

このブログ記事では、以下の内容をご紹介します:
- Cartesiaとは何か、そしてAIボイスエージェント開発においてどのような機能を提供しているか。
- 音声エージェント(他のエージェントと同様に)が、効果的かつ真に信頼されるためには、なぜウェブへのアクセスが必要なのか。
- Bright Dataとの連携を活用し、CartesiaのAIボイスエージェントにウェブ検索や情報抽出の機能を持たせる方法。
さっそく見ていきましょう!
Cartesiaとは?
Cartesiaは、リアルタイムAIボイスエージェントを構築するための、開発者ファーストのプラットフォームです。低遅延の音声モデルと完全なエージェント開発スタックを組み合わせ、アイデアから本番環境対応のボイスエージェントまでを構築するために必要なすべてを提供します。
このプラットフォームは迅速な反復開発を想定して設計されており、開発者は最小限の手間で会話型エージェントのプロトタイプ作成、デプロイ、改良を行うことができます。単一の統合されたエコシステム内で、音声処理、推論、デプロイ、テストをすべて処理します。
Cartesiaの音声スタックは、2つの主要な自社開発モデルによって支えられています:
- Sonic:超低遅延と表現力豊かな出力に最適化されたストリーミング型テキスト読み上げ(TTS)モデルです。40以上の言語に対応し、笑い声や感情表現を交えながら、自然で人間らしい話し声を提供します。
- Ink:実世界の会話向けに設計された、高速かつ高精度な音声認識(STT)モデルです。ノイズ、アクセント、話し言葉の不自然さを処理しつつ、ほぼリアルタイムの文字起こし速度を維持します。
エージェントの構築には、Cartesiaが提供する組み込みのWebエージェントビルダーと、オープンソースのSDK「Line」の両方が利用可能です。Cartesia SDKは、テンプレート、ツール連携、マルチエージェントのオーケストレーションなどをサポートしています。これにより、インテリジェントで実運用レベルの音声エージェントを構築するために必要なすべてが揃います。
音声エージェントにWebアクセスが必要な理由
Cartesiaは、LiteLLMを介して100種類以上のLLMをサポートする、AI音声エージェント構築のための間違いなく機能豊富なソリューションです。しかし、これほど幅広い選択肢があるにもかかわらず、すべてのLLMには共通する本質的な制限があります。それは、その知識が特定の時点に固定されているという点です。これにより、エージェントが現実世界の最新タスクを処理する際、時代遅れの応答、幻覚、あるいは知識の欠落が生じる可能性があります。
さらに、LLMはネイティブにWebにアクセスしたり、外部システムと連携したりすることはできません。その結果、標準的なエージェントのワークフローはモデルの制限に縛られたままとなります。これを克服するには、カスタムツールを介した外部サービスとの統合が不可欠です。
そこでBright Dataの出番となります。CartesiaをBright Dataに接続することで、エージェントはあらゆるウェブサイトからリアルタイムの情報、検索結果、構造化データにアクセスできるようになります。
Bright Dataのエンタープライズグレードのインフラストラクチャは、世界最大級のプロキシネットワークを特徴としており、195カ国に4億以上のIPアドレスを保有しています。これにより、ライブWebコンテンツへの安全で信頼性が高く、スケーラブルなアクセスが可能になります。
Cartesiaの音声エージェントに導入可能なBright Dataの主な製品は以下の通りです:
- SERP API:GoogleやBingなどの検索エンジンの検索結果を収集し、情報に基づいた応答を可能にします。
- Web Unlocker API:CAPTCHAやボット対策機能を回避し、あらゆるサイトのコンテンツを生のHTMLまたはMarkdown形式で取得します。
- Web スクレイパー API:Amazon、LinkedIn、Instagramなどのプラットフォームから構造化データを抽出します。
- Crawl API:ウェブサイト全体を構造化されたデータセットに変換し、下流のAIワークフローに活用します。
Bright Dataを活用することで、Cartesiaのエージェントは事前学習された知識だけに制限されなくなります。エージェントは、リアルタイムで信頼性の高いウェブデータを探索、取得し、推論を行うことが可能になります。これにより、より正確で、文脈を理解し、実用的な応答を提供できるようになります。
Bright DataのWebデータ取得機能を活用したCartesia AIボイスエージェントの構築方法
このステップバイステップのセクションでは、Cartesia を使用して AI 音声エージェントを構築する方法を学びます。このエージェントは、Bright Data を利用したウェブ検索およびウェブスクレイピング機能によって強化されます。
具体的には、このAIボイスエージェントは、指定されたトピックについて聴取可能な、ニュース形式の短いレポートを生成するシミュレーションを行います。また、エージェントとチャットして追加の質問をしたり、トピックについてさらに掘り下げたりすることも可能です。
注:これはAI音声エージェントの実装例の一つに過ぎません。Bright Dataの統合機能は、他にも多くのユースケースに対応しています。
具体的には、Bright DataのAI対応製品のうち2つを統合します:
- Web Unlocker API:エージェントが任意のURLからデータを抽出できるようにします。
- SERP API:エージェントがウェブ検索を行えるようにします。
これら2つのツールを組み合わせることで、AIエージェントは「検索と抽出」のパターンを適用できるようになります。これは、データの根拠付けやウェブ上の情報発見に最適です。
エージェント構築時のプログラム制御を強化するため、Line(Cartesia SDK)を利用します。これは、Agent Builderがプロトタイピングには優れていますが、機能に多少の制限があるためです。
以下の手順に従ってください!
前提条件
このチュートリアルを進めるには、以下の環境が整っていることを確認してください:
- Unixベースのオペレーティングシステム(Linux、macOS、またはWindows上のWSL)。
- Python 3.9以上がローカルにインストールされていること。
- ローカルに
uvがインストールされていること。 - CartesiaがサポートするLLMプロバイダーのいずれかからのAPIキー(ここではGeminiのAPIキーを使用します)。
- Web Unlocker API および SERP API が設定済みで、API キーが発行されているBright Data アカウント。
- APIキーが設定済みのCartesiaアカウント。
Bright Data および Cartesia アカウントの設定については、専用のサブチャプターで順を追って説明しますので、現時点では心配する必要はありません。
ステップ #1: Cartesia プロジェクトの初期化
まず、uvを使用してプロジェクト用のフォルダを作成します(これはCartesia クイックスタートガイドで推奨されている方法です):
uv init cartesia-bright-data-voice-agentプロジェクトフォルダに移動します:
cd cartesia-bright-data-voice-agent次のようなフォルダ構造が表示されるはずです:
cartesia-bright-data-voice-agent/
├── .git/
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.tomlこれが `uv init` コマンドの実行結果です。
main.pyファイルに注目してください。ここに、Bright Data を使用して Web データの取得および検索機能を拡張した AI ボイスエージェントを設計するための Cartesia ロジックを追加します。
次に、以下のコマンドでプロジェクトの依存関係をインストールします:
uv add cartesia-line requests必要なライブラリは以下の2つです:
cartesia-line: インテリジェントで低遅延の音声エージェントを構築するためのCartesia Line SDK。requests:広く使われている Python HTTP クライアント。カスタム Cartesia ツール内で Bright Data の API を呼び出す際に使用されます。
これらのライブラリは、uvによって.venv仮想環境に自動的にインストールされます。これで、お好みのPython IDEでプロジェクトを直接開くことができます。
お疲れ様でした!空の Cartesia プロジェクトの準備が整いました。
ステップ 2: Cartesia CLI の開始
Cartesia エージェントをローカルでテストするには、Cartesia CLI をインストールしてログインする必要があります。認証には Cartesia API キーが必要ですので、まずそれを準備しましょう。
まだアカウントをお持ちでない場合は、新しい Cartesia アカウントを作成してください。すでにアカウントをお持ちの場合は、ログインしてください。ログインすると、ダッシュボードが表示されます:
次に、「API Keys」ページに移動し、「New」ボタンをクリックしてください:
APIキーに名前(例:「Bright Data-Powered Voice Agent」)を付け、「Create」をクリックすると、モーダルウィンドウにAPIキーが表示されます。
APIトークンをコピーし、すぐに必要になるため安全に保管してください。
Unixベースのターミナルで、以下のコマンドを実行して Cartesia CLI をインストールしてください:
curl -fsSL https://cartesia.sh | shインストール後、シェルを再起動すると、どこからでもcartesiaコマンドを使用できるようになります。
CLI で認証するには、次のコマンドを実行します:
cartesia auth loginCartesia APIキーの入力を求められます。キーを貼り付けてEnterキーを押してください。正常に認証されると、次のようなメッセージが表示されます:
注:この例では、「Writech」は Cartesia 組織の名前です。実際の環境では、ご自身の組織に合わせてカスタマイズされたメッセージが表示されます。
完了です!初期の前提条件を完了するために、Bright Dataアカウントを設定しましょう。
ステップ 3: Bright Data アカウントの設定
CartesiaでSERP APIとWeb Unlockerを連携させるには、まずSERP APIゾーンとWeb Unlocker APIゾーンの両方が設定され、APIキーが発行されたBright Dataアカウントが必要です。
Bright Dataアカウントをお持ちでない場合は、新規作成してください。すでにアカウントをお持ちの場合は、ログインしてください。コントロールパネルに移動し、「Proxies & Scraping」ページを開き、「My Zones」テーブルを確認してください: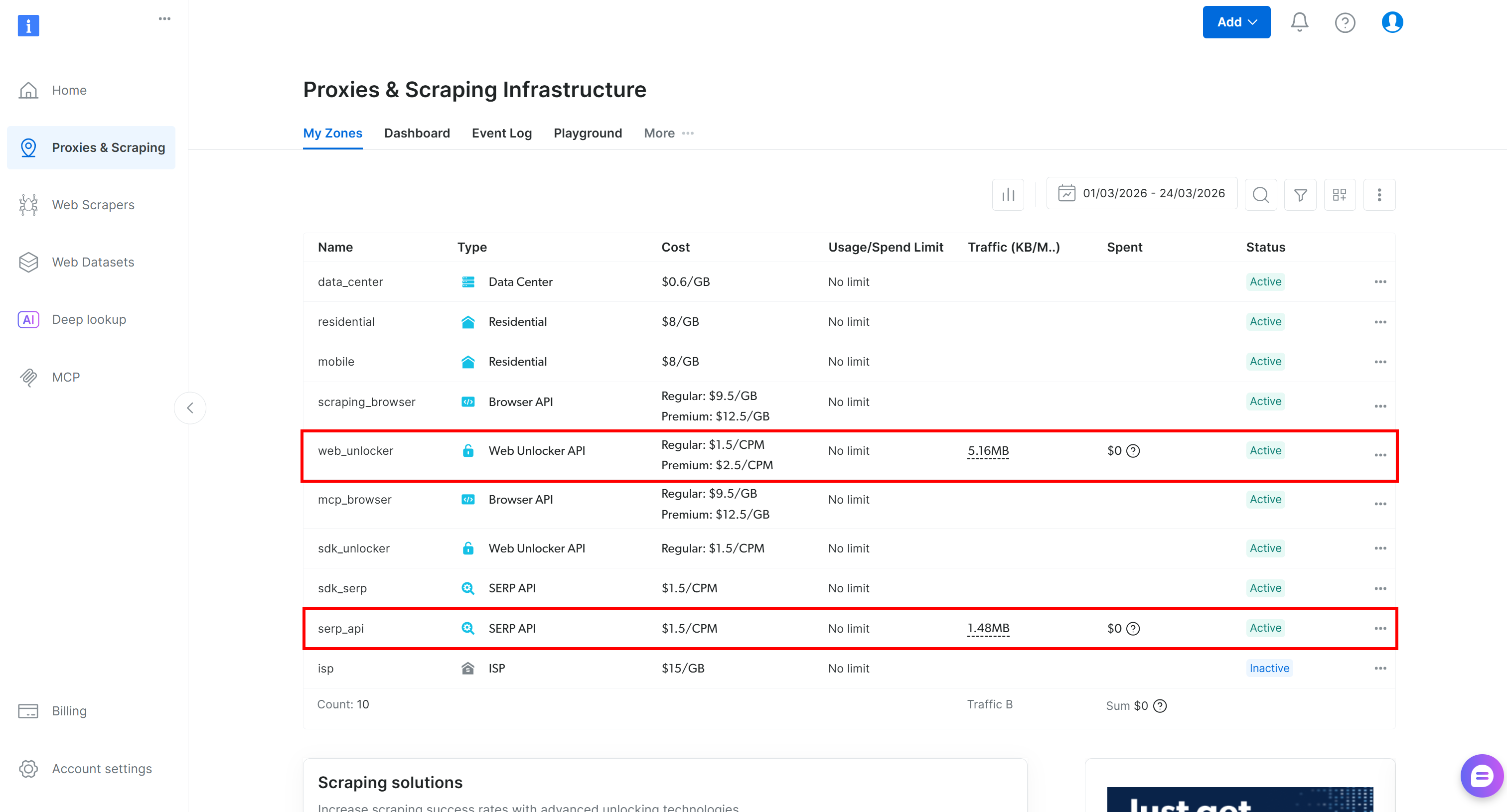
このテーブルに Web Unlocker API ゾーン(例:web_unlocker)と SERP API ゾーン(例:serp_api)がすでに表示されている場合は、準備は完了です。これら 2 つのゾーンを使用して、カスタムツール経由で Web Unlocker および SERP API サービスを呼び出します。
いずれかのゾーンが欠けている場合は、作成してください。「Unblocker API」および「SERP API」のカードまでスクロールし、「ゾーンを作成」をクリックします。ウィザードに従って両方のゾーンを追加してください: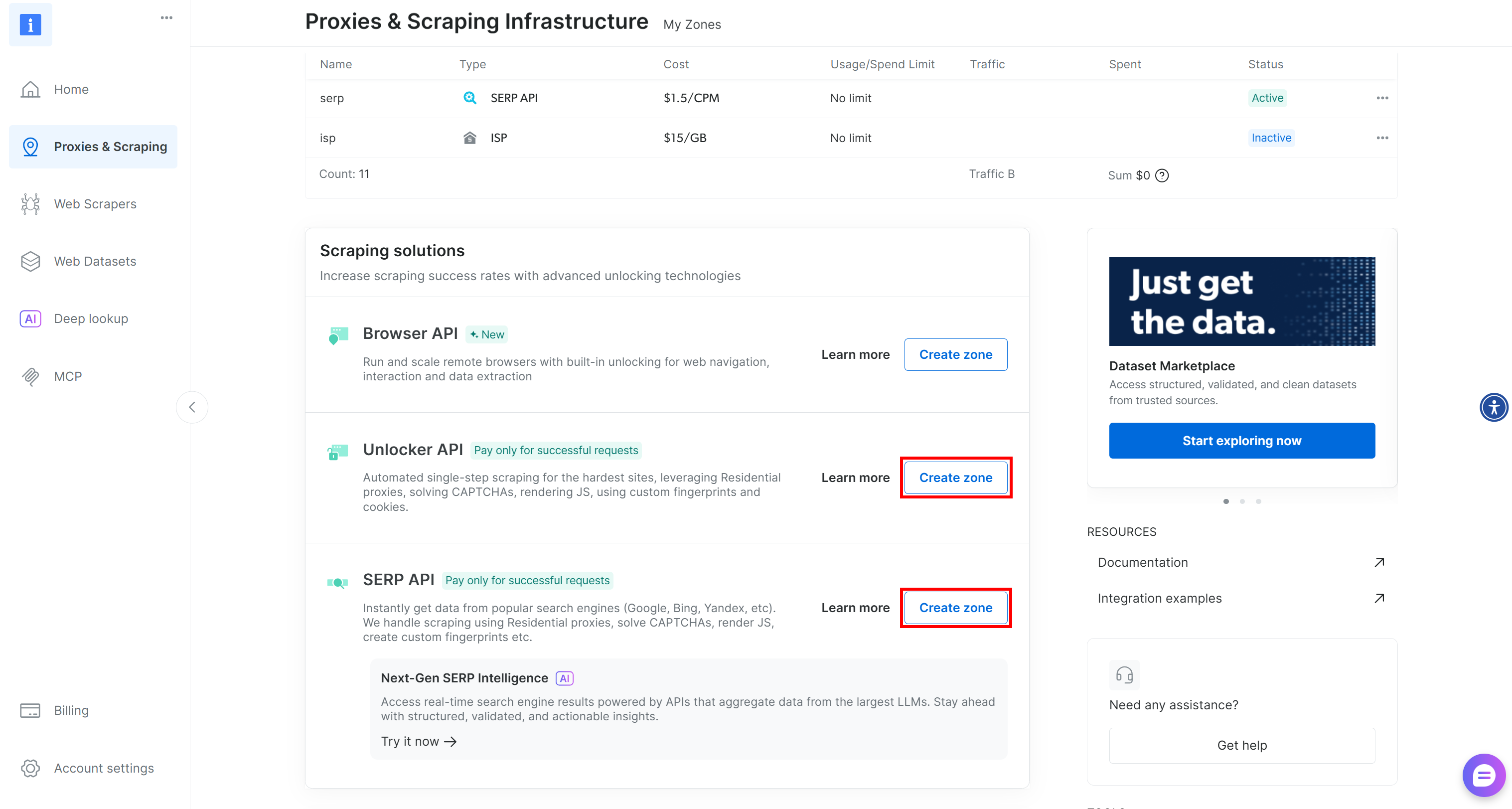
詳細な手順については、以下のドキュメントページをご確認ください:
両方のゾーンに割り当てた名前は、次のステップで必要になるため、覚えておいてください。最後に、Bright Data APIキーを生成し、安全に保管してください。
素晴らしい!これで、Bright DataをCartesiaに統合する準備が整いました。
ステップ 4: 環境変数の読み取り設定
このAIボイスエージェントのワークフローは、いくつかのシークレット(LLMプロバイダー(この場合はGemini)とBright Data(APIキー+ゾーン名))に依存しています。これらのシークレットをコード内にハードコーディングすることはセキュリティリスクとなるため、環境変数に保存することをお勧めします。
Cartesia CLIは、バックグラウンドでpython-dotenvを使用して.envファイルを自動的に読み込むため、すべてのシークレットをそこに保存できます。まず、プロジェクトディレクトリに.envファイルを追加します:
cartesia-bright-data-voice-agent/
├── .git/
├── .env # <-----------
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.toml次に、そこにシークレットを入力します:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" # 例: "web_unlocker"
BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>" # 例: "serp_api"すべてのプレースホルダーを実際の値に置き換えてください。これらのシークレットがすべて設定されていないとワークフローが開始されないようにするため、main.pyに以下のロジックを追加してください:
import os
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("環境変数 GEMINI_API_KEY がありません")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("環境変数 BRIGHT_DATA_API_KEY がありません")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("環境変数 BRIGHT_DATA_SERP_API_ZONE が見つかりません")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("環境変数 BRIGHT_DATA_WEB_UNLOCKER_ZONE がありません").envファイルの使用は必須ではありません。ターミナルで直接環境変数を設定することも可能です。
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>" BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>" BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>"素晴らしい!環境変数が安全に設定されました。次は、ウェブスクレイピングと検索のためのBright Dataツールの実装です。
ステップ #5: ウェブスクレイピング用のWeb Unlockerツールを定義する
デフォルトでは、Cartesia AIボイスエージェントは外部Webにアクセスできません。これを有効にするには、エージェントが呼び出せるカスタムツールを装備させる必要があります。ここでは、ウェブスクレイピングのためにBright DataのWeb Unlocker APIに接続するツールを定義します。
Cartesiaにおいて、ツールとは、利用可能なツールデコレータのいずれかでアノテーションされた関数に他なりません。以下に、Web Unlocker APIに接続するCartesiaのウェブスクレイピングツールの作成方法を示します:
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "スクレイピング対象ページのURL"]
) -> str:
"""
Bright Data Web Unlocker API を使用してウェブページのコンテンツを取得する
"""
url = "https://api.brightdata.com/request"
data = {
"ゾーン": BRIGHT_DATA_WEB_UNLOCKER_ゾーン,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Bright Data Web Unlocker API へのリクエストを実行
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textCartesia SDK では、関数の docstringをツールの説明として使用し、パラメータの型注釈として使用します。また、すべてのツールの最初のパラメータはctx でなければなりません。これはツールのコンテキストを表します。これにより、会話の状態にアクセスできるようになり、将来的な互換性が確保されます。
bright_data_web_unlocker()関数は、Requests HTTP クライアントを利用して、Bright Data Web Unlocker API ゾーンに対して POST リクエストを送信します。これにより、page_url引数で指定されたウェブページの Markdown 形式のコンテンツが返されます。利用可能なパラメータやオプションの詳細については、Bright Data のドキュメントを参照してください。
data_format引数が 「markdown」に設定されている点に注意してください。これにより、「Scrape as Markdown」機能が有効になり、スクレイピングされたコンテンツをAIに最適化されたMarkdown形式で取得できます。これはLLMへの取り込みに最適です。format引数は 「raw」に設定されているため、APIはスクレイピングされたMarkdownコンテンツをJSONでラップすることなく、プレーンな状態で返します。
素晴らしい!これで、Cartesia AIアプリケーションに、Bright Dataを使用して任意のWebサイトからウェブスクレイピングを行うためのツールが追加されました。
ステップ 6: ウェブ検索用の SERP API ツールを定義する
同様に、SERP APIを呼び出すカスタム関数ツールを定義します:
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "Google検索クエリ"]
) -> str:
"""
Bright DataのSERP APIを使用して、特定の用語についてウェブ検索を実行します。
"""
url = "https://api.brightdata.com/request"
data = {
"ゾーン": BRIGHT_DATA_SERP_API_ゾーン,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Bright Data SERP API へのリクエスト
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textこの関数は、SERP APIゾーンに対してPOSTリクエストを実行します。Googleにクエリを送信し、Bright Dataを介してパース済みの検索結果を取得します。詳細については、Bright Data SERP APIのドキュメントを参照してください。
素晴らしい!これで、Cartesiaアプリケーションに必要なBright Data搭載ツールが組み込まれました。
ステップ #7: Cartesia Voice Agent の定義
ここまでで、Cartesiaエージェントを定義するために必要なすべての構成要素が揃いました。推奨されるアプローチは、LiteLLMを介して100以上のLLMプロバイダーをサポートする組み込みのLlmAgentクラスを使用することです。
ボイスエージェントを定義するには、クラスに以下を指定します:
- LLMモデルとAPIキー。
- エージェントが使用できるツール。
- エージェントが実行すべき内容を記述したシステムプロンプト。
- 初期メッセージ。
これらを組み立てる方法は以下の通りです:
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
async def get_agent(env, call_request):
# AI音声エージェントを定義
SYSTEM_PROMPT = """
あなたは、ウェブを検索して最新の情報を取得できる親切なアシスタントです。
ニュースのような明快で情報豊かな口調で応答してください。
"""
return LlmAgent(
model="gemini/gemini-3-flash-preview",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="こんにちは!今日はどのようなご用件でしょうか?",
),
)注意点:
tools配列には、先に定義した2つのカスタムBright Dataツール(bright_data_web_unlockerおよびbright_data_serp_api)が含まれています。- エージェントが会話を適切に終了できるようにするため、組み込みの
end_callツールが必要です。 - 設定されているLLMモデルはGemini 3 Flashですが、他のGeminiモデルでも問題ありません。
最後に、VoiceAgentAppクラスにエージェントを登録して実行します:
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()ミッション完了!ニュース形式の応答を行うAIボイスエージェントを構築しました。このエージェントは、より正確で最新の回答を提供するために、ウェブからリアルタイムの情報を検索・取得することができます。
ステップ #8: 最終的なコード
main.pyファイルの内容は、以下のようになります:
# uv add cartesia-line requests
import os
from line.llm_agent import loopback_tool
from typing import Annotated
import requests
import urllib
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
# 環境変数から必要なシークレットを読み込む
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("環境変数 GEMINI_API_KEY が見つかりません")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("環境変数 BRIGHT_DATA_API_KEY が見つかりません")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("環境変数 BRIGHT_DATA_SERP_API_ZONE が見つかりません")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("環境変数 BRIGHT_DATA_WEB_UNLOCKER_ZONE がありません")
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "スクレイピング対象ページのURL"]
) -> str:
"""
Bright Data Web Unlocker API を使用してウェブページのコンテンツを取得する
"""
url = "https://api.brightdata.com/request"
data = {
"ゾーン": BRIGHT_DATA_WEB_UNLOCKER_ゾーン,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Bright Data Web Unlocker API にリクエストを送信
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "Google検索クエリ"]
) -> str:
"""
Bright DataのSERP APIを使用して、特定の用語についてWeb検索を行います。
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Bright Data SERP APIへのリクエストを送信
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
async def get_agent(env, call_request):
# AI音声エージェントを定義
SYSTEM_PROMPT = """
あなたは、ウェブを検索して最新の情報を取得できる親切なアシスタントです。
ニュースのような、明快で情報豊かな口調で応答してください。
"""
return LlmAgent(
model="gemini/gemini-2.5-flash",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="こんにちは!今日はどのようなご用件でしょうか?",
),
)
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()すごい!たった100行ほどのPythonコードで、Webデータ検索機能を備えた強力な音声AIエージェントを構築できました。
ステップ #9: 音声エージェントのテスト
必要な環境変数がすべて定義されていることを確認してください(.envファイル内、またはexportコマンドを使用)。その後、以下のコマンドでエージェントを起動します:
PORT=8000 uv run python main.pyこれにより、ログに表示される通り、http://localhost:8000 で Cartesia アプリがローカルで起動します:
別のターミナルで、以下のコマンドを実行してエージェントと対話してください:
cartesia chat 8000Cartesia Chatがターミナル上で直接起動します: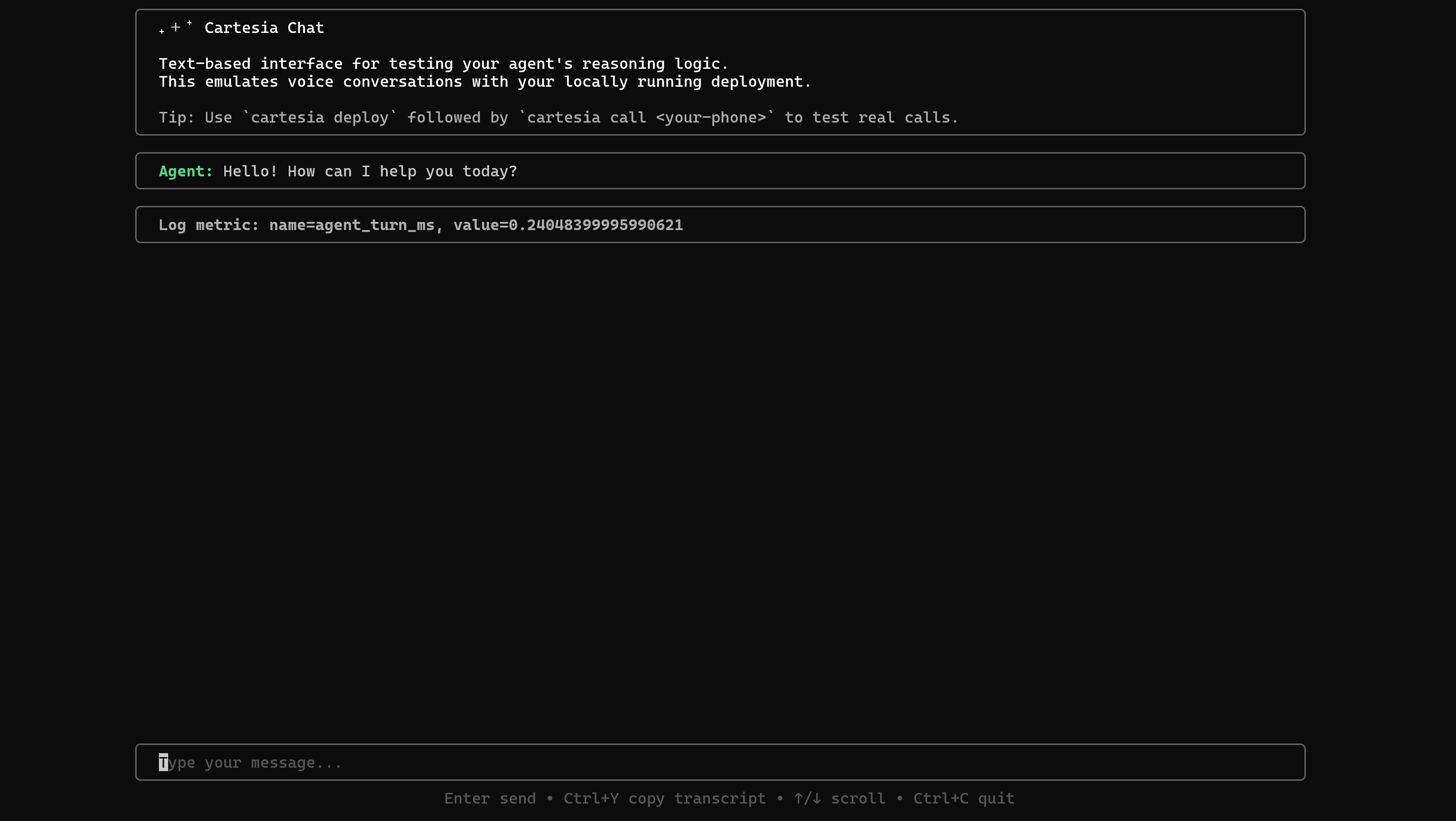
この設定により、音声ではなくチャットを介して会話をシミュレートできるため、テストが大幅に簡素化されます。
次のようなプロンプトを試してみてください:
ウェブ上で「米国のインフレに関するニュース」というクエリを検索し、特定の記事(ニュースハブページを除く)を5件中3件選択して、そのコンテンツをスクレイピングし、その情報を使って、出典を明記しつつ、重要な洞察を要約した約3分間のポッドキャストを作成してください。以下が想定される動作です:
エージェントがまず「US inflation news」というクエリでbright_data_serp_apiツールを呼び出す点に注目してください。別のターミナルでは、Bright Data SERP API から返された JSON 結果を含むログが表示されます。その結果から、エージェントは関連する記事の URL を 3 つ選択します: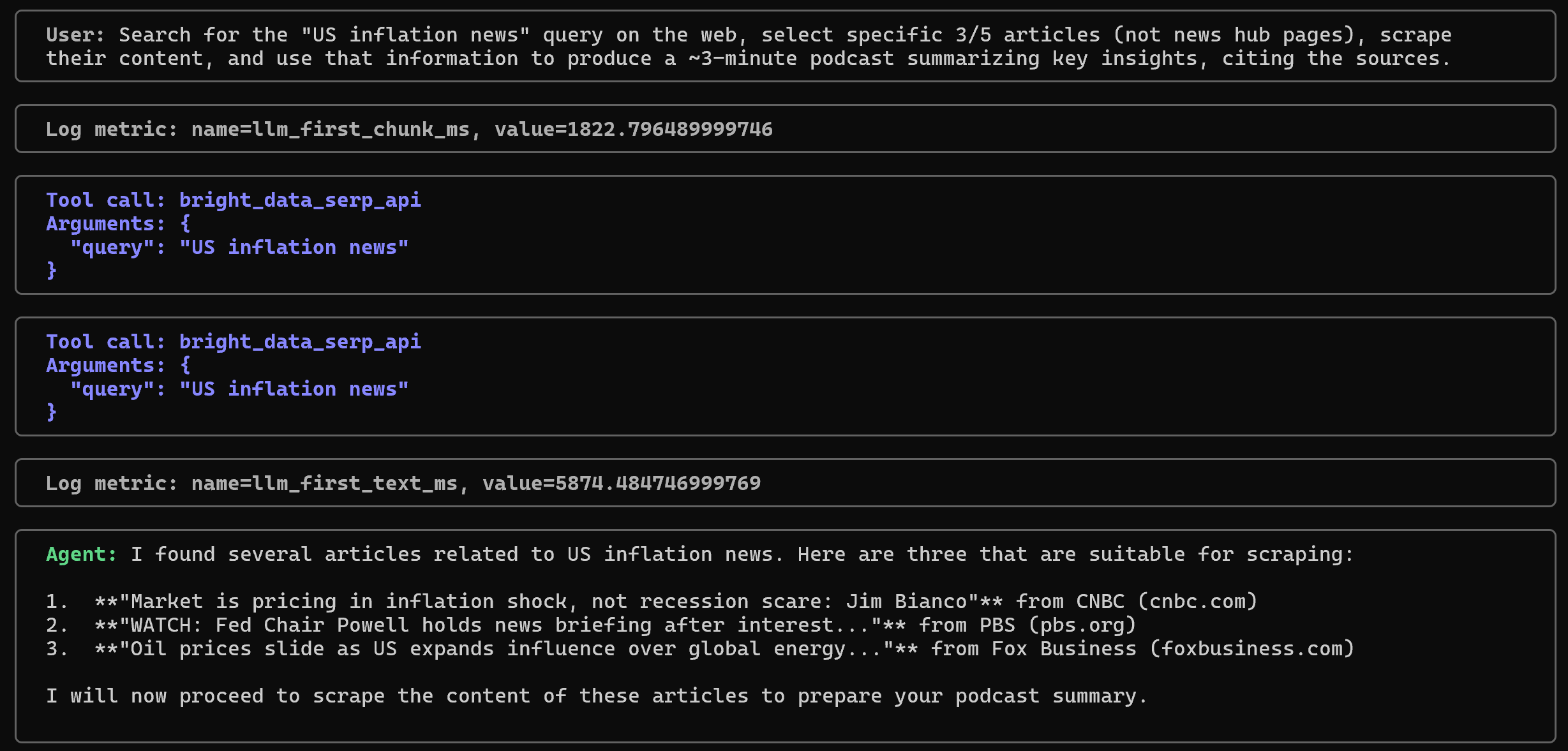
次に、bright_data_web_unlockerツールを使用して各ページをスクレイピングし、出典を明記した要約を作成します: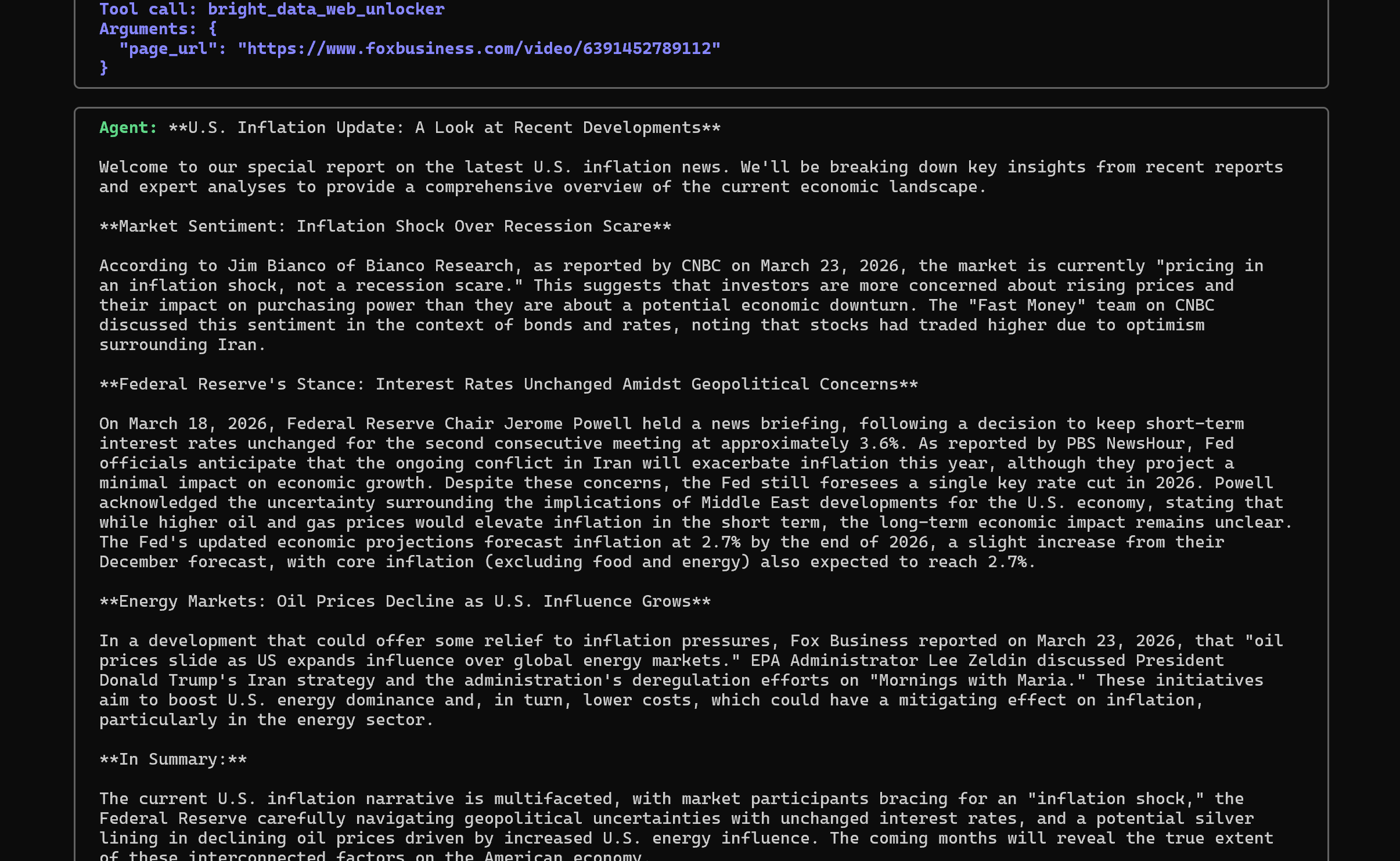
応答のトーンがジャーナリストのそれによく似ており、先ほど定義したシステムプロンプトと一致している点に注目してください。
これで完成です!ウェブから能動的に情報を検索・取得し、文脈を理解した正確な応答を生成できる音声エージェントの構築に成功しました。これは、Bright Dataの検索およびウェブスクレイピングツールを統合していなければ実現できなかったでしょう。
次のステップ
動作するAIボイスエージェントが完成したところで、次のステップはCartesiaにデプロイし、スマートフォンから呼び出すことです。ニーズに合わせてエージェントをさらに洗練・カスタマイズするには、ドキュメントを参照してください。
最後に、このチュートリアルで示したように、他のAPIベースのBright Data製品も統合できることを覚えておいてください。これにより、エージェントの機能をさらに拡張できます。
Cartesiaは、LiveKit(AI音声エージェント構築のための別の技術)を含む多くの統合機能をサポートしています。詳細については、Bright DataとLiveKitの統合方法をご覧ください。
まとめ
このブログ記事では、Cartesiaとは何か、そしてAI音声エージェント開発においてどのようなメリットをもたらすかについて学びました。また、その限界点と、Bright Dataの統合機能を活用してそれらの課題に対処する方法についても確認しました。
ボイスエージェントに2つの専用ツールを追加することで、ウェブ検索やウェブページからのデータスクレイピングが可能になりました。これは、BrightDataのSERP APIおよびWeb Unlocker APIを活用したカスタムツールにエージェントを接続することで実現しました。
ライブWebフィードへのアクセスやWeb操作の自動化など、機能をさらに拡張するには、Cartesiaの音声エージェントをBright DataのAIのためのデータ全ラインナップと統合してください。
今すぐBright Dataのアカウントを無料で登録し、AI対応のWebデータソリューションをエージェントに統合しましょう!





