

最新のデータプロジェクトでは、データベースやアプリケーション間を移動しても情報が意味を失わないように、システム間でフィールドやレコードの位置を合わせるデータマッピングが行われている。かつては手作業で行われていたデータマッピングは、現在ではAIの恩恵を受けています。このガイドでは、AIがデータマッピングをどのように変えるのか、その背後にある重要なテクニック、そして公開ウェブデータを分析可能なデータセットに変える方法を探ります。
データマッピングとは何か?
データ・マッピングとは、データ・フィールドがどのように対応しているかをシステムに伝えることである。例えば、あるデータベースの顧客のEメールは、別のデータベースのEメールアドレスにマッピングされる。適切なマッピングを行わないと、システム間で転送されたデータがコンテキストを失ったり、重複を引き起こしたりする可能性がある。マッピングは、統合、移行、分析に不可欠である。データを新しいツールやウェアハウスに移行する際、すべての値が正しい場所に配置されるようにするためだ。
しかし、従来のマッピングは時間がかかり、エラーが発生しやすい。大企業では、データは何百もの異なるソースとフォーマットで存在します。チームはしばしば、カスタムスクリプトを書いたり、複雑なETLツールを使ったりして、手作業で各フィールドを照合する必要がある。この方法では拡張性がなく、プロジェクトに数カ月かかることもあり、ヒューマンエラーもよく発生する。
構造化されていないHTMLページ、一貫性のないフィールド名、乱雑なフォーマットなど、ウェブデータを扱う場合の課題はさらに大きくなります。質の低いソース・データは、AIツールがいかに高度であろうと、マッピング結果の悪さにつながります。
AIによるデータマッピングの変革
AIを活用したデータマッピングでは、機械学習と自然言語処理を使用して、ソースとターゲットのスキーマを分析し、フィールド名とコンテキストを解釈し、過去のマッピングから学習して、手作業によるフィールドコーディングを必要とする代わりに、正確なマッチングを提案します。
AIは、cust_ID、customerID、customer_idが同じ概念を表すことを認識します。プラットフォームはデータ型の手がかりを検出し、それに応じてターゲット・フィールドを提案するため、マッピング作業が数時間から数分に短縮される。
AIデータマッピングの主な利点は以下のとおりです:
- スピードと効率。マッピングと変換のセットアップが自動化され、手作業が軽減されます。
- 正確性と学習。システムは、あなたのaccept/rejectの選択から学習し、時間の経過とともに提案を改善します。
- スケーラビリティ。AIマッピングは、大規模で複雑なデータセットを処理します。データ量と種類が増加しても、最新のツールは複数のスキーマとソースを同時に分析できます。
- 適応性。静的なスクリプトとは異なり、AIマッピングは変化に適応します。新しいフィールドやフォーマットが出現すると、AIはコンテキストやユーザーからのフィードバックから関係を推測します。システムは組織のデータ・パターンを学習するため、時間の経過に伴う人的修正が少なくて済みます。
- データ品質とガバナンスの向上。自動マッピングにより、一貫性とガバナンスが強化されます。フィールドの整合性を文書化することで、AIツールはデータの系統を維持し、機密データのルーティングを追跡することでコンプライアンスをサポートします。
- コストの削減。これらの利点により、手作業の削減、再作業を必要とするエラーの削減、プロジェクトの早期完了が実現し、コストが削減されます。
AIデータマッピングを支える技術
最新のデータマッピングには、いくつかのAI技術が活用されています:
- 自然言語処理(NLP)。自然言語処理(NLP)。NLPは、フィールド名やラベルの意味を解釈し(例:メールアドレスと e-mail)、ドキュメントを処理してコンテキストを抽出することができるため、名前が大きく異なる場合でもマッピングをより強固なものにする。
- 機械学習モデル。MLモデルは、学習したパターンに基づいてマッピングを分類・予測する。もし多くのデータセットがaccount_managerを請求システムのsales_repにマッピングすることを示していれば、モデルは次回その提案を優先します。
- ナレッジグラフ。プラットフォームによっては、システム間のエンティティや関係をリンクする内部ナレッジグラフを保持しています。グラフは、あるシステムの顧客IDが別のシステムの口座番号と同じであり、両方が請求参照に関連していることを表すことができ、間接的なマッピングを推論し、スキーマの一貫性を保つのに役立ちます。
- ディープラーニングとコンピュータビジョン。非構造化または半構造化ドキュメント(PDF、スキャンしたフォームなど)に対して、ディープラーニングはテキスト、テーブル、キーと値のペアを抽出し、構造化されたターゲットにマッピングすることができます。
- セマンティック・マッチングとスキーマ・アライメント。最新のツールは、スキーママッチングアルゴリズム(グラフ/オントロジーアライメントを含む)を統合し、字句、構造、インスタンスベースのエビデンスに加え、利用可能な場合はドメイン辞書を組み合わせて、対応関係を見つけます。
AIデータマッピングの仕組み(ステップバイステップ)
AIデータマッピングツールは、次のようなワークフローを踏む:
- データソースを接続する。ツールは、ソースおよびターゲット・システム(データベース、ファイル、API)に接続し、フィールド名、データタイプ、サンプル値、およびメタデータを検査し、NLPを使用してラベル/説明を読み取り、一致を提案する前にコンテキストを理解します。
- マッチの分析と提案名前/位置と意味的類似性による自動マッピングを適用し、多くの場合、信頼スコアとともに候補ペアを生成します。例えば、country_codeと CountryIDをマッピングする。型の不一致(”Qty: 12 “のようなテキスト対数値ターゲット)が検出された場合、最終的なマッピングの前に解析/キャスト変換を提案します。
- レビューと絞り込み。信頼性の高い一致は自動承認され、あいまいな一致はスチュワードによるレビューのためにフラグが立てられます。受け入れ/拒否のアクションは監査用にキャプチャされ、今後の提案の改善に使用されます。
- AIはフィードバックから学習します。システムはあなたの選択(あなたの組織の記憶)を内部化し、類似のデータセットは次回より速くマッピングされ、推奨はあなたの命名規則とポリシーに沿うようになります。
- 変換を展開します。マッピングが承認されると、プラットフォームは必要な変換(キャスト、連結、標準化)を生成して運用し、スケジューリング、モニタリング、リネージキャプチャを備えた管理されたETL/ELTパイプライン内で実行します。
マッピング可能なデータをウェブから取得
AIが効果的にデータをマッピングする前に、クリーンで構造化された入力が必要です。ウェブデータは、一貫性のないフォーマット、ネスト化されたHTML、変化するページ構造など、しばしば乱雑に扱われます。マッピング・プロジェクトを成功させるには、適切なウェブ・データ収集が重要になります。
Bright Dataは、AI用にウェブデータを抽出・準備するプラットフォームを提供し、マッピングをよりクリーンな入力から開始します:
- AIウェブスクレーパーページ構造を特定し、最新のサイトから構造化データを抽出します。APIまたはWebhook経由でJSON/CSVを配信します。
- データセット(構築済み)。文書化されたスキーマ(例:Amazon商品)を持つ既製のリフレッシュされたデータセット。
- プロキシと ウェブアンロッカー。ブロックやCAPTCHAを処理することで、公開ウェブサイトへの信頼性の高いアクセスを実現します。
- ブラウザAPIと サーバーレス関数。プログラミング可能な、ホストされたスクレイピングワークフローを実行し、マッピング前に複数ステップの収集を行います。
- 統合。スクレイピングやデータセットの出力をAIアプリフレームワーク(LangChain、LlamaIndexなど)やストレージターゲットに接続します。
収集と最初の構造化をBright Dataが行うことで、マッピングと変換に集中することができます。
簡単な例 – Amazon商品データセットのマッピング
Amazonの商品データを使った実用的な例を見てみましょう。面倒な商品ページを手作業でスクレイピングするのではなく、AIマッピングに最適なクリーンで構造化されたレコードを提供するBright DataのAmazon Product Datasetを使用します。
このデータセットには、タイトル、ブランド、初期価格、通貨、在庫などのフィールドが含まれています。サンプルのレコードは以下のようになる:
{
"title":"Hanes Girls' Cami Tops, 100% Cotton Camisoles..."、
"brand":"Hanes Girls 7-16 Underwear"、
"initial_price":10.00,
「通貨":「USD"、
"availability": true
}ターゲット分析スキーマには、ProductName、Brand、PriceUSD、InStockが必要だとします。AIマッピングツールは以下の変換を提案します:
- title→ProductName(信頼度の高いセマンティックマッチ)
- ブランド→ブランド(完全一致)
- initial_price+currency→PriceUSD(フィールドを組み合わせ、USDに正規化)
- 在庫状況→在庫あり(ブーリアン変換)
マッピングと変換後
{
"ProductName":"ProductName": "Hanes Girls' Cami Tops, ..."、
"ブランド":"Hanes Girls 7-16 Underwear"、
"PriceUSD":10.00,
「在庫あり": true
}ソース・データがクリーンで一貫したフォーマットであったため、AIマッピング・ツールは自動的にほとんどのアライメントを提案した。
カスタム要件については、AI Web Scraperを使用して特定のAmazonフィールドを好みのフォーマットに抽出し、それらをターゲットスキーマにマッピングすることができます。
注意– 人間をループの中に入れておくこと。AIマッピングは、データの専門知識の代わりではなく、インテリジェントなアシスタントとして最適に機能する。重要なマッピング、特に機密性の高いフィールドや規制遵守のためのマッピングは常に検証してください。
自然言語クエリによる高度なマッピング
事前に構築されたフォーマットでは存在しないデータを調査してマッピングする必要がある場合があります。Bright DataのDeep Lookupでは、自然言語クエリを使用してカスタムデータセットを生成し、その結果をターゲットスキーマにマッピングできます。例えば
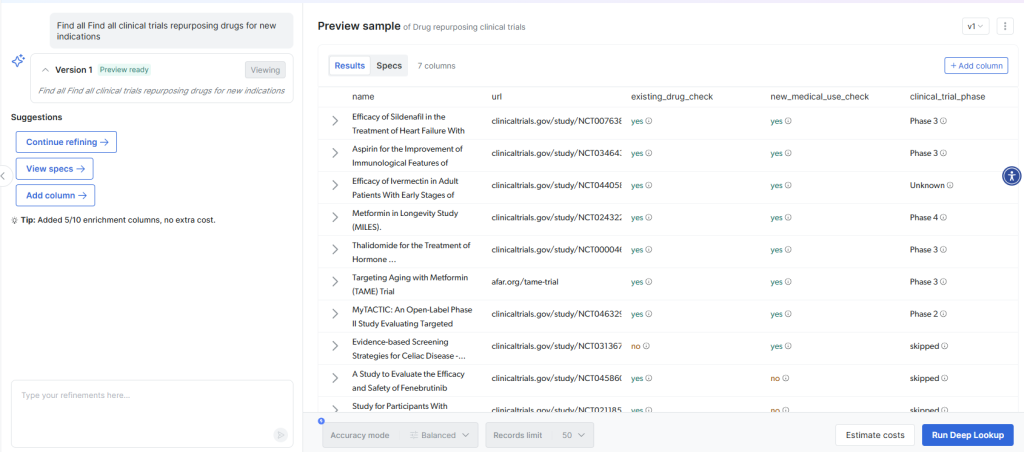
Deep Lookupは、ウェブデータを検索して一致する企業を見つけ、マッピングの準備が整った構造化された結果を返します:

これは、自然言語クエリから直接マッピング可能なデータを提供することで、従来の調査→構造化→マッピングのワークフローを排除します。
結論
AIデータマッピングは、企業が分析およびAIワークフローに公開ウェブデータを統合する方法を変革している。成功はマッピングの前に始まります。高品質で構造化されたソースデータはマッピングの精度を高め、手作業を減らします。
ブライトデータのソリューションが収集と構造化を行うため、お客様はウェブデータを特定のビジネスニーズや分析フレームワークにマッピングすることに集中できます。
クリーンなウェブデータがマッピングプロジェクトに与える影響をお知りになりたいですか?構造化されたマッピング可能なデータセットを迅速に入手するには、弊社までお問い合わせください。





