

この記事では、LLM応答の強化における役割や構成要素を含め、RAGに関するすべてを学びます。
RAGとは
RAGは機械学習(ML)技術であり、従来のLLMをさらに一歩進め、検索(リトリーバル)システムと連携させます。固定された訓練データだけに依存するのではなく、RAG搭載モデルはデータベース、文書、さらにはウェブといった外部ソースを活用して関連情報を発見し、応答の質を向上させます。この場での情報検索と言語生成の組み合わせにより、応答の精度と最新性が向上します。
検索+生成
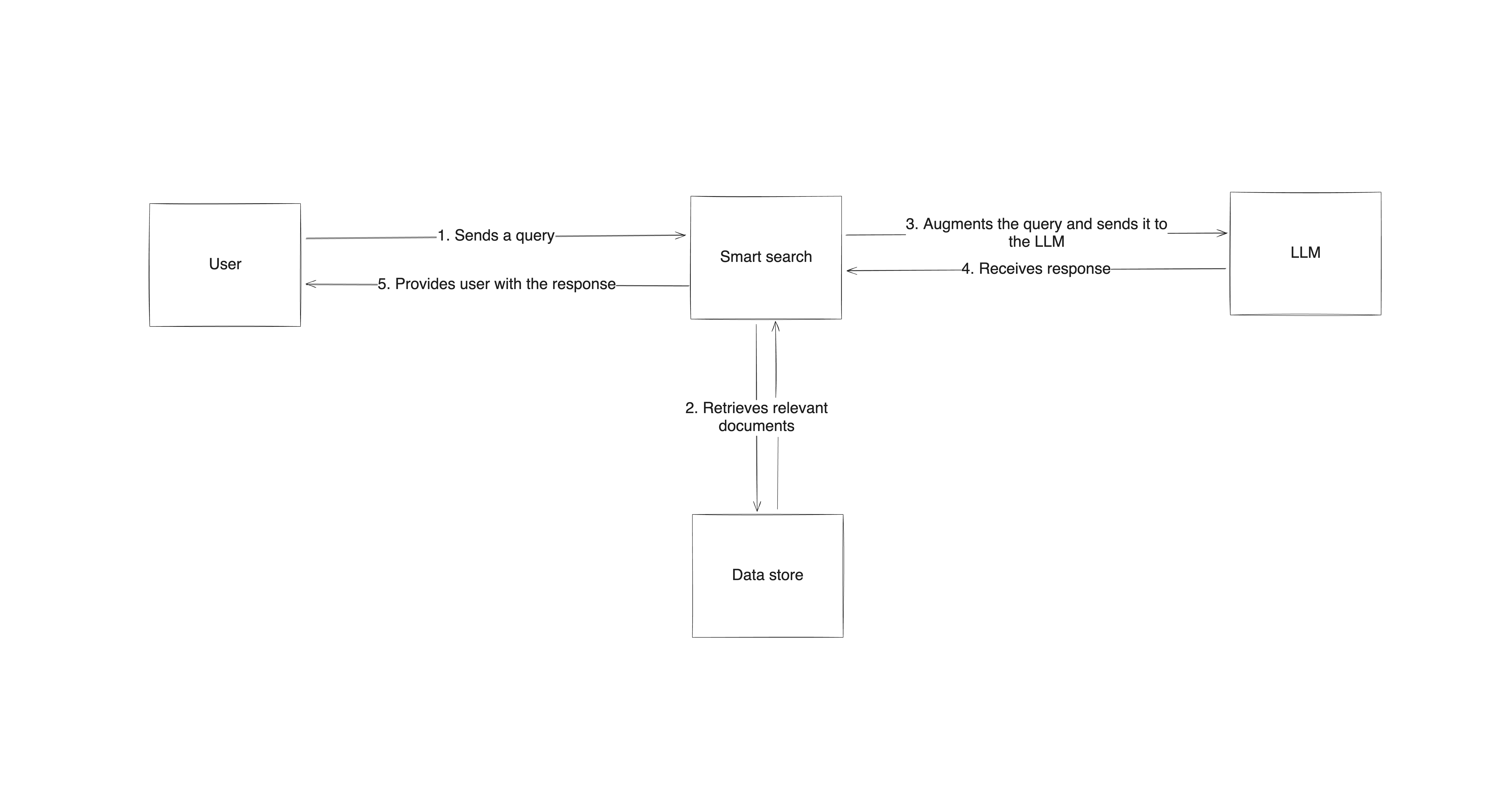
RAGは3つの要素を組み合わせることで機能します:検索(リトリーバル)システム、言語モデル本体、そして両者を統合するプロセスです。質問を受けると、RAGシステムはまずリトリーバルコンポーネントを用いて、言語モデルのトレーニングデータセット外にある関連データを探します。 次に、元のプロンプトを修正し、このデータで補強します。更新されたプロンプトは生成コンポーネント(LLM)に渡され、LLMは自身の学習済みパターンと新たなコンテンツの両方を使用して応答を生成します。これにより、出力は既存のトレーニングの産物であるだけでなく、ソースから直接取得した実在の検証済み情報に基づいたものとなります。
RAGは検索と生成の力を巧みに融合させ、従来型言語モデルの欠点を知的に補完します。より信頼性の高い正確な回答を提供し、多様なトピックに適応できるため、最新情報や専門知識が必要なアプリケーションに最適です。
LLMに拡張が必要な理由
LLMは人間のような応答を生成する点で印象的ですが、欠点がないわけではありません。
幻覚のリスク
LLMの最大の課題の一つは、説得力はあるが誤った情報を生成する「幻覚」のリスクです。これはLLMが大量の静的データセットで訓練され、訓練期間外の更新情報や事実へのリアルタイムアクセスを欠いているため発生します。
さらに、LLMは問題解決マシンではなく、テキスト補完モデルである点も重要です。その最終目標は、与えられたプロンプトに対する「正しい応答に最も近い応答」を生成することであり、応答が必ずしも正確である必要はありません。決定論的アルゴリズムを用いて応答を導出しないため、いずれ幻覚を生成する運命にあるのです。
情報検証
さらに、LLMは新規情報を検証したり、回答をリアルタイム情報源と照合したりできないため、事実を見逃したり誤って伝えたりしやすい。
知識の限界
もう一つの制限は知識のカットオフです。LLMは特定の時点までのデータで訓練されているため、カットオフ以降の出来事や発見について本質的に認識が欠如しています。
信頼できる情報源
LLMは信頼できる情報源を引用することも困難であり、ユーザーは応答の正確性に疑問を抱く可能性があります。最新の情報源へのアクセスや情報の検証手段がない場合、これらのモデルの信頼性は損なわれがちです。
RAG:LLMの限界を解決する手法
前述の通り、RAGは回答を現実の最新データに裏付けさせることでLLMの限界に対処するよう設計されています。
関連情報源からの最新情報
LLMがクエリを受け取った際、RAGは静的なトレーニングデータのみに依存するのではなく、文脈的に関連する外部ソースから最新情報を取得することを可能にします。この仕組みにより、実際の文書やデータに基づいた応答が実現され、幻覚(誤った情報)のリスクが効果的に低減されます。外部ソースを積極的に照会するため、RAGは最近の出来事、新技術、あるいは標準的なLLMが知識の限界(知識カットオフ)により見逃すような情報を含む質問にも回答できます。 例えばカスタマーサポートのシナリオでは、RAGがナレッジベースから最新のポリシー更新を取得し、回答が企業の現行文書に沿っていることを保証します。
透明性の向上
正確性に加え、RAGは応答の出典を明示することで透明性を高めます。特定かつ関連性の高い文書からデータを抽出するため、推論の過程が明確になり、ユーザーは情報の出所を把握できます。この検証可能性はユーザーの信頼を高めるだけでなく、法的・金融サービスなど、明確で裏付けのある回答が求められる分野において、RAG搭載モデルの有用性をさらに高めます。
RAGの主な活用事例
RAGは、正確かつ最新の情報を必要とするアプリケーション、特に変化の速い分野で真価を発揮します。以下にRAGの代表的なユースケースを挙げます。
カスタマーサポートの自動化
RAGは企業のナレッジベースやヘルプ記事を活用することでカスタマーサポートを変革します。最新のドキュメント、製品情報、トラブルシューティングのヒントから引用し、顧客の問い合わせに即座に回答します。これにより、顧客は特定のニーズに合わせた正確な回答を得られると同時に、サポート担当者は日常的な質問に圧倒されることがなくなります。
法務・金融サービス
これらの分野では、正確であるだけでなく、信頼できる情報源に遡及可能な情報が求められます。例えば、法律専門家は意見形成時にRAGを活用して関連判例や規制を抽出できます。金融アナリストはRAGで最新の市場レポートやデータを取得し、タイムリーかつ具体的な情報に裏付けられた洞察をクライアントに提供できます。
研究・コンテンツ制作
ライター、ジャーナリスト、研究者はRAGを活用し、信頼できる情報源から正確な参考文献を抽出できます。これにより、事実確認や情報収集のプロセスが簡素化・高速化されます。記事の草稿作成でも研究データの収集でも、RAGは関連性が高く信頼できる資料への迅速なアクセスを容易にし、クリエイターが高品質なコンテンツ制作に集中できるようにします。
対話型エージェントとチャットボット
RAGを統合することで、対話型エージェントやチャットボットはより正確で文脈を認識した回答を提供し、ユーザー体験を向上させます。例えば、医療チャットボットは最新の医学研究情報を取得でき、技術サポートボットは最新のデバイスファームウェア更新情報を引き出せます。RAGがリアルタイムデータ取得と言語生成を組み合わせる能力は、応答の質と信頼性の両方を高めます。
GPTモデルを用いたRAGチャットボット構築の詳細はこちら。
RAGの課題と限界
RAGは言語モデルに大きな価値をもたらす一方で、固有の課題も伴います。
品質と正確性
プロンプトを強化するために取得される情報の品質と正確性は主要な課題の一つです。RAGは外部ソースに依存するため、モデルの応答品質は取得データに左右されます。取得システムが関連性のない、あるいは不正確な文書を返した場合、生成される応答は依然として不十分となる可能性があります。高品質な取得を確保することは重要であり、データの関連性と正確性を維持するためには、微調整と定期的な更新がしばしば必要となります。
計算コストと複雑性
その他の課題には、RAGシステムを運用する際の計算コストと複雑さが含まれます。スタンドアロンのLLMとは異なり、RAGには強力な検索システムと、取得した情報を容易に統合できるモデルの双方が必要であり、これはリソースを大量に消費する可能性があります。この増加した計算負荷は、特に大量のデータをリアルタイムで検索または処理する必要がある場合、応答速度を低下させる可能性があります。RAGを導入する組織は、精度とパフォーマンスのバランスを取り、速度を損なわずに検索を設定する方法を見つける必要があることが多いです。
RAGの成功は、構造化され信頼性の高いデータソースへのアクセスに大きく依存する。信頼性が高く適切に整理された外部データベースがなければ、検索システムは有用な情報を抽出するのに苦労する可能性がある。さらに、すべてのデータソースが容易にアクセス可能または手頃な価格であるとは限らず、これは小規模組織にとって障壁となり得る。
こうした課題はあるものの、慎重な設定と信頼性の高いデータソースがあれば、RAGは幅広いアプリケーションに変革的なメリットをもたらす可能性があります。
実践におけるRAGの実装
RAGシステムを構築するには、言語モデルと効果的な検索メカニズムを連携させ、外部データへのアクセスを可能にする必要がある。
プロセスは、検索システムと言語モデルを統合した高レベルなアーキテクチャの構築から始まります。ユーザーがクエリを送信すると、検索システムが外部ソースから関連情報を検索し、その情報をプロンプトと共にLLMに送信します。LLMは自身の知識と検索されたデータの両方に基づいて応答を生成します。このアプローチにより、応答は情報に基づくと同時に、最新かつ信頼性の高い情報に文脈的に裏付けられたものとなります。
RAG実装には専用ツールとフレームワークが必要
実用面では、RAGの実装には情報の検索、処理、応答生成を処理できる特定のツールとフレームワークが必要です。LangChainやHaystackのようなライブラリは、応答生成プロセスへの検索統合のための既製コンポーネントを提供するため、人気のある選択肢です。
例えば、LangChainはプロンプトの構造化、データの検索、結果をLLMに直接パイプライン化するツールを提供します。一方、Haystackは高性能な検索に特化しており、データベース、文書、さらにはウェブからの情報取得を可能にします。これらのツールは様々なデータソースに対応するようカスタマイズできるため、多様なRAGアプリケーションに高い適応性を発揮します。
RAGは既存LLM上に構築されたフレームワーク
大局的に見ると、ファインチューニングなどの手法とは異なり、RAGは主要なLLMの構造や構成要素に影響を与えません。既存のLLMの上に構築された単なるフレームワークであり、モデルに送信するプロンプトの品質向上を支援するものです。RAGは単なる高度なプロンプトエンジニアリングに過ぎないという意見もある。RAGシステムに入力される元のプロンプトと、最終応答生成前に生成される拡張プロンプトを比較すれば、その主張の根拠が理解できるだろう。理解を深めるための簡略化した例を以下に示す:
- 生のプロンプト
最新の気候変動がサンゴ礁に与える影響は何か?
- 応答(RAGなしのLLMによる)
珊瑚礁は水温上昇と海洋酸性化の影響を受け、これにより珊瑚の白化現象が発生し、海洋生態系が破壊される。
- 拡張プロンプト(RAG搭載)
取得したデータを使用:NOAAの2024年報告書は、海洋温暖化がカリブ海と太平洋で大規模なサンゴ白化現象を引き起こし、影響地域でサンゴ被覆率が40%減少したことを強調している。酸性化もサンゴの骨格を弱体化させ、嵐による損傷への脆弱性を高めている。これに基づき、以下の質問に回答せよ:最新の気候変動がサンゴ礁に与える影響は何か?
- 回答(RAG搭載LLMによる)
最近のNOAA報告書によれば、海洋温暖化が特にカリブ海と太平洋で大規模な白化現象を促進しており、一部地域ではサンゴ被覆率が40%減少している。酸性化もサンゴ骨格を損傷し、脆弱性を高めている。
この事実は主張を裏付けるように見えるが、重要なのは、元のクエリの文脈においてLLMに適切なデータを提供することがRAG設定の焦点である点を強調することだ。 データストアによっては、検索コンポーネントは単純なSQLクエリから、Google検索やウェブクロールといった複雑なものまで様々です。そしてデータを取得したら、プロンプトに追加する前に、データを正確かつ効率的に優先順位付けし要約する必要があります。この2つのステップにより、RAGはあらゆるプロンプトエンジニアリング技術よりもはるかに複雑になります。
RAG実装には大量の高品質データが必要
データストア自体に関しては、ほとんどのRAGシステムがこれを必要とし、大量のデータが正確で最新かつドメイン特化されていることが望ましいです。このようなデータセットの作成と維持は時間と労力を要します。Bright Dataのような公開データプロバイダーは、検索システムが新鮮で高品質な情報を扱うことを保証する膨大なデータセットを提供することで、この作業を容易にします。
これらのソースには、ウェブデータから構造化データセットまであらゆるものが含まれ、モデルの関連性を大幅に向上させます。Bright Dataのデータセットと統合することで、RAGモデルは最新情報にアクセス可能となり、応答精度が向上するだけでなく、気象システムや物流・サプライチェーン管理など、リアルタイムデータが不可欠な分野でも役立ちます。
Bright Dataが公共データ取得に果たす役割
ウェブ全体から高品質な公開データセットを提供するBright Dataは、RAGシステムにとって貴重なリソースとなり得ます。RAGが高品質で最新の情報を必要とする性質上、Bright Dataのデータセットは時事問題からニッチな研究まで、多様な用途に関連するコンテンツを抽出することを可能にします。
様々な分野にわたる構造化データ
Bright Dataのデータセットには、eコマース、金融市場、ニュースなど、様々な分野にわたる構造化データが含まれており、RAGシステムに統合することでモデルの精度と関連性を向上させることができます。これにより、カスタマーサポートや競合分析などの分野で重要な、最新情報や業界固有の情報を必要とする質問に対して、LLMが正確に応答できるようになります。
大規模な公開データへのアクセスとフィルタリング
独自にウェブからデータを収集する場合、Bright DataAPIと広範なプロキシインフラにより、データ利用ポリシーを遵守しつつ大規模な公開データへのアクセスとフィルタリングが可能です。これは動的な情報取得を必要とするRAGアプリケーションで非常に有用です。例えば金融サービス向けRAG環境では、更新された株式市場データや規制関連ニュースを継続的に取得し、モデルのリアルタイム洞察提供能力を強化できます。
RAGシステムのデータソースとしてBright Dataを利用することで、データストアの維持管理負担が軽減され、プロンプト拡張と応答生成の精緻化に集中できます。
結論
RAGはLLMの能力を飛躍的に向上させ、外部ソースからのリアルタイムデータを取り込むことで知識の断絶や幻覚といった主要な制限を克服します。RAGを通じてモデルは最新かつ検証済みの情報にアクセス可能となり、応答の関連性と信頼性の両方が向上します。この技術により、言語モデルは静的な知識リポジトリから動的で文脈を認識するエージェントへと変貌を遂げます。
高品質なリアルタイムデータをRAG実装に統合することで、AIアプリケーションの精度、関連性、信頼性を向上させられます。カスタマーサポート、財務分析、医療、その他あらゆる業界において、RAGの活用はエンドユーザー体験の大幅な改善に寄与します。
Bright Dataは、信頼性の高い構造化された公開データを調達するためのスケーラブルなソリューションを提供することで、RAG実装の開発を容易にします。豊富なデータセットを提供するBright Dataは、様々な業界やアプリケーションにおいて、RAGシステムが正確で最新の応答を提供することを支援します。
今すぐ登録して無料トライアルを開始しましょう。ダウンロード可能な無料データセットサンプルも含まれています!






