

ウェブスクレイピングとは、専用のツールやプログラムを用いてウェブサイトからデータを自動的に抽出・収集する技術です。データ駆動型の意思決定プロセスを改善したい企業にとって特に有用です。
ただし、ほとんどのウェブサイトに見られる複雑なHTML構造、動的コンテンツ、多様なデータ形式のため、ウェブスクレイピングの効果は使用するツールに依存します。
Scrapy とSeleniumは、ウェブスクレイピングを容易にするために設計された強力なツールです。Scrapyは静的ウェブサイトからデータを抽出するのに対し、Seleniumはウェブブラウザの自動化を実行し、動的ウェブサイトからデータを抽出できます。
本記事では、使いやすさ、パフォーマンスと拡張性、異なるタイプのウェブコンテンツへの適合性、統合機能に基づいて、この2つのツールを比較します。
使いやすさ
ScrapyはPythonベースのウェブスクレイピングツールで、Linux、Windows、macOS、Berkeley Software Distribution(BSD)上で動作します。Scrapyは使いやすいだけでなく、ウェブスクレイピングタスクのための高レベルAPIを提供しており、ウェブスクレイピングプロセスをさらに簡素化するのに役立ちます。
Scrapy を設定するには、インストールし、Python コードを使用していくつかのスパイダーを設定するだけです(これにはウェブスクレイピングの概念に関するある程度の理解が必要です)。 プロジェクトを開始するScrapyコマンドを実行すると、専用のプロジェクトフォルダが生成されます。このフォルダ内にはitems.py、pipelines.py、settings.pyなどのデフォルトPythonファイルが配置されており、簡素化された構造で整理されているため、ウェブスクレイピングを容易に開始できます。
Scrapyは、質問への回答に役立つ厳選された記事や動画を含む詳細なドキュメントを提供しています。また、活発なサブレディットやDiscordコミュニティがあり、様々な議論やトピックに参加できます。
一方、SeleniumはJava、JavaScript、Python、C#など複数プログラミング言語をサポートし、Windows、macOS、LinuxなどScrapyと同様の多くのOSと互換性があります。Scrapyと比較すると、Seleniumは習得が容易ではなく、熟練するにはより多くの時間、労力、場合によってはリソースを要します。
Seleniumを設定するには、Seleniumライブラリをインストールした後、ブラウザ自動化を処理するWebDriverを設定する必要があります。ログインが必要な動的ウェブサイトからデータをスクレイピングする場合、データスクレイピングを開始する前に、ログインプロセスを処理するWeb自動化を設定する必要があります。
Seleniumは豊富なナビゲーション手法を提供し、ウェブページ上の要素を容易に特定できるようカスタマイズ可能です。さらに、クリック、ダブルクリック、ドラッグ、ドロップ、スクロールといった一連のインタラクティブ操作を提供し、ウェブページとのシームレスな対話を実現します。
Seleniumの公式ドキュメントには、Web自動化とウェブスクレイピングの両方に関連する、優れたガイドライン、ステップバイステップの説明、チュートリアルが含まれています。
Seleniumはより汎用的なWeb自動化ツールであるため、規模が大きく多様なコミュニティを有しています。Seleniumの使用中に疑問が生じた場合は、公式ユーザーグループやサブレディットコミュニティが支援を提供します。また、即時対応が必要な問題が発生した場合は、IRCチャットルームを利用できます。
パフォーマンスとスケーラビリティ
ウェブスクレイピングツールの有効性は、大量のデータを迅速に収集するという目的上、その速度に大きく依存します。
Scrapyは静的ウェブページからのコンテンツスクレイピングに優れており、Seleniumよりも高速なデータ抽出を実現します。これは、Seleniumがボタンクリックやフォーム入力などの操作を実行するためにブラウザインスタンスに依存するためです。
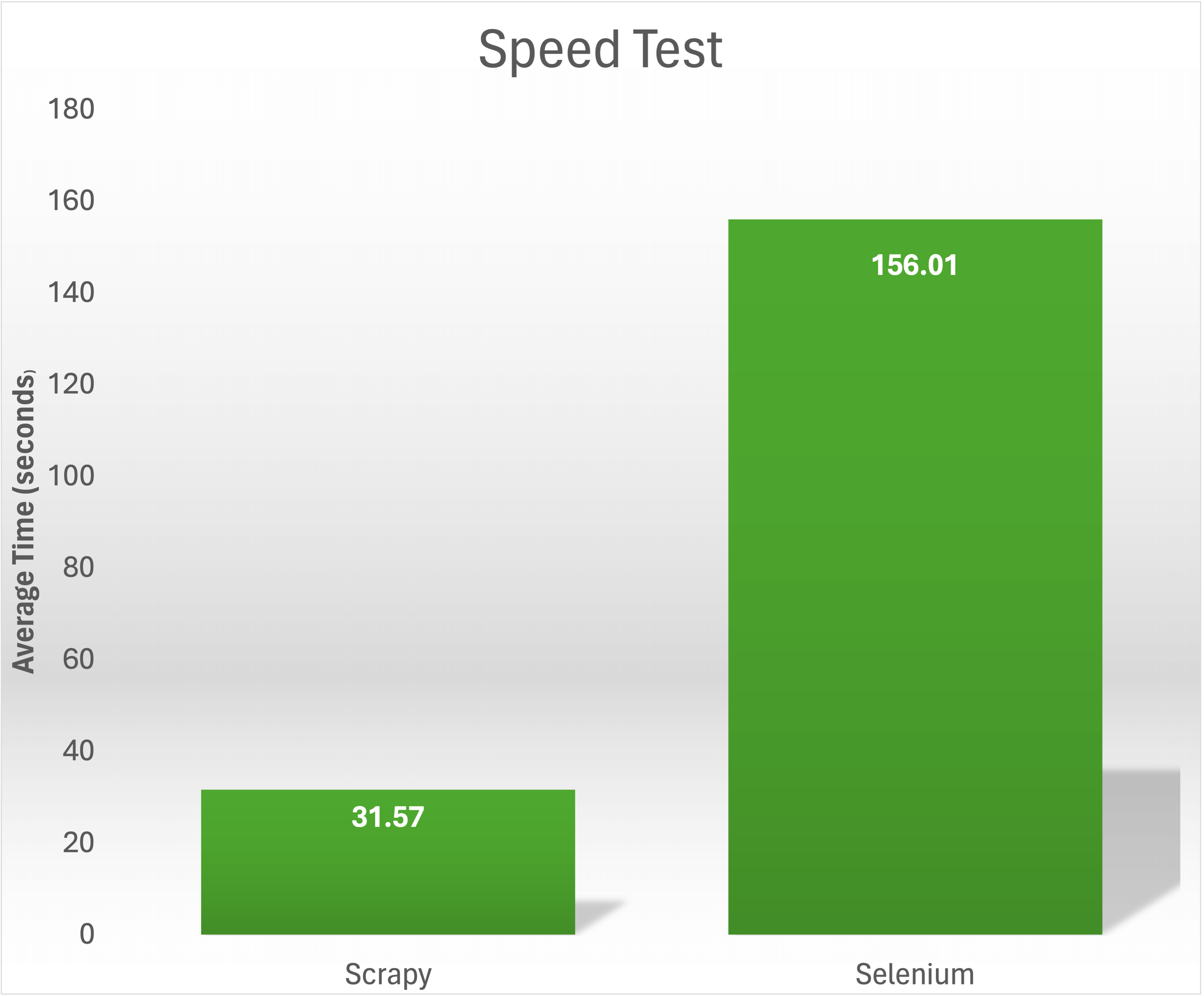
https://books.toscrape.com/ から1,000冊の書籍のタイトルと価格を収集する速度テストでは、Scrapyは31.57秒でタスクを完了しました。一方、Seleniumが同じコンテンツをスクレイピングするのに要した平均時間は156.01秒でした:
Scrapyのアーキテクチャは、レスポンスとアイテムを連続処理することでメモリを効率的に管理し、ウェブページ全体を一度にメモリに読み込む必要性を回避します。また、キャッシュ機能と増分スクレイピングを標準でサポートしており、冗長なリクエストを最小限に抑え、新規または更新されたコンテンツのみを処理することでスケーラビリティを向上させます。
さらに、Scrapyは同時リクエスト数、深さ制限、アイテムパイプラインなどの設定を通じてメモリ使用量を微調整するオプションを提供します。これらの機能により、ウェブスクレイピングプロジェクトの特定の要件に応じてメモリ消費を最適化できます。
Seleniumは、JavaScriptを多用するウェブサイトとのやり取り時に通常大量のメモリを消費し、メモリ使用量の増加につながります。これは特に大規模なスクレイピングプロジェクトにおいて、スケーラビリティとパフォーマンスに悪影響を及ぼす可能性があります。
Scrapyの組み込みミドルウェアであるHTTPCacheMiddlewareは、スパイダーが行うリクエストとその関連レスポンスをキャッシュします。プロジェクトのsettings.pyファイルに以下のコードを追加することでキャッシュを有効化できます:
# HTTPキャッシュの有効化と設定(デフォルトは無効)
HTTPCACHE_ENABLED = True
大規模データスクレイピングに対応するためのSeleniumのスケーリングには、分散システムに複数のインスタンスをデプロイする必要があり、RAMやCPUなどのリソース需要が増加します。
異なるタイプのWebコンテンツへの適応性
インターネット上のウェブサイトの大半は、動的または静的ウェブページで構成されています。ScrapyとSeleniumが両タイプのウェブページをどのように扱うか見てみましょう。
動的ウェブページ
動的ウェブページの大半は、AngularやReactなどのJavaScriptフレームワークによって駆動され、ページ全体を再読み込みせずにコンテンツを更新します。
Seleniumは様々なウェブサイトから動的コンテンツをスクレイピングできますが、ScrapyはJavaScriptで生成された動的コンテンツのスクレイピングを本質的にサポートしていません。この機能を得るには、SeleniumやSplashなどのツールとScrapyを統合する必要があります。
静的ウェブページ
静的ウェブページは、動的ページと比較してインタラクションが限られており、通常はコンテンツの閲覧やリンクのクリックのみが可能です。
前述のように、Seleniumは静的ページをスクレイピングできますが、この作業に最適なツールとは言えません。対照的に、Scrapyは静的データのスクレイピングに優れており、必要な情報を収集するためのスムーズで効率的な体験を提供します。
統合機能
Scrapyは、スクレイピングしたデータを保存するために、MySQL、PostgreSQL、MongoDBなどのデータベースを含む、ほとんどのPythonツールと容易に統合できます。SQLAlchemyなどのオブジェクトリレーショナルマッパー(ORM)を使用して、リレーショナルデータベースへのデータ保存プロセスを簡素化することも可能です。データをさらに処理・分析したい場合は、Python用の人気データ操作・分析ライブラリであるpandasを使用できます。
ScrapyはDjangoやFlaskなどのWebフレームワークとも統合可能で、ウェブスクレイピング機能を組み込んだWebアプリケーションを構築できます。さらにFastAPIとの統合により、非同期処理をサポートした高性能Web APIを構築でき、スクレイピングリクエストの効率的な処理に適しています。
一方、Seleniumはブラウザドライバを提供し、Selenium WebDriver APIとブラウザ間の仲介役として機能します。WebDriverをダウンロードしてインストールすることで、任意のウェブブラウザと統合できます。Seleniumは現在、Chrome、Edge、Firefox、Safari用のブラウザドライバを提供しています。
Selenium は、Web アプリケーションの機能を自動的にテストするためにも使用できますが、組み込みのテストフレームワークは備えていないことに留意してください。Selenium は、CodeceptJS、Helium、Selenide などの他の一般的なテストフレームワークと統合することができます。
Selenium は、Jenkins や Travis CI などの CI ツールと統合して、継続的インテグレーション、継続的デリバリー (CI/CD) パイプラインの一環として自動化スクリプトを自動的に実行できるようにしていましたが、現在では、継続的なテストとデプロイプロセスをサポートするGitHub Actionsですべてを実行しています。
Scrapy は、プロキシ IP およびポートをリクエストパラメータとして渡すことで、Bright Dataなどのさまざまなプロキシサービスプロバイダと統合することができます。この方法は、プロジェクトに特定のプロキシを使用したい場合に推奨されます。
たとえば、プロキシサーバーと統合したい場合は、次のように pipコマンド pip3 install scrapyを使用して Scrapy をインストールできます。
# scrapy モジュールをインポート
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# プロキシ接続
meta={"proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}
ここでは、Scrapyをインポートし、ウェブサイトから書籍リストをスクレイピングするためのBookSpiderクラスを定義しています。このクラスはScrapyのspiderクラスを継承しています。start_requests()メソッドは指定されたURLとプロキシを使用してリクエストを開始し、parse()メソッドはCSSセレクタを使用して書籍のタイトルと価格を抽出します。
一方、SeleniumはChromeDriverやgeckodriverなど様々なブラウザドライバーを通じて、プロキシの直接的な統合をサポートしています。Selenium WebDriverをプロキシサーバー経由でHTTPリクエストをルーティングするよう設定するだけで済みます。
例えば、Bright Dataが提供するプロキシIPとポートを指定することで、Seleniumをプロキシと統合できます。以下のように記述します:
#seleniumモジュールのインポート
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# プロキシ設定
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Selenium オプション : Bright Data のプロキシ認証情報との連携
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Selenium WebDriver のインスタンス化
driver = webdriver.Chrome(options=options)
# 使用例: ウェブページのスクラッピング
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# ドライバーを閉じる
driver.quit()
ここでは、必要なSeleniumモジュールをインポートし、プロキシ設定を構成します。次に、定義されたプロキシサーバーを使用するようにChromeを設定し、WebDriverをインスタンス化、ウェブページ(「https://example.com」)をスクレイピング、ページソースを出力し、WebDriverを閉じて処理を終了します。
結論
本記事では、2つの人気ウェブスクレイピングツールであるScrapyとSeleniumを比較しました。
Scrapyは静的ウェブサイトのデータ抽出に最適な、使いやすいPythonベースのスクラッピングツールです。一方、Seleniumは複数のプログラミング言語を使用した自動化とスクラッピング機能を提供し、様々なウェブブラウザをサポートします。動的コンテンツやJavaScriptでレンダリングされたコンテンツをスクレイピングする場合に優れた選択肢です。
どちらのツールを使用する場合でも、Bright Dataのようなデータプラットフォームの利用が推奨されます。これにより、地理的制限やブロックの回避、CAPTCHAの解決といった機能をウェブスクレイピングスクリプトに追加できます。さらにBright DataのAPIとSDKを活用すれば、より広範なスクレイピング要件に対応でき、プロジェクトの効率性、速度、精度、拡張性を確保できます。 データ収集をさらに進化させたいですか?カスタムデータセットをご購入ください(無料サンプルあり)。




