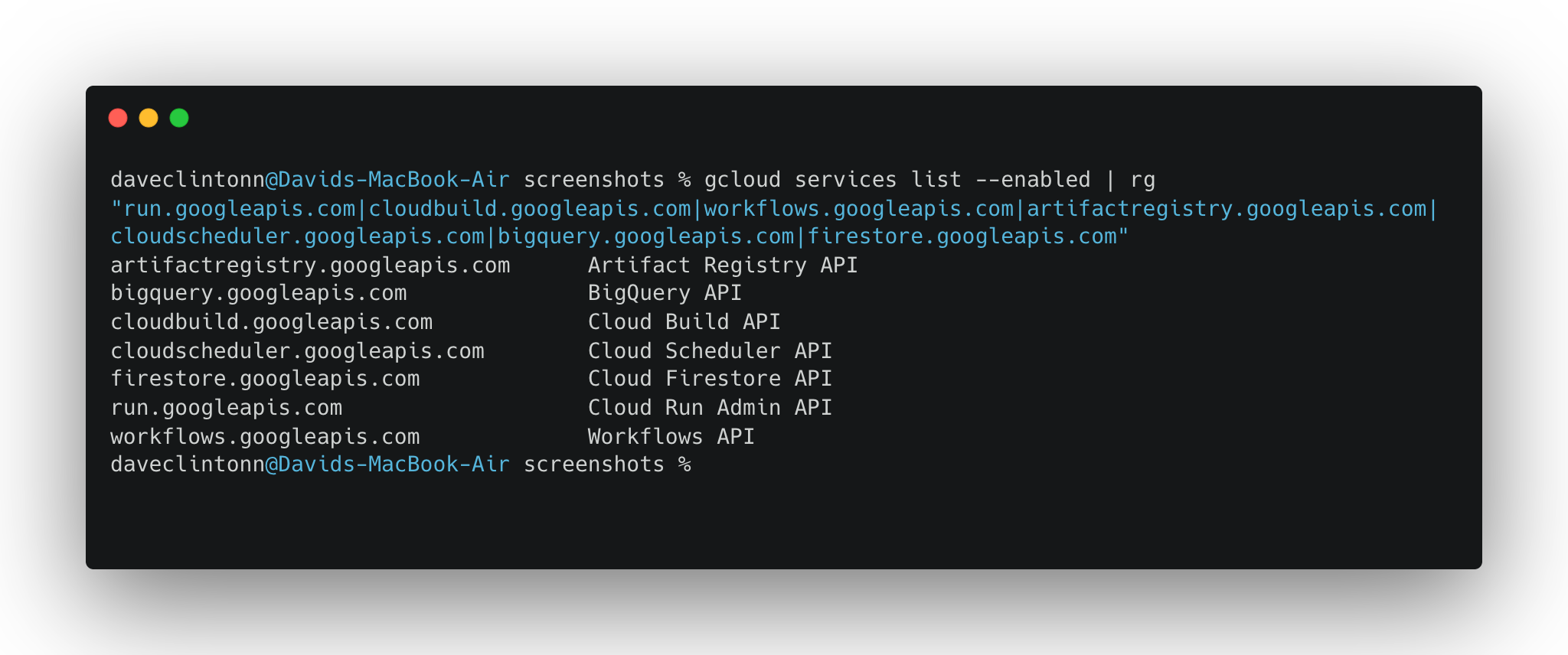
Firestore の設定
ジョブ追跡データの保存と結果のスクレイピングには、ネイティブモードのFirestoreが必要です:
gcloud firestore databases create --location="$REGION" --type=firestore-nativeこのプロジェクトに既にFirestoreが設定されている場合は、この手順をスキップできます。データベースが既に存在するというエラーが発生します。
アーティファクト レジストリの作成
アーティファクト レジストリは Docker イメージの保管場所です。GCP 上のプライベート コンテナ レジストリと考えてください:
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="Docker images for cloud-run-スクレイパー"次に、Docker に認証方法を指示します:
gcloud auth configure-docker "$REGION-docker.pkg.dev"BigQueryの設定
次に、スクレイピングされたデータを格納するBigQueryデータセットとテーブルを作成します。これがパイプライン全体の有用性です。構造化されたETLパイプラインフローにより、スクレイピングされた全データに対してSQLクエリを実行し、トレンドの抽出、ソース別のフィルタリング、ダッシュボード構築が可能になります。
データセットを作成:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"次に、スクレイパーで使用するスキーマでテーブルを作成します:
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRING動作確認:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"IAM権限の設定
この部分は最もエキサイティングではありませんが、非常に重要です。Cloud Runサービスは、Firestore、BigQuery、および相互通信を行うための権限が必要です。これらのIAMバインディングがないと、明確な説明のない不可解な403エラーが発生します。
まず、コンピューティングサービスアカウントを取得します:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"次に必要なロールを付与します:
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"これは5つのロールバインディングです。それぞれがサービスアカウントに特定の操作を許可します:Firestoreの読み取り/書き込み、BigQueryへの挿入、Cloud Runサービスの呼び出し、ワークフローのトリガーです。
依存関係のインストール
リポジトリのルートディレクトリから、両サービスの依存関係をインストールします:
npm --prefix scraper-service install
npm --prefix api-service installスクレイパーサービスのデプロイ
これはパイプライン全体の主力です。URLを訪問し、コンテンツを取得し、結果をFirestoreとBigQueryに書き込むサービスです。スクレイパーでより複雑なボット対策シナリオを処理したい場合は、Bright Dataのスクレイピングブラウザのようなツールを検討する価値があります。クラウドベースのブラウザ自動化を大規模に行うのに適しています。
プライベートサービスとしてデプロイします。--no-allow-unauthenticatedフラグに注意してください。ワークフローからのリクエストなど、認証済みリクエストのみが呼び出せます:
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=productionデプロイ完了後にURLを取得:
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"このURLを保存してください。ワークフロー設定で必要になります。
APIサービスのデプロイ
APIサービスはパイプラインの公開側です。FirestoreとBigQueryから読み込み、エンドポイントを露出させることで、あなたやフロントエンドがスクレイピングされたデータにアクセスできるようにします:
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionURLを取得:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"デプロイ済みサービスのテスト
いよいよ本番サービスの動作確認です。IPブロックやレート制限といったウェブスクレイピングの課題はサーバーレス環境でも発生し得るため、事前に対策を検討しておくことをお勧めします。
APIサービスに対して以下を試してみてください:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"スクレイパーは非公開サービスであるため、認証トークンを渡す必要があります:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"ページ上の特定の要素をターゲットにしたい場合は、カスタムCSSセレクタを渡すこともできます:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
"$SCRAPER_URL/scrape"ワークフローの設定
ワークフローはスクレイパーをスケジュールに紐付けるものです。これはYAMLファイルであり、Cloud Workflowsにリスト内の各URLに対してスクレイパーを呼び出すよう指示します。
workflows/scrape-pipeline.yamlを開き、scraper_urlをスクレイパーデプロイメントステップで取得したURLに設定します。
次にデプロイします:
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"スケジューラジョブの作成
ここでパイプラインが完全に自動化されます。UTC 午前6時に毎日ワークフローを実行するcronジョブを設定します:
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'ジョブが既に存在し、更新のみを行う場合:
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'最初のフルテストの実行
スケジューラーを待機しないでください。ワークフローを手動でトリガーし、パイプライン全体の実行を確認します:
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'実行状況は以下で監視できます:
gcloud workflows executions list scrape-pipeline --location "$REGION"1~2分待ちます。実行結果がSUCCEEDED と表示されれば、データが Firestore と BigQuery に流れ込んでいるはずです。
データの確認
では、データが実際に所定の場所に到達したか確認しましょう。
BigQueryで行数を確認します:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"最新のスクレイピング結果を確認:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"コンソールで Firestore を確認してください。jobsとresults の 2 つのコレクションが表示されるはずです。
次にAPIを実行し、全データが読み取れることを確認します:
curl -s "$API_URL/jobs?limit=1"レスポンスからjobIdを取得し、さらに掘り下げます:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"これらがすべてデータを返す場合、パイプラインはエンドツーエンドで動作しています。
Cloud Build による CI/CD
リポジトリには、両サービスのビルドとデプロイを一括処理するcloudbuild.yamlファイルが含まれています。変更をデプロイする際は以下を実行してください:
gcloud builds submit --config cloudbuild.yaml .この単一コマンドで両Dockerイメージをビルドし、Artifact Registryにプッシュ後、両Cloud Runサービスをデプロイします。単一パイプラインを超える拡張を検討中なら、主要ウェブスクレイピングツールの概要を確認し、このクラウド基盤を補完する多様なソリューションを調査してください。
最終チェックリスト
完了前に以下の検証手順を実行してください:
gcloud run services list --region us-central1で両方のサービスが表示されることを確認してください。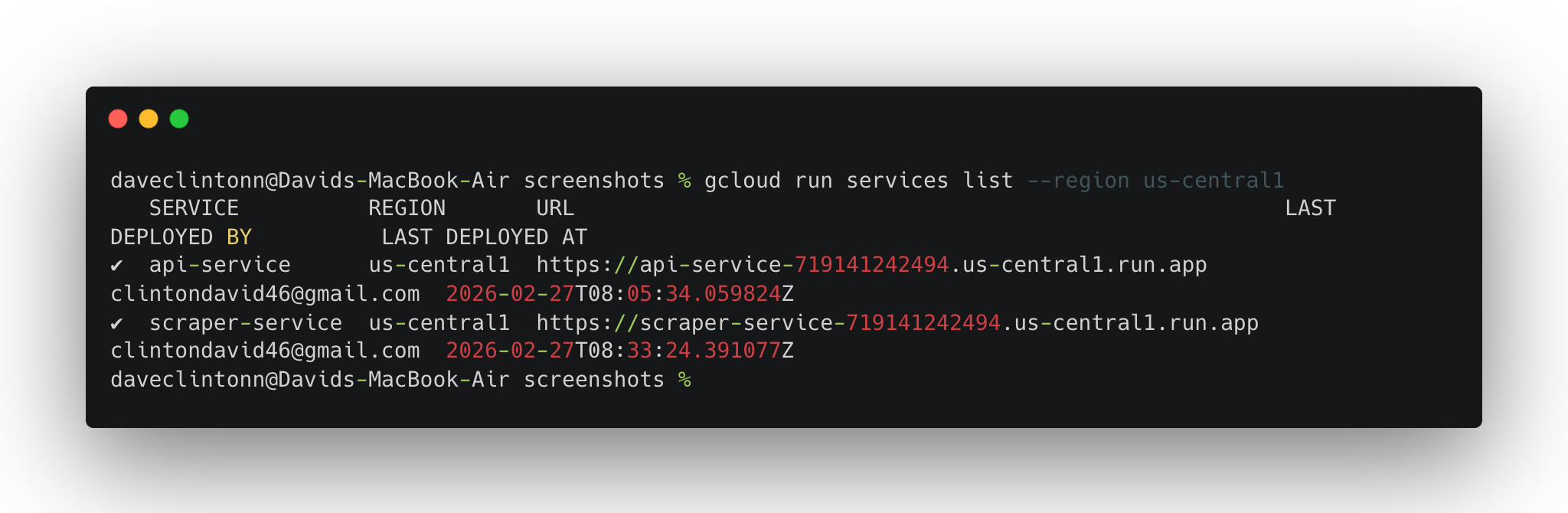
gcloud workflows describe scrape-pipeline --location us-central1でワークフローの詳細が返されるはずです。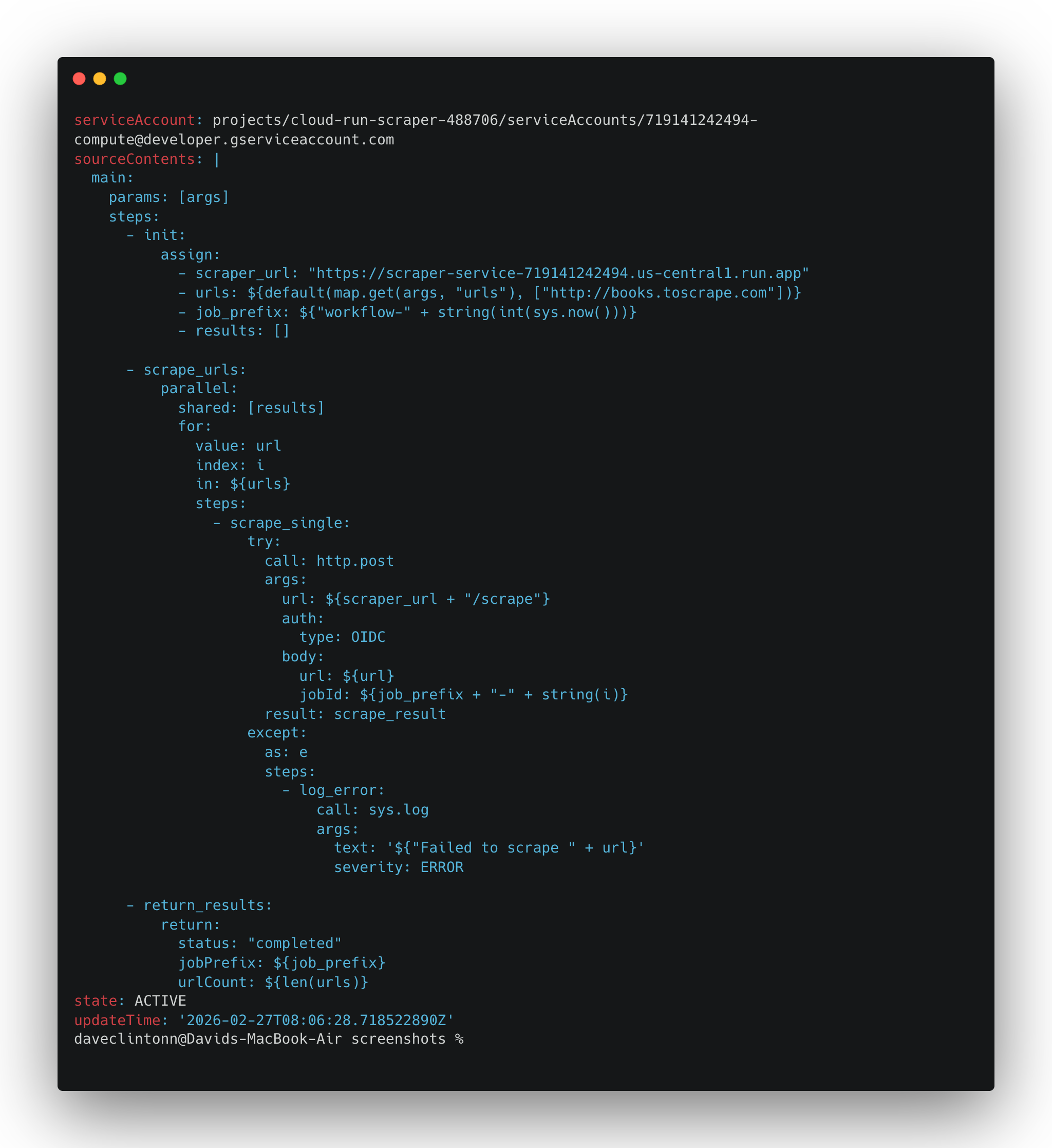
gcloud scheduler jobs list --location us-central1でスケジューラジョブが表示されるはずです。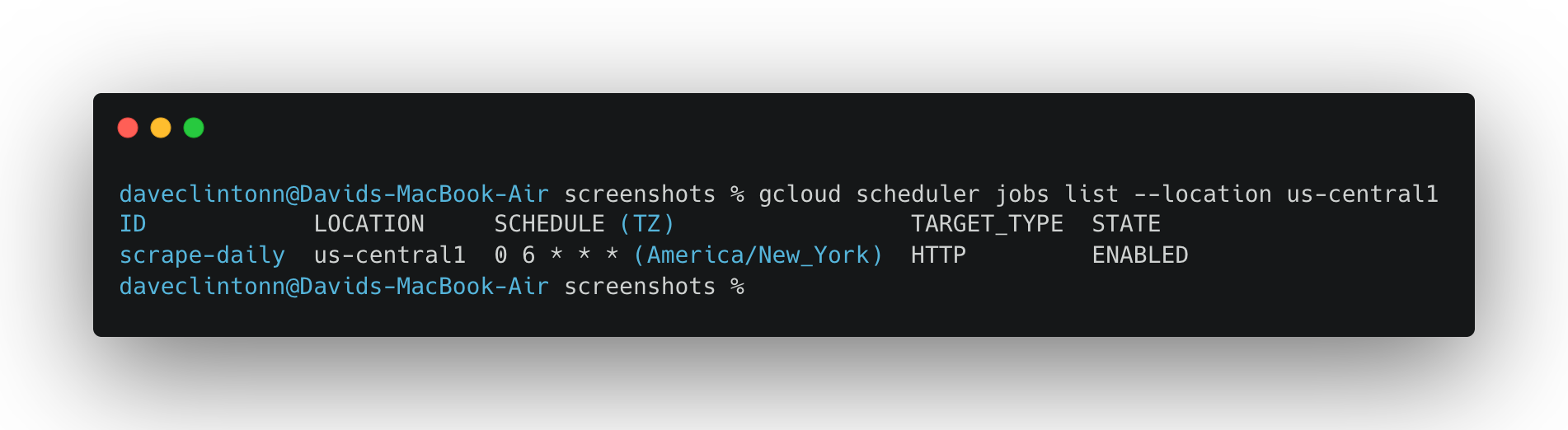
- Firestoreに
ジョブと結果のコレクションが存在すること。 - BigQueryテーブルには行が存在するはずです。
- APIの
/jobsエンドポイントは実際のレコードを返すはずです。
これら6つの項目すべてが正常に動作している場合、もはやデモを実行しているわけではありません。スケジュールに従ってスクレイピングを行い、2か所にデータを保存し、パブリックAPIを通じて提供する、本物のパイプラインを運用していることになります。
まとめ
本ガイドでは、Google Cloud 上で完全なサーバーレス ウェブスクレイピング パイプラインを構築する手順を解説しました。インフラストラクチャの設定、2 つの Cloud Run サービスのデプロイ、Cloud Workflows によるウェブスクレイピング実行のオーケストレーション、Cloud Scheduler による全プロセスの自動化について取り上げました。
インフラの維持管理よりもマネージドなアプローチを好む場合は、Bright Dataの事前収集済みデータセット やスクレイパー Studioを活用し、任意のウェブサイトを既製のデータパイプラインに変換できます。また、ScrapyとAWSを用いたサーバーレススクレイピングのガイドを参照すれば、異なるクラウドプロバイダーにおける類似アーキテクチャの構築方法を確認できます。プロジェクトをクローンし、自身のターゲットURLを差し替えれば、スクレイピングパイプラインを稼働させられます。






