

Next.jsサイトのスクラッピング手法に関するこのチュートリアルでは、以下の内容を学びます:
- Nextとは何か、なぜ人気があるのか
- Reactハイデーションの仕組みがNext.jsウェブページのウェブスクレイピングを容易にする理由
- ウェブスクレイピングにReactハイドレーションを活用する方法
さっそく始めましょう!
Next.jsとは何か?その仕組みは?
Next.jsは、サーバーサイドレンダリングおよび静的生成ウェブサイトを構築するためのReact上に構築されたJavaScriptフレームワークです。豊富なAPIと構造化されたアプローチを提供することで、サーバーサイドReactアプリケーションの開発プロセスを簡素化します。
Next.jsは近年大きな人気を獲得し、Statistaによれば最も使用されているWebライブラリの5位となっています。その理由は、使いやすさ、優れたパフォーマンス、Reactとの親和性、充実したドキュメント、そしてコミュニティサポートにあります。多くの大企業やスタートアップがWeb開発にNext.jsを選択するのも当然でしょう。
Next.jsは、サーバー上でデータを取得し、それをReactコンポーネントに渡して事前レンダリングされたHTMLドキュメントを作成するという仕組みで動作します。このプロセスにより、サーバー上でHTMLコンテンツを生成し、それをクライアントに送信することで初期ページ読み込みを高速化するため、パフォーマンスが向上します。
ウェブスクレイピングにおけるReactハイドレーションの活用方法
ハイドレーションはサーバーサイドレンダリングとクライアントサイドレンダリングの橋渡し役です。具体的には、Next.jsが生成したHTMLドキュメントを完全に機能するクライアントサイドReactアプリケーションへ変換するプロセスを指します。
ハイドレーション中(ブラウザがサーバーから返されたHTMLページを読み込んだ後)、Reactはページにインタラクティブ性を追加します。具体的には、サーバー上でレンダリングされたReactコンポーネントに対応するDOMノードにイベントリスナーをアタッチし、状態を処理します。
Reactがプリレンダリングされたページをハイドレーションするために必要な手順は以下の通りです:
- 初期サーバーレンダリング: サーバーが、ページで使用される React コンポーネントの HTML 表現を含む HTML ドキュメントを生成します。
- クライアントサイドJavaScriptの実行: クライアントがHTMLマークアップを受信すると、Reactコードを含むJavaScriptバンドルを実行します。
- 再調整(Reconciliation):Reactはサーバーから返されたHTMLと、動的に生成された仮想DOM表現を比較します。詳細は公式ドキュメントを参照してください。
- ハイドレーション: 両者が同一の場合、Reactは既存のDOMを可能な限り再利用しつつ、イベントハンドラを追加し状態を処理することでレンダリングを完了します。
この操作を実行するには、ReactはサーバーがHTMLドキュメントを生成する際に使用したのと同じデータが必要です。これがNext.jsが生成されたページにプロップスデータを含む特別なDOM要素を追加する理由です。
一部のNext.jsサイトでは、このデータが__NEXT_DATA__IDを持つ<script>要素内に存在します。この特別なDOMノードには、Reactがハイドレーションに使用するJSON形式のデータが以下のように含まれています:
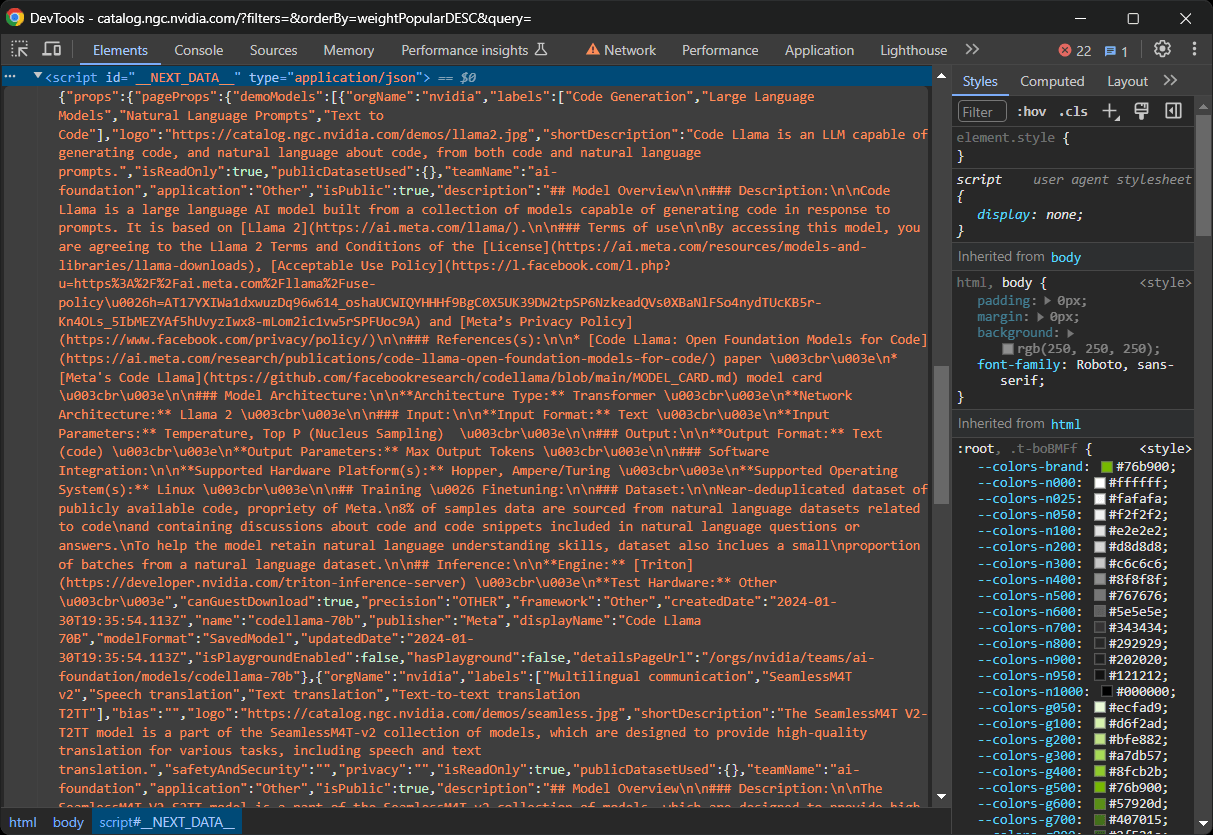
新しいApp Router を利用する最新の Next.js サイトでは、ハイドレーションデータは代わりに複数の<script>ノード内のself.__next_f.push()関数呼び出しに格納されます:
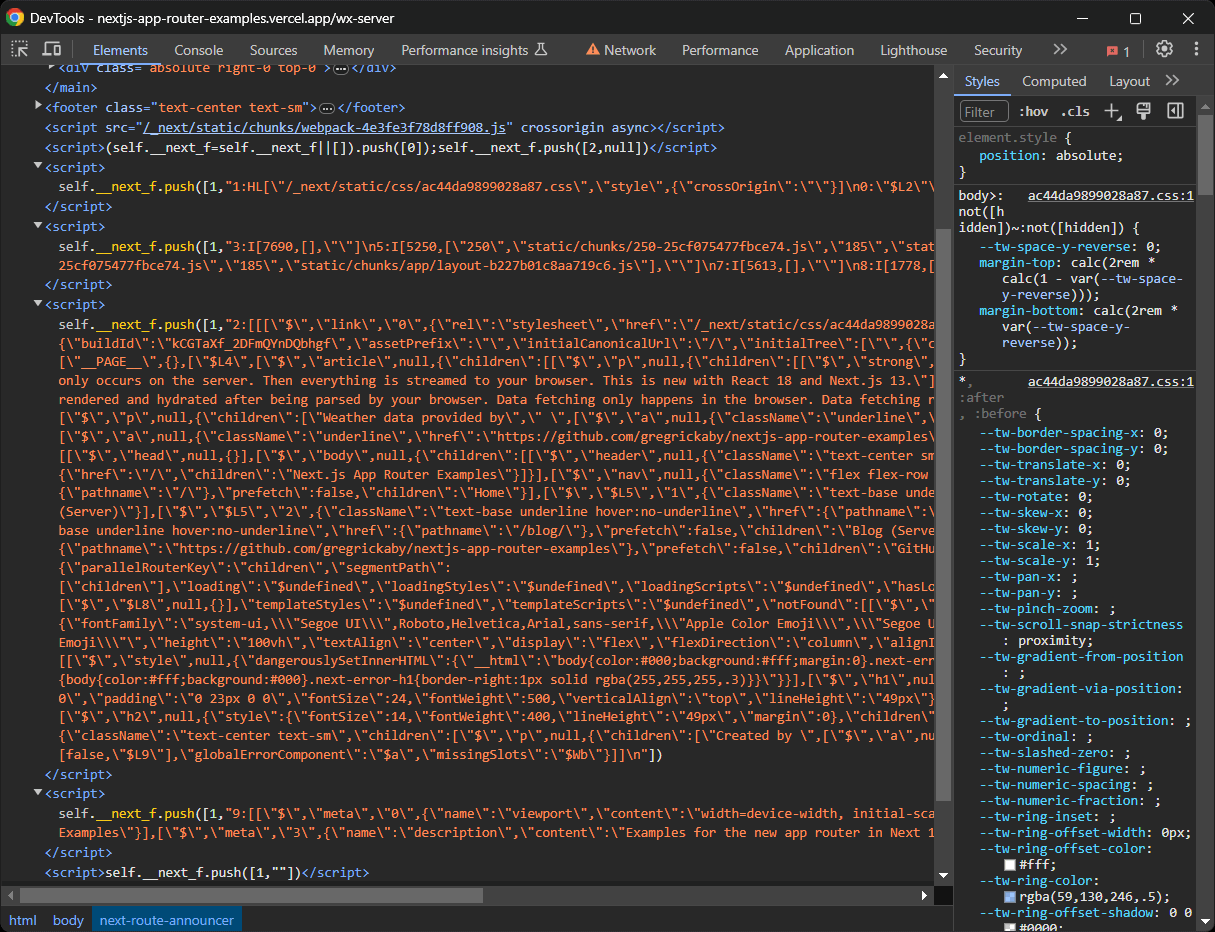
これらのノードには、サイト上に表示されるデータよりもさらに多くの情報が含まれている場合があります。なぜでしょうか? これらのハイドレーション要素には、ページ生成時にサーバーから取得され React コンポーネントに渡される API およびデータベースデータがすべて格納されているからです。ただし、それらのオブジェクトの全属性がコンポーネント内で実際にアクセス・使用されるとは限りません。
さて、Reactが機能するためにそのデータがなぜ必要なのかを理解できたかどうかは問題ではありません。重要なのは、Next.js経由で生成されたウェブページが、レンダリングされるデータを特別なDOMノード内にJSON形式で保持していることです。ご想像の通り、これはNext.jsのウェブスクレイピングに多大な影響を及ぼします!
ハイドレーションデータを通じたNext.jsサイトのスクレイピング
Next.jsで構築されたページからデータを抽出するのは非常に簡単で、スクレイピングスクリプトすら必要ありません。ブラウザのデベロッパーツールだけで十分です。
それでは、Reactハイドレーションを活用してNext.jsサイトを数秒でスクレイピングする方法を見ていきましょう!
__NEXT_DATA__からのデータ抽出
スクレイピング対象ページがNext.jsで構築されていることを確認したと仮定します(確認方法はFAQの質問を参照)。
ブラウザでそのページを開き、右クリックして「要素を検査」を選択し、開発者ツールを開きます。コンソールタブに移動し、以下のJavaScriptを実行して目的の<script>要素を選択します:
const scriptNode = document.querySelector("#__NEXT_DATA__")これにより、querySelector()関数がDOM内のIDが__NEXT_DATA__の要素を選択し、scriptNode変数に代入されます。
コンソールでscriptNodeと入力して Enter を押すと、目的のノードが表示されます:
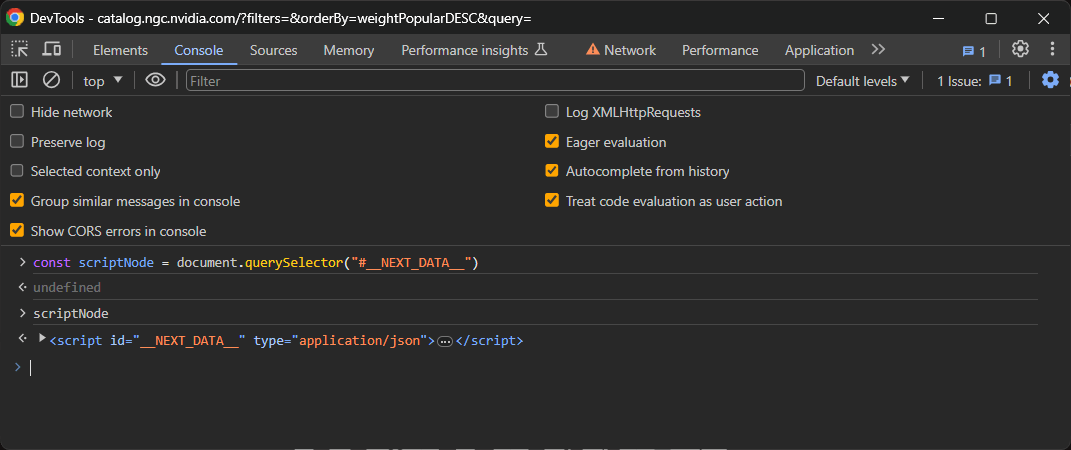
その内部HTMLコンテンツにアクセスし、以下の方法でJSONコンテンツとしてパースします:
const jsonData = JSON.parse(scriptNode.innerHTML)
これで完了です!jsonDataオブジェクトには、ページ上のコンポーネントをレンダリングするためにReactが使用した全データが含まれます:
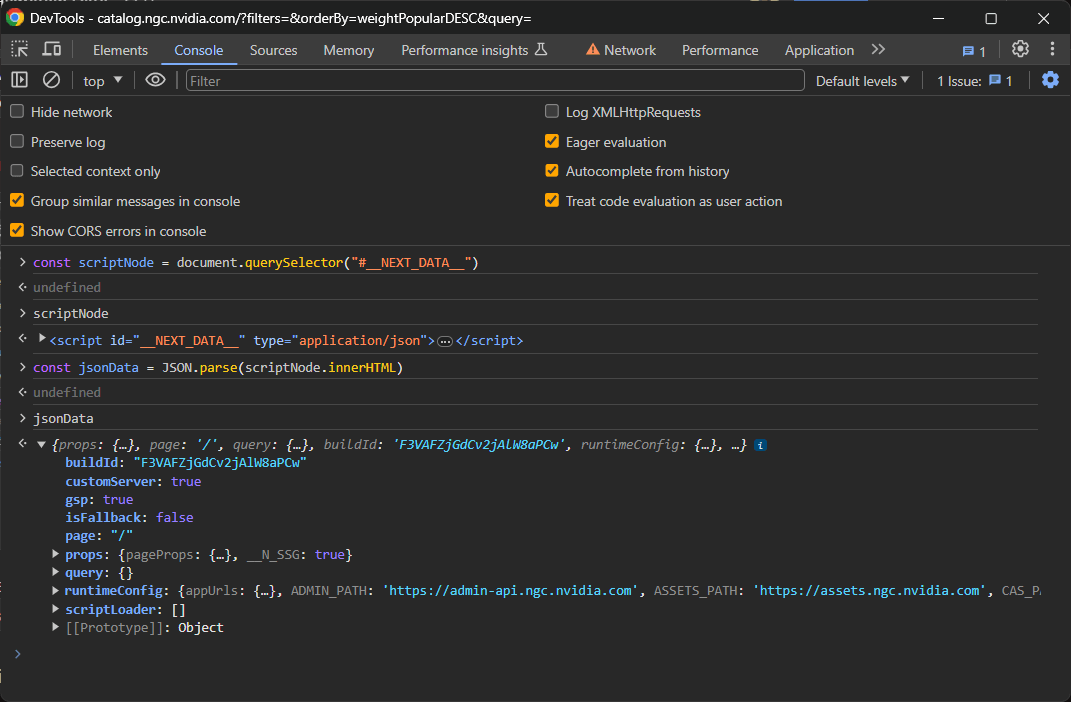
詳細には、props内のpagePropsフィールドに注目してください:
jsonData.props.pageProps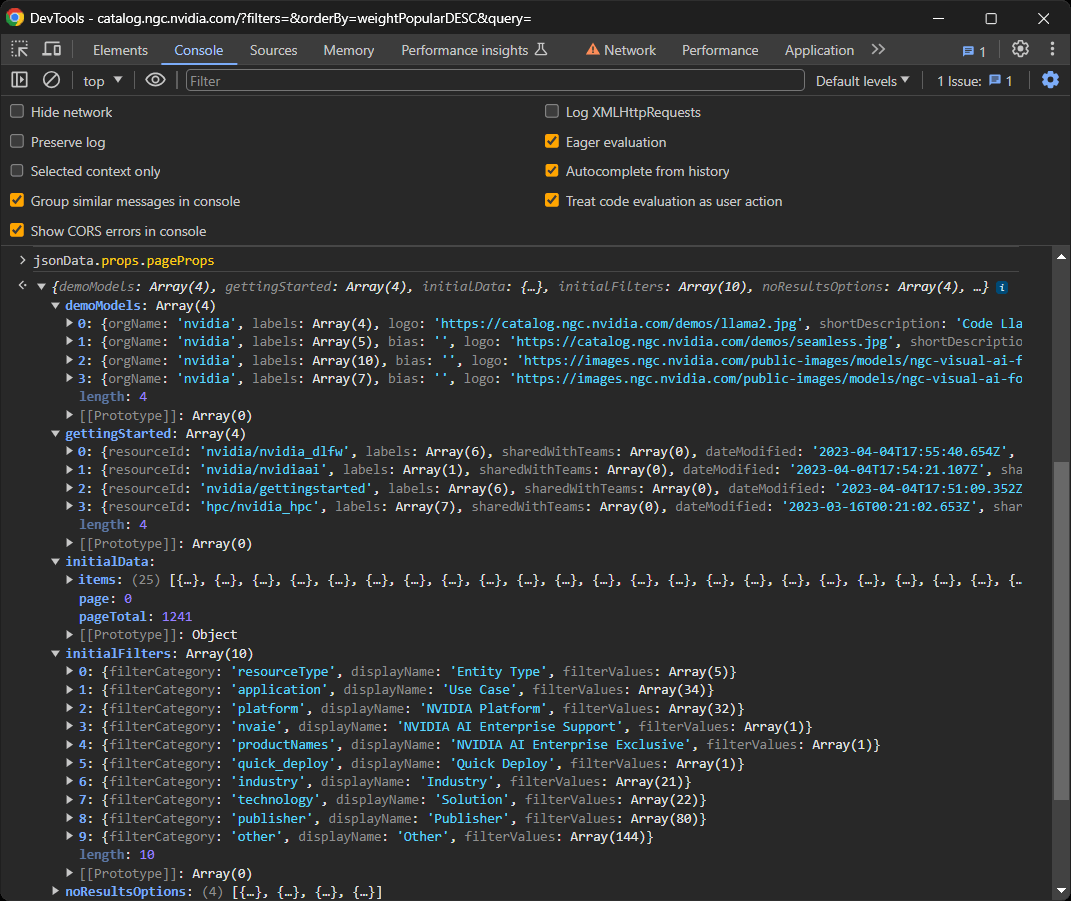
次に、オブジェクトを右クリックし、「オブジェクトをコピー」オプションを選択します:
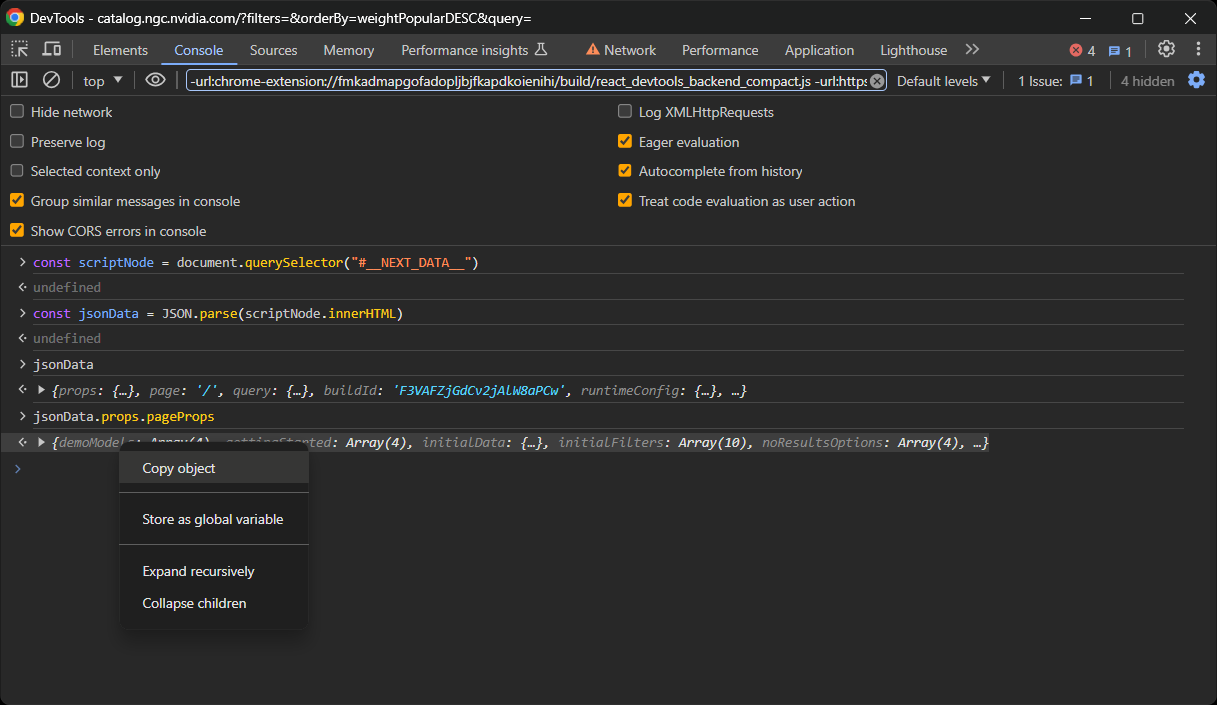
最後に、data.jsonファイルを作成し、必要な内容を貼り付けましょう!
素晴らしい!わずか1分足らずでNext.jsサイトのウェブスクレイピングを完了しました。
すべてをまとめると、次のNext.jsスクレイピングスクリプトが完成します:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pageProps self.__next_f.push関数からのデータ取得
Next.js 13ではApp Routerが導入されました。これにより、Next.jsがReactにデータをハイドレーション(hydration)として渡す方法が変更されました。この場合、self.__next_f.pushという文字列を含むすべての<script>ノードを選択する必要があります。
再度、ブラウザで対象ページにアクセスしコンソールを開きます。以下のコマンドを実行して<script>ノードを選択します:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() は NodeListオブジェクトを返します。Array.from()で配列に変換し、filter()メソッドを適用して対象のノードのみを取得します:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))これでhydrationScriptNodesにはページ上のすべてのハイドレーション用<script>要素が含まれます:
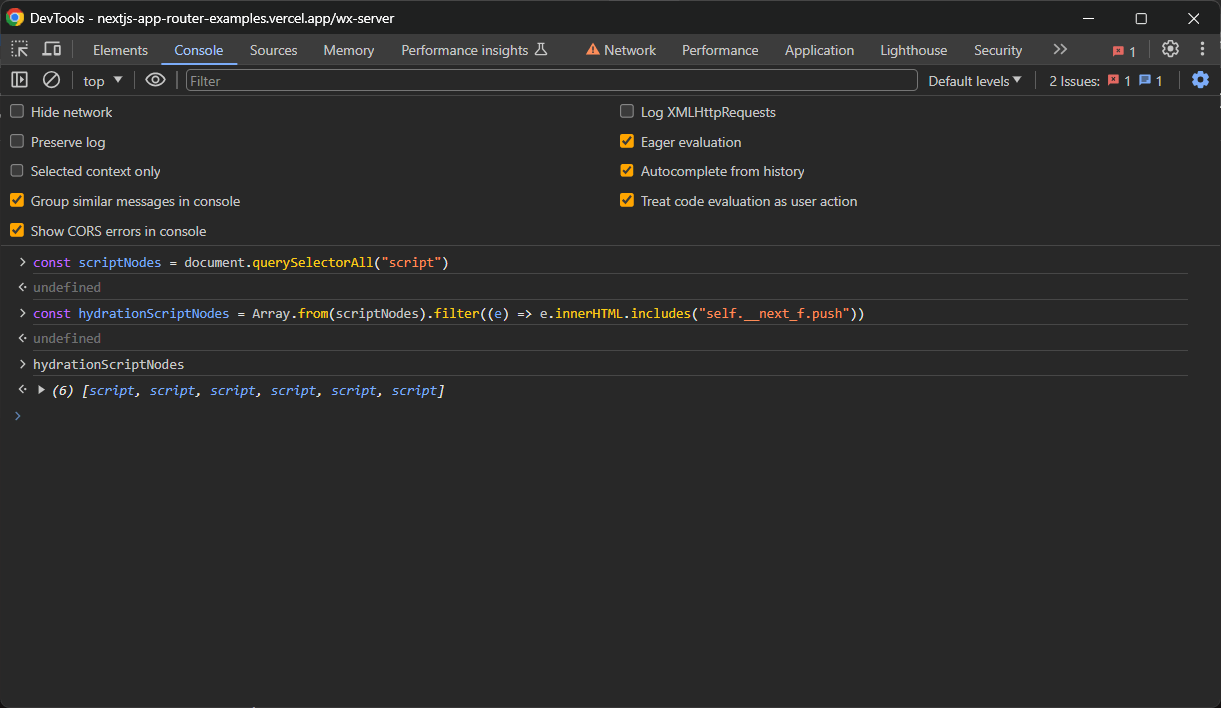
ただし、通常はinitialTree属性を有するノードのみが必要となります。ここに、関心のあるすべてのハイドレーションデータが格納されています:
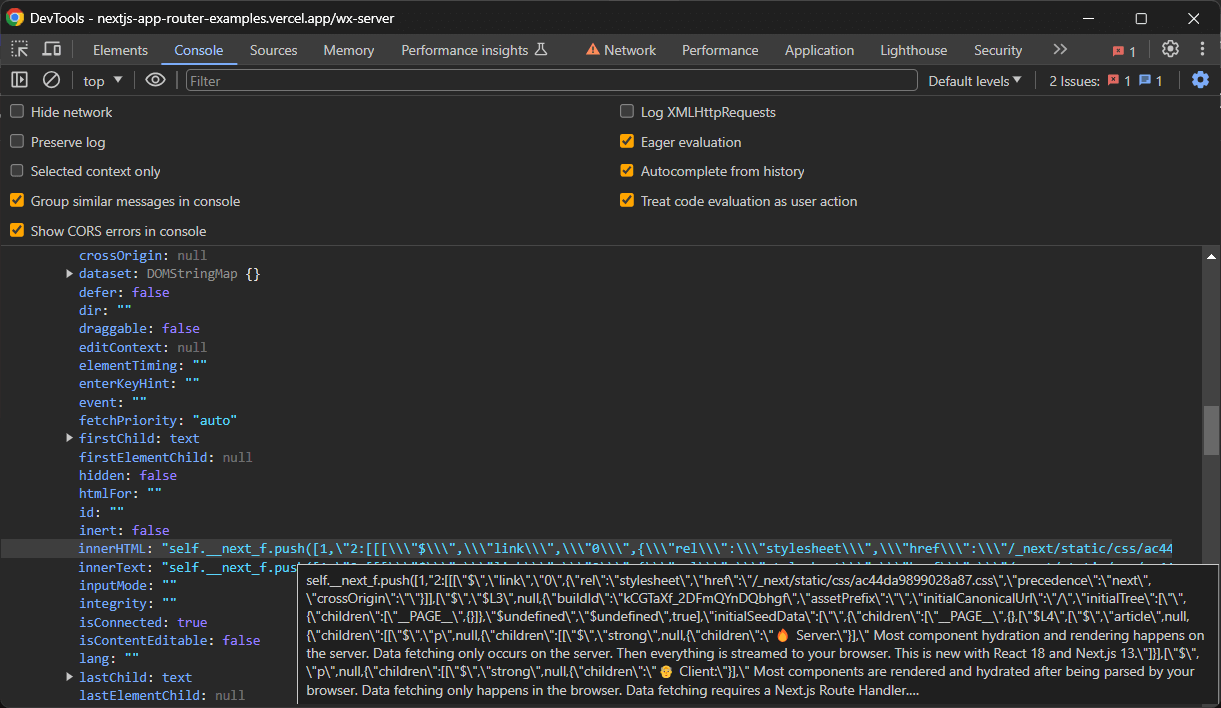
以下のように選択します:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))次に、必要なデータを抽出します:
scriptNode.innerHTML取得したデータには必要な情報が含まれていますが、追加のパースが必要です。数行の追加処理で読みやすい形式に変換できます。
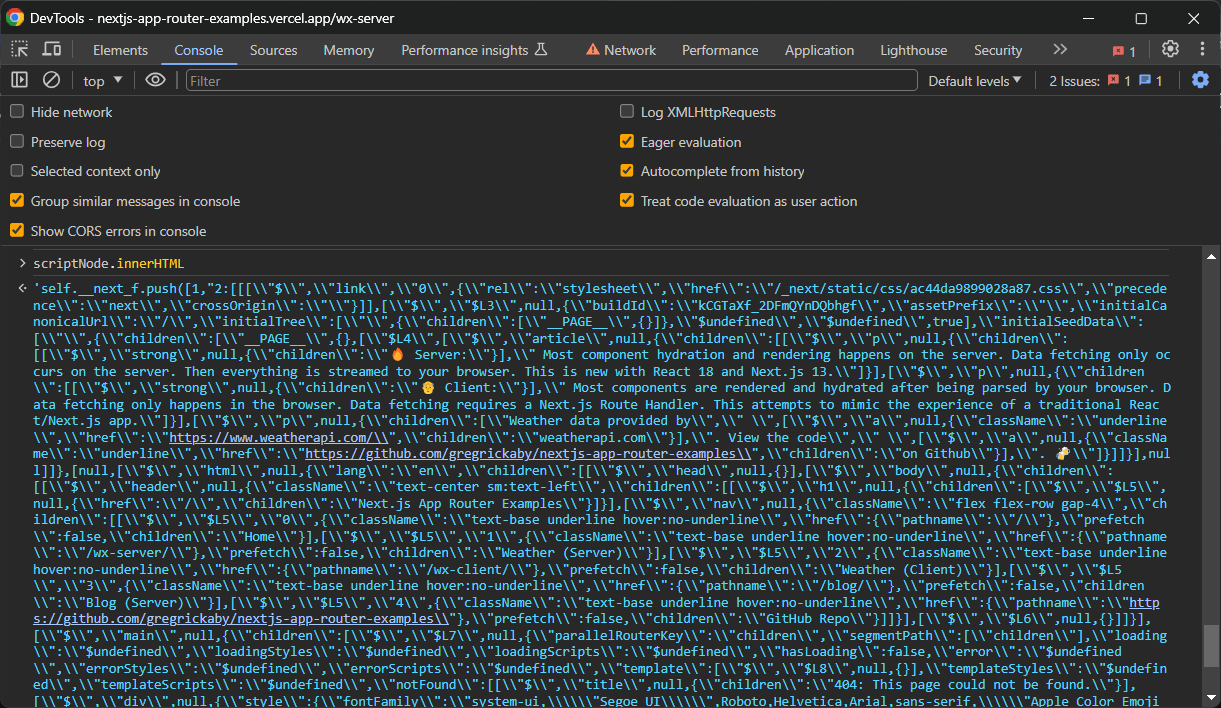
今回のNext.jsスクレイピングスクリプトは次の通りです:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTMLおめでとうございます!Next.jsサイトのスクレイピングがこれまで以上に簡単になりました!
このNext.jsスクレイピング手法の制限事項
Reactハイドレーションデータに基づくこのスクレイピング手法は迅速かつ効果的ですが、いくつかの制限があります。具体的には以下の通りです:
- 部分的なデータ: Next.jsによって追加される特別な
<SCRIPT>ノードには、サーバーから取得されハイドレーション中にReactコンポーネントに渡されるデータのみが含まれます。これはページ上の全データではない可能性があります。Reactコンポーネントにはハードコードされた値が含まれる場合や、AJAXを介して動的に他のデータを取得する場合があるためです。この場合、ブラウザ自動化ツールを用いたウェブスクレイピングを実行する必要があります。 - 追加のパースが必要:
self.__next_f.pushは独自形式のデータを含むため、正確にパースするのは必ずしも容易ではありません。 - 手動操作が必要: 上記のスクリプトをJavaScriptやPythonなどの言語でスクレイピングスクリプトに変換し、データエクスポートロジックを統合しない限り、データを手動でテキストファイルにエクスポートする必要があります。詳細はJavaScriptとNode.jsを用いたウェブスクレイピングガイドをご覧ください。
まとめ
本記事では、Next.jsの定義、世界的にサイト構築で広く採用される理由、およびデータスクレイピング手法について解説しました。特に、Reactハイドレーションへの依存関係とその影響を理解できたはずです。この特性により、サーバーが返すHTMLページには必要なデータが全て(しかもJSON形式で!)含まれています。これによりNext.jsサイトのウェブスクレイピングは非常に容易です。
真の問題は別の点にあります:ボット対策技術によるブロックです。これらのシステムは自動スクレイピングスクリプトを検知しブロックします。幸い、Bright Dataには効果的な解決策が複数用意されています:
- WebスクレイパーIDE:あらゆるブロックを自動的に回避できるウェブスクレイパーを構築するクラウドIDE。
- WebスクレイパーAPI: 99.99%の稼働率と無制限のスケーラビリティを備え、構造化されたウェブデータにプログラムで簡単にアクセスできます。
- スクレイピングブラウザ:CAPTCHA処理、ブラウザフィンガープリンティング対策、自動リトライなどを自動化し、JavaScriptレンダリング機能を備えたクラウドベースの制御可能ブラウザ。PlaywrightやPuppeteerなど主要な自動化ブラウザライブラリと連携。
- Web Unlocker API:あらゆるページの生のHTMLをシームレスに取得し、あらゆるウェブスクレイピング対策をかいくぐるWeb Unlocker API。
ウェブスクレイピング自体には関心がなく、オンラインデータのみが必要な場合でも、Bright Dataの即利用可能なデータセットをご検討ください!
FAQ
Next.jsでDOMから__NEXT_DATA__を非表示または削除できますか ?
いいえ、削除または非表示にすることはできません。DOMから_NEXT_DATA_ <script>要素を削除すると、Reactはハイドレーションできなくなります。このスクリプト内のデータはReactの正常な動作に必須であるため、機能不全や機能低下を招くことなく削除することはできません。このトピックに関するGitHubディスカッションをご覧ください。
DOMからself.__next_f.push 呼び出しを削除できますか ?
いいえ、Next.jsによって追加された<script>ノード内のself.__next_f.push呼び出しを削除することはできません。これらのDOM要素は、クライアントサイドのReactアプリケーションがハイドレートされ、期待通りに機能できるようにするためにサーバーによって追加されます。詳細については、このトピック専用のGitHubディスカッションを参照してください。
サイトがNext.jsで構築されているかどうかの見分け方は?
Next.jsで構築されたサイトかどうかを判断する方法はいくつかあります。まず、一部のNext.jsバージョンでデフォルトで設定されるX-Powered-Byヘッダーを確認してください:
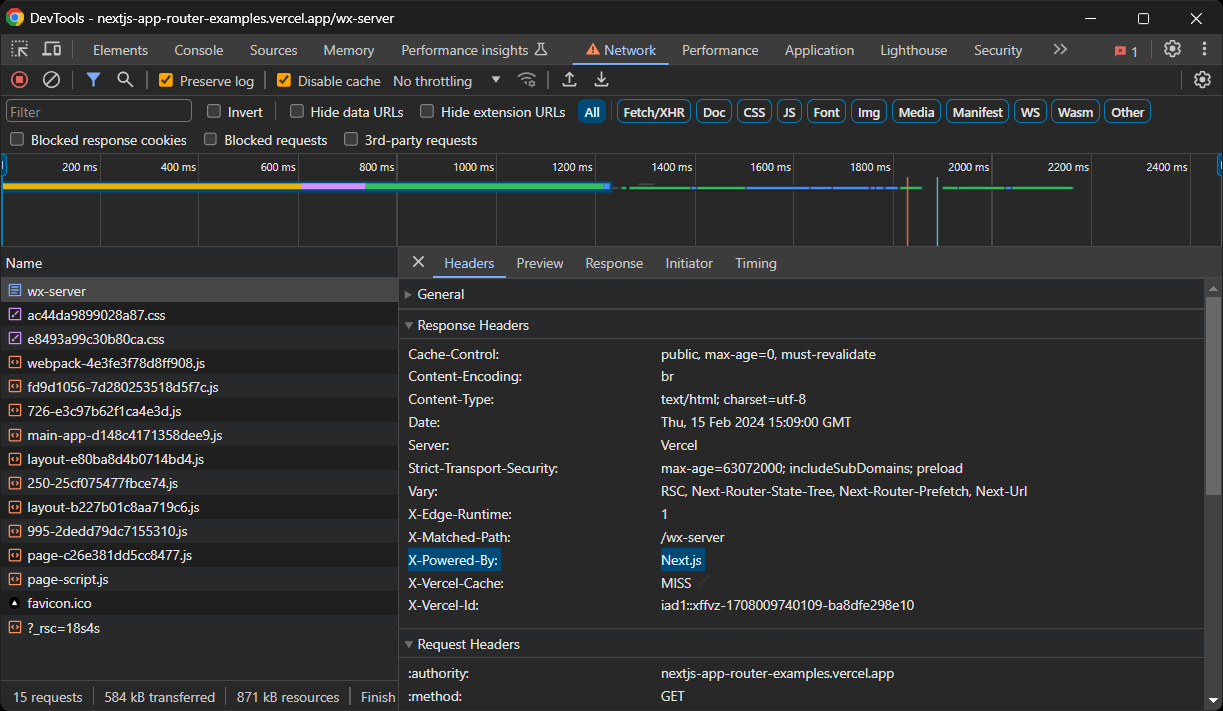
あるいは、DOM内に<script id="__NEXT_DATA__" ... >ノード、または<script>self.__next_f.push(...)</script>ノードが存在するか確認してください。
Next.jsだけがReactハイドレーションに依存する技術ですか?
いいえ、Next.jsだけがReactハイドレーションに依存する技術ではありません。Gatsbyなどの他のサーバーサイドレンダリング(SSR)ジェネレーターも、サーバーでレンダリングされたHTMLをクライアントサイドでインタラクティブなReactアプリケーションに変換するためにReactハイドレーションを利用しています。このプロセスはReactを用いたSSRにおける一般的な手法であり、Next.jsに限定されるものではありません。




