

このチュートリアルでは、次のことを学びます:
- そもそもなぜカスタムブランドモニタリングソリューションが必要なのか。
- Bright Data SDK、OpenAI、SendGridを使って構築する方法。
- PythonでブランドレピュテーションモニタリングAIワークフローを実装する方法。
全てのプロジェクトファイルはGitHubリポジトリで見ることができます。さあ、飛び込もう!
なぜカスタムブランドモニタリングソリューションを構築するのか?
ブランドモニタリングはマーケティングにおいて最も重要なタスクの一つであり、それを支援するオンラインサービスがいくつかあります。これらのソリューションの問題点は、高額になりがちなことと、特定のニーズに対応していない可能性があることです。
そのため、カスタムブランドの評判モニタリングソリューションを構築することは理にかなっているのです。最初は、それは複雑な目標のように見えるかもしれないので、威圧的に聞こえるかもしれません。しかし、適切なツールを使えば(これからご覧になるように)、それは完全に達成可能です。
ブランド・レピュテーションAIワークフロー ワークフローの説明
何よりもまず、ブランドに関する信頼できる外部情報がなければ、効果的なブランド・モニタリング・ツールを構築することはできない。そのための素晴らしい情報源はGoogleニュースだ。日々のニュース記事で自社ブランドについて何が語られているのか、そしてその背後にある感情を理解することで、情報に基づいた意思決定を行うことができる。最終的なゴールは、ブランドへの対応、保護、宣伝だ。
問題は、ニュース記事のスクレイピングが難しいことだ。特にグーグルニュースは、複数のボット対策で守られている。その上、各ニュースソースは独自の保護対策を施した独自のウェブサイトを持っているため、プログラムでニュースデータを一貫して収集するのは難しい。
そこでBright Dataの出番だ。そのウェブ検索とスクレイピング機能のおかげで、あらゆるウェブサイトからAIに対応した公開ウェブデータにプログラムでアクセスするための多くの製品と統合機能を備えています。
特に、新しいBright Data SDKを使えば、Pythonコードを数行書くだけで、最も便利なBright Dataソリューションをシンプルな方法で活用することができます!
ニュースデータが手に入ったら、AIを頼りに最も関連性の高い記事を選択し、センチメントやブランドインサイトのために分析することができます。そして、Twilio SendGridのようなサービスを利用して、結果のレポートをマーケティングチーム全体に送信することができる。ハイレベルでは、これはまさにカスタムブランドレピュテーションAIワークフローが行うことである。
では、技術的な観点からどのように実装するかを詳しく見てみよう!
技術的ステップ
ブランドレピュテーションモニタリングAIワークフローを実装する手順は以下の通りです:
- 環境変数をロードする:Bright Data、OpenAI、SendGridのAPIキーを環境変数からロードする。これらのキーは、このワークフローを動かすサードパーティ・サービスに接続するために必要である。
- 設定ファイルを読み込む:最初の検索クエリ、レポートに含めるニュース記事の数、送信者のメールアドレスと受信者のメールアドレスを含むJSON設定ファイル(
config.jsonなど)を読み込みます。 - GoogleニュースページのURLを取得します:Bright Data SDKを使用して、設定した検索キーワードの検索エンジン結果ページ(SERP)をスクレイピングします。それぞれのページからGoogle NewsページのURLにアクセスします。
- Googleニュースページをスクレイピングします:Bright Data SDKを使用して、Markdown形式のGoogle Newsページをスクレイピングします。それぞれのページには複数のニュース記事URLが含まれています。
- AIにトップニュースを特定させる:スクレイピングしたGoogle NewsページをOpenAIのモデルにフィードし、ブランドモニタリングに最も関連性の高いニュース記事を選択させます。
- 個々のニュース記事をスクレイピングする:Bright Data SDKを使って、AIが返した各ニュース記事の内容を取得します。
- ブランドの評判についてニュース記事を分析する:各ニュース記事をAIにフィードし、ブランドの評判に関する要約、センチメント分析表示、主要な洞察を提供するよう依頼します。
- 最終的なHTMLレポートを作成する:ニュースの分析結果をAIに渡し、構造化されたHTMLレポートを作成するよう依頼する。
- レポートを電子メールで送信する:SendGrid SDKを活用して、AIが作成したHTMLレポートを指定した受信者に送信し、ブランドの評判に関する包括的な概要を提供する。

PythonでこのAIワークフローを実装する方法を参照してください!
Bright Data SDKでAIを活用したブランドレピュテーションワークフローを作成する
このチュートリアルでは、ブランドの評判を監視するAIワークフローの構築方法を学びます。必要なブランドニュースデータは、Bright DataPython SDKを通じてBright Dataから入手します。AI機能はOpenAIによって提供され、メール配信はSendGridによって処理されます。
このチュートリアルが終わる頃には、結果を受信トレイに直接配信する完全なPython AIワークフローが完成していることでしょう。出力されるレポートは、あなたのブランドが注意すべき重要なニュースを特定し、迅速な対応と強力なブランド・プレゼンスの維持に必要なすべてを提供します。
ブランドレピュテーションAIワークフローを構築してみよう!
前提条件
このチュートリアルに従うには、以下のものがあることを確認してください:
- Python 3.8+がローカルにインストールされていること。
- Bright Data APIキー。
- OpenAI APIキー
- Twilio SendGrid API キー。
Bright Data API トークンをまだお持ちでない場合は、Bright Data にサインアップし、セットアップガイドに従ってください。同様に、OpenAIの公式手順に従って、OpenAI APIキーを取得してください。
SendGridについては、アカウントを作成し、それを確認し、メールアドレスを接続し、ドメインを確認する。APIキーを作成し、プログラムでメールを送信できることを確認する。
ステップ #1: Pythonプロジェクトの作成
ターミナルを開き、ブランドの評判モニタリングAIワークフロー用の新しいディレクトリを作成します:
mkdir brand-reputation-monitoring-workflowbrand-reputation-monitoring-workflow/フォルダには、AIワークフロー用のPythonコードが含まれます。
次に、プロジェクト・ディレクトリに移動し、仮想環境をセットアップする:
cd brand-reputation-monitoring-workflow
python -m venv .venv次に、お気に入りのPython IDEでプロジェクトをロードします。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトフォルダ内に、workflow.py という名前の新しいファイルを追加します。プロジェクトには
brand-reputation-monitoring-workflow/」です。
├─ .venv/
└── workflow.pyworkflow.pyはメインのPythonファイルになります。
仮想環境を有効にする。LinuxまたはmacOSの場合、実行します:
source .venv/bin/activate を実行します。同様に、Windowsでは、以下を実行します:
.venv/Scripts/activate環境をアクティブにした状態で、必要な依存関係をインストールします:
pip install python-dotenv brightdata-sdk openai sendgrid pydanticインストールしたライブラリは以下の通りです:
python-dotenv:.envファイルから環境変数をロードし、APIキーを安全に管理しやすくします。brightdata-sdk:PythonでBright Dataのスクレイピングツールやソリューションにアクセスするのに役立ちます。openaiOpenAIの言語モデルと対話する。sendgridTwilio SendGrid Web API v3 を使って素早くメールを送信する。pydanticAIの出力モデルとあなたの設定を定義する。
完了!あなたのPython開発環境は、OpenAI、Bright Data SDK、SendGridを使って、ブランド評価のモニタリングAIワークフローを構築する準備ができています。
ステップ #2: 環境変数の読み込みを設定する
環境変数から秘密を読み取るようにスクリプトを設定します。workflow.pyファイルで、python-dotenvをインポートし、load_dotenv()を呼び出して環境変数を自動的に読み込みます:
from dotenv import load_dotenv
load_dotenv()これでスクリプトはローカルの.envファイルから変数を読み込めるようになりました。このように、プロジェクト・ディレクトリのルートに.envファイルを作成します:
.envファイルをプロジェクトディレクトリのルートに作成します。
├─ .venv/
├── .env # <----------- └── workflow.py
└── workflow.py.envファイルを開き、OPENAI_API_KEY、BRIGHT_DATA_API_TOKEN、SENDGRID_API_KEYのenvを追加します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
bright_data_api_token="<your_bright_data_api_token>"
sendgrid_api_key="<your_sendgrid_api_token>"プレースホルダーを実際の認証情報で置き換えます:
<YOUR_OPENAI_API_KEY>→あなたのOpenAI APIキー。<YOUR_BRIGHT_DATA_API_TOKEN>→Bright Data APIトークン。<YOUR_SENDGRID_API_KEY>→あなたのSendGrid APIキー。
素晴らしい!これで、環境変数を使用してサードパーティのシークレットを安全に設定できました。
ステップ3: SDKの初期化
必要なインポートを追加することから始めましょう:
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient次に、SDKクライアントを初期化します:
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()上記3行は以下を初期化します:
- Bright Data Python SDK
- OpenAI Python SDK
- SendGrid Python SDK
コード内でAPIキーの環境変数を手動でロードし、コンストラクタに渡す必要はないことに注意してください。なぜなら、OpenAI SDK、Bright Data SDK、SendGrid SDKは、それぞれ自動的にOPENAI_API_KEY、BRIGHT_DATA_API_TOKEN、SENDGRID_API_KEYを環境変数から探すからです。言い換えると、.envにこれらのenvが設定されると、SDKがあなたの代わりにロードを処理します。
特に、SDKは設定されたAPIキーを使用して、あなたのアカウントを使用してサーバーへのAPIコールを認証します。
重要です:Bright Data SDKがどのように動作し、Bright Dataアカウントの必要なゾーンに接続する方法の詳細については、公式GitHubページまたはドキュメントをご覧ください。
完璧です!これで、ブランドレピュテーションモニタリングAIワークフローを構築するための構成要素が揃いました。
ステップ #4: GoogleニュースのURLを取得する
ワークフローのロジックの最初のステップは、監視したいブランド関連の検索クエリのSERPをスクレイピングすることだ。これはBright Data SDKのsearch()メソッドで行い、裏でSERP APIを呼び出す。
そして、search()から取得したJSONテキストレスポンスを解析し、Google NewsページのURLにアクセスします:
https://www.google.com/search?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&。sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQJegQIPhABこの関数ですべてを実現する:
def get_google_news_page_urls(search_queries):
# 与えられた検索クエリに対するSERPを取得する
serp_results = brightdata_client.search(
search_queries、
search_engine="google"、
parse=True # SERPの結果をパースされたJSON文字列として取得する
)
news_page_urls = [].
for serp_result in serp_results:
# JSON文字列を辞書にロードする
serp_data = json.loads(serp_result)
# 解析された各SERPからGoogleニュースのURLを抽出する
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urlssearch()にクエリの配列を渡すと(今回のように)、このメソッドはそれぞれのクエリに対応するSERPの配列を返します。parseは Trueに設定されているので、それぞれの結果はJSON文字列として返され、Pythonの組み込みjsonモジュールでパースする必要があります。
Python標準ライブラリからjsonをインポートすることを忘れないでください:
インポート jsonすごい!これで、あなたのブランドに関連するGoogleニュースページのURLリストをプログラムで取得することができる。
ステップ #5: Googleニュースページをスクレイピングし、ベストなニュースURLを取得する
1つのGoogleニュースページには複数のニュース記事が含まれていることを覚えておこう:
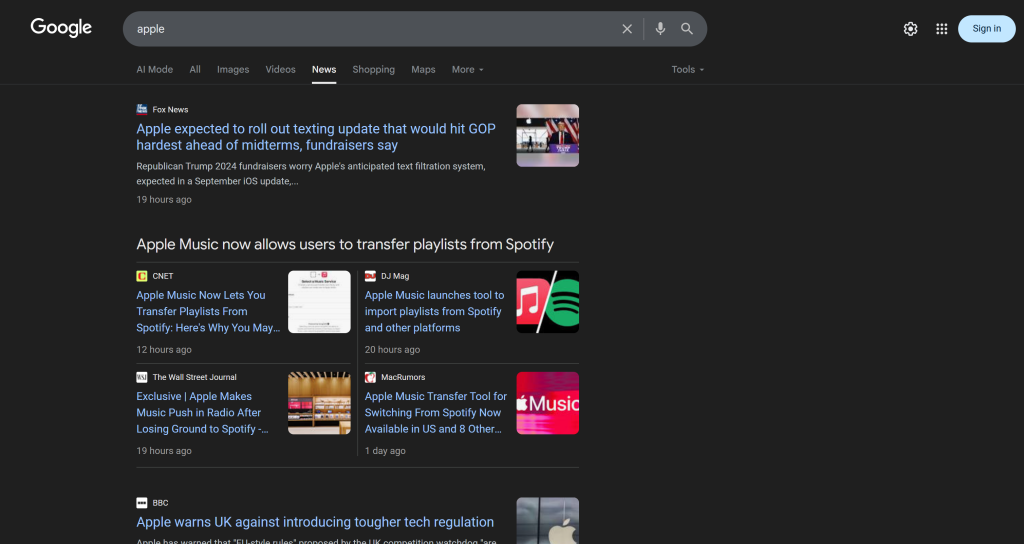
そこで、次のことを行う:
- Googleニュースページのコンテンツをスクレイピングし、結果をMarkdown形式で取得する。
- MarkdownのコンテンツをAI(この場合はOpenAIのモデル)にフィードし、ブランドの評判をモニタリングするためにトップ5のニュース記事を選択するよう依頼する。
この関数で最初のマイクロステップを達成する:
def scrape_news_pages(news_page_urls):
# 各ニュースページを並行してスクレイピングし、そのコンテンツをMarkdownで返す
return brightdata_client.scrape(
url=news_page_urls、
data_format="markdown"
) ブライトデータSDKのscrape()メソッドはWeb Unlocker APIを呼び出します。URLの配列を渡すと、scrape()はスクレイピングタスクを並行して実行し、全てのページを同時に取得します。この場合、APIはLLMの取り込みに理想的なMarkdownでデータを返すように設定されています(Kaggleのデータフォーマットベンチマークで証明されています)。
次に、2番目のマイクロステップを完了させる:
def get_best_news_urls(news_pages, num_news):
# GPTを使って最も関連性の高いニュースのURLを抽出する
response = openai_client.responses.parse(
model="gpt-5-mini"、
input=[
{
"role":「システム
"content": f "ブランドレピュテーションモニタリングに最も関連性の高いニュース{num_news}をテキストから抽出し、URL文字列のリストとして返す。"
},
{
"role":"ユーザー"、
"content":"nn---------------nn".join(news_pages)
},
],
text_format=URLList、
)
return response.output_parsed.urlsこれは単純に、前の関数からのMarkdownテキスト出力を連結し、GPT-5-mini OpenAIモデルに渡し、最も関連性の高いURLを抽出するよう依頼します。
出力はURLListモデルに従うことが期待されており、これは次のように定義されたPydanticモデルです:
クラス URLList(BaseModel):
urls:リスト[str] parse()メソッドのtext_formatオプションのおかげで、結果をURLListのインスタンスとして返すようにOpenAI APIに指示していることになります。基本的には、文字列のリストを取得し、それぞれの文字列が URL を表しています。
pydanticから必要なクラスをインポートします:
from pydantic import BaseModel
from typing import Listすごい!これで構造化されたニュースURLのリストができあがり、ブランドの評判をスクレイピングして分析する準備が整いました。
ステップ #6: ニュースページをスクレイピングし、ブランドレピュテーションモニタリングのために分析する
ベストなニュースURLのリストができたので、もう一度scrape()を使ってコンテンツをMarkdownで取得しよう:
def scrape_news_articles(news_urls):
# 各ニュースのURLをスクレイピングし、URLとコンテンツを含むdictsのリストを返す
news_content_list = brightdata_client.scrape(
url=news_urls、
data_format="markdown"
)
news_list = [] (ニュースリスト)
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url、
「コンテンツ": コンテンツ
})
return news_listこれらのニュース記事がどのドメインでホストされていようと、スクレイピング対策が施されていようと、Web Unlocker APIがそれを処理し、各記事のコンテンツをMarkdownで返してくれる。詳細には、ニュース記事は並行してスクレイピングされます。どのニュースのURLがどのMarkdownの出力に対応しているかを追跡するには、zip()を使います。
次に、ブランドの評判を分析するために、各MarkdownのニュースコンテンツをOpenAIにフィードする。各記事について、以下を抽出する:
- タイトル
- URL
- 短い要約
- 簡単なセンチメントラベル(「ポジティブ」、「ネガティブ」、「ニュートラル」など)
- 3-5つの実用的で、短く、理解しやすい洞察
以下の関数でこれを実現する:
def process_news_list(news_list):
# 分析されたニュース記事を保存する場所
news_analysis_list = [].
# 各ニュース記事をGPTで分析し、ブランドレピュテーションモニタリングのインサイトを得る
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini"、
input=[
{
"role":"system"、
「コンテンツ": f""
ニュースの内容が与えられたら
1.タイトルを抽出する。
2.URLを抽出する。
3.要約を30字以内で書く。
4.ニュースのセンチメントを以下のいずれかとして抽出する:「ポジティブ」、「ネガティブ」、「ニュートラル」のいずれか。
5.ニュースから、ブランドの評判に関する実用的で短い洞察(10~12字以内)を上位3~5個抽出し、明確、簡潔、わかりやすい言葉で提示する。
"""
},
{
"role":"ユーザー"、
"content": f "NEWS URL:{news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis、
)
# 出力された分析済みニュースオブジェクトを取得し、リストに追加する
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list今回、text_formatに設定されたPydanticモデルは以下の通りです:
class NewsAnalysis(BaseModel):
title: str
url: str
summary: str
sentiment_analysis: str
insights: strリスト[str]つまり、process_news_list()関数の結果はNewsAnalysisオブジェクトのリストになります。
素晴らしい!これで、ブランドの評判モニタリングのためのAIによるニュース処理は完了です。
ステップ #7: メールレポートを作成して送信する
Eメールがどのように構成され、クライアントの受信トレイにきれいに表示されるのか不思議に思ったことはありませんか?それは、ほとんどのメール本文が、実際には構造化されたHTMLページだからです。結局のところ、メールプロトコルはHTMLドキュメントの送信をサポートしているのです。
先ほど生成されたニュース分析オブジェクト・リストが与えられたら、それをJSONに変換してAIに渡し、電子メールで送信できるHTMLドキュメントを生成するよう依頼する:
def create_html_email_body(news_analysis_list):
# 分析されたニュースから構造化されたHTMLメール本文を生成する
response = openai_client.responses.create(
model="gpt-5-mini"、
input=f""
以下のコンテンツが与えられたら、書式が整っていて、レスポンシブで、送信可能な構造化されたHTMLメール本文を生成します。
見出し、段落、カラーラベル、リンクを適切に使用してください。
ヘッダーやフッターのセクションは含めず、これらの情報のみを含めるようにしてください。
コンテンツ:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]]}。
"""
)
return response.output_text最後に、Twilio SendGrid SDKを使用して、プログラムでメールを送信します:
def send_email(sender, recipients, html_body):
# SendGridを使ってHTMLメールを送信
message = Mail(
from_email=sender、
to_emails=recipients、
件名="ブランドモニタリング週間レポート"、
html_content=html_body
)
sendgrid_client.send(message)これには以下のインポートが必要です:
from sendgrid.helpers.mail import Mailこれで完了だ!これで、このブランドレピュテーション監視AIワークフローを実装するためのすべての関数が実装されました。
ステップ #8: 環境設定とコンフィギュレーションのロード
前のステップで定義した関数の中には、特定の引数を受け付けるものがあります(search_queries、num_news、sender、recipientsなど)。これらの値は実行ごとに変わる可能性があるので、Pythonスクリプトにハードコードすべきではありません。
その代わりに、以下のフィールドを含むconfig.jsonファイルからそれらを読み込みます:
search_queries:ニュースを取得するブランド評価クエリのリスト。num_news:最終レポートで取り上げるニュース記事の数。送信者:レポートの送信元となるSendGridが承認したメールアドレス。受信者:HTMLレポートを送信するメールアドレスのリスト。
以下のPydanticクラスを使って設定オブジェクトをモデル化します:
クラス Config(BaseModel):
search_queries:リスト[str] = フィールド(..., min_items=1)
num_news: int = Field(..., gt=0)
sender: str = Field(..., min_length=1)
受信者リスト[str] = Field(..., min_items=1)Field定義は、コンフィギュレーションが期待されるフォーマットに準拠していることを確認するための検証ルールを指定します。でインポートします:
from pydantic import Field次に、ワークフロー設定をローカルのconfig.jsonファイルから読み込み、Configオブジェクトにパースします:
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config) プロジェクトのディレクトリにconfig.jsonファイルを追加します:
config.jsonファイルをプロジェクトのディレクトリに追加します。
├─ .venv/
├─ .env
├── config.json # <----------- └── workflow.py
└── workflow.pyそして、以下のように入力する:
{
"search_queries": ["apple", "iphone", "ipad"]、
"sender":"[email protected]"、
「recipients": ["[email protected]", "[email protected]", "[email protected]"]、
「num_news":5
}この値は、あなたの目標に合わせて変更してください。また、送信者フィールドはSendGridアカウントで認証されたメールアドレスでなければならないことを覚えておいてください。そうでない場合、send_email()関数は403 Forbiddenエラーで失敗します。
完了です!これでワークフローは完成です。
ステップ #9: メイン関数の定義
すべてを構成する時間です。各定義済み関数を正しい順序で呼び出し、設定から正しい入力を与えます:
search_queries = config.search_queries
print(f "Retrieving Google News page URLs for the following search queries:print(f "Retrieving Google News page URLs for the following search queries: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} GoogleニュースページのURLを取得しました。
print("各Googleニュースページからコンテンツをスクレイピング...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Googleニュースのページをスクレイピングしました。")
print("最も関連性の高いニュースのURLを抽出...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)}ニュース記事が見つかりました:˶" + "˶".join(f"- {news}" for news in news_urls) + "˶")
print("Scraping the selected news articles...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} スクラップされたニュース記事!")
print("ブランドの評判モニタリングのために各ニュースを分析...")
news_analysis_list = process_news_list(news_list)
print("ニュースの分析が完了しました。")
print("HTMLメール本文の生成...")
html = create_html_email_body(news_analysis_list)
print("HTMLメール本文を生成しました。")
print("ブランドレピュテーションのモニタリングHTMLレポートを含むメールを送信します...")
send_email(config.sender, config.recipients, html)
print("メールを送信しました!")注:ワークフローが完了するまでに時間がかかるかもしれないので、ターミナルで進行状況を追跡するためにログを追加すると便利です。ミッション完了!
ステップ10:すべてをまとめる
workflow.pyファイルの最終的なコードは次のようになります:
from dotenv import load_dotenv
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Field
from typing import リスト
json をインポート
from sendgrid.helpers.mail import Mail
# .env ファイルから環境変数をロードする
load_dotenv()
# Bright Data SDKクライアントを初期化します
brightdata_client = bdclient()
# OpenAI SDK クライアントの初期化
openai_client = OpenAI()
# SendGrid SDK クライアントの初期化
sendgrid_client = SendGridAPIClient()
# Pydantic モデル
class Config(BaseModel):
search_queries:List[str] = Field(..., min_items=1)
num_news: int = Field(..., gt=0)
sender: str = Field(..., min_length=1)
受信者リスト[str] = フィールド(..., min_items=1)
class URLList(BaseModel):
urls:リスト[str]
class NewsAnalysis(BaseModel):
title: str
url: str
summary: str
sentiment_analysis: str
insights: strリスト[str]
def get_google_news_page_urls(search_queries):
# 指定された検索クエリのSERPを取得する
serp_results = brightdata_client.search(
search_queries、
search_engine="google"、
parse=True # SERPの結果をパースされたJSON文字列として取得する
)
news_page_urls = [].
for serp_result in serp_results:
# JSON文字列を辞書にロードする
serp_data = json.loads(serp_result)
# 解析された各SERPからGoogleニュースのURLを抽出する
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urls
def scrape_news_pages(news_page_urls):
# 各ニュースページを並行してスクレイピングし、その内容をMarkdownで返す
return brightdata_client.scrape(
url=news_page_urls、
data_format="markdown"
)
def get_best_news_urls(news_pages, num_news):
# GPTを使って最も関連性の高いニュースのURLを抽出する
response = openai_client.responses.parse(
model="gpt-5-mini"、
input=[
{
"role":「システム
"content": f "ブランドレピュテーションモニタリングに最も関連性の高いニュース{num_news}をテキストから抽出し、URL文字列のリストとして返す。"
},
{
"role":"ユーザー"、
"content":"nn---------------nn".join(news_pages)
},
],
text_format=URLList、
)
return response.output_parsed.urls
def scrape_news_articles(news_urls):
# 各ニュースのURLをスクレイピングし、URLとコンテンツを含むdictsのリストを返す
news_content_list = brightdata_client.scrape(
url=news_urls、
data_format="markdown"
)
news_list = [] (ニュースリスト)
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url、
「コンテンツ": コンテンツ
})
return news_list
def process_news_list(news_list):
# 分析されたニュース記事を格納する場所
news_analysis_list = [].
# 各ニュース記事をGPTで分析し、ブランドレピュテーションモニタリングのインサイトを得る
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini"、
input=[
{
"role":"system"、
「コンテンツ": f""
ニュースの内容が与えられたら
1.タイトルを抽出する。
2.URLを抽出する。
3.要約を30字以内で書く。
4.ニュースのセンチメントを以下のいずれかとして抽出する:「ポジティブ」、「ネガティブ」、「ニュートラル」のいずれか。
5.ニュースから、ブランドの評判に関する実用的で短い洞察(10~12字以内)を上位3~5個抽出し、明確、簡潔、わかりやすい言葉で提示する。
"""
},
{
"role":"ユーザー"、
"content": f "NEWS URL:{news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis、
)
# 出力された分析済みニュースオブジェクトを取得し、リストに追加する
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list
def create_html_email_body(news_analysis_list):
# 分析されたニュースから構造化されたHTMLメール本文を生成する
response = openai_client.responses.create(
model="gpt-5-mini"、
input=f""
以下のコンテンツが与えられたら、書式が整っていて、レスポンシブで、送信可能な構造化されたHTMLメール本文を生成します。
見出し、段落、カラーラベル、リンクを適切に使用してください。
ヘッダーやフッターのセクションは含めず、これらの情報のみを含めるようにしてください。
コンテンツ:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]]}。
"""
)
return response.output_text
def send_email(sender, recipients, html_body):
# SendGridを使ってHTMLメールを送信する
message = Mail(
from_email=sender、
to_emails=recipients、
件名="ブランドモニタリング週間レポート"、
html_content=html_body
)
sendgrid_client.send(message)
def main():
# コンフィグファイルの読み込みとバリデーション
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config)
search_queries = config.search_queries
print(f "Retrieving Google News page URLs for the following search queries:{", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} GoogleニュースページのURLを取得しました。
print("各Googleニュースページからコンテンツをスクレイピング...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Googleニュースのページをスクレイピングしました。")
print("最も関連性の高いニュースのURLを抽出...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)}ニュース記事が見つかりました:˶" + "˶".join(f"- {news}" for news in news_urls) + "˶")
print("Scraping the selected news articles...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} スクラップされたニュース記事!")
print("ブランドの評判モニタリングのために各ニュースを分析...")
news_analysis_list = process_news_list(news_list)
print("ニュースの分析が完了しました。")
print("HTMLメール本文の生成...")
html = create_html_email_body(news_analysis_list)
print("HTMLメール本文を生成しました。")
print("ブランドレピュテーションのモニタリングHTMLレポートを含むメールを送信します...")
send_email(config.sender, config.recipients, html)
print("メールを送信しました!")
# メイン関数を実行する
if __name__ == "__main__":
main()これで完了だ!Bright Data SDK、OpenAI API、Twilio SendGrid SDKのおかげで、200行以下のコードでAIを活用したブランドレピュテーション監視ワークフローを構築することができました。
ステップ #11: ワークフローのテスト
search_queriesを "nike "と"nike shoes "に設定し、num_newsを 5に設定し、レポートを個人のEメールに送信するように設定します(送信者と受信者の最初の項目の両方に同じEメールアドレスを使用できることに注意してください)。
アクティベートした仮想環境で、ワークフローを起動します:
python workflow.pyターミナルに表示される結果は以下のようになります:
次の検索クエリに対する Google ニュースページの URL を取得: nike, nike shoes
2 Google ニュースページの URL が取得されました!
各Googleニュースページからコンテンツをスクレイピング...
Googleニュースのページがスクレイピングされました!
最も関連性の高いニュースURLを抽出...
5件のニュース記事が見つかりました:
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
選択したニュース記事をスクレイピング...
5つのニュース記事をスクレイピング!
各ニュース記事をブランドの評判モニタリングのために分析...
ニュース分析完了
HTMLメール本文の生成
HTMLメール本文が生成されました!
ブランドレピュテーションモニタリングHTMLレポートをメール送信...
メールが送信されました!注:結果は利用可能なニュースに基づいて変更されます。そのため、このチュートリアルを読む頃には、上記の結果と同じになっていることはありません。
メールが送信されました!」メッセージの後、受信トレイに「ブランドモニタリング週次レポート」メールが表示されるはずです:

それを開くと、次のような内容が記載されています:
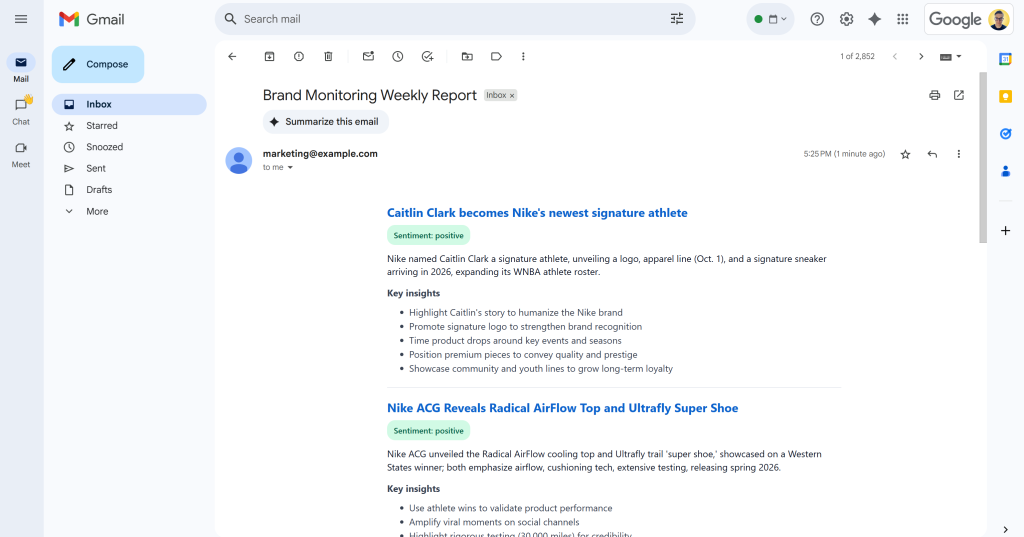
ご覧のように、AIは要求されたすべてのデータを含む視覚的に魅力的なブランド・モニタリング・レポートを作成することができました。
レポートをスクロールしてください:
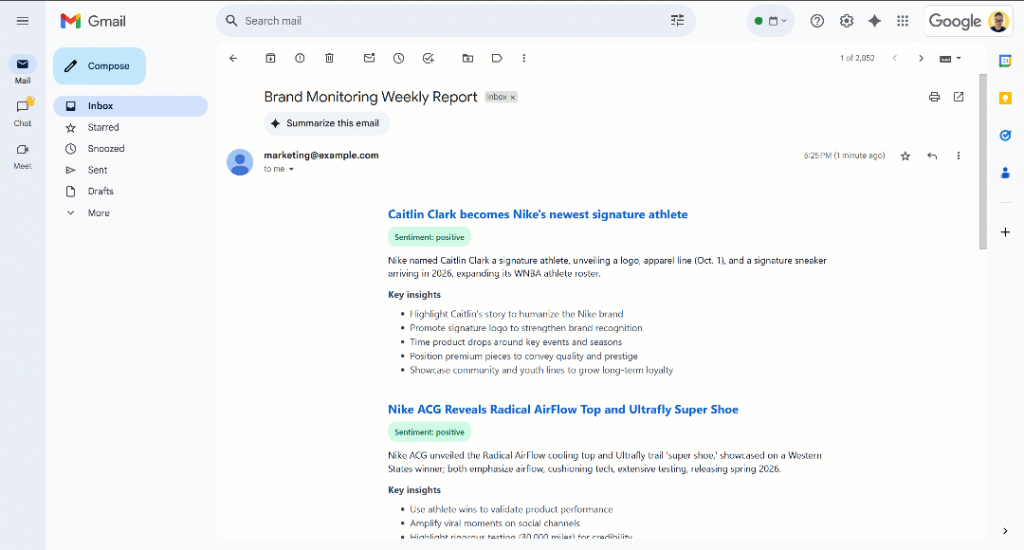
センチメントのラベルは、センチメントを素早く理解できるように色分けされていることに注目してください。また、ニュースアイテムのタイトルは青色で表示されています。
これで完了です!あなたは、いくつかの検索クエリから始めて、よく構造化されたブランドモニタリングレポートを含むEメールに行き着きました。
これはすべて、Bright Data SDKで利用可能なウェブデータスクレイピングソリューションのパワーのおかげです。スクレイピングされたページは、LLMに最適化されたMarkdown形式で返されるため、どのAIモデルでもニーズに合わせて分析できることを覚えておいてください。サポートされている他のエージェントとAIワークフローの使用例をご覧ください!
次のステップ
現在のブランドレピュテーションモニタリングAIワークフローはすでにかなり洗練されているが、以下のアイデアでさらに改善することができる:
- 過去に取り上げたニュースのメモリーレイヤーを追加する:同じ記事を何度も分析することを避け、重複を減らしながらレポートの精度を高める。
- 標準化のためにSendGridのテンプレート化を導入する:AIは、実行するたびに、構造が微妙に異なるHTMLレポートを作成する可能性がある。レイアウトを統一するには、SendGridテンプレートを定義し、生成されたニュース分析データを入力して、SendGrid SDK経由で送信します。詳しくは公式ドキュメントをご覧ください。
- 生成されたHTMLレポートをクラウドに保存します:レポートをS3に保存し、アーカイブして過去のブランドモニタリング分析に利用できるようにします。
まとめ
この記事では、Bright Dataのウェブ検索とスクレイピング機能を活用して、AIを活用したブランドレピュテーションワークフローを構築する方法を学びました。このプロセスは、シンプルなメソッドコールでBright Data製品にアクセスできる新しいBright Data SDKのおかげでさらに簡単になりました。
ここで紹介するAIワークフローは、ブランドをモニタリングし、低コストで実用的な洞察を得ることに関心のあるマーケティングチームに最適です。ブランド保護と意思決定をサポートするために文脈に沿った指示を提供することで、時間と労力の節約に役立ちます。
より高度なワークフローを作成するには、ライブのウェブデータを取得、検証、変換するBright Data AI インフラストラクチャのあらゆるソリューションをご覧ください。
無料のBright Dataアカウントを作成し、AI対応のウェブデータソリューションの実験を開始してください!






