

このチュートリアルでは、Laravel でのウェブスクレイピングを学び、以下の内容を習得します:
- Laravelがウェブスクレイピングに最適な技術である理由
- 最適なLaravelスクレイピングライブラリ
- LaravelウェブスクレイピングAPIをゼロから構築する方法
さあ、始めましょう!
Laravelでウェブスクレイピングは可能か?
結論:はい、Laravelはウェブスクレイピングに有効な技術です。
Laravelは、洗練された表現力豊かな構文で知られる強力なPHPフレームワークです。特に、ウェブからデータをスクレイピングするためのAPIを即座に作成できます。これは、ページからデータを取得するプロセスを簡素化する多くのスクレイピングライブラリのサポートによって可能になります。詳細なガイダンスについては、PHPでのウェブスクレイピングに関する記事をご覧ください。
Laravelは、スケーラビリティ、他ツールとの容易な連携、そして広範なコミュニティサポートにより、ウェブスクレイピングに最適な選択肢です。その強力なMVCアーキテクチャは、スクレイピングロジックを整理し、保守性を高めるのに役立ちます。これは複雑な、あるいは大規模なスクレイピングプロジェクトを構築する際に非常に便利です。
Laravel向けベストウェブスクレイピングライブラリ
Laravelでウェブスクレイピングを行うのに最適なライブラリは以下の通りです:
- BrowserKit: Symfonyフレームワークの一部であり、HTMLドキュメントとのやり取りのためにウェブブラウザのAPIをシミュレートします。HTMLドキュメントのナビゲーションとスクレイピングには
DomCrawlerに依存しています。このライブラリは、PHPで静的ページからデータを抽出するのに最適です。 - HttpClient: HTTPリクエストを送信するためのSymfonyコンポーネント。
BrowserKitとシームレスに連携します。 - Guzzle: サーバーへのウェブリクエスト送信とレスポンス処理を効率的に行う堅牢なHTTPクライアント。ウェブページに関連するHTMLドキュメントの取得に有用です。Guzzleでのプロキシ設定方法をご覧ください。
- Panther: ウェブスクレイピング用のヘッドレスブラウザを提供するSymfonyコンポーネント。レンダリングや操作にJavaScriptを必要とする動的サイトとのやり取りを可能にします。
前提条件
Laravelでのウェブスクレイピングチュートリアルを実践するには、以下の前提条件を満たす必要があります:
PHP コーディング用の IDE も推奨されます。Visual Studio Code(PHP 拡張機能付き)やWebStormは優れた選択肢です。
LaravelでウェブスクレイピングAPIを構築する方法
このステップバイステップセクションでは、Laravel ウェブスクレイピング API の構築方法を説明します。対象サイトはQuotes スクレイピングサンドボックスサイトとし、スクレイピングエンドポイントは以下を行います:
- ページから引用文のHTML要素を選択
- それらからデータを抽出する
- スクレイピングしたデータをJSON形式で返す
対象サイトの外観は以下の通りです:

以下の手順に従い、Laravelでのウェブスクレイピング手法を学びましょう!
ステップ1: Laravelプロジェクトの設定
ターミナルを開きます。次に、以下の Composercreate コマンドを実行して Laravel ウェブスクレイピングアプリケーションを初期化します:
composer create-project laravel/laravel laravel-スクレイパーこれでlaravel-スクレイパーフォルダに空のLaravelプロジェクトが作成されます。お好みのPHP IDEで読み込んでください。
現在のバックエンドのファイル構造は以下の通りです:
素晴らしい!これでLaravelプロジェクトの準備が整いました。
ステップ2: スクラッピングAPIの初期化
プロジェクトディレクトリで以下のArtisan コマンドを実行し、新しい Laravel コントローラーを追加します:
php artisan make:controller HelloWorldControllerこれにより、/app/Http/Controllersディレクトリに以下のScrapingController.phpファイルが作成されます:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
class ScrapingController extends Controller
{
//
}ScrapingControllerファイルに、以下のscrapeQuotes()メソッドを追加します:
public function scrapeQuotes(): JsonResponse
{
// スクレイピングロジック...
return response()->json('Hello, World!');
}現在、このメソッドはプレースホルダーの「Hello, World!」というJSONメッセージを返します。まもなく、Laravelでのスクレイピングロジックが含まれる予定です。
以下のインポートを忘れずに追加してください:
use IlluminateHttpJsonResponse;scrapeQuotes()メソッドを専用のエンドポイントに関連付けるため、以下の行をroutes/api.php に追加します:
use AppHttpControllersScrapingController;
Route::get('/v1/scraping/scrape-quotes', [ScrapingController::class, 'scrapeQuotes']);素晴らしい!LaravelのスクレイピングAPIが期待通りに動作するか確認しましょう。LaravelのAPIは/apiパスで利用可能です。したがって、完全なAPIエンドポイントは/api/v1/scraping/scrape-quotesとなります。
以下のコマンドでLaravelアプリケーションを起動します:
php artisan serveこれでサーバーはローカルのポート8000で待機状態になります。
cURLを使用して/api/v1/scraping/scrape-quotesエンドポイントにGETリクエストを送信します:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'注: Windowsではcurl をcurl.exeに置き換えてください。詳細はウェブスクレイピング用cURLガイドを参照してください。
以下のレスポンスが返されるはずです:
"Hello, World!"素晴らしい!サンプルスクレイピングAPIは完璧に動作しています。次はLaravelでスクレイピングロジックを定義しましょう。
ステップ3: スクラッピングライブラリのインストール
パッケージをインストールする前に、どのLaravelウェブスクレイピングライブラリがニーズに最適か判断する必要があります。そのためには、対象サイトをブラウザで開きます。ページを右クリックし、「要素を検査」を選択して開発者ツールを開きます。次に「ネットワーク」タブに移動し、ページを再読み込みして「Fetch/XHR」セクションにアクセスします:
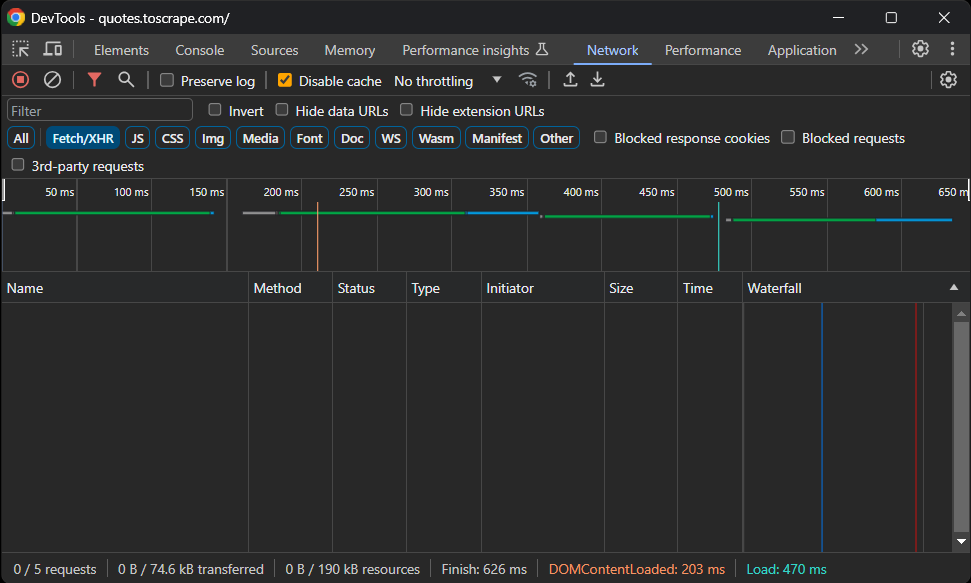
ご覧の通り、このウェブページはAJAXリクエストを一切実行していません。つまり、クライアント側で動的にデータをロードしていないということです。したがって、すべてのデータがHTML文書に埋め込まれた静的ページとなります。
ページが静的であるため、スクレイピングにヘッドレスブラウザライブラリは不要です。ブラウザ自動化ツールの使用も可能ですが、不必要なオーバーヘッドが生じるだけです。推奨されるアプローチは、SymfonyのBrowserKitおよびHttpClientコンポーネントを使用することです。
プロジェクトの依存関係にsymfony/browser-kitとsymfony/http-clientコンポーネントを追加します:
composer require symfony/browser-kit symfony/http-client完了です!これでLaravelでのデータスクレイピングに必要な環境が整いました。
ステップ4: 対象ページのダウンロード
ScrapingControllerでBrowserKitとHttpClientをインポートします:
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;scrapeQuotes()内で、新しいHttpBrowserオブジェクトを初期化します:
$browser = new HttpBrowser(HttpClient::create());これにより、ブラウザの動作をシミュレートしてHTTPリクエストを送信できます。ただし、実際のブラウザでリクエストを実行するわけではない点に注意してください。HttpBrowserはクッキーやセッションの処理など、ブラウザと同様の機能を提供するだけです。
request()メソッドを使用して、対象ページのURLへHTTP GETリクエストを実行します:
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');結果はCrawlerオブジェクトとなり、サーバーから返されたHTML文書を自動的にパースします。このクラスはノード選択やデータ抽出機能も提供します。
クローラーからページのHTMLを抽出することで、上記のロジックが機能することを確認できます:
$html = $crawler->outerHtml();テストのため、APIがこのデータを返すように設定してください。
scrapeQuotes()関数は以下のようになります:
public function scrapeQuotes(): JsonResponse
{
// ブラウザのようなHTTPクライアントを初期化
$browser = new HttpBrowser(HttpClient::create());
// 対象ページのHTMLをダウンロードしてパース
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// ページの外部HTMLを取得して返す
$html = $crawler->outerHtml();
return response()->json($html);
}素晴らしい!これでAPIは以下の内容を返します:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<!-- 簡略化のため省略 ... -->ステップ5: ページコンテンツの調査
データ抽出ロジックを定義するには、対象ページのHTML構造を調査することが不可欠です。
ブラウザで「Quotes To Scrape」を開きます。次に、引用文のHTML要素を右クリックし、「要素を検査」を選択します。ブラウザのデベロッパーツールでHTMLを展開し、分析を開始します:
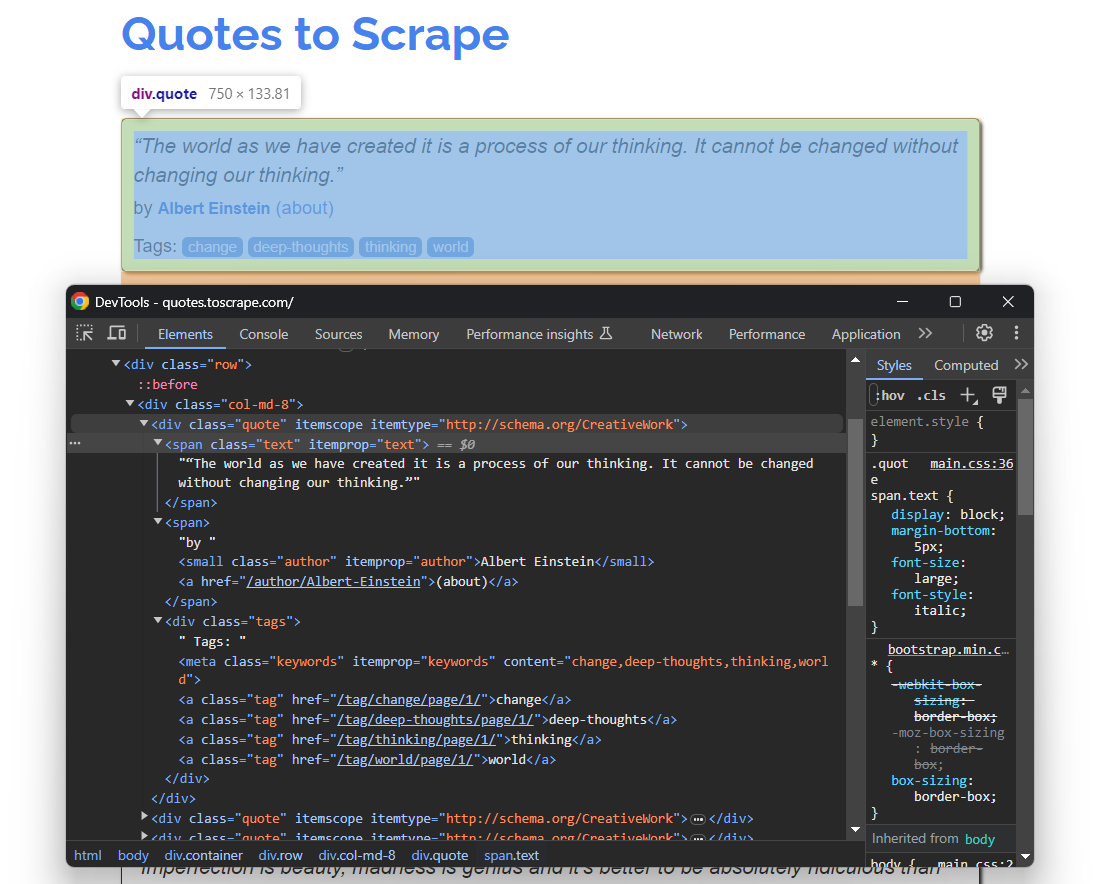
ここで、各引用カードが.quoteHTMLノードであり、以下を含むことに注目してください:
- 引用文テキストを含む
.text要素 - 著者の名前を含む
.authorノード - 複数の
.tag要素(各タグを個別に表示)
上記のCSSセレクタがあれば、Laravelでウェブスクレイピングを行うために必要な要素は全て揃っています。これらのセレクタを使って対象のDOM要素を特定し、次のステップでデータを抽出しましょう!
ステップ6: ウェブスクレイピングの準備
対象ページには複数の引用文が含まれるため、スクレイピングしたデータを格納するデータ構造を作成します。配列が最適です:
quotes = []次に、Crawlerクラスのfilter ()メソッドを使用してすべての引用文要素を選択します:
$quote_html_elements = $crawler->filter('.quote');これにより、指定された.quoteCSS セレクタに一致するページ上のすべての DOM ノードが返されます。
次に、それらを反復処理し、各要素に対してデータ抽出ロジックを適用する準備をします:
foreach ($quote_html_elements as $quote_html_element) {
// 新しい引用クローラーを作成
$quote_crawler = new Crawler($quote_html_element);
// スクレイピングロジック...
}filter()が返すDOMNodeオブジェクトはノード選択メソッドを提供しない点に注意してください。そのため、特定のHTML引用要素に限定されたローカルなCrawlerインスタンスを作成する必要があります。
上記のコードを動作させるには、以下のインポートを追加してください:
use SymfonyComponentDomCrawlerCrawler;DomCrawlerパッケージを手動でインストールする必要はありません。これはBrowserKitコンポーネントの直接依存関係だからです。
すごい!Laravelでのウェブスクレイピング目標に一歩近づきました。
ステップ7: データスクレイピングの実装
foreachループ内で:
.text、.author、.tag要素から必要なデータを抽出- それらで新しい
$quoteオブジェクトを生成 - 新しい
$quoteオブジェクトを$quotesに追加
まず、HTML引用要素内の.text要素を選択します。次にtext()メソッドを使用して内部テキストを抽出します:
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();各引用文はu201cとu201dの特殊文字で囲まれていることに注意してください。PHP のstr_replace()関数を使用して以下のように削除できます:
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);同様に、著者情報を以下のようにスクレイピングします:
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();タグのスクレイピングは少し難しい場合があります。1つの引用文に複数のタグが含まれる可能性があるため、配列を定義し、各タグを個別にスクレイピングする必要があります:
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}filter()が返すDOMNode要素は text()メソッドを公開していません。代わりにtextContent属性を提供します。
Laravelのデータスクレイピングロジック全体は以下のようになります:
// 新しい引用クローラーを作成
$quote_crawler = new Crawler($quote_html_element);
// データ抽出ロジックを実行
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// 生のテキスト情報から特殊文字を除去
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}さあ、いよいよ最終目標に近づきました。
ステップ8: スクレイピングしたデータを返す
スクレイピングしたデータで$quoteオブジェクトを作成し、$quotesに追加します:
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
$quotes[] = $quote;次に、APIレスポンスデータを$quotesリストで更新します:
return response()->json(['quotes' => $quotes]);スクレイピングループの終了時点で、$quotesには以下が含まれます:
array(10) {
[0]=>
array(3) {
["text"]=>
string(113) "私たちが創造した世界は、私たちの思考の産物である。私たちの思考を変えずに世界を変えることはできない。"
["author"]=>
string(15) "Albert Einstein"
["tags"]=>
array(4) {
[0]=>
string(6) "change"
[1]=>
string(13) "deep-thoughts"
[2]=>
string(8) "thinking"
[3]=>
string(5) "world"
}
}
// 簡略化のため省略...
[9]=>
array(3) {
["text"]=>
string(48) "太陽の光のない日は、つまり、夜のようなものです。"
["author"]=>
string(12) "Steve Martin"
["tags"]=>
array(3) {
[0]=>
string(5) "humor"
[1]=>
string(7) "obvious"
[2]=>
string(6) "simile"
}
}
}素晴らしい!このデータは、JSON にシリアル化され、Laravel のスクレイピング API によって返されます。
ステップ 9: すべてをまとめる
Laravel のScrapingControllerファイルの最終的なコードは次のとおりです。
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateHttpJsonResponse;
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class ScrapingController extends Controller
{
public function scrapeQuotes(): JsonResponse
{
// ブラウザのようなHTTPクライアントを初期化
$browser = new HttpBrowser(HttpClient::create());
// 対象ページのHTMLをダウンロードしてパース
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// スクレイピングしたデータの保存先
$quotes = [];
// ページ上のすべての引用HTML要素を選択
$quote_html_elements = $crawler->filter('.quote');
// 各引用HTML要素を反復処理し、
// スクレイピングロジックを適用
foreach ($quote_html_elements as $quote_html_element) {
// 新しい引用クローラーを作成
$quote_crawler = new Crawler($quote_html_element);
// データ抽出ロジックを実行
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// 生のテキスト情報から特殊文字を除去
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}
// 新しい引用オブジェクトを作成
// スクレイピングしたデータで
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
// 引用オブジェクトを引用配列に追加
$quotes[] = $quote;
}
var_dump($quotes);
return response()->json(['quotes' => $quotes]);
}
}テストしてみましょう!
Laravelサーバーを起動:
php artisan serve次に、 /api/v1/scraping/scrape-quotesエンドポイントに GET リクエストを送信:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'以下の結果が返されます:
{
"quotes": [
{
"text": "私たちが作り出した世界は、私たちの思考の産物です。私たちの思考を変えなければ、世界は変わりません。",
"author": "アルバート・アインシュタイン",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
// 簡潔にするため省略...
{
"text": "太陽の光のない日は、ご存知のように、夜のようなものです。",
"author": "スティーブ・マーティン",
"tags": [
"humor",
"obvious",
"simile"
]
}
]
}さあ、これで完了です!100 行にも満たないコードで、Laravel によるウェブスクレイピングを実行しました。
次のステップ
ここで構築した API は、Laravel を使ってウェブスクレイピングを行う場合の基本的な例にすぎません。プロジェクトを次のレベルに引き上げるには、以下の改善点を検討してください。
- ウェブクローリングの実装:対象サイトには複数のページにまたがる引用文が複数存在します。完全なデータ取得にはウェブクローリングが必要な典型的なシナリオです。ウェブクローラーの定義に関する記事を参照してください。
- スクレイピングタスクのスケジュール化:APIを定期的に呼び出すスケジューラを追加し、データをデータベースに保存することで、常に最新のデータを確保します。
- プロキシの統合:同一IPからの複数リクエストは、スクレイピング対策によるブロックを招く可能性があります。これを回避するため、PHPスクレイパーにレジデンシャルプロキシを統合することを検討してください。
Laravelによるウェブスクレイピングを倫理的かつ尊重ある方法で実施する
ウェブスクレイピングは様々な目的で貴重なデータを収集する効果的な方法です。ただし、目的は責任を持ってデータを取得することであり、対象サイトを損なうことではありません。したがって、適切な予防策を講じてスクレイピングに臨むことが重要です。
責任あるKotlinウェブスクレイピングを確保するためのヒント:
- サイトの利用規約を確認し遵守する:スクレイピング前に利用規約を確認してください。著作権、知的財産権、データ利用ガイドラインに関する情報が記載されていることが多いです。
- robots.txtファイルを尊重する:サイトのrobots.txtファイルは、自動クローラーがページにアクセスする方法を定義するルールです。倫理的な実践を維持するため、これらのガイドラインを遵守してください。詳細は、 ウェブスクレイピングのための robots. txtガイドをご覧ください。
- 公開情報のみを対象とする: 公開されているデータに焦点を当ててください。ログイン認証やその他の認可形式で保護されたページのスクレイピングは避けてください。適切な許可なく非公開または機密データを対象とすることは非倫理的であり、法的措置につながる可能性があります。
- リクエスト頻度の制限:短時間に過剰なリクエストを行うとサーバーに負荷がかかり、全ユーザーのサイトパフォーマンスに影響します。レート制限措置が発動し、アクセスがブロックされる可能性もあります。リクエスト間にランダムな遅延を追加し、対象サーバーへの過剰な負荷を回避してください。
- 信頼性が高く最新のウェブスクレイピングツールを利用:評判の良いプロバイダーを優先し、適切に保守・定期更新されているツールを選択してください。これにより最新の倫理的なLaravelウェブスクレイピング手法に沿った運用が保証されます。不明な場合は、最適なウェブスクレイピングサービスの選び方に関する記事をご参照ください。
まとめ
本ガイドでは、LaravelがウェブスクレイピングAPI構築に適したフレームワークである理由を解説しました。また、優れたスクレイピングライブラリをいくつか紹介しました。さらに、ターゲットページからリアルタイムでデータを抽出するLaravelウェブスクレイピングAPIの作成方法を学びました。ご覧の通り、Laravelを用いたウェブスクレイピングは簡潔で、わずか数行のコードで実現できます。
問題は、ほとんどのサイトがデータをボット対策やスクレイピング対策技術で保護していることです。これらの技術は自動化されたリクエストを検知しブロックします。幸い、Bright Dataにはスクレイピングを容易にする一連のソリューションがあります:
- スクレイピングブラウザ: JavaScriptレンダリング機能を備えたクラウドベースの制御可能ブラウザ。CAPTCHA対応、ブラウザフィンガープリント対策、自動リトライなどを自動処理します。PlaywrightやPuppeteerなど主要な自動化ブラウザライブラリと統合可能です。
- Web Unlocker:あらゆるページのクリーンなHTMLをシームレスに返すアンロックAPI。あらゆるウェブスクレイピング対策をかいくぐります。
- ウェブスクレイピングAPI:数十の人気ドメインから構造化されたウェブデータへプログラムでアクセスするためのエンドポイント。
ウェブスクレイピングは扱いたくないが、オンラインデータには興味がある?Bright Dataのすぐに使えるデータセットを探索しよう!
今すぐ登録して無料トライアルを開始しましょう。





