
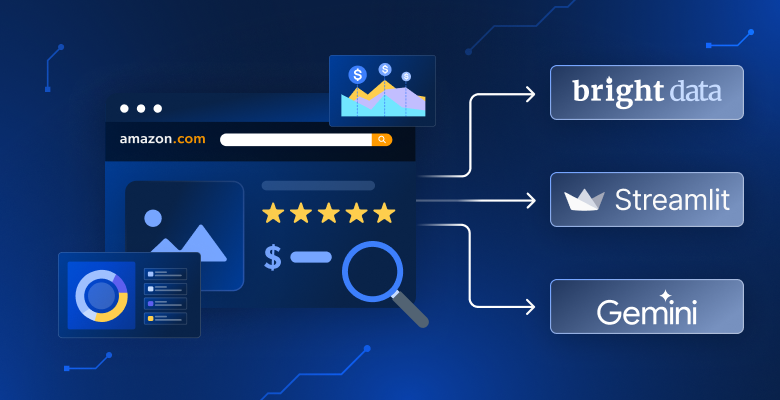
Amazonで製品を手動比較するのに疲れていませんか?検索結果についてAIに質問したいですか?価格や評価順だけの分析では物足りないですか?このチュートリアルでは、23のAmazonマーケットプレイスから検索し、AIで結果を分析し、インタラクティブなダッシュボードでインサイトを提供するAmazon製品分析ツールを構築します。
構築する内容
このガイドの終わりまでに、Amazon商品データを取得し、AIによる洞察を備えた閲覧しやすいダッシュボードに整理する機能的なWebアプリを構築します。
コア機能とユーザーワークフロー
動作の流れ:
- 検索とデータ収集。23のAmazonマーケットプレイス(米国、ドイツ、日本など)から1つを選択し、「ワイヤレスヘッドフォン」などの商品キーワードを入力します。アプリはBright DataのWebスクレイパーAPIを使用して商品情報を収集します。
- 整理された結果表示。データはタブベースのシンプルなインターフェースで提示されます:
- 推奨機能:カスタムスコアリングアルゴリズム(評価・レビュー数・割引率を統合)でランク付けされた商品を3カテゴリー(「総合ベストバリュー」「最高評価」「最良のディール」)で閲覧。
- 市場分析。価格分布や評価パターンのインタラクティブチャートで製品動向を把握。
- AIアシスタント。平易な英語で質問可能(例:「100ドル以下の最高評価製品は?」)。AIが現在の検索結果を分析し、製品引用付きで回答を提供。
- 商品結果。完全なデータセットを閲覧・並べ替えし、CSV形式でエクスポートして詳細分析が可能です。
アプリの機能を確認したところで、これを実現する技術を見ていきましょう。
技術スタックとプロジェクトアーキテクチャ
当アプリは、データ処理、AI、ウェブ開発における各コンポーネントの特性を考慮して選定された、Pythonベースの最新スタックを採用しています。
| コンポーネント | 技術 | 目的 |
|---|---|---|
| データソース | Bright Data Amazon スクレイパー API | 信頼性の高い、企業規模のAmazonデータ収集を実現。プロキシ管理やCAPTCHAの解決の手間を省きます。 |
| フロントエンド | Streamlit | Pythonのみを使用して、インタラクティブで美しいWebダッシュボードを迅速に構築。 |
| AI統合 | Google Gemini | 自然言語によるインサイト、データ要約、AIアシスタント機能を提供。 |
| データ処理 | Pandas | すべてのデータクリーニング、変換、分析の基盤。 |
| 数学演算 | NumPy | 値スコアリングアルゴリズムと統計計算。 |
| 可視化 | Plotly | ユーザーが探索できる、リッチでインタラクティブなチャートやグラフ。 |
| HTTP(S) およびリトライ | リクエスト+粘り強さ | 外部APIとの堅牢で回復力のある通信。 |
プロジェクトアーキテクチャ
プロジェクトはモジュール構造で構成され、関心事の明確な分離を確保し、コードの保守性と拡張性を高めています。
├── streamlit_app.py # メイン Streamlit アプリケーションのエントリポイント
├── requirements.txt # プロジェクト依存関係
├── .env # API キーと環境変数 (非公開)
└── amazon_analytics/ # コアアプリケーションロジックモジュール
├── __init__.py # パッケージ初期化
├── api.py # Bright Data API統合
├── data_processor.py # データクリーニング、正規化、特徴量エンジニアリング
├── shopping_intelligence.py # 製品推薦およびスコアリングエンジン
├── gemini_ai_engine.py # Geminiを用いたAI分析およびプロンプトエンジニアリング
├── ai_engine_interface.py # AIエンジンインターフェースの抽象化
├── ai_response.py # 標準化されたAI応答オブジェクト
└── config.py # 設定管理アーキテクチャが明確になったところで、開発環境を整えましょう。
前提条件
コーディングを始める前に、以下の準備が整っていることを確認してください:
- Python 3.8以上。未インストールの場合、公式Pythonサイトからダウンロードしてください。
- Bright Dataアカウント。 AmazonスクレイパーAPIにアクセスするにはAPIキーが必要です。無料トライアルに登録してAPIキーを生成してください。
- Google APIキー。Gemini AIモデルの利用に必須です。Google AI Studioから生成できます。
- 基礎知識。Python、Pandas、およびWeb APIの概念に関する知識があると役立ちます。
これらが揃ったら、プロジェクトの設定を進めましょう。
ステップ1 – 開発環境のセットアップ
まず、プロジェクトリポジトリをクローンし、依存関係を分離するための仮想環境を作成し、必要なパッケージをインストールします。
インストール
ターミナルを開き、以下のコマンドを実行してください:
# リポジトリのクローン
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# 仮想環境の作成と有効化
python -m venv venv
source venv/bin/activate # Windowsの場合: venvScriptsactivate
# 必要なライブラリのインストール
pip install -r requirements.txtAPIキーの設定
次に、プロジェクトのルートディレクトリに.envファイルを作成し、API キーを安全に保管します。
# .envファイルを作成
touch .envテキストエディタで.envファイルを開き、キーを追加します:
BRIGHT_DATA_TOKEN=your_bright_data_token_here
GOOGLE_API_KEY=your_google_api_key_hereこれで環境設定は完了です。コアロジック(データ収集)に進みましょう。
ステップ2 – Bright DataによるAmazon商品データのスクレイピング
アプリの基本は高品質なデータです。Amazonのようなサイトを手動でスクレイピングするのは複雑です。プロキシの管理、異なるページレイアウトへの対応、AmazonのCAPTCHAやブロック機能の回避方法を見つける必要があります。
BrightDataのAmazon WebスクレイパーAPIは、こうした複雑さをすべて抽象化します。以下を提供します:
- エンタープライズレベルの信頼性。195カ国にまたがる1億5000万以上の倫理的に調達されたレジデンシャルプロキシIPネットワークを基盤とし、一貫した中断のないアクセスを保証します。
- インフラ管理の手間ゼロ。自動IPローテーション、CAPTCHAの解決、プロキシ管理をバックエンドで代行。
- 包括的な構造化データ。ASIN、価格、評価、レビュー、販売者情報、商品説明、画像、在庫状況など、商品ごとに20以上のデータポイントを含むクリーンで構造化されたJSONデータを提供。
- 費用対効果の高い価格設定。1レコードあたり0.001ドルからの従量課金モデルで、あらゆる規模のプロジェクトに拡張可能です。
API統合(api.py)
api. py内のBrightDataAPIクラスがAPIとの全やり取りを処理します。トリガー-ポーリング-ダウンロードのワークフローを採用しており、長時間実行される可能性のあるスクレイピングジョブに最適です。
`trigger_search`メソッドがスクレイピングジョブを開始します。tenacityライブラリの `@retry`デコレータの使用に注意してください。これはリクエストが失敗した場合、指数関数的バックオフで自動的に再試行することで耐障害性を追加します。
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/データセット/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""新しいスクレイピングジョブをトリガーし、スナップショットIDを返します。"""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]検索をトリガーした後、wait_for_resultsメソッドはジョブが完了するまでAPIをポーリングし、その後データをダウンロードします。これにより、待機中のアプリのフリーズを防ぎ、無限ループを回避するためのタイムアウトも含まれています。
信頼性の高いデータ収集が整った後、次のステップはこの生データをクリーンアップし、リッチ化することです。
ステップ3 – データ処理パイプラインの構築
あらゆるソースからの生データは、分析に最適な形式であることは稀です。data_processor.py内のDataProcessorクラスは、スクレイピングしたAmazonデータからクリーニング、正規化、新特徴量のエンジニアリングを行い、AIおよび可視化レイヤーに利用可能な状態にします。データ処理のより広範な概要については、Pythonを用いたデータ分析ガイドを参照してください。
インテリジェントな価格パース
eコマースデータにおける大きな課題は、国際的なフォーマットの処理です。例えば、ドイツでは価格が「1.234,56」と表記される一方、米国では「1,234.56」となります。parse_float_locale関数は、こうしたバリエーションをインテリジェントに処理します。
# amazon_analytics/data_processor.py (可読性向上のため簡略化)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""国際的な数値表記形式に対応した堅牢な浮動小数点解析器"""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# 最後の位置から小数点区切りを判定
if s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # 欧州形式
else:
s = s.replace(',', '') # 米国形式
elif has_comma:
# カンマが千の区切り記号か小数点か確認
if re.search(r",d{3}$", s):
s = s.replace(',', '') # 千の区切り記号
else:
s = s.replace(',', '.') # 小数点
return float(s)
return Noneカスタム値スコアリングアルゴリズム
ユーザーが最適な商品を素早く見つけられるよう、カスタム値スコアを作成しました。この複合指標は複数の要素を単一の分かりやすいスコアに統合します。
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10)
-> float:
"""品質、ソーシャルプルーフ、取引価値に基づいて複合的な価値スコアを計算します。"""
score = 0.0
# 商品品質(評価)に40%の重み付け
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# ソーシャルプルーフ(評価数)に30%の重み付け
if num_ratings and num_ratings >= min_reviews:
# 過度に人気の高い商品が支配的にならないよう対数スケール化
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30% 割引率(ディール価値)の重み付け
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # 最大50%割引
score += discount_score * 0.3
return round(score, 2)このアルゴリズムは、品質(評価)、社会的証明(レビュー数)、取引価値(割引)のバランスを取り、製品の魅力を包括的に測定します。
データがクリーン化・強化されたので、AIエンジンに投入してより深い洞察を得られます。
ステップ4 – GeminiによるAI統合でスマート分析を実現
ここでアプリは真に知能化されます。GoogleのGemini AIを用いて処理済みデータを分析し、ユーザー質問に回答します。LLMの主要課題は幻覚現象(ソースデータに存在しない事実を創作すること)です。当社のGeminiAIEngineはこの防止を目的として設計されています。
# amazon_analytics/gemini_ai_engine.py (チュートリアル明瞭化のため大幅に簡略化)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""全データコンテキストを含めることで幻覚耐性のあるプロンプトを生成"""
# 注:実際の実装では、20以上の商品属性に対する詳細なフィールドマッピング、
# 型変換、NaN処理が含まれます
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating': float(row.get('rating', 0)) if pd.notna(row.get('rating')) else 0,
'num_ratings': int(row.get('num_ratings', 0)) if pd.notna(row.get('num_ratings')) else 0,
# ... 適切な型処理を施した追加フィールド
}
products_data.append(product)
return f"""あなたは高度な推論能力を持つAmazon商品分析のエキスパートです。
ゼロ幻覚ルール:
1. いかなる商品情報も創作・捏造しないこと
2. 明示的に提供されたデータのみを使用すること
3. 情報が欠落している場合は「この情報は利用できません」と明記すること
4. 検証のため常に具体的な商品ASINを引用すること
5. 実際のデータに基づき、推論を用いて価値ある洞察を提供する
推論能力:
- 価格、評価、レビュー、機能を分析して製品を比較する
- 価格と評価の関係を考慮し、コストパフォーマンスに優れた製品を特定する
- 評価の質とレビュー数を評価し、製品の信頼性を判断する
- 初期価格と最終価格を比較し、お得な取引を検出する
ユーザークエリ: {user_query}
利用可能な製品データ({len(df)}件):
{json.dumps(products_data, indent=2)}
推論を用いてこのデータを分析し、有益で正確な洞察を提供してください。検証のため具体的なASINと数値を含めてください。"""主な幻覚防止技術:
- 完全なデータ包含。推測の余地を残さず、全ての製品情報をAIに提供。
- 境界の明示。AIが実行可能/不可能な事項に関する明確なルール。
- ASIN引用。検証のためにAIが特定製品を参照することを強制。
- 構造化されたデータ形式。JSON形式によりAIのデータパースを確実化。
このプロンプト設計手法により、AIは信頼性の高いデータアナリストへと変貌し、その出力は信頼性と検証可能性を獲得する。
AIエンジンが準備できたので、レコメンデーションシステムを構築できます。
ステップ5 – ショッピングインテリジェンスエンジンの作成
shopping_intelligence.py内の ShoppingIntelligenceEngineは、処理済みデータを用いて3つの主要な推奨事項を生成します:「総合ベストバリュー」、「最高評価」、「ベストディール」。エンジンは高度なフィルタリング基準を適用し、質の高い推奨を保証します。
システムは商品辞書のリストを扱い、各推薦カテゴリごとに特定の品質閾値を持つ別々のヘルパーメソッドを使用します。
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""商品データからショッピングインテリジェンスを生成する。"""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""理由付きで上位商品推薦を生成する"""
try:
# まず有効な商品のみをフィルタリング
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# 専用メソッドで各カテゴリのベスト商品を探す
best_value = self._find_best_value(valid_products)
if best_value and best_value.get('asin') not in used_asins:
picks.append({
'product': best_value,
'reason': '総合的な価値が最高',
'explanation': '品質、価格、顧客レビューのバランスが優れている'
})
used_asins.add(best_value['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': '最高評価',
'explanation': '実績に基づく顧客満足度トップ'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': '最良の取引',
'explanation': '大幅な節約と良質な製品による優れた価値'
})
used_asins.add(best_deal['asin'])
# 必要に応じて残りの枠を品質の良い商品で埋める
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': '品質重視',
'explanation': '品質と価値のバランスが良好'
})
return picks[:3]
except Exception:
return []品質フィルタリング手法
各推奨カテゴリには信頼性の高い推奨を保証するための品質閾値が設定されています:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""最高の価値スコアを持つ製品を検索 - 10件以上のレビューが必要"""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""最高評価の製品を検索 - 評価4.0以上かつレビュー50件以上が必要"""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""最良の割引を検索 - 10%以上の割引かつ3.5以上の評価が必要"""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))主要な設計上の決定事項:
- 品質閾値。各カテゴリには最低基準を設定し、質の低い商品の推薦を防止。
- 重複排除。
used_asinsセットにより各商品が1回のみ出現。 - フォールバックロジック。推奨候補が3件未満の場合、次善の値スコアで補完する。
- エラー処理。不正なデータによるクラッシュをtry/catchで防止。
このアプローチにより、ユーザーは単に最初に見つかった製品ではなく、信頼性の高い高品質な推奨を得られます。
これでバックエンドコンポーネントは全て揃いました。これらを統合するユーザーインターフェースを構築しましょう。
ステップ6 – Streamlitによるインタラクティブダッシュボードの設計
最後のピースはユーザーインターフェースで、streamlit_app.pyで処理されます。Streamlitは最小限のコードでリアクティブなWebベースのダッシュボードを構築できます。このアプリは洗練されたタブベースのレイアウトを採用し、リアルタイム進捗追跡と複数のチャートタイプを備えています。
セッション状態とコンポーネントのキャッシュ
本アプリではデータフロー管理に特定のセッション状態変数を使用し、パフォーマンス向上のためバックエンドコンポーネントをキャッシュします:
# streamlit_app.py - セッション状態の初期化
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""バックエンドコンポーネントの初期化とキャッシュ"""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engine進行状況追跡付きインライン検索処理
検索ロジックは詳細な進捗追跡とデータ永続化機能を備え、メインアプリフローに直接組み込まれています:
# streamlit_app.py - 検索処理(簡略化版)
# 進捗追跡付き検索実行
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# 検索トリガー
status_text.text("Amazon検索を開始中...")
snapshot_id = API.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# スマートな進捗更新で結果待ち
status_text.text("Amazonで検索を処理中...")
results = smart_wait_for_results(API, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# 結果を処理
status_text.text("商品を分析中...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# 包括的な結果をセッション状態に保存
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"{elapsed_time:.1f}秒で{len(processed_results)}件の商品が見つかりました!")
progress_bar.progress(100)
except Exception as e:
st.error(f"検索失敗: {str(e)}")複数のインタラクティブな可視化
市場分析タブでは、それぞれ固有のスタイルと注釈を持つ様々なチャートタイプをインラインで作成します:
# streamlit_app.py - 中央値線付き価格分布
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="価格帯",
labels={'x': f'価格 ({currencies.get(current_country_code, "USD")})', 'y': '商品数'},
color_discrete_sequence=['#667eea']
)
# 中央値の線を追加
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="中央値")
st.plotly_chart(fig_price, use_container_width=True)
# 評価と価格の散布図(サイズと色でエンコード)
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="品質 vs 価格",
labels={'final_price': f'価格 ({currencies.get(current_country_code, "USD")})', 'rating': '評価 (星数)'},
color='rating',
color_continuous_scale='Viridis')
st.plotly_chart(fig_scatter, use_container_width=True)
# パーセンタイルマーカー付き価値スコア分布
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="ベストバリュー製品",
labels={'x': '価値スコア (0.0-1.0)', 'y': '製品数'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="中央値")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75パーセンタイル")
st.plotly_chart(fig_value, use_container_width=True)高度なチャート機能
ダッシュボードにはビジネスインテリジェンスを活用した高度な可視化機能が含まれます:
- 価格ヒストグラム。市場ポジショニングのための中央値と四分位点マーカー付き。
- 評価散布図。サイズはレビュー数を、色は評価の質を示します。
- 順位円グラフ。検索順位分布を表示(1-5位、6-10位、11-20位、21位以上)。
- 価格帯棒グラフ。商品を予算/バリュー/プレミアム/ラグジュアリー層に分類。
- 割引分析。実質的な割引と不当な価格設定を識別。
この包括的なアプローチにより、実用的な市場洞察を提供するプロフェッショナルな分析ダッシュボードが構築されます。
結論
エンタープライズレベルのデータ収集、高度なAI、インタラクティブなデータ可視化を活用したAmazon製品分析ツールの構築に成功しました。本プロジェクトの完全なソースコードはGitHubで公開されており、自由に参照・カスタマイズできます。
以下の手法を習得しました:
- Bright DataのウェブスクレイパーAPIを使用して、大規模なAmazonデータを確実にスクレイピングする方法
- 複雑な実世界のデータ課題を処理する堅牢なデータ処理パイプラインの実装
- 信頼性の高い分析を実現するGoogle Geminiを用いた幻覚防止AIアシスタントの設計
- StreamlitとPlotlyを用いた直感的でインタラクティブなユーザーインターフェースの構築
このプロジェクトは、膨大なウェブデータを実用的なビジネスインテリジェンスに変換する必要があるあらゆるアプリにとって強力なテンプレートとなります。ここから、専用のAmazon価格トラッカーを構築したり、他のデータソースを統合したりと、拡張が可能です。
eコマースデータの世界は広大です。事前収集済みで即利用可能なデータセットが必要な場合は、Bright Dataのマーケットプレイスで多様な選択肢を探索してください。





