
このチュートリアルでは、次のことを学びます:
- Flyteとは何か、AI、データ、機械学習のワークフローにとってFlyteが特別である理由。
- Webデータを組み込むと、Flyteワークフローがさらに強力になる理由。
- FlyteとBright Data SDKを統合して、SEO分析のためのAIを活用したワークフローを構築する方法。
さっそく見ていきましょう!
Flyteとは?
Flyteは最新のオープンソースワークフローオーケストレーションプラットフォームで、プロダクショングレードのAI、データ、機械学習パイプラインの作成を支援します。Flyteの主な強みは、チームとテクノロジースタックを統合し、データサイエンティスト、MLエンジニア、開発者間のコラボレーションを促進することにあります。
Kubernetes上に構築されたFlyteは、スケーラビリティ、再現性、分散処理のために構築されています。Python SDKを使ってワークフローを定義できます。そして、それらをクラウドまたはオンプレミス環境にデプロイすることで、効率的なリソース利用と簡素化されたワークフロー管理への扉を開くことができる。
本稿執筆時点で、FlyteのGitHubリポジトリは6.5k以上のスターを誇っている!
コア機能
Flyteがサポートする主な機能は以下のとおりです:
- 強い型付きインターフェース:すべてのステップでデータ型を定義することで、正確性を保証し、データのガードレールを実施します。
- 不変性:イミュータブルな実行により、ワークフローの状態の変更を防ぎ、再現性を保証します。
- データリネージ:ワークフローのライフサイクル全体にわたるデータの移動と変換を追跡します。
- マップタスクと並列性:最小限の構成で効率的にタスクを並列実行します。
- きめ細かな再実行と障害回復:失敗したタスクのみを再試行したり、以前のワークフロー状態を変更することなく特定のタスクを再実行します。
- キャッシュ:タスク出力をキャッシュし、繰り返し実行を最適化します。
- 動的なワークフローと分岐: 要件に基づいて進化する適応可能なワークフローを構築し、選択的に分岐を実行します。
- 言語の柔軟性:Python、Java、Scala、JavaScript SDK、または任意の言語の生コンテナを使用してワークフローを開発できます。
- クラウドネイティブなデプロイメント:AWS、GCP、Azure、その他のクラウドプロバイダーにFlyteをデプロイできます。
- 開発から生産までのシンプルさ:ワークフローを開発またはステージングから本番環境に手間なく移行できます。
- 外部入力の処理:必要な入力が利用可能になるまで、実行を一時停止します。
すべての機能については、Flyteの公式ドキュメントを参照してください。
AIワークフローに新鮮なウェブデータが必要な理由
AIワークフローは、処理するデータほど強力ではありません。もちろん、オープンデータは貴重だが、リアルタイムのデータへのアクセスこそが、ビジネスの観点からの違いを生む。そして、最大かつ最も豊富なデータ源は何か?ウェブだ!
リアルタイムのウェブデータをAIのワークフローに組み込むことで、より深い洞察を得て、予測精度を向上させ、より情報に基づいた意思決定を行うことができる。例えば、SEO分析、市場調査、ブランドセンチメントの追跡などのタスクはすべて、オンライン上で常に変化する最新の情報に依存しています。
問題は、新鮮なウェブデータを得ることが難しいということです。ウェブサイトの構造はさまざまで、スクレイピングのアプローチも異なり、更新も頻繁です。そこで、Bright Data Python SDKのようなソリューションの登場です!
このSDKを使えば、生きたウェブコンテンツをプログラムで検索、スクレイピング、対話することができます。具体的には、Bright Dataインフラストラクチャの最も有用なプロダクトへのアクセスを、いくつかのシンプルなメソッドコールで提供します。これにより、ウェブデータへのアクセスが信頼性と拡張性の両方において可能になります。
FlyteとBright Dataのウェブ機能を組み合わせることで、常に変化するウェブに対応した自動AIワークフローを作成できます。次の章でその方法をご覧ください!
FlyteとBright Data Python SDKでSEO AIワークフローを構築する方法
このガイドセクションでは、Flyteで次のようなAIエージェントを構築する方法を学びます:
- キーワード(またはキーフレーズ)を入力として受け取り、Bright Data SDKを使用して関連する結果をウェブ検索します。
- Bright Data SDKを使用して、指定されたキーワードの上位3ページをスクレイピングします。
- 得られたページのコンテンツをOpenAIに渡し、SEOインサイトを含むMarkdownレポートを生成する。
つまり、FlyteとBright Dataの統合により、SEO分析のための実際のAIワークフローが構築されます。これにより、上位にランクインしているページが何を行っているかに基づいて、コンテンツに関連した実用的なインサイトが提供されます。
さっそく始めましょう!
前提条件
このチュートリアルに従うには、以下を確認してください:
- Python がローカルにインストールされていること
- Bright Data APIキー(管理者権限付き)
- OpenAI API キー
Bright Data Python SDK を使用するために Bright Data アカウントを設定する手順を説明します。詳細はドキュメントをご覧ください。
Flyteの公式インストールガイドでは、uv経由でのインストールを推奨しています。そこで、uvをグローバルにインストール/更新します:
pip install -U uvステップ #1: プロジェクトのセットアップ
ターミナルを開き、SEO分析AIプロジェクト用の新しいディレクトリを作成します:
mkdir flyte-seo-workflowflyte-seo-workflow/フォルダには、FlyteワークフローのPythonコードが格納されます。
次に、プロジェクトディレクトリに移動します:
cd flyte-seo-workflowこの記事を書いている時点では、FlyteはPythonのバージョン>=3.9と <3.13のみをサポートしています(バージョン3.12を推奨)。
Python3.12の仮想環境をセットアップします:
uv venv --python 3.12仮想環境を有効にします。LinuxまたはmacOSでは、以下を実行する:
source .venv/bin/activate を実行する。同様に、Windowsでは、以下を実行する:
を実行します。workflow.pyという新しいファイルを追加します。これでプロジェクトは
flyte-seo-workflow/
├─ .venv/
└── workflow.pyworkflow.pyはメインのPythonファイルです。
仮想環境を有効にして、必要な依存関係をインストールします:
uv pip install flytekit brightdata-sdk openaiインストールしたライブラリは以下の通りです:
flytekit:Flyteワークフローとタスクの作成に使用します。brightdata-sdk:PythonでBright Dataのソリューションにアクセスするのに役立ちます。openai:OpenAIのLLMと対話する。
注意: Flyteは公式のChatGPTコネクタ(ChatGPTTask)を提供していますが、これは古いバージョンのOpenAI APIに依存しています。また、厳しいタイムアウトなどの制限もあります。これらの理由から、一般的にはカスタム統合を進める方が良いでしょう。
お好きなPython IDEでプロジェクトをロードします。Python拡張機能付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
完了です!これで、FlyteでAIワークフローを開発するためのPython環境が整いました。
ステップ#2: AIワークフローの考案
いきなりコーディングに入る前に、一歩下がってAIワークフローが何をする必要があるのかを考えてみるとよいでしょう。
まず、Flyteのワークフローは次のように構成されていることを覚えておいてください:
- タスク:
タスク:@taskアノテーションが付けられた関数。これらはFlyteにおける計算の基本単位です。タスクは独立して実行可能で、強く型付けされ、ワークフローを構成するコンテナ化されたビルディングブロックです。 - ワークフロー:
workflowでマークされたワークフローは、タスクを連結することで構築され、あるタスクの出力が次のタスクの入力に供給され、有向無サイクルグラフ(DAG)が形成されます。
この場合、以下の3つの単純なタスクで目的を達成することができる:
get_seo_urls:キーワードやキーフレーズが入力されると、Bright Data SDKを使用して、結果のGoogle SERP(検索エンジンの結果ページ)からトップ3のURLを取得します。get_content_pages:URLを入力として受け取り、Bright Data SDKを使用してページをスクレイピングし、そのコンテンツをMarkdown形式(AI処理に最適)で返します。generate_seo_report:ページのコンテンツリストを取得し、それをプロンプトに渡して、一般的なアプローチ、主要な統計(単語数、段落数、H1、H2など)、その他の関連するメトリクスなどのSEOインサイトを含むMarkdownレポートを作成するよう依頼します。
flytekitからインポートして、Flyteタスクとワークフローを実装する準備をします:
from flytekit import task, workflowすばらしい!あとは実際のワークフローを実装するだけです。
ステップ#3: APIキーの管理
タスクを実装する前に、OpenAIとBright Dataの統合のためのAPIキー管理を行う必要があります。
Flyteには専用のシークレット管理システムが付属しており、APIキーや認証情報など、スクリプト内のシークレットを安全に扱うことができます。本番環境では、Flyteのシークレット管理システムに依存することがベストプラクティスであり、強く推奨されます。
このチュートリアルでは、シンプルなスクリプトを使用するため、コード内で API キーを直接設定することで簡略化できます:
インポート os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"プレースホルダを実際のAPIキー値に置き換えます:
<YOUR_OPENAI_API_KEY>→あなたのOpenAI APIキー。<YOUR_BRIGHT_DATA_API_TOKEN>→Bright Data APIトークン(Bright Dataの公式ガイドに従って取得してください。)
管理者権限のあるBright Data APIキーを使用することをお勧めします。これにより、Bright Data Python SDK はクライアントを初期化する際に自動的にアカウントに接続し、必要なプロダクトを設定することができます。
言い換えると、管理者APIキーを持つBright Data Python SDKは、操作に必要なすべてのものをあなたのアカウントに自動的にセットアップします。
覚えておいてください:プロダクションスクリプトにシークレットをハードコードしないでください!必ずFlyte のシークレットマネージャを使用してください。
ステップ #4:get_seo_urlsタスクの実装
キーワードを文字列として受け取るget_seo_urls()関数を定義し、有効な Flyte タスクとなるように@taskでアノテーションします。関数内部では、Bright Data Python SDKのsearch()メソッドを使用してWeb検索を実行します。
裏側では、search()はBright Data SERP APIを呼び出し、検索結果をこの形式のJSON文字列として返します:
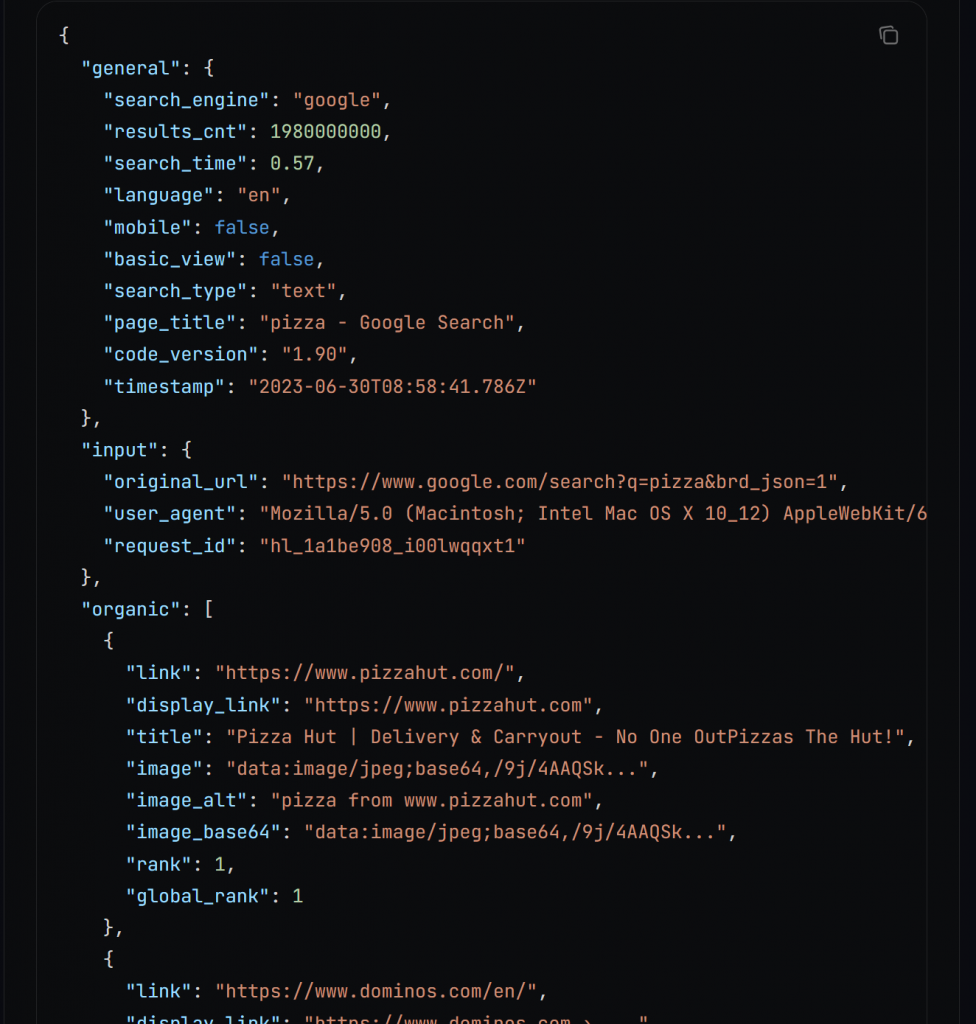
JSON出力機能の詳細については、ドキュメントを参照してください。
JSON文字列を辞書にパースし、指定された数のSEO URLを抽出します。これらのURLは、入力キーワードで検索したときにGoogleから通常得られるであろう上位X個の結果に対応する。
タスクを実装する
タスクは次のように実装します
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Bright Data SDK クライアントの初期化
from brightdata import bdclient
bright_data_client = bdclient()
# 指定されたキーワードのGoogle SERPをパースされたJSON文字列として取得する
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"].
data = json.loads(json_response)
# SERPから "num_links "上位のSEOページURLを抽出する
seo_urls = [item["link"] for item in data["organic"][:num_links]] # SERPから上位のSEOページURLを抽出する。
return seo_urlsタイピングに必要なインポートを覚えておこう:
from typing import List注: なぜBright Data Python SDKクライアントがグローバルではなくタスク内部でインポートされるのか不思議に思うかもしれません。Flyteタスクは独立して実行可能であるべきなので、これは意図的なものです。言い換えると、各タスクは、グローバルな依存関係に依存することなく、それ自身で実行するために必要なすべてを含んでいなければなりません。
ステップ #5:get_content_pagesタスクの実装
SEOのURLを取得したので、Bright Data Python SDKのscrape()メソッドに渡します。このメソッドは全てのページを並行してスクレイピングし、そのコンテンツを返します。出力をMarkdown形式で受け取るには、data_format="markdown "引数を設定するだけです:
タスク
def get_content_pages(page_urls:List[str]) -> List[str]:
# Bright Data SDKクライアントを初期化する
from brightdata import bdclient
bright_data_client = bdclient()
# 各ページからMarkdownコンテンツを取得
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_listは文字列のリストになり、各文字列は対応する入力ページのMarkdown表現です。
scrape()はBright Data Web Unlocker APIを呼び出します。これは汎用のスクレイピングAPIで、ボット対策に関係なく、どんなウェブページにもアクセスできます。
前のタスクで取得したURLに関係なく、get_content_pages()はそのコンテンツを取得し、生のHTMLから最適化されたAI対応のMarkdownに変換します。
ステップ #6:generate_seo_reportタスクの実装
スクレイピングされたページのコンテンツに基づいてSEOレポートを生成するために、適切なプロンプトでOpenAI APIを呼び出します:
def generate_seo_report(page_content_list: List[str]) -> str:
# OpenAI APIを呼び出すためにOpenAIクライアントを初期化する
from openai import OpenAI
openai_client = OpenAI()
# 目的のSEOレポートを生成するためのプロンプト
prompt = f""
# 以下のいくつかのウェブページのコンテンツが与えられる、
各ページのコンテンツを分析することで得られたSEOの洞察を含む # 構造化されたレポートをMarkdown形式で生成する。
# レポートには以下を含めること:
# - 全ページに共通するトピックと要素
# - ページ間の主な相違点
# - 単語数、段落数、H2およびH3見出しの数などの統計を含む要約表。
# コンテンツ
コンテンツ: # {" nPAGE:".join(page_content_list)} # {" nPAGE:".join(page_content_list)
# """
# 選択したAIモデルでプロンプトを実行する
response = openai_client.responses.create(
model="gpt-5-mini"、
input=prompt、
)
return response.output_textこのタスクの出力は、目的のSEO Markdownレポートになります。
注:上記で使用したOpenAIのモデルはGPT-5-miniですが、他のOpenAIのモデルに置き換えることができます。同様に、OpenAIの統合を完全に置き換えて、他のLLMプロバイダーを使うこともできます。
素晴らしい!タスクの準備は整ったので、次はそれらをFlyte AIワークフローに組み合わせる番だ。
ステップ #7: AIワークフローの定義
タスクを順番にオーケストレーションする@workflow関数を作成します:
ワークフロー
def seo_ai_workflow() -> str:
input_kw = "最高のllms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
レポートを返すこのワークフローでは
get_seo_urlsタスクは、”best llms “キーワードのトップ3のSEO URLを取得する。get_content_pagesタスクは、これらのURLのコンテンツをスクレイピングし、Markdownに変換する。generate_seo_reportタスクは、そのMarkdownコンテンツを受け取り、最終的なSEOインサイトレポートをMarkdown形式で作成する。
ミッションは完了だ!
ステップ #8: 全てをまとめる
最終的なworkflow.pyファイルは以下のようになります:
from flytekit import task, workflow
import os
from typing import List
# 必要なシークレットを設定する(APIキーに置き換える)
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"
タスク()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
インポート json
# Bright Data SDK クライアントの初期化
from brightdata import bdclient
bright_data_client = bdclient()
# 指定されたキーワードのGoogle SERPをパースされたJSON文字列として取得する
res = bright_data_client.search(kw, response_format="json", parse=True)
# JSON文字列を解析して辞書に変換する
json_response = res["body"].
data = json.loads(json_response)
# SERPから "num_links "上位のSEOページURLを抽出する
seo_urls = [item["link"] for item in data["organic"][:num_links]] # SERPから上位のSEOページURLを抽出する。
return seo_urls
タスク
def get_content_pages(page_urls: List[str]) -> List[str]:
# Bright Data SDKクライアントの初期化
from brightdata import bdclient
bright_data_client = bdclient()
# 各ページからMarkdownコンテンツを取得
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
タスク
def generate_seo_report(page_content_list: List[str]) -> str:
# OpenAI APIを呼び出すために、OpenAIクライアントを初期化する。
from openai import OpenAI
openai_client = OpenAI()
# 目的のSEOレポートを生成するためのプロンプト
prompt = f""
# 以下のいくつかのウェブページのコンテンツが与えられる、
各ページのコンテンツを分析することで得られたSEOの洞察を含む # 構造化されたレポートをMarkdown形式で生成する。
# レポートには以下を含めること:
# - 全ページに共通するトピックと要素
# - ページ間の主な相違点
# - 単語数、段落数、H2およびH3見出しの数などの統計を含む要約表。
# コンテンツ
コンテンツ: # {" nPAGE:".join(page_content_list)} # {" nPAGE:".join(page_content_list)
# """
# 選択したAIモデルでプロンプトを実行する
response = openai_client.responses.create(
model="gpt-5-mini"、
input=prompt、
)
return response.output_text
ワークフロー
def seo_ai_workflow() -> str:
input_kw = "best llms" # SEO分析の目的に合わせて変更する。
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
レポートを返す
if __name__ == "__main__":
seo_ai_workflow()すごい!80行未満のPythonコードで、完全なSEO AIワークフローを構築しました。これは、FlyteとBright Data SDKなしでは不可能でした。
ワークフローはCLIから実行できます:
pyflyte run workflow.py seo_ai_workflowこのコマンドはworkflow.pyファイルからseo_ai_workflow @workflow関数を起動します。
注意: ウェブ検索、スクレイピング、AI処理には時間がかかるため、結果が表示されるまで少し時間がかかるかもしれません。
ワークフローが完了すると、このようなMarkdown出力が得られるはずです:
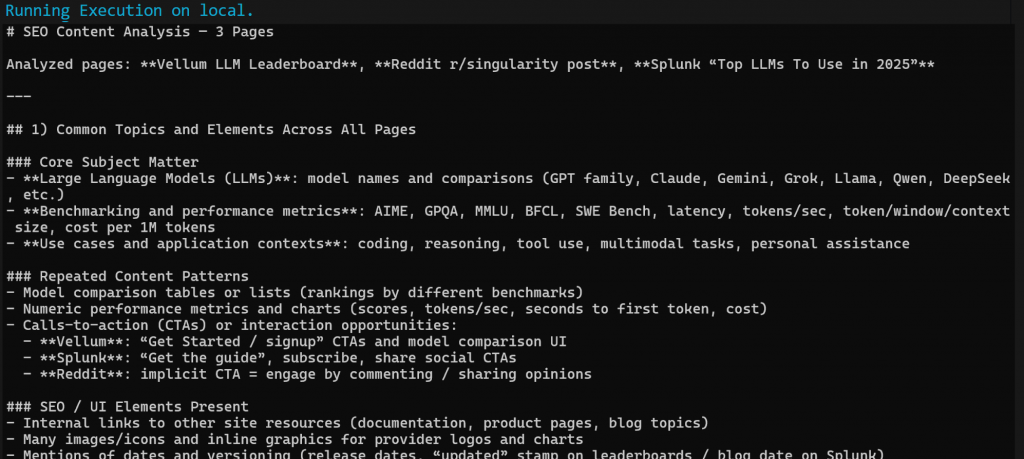
このMarkdown出力を任意のMarkdownビューアーに貼り付けて、スクロールして調べてみよう。下図のようになるはずだ:
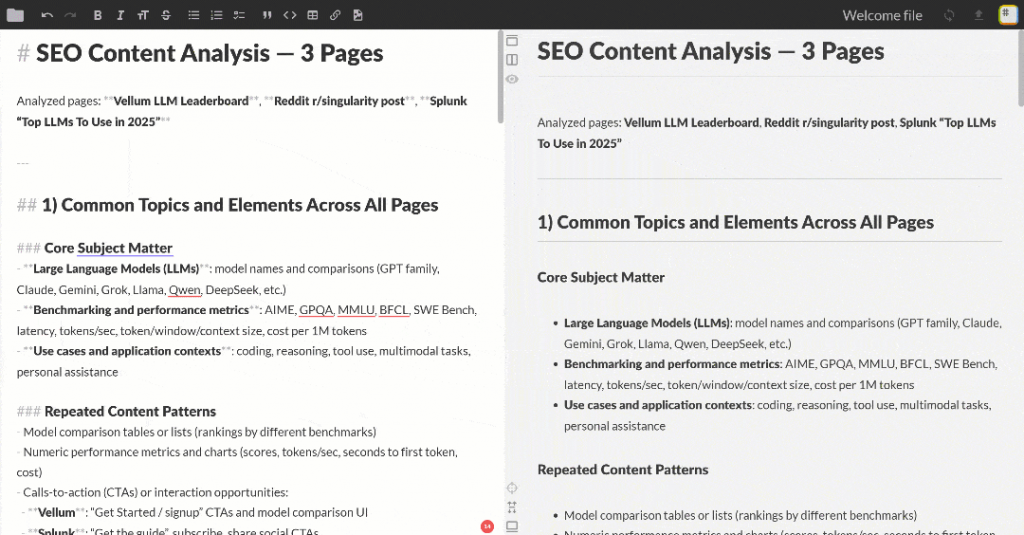
出力には、OpenAIから要求されたとおりに、いくつかのSEOインサイトと要約表が含まれています。これは、FlyteとBright Dataの統合のパワーを示す簡単な例です!
これで完了です!他のタスクを定義し、他の有用なエージェントやAIワークフローのユースケースを実装するために、さまざまなLLMを試してみてください。
次のステップ
ここで紹介したFlyte AIワークフローの実装は、あくまで一例です。本番環境に対応させるため、あるいは適切な実装を進めるためには、次のステップが必要です:
- Flyteがサポートする秘密管理システムを統合する:コード内のAPIキーのハードコーディングは避ける。Flyteのタスクシークレットやその他のサポートされているシステムを使用して、安全かつエレガントにクレデンシャルを処理します。
- プロンプトの処理:タスク内でプロンプトを生成しても構いませんが、再現性を高めるために、プロンプトをバージョン管理するか、外部に保存することを検討してください。
- ワークフローをデプロイする:公式の指示に従ってワークフローを docker化し、Flyte の機能を使用してデプロイの準備をします。
まとめ
このブログ記事では、Flyte内でBright Dataのウェブ検索とスクレイピング機能を使用して、AIを活用したSEO分析ワークフローを作成する方法を学びました。Bright Data SDKは、簡単なメソッド呼び出しによってBright Data製品に簡単にアクセスできるため、実装プロセスはよりシンプルになりました。
より高度なワークフローを構築するには、ライブのウェブデータを取得、検証、変換するBright Data AI インフラストラクチャのソリューションスイートをご覧ください。
Bright Dataアカウントに無料でサインアップして、AI対応のWebデータソリューションの実験を始めてください!





