

このガイドでは、以下の内容をご紹介します:
- Bright Data CLIとは何か、その仕組み、提供される機能、公開されているコマンドについて。
- Linux、macOS、WSL、WindowsへのインストールとCLIの使い始め方。
- シンプルでガイド付きの方法でCLIを使い始めるための最初のステップ。
- 実際の例を用いて示される、サポートされるユースケースとシナリオ。
さっそく始めましょう!
Bright Data CLIの概要
実際の動作を見る前に、Bright Data CLIが何をもたらし、どのように機能するかを理解しましょう。
Bright Data CLIとは?
Bright Data CLIは、Bright Data APIの全機能への合理的なアクセスを提供するオールインワンのターミナルツールです。つまり、直接的なターミナルコマンドを公開することで、Bright DataのプロダクトとサービSとの統合を簡素化します。
大まかに言えば、以下のコマンドを提供します:
- Web Unlocker APIを通じて、CAPTCHAやアンチボット保護を回避しながら任意のウェブサイトをスクレイピング。
- SERP APIを使用して、Google、Bing、Yandexなどの主要エンジンで構造化検索を実行。
- Web Scraping APIを通じて、40以上のプラットフォーム(Amazon、LinkedIn、Instagramなど)からデータを抽出。
- Browser APIを介して、ブロック不可能なリモートブラウザを使用してウェブページをプログラム的に操作。
- Bright Data Web MCPによるセットアップとオーケストレーションの簡素化。
- さらに多くの機能…
参考資料:
仕組み
@brightdata/cliはBright Data CLIの公式npmパッケージです。インストールすると、brightdataコマンド(省略形としてbdata)にアクセスでき、ターミナルから直接Bright Data APIの全機能を操作できます。
brightdata CLIツールはBright Dataのウェブデータプラットフォーム全体をラップし、シンプルで開発者に優しいコマンドで公開します。内部では以下を行います:
- OAuth、デバイスフロー、またはAPIキーで一度認証し、資格情報をローカルに保存するため再入力不要。以降、すべてのコマンドがすぐに機能し、トークン管理、ゾーン作成、プロキシ設定も不要です!
- 初回ログイン時にBright Dataアカウントで必要なゾーン(
cli_unlockerおよびcli_browser)を自動的にプロビジョニングし、すぐに開始できます。 - Bright Dataのインフラストラクチャーにリクエストをルーティングし、CAPTCHA、ボット検出、IP ローテーション、JavaScriptレンダリング、その他すべてのウェブスクレイピングの課題を処理。
- ターミナルでのフォーマット済みテーブルや構造化JSON、CSV、Markdown(下流の分析・処理、AIワークフローを含む優れたデータ形式)など、クリーンで使いやすい出力を返します。
機能と特性
以下はBright Data CLIが提供するコア機能の一覧です:
- インフラと費用管理:単一のCLIベースのインターフェースからプロキシの使用状況を監視し、設定を確認し、アカウント残高、帯域幅の使用量、ゾーンごとのコストを追跡。
- ユニバーサルウェブスクレイピング:アンチボット保護の組み込み処理により、任意のウェブサイトからデータにアクセスし、クリーンですぐに使える出力を提供。
- 検索エンジンデータアクセス:主要な検索エンジンでクエリを実行し、オーガニックリスト、広告などを含む構造化された結果を受信。
- 構造化データ抽出:分析準備が整った数十のプラットフォームからウェブデータフィードを取得。
- リモートブラウザ自動化:管理されたブラウザを通じてライブウェブページとプログラム的に対話し、ナビゲーション、クリック、タイピング、動的コンテンツの処理を実行。
- 自動化フレンドリーなワークフロー:Bashスクリプトとパイプラインにコマンドを統合し、チェーニングと大規模なデータ処理をサポート。
- AIエージェント統合:簡略化された方法でAIコーディングアシスタントに事前構築済みスキルまたはMCP接続を追加。
- 簡単なセットアップと設定:ガイド付きセットアップと資格情報およびデフォルト設定の一元化された設定で、CLIを素早く初期化し環境設定を管理。
主要コマンド
Bright Data CLIはbrightdataコマンド(またはbdataエイリアス)で利用できます。次のように使用します:
brightdata <COMMAND> <ARGUMENTS>サポートされているコマンドは以下の通りです:
| コマンド | 機能 |
|---|---|
scrape <url> |
CAPTCHA、JavaScriptレンダリング、その他のアンチスクレイピング保護を処理しながら任意のウェブサイトをスクレイピング。 |
search <query> |
Google、Bing、またはYandexで構造化検索を実行し、整理されたJSON結果を受信。 |
pipelines <type> [params...] [options] |
Amazon、LinkedIn、TikTokなど40以上のプラットフォームから構造化データを抽出。 |
browser |
実際のブラウザをリモートで制御し、ウェブページのナビゲーション、クリック、タイピング、プログラム的な操作を実行。 |
add mcp |
Bright Data Web MCPサーバーをClaude Code、Cursor、CodexなどのAIコーディングエージェントに接続。 |
skill |
Bright DataのAIエージェントスキルを事前構築済みでコーディングアシスタントにインストールし、自動化を強化。 |
zones |
Bright Dataプロキシのゾーンと現在の設定を一覧表示および確認。 |
budget |
アカウント残高、ゾーンごとのコスト、帯域幅の使用量を一目で確認。 |
サポートされているオプションと引数を含むコマンドの完全なリストについては、ドキュメントを参照してください。
Bright Data CLIの使い始め方:ステップバイステップガイド
以下のチュートリアルセクションでは、ローカルマシンにBright Data CLIをセットアップするプロセスを案内します。
インストール手順は環境によって異なります:
- LinuxまたはmacOSでは、専用のCLIインストーラーを使用してすぐに開始できます。
- Windows、またはNode.jsを使用するLinux/macOSでは、npmパッケージをグローバルにインストールし、特定のコマンドで設定を完了する必要があります。
どちらの場合も、初期セットアップにかかる時間はわずか数分です!
次の2つの章では、共通の前提条件から始めて両方のアプローチを紹介します。
前提条件
マシンでBright Data CLIを操作するには(環境に関わらず)、以下が必要です:
- ローカルにインストールされたNode.jsバージョン20以上(LTSバージョン推奨)。
- Bright Dataアカウント(無料で新規作成可能)。
Linux/macOS/WSLでのBright Data CLIのセットアップ
macOS、Linux、その他のUnixベースシステム(WSLを含む)では、以下のコマンドでBright Data CLIをインストールします:
curl -fsSL https://cli.brightdata.com/install.sh | shこのコマンドはBright Data CLIインストーラーをダウンロードして実行します。CLIのインストールとセットアップが行われます。
以下のような出力が表示されます: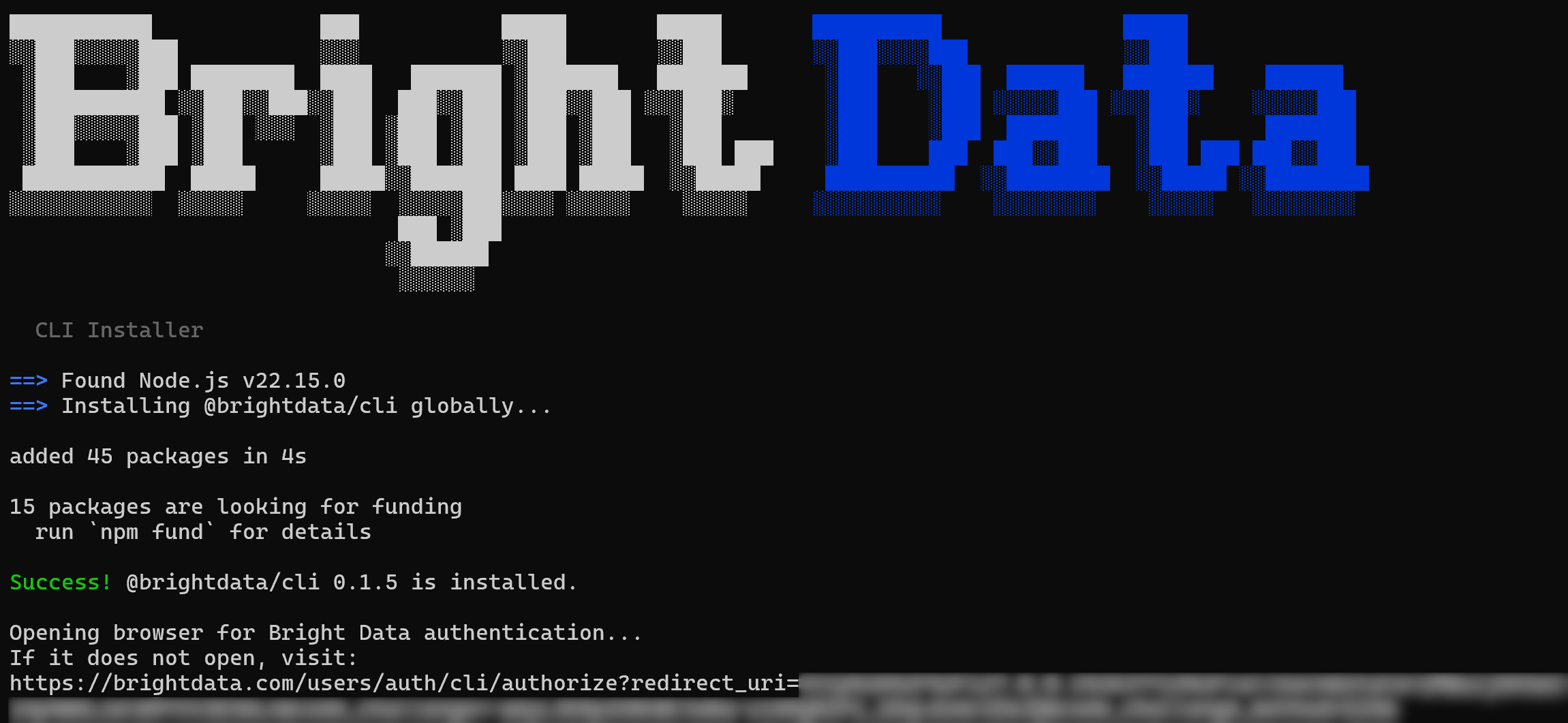
@brightdata/cli npmパッケージがグローバルにインストールされていることに注目してください。次に、Bright Dataアカウントで認証するためのURLが表示されます。Bright DataログインページへのブラウザページがAUTOMATICALLYに開くはずです。開かない場合は、URLをコピーして手動で開いてください。
ログイン後、以下の確認画面が表示されます: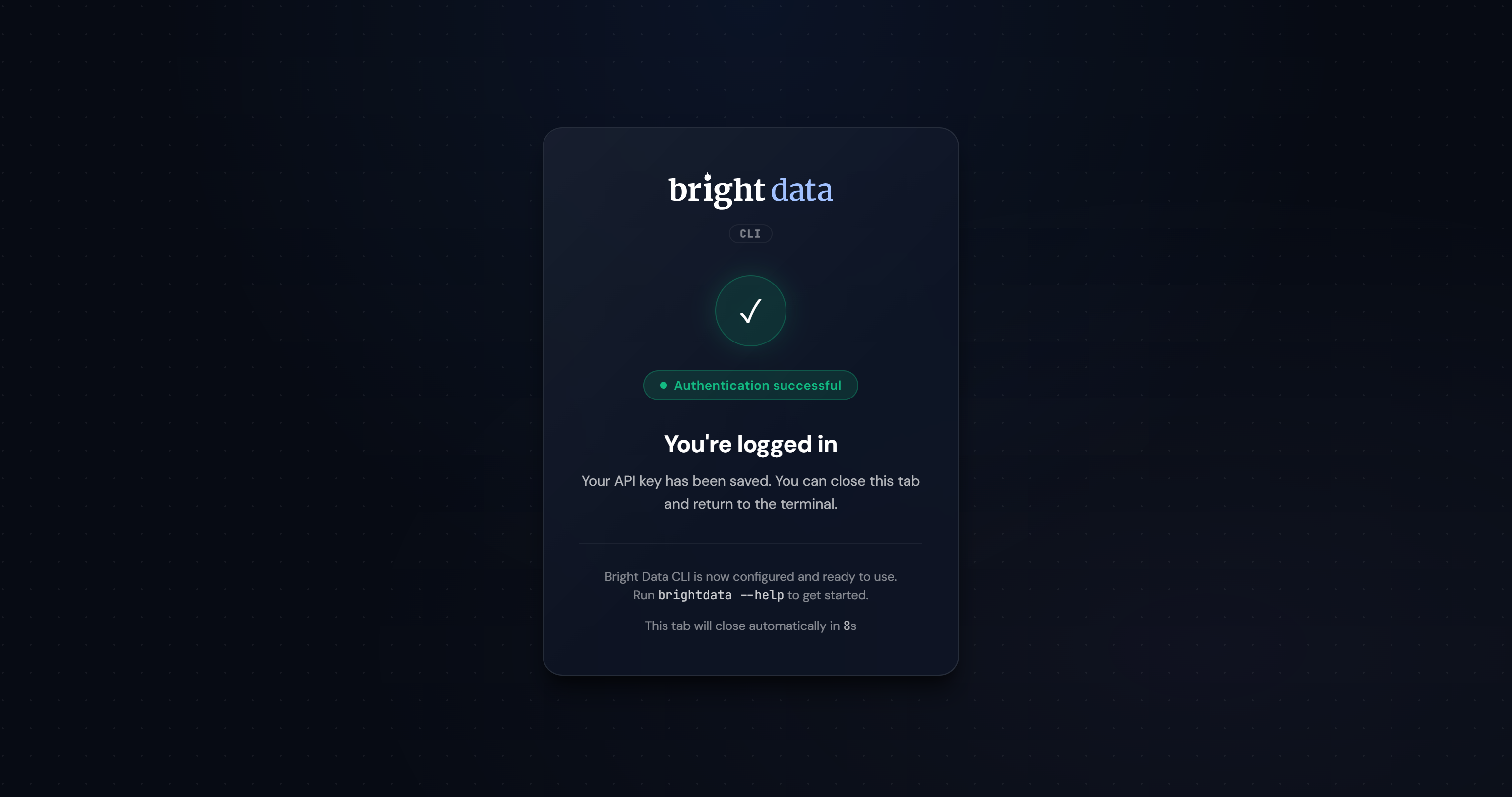
認証が成功すると、Bright Data CLIは必要なゾーンを作成し、システムで完全に動作可能になります:
セットアップが正常に完了したことを以下のコマンドで確認します:
brightdata --versionまたは同等のエイリアス:
bdata --versionどちらの場合も、結果は次のようになります:
0.1.5この場合、0.1.5はローカルにインストールされたBright Data CLIのバージョンです。
Bright Data CLIがローカルにインストールされ、Bright Dataアカウントが設定され、CLIが認証されました。完了です!
WindowsまたはNode.js経由での他のOSへのBright Data CLIのセットアップ
以下の手順に従って、WindowsまたはNode.js経由で他のオペレーティングシステムにBright Data CLIをセットアップします。
ステップ#1:npmでCLIをインストール
WindowsまたはいずれかのプラットフォームでCLIをインストールするには、npmを使用してBright Data CLIをグローバルにインストールします:
npm install -g @brightdata/cliこれにより、マシン上のどこからでもbrightdataコマンドを使用できるようになります。
注意:インストールせずにCLIを実行するには、以下を使用します:
npx --yes --package @brightdata/cli brightdata <command>brightdataコマンド(またはそのエイリアスbdata)がグローバルに利用可能であることを確認します:
brightdata --version結果にはインストールされたパッケージのバージョンが表示されます:
0.1.5Bright Data CLIがローカルにインストールされ、グローバルコマンドとしてアクセス可能になりました。
ステップ#2:Bright Dataアカウントに接続
以下のコマンドを実行して、CLIをBright Dataアカウントにリンクします:
brightdata login以下の出力が表示されます:
Bright DataログインページへのブラウザページがAUTOMATICALLYに開きます。開かない場合は、提供されたURLをコピーして手動で開いてください。これにより、Bright DataアカウントでOAuthを使用して認証できます。
ログイン後、次のような確認ページが表示されます:
新しいBright Data Agent APIキーが作成され、認証のためにマシンにローカルに保存されます。成功すると、CLIは自動的に必要なゾーンをセットアップし、使用準備が整います:
まとめると、loginコマンドは以下を行います:
- APIキーをローカルに検証して保存
- 必要なプロキシゾーン(
cli_unlocker、cli_browser)を自動的に作成 - すぐに開始できるよう適切なデフォルト設定を行う
注意:ログアウトして認証をリセットするには、以下を実行します:
brightdata logoutBright Data CLIがインストールされ、認証され、使用準備が整いました。
セットアップ後の概要と最初のステップ(オプション)
Bright Data CLIのセットアップ後、Bright Dataアカウントには2つの新しいゾーン(cli_unlockerおよびcli_browser)が追加されます: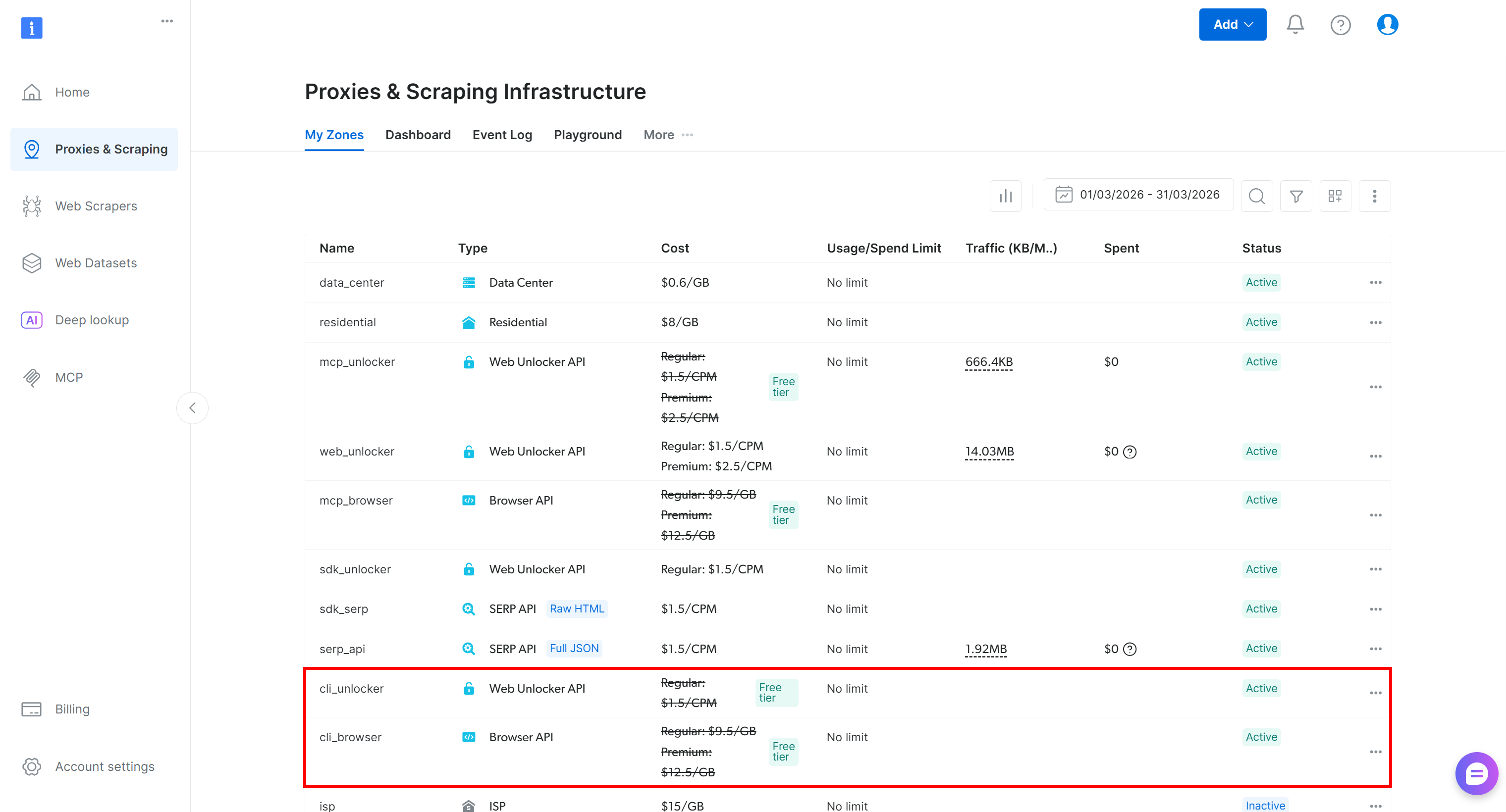
また、新しいAgent APIキーも作成されます。これはOAuth経由で作成された特別なBright Data APIキーで、ゾーンの管理、リクエストの送信、予算情報の取得などを行えます: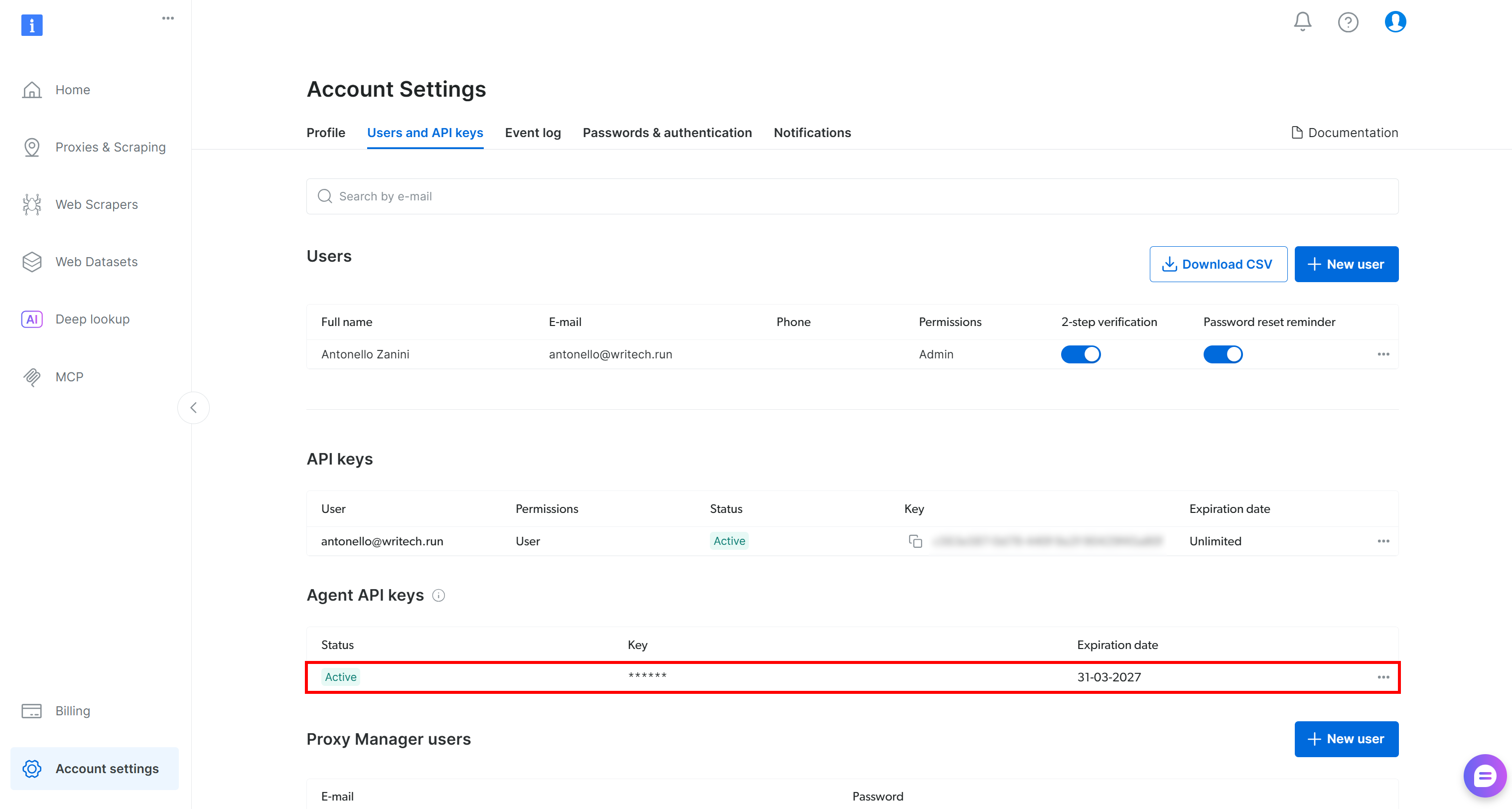
CLIを初めて実行する場合は、initコマンドで開始します:
brightdata initこれにより、Bright Data CLIを設定するインタラクティブウィザードが起動し、テスト用のいくつかの例が提供されます。
セットアップ中に以下を求められます:
- 設定されたBright Data Agent APIキーの確認または更新。
- デフォルトのWeb Unlockerゾーンの選択(デフォルト:
cli_unlocker)。 - SERP APIのデフォルトとして同じゾーンを使用するかどうかの選択。
- デフォルトの出力形式の選択(MarkdownまたはJSON)。
完了すると、インストールのテストと検証のためのBright Data CLIコマンドの例が続く簡潔なセットアップサマリーが表示されます。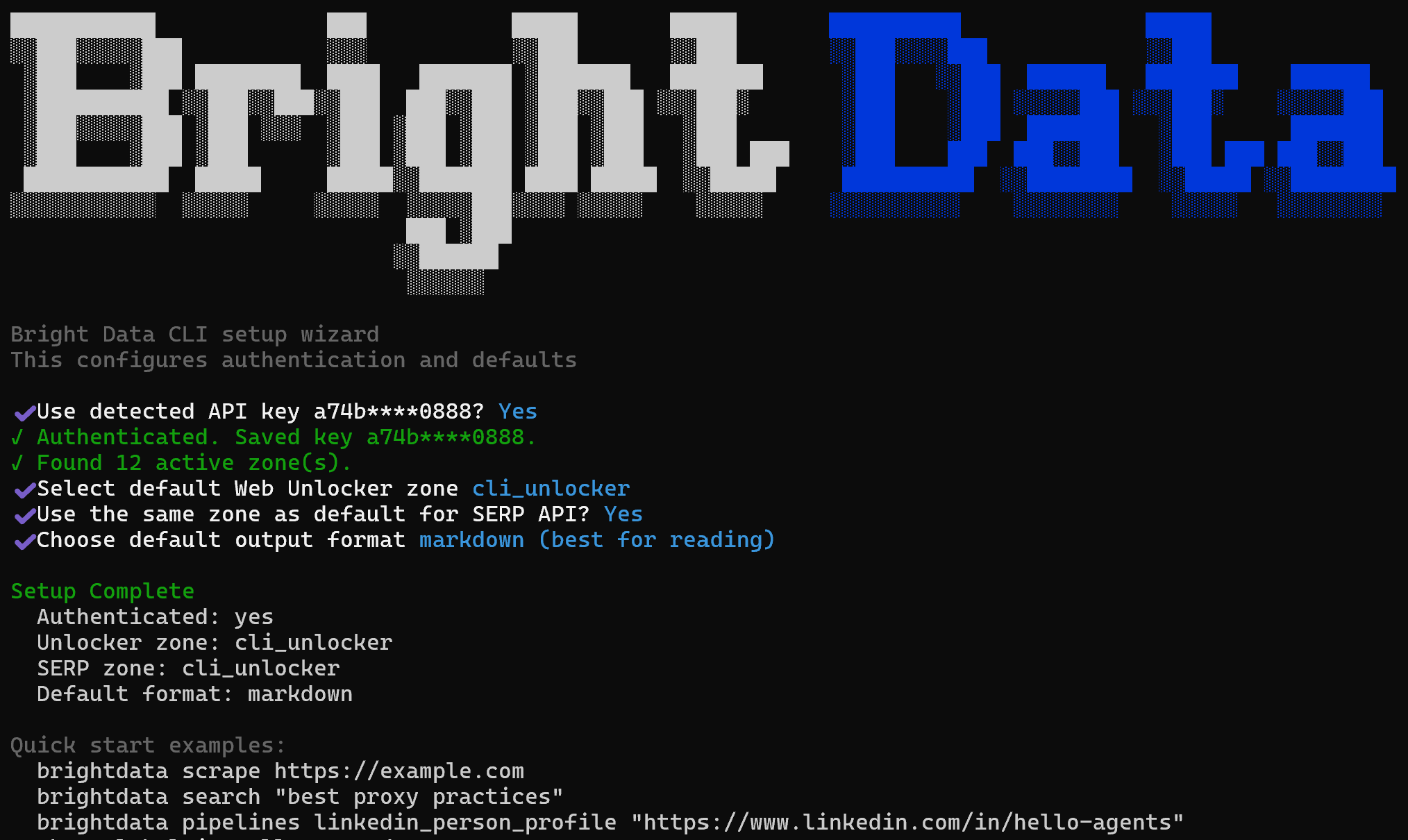
注意:現在の設定を表示するには、brightdata configコマンドを使用します。設定を更新するには、以下を実行します:
brightdata config set <CONFIG_NAME> <CONFIG_VALUE>または、グローバル環境変数を使用してオーバーライドします。
Bright Data CLIの実例:実際のユースケース
Bright Data CLIは多くのオプションを持つ複数のコマンドをサポートしています。ここでは最も関連性の高いものをいくつか探ります。完全な例のリストについては、ドキュメントをご覧ください。
注意:Bright Data CLIの使用は、月間5,000リクエストまで定期的に無料です。つまり、無料で始められます!
任意のウェブサイトのスクレイピング
ウェブページからコンテンツを取得するには、scrapeコマンドを次のように使用します:
brightdata scrape https://nodejs.org/en結果はMarkdown形式(デフォルトのデータ形式)でSTDOUTに出力されます:
これはコマンドで指定されたページの(LLMの取り込みに最適な)Markdownバージョンに対応しています: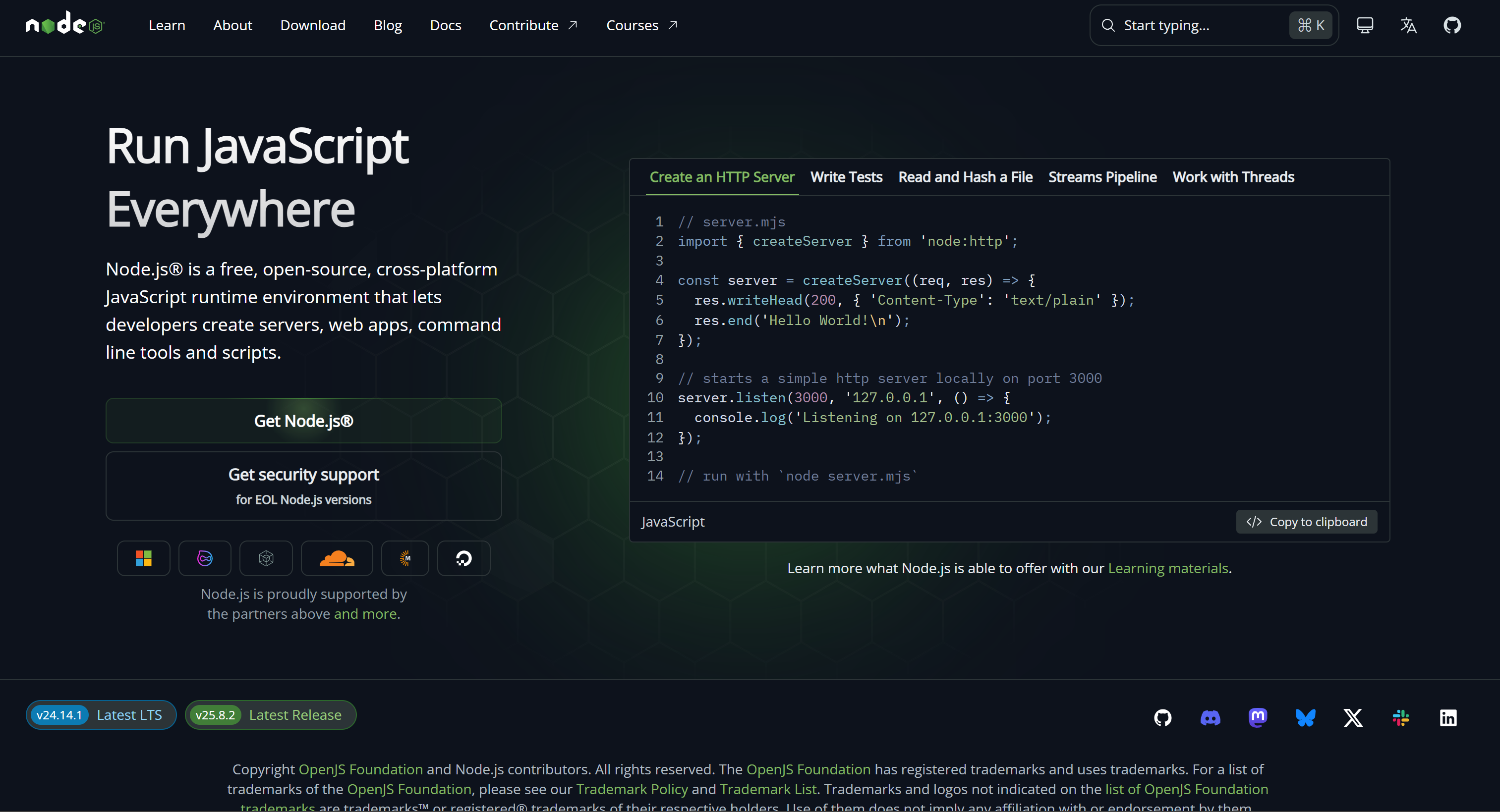
特定の国(例:米国)でリクエストをジオローカライズしたい場合は、--country引数を使用します:
brightdata scrape amazon.com/Apple-Cellular-Multisport-Smartwatch-Titanium/dp/B0FQF9TJ86 --country us米国からページを閲覧しているかのような結果が得られます(地理的制限の回避や場所によって変わるコンテンツの表示に便利)。
結果をファイルにエクスポートするには、-o引数を使用します:
brightdata scrape https://www.w3schools.com/sql/sql_where.asp -o tutorial.mdtutorial.mdファイルが作成され、Markdown形式のスクレイピングされたコンテンツが入力されます: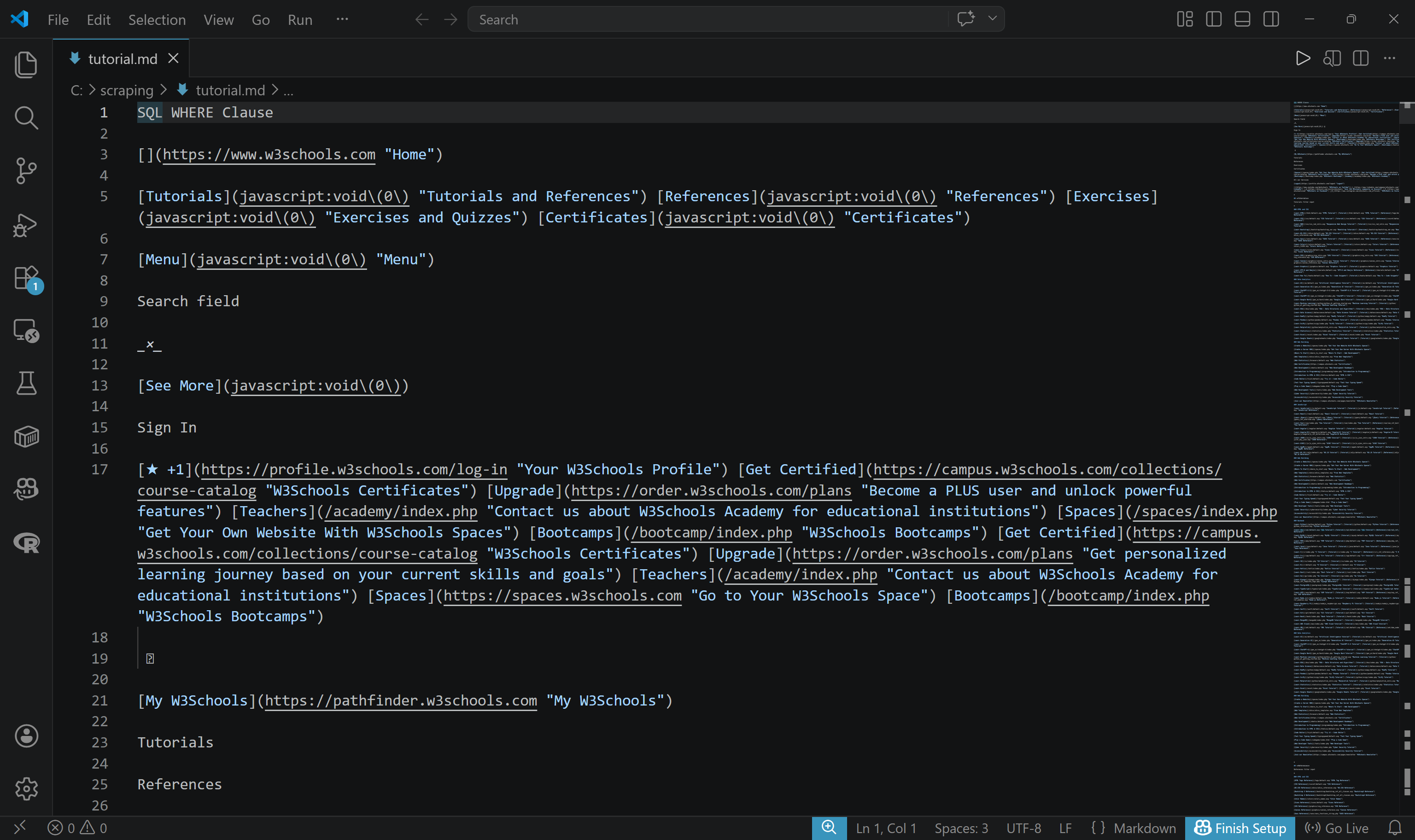
生のHTMLを取得するには、-f引数を使用して形式を指定します。また、出力をファイルに書き込むことも検討してください:
brightdata scrape https://developer.mozilla.org/en-US/ -f html -o index.html出力はスクレイピングされたページの生のHTMLを含むindex.htmlという名前のファイルになります: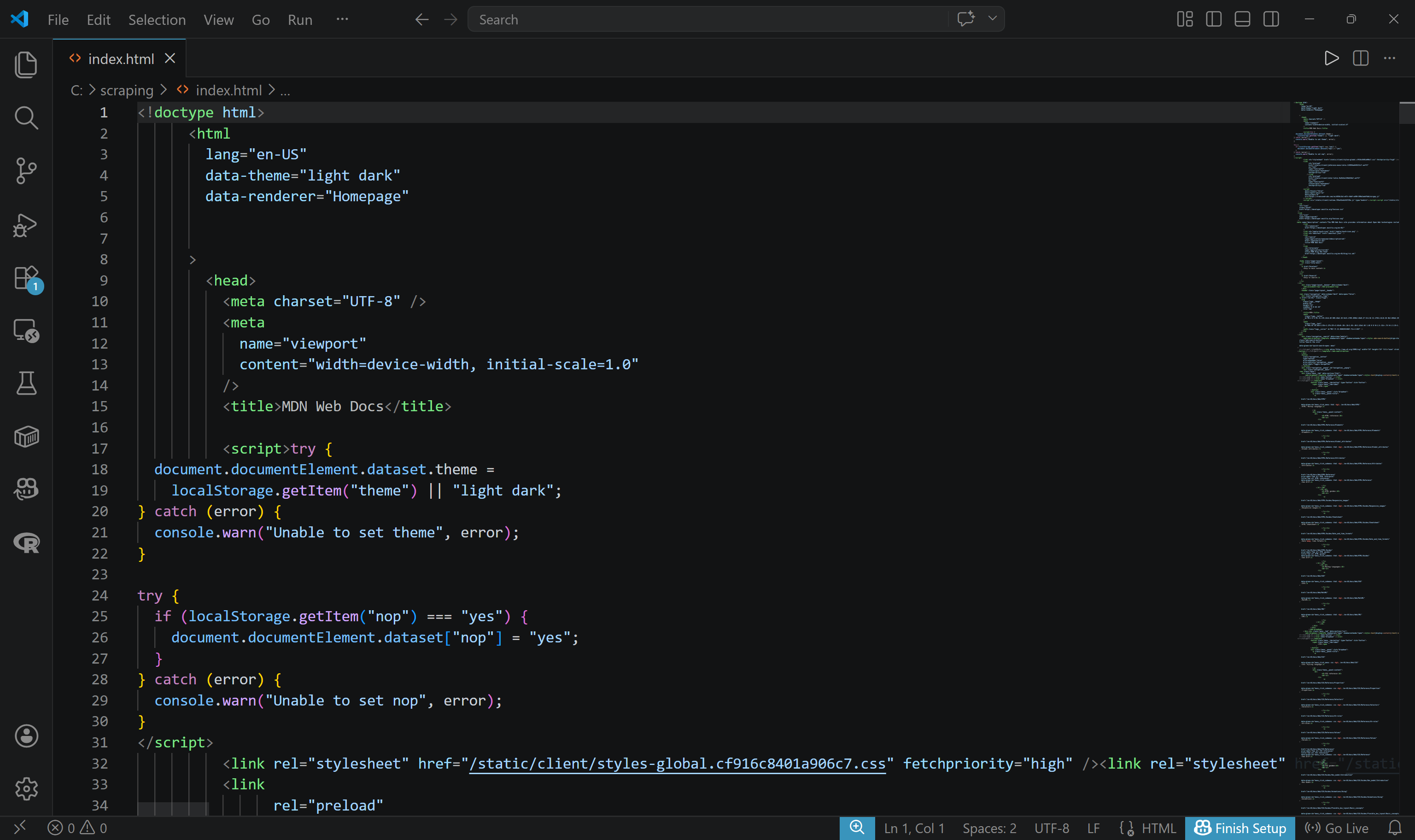
同様のメカニズムで、特定のページのスクリーンショットを撮ることもできます:
brightdata scrape https://www.amazon.com/Apple-2026-MacBook-13-inch-Laptop/dp/B0GR6BVYS5?th=1 -f screenshot -o page.pngpage.pngには以下が含まれます: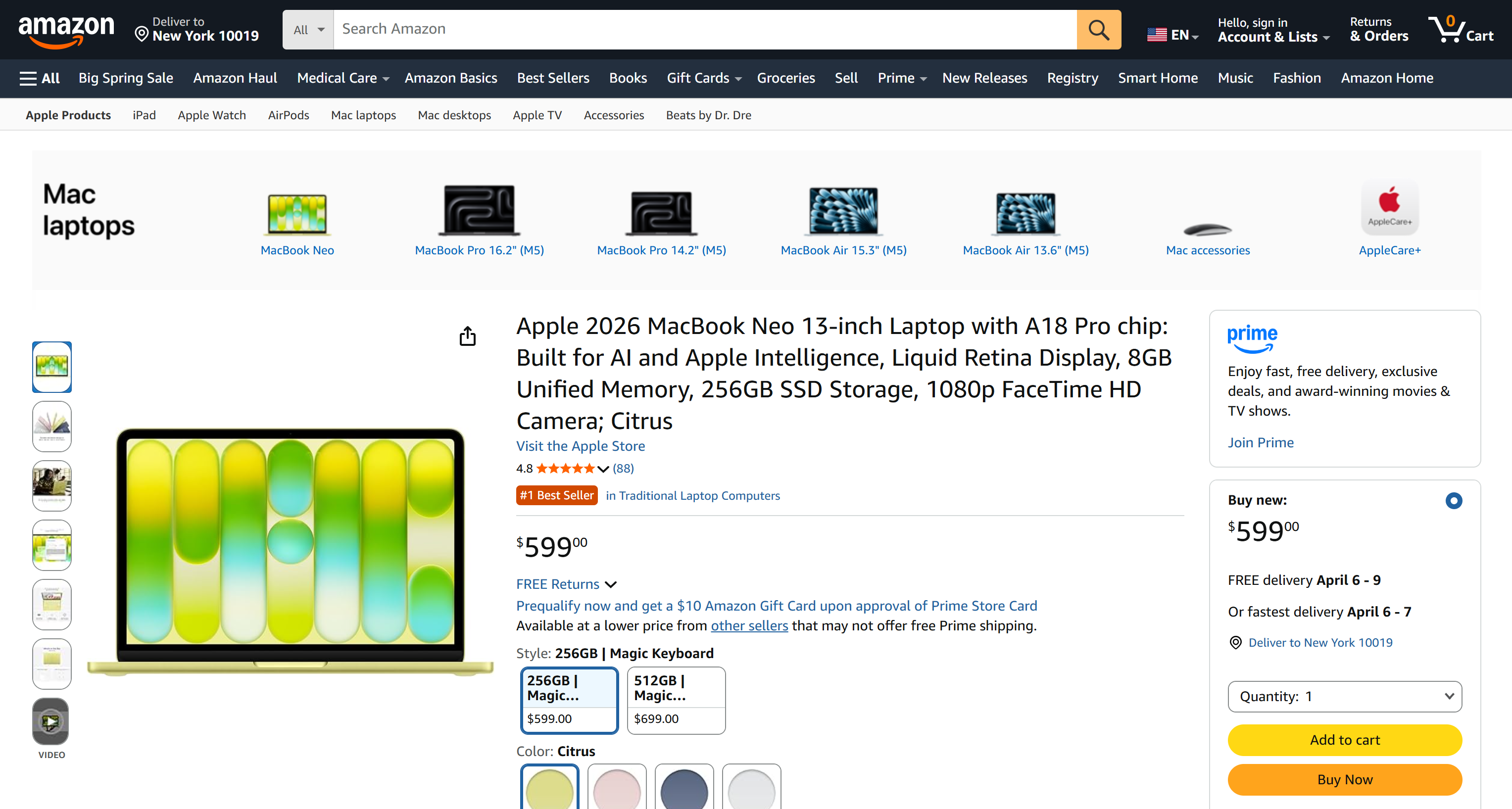
ウェブ検索
searchコマンドを使用してCLIから直接ウェブ検索を実行します:
brightdata search "best chatgpt scrapers"結果はフォーマットされたテーブルとして返され、読みやすく確認しやすくなっています:
結果のテーブルは「best cheap scrapers」クエリのGoogle SERPに対応しています: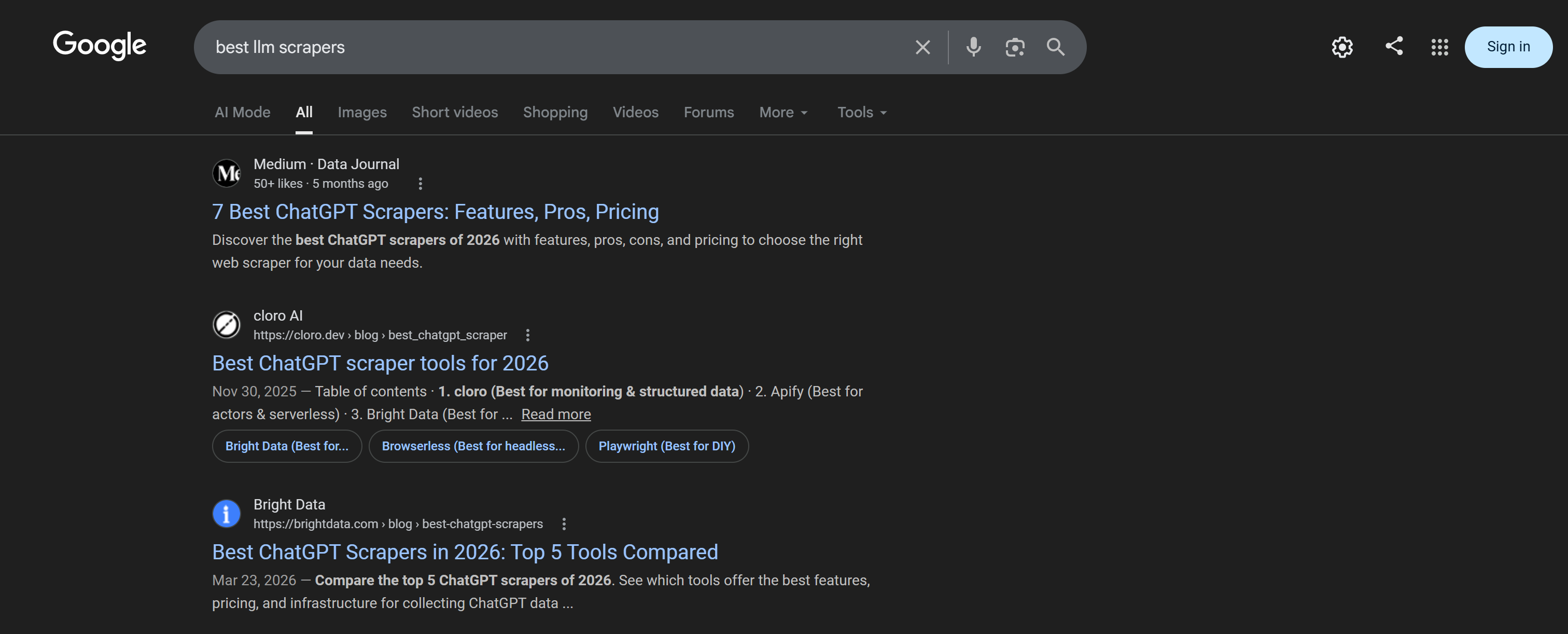
Googleの結果ページを制御するには、--page引数を指定します:
brightdata search "best llms" --page 2
さらなる処理のための構造化データが必要な場合は、--jsonフラグを使用して生のJSON出力を取得します:
brightdata search "node.js security best practices" --jsonこれはスクリプトへの結果のパイプや他のツールとの統合に最適です:
より読みやすいバージョンの生の出力を得るには、--prettyフラグを設定します:
brightdata search "best llm scrapers" --pretty上記のコマンドは結果を見やすい形式で生成し、デバッグや調査中に役立ちます:
検索コンテキストをカスタマイズすることもできます。例えば、特定の国と言語でローカライズされたクエリを実行するには:
brightdata search "mejores restaurantes italianos en Madrid" --country es --language esコマンドはスペインからスペイン語で検索を実行したかのように結果を返します:
最後に、取得したい結果のタイプを特定することができます。例えば、ニュース結果のみを取得するには:
brightdata search "barcelona beaches" --type imagesユースケースに応じて、shoppingやnewsなどの他のサポートされているタイプもあります。
構造化データフィードの取得
生のスクレイピングを超えて、pipelinesコマンドを使用して人気プラットフォームから構造化データを抽出できます。これにより、特定のアプリケーション向けのクリーンですぐに使えるデータセットが返されます。
例えば、Amazonの商品ページから構造化された詳細情報を収集するには、以下を実行します:
brightdata pipelines amazon_product "https://www.amazon.com/Apple-2025-MacBook-Laptop-10%E2%80%91core/dp/B0FWD726XF/"これにより、Bright Data Amazon Web スクレイパー上で非同期タスクがトリガーされ、レスポンスが準備できるまで自動的にポーリングされます: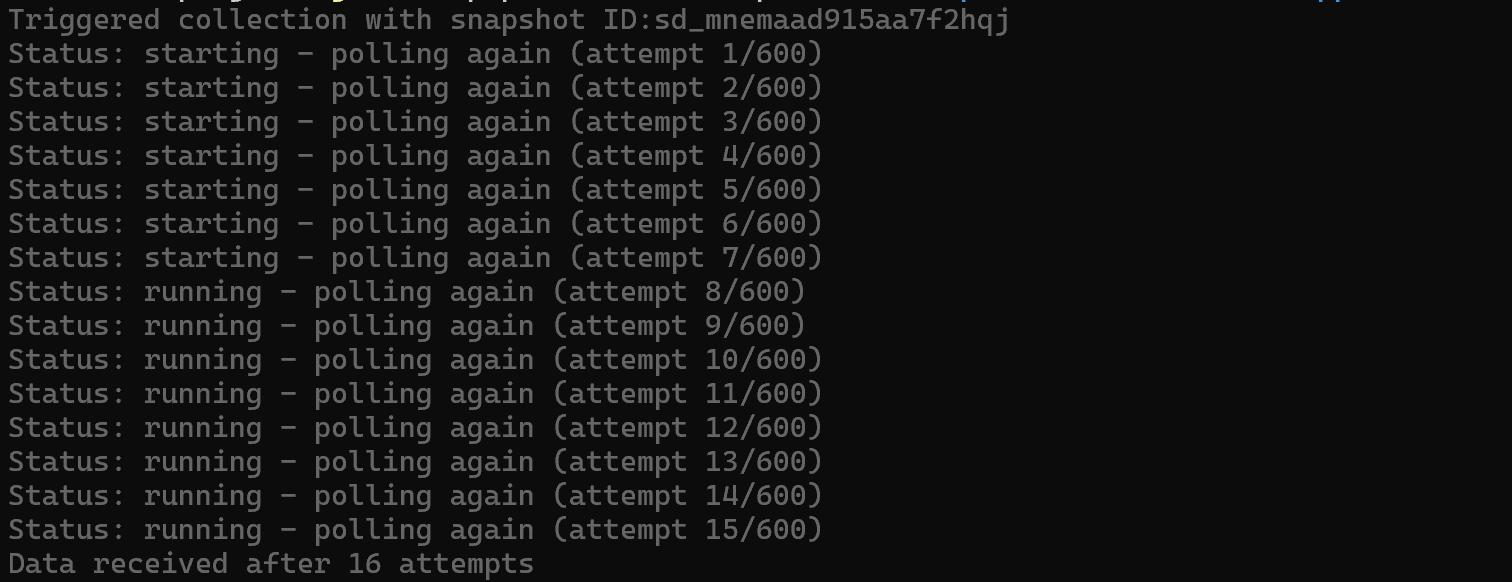
ターゲットデータセットが準備できると、ターミナルに(デフォルト形式のJSONで)印刷されます: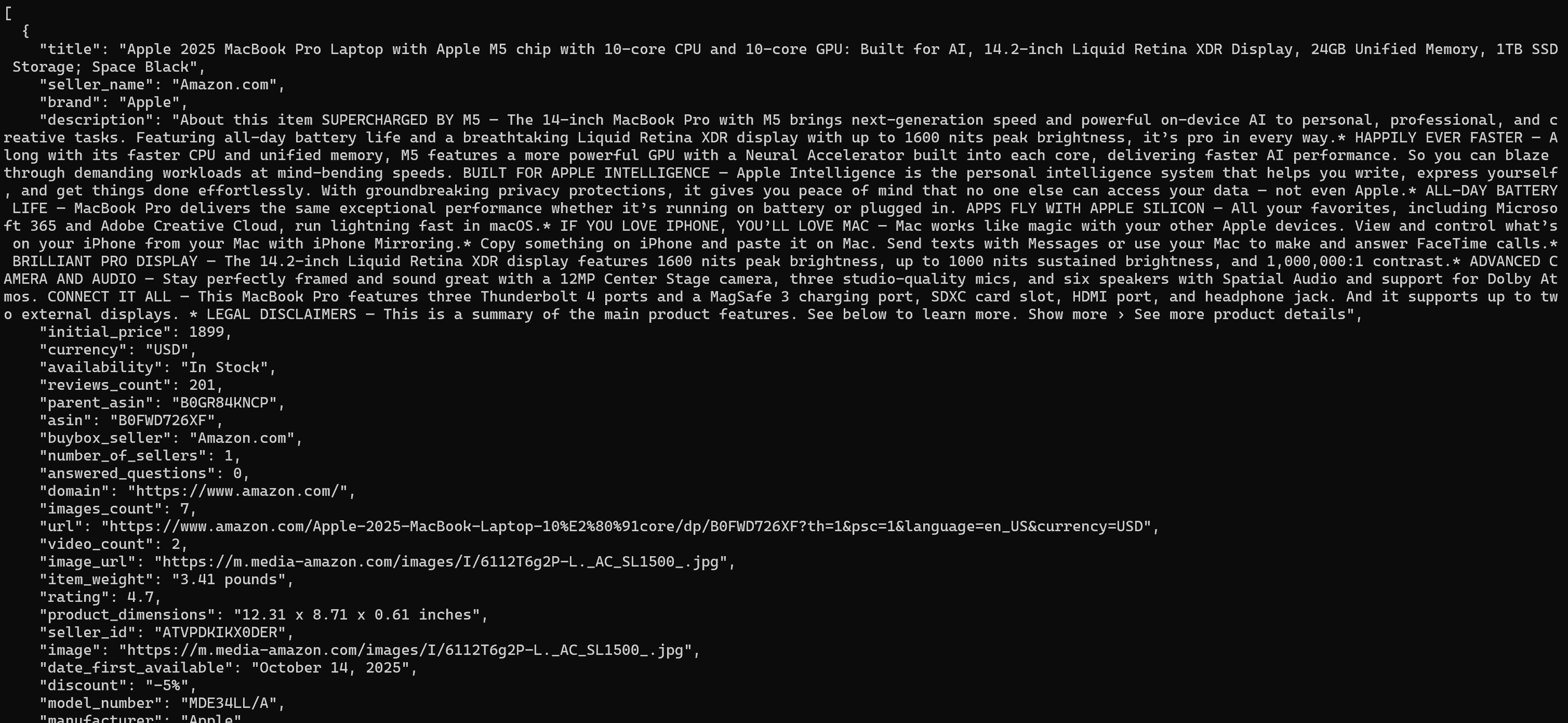
出力には商品タイトル、価格、評価、仕様などが構造化形式で含まれます。
同様に、企業レベルの洞察を得るために、Crunchbaseのようなビジネスインテリジェンスソースをターゲットにしたパイプラインを使用できます:
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata"上記のpipelinesコマンドは、資金調達、業界、会社概要などの主要な詳細を収集します: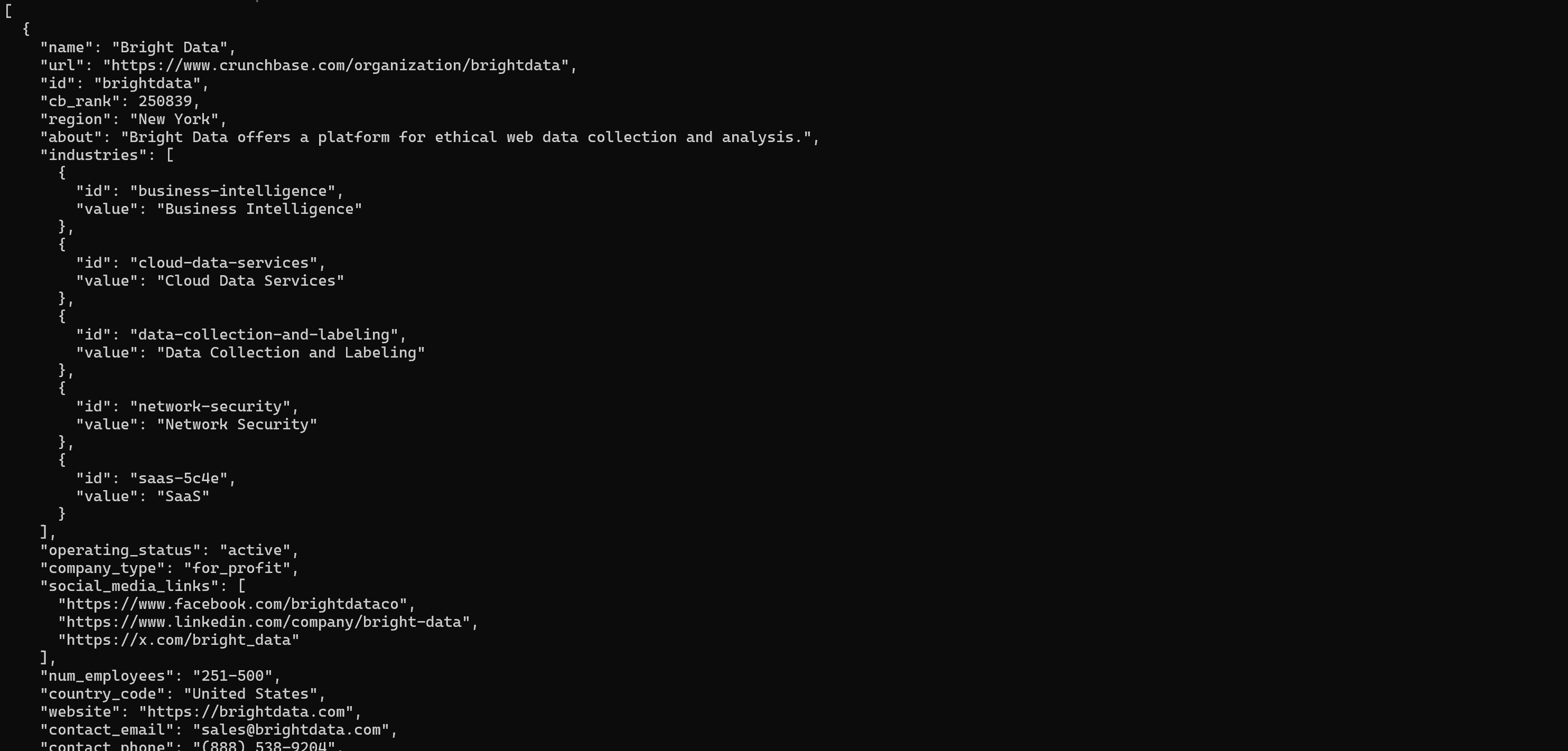
これはCrunchbaseの企業ページで見つけられる公開情報と一致します:
LinkedInプロフィールから構造化データを取得したい場合は、以下を実行します:
brightdata pipelines linkedin_person_profile "https://es.linkedin.com/in/antonello-zanini"返される情報には名前、役割、経験、学歴が含まれます: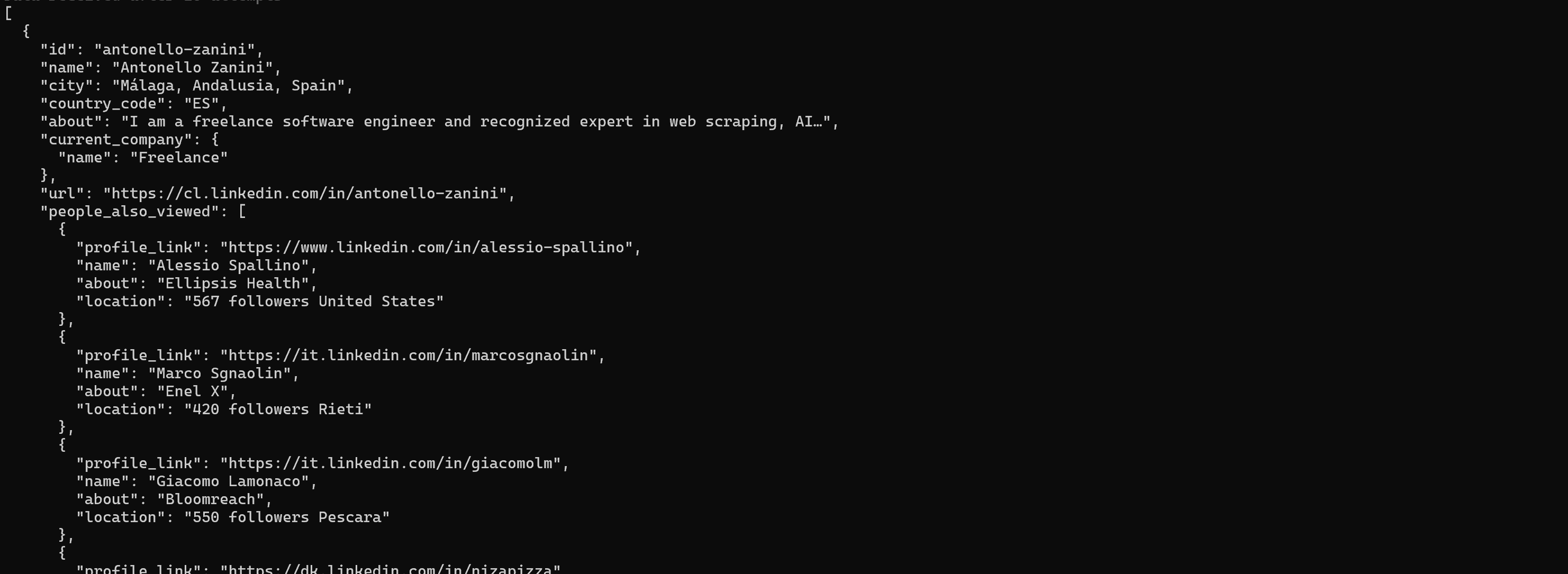
スクレイピングと同様に、構造化された結果をファイルにエクスポートできます:
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata" --format csv -o company.csvこれにより、下流の分析と処理に対応した構造化された企業データを含むcompany.csvファイルが作成されます:
実際のブラウザセッションの制御
browserコマンドを使用すると、Bright DataのスクレイピングブラウザAPIを搭載した実際のリモートブラウザを制御できます。永続的なセッションを維持するため、すべてのコマンドで再接続することなくページをステップバイステップで操作できます。
セッションを開始してページに移動するには、以下を実行します:
brightdata browser open https://example.comこれにより自動的にブラウザセッションが起動し、ターゲットページが読み込まれます:

ページコンテンツを構造化されたトークン効率の良い方法で読み取るには、以下を入力します:
brightdata browser snapshot --compactこれにより、各インタラクティブ要素に参照ID(例:e1、e2)が割り当てられたページのアクセシビリティツリーが返され、さらなるアクションに使用できます: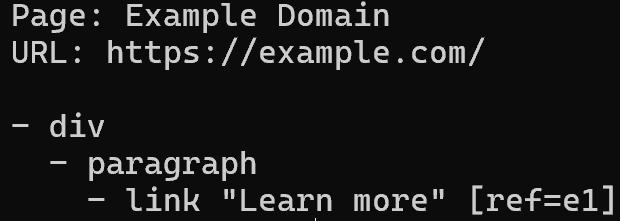
返されたツリーがターゲットウェブページと一致していることに注目してください:
要素のクリックなど、ページを操作できるようになりました:
brightdata browser click e1または入力フィールドへの入力、スクリーンショットの撮影、その他多くのアクションも可能です。
最後に、完了したらセッションを閉じます:
brightdata browser closeこれにより、リモートブラウザが停止します:
Unixパイプによるコマンドのチェーン
Bright Data CLIはパイプフレンドリーに設計されています。STDOUTがTTYでない場合、色とスピナーが自動的に無効になり、スクリプティングと自動化に最適です。
このメカニズムにより、コマンドをチェーンしてシンプルなデータパイプラインを構築できます。検索からスクレイピングまでを一つのフローで行う方法を以下に示します:
brightdata search "best python scraping libraries" --json
| jq -r ".organic[0].link"
| xargs brightdata scrape上記のパイプラインはGoogle検索を実行し、最初の結果URL(この場合はRedditページ)を抽出し、すぐにスクレイピングします(Markdownでコンテンツを返します):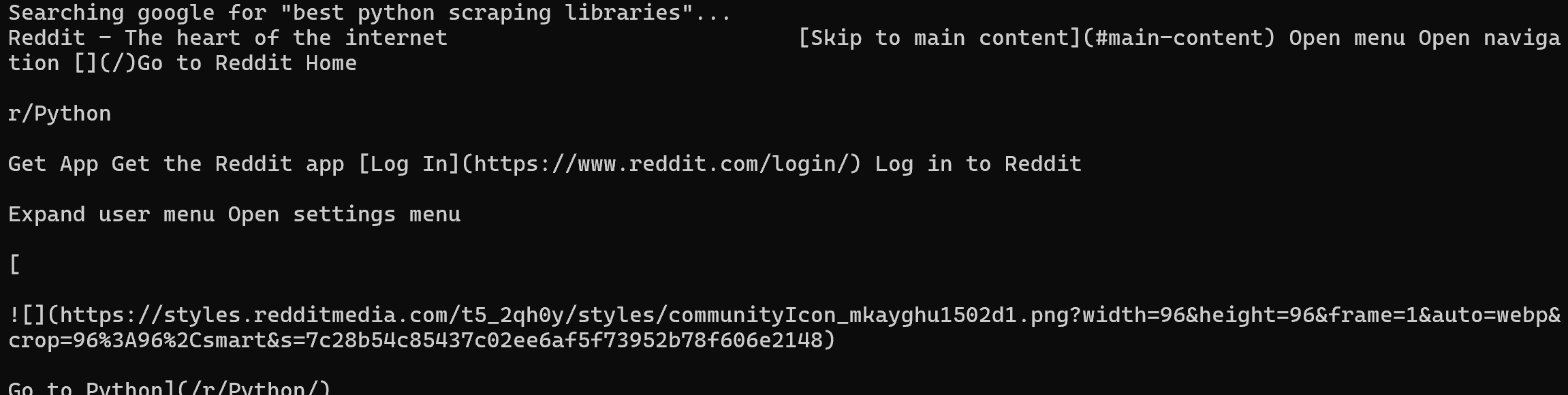
このパターンは、Bright DataをシェルスクリプトやCronジョブ、または大規模なデータワークフローに統合する際に特に強力です。実行するには、jqがローカルにインストールされている必要があります:
sudo apt-get install jqスキルによるコーディングエージェントの拡張
CLIから直接Bright Dataスキルをインストールして、AIコーディングエージェントを強化します。
インタラクティブにスキルを選択してインストールするには、以下を実行します:
brightdata skill addこれにより、インストールするスキルとターゲットとするエージェントソリューション(Claude Code、Amp、Cline、Codexなど)を選択できるインタラクティブピッカーが開きます: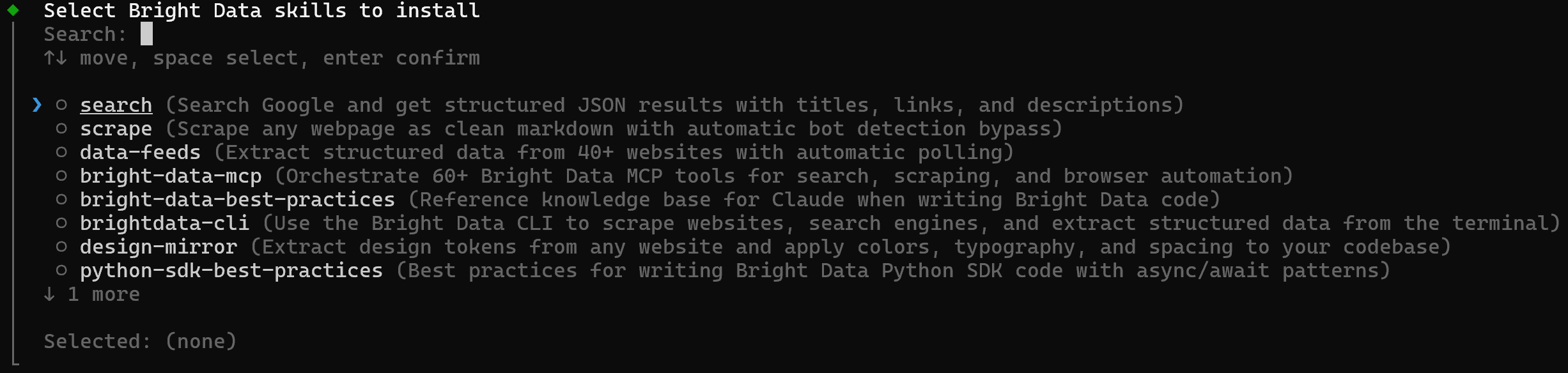
または、Web MCPを通じてBright Dataをエージェントソリューションに直接接続できます:
brightdata mcp addこれにより、Bright Data MCPサーバーがClaude Code、Cursor、またはCodexにリンクされ、スクレイピング、検索、データパイプラインをネイティブツールとして使用できるようになります: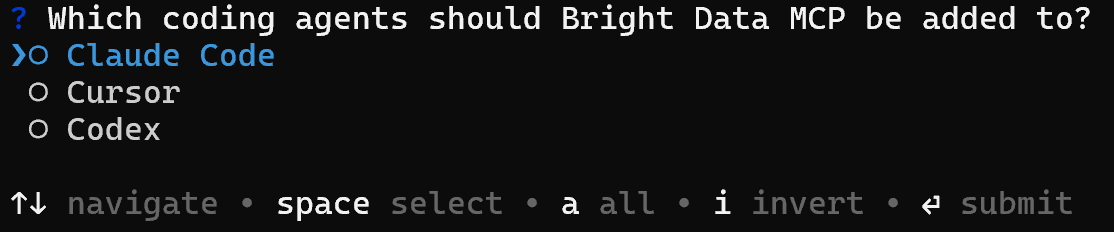
アカウント管理とモニタリング
CLIを活用してBright Dataアカウントを監視し、使用状況、残高、コストをリアルタイムで追跡します。
利用可能なすべてのゾーンを表示するには、以下を使用します:
brightdata zones考えられる出力は: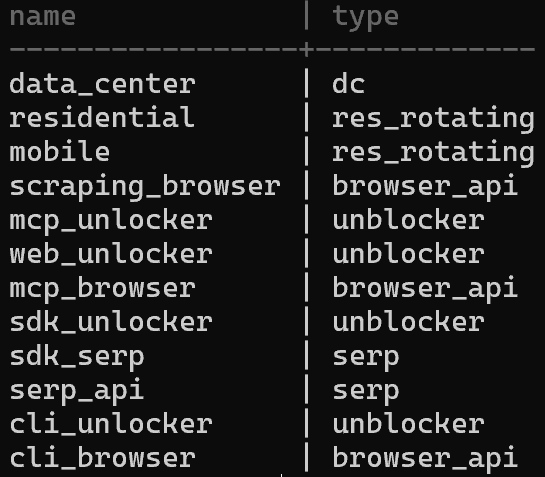
これはBright Dataコントロールパネルの「マイゾーン」テーブルと一致します: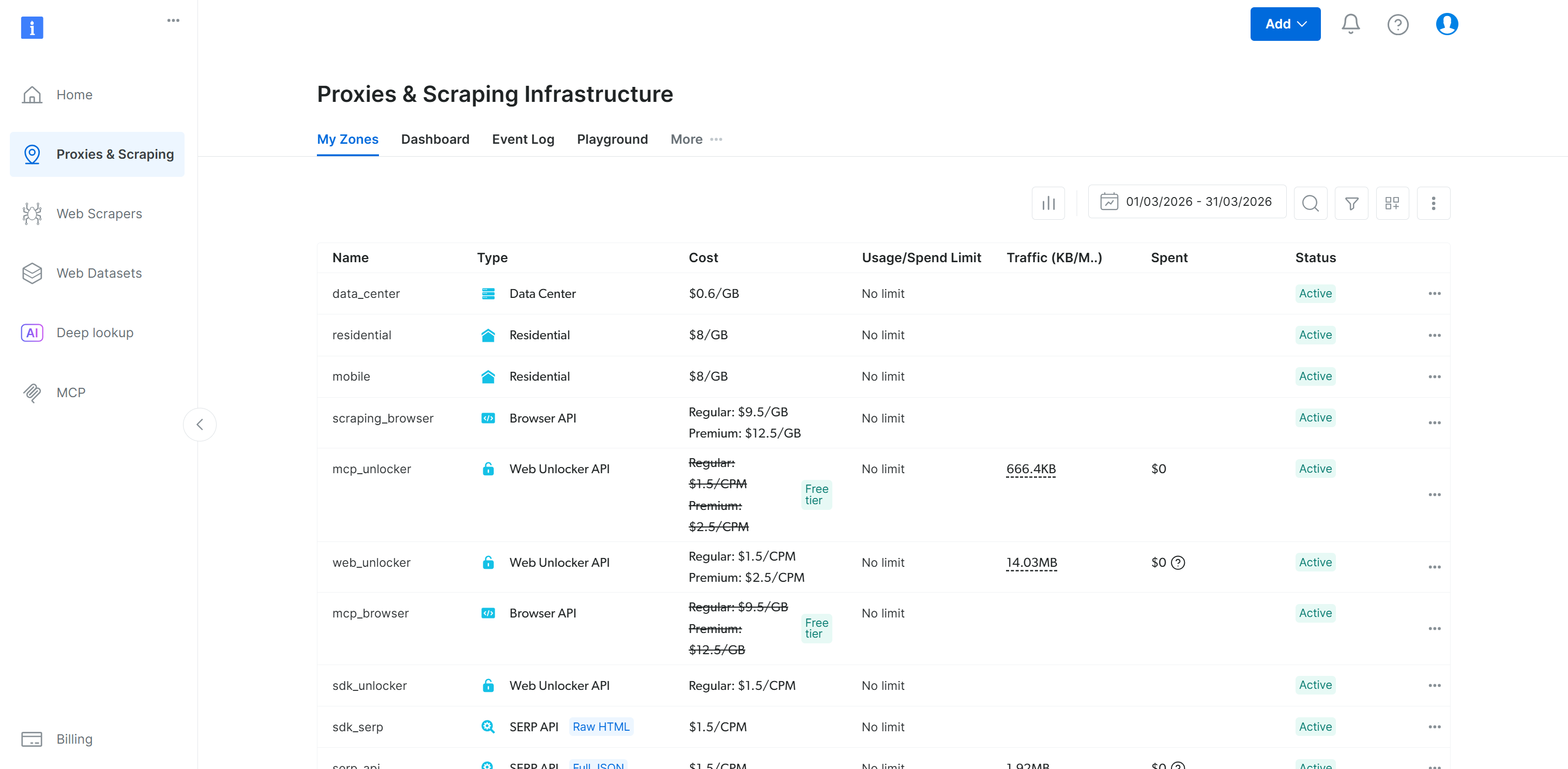
残高をすばやく確認するには、以下を実行します:
brightdata budgetこれにより、現在のクレジットの概要が返されます:
異なるゾーン間の支出を分析したい場合は、以下でコスト分布を確認します:
brightdata budget zonesこれにより、ゾーンごとの使用状況が表示され、クレジットがどこで消費されているかを特定しやすくなります: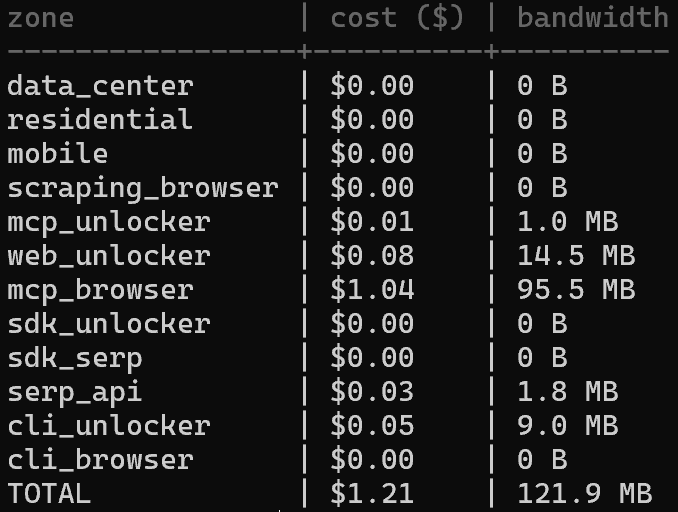
まとめ
このブログ記事では、Bright Data CLIが提供するものと、それがもたらす主なメリットについて学びました。これにより、ターミナルから直接すべてのBright Data APIベースのソリューションに接続、操作、利用できることがわかりました。
CLIは完全にパイプフレンドリーで、複雑なBashベースのデータワークフローもサポートします。Bright Data CLIドキュメントで、サポートされているすべてのシナリオ、コマンド、統合を確認してください。また、GitHubリポジトリにスターを付けることもご検討ください!
今日、無料でBright Dataアカウントを作成し、CLIを含むウェブデータプロダクトをお試しください!
FAQ
その他のFAQとトラブルシューティングについては、公式ドキュメントをご確認ください。
CLIを使用するにはBright Dataアカウントが必要ですか?
はい!CLIはウェブリクエストの管理にBright Dataのインフラを使用します。無料アカウントを作成して無料ティアから始めることができます。
Bright Data CLIの資格情報はどこに保存されますか?
資格情報はマシンにローカルに保存され、所有者の読み取り/書き込み専用(0o600)のアクセス権が設定されます:
- macOS:
~/Library/Application Support/brightdata-cli/credentials.json - Linux:
~/.config/brightdata-cli/credentials.json - Windows:
%APPDATA%brightdata-clicredentials.json
ブラウザなしのリモートサーバーでログインするにはどうすればよいですか?
deviceオプションと共にloginコマンドを使用します:
brightdata login --deviceこれにより、URLと確認コードが表示されます。ブラウザを持つ任意のデバイスでURLを開き、コードを入力すると、サーバーで認証が完了します。
サポートされている出力形式は何ですか?
Bright Data CLIでサポートされている出力データ形式は以下の通りです:
scrapeコマンドの場合:markdown(デフォルト)、html、json、screenshot。searchコマンドの場合:フォーマットされたテーブル(デフォルト)、json(生のJSON)、pretty(インデントされたJSON)。pipelinesコマンドの場合:json(デフォルト)、csv、ndjson、jsonl。
すべてのコマンドは、スクレイピングされた出力を直接ファイルに書き込む-o <path>オプションをサポートしていることに注意してください。






