

このブログ記事では以下をご覧いただけます:
- – Claude Agent SDKの定義と独自性
- より強力なAIエージェントを実現する理想的なアプローチとして、Bright DataのWeb MCPによる拡張が選ばれる理由
- Claude Agent SDKで構築したAIエージェントをWeb MCP経由でBright Dataウェブツールに接続する方法
それでは、さっそく見ていきましょう!
Claude Agent SDKとは?
Claude Agent SDKは、Anthropicが提供するオープンソースフレームワークであり、Claude Codeを活用した自律型AIエージェントの構築を可能にします。特に、エージェントがカスタムオーケストレーションロジックを必要とせずに、ファイルの読み取り、コマンドの実行、ウェブ検索、コード編集、ツールとの連携を行えるようにします。
このSDKは、コンテキストの収集、アクションの実行、結果の検証を可能にする堅牢なエージェントループを提供します。これにより、エージェントが複雑なワークフローを確実に実行できるようになります。SDKは以下の言語で利用可能です:
- Python版(GitHubスター数4,500超のライブラリ)
- TypeScript(720以上のGitHubスターを獲得したライブラリ)
Claude Agent SDKは、組み込みツール、サブエージェント、外部サービス向けMCP(Model Context Protocol)とのネイティブ統合をサポートします。その最終目標は、AIエージェント開発を簡素化し、Claudeの推論能力とツール実行能力を活用した専門アシスタント、リサーチエージェント、自動化ボットを構築するためのシンプルなAPIを提供することです。
Bright DataのWebデータ機能でClaude Agent SDKを拡張する理由
Claudeエージェントの限界と、その解決策を探る!
Claude Agent SDKツールに関する背景情報
最も高性能なClaude AIモデルでさえ、全てのLLM(大規模言語モデル)に内在する限界があります。これらの限界は、AIモデルが過去の断片的なデータで訓練されているという事実から生じています。
その結果、LLMは学習データに基づく回答しか生成できません。未知の事象(またはごく最近の出来事)について質問されると、完全に失敗するか、さらに悪いことに「幻覚」を生成する可能性があります。また、LLMは単独で外部世界とやり取りできません。
AIエージェントはLLMによって駆動されるため、これらの制限をすべて引き継ぎます。一方でエージェントには重要な利点があります:ツールを使用できることです!ツールにより、エージェントは外部サービスやシステムを呼び出せ、LLMのみに依存する限られた機能を拡張できます。
Claude Agent SDKは、ファイル操作、コマンド実行、ウェブ検索、コード編集などを行うためのデフォルト組み込みツール群をエージェントに提供します。
さらに、独自のツール定義手法も導入しています。Claude Agent SDKでは、カスタムツールはプロセス内MCPサーバーとして実装されます。Claudeを開発したAnthropic社がMCPを定義していることを考えれば、これは当然のことでしょう。
デフォルトのClaude Agent SDKツールは有用ですが、本番環境レベルのユースケースには必ずしも十分ではありません。実際には、知識の陳腐化やライブウェブとの限定的な連携といったLLMの一般的な制限に対処するよう設計された、専門的なサードパーティプロバイダーを統合する方が効果的です。
そこで登場するのがBright Data Web MCPです!
Bright Data Web MCPのご紹介
Claude Agent SDKのカスタムツールは、バックエンドでMCPを基盤に動作します。したがって、豊富な本番環境対応ツール群を提供するMCPでエージェント構築を拡張するのは理にかなっています。
BrightDataのWeb MCPは、自動化されたウェブデータ収集、構造化データ抽出、ブラウザレベルでのインタラクションを実現する60以上のAI対応ツールを提供します。リモートサービスとローカルサーバーの両方で利用可能で、2,000以上のGitHubスターを獲得した公開リポジトリが基盤となっています。
無料プランでも、MCPサーバーは以下の2つの特に有用なツール(およびバッチ版)を提供します:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
あらゆるウェブページを、ボット対策機能を回避してクリーンな Markdown 形式にスクレイピングします。 |
Web MCPが真に優れているのはProモードであり、Amazon、LinkedIn、Yahoo Finance、YouTube、TikTok、Zillow、Google Mapsなど、数多くのプラットフォームから構造化データを抽出するプレミアムツールを利用可能にします。さらに、あらゆるAIエージェントに、人間のユーザーのようにウェブをナビゲートし、ウェブページと対話する能力を付与します。
それでは、Bright Data Web MCPをClaude Agent SDKに統合する方法を見ていきましょう!
Web MCP経由でClaude Agent SDKをBright Dataツールに接続する方法
このステップバイステップガイドでは、MCPを介してClaude Agent SDKで構築されたAIエージェントにBright Dataサービスを統合する方法を学びます。具体的には、Bright DataのWeb MCPをClaude Agent SDK AIエージェントに接続し、利用可能なあらゆるウェブデータツールへのアクセス権を付与します。
注:Claude AgentSDKはTypeScript版も提供されています。以下のセクションは、公式ドキュメントを参照することでPythonからJavaScriptまたはTypeScriptへ簡単に変換可能です。
以下の手順に従ってください!
前提条件
このチュートリアルを実行するには、以下の要件を満たしていることを確認してください:
- ローカルにPython 3.10以降がインストールされていること。
- Claude Codeがマシンにインストールされていること。
- 利用可能なクレジットがあるClaude APIキー。
- APIキー付きのBright Dataアカウント。
注: Bright Dataアカウントの設定手順(Web MCP利用向け)は、チュートリアルの後ほど専用のセクションで説明します。
Claude Agent SDK は Claude Code をランタイムとして使用するため、Claude Code をローカルにインストールする必要があることに留意してください。詳細な手順については、Claude Code と Bright Data Web MCP の統合に関するガイドを参照してください。
最後に、MCPプロトコルとWeb MCPが提供するツール に関する基本的な知識があると便利です。
ステップ #1: Python で Claude Agent SDK プロジェクトを設定する
まず、お使いのマシンにClaude Codeがインストールされていることを確認してください。以下のコマンドを実行します:
claude --version以下のような出力が表示されるはずです:
2.1.29 (Claude Code)問題なければ、Claude Agent SDK を使用するための主要な前提条件が整っていることを確認できます。
次に、プロジェクトディレクトリを作成します。ターミナルからそのディレクトリに移動してください:
mkdir claude-agent-sdk-bright-data-ai-agent
cd claude-agent-sdk-bright-data-ai-agentプロジェクト内で仮想環境を初期化します:
python -m venv .venvプロジェクトルートにagent.pyという新しいファイルを作成します。これで以下のようになります:
claude-agent-sdk-bright-data-AI-agent/
├── .venv/
└── agent.pyagent.pyファイルには、Claude Agent SDKで構築され、Bright Data Web MCPと連携するAIエージェントのロジックが含まれます。
お好みのPython IDEでプロジェクトフォルダを開きます。例:PyCharm Community EditionまたはPython拡張機能付きのVisual Studio Codeで読み込みます。
次に、事前に作成した仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を実行:
source .venv/bin/activateWindowsでは同等の操作として以下を実行します:
.venv/Scripts/activate仮想環境をアクティブ化した状態で、必要な依存関係をインストールします:
pip install claude-agent-sdk python-dotenvこのアプリケーションの依存関係は以下の通りです:
claude-agent-sdk: Claude Agent SDK を通じて Python で AI エージェントを構築するため。python-dotenv: ローカルの .env ファイルからシークレット(Claude API キーや Bright Data API キーなど)を読み込むため。
準備完了!Python環境はClaude Agent SDKを用いたAIエージェント構築の準備が整いました。
ステップ #2: 環境変数読み込みの準備
AIエージェントはBright Dataや(当然ながら)Claudeといったサードパーティサービスに接続します。そのためには、各サービス上のアカウントに関連付けられたAPIキーを使用する必要があります。ベストプラクティスとして、ソースコードに認証情報を直接ハードコードすることは絶対に避けてください。
代わりに、必要なAPIキーは.envファイルから読み込むべきです。これが、前のステップでpython-dotenvをインストールした理由です。まず、agent.pyファイルでライブラリをインポートします:
from dotenv import load_dotenv次に、プロジェクトルートに.envファイルを作成します:
claude-agent-sdk-bright-data-AI-agent/
├─── .venv/
├─── agent.py
└─── .env # <-----.envファイルには、本プロジェクトで必要な2つのシークレットであるClaude APIキーとBright Data APIキーを保存します。
次に、agent.py で以下の関数を呼び出し、.env ファイルから環境変数をロードします:
load_dotenv()これで完了です!スクリプトは環境変数から機密情報を安全に読み取り、コードベースに直接記述せずに済みます。
ステップ #3: Claude Agent SDK の使用を開始する
agent.py に以下のコードを追加し、Claude Agent SDK を使用したシンプルな AI エージェントを構築します:
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions
from claude_agent_sdk.types import StreamEvent
async def main():
# Claudeエージェントの設定
options = ClaudeAgentOptions(
model="claude-haiku-4-5", # 任意のClaudeモデルに置き換えてください
include_partial_messages=True # ストリーミング応答を有効化
)
# エージェントに送信するプロンプト
prompt = "Hey! How is it going?"
# エージェントループ: Claude Agent SDKが返すイベントをストリーム処理
async for message in query(prompt=prompt, options=options):
# ストリーミングイベントのみを捕捉
if isinstance(message, StreamEvent):
event = message.event
event_type = event.get("type")
# 増分テキスト出力を処理
if event_type == "content_block_delta":
delta = event.get("delta", {})
if delta.get("type") == "text_delta":
# ストリームテキストを到着順に出力
print(delta.get("text", ""), end="", flush=True)
asyncio.run(main())このスクリプトは主に3つの構成要素から成ります:
options: エージェントを設定します。この例では、Claude Haiku 4.5モデルを使用し、ストリーム応答を有効化することで、出力を増分的に印刷できるようにします。プロンプト: Claude AIエージェントに実行させたい内容を定義します。Claudeはこの入力に基づいてタスクの処理方法を自動的に決定します。クエリ: エージェントループを開始するメインエントリポイント。非同期イテレータを返すため、Claudeが推論・ツール呼び出し・結果観察・出力生成を行う過程でメッセージをストリーミングするにはasync forを使用します。
非同期 forループは、Claude が「思考中」の間も実行を継続します。各反復処理では、推論ステップ、ツール呼び出し、ツール結果、最終回答など、異なるメッセージタイプが生成される可能性があります。この例では、最終的なテキスト出力のみを端末にストリーミングしています。
正常に実行するには、Claude Agent SDKがClaude APIへのアクセスを必要とします。デフォルトでは、APIキーをANTHROPIC_API_KEY環境変数から読み取ります。したがって、.envファイルに以下のように追加してください:
ANTHROPIC_API_KEY="<YOUR_ANTHROPIC_API_KEY>" <YOUR_ANTHROPIC_API_KEY>を実際のAnthropic Claude APIキーに置き換えてください。
注意: Claude Agent SDK エージェントが API キーにアクセスできない場合、以下のエラーが発生します:
組織がClaudeへのアクセス権を持っていません。再度ログインするか、管理者にお問い合わせください。前のステップのコードをすべて考慮した上で、エージェントを起動するには以下を実行してください:
python agent.pyターミナルには、以下のようなストリーミング応答が表示されるはずです:
素晴らしい!応答が入力プロンプトと一致しています。これはClaude Agent SDK搭載のAIエージェントが正常に動作していることを意味します。
ステップ #4: Bright DataのWeb MCPで開始
Claude Agent SDKのカスタムツールは、インプロセスMCPサーバーを介して実装されることを覚えておいてください。このため、AIエージェントをBright Data Web MCPサーバーインスタンスに直接接続するのが理にかなっています。
結局のところ、Bright Dataサービスと直接連携してカスタムツールを定義し、それをMCP経由で公開する意味はあまりありません。公式(かつ広く利用されている!)MCPサーバーが既に存在するからです。
本セクションではローカルインスタンスへの接続方法を示します。同時に、よりスケーラブルでエンタープライズ対応の環境構築のため、リモートWeb MCPサーバーへの接続も可能です。
Claude Agent SDKをBright DataのWeb MCPに接続する前に、MCPサーバーがご自身のマシンで実行可能か必ず確認してください!
まず、Bright Dataアカウントを作成してください。既にアカウントをお持ちの場合はログインしてください。迅速なセットアップには、ダッシュボードの「MCP」セクションにあるウィザードに従ってください: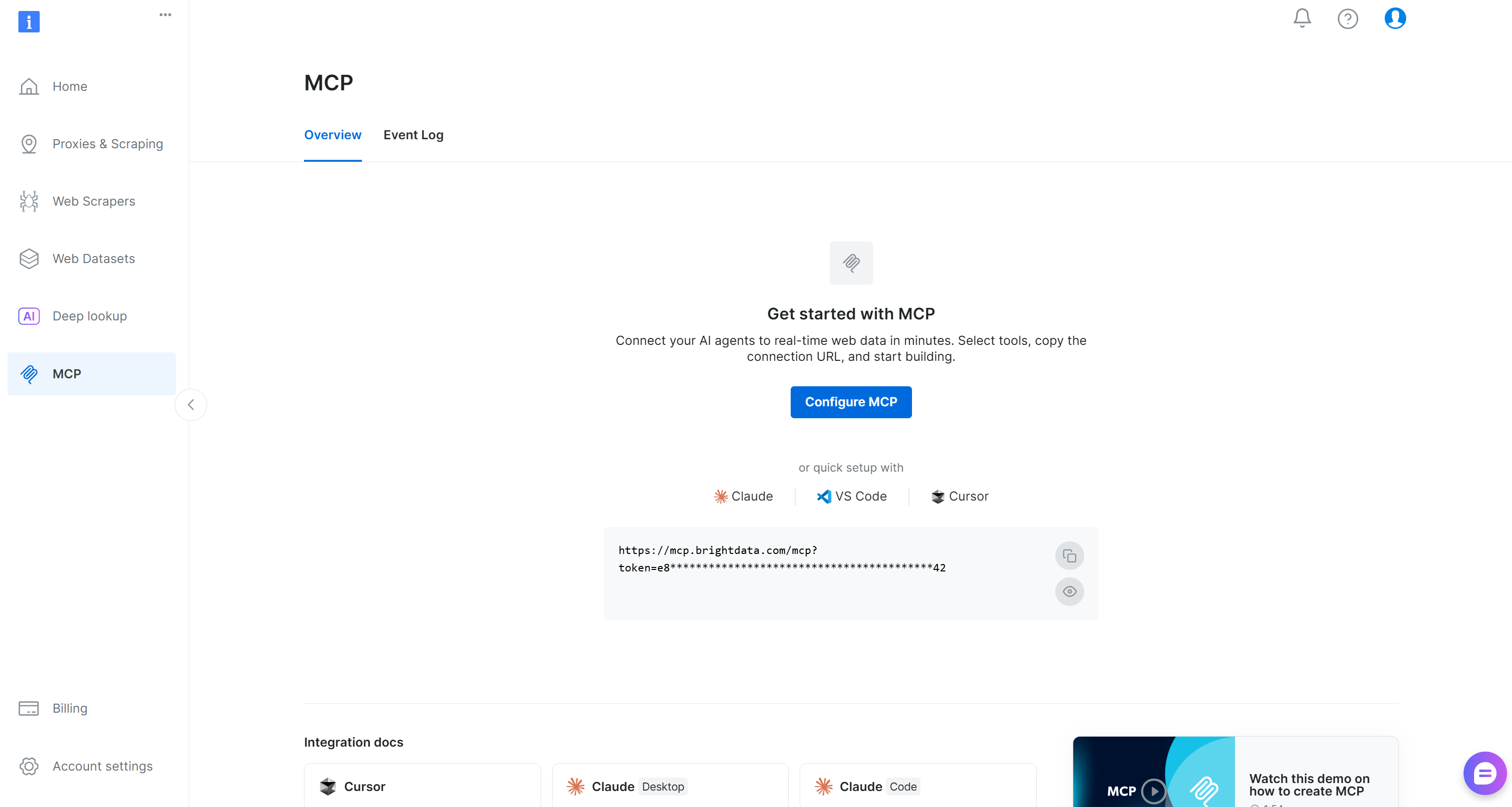
追加のガイダンスが必要な場合は、以下の手順を参照してください。
Bright Data APIキーの生成から始めます。このAPIキーは、ローカルWeb MCPインスタンスをBright Dataアカウントで認証するためにすぐに使用します。コード内でアクセスする必要があるため、.envファイルに以下のように追加してください:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"次に、agent.pyファイルで読み込みます:
import os
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")@brightdata/mcpパッケージを使用して Web MCP をグローバルにインストールします:
npm install -g @brightdata/mcpLinux/macOSでは、ローカルでMCPサーバーが実行されていることを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellでは同等の方法で実行:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを実際の Bright Data API トークンに置き換えてください。これらの(同等の)コマンドは、必要な API_TOKEN 環境変数を設定し、ローカルで Web MCP サーバーを起動します。
成功した場合、以下のようなログが表示されます:
初回起動時、Web MCPパッケージはBright Dataアカウント内に自動的に2つのゾーンを設定します:
mcp_unlocker:Web Unlocker用ゾーンmcp_browser:Browser API 用ゾーン。
これらの2つのゾーンが、Web MCPで利用可能な60以上のツールを支えています。ドキュメントで説明されているように、2つのゾーンのデフォルト名を上書きすることも可能です。
作成を確認するには、Bright Dataダッシュボードの「プロキシ&スクレイピングインフラ」ページに移動してください。「マイゾーン」テーブルに両ゾーンがリストされていることを確認できます: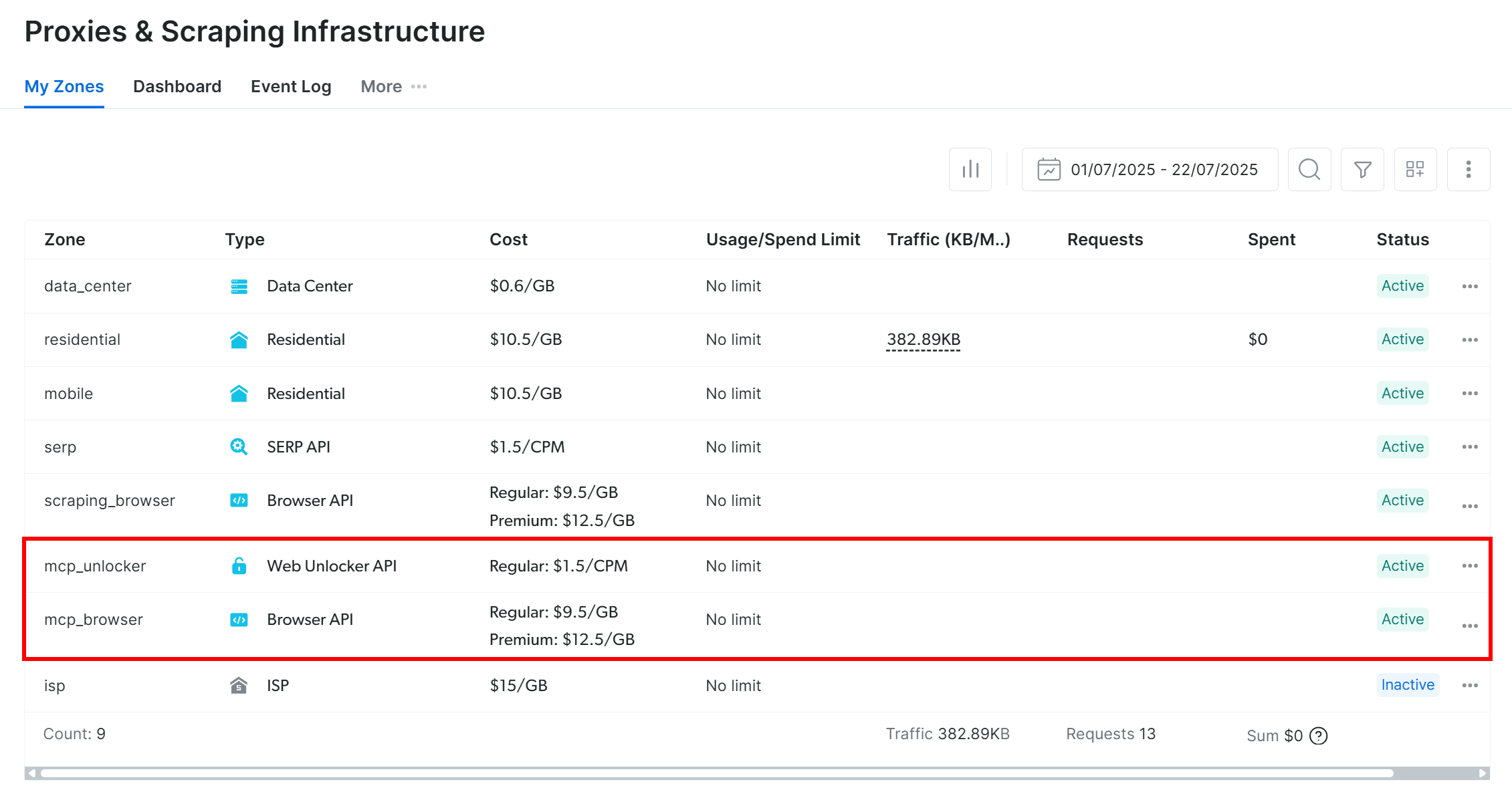
なお、Web MCPの無料プランではsearch_engineツールとscrape_as_markdownツール(およびそれらのバッチ版)のみが利用可能です。
60以上の全ツールを利用するには、環境変数PRO_MODE="true"を設定して Pro モードを有効化する必要があります:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpWindowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp重要: Proモードは無料プランに含まれず、追加料金が発生します。
素晴らしい!これでWeb MCPサーバーがマシン上で確実に実行されていることが確認できました。次に、Claude Agent SDKを設定してサーバーを自動起動し、接続します。
ステップ #5: Claude Agent SDK を Web MCP に接続
Claude Agent SDKは、ClaudeAgentOptionsクラスの mcp_serversオプションを介したMCP接続をサポートしています。これにより、エージェントがBright DataのWeb MCPと直接通信できるようになります。
Web MCPに接続するには、options変数を以下のように更新します:
options = ClaudeAgentOptions(
# Bright DataのWeb MCPに接続
mcp_servers={
"bright_data": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Proモードを有効化
}
}
},
allowed_tools=["mcp__bright_data__*"], # Bright Data Web MCPの全ツールを有効化
model="claude-haiku-4-5", # お好みのClaudeモデルに置き換えてください
include_partial_messages=True, # ストリーミング応答を有効化
)この設定は、環境変数経由で認証情報と設定を渡す、以前にテストしたnpxコマンドを反映しています:
API_TOKEN: 認証に必須。Bright Data APIキーを設定してください。PRO_MODE: Proモードを有効化するために必須。
重要: `allowed_tools`フィールドはワイルドカードを使用し、設定済みのbright_dataサーバー上の全ツールを許可します。これを指定しないと、Claude搭載エージェントはツールを認識できても使用できません。
コード内で mcp_servers オプションを指定したくない場合は、プロジェクトルートに以下の構造で.mcp.jsonファイルを作成することも可能です:
{
"mcpServers": {
"bright_data": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Web MCP接続を確認するには、簡単なプロンプトでエージェントをテストします:
prompt = "どのBright Data MCPツールにアクセスできますか?"プロモード(PRO_MODE="true")では、以下のように利用可能な60以上のツールがすべてリストされるはずです: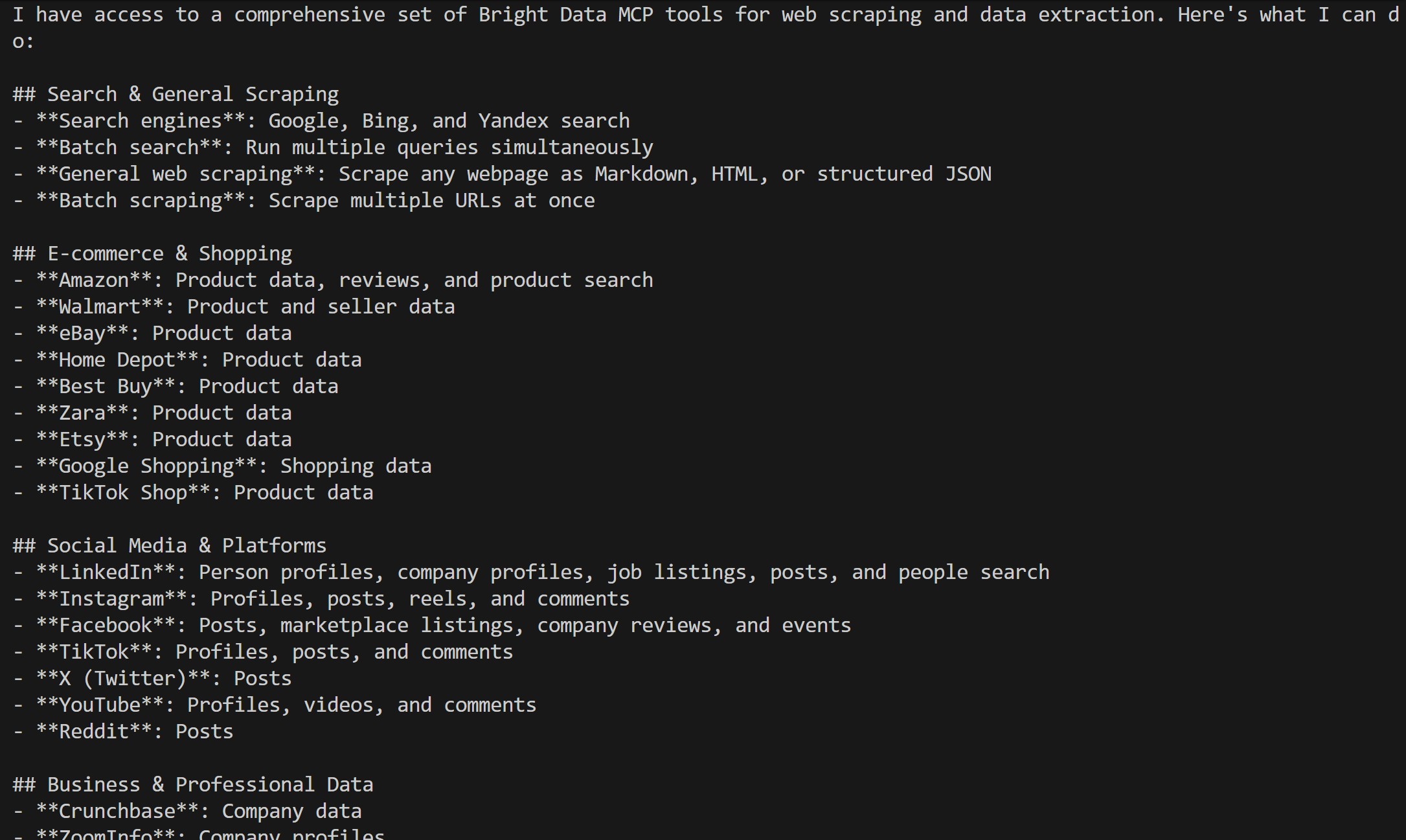
これでエージェントはWeb MCPサーバーで利用可能な全ハイレベルツールを認識・使用できます。ミッション完了!Claude Agent SDKで構築したAIエージェントが、Web MCPツール経由でBright DataのWebデータ機能拡張を実現しました。
ステップ #6: エージェントの実行
Bright Data Web MCPと統合されたAIエージェントの効果を示すには、適切なプロンプトが必要です。特に、ウェブデータの取得やウェブとの相互作用を含むプロンプトが求められます。
例えば、競合他社のウェブサイトを監視し、自動的にスクリーンショットを撮影してページテキストを抽出するAIエージェントを構築したいと想像してください。これは、適切なツールなしでは標準的なAIエージェントが単独で実行できないタスクです。
ナイキを競合と仮定した場合、以下のようなプロンプトを作成できます:
prompt = """
スクレイピングブラウザセッションを開き、以下のウェブページに移動する:
"https://www.nike.com/"
ページが完全に読み込まれるのを待ち、フルページのスクリーンショットをキャプチャする。また、ページ全体のテキストを抽出する。スクリーンショットをローカルの `screenshot.png` ファイルに、ページテキストをローカルの `text.txt` ファイルに保存する。
"""プレミアム版Bright Data Web MCPツールのブラウジング機能により、AIエージェントは以下が可能になりました:
- Browser APIを介してクラウド上でリモートブラウザセッションを開き、一般的なボット対策機能を回避して事実上あらゆるウェブページにアクセスする。
- ページが完全に読み込まれるまで待機します。
- フルページのスクリーンショットをキャプチャし、表示されているテキストをすべて抽出します。
最後に、エージェントはClaude Agent SDKが提供する組み込みツールを使用して、要求された通り生成された出力をディスクに保存します。
画像処理とディスクへの書き込みを有効にするには、以下の2つの追加オプションも必要です:
options = ClaudeAgentOptions(
# ...
permission_mode="acceptEdits", # エージェントがファイルをディスクに書き込めるようにする
max_buffer_size=10 * 1024 * 1024, # 画像処理用に10MBに増やす
)エージェントの実行ではツールの使用が発生するため、ツール呼び出しに関連するイベントも捕捉するようストリーミングロジックを更新するのが合理的です。非同期forループを以下のように更新してください:
# 現在のツールを追跡し、その入力JSONを蓄積
current_tool = None
tool_input = ""
# エージェントループ: Claude Agent SDKが返すイベントをストリーム処理
async for message in query(prompt=prompt, options=options):
# ストリーミングイベントのみを捕捉
if isinstance(message, StreamEvent):
event = message.event
event_type = event.get("type")
if event_type == "content_block_start":
# 新しいツール呼び出しが開始
content_block = event.get("content_block", {})
if content_block.get("type") == "tool_use":
current_tool = content_block.get("name")
tool_input = ""
print(f"nStarting tool: {current_tool}")
# 増分テキスト出力の処理
elif event_type == "content_block_delta":
delta = event.get("delta", {})
if delta.get("type") == "text_delta":
# 到着したストリームテキストを出力
print(delta.get("text", ""), end="", flush=True)
elif delta.get("type") == "input_json_delta":
# ストリームで到着するJSON入力を蓄積
chunk = delta.get("partial_json", "")
tool_input += chunk
elif event_type == "content_block_stop":
# ツール呼び出し完了(最終入力を表示)
if current_tool:
print(f"Tool {current_tool} called with: {tool_input}")
current_tool = Noneこのロジックにより、エージェントが呼び出すツールとその入力内容をより深く理解できます。素晴らしい!あとはエージェントをテストするだけです。
ステップ #7: AI エージェントのテスト
最終的なagent.pyファイルの内容:
from dotenv import load_dotenv
import os
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions
from claude_agent_sdk.types import StreamEvent
# .envファイルから環境変数をロード
load_dotenv()
# Bright Data APIキーの環境変数にアクセス
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
async def main():
options = ClaudeAgentOptions(
# Bright DataのWeb MCPに接続
mcp_servers={
"bright_data": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Proモードを有効化
}
}
},
allowed_tools=["mcp__bright_data__*"], # Bright Data Web MCPの全ツールを有効化
model="claude-haiku-4-5", # お好みのClaudeモデルに置き換えてください
include_partial_messages=True, # ストリーム応答を有効化
permission_mode="acceptEdits", # エージェントがディスクにファイルを書き込めるようにする
max_buffer_size=10 * 1024 * 1024, # 画像処理用に10MBに増やす
)
# エージェントに送信するプロンプト
prompt = """
スクレイピングブラウザセッションを開き、以下のウェブページに移動してください:
"https://www.nike.com/"
ページが完全に読み込まれるのを待ち、フルページのスクリーンショットをキャプチャしてください。また、ページ全体のテキストを抽出してください。スクリーンショットをローカルの `screenshot.png` ファイルに、ページテキストをローカルの `text.txt` ファイルに保存してください。
"""
# 現在のツールを追跡し、その入力 JSON を蓄積する
current_tool = None
tool_input = ""
# エージェントループ: Claude Agent SDKが返すイベントをストリーム処理
async for message in query(prompt=prompt, options=options):
# ストリーミングイベントのみをインターセプト
if isinstance(message, StreamEvent):
event = message.event
event_type = event.get("type")
if event_type == "content_block_start":
# 新しいツール呼び出しが開始
content_block = event.get("content_block", {})
if content_block.get("type") == "tool_use":
current_tool = content_block.get("name")
tool_input = ""
print(f"nStarting tool: {current_tool}")
# 増分テキスト出力を処理
elif event_type == "content_block_delta":
delta = event.get("delta", {})
if delta.get("type") == "text_delta":
# 到着したストリームテキストを出力
print(delta.get("text", ""), end="", flush=True)
elif delta.get("type") == "input_json_delta":
# JSON入力がストリーミングされるにつれて蓄積
chunk = delta.get("partial_json", "")
tool_input += chunk
elif event_type == "content_block_stop":
# ツール呼び出し完了(最終入力を表示)
if current_tool:
print(f"Tool {current_tool} called with: {tool_input}")
current_tool = None
asyncio.run(main())以下のコマンドで実行:
python agent.pyエージェントを実行すると、以下のような出力が表示されます:
ご覧の通り、エージェントはWeb MCPに接続し、以下のツールを使用します:
mcp__bright_data__scraping_browser_screenshotでページ全体のスクリーンショットを取得mcp__bright_data__scraping_browser_get_text: ウェブページから全テキストを抽出
その後、「Write」ツールを使用して出力を指定されたファイルに保存します。実行後、プロジェクトのルートフォルダにscreenshot.pngとtext.txt が生成されます: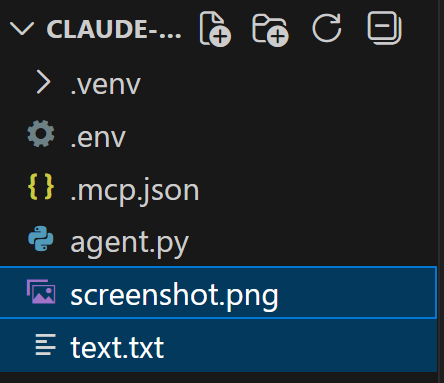
screenshot.pngを開くと、対象のNikeホームページのフルページスクリーンショットが表示されます:
text.txtを開くと、上記ページから抽出されたテキストが表示されます: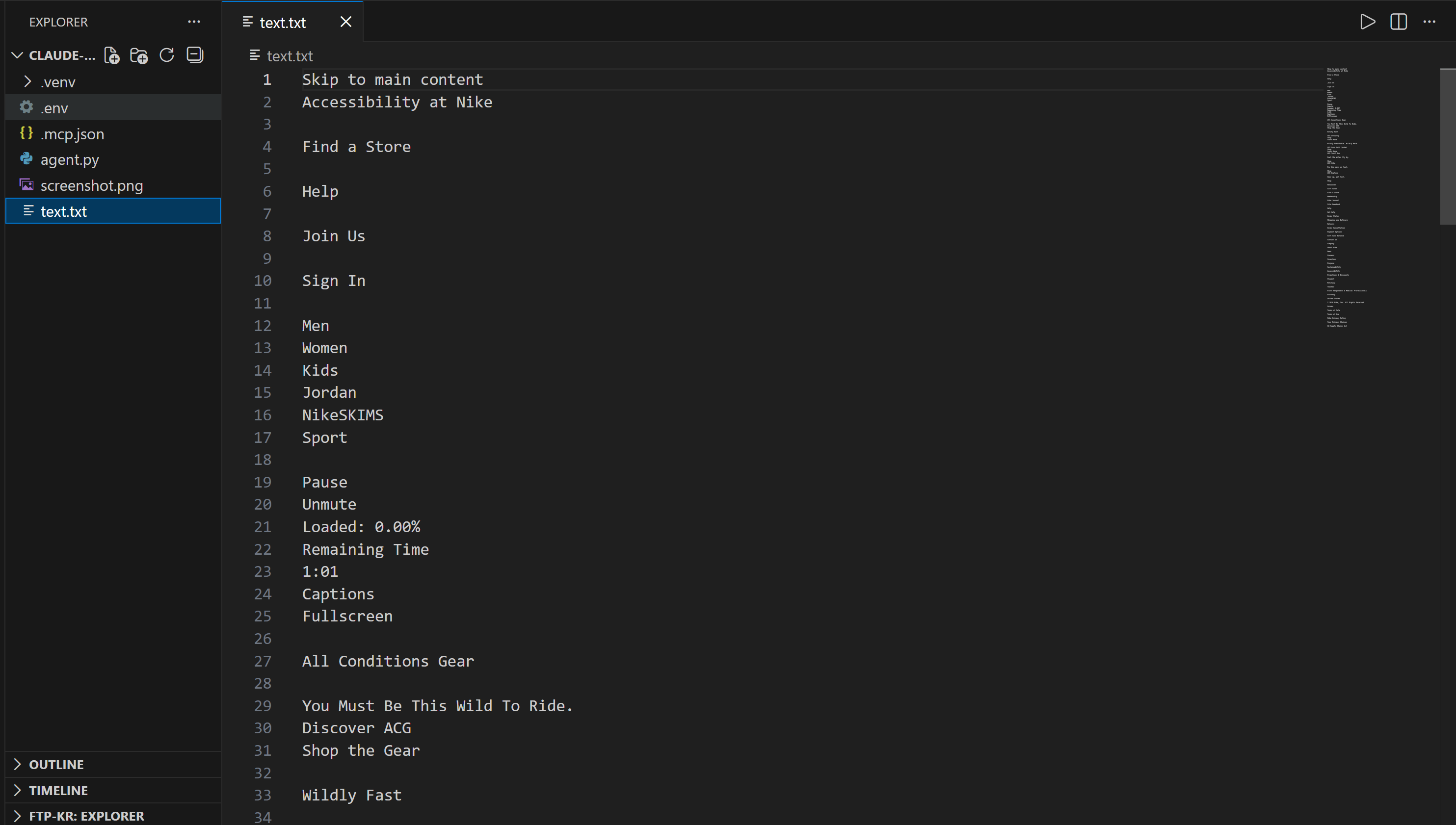
これで完了です!Claude Agent SDKを介して調整され、Bright Data Web MCPで拡張されたAIエージェントが、ウェブブラウジングをはじめ、さらに多くの処理を実行できるようになりました!
まとめ
本チュートリアルでは、Claude Agent SDKのMCP統合によるカスタムツール活用で拡張AIエージェントを構築する方法を学びました。具体的には、Bright DataのWeb MCPと連携させることで、Claude Agent Python SDK搭載AIエージェントを強化する意義と手法を確認しました。
この統合により、Claude搭載のAIエージェントはウェブ検索、構造化データ抽出、ライブウェブデータ取得、自動化されたウェブ操作といった強力な機能を獲得し、多様なエージェントユースケースを実現します。
今すぐBright Dataアカウントに無料で登録し、AIのためのWebデータツールを実際に体験しましょう!






