

Google フライトは、航空券の価格、スケジュール、航空会社の詳細などの豊富なデータを提供する、広く利用されているフライト予約サービスです。残念ながら、Googleはこのデータにアクセスするための公開APIを提供していません。ただし、Webスクレイピングを使えば、Google フライトのデータを抽出することができます。
この記事では、Pythonを使ってGoogle フライトの堅牢なスクレイパーを構築する方法を紹介します。各ステップを一つひとつ、順を追って明確に説明していきます。
Google フライトをスクレイピングする理由
Google フライトのスクレイピングには、次のような利点があります。
- 継続的にフライト料金を追跡
- 価格動向の分析
- フライトの予約に最適な時期を見極める
- 異なる日程と航空会社の料金を比較
旅行者にとっては、お得な情報を見つけてお金を節約することにつながります。企業にとっては、市場分析、競合情報、効果的な価格戦略の策定に役立ちます。
Google フライトスクレイパーの構築
当社が構築するスクレイパーは、出発空港、目的地、旅行日、航空券の種類(片道または往復)などの詳細を入力することができます。往復航空券を予約する場合は、帰国日も入力する必要があります。スクレイパーは、利用可能なすべてのフライトを読み込み、データをスクレイピングし、結果をさらに分析できるようJSONファイルに保存します。
Pythonを使ったWebスクレイピングに馴染みのない方は、こちらのチュートリアルをご覧ください。
1.Google フライトから抽出できるデータの種類
Google フライトでは、航空会社名、出発時刻と到着時刻、合計所要時間、経由地数、航空券の価格、環境影響データ(CO2 排出量など)といったさまざまなデータが提供されています。
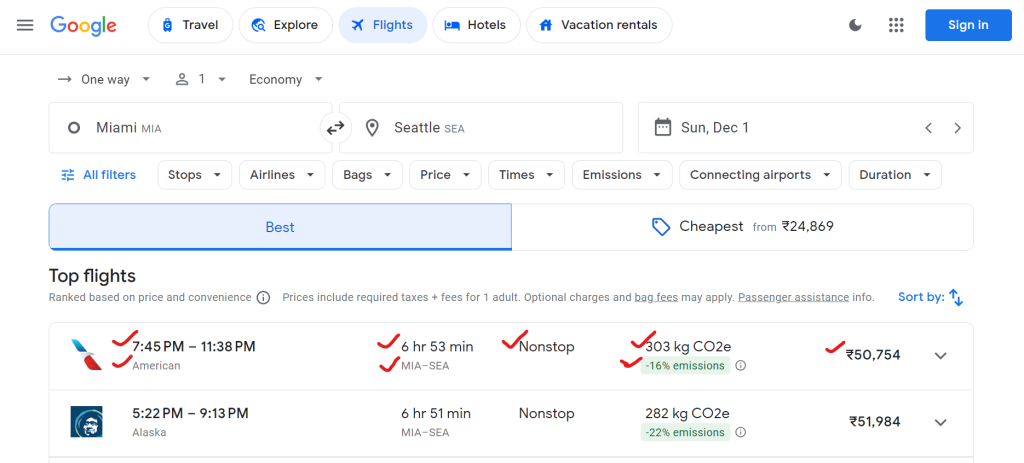
スクレイピングできるデータの例は次のとおりです:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2.環境のセットアップ
まず、スクレイパーを実行する環境をシステムに構築しましょう。
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.flight-scraper-envScriptsactivate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwrightは、ブラウザの自動化や、Google フライトのような動的なウェブページとのやりとりを得意とします。Tenacityを使ってリトライ処理を実装します。
Playwrightを初めて使う場合は、必ずPlaywrightを使ったWebスクレイピングのガイドを確認してください。
3.データクラスの定義
Pythonのデータクラスを使用すると、検索パラメータとフライトデータをきれいに構造化することができます。
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
ここで、SearchParametersクラスは出発地、目的地、日付、チケットタイプなどのフライト検索の詳細を保存し、FlightDataクラスは航空会社、価格、CO2排出量、その他の関連情報を含む各フライトに関するデータを保存します。
4.FlightScraperクラスのスクレイパーのロジック
主なスクレイピングのロジックはFlightScraperクラスにカプセル化されています。詳しい内容は以下の通りです。
4.1 CSS セレクタの定義
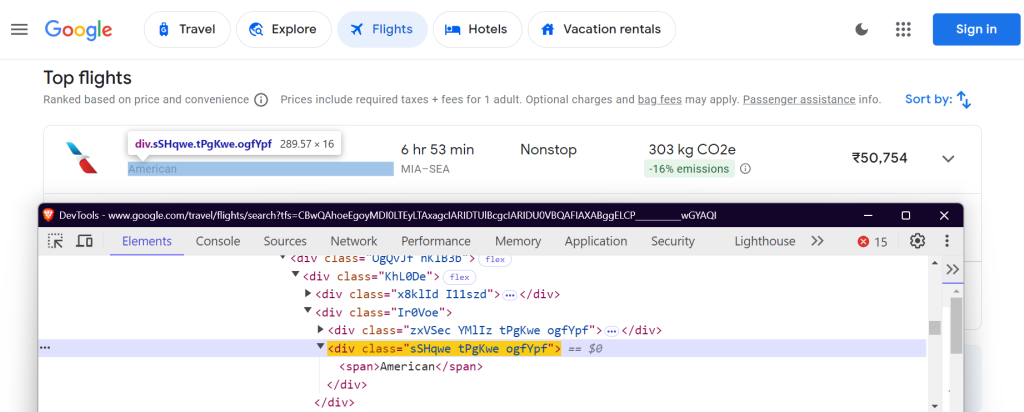
データを抽出するには、Google フライトページで特定の要素を見つける必要があります。これはCSSセレクタを使って処理します。以下は、FlightScraperクラスでのセレクタの定義です:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
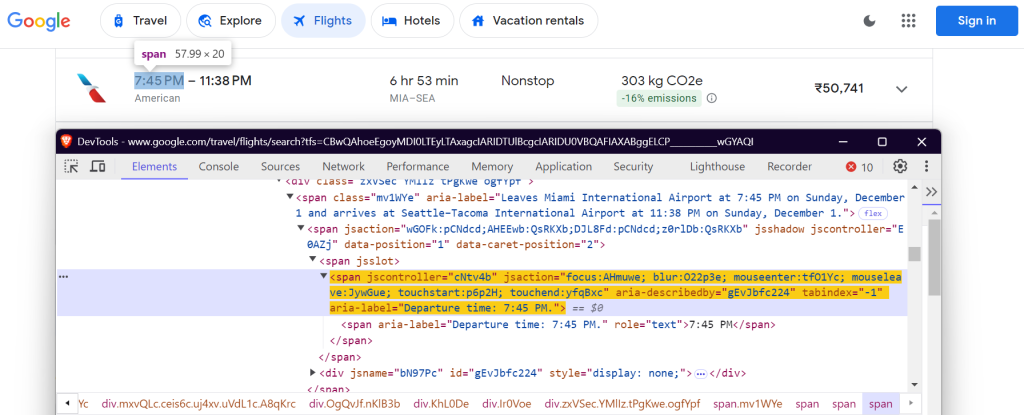
"departure_time": 'span[aria-label^="Departure time"]',
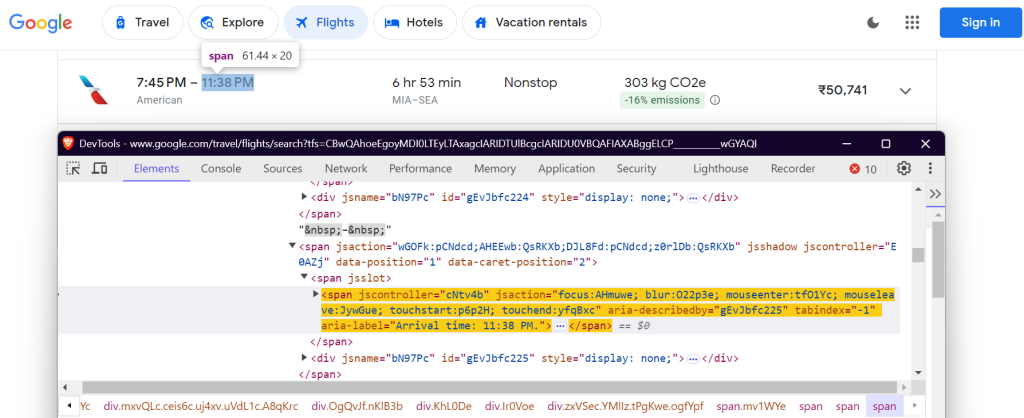
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
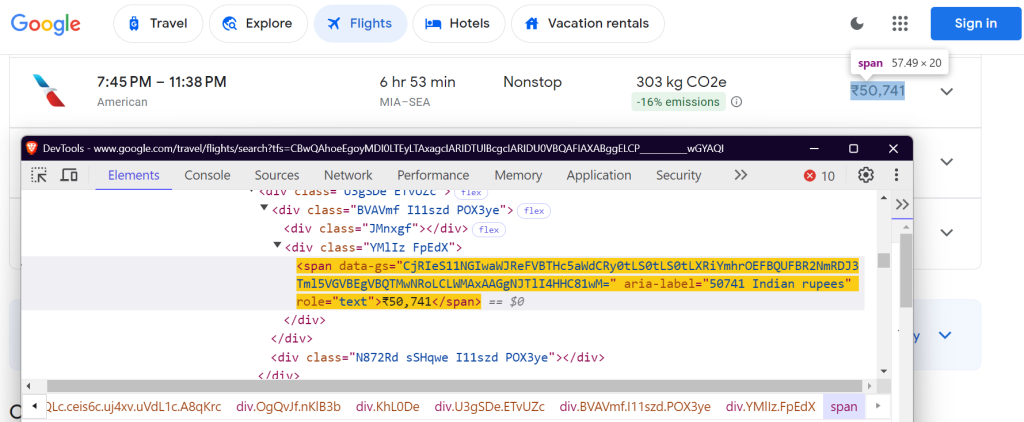
"price": "div.FpEdX span",
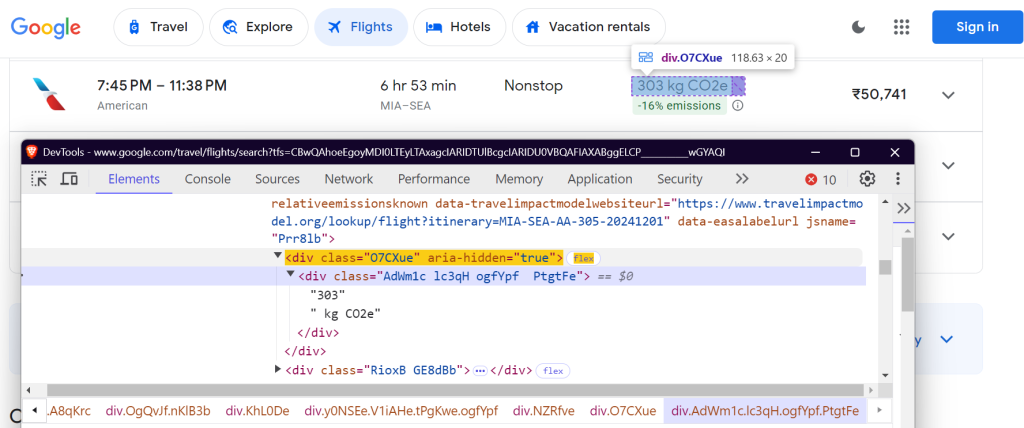
"co2_emissions": "div.O7CXue",
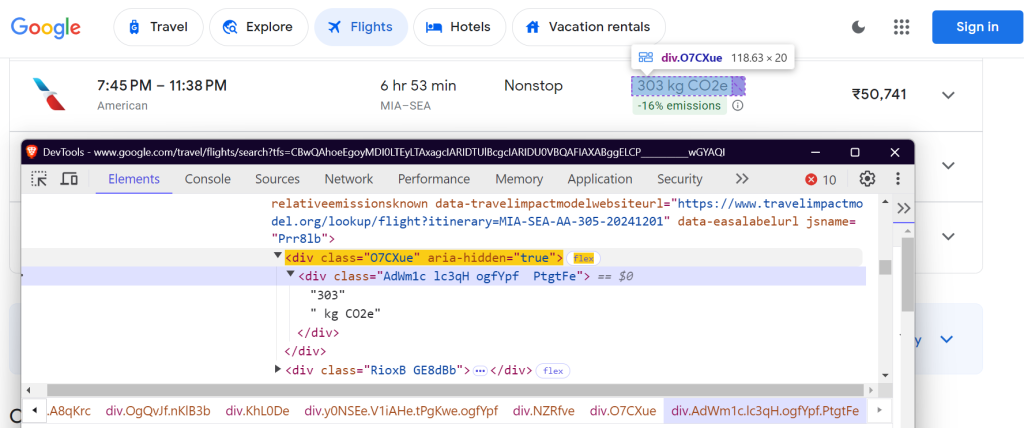
"emissions_variation": "div.N6PNV",
}
これらセレクタは、航空会社名、フライト時間、所要時間、経由地、料金、CO2排出量データを対象としています。
航空会社名:
出発時刻:
到着時刻:
飛行時間:

経由地の数:
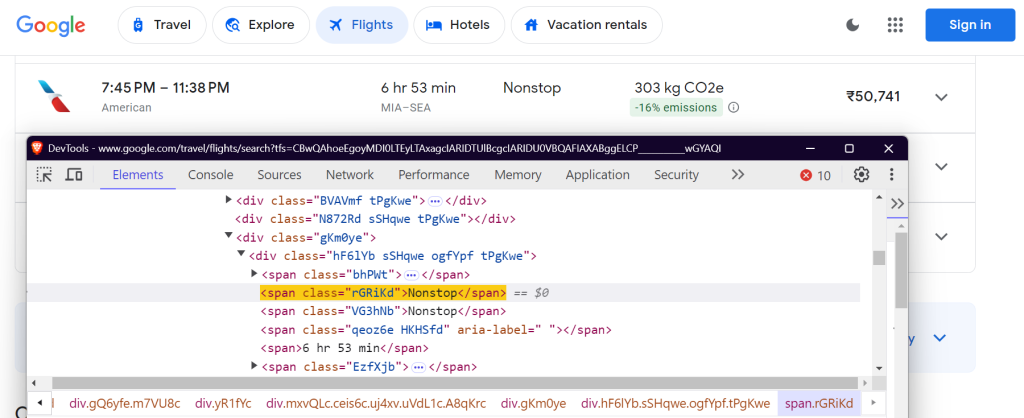
料金:
CO2e:
CO2排出量の変動:
4.2 検索フォームへの入力
_fill_search_formメソッドは、出発地、目的地、日付の詳細を検索フォームに記入するシミュレーションを行います。
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 すべての結果を読み込み
Google フライトはページネーションを使ってフライトを読み込みます。利用可能なフライトをすべて読み込むには、「その他のフライトを表示」ボタンをクリックする必要があります:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 フライトデータの抽出
フライトが読み込まれたら、フライトの詳細をスクレイピングできるようになります:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5.リトライ処理の追加
スクレイパーの信頼性を高めるには、tenacityライブラリを使用してリトライロジックを追加してください:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6.スクレイピングの結果を保存
今後の分析に備えて、スクレイピングしたフライトデータをJSONファイルに保存します。
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7.スクレイパーの実行
Google フライトスクレイパーを実行する方法は次のとおりです:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
最終結果
スクレイパーを実行すると、フライトデータは次のようなJSONファイルに保存されます:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
完全なコードはGitHub Gistにあります。
Google フライトのスクレイパーをスケーリングする際の一般的な課題
Googleフライトのデータスクレイピングをスケーリングする場合、IPブロックやCAPTCHAのような課題に遭遇することはよくあります。たとえば、スクレイパーを使用して短時間で多くのリクエストを送信すると、ウェブサイトがIPアドレスをブロックする可能性があります。これを回避するには、手動のIPローテーションを使用するか、上位プロキシサービスのいずれかを選択します。自分のユースケースに最適なプロキシタイプがわからない場合は、Webスクレイピングに最適なプロキシに関するガイドをご覧ください。
もう1つの課題は、CAPTCHAの処理です。ボットトラフィックが疑われる場合、CAPTCHAが解けるまでスクレイパーをブロックするために、ウェブサイトはよくこれを使用します。手作業でこれを処理するのは時間がかかるし、複雑です。
では、解決策は何でしょう?詳しく見てみましょう。
解決策:Bright DataのWebスクレイピングツール
Bright Dataは、お客様のWebスクレイピング作業を簡素化し、効率的にスケーリングするために設計された様々なソリューションを提供しています。これらの一般的な課題を克服するために、Bright Dataがどのようにお役に立てるかを探ってみましょう。
1. 住宅用プロキシ
Bright Dataの住宅用プロキシは、洗練されたターゲットウェブサイトにアクセスし、スクレイピングする能力を提供します。住宅用プロキシを使えば正規の住宅用接続を介してWebスクレイピングリクエストをルーティングできます。住宅用プロキシを介して送信したリクエストは、特定の地域または地域の正規ユーザーからのものとして目的のウェブサイトに認識されます。そのため、IP制限を用いたスクレイピング対策がされているページへのアクセスに有効です。
2. Webアンロッカー
Bright DataのWebアンロッカーは、CAPTCHAや制限に直面しているスクレイピングプロジェクトに最適です。Webアンロッカーは、これらの問題を手動で処理する代わりに、サイトブロックの変化に適応して、高確率(通常は 100%)で、自動的に問題を解決します。1つのリクエストを送信するだけで、残りはWebアンロッカーが処理します。
3. スクレイピングブラウザ
Bright Dataのスクレイピングブラウザは、PuppeteerやPlaywrightのようなヘッドレスブラウザを使用する開発者にとって、もう一つの強力なツールです。従来のヘッドレスブラウザとは異なり、スクレイピングブラウザはCAPTCHAの解決、ブラウザのフィンガープリンティング、リトライなどをすべて自動的に処理するため、サイトの制限を気にすることなくデータ収集に集中できます。
まとめ
この記事では、PythonとPlaywrightを使用してGoogle フライトのデータをスクレイピングする方法について説明しました。手作業によるスクレイピングは効果的ではあるものの、IPのブロックや継続的なスクリプトメンテナンスの必要性といった課題が伴います。データ収集の取り組みを簡素化および強化するには、住宅用プロキシ、Webアンロッカー、スクレイピングブラウザなどのBright Dataソリューションの活用を検討してください。
今すぐBright Dataの無料トライアルにご登録ください!
さらに、Google 検索結果データ、Google Trends、Google Scholar、Google マップなど、他のGoogleサービスのスクレイピングに関するガイドをご覧ください。






