
本記事では以下の内容を解説します:
- データパイプラインとは何か?
- 優れたデータパイプラインアーキテクチャがビジネスに与える効果
- データパイプラインアーキテクチャの事例
- データパイプラインとETLパイプラインの違い
データパイプラインとは何か?
データパイプラインとは、データが経るプロセスを指します。通常、データは「ターゲットサイト」と「データレイクまたはデータプール」の間で完全なサイクルを回ります。データレイクやデータプールは、チームの意思決定プロセスやAI機能におけるアルゴリズムにサービスを提供します。典型的なフローは次のようなものです:
- 収集
- 取り込み
- 準備
- 計算
- 提示
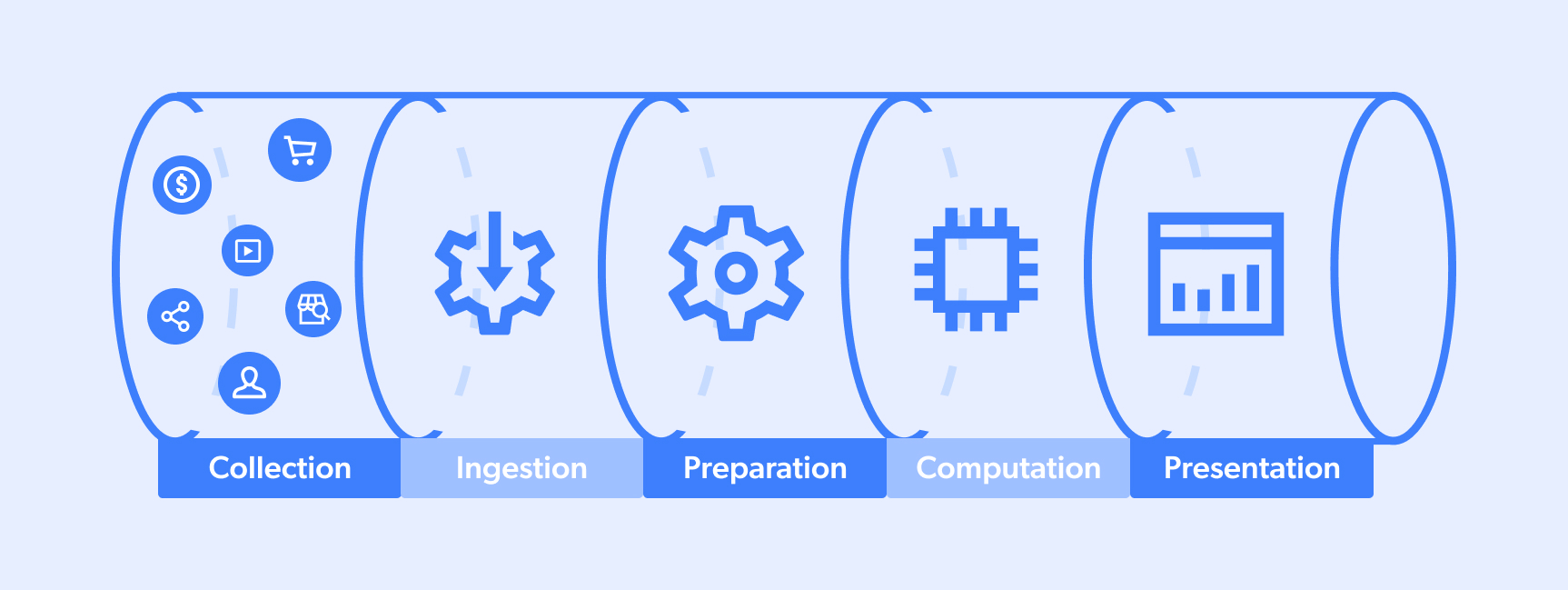
ただし、データパイプラインには複数のソース/デスティネーションが存在し、ステップが同時に実行される場合がある点に留意してください。また、特定のパイプラインは部分的(例えば1~3や3~5など)である場合もあります。
ビッグデータパイプラインとは何か?
ビッグデータパイプラインとは、大規模なデータ収集・処理・実装を扱う運用フローです。その概念は、「データ収集」の規模が大きければ大きいほど、重要なビジネス判断を行う際の誤差の余地が小さくなるというものです。
ビッグデータパイプラインの代表的な応用例:
- 予測分析:アルゴリズムは、例えば株式市場や製品需要に関する予測を可能にします。この機能には、システムが人間の行動パターンを理解し将来の結果を予測できるようにする、過去のデータセットを用いた「データトレーニング」が必要です。
- リアルタイム市場捕捉:この 手法は 、例えば現在の消費者心理が突発的に変化し得ることを理解しています。そのため、ソーシャルメディアデータ、eコマース市場データ、検索エンジン上の競合広告データなど、複数のソースから大量の情報を集約します。これらの独自のデータポイントを大規模に相互参照することで、より優れた意思決定が可能となり、市場シェアの拡大につながります。
データ収集プラットフォームを活用することで、ビッグデータパイプラインの運用フローは以下の処理が可能となる:
- スケーラビリティ – データ量は頻繁に変動するため、システムは要求に応じてリソースを動的に起動/停止する能力を備える必要がある。
- 流動性– 複数のソースから大規模にデータを収集する場合、ビッグデータ処理オペレーションは多様なフォーマット(例:JSON、CSV、HTML)に対応する能力と、構造化されていないターゲットウェブサイトデータをクリーニング、マッチング、統合、処理、構造化するノウハウが必要です。
- 同時リクエスト管理 – Bright DataのCEO、Or Lenchnerが言うように:「大規模なデータ収集は、音楽フェスでオンラインでビールを待つようなものだ。同時リクエストは短く素早い列で、迅速かつ同時にサービスを受けられる。一方、もう一方の列は遅く連続的だ。ビジネス運営がそれに依存する場合、どちらの列に並んでいたいだろうか?」
優れたデータパイプラインアーキテクチャがビジネスに与える効果
優れたデータパイプラインアーキテクチャが日常業務プロセスを効率化する主な方法は以下の通りです:
一つ目:データ統合
データはソーシャルメディア、検索エンジン、株式市場、ニュース媒体、マーケットプレイス上の消費者行動など、多様なソースから発生します。データパイプラインはこれら全てを一箇所に集約する漏斗として機能します。
二つ目:摩擦の低減
データパイプラインは、初期分析のためのデータクリーニングや準備に必要な労力を削減することで、摩擦と「インサイト獲得までの時間」を短縮します。
三:データの区画化
インテリジェントに実装されたデータパイプラインアーキテクチャは、関連するステークホルダーのみが特定の情報を取得できるようにし、各アクターの進路を確実に保つのに役立ちます。
四:データの均一性
データは多様なソースから様々な形式で流入します。データパイプラインアーキテクチャは、統一性を創出する手法を把握しているだけでなく、様々なリポジトリ/システム間でのコピー/移動/転送も可能です。
データパイプラインアーキテクチャの事例
データパイプラインアーキテクチャは、予想される収集量、データの送信元と送信先、そして発生する可能性のある処理の種類などを考慮に入れる必要があります。
代表的なデータパイプラインアーキテクチャの例を3つ示す:
- ストリーミングデータパイプライン:リアルタイム性の高いアプリケーション 向け。 例:競合他社の価格設定、バンドル商品、広告キャンペーンに関するデータを収集するオンライン旅行代理店(OTA)。この情報は処理/フォーマットされ、関連チーム/システムに配信され、さらなる分析や意思決定(例:競合他社の価格下落に基づく航空券の再価格設定を担当するアルゴリズム)に活用される 。
- バッチベースのデータパイプライン: よりシンプルで直截的なアーキテクチャです。 通常、大量のデータポイントを生成する単一のシステム/ソースから構成され、生成されたデータは単一の宛先(データストレージ/分析「施設」)に配信されます。 典型例として、金融機関がナスダックにおける投資家の売買・取引量に関する大量データを収集するケースが挙げられる。この情報は分析のために送信され、ポートフォリオ管理の判断材料として活用される。
- ハイブリッドデータパイプライン:この アプローチは 、リアルタイムの洞察とバッチ処理/分析の両方を可能にするため、非常に大規模な企業/環境で人気があります。このアプローチを選択する多くの企業は、将来の新たなクエリやパイプライン構造の変更に対応する柔軟性を高めるため、データを生の形式で保持することを好みます。
データパイプラインとETLパイプライン
ETL(抽出、変換、ロード)パイプラインは、主にデータウェアハウジングと統合を目的とします。通常、異なるソースから収集したデータをより汎用的でアクセスしやすい形式に変換し、ターゲットシステムへアップロードする手段として機能します。ETLパイプラインは、データの収集・保存・準備を行い、迅速なアクセスや分析を可能にします。
データパイプラインは、データを収集・フォーマットし、ターゲットシステムへ転送/アップロードする体系的なプロセス構築に重点を置きます。データパイプラインはプロトコルとしての側面が強く、「機械」の全構成要素が意図通りに動作することを保証します。
結論
自社ビジネスに適したデータパイプラインアーキテクチャを見出し実装することは、ビジネスの成功にとって極めて重要です。ストリーミング型、バッチ処理型、ハイブリッド型いずれのアプローチを選択する場合でも、特定のニーズに合わせてソリューションを自動化・カスタマイズできる技術を活用すべきです。





