

ウェブスクレイピングとは、ウェブサイトからデータを収集するプログラム的な手法であり、市場調査、価格監視、データ分析、リード生成など、その用途は無限に広がっています。
このチュートリアルでは、子育てにおける一般的な課題に焦点を当てた実用的なユースケースを検討します:学校から送られてくる情報の収集と整理です。ここでは、宿題の課題と学校給食情報に重点を置きます。
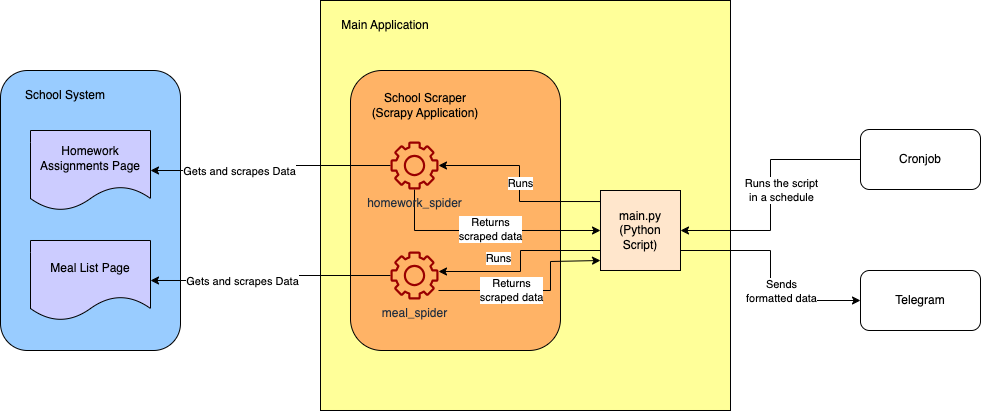
以下は最終プロジェクトの概略アーキテクチャ図です:
前提条件
このチュートリアルを実践するには、以下の環境が必要です:
- Python 3.10以上
- アクティブ化された仮想環境
- Scrapy CLI 2.11.1
- Visual Studio Code
プライバシー保護のため、以下のダミー学校システムウェブサイトを使用します:https://systemcraftsman.github.io/scrapy-demo/website/
プロジェクトの作成
ターミナルでベースプロジェクトディレクトリを作成します(任意の場所に配置可能):
mkdir school-scraper
新しく作成したフォルダに移動し、以下のコマンドを実行して新しい Scrapy プロジェクトを作成します:
cd スクレイパー &
scrapy startproject school_scraper
プロジェクト構造は以下のようになります:
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
前のコマンドは2階層のschool_scraperディレクトリを作成します。内側のディレクトリには自動生成されたファイル群があります:middlewares.py(Scrapyミドルウェアを定義)、pipelines.py(データを変更するカスタムパイプラインを定義)、settings.py(スクレイピングアプリケーションの一般設定を定義)。
最も重要なのは、スパイダーが配置されるspiders フォルダです。スパイダーは特定のサイトを特定の方法でスクレイピングするために利用できる Python クラスです。これらはスクレイピングシステム内の関心事の分離原則に従い、各スクレイピングタスク専用のスパイダーを作成することを可能にします。
まだ生成されたスパイダーが存在しないため、このフォルダは空ですが、次のステップで最初のスパイダーを生成します。
宿題スパイダーの作成
学校のシステムから宿題データをスクレイピングするには、まずシステムにログインし、次に宿題課題ページに移動してデータをスクレイピングするスパイダーを作成する必要があります:
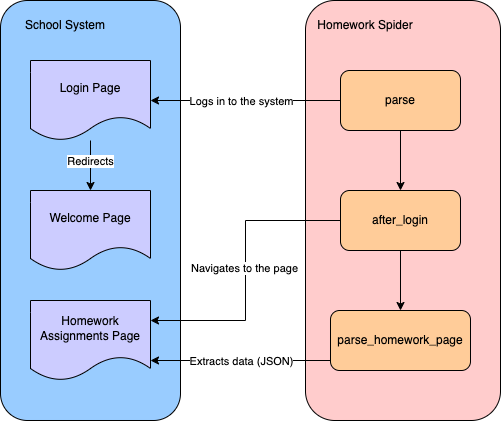
ウェブスクレイピング用のスパイダー作成にはScrapy CLIを使用します。プロジェクトのschool-scraper/school_scraperディレクトリに移動し、以下のコマンドを実行してspidersフォルダ内にHomeworkSpiderという名前のスパイダーを作成します:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html
注意: PythonやScrapy関連のコマンドは、必ずアクティブ化した仮想環境内で実行してください。
scrapy genspider コマンドはスパイダーを生成します。次のパラメータはスパイダー名(例: homework_spider)、最後のパラメータはスパイダーの開始URLを定義します。これにより、systemcraftsman.github.io が Scrapy によって許可されたドメインとして認識されます。
出力は次のようになります:
Created spider 'homework_spider' using template 'basic' in module:
school_scraper.spiders.homework_spider
school_scraper/spiders ディレクトリ下にhomework_spider.py というファイルを作成し、以下のように記述します:
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
クラス名をHomeworkSpider に変更し、クラス名内の冗長なSpider を削除します。parse 関数はスクレイピングを開始する初期関数です。この場合、システムへのログイン処理を行います。
注記:
https://systemcraftsman.github.io/scrapy-demo/index.htmlのログインフォームは、数行の JavaScript で構成されたダミーのログインフォームです。ページが HTML であるため POST リクエストを受け付けず、代わりに HTTP GET リクエストを使用してログインを模倣します。
parse関数を以下のように更新します:
...コード省略...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
ここでは、index.htmlページ内のログインフォームを送信するためのフォームリクエストを作成します。送信されたフォームは定義されたwelcome_page_urlにリダイレクトされ、スクレイピング処理を継続するためのコールバック関数を持つ必要があります。after_loginコールバック関数は後ほど追加します。
他の変数が定義されているクラスの先頭にwelcome_page_url を追加して定義します:
...コード省略...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...コード省略...
次に、クラスのparse関数の直後に after_login関数を追加します:
...コード省略...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...コード省略...
after_login関数は レスポンスステータスが200(成功)であることを確認します。その後、宿題ページに移動し、parse_homework_pageコールバック関数を呼び出します。この関数は次のステップで定義します。
他の変数が定義されているクラスの先頭にhomework_page_url を追加して定義します:
...コード省略...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...コード省略...
クラス内の after_login関数の後にparse_homework_page関数を追加:
...コード省略...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...コード省略...
parse_homework_page関数は、レスポンスステータスが200(成功)かどうかを確認します。その後、HTMLテーブルで提供される宿題データをパースします。
この関数はHTTP 200コードを確認した後、XPathを使用して各データの行を抽出します。各行を抽出した後、関数はデータを反復処理し、プライベート関数_get_itemを使用して特定の項目を抽出します。この関数はSpiderクラスに追加する必要があります。
_get_item関数は以下のようになります:
...コード省略...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
_get_item は行番号と列番号と共に XPath を使用して各セルの内容を取得します。セルに複数の段落がある場合、関数はそれらを反復処理し、各段落を追加します。
parse_homework_page関数では date_strの定義も必要です。静的ウェブサイトに存在する日付データである2024年3月12日(12.03.2024)を定義してください。
注記: 実際の運用環境では、ウェブサイトデータが動的であるため、日付は動的に定義する必要があります。
date_str は、他の変数が定義されているクラスの先頭に追加して定義します:
...コード省略...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...コード省略...
最終的なhomework_spider.py ファイルは以下のようになります:
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
school-scraper/school_scraper ディレクトリで、以下のコマンドを実行し、宿題データのスクラッピングが正常に行われることを確認してください:
scrapy crawl homework_spider
他のログの間にスクレイピング結果が表示されるはずです:
...出力省略...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html>
{'MATHS': "数学 解説付きワークブック-6 13ページを解いてください。n", 'ENGLISH': 'リーディングログの100-107ページにある「Manny and His Monster Manners」という物語を読み、物語に基づいて108ページと109ページのアクティビティを完成させてください。nnリーディングログの100-107ページにある "Manny and His Monster Manners"という物語を読み、108ページと109ページの問題を物語に基づいて解いてください。n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO: クローラー終了 (完了)
...出力省略...
おめでとうございます!最初のスパイダーの実装が完了しました。次を作りましょう!
食事リストスパイダーの作成
食事リストページをクロールするスパイダーを作成するには、school-scraper/school_scraper ディレクトリで次のコマンドを実行してください:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html
生成されたスパイダークラスは次のようになります:
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
食事スパイダーの作成プロセスは、宿題のスパイダー作成と非常に似ています。唯一の違いはHTMLスクレイピング対象のページです。
時間を節約するため、meal_spider.py の内容を以下のコードで置き換えてください:
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
meal_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
date_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
key = ""
try:
for row in rows[1:]:
if self._get_item(row, week_no) in data.keys():
key = self._get_item(row, week_no)
else:
data[key] = self._get_item(row, week_no, "n")
finally:
return data
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str
parse関数と after_login関数はほぼ同一であることに注意してください。唯一の違いはコールバック関数parse_meal_pageの名前であり、これは異なるXPathロジックを用いて食事ページのHTMLを解析します。この関数はまた、宿題用に作成されたものと同様の動作をするプライベート関数_get_itemの支援を受けています。
宿題ページと食事リストページではテーブルの使用方法が異なるため、データのパースと処理方法も異なります。
meal_spiderを検証するには、school-scraper/school_scraperディレクトリで次のコマンドを実行してください:
scrapy crawl meal_spider
出力は次のようになります:
...出力省略...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRANnKIRMIZILAHANA SALATAnROKALI GÖBEK SALATAn', 'FRUIT TIME': 'FINDIK& KURU ÜZÜMn'}
2024-03-20 02:44:42 [scrapy.core.engine] INFO: Closing spider (finished)
...出力省略...
注記: データは元のウェブサイトからのものであるため、元の形式を保持するために翻訳は一切行われていません。
データのフォーマット
宿題課題と食事リストページ用に作成したスクレイパーは、JSON形式でデータをスクレイピングする準備が整っています。ただし、プログラムでスパイダーを起動してデータをフォーマットしたい場合もあるでしょう。
Pythonアプリケーションでは通常、main.pyファイルがエントリポイントとして機能し、主要コンポーネントを呼び出してアプリケーションを初期化します。しかしこのScrapyプロジェクトでは、Scrapy CLIがスパイダー実装用の事前構築済みフレームワークを提供し、同じCLI経由でスパイダーを実行できるため、エントリポイントを作成していません。
このシナリオでデータをフォーマットするには、引数を受け取りそれに応じてスクレイピングを行う基本的なPythonコマンドラインプログラムを構築します。
school-scraperプロジェクトのルートディレクトリにmain.pyというファイルを作成し、以下の内容を入力します:
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework":
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal":
process.crawl(MealSpider)
process.start()
print(_prepare_message("MEAL LIST", results[0]))
if __name__ == "__main__":
main()
main.pyファイル にはmain関数が存在し、アプリケーションのエントリポイント関数となります。main.pyを実行すると main メソッドが呼び出されます。main メソッドはargsという配列引数を受け取り、プログラムへの引数送信に使用できます。
main.py はまずargs の値を確認し、ResultsPipeline というパイプラインを定義することで Scrapy クローラーの設定を行います。ご覧の通り、ResultsPipeline はこのファイル内で定義されていますが、パイプラインはpipelines パッケージの下で定義します。
ResultsPipelineは単純に結果を取得し、resultsという配列に追加します。つまりresults配列は、フォーマット済みメッセージを準備するプライベート関数_prepare_messageの入力として使用できます。 これはメイン関数内でスパイダーごとに実行され、args配列の2番目の引数(スパイダータイプを示す)によって区別が可能になります。スパイダータイプがhomeworkの場合、クローラープロセスはHomeworkSpiderを呼び出して起動します。スパイダータイプがmealの場合、クローラープロセスはMealSpiderを呼び出して起動します。
スパイダーが起動すると、注入されたResultsPipelineが results配列にデータを追加します。メイン関数は各スパイダーに対して_prepare_messageを呼び出すことで、出力データのフォーマットを支援できます。
メインプロジェクトディレクトリで、新たに実装したmain.py を以下のコマンドで実行し、宿題課題を取得します:
python main.py homework
出力は次のようになります:
...出力省略...
====HOMEWORK ASSIGNMENTS====
----------------
===MATHS===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===ENGLISH===
リーディングログの100-107ページにある「Manny and His Monster Manners」を読み、物語に基づいて108ページと109ページのアクティビティを完了してください。
Reading Log kitabınızın 100-107 sayfalarındaki "Manny and His Monster Manners" adlı hikayeyi okuyunuz ve 108 ve 109. sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.
----------------
...出力省略...
その日の食事リストを取得するには、Pythonのmain.py mealコマンドを実行してください。出力は次のようになります:
...出力省略...
====食事リスト====
----------------
===朝食===
パンケーキ
クリームチーズ
スズメペニル(水切りチーズ)
カカオ入りヘーゼルナッツクリーム
牛乳
----------------
===昼食===
タルハナスープ
酸味のあるミートボール
パスタ
----------------
===サラダ/デザート===
アイラン
赤キャベツサラダ
ロカ入りレタスサラダ
----------------
===フルーツタイム===
クルミ&干しぶどう
----------------
...出力省略...
ウェブスクレイピングの一般的な障害を克服するためのヒント
おめでとうございます!ここまで進んだあなたは、正式にScrapyスクレイパーを作成しました。
Scrapyでウェブスクレイパーを作成するのは簡単ですが、実装時にはCAPTCHA、IP禁止、セッションやクッキーの管理、動的ウェブサイトなど、いくつかの障害に直面する可能性があります。これらの異なるシナリオに対処するためのヒントをいくつか見ていきましょう:
動的ウェブサイト
動的ウェブサイトは、システム構成、所在地、年齢、性別などの要素に基づいて訪問者に異なるコンテンツを提供します。例えば、同じ動的ウェブサイトを訪問した2人のユーザーが、それぞれに最適化された異なるコンテンツを目にする可能性があります。
Scrapyは動的ウェブコンテンツのスクレイピングが可能ですが、そのために設計されたものではありません。動的コンテンツをスクレイピングするには、Scrapyを定期的に実行するようにスケジュールし、結果を保存して比較することで、ウェブページ上の変化を時間をかけて追跡する必要があります。
特定のケースでは、ウェブページ上の動的コンテンツも静的コンテンツとして扱われることがあります。特に、それらのページが更新されるのがごく稀な場合です。
CAPTCHA
一般的に、CAPTCHAは英数字を含む動的な画像です。ページ訪問者は、検証プロセスを通過するために、CAPTCHA画像から一致する値を入力する必要があります。
CAPTCHAは、ページの訪問者が人間(スパイダーやボットではない)であることを確認し、多くの場合、ウェブスクレイピングを防ぐためにウェブページで使用されます。
ここで使用したダミーの学校システムは CAPTCHA システムを使用していませんが、実際に遭遇した場合には、CAPTCHA をダウンロードし、OCR ライブラリを使用してテキストに変換する Scrapy ミドルウェアを作成することができます。
セッションとクッキーの操作
ウェブページを開くと、そのページシステム内でセッションが開始されます。このセッションはログイン情報やその他の関連データを保持し、システム全体でユーザーを識別します。
同様に、クッキーを使用してウェブページ訪問者に関する情報を追跡できます。ただし、セッションデータとは異なり、クッキーはウェブサイトサーバーではなく訪問者のコンピューターに保存され、ユーザーは必要に応じて削除できます。結果として、クッキーを使用してセッションを維持することはできませんが、データ損失が致命的でない様々な補助的なタスクに使用できます。
ユーザーのセッションを操作したり、クッキーを更新したりする必要が生じる場合があります。Scrapyは、組み込み機能または互換性のあるサードパーティライブラリを通じて、両方の状況に対応できます。
IP禁止
IP禁止(IPアドレスブロック)とは、ウェブサイトが特定の送信元IPアドレスを遮断するセキュリティ手法です。主にボットやスパイダーが機密情報にアクセスするのを防ぎ、人間のユーザーのみがデータにアクセス・処理できるようにするために使用されます。CAPTCHAと並行して、企業はウェブスクレイピング活動を抑止するためにIP禁止を採用しています。
このシナリオでは、学校システムはIP禁止メカニズムを使用していません。しかし、もし実装されていた場合、ウェブサイトのスクラッピングを継続するには、動的IPの使用やプロキシの壁の背後でIPアドレスを隠すなどの戦略を採用する必要がありました。
結論
本記事では、Scrapyを用いてログイン処理とXPathによるテーブルパースを行うスパイダーの作成方法を学びました。さらに、データ制御を強化するためのプログラムによるスパイダー起動手法についても習得しました。
本チュートリアルの完全なコードは、こちらのGitHubリポジトリで公開されています。
Scrapyの機能を拡張しウェブスクレイピングの課題を克服したい方には、Bright Dataがパブリックウェブデータに特化したソリューションを提供します。BrightDataのScrapy統合によりスクレイピング能力が強化され、プロキシサービスでIP禁止を回避、Web UnlockerがCAPTCHAや動的コンテンツの処理を簡素化するため、Scrapyでのデータ収集がより効率的になります。
今すぐ登録し、当社のスクレイピングソリューションについてデータエキスパートにご相談ください。





