

インターネット上のデータ量が拡大し続ける中、ウェブサイトから自動的に情報を巡回・抽出する「ウェブクローリング」は、開発者が習得すべき重要なスキルとなりつつあります。これはウェブサーバーへHTTPリクエストを送信し、HTML応答をパースして目的のデータを抽出する手法です。
ウェブクローリングのプロセスは複雑で時間がかかる場合がありますが、適切なツールと技術が役立ちます。柔軟性と使いやすさから、Pythonはウェブクローラー構築に人気の言語として台頭し、開発者がデータ抽出プロセスを自動化するスクリプトを迅速に記述することを可能にしています。
この記事では、Scrapyライブラリを用いたPythonによるウェブクローリングのすべてを学びます。
ウェブクローリングが必要な理由
チュートリアルに入る前に、ウェブスクレイピングとウェブクローリングの違いを理解することが重要です。類似しているものの、ウェブスクレイピングは特定のデータをウェブページから抽出するのに対し、ウェブクローリングは検索エンジン向けにインデックス作成のための情報収集を目的としてウェブページを巡回します。
ウェブクローリングは以下の状況を含む様々な場面で有用です:
- データ抽出:特定のデータをウェブサイトから抽出し、分析や研究に活用できます。
- ウェブサイトのインデックス化:検索エンジンは、ウェブサイトをインデックス化し、ユーザーが検索できるようにするために、しばしばウェブクローリングを利用します。
- 監視:ウェブクローリングは、ウェブサイトの変更や更新を監視するために使用できます。この情報は競合他社の追跡に有用です。
- コンテンツ集約:複数のウェブサイトからコンテンツを収集し、アクセスしやすい単一場所に集約するために使用できます。
- セキュリティテスト:ウェブクローリングは、ウェブサイトやウェブアプリケーションの脆弱性や弱点を特定するためのセキュリティテストに利用できます。
Pythonによるウェブクローリング
Pythonは、コーディングの容易さと直感的な構文から、ウェブクローリングに広く採用されています。さらに、最も人気のあるウェブクローリングフレームワークの一つであるScrapyはPythonで構築されています。この強力で柔軟なフレームワークにより、ウェブサイトからのデータ抽出、リンク追跡、結果の保存が容易になります。
Scrapyは大容量データの処理を想定して設計されており、幅広いウェブスクレイピングタスクに使用できます。HTTPダウンローダー(HTTPダウンロードツール)、ウェブサイトをクロールするスパイダー、クロール頻度を管理するスケジューラー、スクレイピングしたデータを処理するアイテムパイプラインなど、Scrapyに含まれるツール群は様々なウェブクローリングタスクに最適です。
Pythonを使用したウェブクローリングを始めるには、システムにScrapyフレームワークをインストールする必要があります。
ターミナルを開き、以下のコマンドを実行します:
pip install scrapyn
このコマンドを実行すると、システムにScrapyがインストールされます。Scrapyは「スパイダー」と呼ばれるクラスを提供し、これらがウェブクローリングタスクの実行方法を定義します。これらのスパイダーは、ウェブサイトのナビゲーション、リクエスト送信、ウェブサイトHTMLからのデータ抽出を担当します。
Scrapyプロジェクトの作成
この記事では、Books to Scrapeというウェブサイトをクロールし、各書籍の名前、カテゴリ、価格をCSVファイルに保存します。このウェブサイトはスクレイピングプロジェクトのサンドボックスとして機能するように作成されました。
Scrapyのインストールが完了したら、次のコマンドで新しいプロジェクト構造を作成します:
scrapy startproject bookcrawlern
(注:「command not found」エラーが発生した場合は、ターミナルを再起動してください)
デフォルトのディレクトリ構造は、ウェブスクレイピングプロセスの各コンポーネントごとにファイルとディレクトリを分離した、明確で整理されたフレームワークを提供します。これにより、スパイダーコードの記述・テスト・保守が容易になり、抽出データを任意の方法で処理・保存できます。ディレクトリ構造は以下のようになります:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Scrapyプロジェクトでクロール処理を開始するには、bookcrawler/spidersディレクトリに新しいスパイダーファイルを作成することが不可欠です。これはScrapyがコードを実行するスパイダーを検索する標準ディレクトリだからです。これを行うには、bookcrawler/spidersディレクトリに移動し、bookspider.pyという名前の新しいファイルを作成します。次に、スパイダーを定義しその動作を指定するために、以下のコードをファイルに記述します:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
このコードは、組み込みのCrawlSpiderを継承したBookCrawlerを定義し、リンク追跡とデータ抽出のルールを定義する便利な方法を提供します。start_urls属性は、クロールを開始するURLのリストを指定します。この例では、ウェブサイトのホームページである1つのURLのみを含みます。
rules属性は、スパイダーが追跡すべきリンクを決定する一連のルールを指定します。ここではscrapy.spidersモジュールのRuleクラスを使用して作成された1つのルールのみが定義されています。このルールは、スパイダーが追跡すべきリンクのパターンを指定するLinkExtractorインスタンスで定義されます。LinkExtractorの allowパラメータは/catalogue/category/books/に設定されており、これはスパイダーがURLにこの文字列を含むリンクのみを追跡することを意味します。
スパイダーを実行するには、ターミナルを開き以下のコマンドを実行します:
scrapy crawl bookspidern
これを実行すると、ScrapyはBookCrawlerスパイダークラスを初期化し、start_urls属性内の各URLに対してリクエストを作成し、それらをScrapyスケジューラに送信します。スケジューラがリクエストを受信すると、スパイダーのallowed_domains属性(指定されている場合)によってリクエストが許可されているかどうかを確認します。 許可されたドメインの場合、リクエストはダウンローダーに渡され、サーバーへのHTTPリクエストを実行してレスポンスを取得します。
この時点で、スパイダーがクロールした全URLがコンソールウィンドウに表示されるはずです:
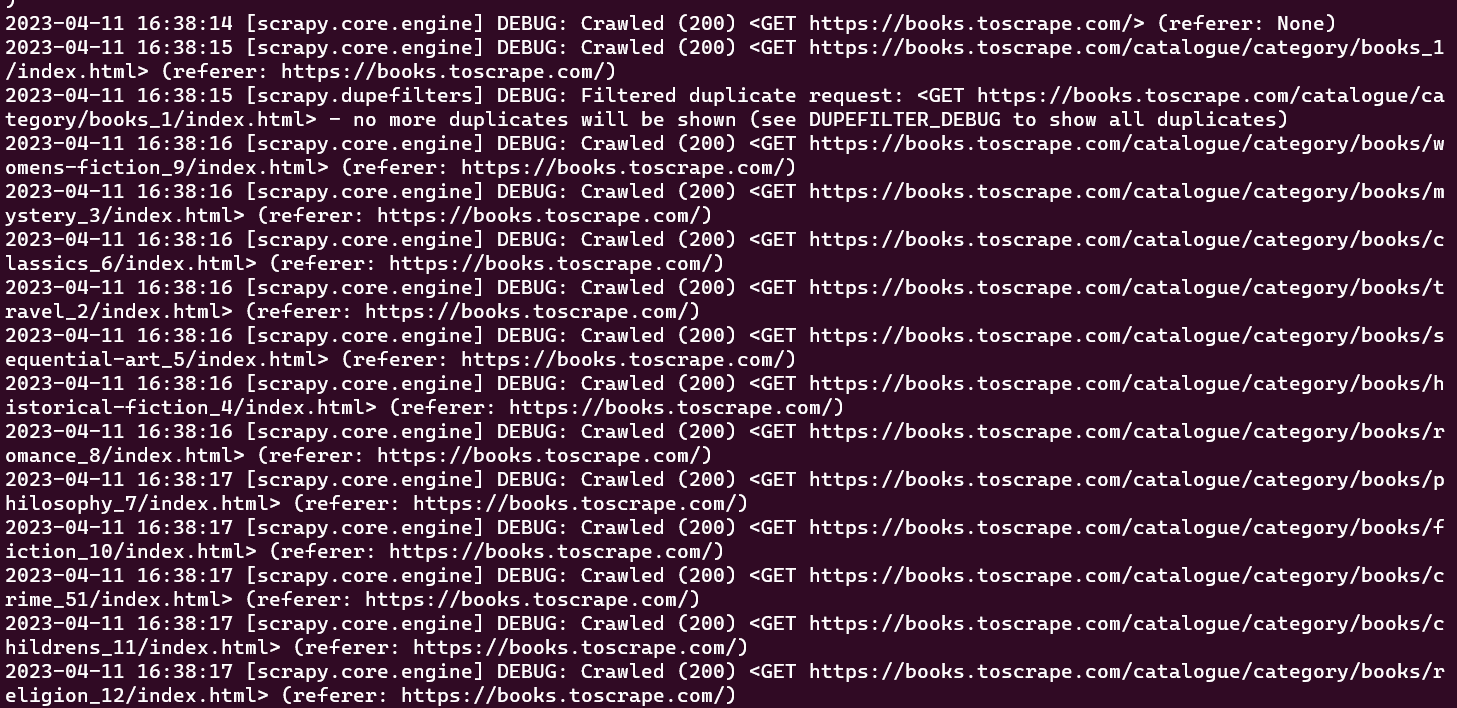
初期のクローラーは、事前定義されたURLセットをクロールするタスクのみを実行し、情報を抽出することはありません。クロールプロセス中にデータを取得するには、クローラークラス内にparse_item関数を定義する必要があります。parse_item関数は、クローラーが行った各リクエストからのレスポンスを受け取り、レスポンスから取得した関連データを返す役割を担います。
注意:
parse_item関数は、LinkExtractorでcallback属性を設定した後にのみ機能します。
Scrapyでウェブページをクロールして得られたレスポンスからデータを抽出するには、CSSセレクタを使用する必要があります。次のセクションではCSSセレクタについて簡単に紹介します。
CSSセレクタについて
CSSセレクタは、タグ、クラス、属性を指定してウェブページからデータを抽出する方法です。例えば、scrapy shell books.toscrape.com で初期化されたScrapyシェルセッションは以下のようになります:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
このセッションでは、css関数がタグ(例: title)を受け取り、Selectorオブジェクトを返します。titleタグ内のテキストを取得するには、以下のクエリを記述します:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
このスニペットでは、テキスト疑似セレクタを使用して囲むtitleタグを除去し、内部テキストのみを返します。getメソッドはデータ値のみを表示するために使用されます。
要素のクラスを取得するには、右クリックで「要素を検査」を選択し、ページのソースコードを表示する必要があります:
Scrapyを使用したデータ抽出
レスポンスオブジェクトから要素を抽出するには、コールバック関数を定義し、Ruleクラスの属性として割り当てる必要があります。
bookspider.pyを開き、以下のコードを実行します:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
BookCrawlerクラスのparse_item関数には、抽出対象データのロジックが含まれており、コンソールにyieldで出力します。yieldを使用することで、Scrapyはデータをアイテム形式で処理でき、その後アイテムパイプラインを通過させてさらなる処理や保存が可能です。
カテゴリの選択プロセスは、単純な<h1>タグ内に記述されているため容易です。一方、book_titlesの選択は多段階の選択プロセスを経て実現されます。最初のステップでは、classproduct_podを持つ<article>タグを選択します。 続いて、<h3>タグ内にネストされた<a>タグを特定する探索処理が続きます。book_pricesの選択にも同様のアプローチが採用され、ウェブページから必要な情報を取得することが可能となります。
ここまでで、ウェブサイトをクロールしてデータを取得するスパイダーを作成しました。スパイダーを実行するには、ターミナルを開き以下のコマンドを実行します:
scrapy crawl bookspider -o books.jsonn
実行すると、クローラーがクロールしたウェブページと対応するデータがコンソールに表示されます。-oフラグの使用により、Scrapyは取得した全データをbooks.jsonというファイルに保存するよう指示されます。スクリプト完了後、プロジェクトディレクトリにbooks.jsonという新規ファイルが作成されます。このファイルにはクローラーが取得した書籍関連データが全て含まれます:
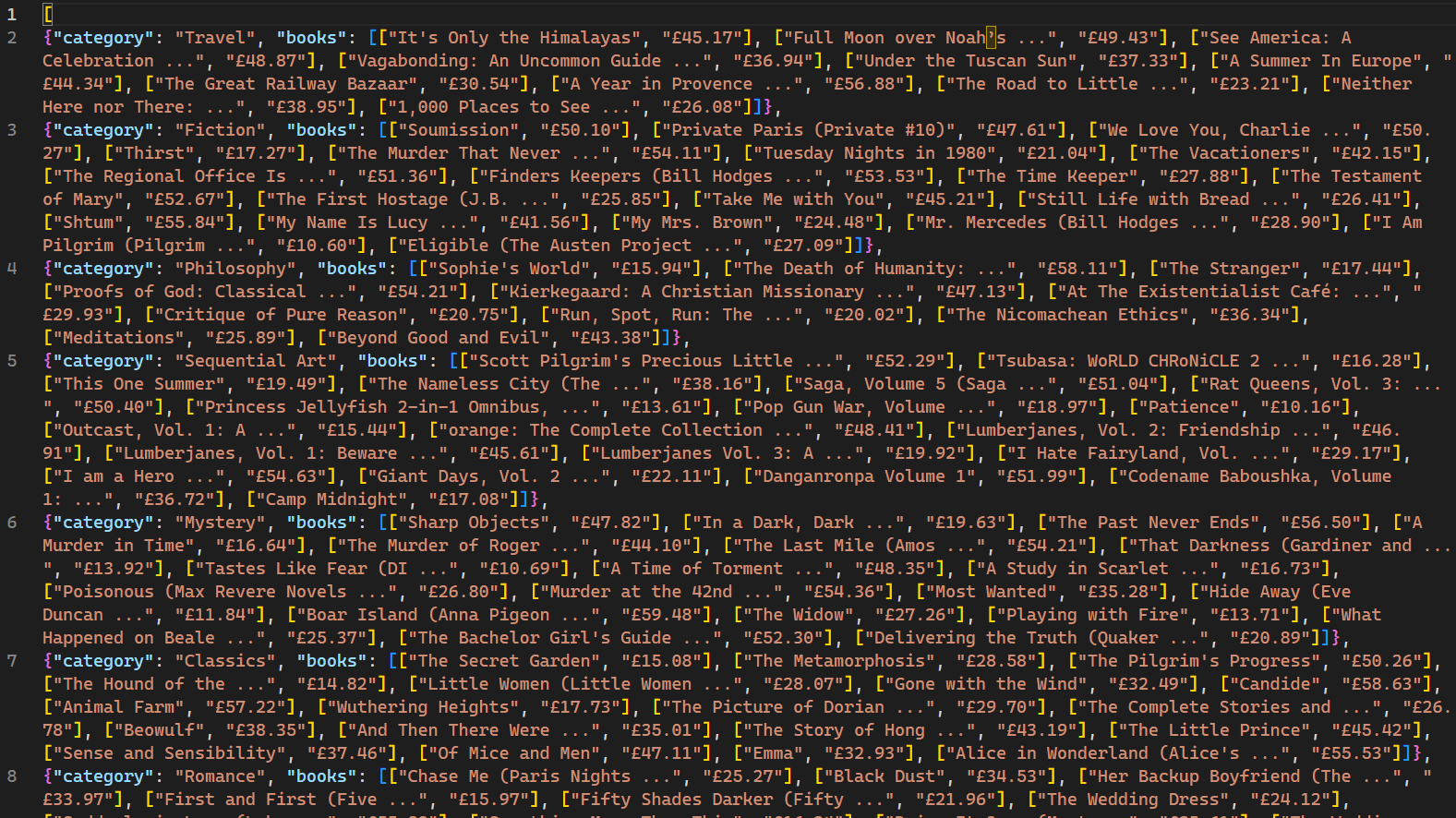
重要な注意点として、このウェブクローラーは、複数リクエストに対するIPブロック機構を採用していないウェブサイトでのみ有効です。ウェブボットやクローラーへの対応が厳しいサイトでは、Bright Dataなどのプロキシサービスを利用し、大規模なデータ抽出を行う必要があります。Bright Dataのサービスは、IPブロックや検知を回避しながら、複数のソースからウェブデータを収集することを可能にします。
結論
ウェブクローリングとウェブスクレイピングを統合した技術は、データ収集やデータサイエンスにおいて極めて有用です。ウェブクローリング向けに設計されたフレームワークScrapyは、組み込みのクローラーとスクレイパーを提供することでこのプロセスを簡素化します。
本記事では、Scrapyフレームワークを用いたウェブクローラーの構築とデータスクレイピングの手順を解説しました。CrawlSpiderによる 効率的なウェブクローリングの実践 、特定のURLパターンをクロールするためのRuleやLinkExtractorといった 概念の理解、さらにCSSセレクターを用いたHTML要素の選択手法について学びました。これらのスキルを習得することで、データサイエンスをはじめとする様々な分野におけるウェブクローリングとウェブスクレイピングの課題に十分対応できるでしょう。






