

この記事では、次のことを学びます:
- Anthropicウェブ取得ツールとは何か、その主な制限事項。
- どのように動作するか。
- cURLとPythonでの使用方法。
- 同様の目的を達成するためにBright Dataが提供するもの
- AnthropicウェブフェッチツールとBright Dataウェブデータツールの比較。
- 簡単な比較のための要約表
さあ、飛び込もう!
Anthropic ウェブフェッチツールとは?
Anthropicウェブフェッチツールは、クロードモデルがウェブページやPDFドキュメントからコンテンツを取得することを可能にします。このツールは2026-09-10のクロードベータリリースで無料で導入されました。
このツールをClaude APIリクエストに含めることで、設定されたLLMは指定されたウェブページやPDF URLから全文を取得して分析することができます。これにより、Claudeは、根拠のある応答のための最新のソースベースの情報にアクセスできるようになります。
注意事項と制限事項
Anthropicウェブフェッチツールに関連する主な注意事項と制限事項です:
- 追加費用なしでClaude APIで利用可能。会話コンテキストに含まれるフェッチされたコンテンツに対してのみ、標準的なトークン料金を支払います。
- 指定したウェブページとPDFドキュメントからフルコンテンツを取得します。
- 現在ベータ版で、ベータ版ヘッダ
web-fetch-2026-09-10が必要です。 - クロードは URL を動的に構築することはできません。完全な URL を明示的に提供するか、以前のウェブ検索やフェッチ結果から取得した URL のみを使用する必要があります。
- 会話コンテキストに既に表示されている URL のみをフェッチできます。これには、ユーザーメッセージ、クライアント側ツールの結果、または以前のウェブ検索およびウェブ取得結果からの URL が含まれます。
- 以下のモデルでのみ動作します:クロード オーパス 4.1
(claude-opus-4-1-20260805)、クロード オーパス 4(claude-opus-4-20260514)、クロード ソネット 4.5(claude-sonnet-4-5-20260929)、クロード ソネット 4(claude-sonnet-4-20260514)、クロード ソネット 3.7(claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (deprecated)(claude-3-5-sonnet-latest), Claude Haiku 3.5(claude-3-5-haiku-latest). - 動的にレンダリングされるJavaScriptウェブサイトはサポートしません。
- 取得したコンテンツの引用をオプションで含めることができます。
- プロンプトのキャッシュと連動し、会話の順番をまたいでもキャッシュされた結果を再利用できます。
max_uses、allowed_domains、blocked_domains、max_content_tokensパラメータをサポートする。- 一般的なエラーコード:
invalid_input、url_too_long、url_not_allowed、url_not_accessible、too_many_requests、unsupported_content_type、max_uses_exceeded、unavailable。
クロード・モデルにおけるウェブ・フェッチの仕組み
AnthropicウェブフェッチツールをAPIリクエストに追加すると、舞台裏ではこのようなことが起こります:
- Claudeはプロンプトと提供されたURLに基づいて、コンテンツをフェッチするタイミングを決定します。
- APIは指定されたURLから全文コンテンツを取得します。
- PDF の場合は、自動テキスト抽出が実行されます。
- Claudeは取得したコンテンツを分析し、任意で引用を含む応答を生成する。
結果のレスポンスはユーザーに返されるか、さらなる分析のために会話コンテキストに追加される。
Anthropicウェブフェッチツールの使い方
ウェブフェッチツールを使用する2つの主な方法は、サポートされているクロードモデルの1つへのリクエストでそれを有効にすることです。これは以下のいずれかの方法で行うことができます:
- Anthropic APIへの直接APIコールを介して。
- Anthropic Python APIライブラリのようなClaudeクライアントSDKの1つを通して。
以下のセクションで方法をご覧ください!
どちらの場合も、以下に示すAnthropicホームページをスクレイピングするためにウェブフェッチツールを使用する方法を示します:

前提条件
Anthropicウェブフェッチツールを使用するための主な条件は、Anthropic APIキーにアクセスできることです。ここでは、APIキーを持つAnthropicアカウントを持っていると仮定します。
直接APIコールを通して
以下のように、cURL POSTリクエストで Anthropic APIに直接APIコールを行うことで、Webフェッチツールを利用することができます:
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10" ¦ --header "content-type: application-type.
--header "content-type: application/json" ୧-͈ᴗ-͈
--データ '{
"model":"claude-sonnet-4-5-20260929",
"max_tokens":1024,
「メッセージ": [
{
"role":"user": "ユーザー"、
"content":"「https://www.anthropic.com/」からコンテンツをスクレイピングする"
}
],
「ツール": [{
"type":"web_fetch_20260910",
"name":"web_fetch"、
"max_uses":5
}]
}'claude-sonnet-4-5-20260929は、ウェブフェッチツールがサポートするモデルの1つであることに注意してください。
また、2つの特別なヘッダー、anthropic-versionとanthropic-betaが必要であることに注意してください。
設定されたモデルでweb fetchツールを有効にするには、リクエストボディのtools配列に以下の項目を追加する必要があります:
{
"type":"web_fetch_20260910",
"name":"web_fetch"、
"max_uses":5
}typeと nameフィールドが重要で、max_usesはオプションで、1回の繰り返しでツールを何回呼び出せるかを定義します。
<YOUR_ANTHROPIC_API_KEY>プレースホルダーを実際のAnthropic APIキーに置き換えてください。そして、リクエストを実行すると、以下のようなものが得られます:
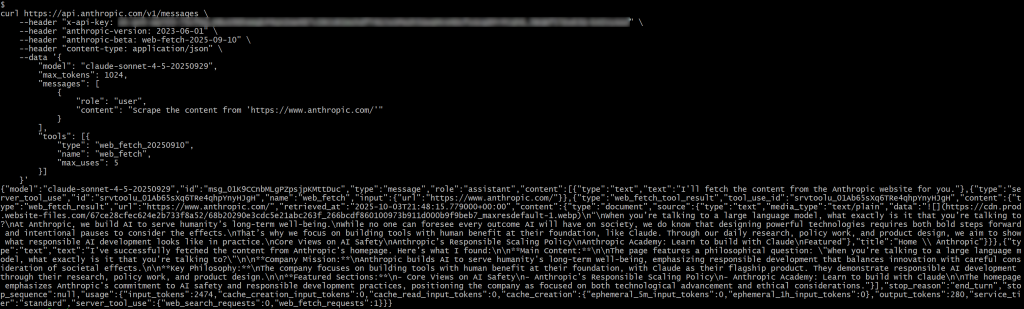
レスポンスには
{"type": "server_tool_use", "id": "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name": "web_fetch", "input":{"url": "https://www.anthropic.com/"}} となります。これは、LLMがweb_fetchツールの呼び出しを実行したことを指定します。
具体的には、このツールによって生成される結果は次のようなものになる:

"大規模な言語モデルと話しているとき、話している相手はいったい何なのでしょうか?
Anthropicでは、人類の長期的な幸福のためにAIを構築しています。
AIが社会にもたらすすべての結果を予見することは誰にもできませんが、強力なテクノロジーを設計するには、大胆な前進と影響を考慮するための意図的な休止の両方が必要であることは分かっています。
だからこそ私たちは、クロードのような人間にとって有益なツールを開発することに重点を置いているのです。日々の研究、政策活動、製品デザインを通じて、責任あるAI開発が実際にどのようなものかを示すことを目指しています。
AIの安全性に関する基本的な考え方
Anthropicの責任あるスケーリングポリシー
Anthropicアカデミー:クロードとビルドすることを学ぶ
特集
これは、指定された入力URLのホームページのMarkdownのようなバージョンを表します。いくつかのリンクは省略され、最初の画像は別として、出力は主にテキストに焦点を当てており、まさにウェブ取得ツールが返すように設計されているため、「一種の」Markdownです。
注:全体として、結果は正確ですが、ツールによる処理中に失われた可能性のあるコンテンツが含まれていないことは確かです。実際、元のページには取得されたものよりも多くのテキストが含まれています。
Anthropic Python APIライブラリの使用
Anthropic Python API ライブラリを使用して、Web フェッチツールを呼び出すこともできます:
# pip install anthropic
Anthropic をインポートする
# AnthropicのAPIキーに置き換えてください。
anthropic_api_key = "<your_anthropic_api_key>"
# Anthropic APIクライアントの初期化
クライアント = Anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# ウェブフェッチツールを有効にしてClaudeへのリクエストを実行する
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024、
messages=[
{
"role":"ユーザー"、
"content":"「https://www.anthropic.com/」からコンテンツをスクレイピングする"
}
],
tools=[
{
"type":"web_fetch_20260910",
"name":"web_fetch"、
"max_uses":5
},
],
extra_headers={
"anthropic-beta":"web-fetch-2026-09-10"
}
)
# AIが生成した結果をターミナルに表示する
print(response.content)
今回の結果は
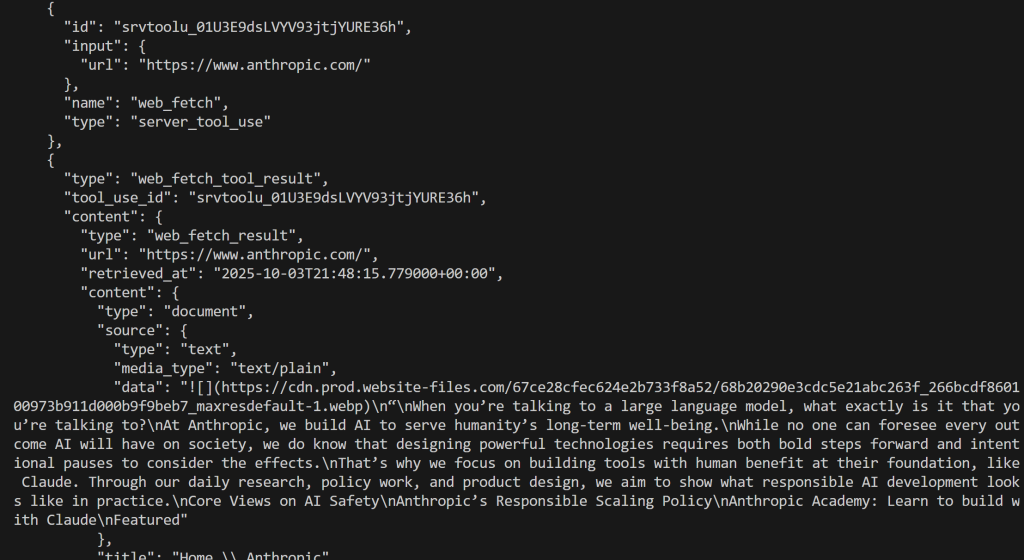
素晴らしい!これは先ほど見たものと同じです。
Bright Dataウェブデータツールの紹介
Bright DataのAIインフラストラクチャーは、AIにウェブを自由に検索、クロール、ナビゲートさせるための豊富なソリューションを提供します。これには以下が含まれます:
- Unlocker API:あらゆる公開URLからコンテンツを確実に取得し、ブロックを自動的に回避し、CAPTCHAを解決します。
- クロールAPI:効率的な推論と推論を行うために、LLMに対応したフォーマットで出力されます。
- SERP API:検索エンジンの検索結果をリアルタイムで収集し、特定のクエリに関連するデータソースを発見します。
- ブラウザAPI:リモートのステルス・ブラウザを使用して、AIがダイナミックなサイトと対話し、エージェントのワークフローを大規模に自動化できるようにします。
Bright Dataのインフラストラクチャーには、ウェブデータ検索のための多くのツール、サービス、製品がありますが、ここではWeb MCPに焦点を当てます。これは、Anthropicが提供するものに直接匹敵する、Bright Data製品の上に構築されたAI統合のためのツールを提供します。Web MCPはクロードMCPとしても機能し、Anthropicのモデルと完全に統合することができます。
60以上の利用可能なツールの中で、scrape_as_markdownツールは比較に最適です。このツールは、コンテンツ抽出のための高度なオプションを使って、1つのウェブページURLをスクレイピングし、結果をMarkdownフォーマットで返すことができます。このツールは、ボット検知やCAPTCHAを使用しているものであっても、あらゆるウェブページにアクセスすることができる。
重要なのは、このツールはWeb MCPのフリー・ティアでも利用できるということだ。つまり、Web MCPはAnthropicのWebフェッチツールと同様のWebデータ検索機能を実現しており、Web MCPは直接比較するのに理想的なのです。
AnthropicウェブフェッチツールとBright Dataウェブデータツールの比較
このセクションでは、AnthropicウェブフェッチツールとBright Dataのウェブデータツールを比較するプロセスを構築します。詳細は以下の通りです:
- AnthropicのPython APIライブラリを通してWebフェッチツールを使用する。
- LangChain MCPアダプタを使用してBright DataのWeb MCPに接続します。
以下の4つの入力URLで同じプロンプトとクロードモデルを使って両方のアプローチを実行します:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
これらは、AIに自動的にコンテンツをフェッチさせたいであろう現実世界のページの良いミックスを表している:ウェブサイトのホームページ、G2の製品ページ、Amazonの製品ページ、そして、LinkedInの公開プロフィールである。G2はCloudflareの保護のため、スクレイピングが難しいことで有名である。
2つのツールのパフォーマンスを見てみよう!
前提条件
このセクションに従う前に、以下を用意しておく必要がある:
- Pythonがローカルにインストールされていること。
- Anthropic APIキー。
- APIキーを持つBright Dataアカウント。
Bright Dataアカウントを設定し、APIキーを生成するには、公式ガイドに従ってください。また、公式Web MCPドキュメントを確認することをお勧めします。
さらに、LangChain統合の仕組みや、Web MCPが提供するツールの知識もあると便利です。
ウェブフェッチツール統合スクリプト
選択した入力URLを通してAnthropicウェブフェッチツールを実行するには、以下のようにPythonロジックを記述します:
# pip install anthropic
Anthropic をインポート
AnthropicのAPIキーに置き換えてください。
Anthropic_api_key = ""
Anthropic APIクライアントを初期化する
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929"、
max_tokens=1024、
messages=[
{
"role":"user"、
"content": f "コンテンツを '{url}' からスクレイピングしてください。
}
],
tools=[
{
"type":"web_fetch_20260910",
"name":"web_fetch"、
"max_uses":5
},
],
extra_headers={
"anthropic-beta":"web-fetch-2026-09-10"
}
)
次に、入力URLに対してこの関数を次のように呼び出します:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Bright Dataウェブデータツール統合スクリプト
Web MCPは、私たちのブログで説明されているように、様々なテクノロジーと統合することができます。ここでは、最も簡単で一般的なオプションであるLangChainとの統合について説明します。
始める前に、ガイドをチェックすることをお勧めします:「LangChain MCP Adapters with Bright Data’s Web MCP” をご覧ください。
この場合、以下のようなPythonスニペットが完成するはずです:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
asyncioをインポートする
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
インポート json
# APIキーで置き換える
anthropic_api_key = "<your_anthropic_api_key>"
bright_data_api_key = "<your_bright_data_api_key>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# エージェントのタスク記述
input_prompt = f"{url}'からコンテンツをスクレイプする"
# エージェント内でリクエストを実行し、レスポンスをストリームし、文字列として返す
output = [] # エージェント内でリクエストを実行し、レスポンスをストリームし、文字列として返す
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
非同期 def main():
# LLMエンジンを初期化する
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# ローカルのBright Data Web MCPサーバインスタンスに接続するための設定
server_params = StdioServerParameters(
command="npx"、
args=["-y", "@brightdata/mcp"]、
env={
"API_TOKEN":bright_data_api_key、
"PRO_MODE":"false" # オプションでProモードを "true "に設定可能
}
)
# MCPサーバーに接続する
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# MCPクライアント・セッションを初期化します。
await session.initialize()
# Web MCPツールを取得する
tools = await load_mcp_tools(session)
# Web MCPを統合したReActエージェントの作成
エージェント = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
これは、Web MCPツールにアクセスできるReActエージェントを定義します。
覚えておいてください:Web MCPには、プレミアム・ツールにアクセスできるProモードがあります。この場合、Proモードを使用する必要はありません。従って、無料層で利用可能なツールだけに頼ることができます。無料ツールにはscrape_as_markdownが含まれており、このベンチマークにはこれで十分である。
簡単に言えば、コストの観点からは、無料モードで Web MCP を使用しても、クロード・モデ ル自体のトークン使用量(これはどちらのシナリオでも同じ)以上のコストはかかりません。基本的に、このセットアップのコスト構造は、API経由でクロードに直接接続する場合と同じです。
ベンチマーク結果
さて、AIのための2つのデータ取得方法を表す2つの関数を、以下のようなロジックで実行します:
# ベンチマーク結果の格納場所
ベンチマーク結果を格納する場所
# 2つのアプローチをテストする入力URL
urls = [
"https://www.anthropic.com/"、
"https://www.g2.com/products/bright-data/reviews"、
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/"、
"https://it.linkedin.com/in/antonello-zanini"
]
# 各URLをテストする
for url in urls:
print(f "Testing the two approaches on the following URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = { { "url": url
"url": url、
"anthropic":{
"execution_time": anthropic_end_time - anthropic_start_time、
"output": anthropic_response.to_json()
},
"bright_data":{
"execution_time": bright_data_end_time - bright_data_start_time、
「出力": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# ベンチマークデータのエクスポート
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
結果は以下の表にまとめられます:
| Anthropicウェブフェッチツール | 明るいデータ ウェブデータツール | |
|---|---|---|
| Anthropicホームページ | ✔️ (部分的なテキスト情報) | ✔️ (Markdownによる全情報) |
| G2レビューページ | ❌ (ツールは10秒後に失敗しました) | ✔️ (ページの完全なMarkdownバージョン) |
| アマゾンの商品ページ | ✔️ (部分的なテキスト情報) | ✔️ (ページの完全なMarkdownバージョン、またはProモードの構造化JSON製品データ) |
| LinkedInのプロフィールページ | ❌ (ツールはすぐに失敗しました) | ✔️ (ページの完全なMarkdownバージョン、またはProモードの構造化JSONプロフィールデータ) |
お分かりのように、AnthropicウェブフェッチツールはBright Dataウェブデータツールよりも効果が低いだけでなく、機能した場合でも完全な結果が得られません。
Anthropicツールは主にテキストに焦点を当てますが、scrape_as_markdownのようなWeb MCPツールはページの完全なMarkdownバージョンを返します。さらに、web_data_amazon_productのようなProツールを使えば、Amazonのような人気サイトから構造化データフィードを取得することができる。
全体的に、Bright Dataのウェブデータツールは、精度と実行時間の両面で明らかに勝っています!
まとめ:比較表
| Anthropicウェブフェッチツール | Bright Dataウェブデータツール | |
|---|---|---|
| コンテンツの種類 | ウェブページ、PDF | ウェブページ |
| 機能 | テキスト抽出 | コンテンツ抽出、ウェブスクレイピング、ウェブクローリングなど |
| 出力 | 主にプレーンテキスト | Markdown、JSON、その他のLLM対応フォーマット |
| モデルの統合 | 特定のクロードモデルでのみ動作 | あらゆるLLMと70以上のテクノロジーと完全に統合 |
| JavaScriptレンダリングサイトのサポート | ❌ | ✔️ |
| アンチボットバイパス/CAPTCHA処理 | ❌ | ✔️ |
| 堅牢性 | ベータ | プロダクション・レディ |
| バッチリクエストのサポート | ✔️ | ✔️ |
| エージェントの統合 | クロードソリューションのみ | ✔️ (MCP または公式 Bright Data ツールをサポートするAI エージェント構築ソリューション) |
| 信頼性と完全性 | 部分的なコンテンツ;複雑なページでは失敗する可能性あり | 完全なコンテンツ抽出。ボット対策が施された複雑なサイトやページに対応 |
| コスト | 標準トークンのみ使用 | 無料モードでは標準的なトークン使用のみ。 |
Web MCPとAnthropicテクノロジーおよびClaudeモデルの統合については、以下のガイドを参照してください:
結論
この比較ブログポストでは、AnthropicウェブフェッチツールがBright Dataが提供するウェブデータ検索とインタラクション機能に対してどのようにスタックするかを見ていただきました。特に、Anthropicツールの実際の使用例と、Bright DataのWeb MCPと対話する同等のLangChainエージェントを使用したベンチマーク比較について学びました。
ブライトデータのツールは、様々なユースケースやシナリオをサポートすることができる、AIに対応した製品やサービスを提供しています。
今すぐBright Dataのアカウントを無料で作成し、AIのためのウェブデータツールをお試しください!






