

ウェブスクレイピングは、ウェブページからデータを抽出するために使用できる技術です。対象のウェブサイトがAPIを提供していない場合、APIが使用できない場合、または必要なデータを正確に返さない場合に特に有用です。
正規表現(Regex)は、テキストからデータを抽出するための強力な文法パターンであり、ウェブスクレイピングで一般的に使用されます。正規表現はテキスト内で一致するパターンを定義し、テキストから情報を探して抽出するために広く用いられています。そのため、ウェブスクレイピングにおいて多用されています。
この記事では、Pythonで正規表現をウェブスクレイピングに活用する方法を学びます。記事を読み終える頃には、静的サイトと動的サイトのスクレイピング手法を理解し、遭遇する可能性のある制限事項についても把握できるようになります。
正規表現とは
正規表現は特定のパターンに一致するトークンを用いて定義されます。すべてのトークンを詳細に説明することは本記事の範囲外ですが、以下に頻繁に使用される代表的なトークンをいくつか示します:
| トークン | Matches |
|---|---|
| 特殊でない任意の文字 | 指定された文字 |
^ |
文字列の先頭 |
$ |
文字列の終わり |
. |
n以外の任意の文字 |
* |
前の要素がゼロ回以上出現 |
? |
前の要素が0回または1回出現 |
+ |
前の文字が1回以上出現 |
{数字} |
前の要素の正確な数 |
d |
任意の数字 |
s |
任意の空白文字 |
w |
任意の単語文字 |
D |
dの補数 |
S |
sの逆 |
W |
wの逆 |
正規表現についてさらに学び、実践的な経験を積むには、regexr.com を訪問してください。さらに、この記事では正規表現のパフォーマンスを最適化するための重要なヒントをいくつか共有しています。
Pythonでのウェブスクレイピングにおける正規表現の使用
このチュートリアルでは、正規表現を使用してウェブページからデータを抽出するシンプルなPythonスクレイパーを作成します。
まず、プロジェクト用のディレクトリを作成します:
mkdir web_scraping_with_regex
cd web_scraping_with_regex
次に、Python仮想環境を作成します:
python -m venv venv
そして有効化します:
source ./venv/bin/activate
ウェブスクレイパーを作成するには、以下の2つのライブラリをインストールする必要があります:
- ウェブページ取得用の
requests - HTMLコンテンツのパースと要素の検索用:
beautifulsoup4
ライブラリをインストールするには以下のコマンドを実行します:
pip install beautifulsoup4 requests
注意: ウェブサイトをスクレイピングする前に、必ずその利用規約を確認し、スクレイピングが許可されているか確認してください。禁止されている場合はスクレイピングを行わないでください。
Eコマースサイトのスクレイピング
このセクションでは、シンプルなダミーECサイトをウェブスクレイピングするスクレイパーを作成します。最初のページをスクレイピングし、書籍のタイトルと価格を抽出します。
そのためには、スクレイパー.py という名前のファイルを作成し、必要なモジュールをインポートします:
import requests
from bs4 import BeautifulSoup
import re
注:
reモジュールは正規表現を扱うPython組み込みモジュールです。
次に、対象ウェブページにGETリクエストを送信し、ページのHTMLコンテンツを取得します:
page = requests.get('https://books.toscrape.com/')
このデータをBeautiful Soupに渡して、ウェブページのHTML構造をパースします:
soup = BeautifulSoup(page.content, 'html.parser')
HTML内の要素構造を把握するには、要素検査ツールを使用します。ブラウザでウェブページを開き、Ctrl + Shift + I を押してインスペクターを開きます。 スクリーンショットの通り、商品はクラスcol-xs-6 col-sm-4 col-md-3 col-lg-3 のli要素に格納されています。書籍タイトルはa要素のtitle属性から取得でき、価格はクラスprice_color のp要素に格納されています:
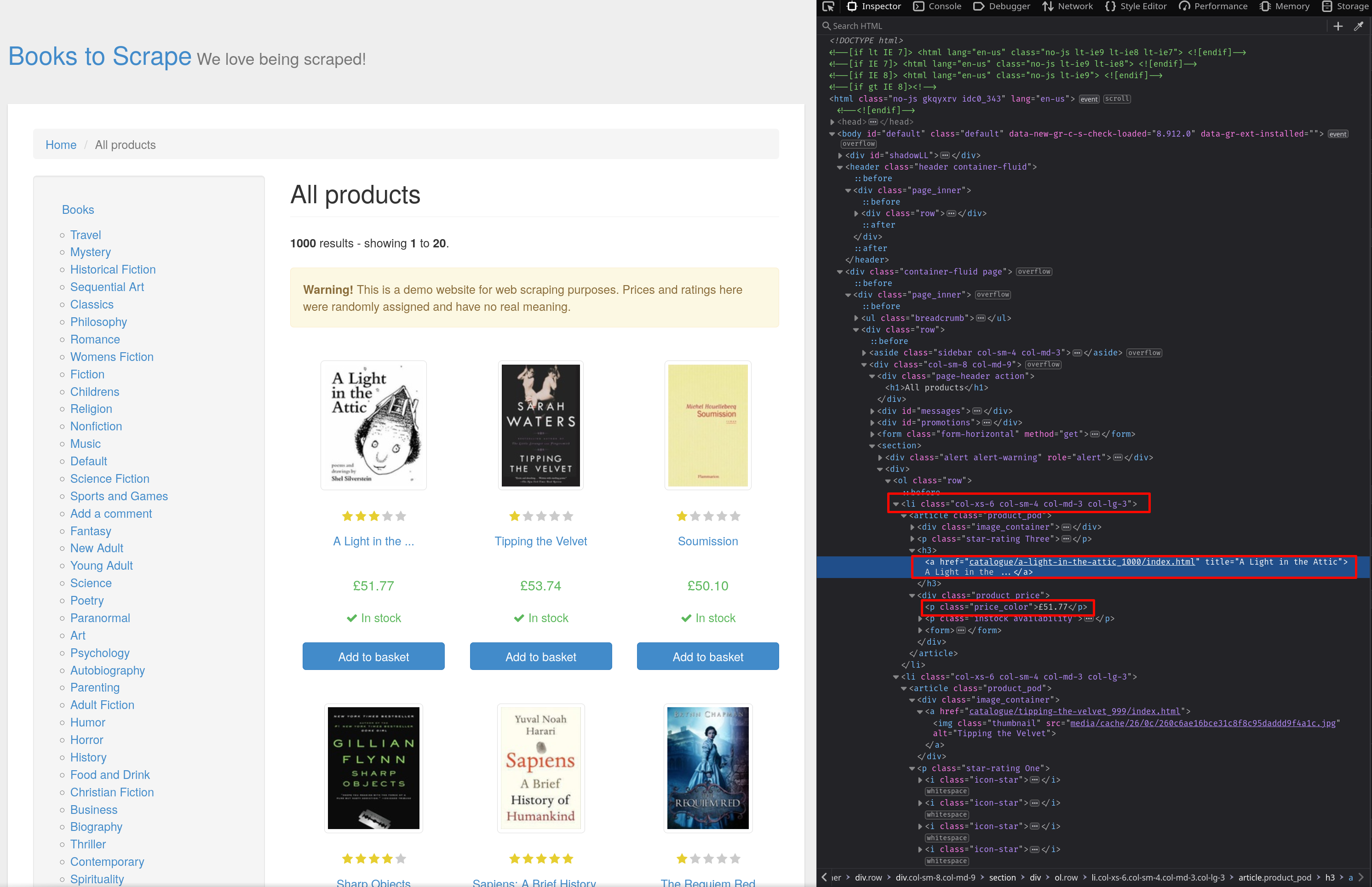
Beautiful Soupのfind_allメソッドを使用して、クラスcol-xs-6 col-sm-4 col-md-3 col-lg-3を持つすべてのli要素を検索します:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)
content変数にはli要素のHTMLテキストが格納され、正規表現でタイトルと価格を抽出できます。
最初のステップは、テキスト内のタイトルと価格に一致する正規表現を構築することです。そのためには、再度「要素を検査」機能を使用する必要があります。
書籍のタイトルはa 要素のtitle 属性に格納されており、a 要素は以下のような構造をしています:
<a href="..." title="...">
タイトル後のダブルクォート内の内容を一致させるには、古典的な`.*?` 正規表現を使用します。`.` は単一文字に一致し、`*` は先行要素(この場合は`.` で一致した内容)の 0 回以上の一致に、`?` は先行要素(この場合は`.*` で一致した内容)の 0 回または 1 回の一致にそれぞれ対応します。これらを組み合わせて、以下の完全な式でダブルクォート内の内容に一致させます:
<a href=".*?" title="(.*?)"
.*?を囲む括弧はキャプチャグループを作成します。キャプチャグループはパターン一致の情報を記憶し、複雑な式では既に一致したパターンを識別・参照するために使用されます。ただし今回は、一致したテキストを抽出するためにキャプチャグループを使用しています。キャプチャグループがなければテキストは依然として一致しますが、一致したテキストにアクセスすることはできません。
価格を抽出するには、同じ正規表現(.*?)を使用します。価格は class="price_color” を持つp 要素に格納されているため、完全な正規表現は<p class="price_color">(.*?)</p> となります。
2つのパターンを定義します:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
注:
.*の後に?が必要な理由が気になる場合、このStack Overflowの回答が?の役割を明確に説明しています。
これでre.findall() を使用して HTML 文字列から正規表現に一致するすべての要素を検索できます:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
最後に、一致した結果を反復処理して出力します:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
このコードはpython スクレイパー.py で実行できます。出力例は以下の通りです:
屋根裏の灯り: £51.77
ティッピング・ザ・ベルベット: £53.74
服従: £50.10
シャープ・オブジェクツ: £47.82
サピエンス全史: £54.23
レクイエム・レッド: £22.65
夢の仕事を手に入れるための汚い小さな秘密: £33.34
『来るべき女:悪名高きフェミニスト、ヴィクトリア・ウッドハルを基にした小説』: £17.93
『ボートに乗った少年たち:1936年ベルリン五輪で金メダルを目指す9人のアメリカ人』: £22.60
『ブラック・マリア』: £52.15
『飢えた心(三角貿易三部作 #1)』: £13.99
シェイクスピアのソネット集: £20.66
私を解き放て: £17.46
スコット・ピルグリムの尊い小さな人生(スコット・ピルグリム #1): £52.29
破り捨てて、また始めよう: £35.02
我らのバンドが君の人生になる: アメリカン・インディー・アンダーグラウンドの情景、1981-1991: £57.25
オリオ: £23.88
メサエリオン: 1800-1849年 最高のSF短編集: £37.59
リバタリアニズム入門: £51.33
ヒマラヤだけのことさ: £45.17
Wikipediaページのスクレイピング
では、ウィキペディアのページをスクレイピングし、すべてのリンクに関する情報を抽出できるスクレイパーを作成しましょう。
wiki_scraper.py という名前の新しいファイルを作成します。前回と同様に、ライブラリのインポート、GETリクエストの実行、コンテンツのパースから始めます:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
すべてのリンクを見つけるには、find_all()メソッドを使用します:
links = soup.find_all("a")
content = str(links)
リンクテキストはtitle属性に、リンクURLはhref属性に格納されています。同じ正規表現(.*?)を使用して情報を抽出できます。完全な式は以下のようになります:
<a href="(.*?)" title="(.*?)">.*?</a>
3つ目の.*? はキャプチャグループではありません。aタグの内容自体には関心がないためです。
以前と同様に、findall()を使用して全ての一致を検索し、結果を出力します:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
python wiki_scraper.py で実行すると、以下の出力が得られます:
簡潔化のため出力は省略
/wiki/Category:ウェブスクレイピング => Category:ウェブスクレイピング
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Category:CS1 maint: multiple names: authors list
/wiki/Category:CS1_Danish-language_sources_(da) => Category:CS1 Danish-language sources (da)
/wiki/Category:CS1_French-language_sources_(fr) => Category:CS1 French-language sources (fr)
/wiki/Category:Articles_with_short_description => Category:Articles with short description
/wiki/Category:Short_description_matches_Wikidata => Category:Short description matches Wikidata
/wiki/Category:Articles_needing_additional_references_from_April_2023 => Category:Articles needing additional references from April 2023
/wiki/Category:追加出典が必要なすべての記事 => カテゴリ:追加出典が必要なすべての記事
/wiki/Category:2015年10月以降の地理的範囲が限定された記事 => カテゴリ:2015年10月以降の地理的範囲が限定された記事
/wiki/Category:United_States-centric => カテゴリ:アメリカ中心主義
/wiki/Category:All_articles_with_unsourced_statements => カテゴリ:出典不明の記述がある全記事
/wiki/Category:Articles_with_unsourced_statements_from_April_2023 => カテゴリ:2023年4月時点の出典不明の記述がある記事
動的サイトのスクレイピング
これまでスクレイピングしてきたウェブページは全て静的でした。動的ウェブページのスクレイピングは、Seleniumのようなブラウザ自動化ツールが必要となるため、やや難易度が高くなります。以下は、OpenWeatherMapのロンドン向けホームページをスクレイピングし、正規表現とSeleniumを用いて現在の気温を取得する例です:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
このコードはSeleniumを使用してFirefoxのインスタンスを起動し、CSSセレクタで現在の気温を表示する要素を選択します。その後、正規表現<span .*?>(.*?)</span>を使用して気温を抽出します。
Seleniumで動的ウェブページのウェブスクレイピングを始めるためのさらに詳しい情報をお探しなら、こちらのチュートリアルをご覧ください。
ウェブスクレイピングにおける正規表現の限界
正規表現はパターンマッチングやテキストからの情報抽出に強力なツールです。開発者はよく正規表現を学び、ウェブスクレイピングに活用しようとします。しかし正規表現単体ではウェブスクレイピングに適していません。正規表現はテキストを対象とし、HTML構造の概念や理解を持ちません。これは結果がHTMLコードの記述方法に大きく依存することを意味します。例えばWikipediaの例では、一部のリンクが正しく抽出されなかったことに気づいたかもしれません:

Pythonコードを編集し、Beautiful Soupが返すHTML文字列を出力するprint(content)を追加すると、問題の原因が明らかになります。その様子は以下の通りです:
<a href="#cite_ref-9">^</a>
ここではtitle属性が欠落していますが、正規表現では<a href="(.*?)" title="(.*?)">.*?</a>という構造を想定していました。 正規表現はHTML要素を認識しないため、エラーを発生させたり一致を停止したりせず、.*?パターンは盲目的に文字を一致させ続け、最終的に".title="(.*?)">.*?</a>"に一致してパターンを終了させました。これにより次の数個のaタグまで飲み込んでしまい、HTMLコードが予想外の形式で記述されている場合、正規表現の使用が意図しない結果を招く可能性があることを示しています。
さらに、HTMLは正規言語ではないため、正規表現だけでは任意のHTMLデータをパースできません。このStack Overflowの回答は、正規表現でHTMLをパースしようとする開発者を皮肉ったことで開発者の間でカルト的な人気を博しています。ただし、正規表現でHTMLデータをパース・スクレイピングできる状況もいくつか存在します。
例えば、既知で限定されたHTMLコードセットがあり、コード構造を完全に把握している場合、正規表現が有効です。HTML内の全てのaタグがhref 属性とtitle属性を持つ固定パターンに従っていると分かっている場合、正規表現で情報を抽出できます。ただし、より優れた堅牢な解決策は、Beautiful SoupのようなHTMLパーサーを使用して要素を見つけ、そこからテキストデータを抽出することです。
テキストデータを抽出したら、正規表現でさらに処理できます。例えば、以下はBeautifulSoupでhrefと title属性を抽出した後、正規表現で英数字以外の文字を含むタグを除外するWikipediaスクレイパーの修正版です:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
結論
正規表現はテキストデータ内のパターンを見つける強力なツールです。その堅牢性から、ウェブスクレイピングで情報を抽出する際によく使用されます。
本記事では、正規表現の概要と、Beautiful Soupを用いたECサイト・Wikipedia・動的ウェブページのウェブスクレイピング手法を学びました。また正規表現の限界と、他のツールとの連携による最適な活用法についても理解を深めました。
正規表現を最大限活用しても、ウェブスクレイピングには課題が伴います。繰り返しスクレイピングを行うと、スクレイパーのIPアドレスがブロックされる可能性があります。また、スクレイパーの正常な動作を妨げるCAPTCHAに直面することもあります。 Bright DataはIP禁止を回避できる強力なプロキシを提供します。世界規模のプロキシネットワークには、データセンタープロキシ、レジデンシャルプロキシ、ISPプロキシ、モバイルプロキシが含まれます。Web Unlockerを使えば、ボット検知を回避し、面倒なくCAPTCHAを解決できます。今すぐ無料トライアルを開始しましょう!






