

何十ものGoogle検索結果を手作業でコンテンツリサーチするのは時間がかかりすぎ、複数のソースに散在する重要な洞察を見逃すことが多い。従来のウェブスクレイピングは、生のHTMLを提供しますが、情報を首尾一貫した物語に合成するインテリジェンスが欠けています。このガイドでは、Google SERPの結果を自動的にスクレイピングし、エンベッディングを使用してコンテンツを分析し、包括的な記事やアウトラインを生成するAI搭載システムを構築する方法を紹介します。
このガイドで学べること
- Bright Dataとベクトル埋め込みを使用した研究から記事への自動パイプラインの構築方法
- スクレイピングされたコンテンツを意味的に分析し、繰り返されるテーマを特定する方法
- LLMを使用して構造化されたアウトラインと完全な記事を生成する方法
- コンテンツ生成のためのインタラクティブなStreamlitインターフェースの作成方法
始めよう
コンテンツ作成のためのリサーチの課題
コンテンツ制作者は、記事、ブログ記事、マーケティング資料のトピックをリサーチする際、大きな障害に直面します。手作業によるリサーチでは、ブラウザのタブを何十個も開き、長い記事に目を通し、バラバラのソースから情報を総合しようとします。このプロセスは、ヒューマンエラーが起こりやすく、時間がかかり、スケールが難しい。
BeautifulSoupや Scrapyを使用した従来のウェブスクレイピングアプローチは、生のHTMLテキストを提供するが、コンテンツのコンテキストを理解し、重要なテーマを特定し、複数のソースにまたがる情報を合成するインテリジェンスが欠けている。その結果、構造化されていないテキストのコレクションとなり、手作業による多大な処理が必要となります。
Bright Dataの堅牢なスクレイピング機能と、ベクトル埋め込みや大規模言語モデルのような最新のAI技術を組み合わせることで、研究から論文へのパイプライン全体を自動化することができます。これにより、数時間の手作業が数分の自動分析に変わります。
私たちが構築しているものAIを活用したコンテンツリサーチシステム
任意のキーワードのGoogle検索結果を自動的にスクレイピングするインテリジェントなコンテンツ生成システムを作成します。このシステムは、ターゲットウェブページから完全なコンテンツを抽出し、テーマと洞察を特定するためにベクトル埋め込みを使用して情報を分析し、直感的なStreamlitインターフェイスを介して構造化された記事のアウトラインまたは完全なドラフト記事のいずれかを生成します。
前提条件
以下の要件で開発環境をセットアップしてください:
- Python 3.9以上
- Bright Dataアカウント:サインアップしてAPIトークンを作成する(無料トライアルクレジットあり)
- OpenAI APIキー:OpenAIダッシュボードでエンベッディングとLLMアクセス用のキーを作成する。
- Python仮想環境:依存関係を隔離
- LangChain+ Vector Embeddings (FAISS):コンテンツの解析と保存を行う
- Streamlit:インタラクティブなユーザーインターフェイスを提供し、ユーザーがツールを利用できるようにする。
環境セットアップ
プロジェクト・ディレクトリを作成し、依存関係をインストールします。他のPythonプロジェクトとのコンフリクトを避けるために、クリーンな仮想環境をセットアップすることから始める。
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvarticle_generator.pyという新しいファイルを作成し、以下のインポートを追加します。これらのライブラリは、ウェブスクレイピング、テキスト処理、埋め込み、ユーザーインターフェイスを扱います。
stとしてstreamlitをインポートする。
import os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()ブライトデータの設定
環境変数を使用してAPI認証情報を安全に保存します。.envファイルを作成して認証情報を保存し、機密情報をコードから分離します。
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token_here"
BRIGHT_DATA_ZONE="あなたの_serp_zone_name"
OPENAI_API_KEY="your_openai_api_key_here"必要です:
- Bright Data APIトークン:Bright Dataダッシュボードから生成
- SERPスクレイピングゾーン:Google SERP用に設定された新しいウェブスクレイパーゾーンを作成します。
- OpenAI APIキー:埋め込みとLLMテキスト生成用
article_generator.py で API 接続を設定する。このクラスはBright Dataのスクレイピングインフラとの全ての通信を処理する。
class BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx"、
args=["@brightdata/mcp"]、
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN")、
"web_unlocker_zone":"mcp_unlocker"、
"browser_zone":"scraping_browser1"、
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("利用可能なMCPツールがありません")
return {'結果': []}.
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
tool_nameに'search_engine'があり、かつtool_nameに'batch'がない場合:
try:
if hasattr(tool, '_run'):
result = tool._run(query=keyword)
elif hasattr(tool, 'run'):
result = tool.run(query=keyword)
elif hasattr(tool, '__call__'):
result = tool(query=keyword)
else:
result = tool.search_engine(クエリー=キーワード)
if result:
return self._parse_serp_results(result)
exception as method_error:
st.warning(f "Method failed for {tool_name}:{str(method_error)}")。
続ける
except Exception as tool_error:
st.warning(f "ツール{ツール名}に失敗しました:{str(tool_error)}")。
続ける
st.warning(f "No search_engine tool could process: {keyword}")
return {'結果': []}.
except Exception as e:
st.error(f "MCPスクレイピングに失敗しました:{str(e)}")。
return {'結果': []}.
def _parse_serp_results(self, mcp_result):
"""MCPツールの結果を期待される形式に解析する。"""
if isinstance(mcp_result, dict) and 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
result': mcp_result} を返す。
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
else:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}.
ただし
return {'結果': []}.
def _parse_html_search_results(self, html_content):
"""検索結果を抽出するためにHTML検索結果ページを解析する。"""
インポート re
結果 = [].
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
リンク = re.findall(link_pattern, html_content, re.DOTALL)
for link_url, link_text in links:
if (link_url.startswith('http') and
if (link_url.startswith('http') and not any(skip in link_url for skip in [ ])
'google.com', 'accounts.google', 'support.google'、
'/search?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10:
results.append({
'url': link_url、
'title': clean_title[:200]、
'snippet': ''、
'position': len(results) + 1
})
if len(results) >= 10:
ブレーク
if not results:
specific_pattern = r' [(.*?)ʅ((https?://[^)]+)ʃ'')
matches = re.findall(specific_pattern, html_content)
for title, url in matches:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url、
'title': title.strip()、
'snippet': ''、
'position': len(results) + 1
})
if len(results) >= 10:
ブレーク
return {'results': results}.記事ジェネレーターを構築する
ステップ 1: SERP とターゲットページのスクレイピング
私たちのシステムの基礎は包括的なデータ収集です。最初にGoogle SERPの結果を抽出し、次に最も関連性の高いソースから全ページのコンテンツを収集するためにそれらのリンクをたどるスクレーパーを構築する必要があります。
class ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx"、
args=["@brightdata/mcp"]、
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN")、
"web_unlocker_zone":"mcp_unlocker"、
"browser_zone":"scraping_browser1"、
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""GoogleのSERP結果からURLを抽出する。"""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = [].
results_list = serp_data.get('results', [])
for result in results_list:
if 'url' in result and self.is_valid_url(result['url']):
urls.append({
'url': result['url']、
'title': result.get('title', '')、
'snippet': result.get('snippet', '')、
'position': result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']):
urls.append({
'url': result['link']、
'title': result.get('title', '')、
'snippet': result.get('snippet', '')、
'position': result.get('position', 0)
})
return urls
def is_valid_url(self, url):
"""画像、PDF、ソーシャルメディアのような記事以外のURLをフィルタリングする。"""
excluded_domains = ['youtube.com','facebook.com','twitter.com','instagram.com']。
除外される拡張子 = ['.pdf', '.jpg', '.png', '.gif', '.mp4'].
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Bright Data MCPツールを使用してウェブページからきれいなテキストコンテンツを抽出する。"""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("No MCP tools available for content scraping")
return ""
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(結果)
if content:
return self._clean_content(content, max_length)
exception as method_error:
st.warning(f "Method failed for {tool_name}:{str(method_error)}")。
続ける
except Exception as tool_error:
st.warning(f"{url}でツール{tool_name}が失敗しました:{str(tool_error)}")。
続ける
st.warning(f "No scrape_as_markdown tool could scrape: {url}")
return ""
except Exception as e:
st.warning(f"{url}のスクレイピングに失敗しました:{str(e)}")。
return ""
def _extract_content_from_result(self, result):
"""MCPツールの結果からコンテンツを抽出する。"""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result and result[key]:
return result[key].
elif isinstance(result, list) and len(result) > 0:
return str(result[0])
return str(result) if result else "".
def _clean_content(self, content, max_length):
"""スクレイピングされたコンテンツをクリーンにしてフォーマットする。"""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
コンテンツに'<'があり、コンテンツに'>'がある場合:
インポート re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = '.join(chunk for chunks in chunks if chunks)
return text[:max_length]このスクレーパーは、記事のコンテンツに集中するようにURLをインテリジェントにフィルタリングする一方で、分析のための貴重なテキストコンテンツを提供しないマルチメディアファイルやソーシャルメディアリンクを避ける。
ステップ 2: ベクトル埋め込みとコンテンツ分析
スクレイピングされたコンテンツを検索可能なベクトル埋め込みに変換し、セマンティックな意味を捉え、インテリジェントなコンテンツ分析を可能にします。埋め込みプロセスは、テキストを機械が理解し比較できる数値表現に変換します。
class ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000、
chunk_overlap=200、
separators=["n", "n", ".", "!", "?", ",", "", "", "", "", "")
)
def process_content(self, scraped_data):
"""スクレイピングされたコンテンツを埋め込みに変換し、テーマを分析する。"""
all_texts = []"
メタデータ = []"
for item in scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url']、
'title': item['title']、
'position': item['position'].
})
if not all_texts:
raise ValueError("分析可能なコンテンツがありません")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5):
"""セマンティック検索を使って主要なテーマとトピックを特定する。"""
theme_analysis = {}。
for term in query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = { {次のようになります。
'relevant_chunks': len(similar_docs)、
'key_passages': [doc.page_content[:200]].+ ...」 for doc in similar_docs[:3]]、
'sources': list(set([doc.metadata['url'] for doc in similar_docs])).
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""スクレイピングされたコンテンツの統計的要約を生成する。"""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
リターン
'total_sources': len(set(meta['url'] for meta in metadata))、
'total_chunks': total_chunks、
'total_words': total_words、
'avg_chunk_length': round(avg_chunk_length, 1)
}アナライザーは、コンテンツを意味的なチャンクに分割し、インテリジェントなテーマ識別とコンテンツ合成を可能にする検索可能なベクトルデータベースを作成します。
ステップ3:LLMで記事またはアウトラインを生成する
埋め込み分析から得られた意味的洞察を活用し、慎重に作成されたプロンプトを使用して、分析されたコンテンツを構造化された出力に変換します。LLMは、あなたの研究データを取り込み、首尾一貫した、よく構造化されたコンテンツを作成します。
クラス ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY")、
temperature=0.7、
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""調査データに基づいて構造化された記事のアウトラインを生成する。"""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f""
キーワード}」に関する包括的な調査に基づいて、詳細な記事のアウトラインを作成する。
研究の概要
- content_summary['total_sources']}ソースを分析する。
- content_summary['total_words']}語のコンテンツを処理
- 重要なテーマと洞察を特定
発見された主要テーマ
{テーマ}
構造化されたアウトラインを作成する
1.説得力のある見出し
2.導入部のフックと概要
3.4-6つのメインセクションとサブセクション
4.要点と結論
5.行動喚起の提案
階層を明確にしたマークダウン形式
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""完全な記事原稿を生成する。"""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f""
キーワード}」に関する包括的な{target_length}ワードの記事を、広範な調査に基づいて書いてください。
研究財団:
{テーマ}
コンテンツの要件
- 読者を惹きつける導入部
- 明確なセクションで構成された本文
- リサーチからの具体的な洞察やデータポイントを含む
- プロフェッショナルで有益なトーン
- 実行可能な収穫を伴う強力な結論
- 小見出しのあるSEOに適した構造
マークダウン形式で記事全体を書く
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""LLM消費用にテーマ分析をフォーマットする。"""
formatted_themes = [].
for theme, data in theme_analysis.items():
theme_info = f "**{theme}**:data['related_chunks']}のコンテンツセクションで見つかった""
theme_info += f "キーインサイト:{data['key_passages'][0][:150]}...n"
theme_info += f "ソース:ソース: {len(data['sources'])} unique referencesn"
formatted_themes.append(theme_info)
return "n".join(formatted_themes)ジェネレーターは2つの異なる出力フォーマットを作成します:コンテンツプランニングのための構造化されたアウトラインと、即時出版のための完全な記事です。どちらの出力も、スクレイピングされたコンテンツのセマンティック分析に基づいている。
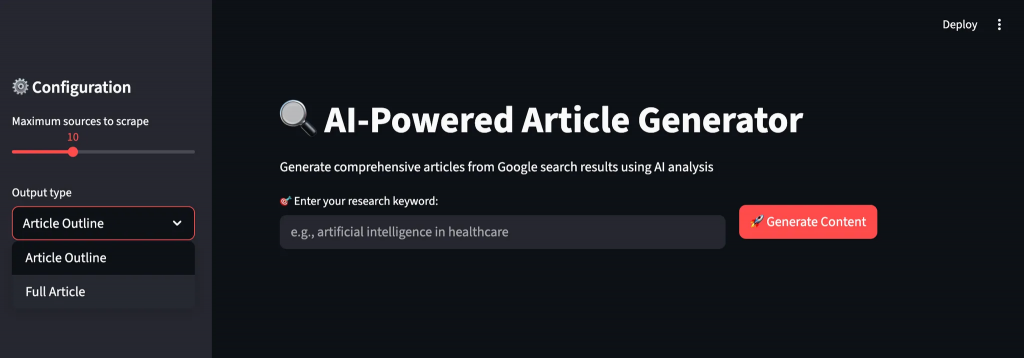
ステップ4:ストリームリットUIの構築
リアルタイムのフィードバックとカスタマイズオプションにより、コンテンツ生成ワークフローを通してユーザーをガイドする直感的なインターフェースを作成する。このインターフェースは、複雑なAI操作を非技術的なユーザーでも利用できるようにする。
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="ᷔ", layout="wide")
st.title("AI搭載記事ジェネレーター")
st.markdown("AI分析を使ってGoogle検索結果から包括的な記事を生成")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
generator = ArticleGenerator()
st.sidebar.header("⚙️ コンフィギュレーション")
max_sources = st.sidebar.slider("Maximum sources to scrape", 5, 20, 10)
output_type = st.sidebar.selectbox("Output type", ["Article Outline", "Full Article"])
target_length = st.sidebar.slider("target word count (full article)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
col1:
keyword = st.text_input("🎯 研究キーワードを入力してください:", placeholder="例:ヘルスケアにおける人工知能")
col2:
st.write("")
generate_button = st.button("🚀 コンテンツの生成", type="primary")
if generate_button and keyword:
try:
progress_bar = st.progress(0)
status_text = st.empty()
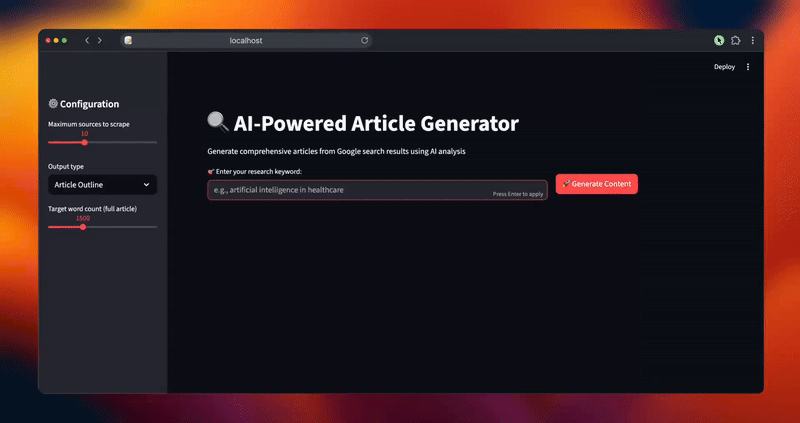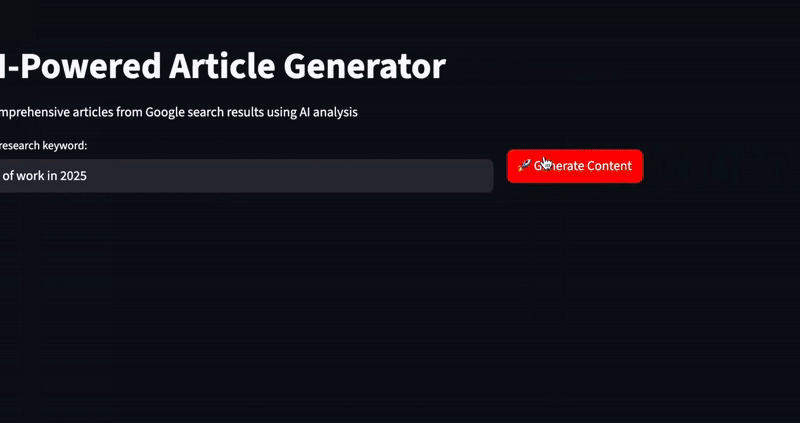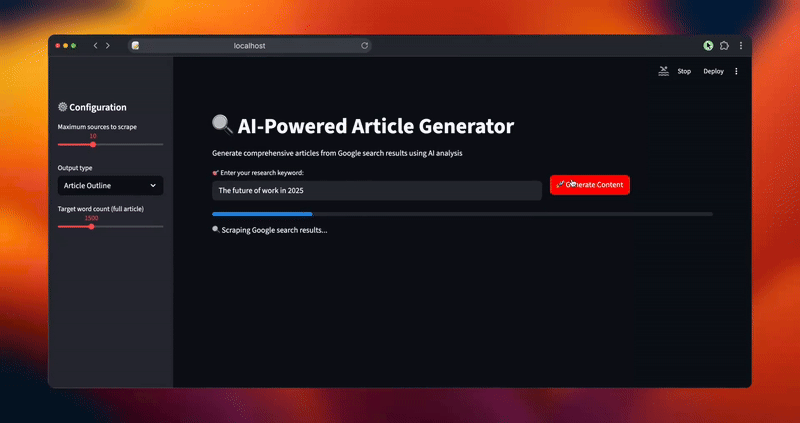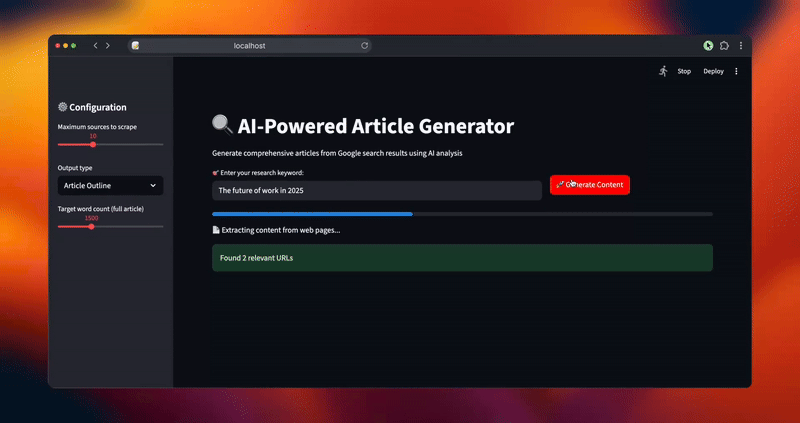
status_text.text("🔍 Googleの検索結果をスクレイピング中...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f "Found {len(urls)} relevant URLs")
status_text.text("📄 ウェブページからコンテンツを抽出中...")
progress_bar.progress(0.4)
scraped_data = [].
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url']、
'title': url_data['title']、
'content': コンテンツ、
'position': url_data['position'].
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("ᾐ AIエンベッディングでコンテンツを分析中...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword]キーワード] + keyword.split()[:3
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ AI搭載コンテンツを生成中...")
progress_bar.progress(0.9)
if output_type == "Article Outline":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
さもなければ
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
progress_bar.progress(1.0)
status_text.text("✅ コンテンツ生成完了!")
st.markdown("---")
st.subheader(f"📊『{キーワード}』の調査分析")
col1, col2, col3, col4 = st.columns(4)
col1:
st.metric("Sources Analyzed", content_summary['total_sources'])
with col2:
st.metric("Content Chunks", content_summary['total_chunks'])
col3 の場合
st.metric("Total Words", content_summary['total_words'])
col4 の場合
st.metric("平均チャンクサイズ", f"{content_summary['avg_chunk_length']} words")
st.expander("🎯同定された主要テーマ"):
for theme, data in theme_analysis.items():
st.write(f "**{theme}**: {data['relevant_chunks']} 関連するセクションが見つかりました")
st.write(f "Sample insight: {data['key_passages'][0][:200]}...")
st.write(f "ソース:ソース:{len(data['sources'])}一意の参照")
st.write("---")
st.markdown("---")
st.subheader(f"📝生成された{output_type}")
st.markdown(結果)
st.download_button(
label="💾コンテンツのダウンロード"、
data=result、
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md"、
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ 生成に失敗しました:{str(e)}")。
st.write("API認証情報を確認して再試行してください。")
if __name__ == "__main__":
main()Streamlitのインターフェースは、リアルタイムの進捗追跡、カスタマイズ可能なパラメーター、リサーチ分析と生成されたコンテンツの即時プレビューなど、直感的なワークフローを提供します。ユーザーは結果をマークダウン形式でダウンロードし、編集や出版に役立てることができます。
記事ジェネレータの実行
ウェブリサーチからコンテンツを生成するためにアプリケーションを実行します。ターミナルを開き、プロジェクトのディレクトリに移動します。
streamlit run article_generator.pyあなたのリクエストを処理するシステムのインテリジェントなワークフローが表示されます:
- GoogleのSERPから関連性フィルタリングを使って包括的な検索結果を抽出します。
- ボット対策でターゲットのウェブページからフルコンテンツをスクレイピング
- ベクトル埋め込みとテーマ識別を使用してコンテンツを意味的に処理します。
- 複数のソースにまたがる反復パターンと重要な洞察を分析します。
- 適切なフローとプロフェッショナルなフォーマットで構造化されたコンテンツを生成します。
最終的な感想
これで、複数のソースから調査データを自動的に収集し、包括的なコンテンツに変換する完全な記事生成システムが完成しました。このシステムは、意味論的なコンテンツ分析を行い、ソース間で繰り返されるテーマを特定し、構造化された記事やアウトラインを生成します。
スクレイピングターゲットや分析基準を変更することで、このフレームワークを様々な業界に適応させることができます。モジュール設計により、ニーズの変化に応じて新しいコンテンツプラットフォーム、埋め込みモデル、生成テンプレートを追加することができます。
より高度なワークフローを構築するには、Bright DataのAIインフラストラクチャで、ライブのウェブデータを取得、検証、変換するためのあらゆるソリューションをお試しください。
無料の Bright Data アカウントを作成して、AI 対応のウェブデータソリューションの実験を開始してください!






